Transformer
Sequence-to-sequence(简称 Seq2seq,序列到序列) 是一种深度学习的,核心逻辑是,输入和输出的长度可以不相等,输出长度由模型自主决定。它是解决“输入输出均为可变长度序列” 这类问题的通用范式,,因此广泛成为自然语言处理(NLP)、语音处理等领域的核心框架。上述任务(语音识别、机器翻译、语音翻译、TTS、聊天机器人、问答系统)核心都围绕语言 / 语音序列的处理,因此绝大多数
Seq2seq应用
Sequence-to-sequence(简称 Seq2seq,序列到序列) 是一种深度学习的通用建模框架,核心逻辑是将一个任意长度的输入序列,映射为另一个任意长度的输出序列,输入和输出的长度可以不相等,输出长度由模型自主决定。它是解决 “输入输出均为可变长度序列” 这类问题的通用范式,只要任务可以抽象为「序列→序列」的映射,就可以用 Seq2seq 架构解决,因此广泛成为自然语言处理(NLP)、语音处理等领域的核心框架。
Seq2seq在传统NLP任务中的应用有以下几种:
- 语音识别(Speech Recognition):
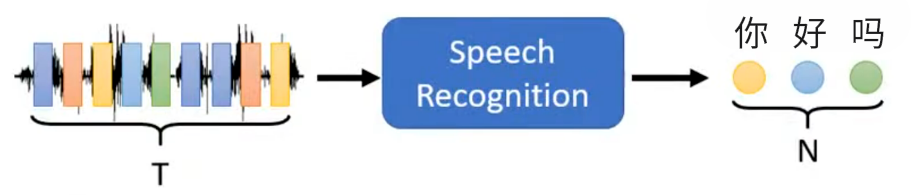
- 输入:长度为
的语音波形时间序列(音频信号,连续时间帧组成的序列)
- 输出:长度为
的文本字符 / 词语序列
- 输入:长度为
- 机器翻译(Machine Translation):

- 输入:长度为
- 输出:长度为
的目标语言文本序列(如英文 “machine learning” ,2 个单词)
- Seq2seq 最经典的应用场景。编码器编码源语言序列的语义信息,解码器基于该信息生成目标语言序列,完美适配 “源语言序列→目标语言序列” 的可变长度映射需求。
- 输入:长度为
- 端到端语音翻译(Speech Translation):

- 输入:长度为
- 输出:长度为
- 跳过 “语音转文本” 的中间步骤,直接将语音序列端到端映射为目标语言文本序列,输入输出长度可变。
- 输入:长度为
- 语音合成(Text-to-Speech, TTS):
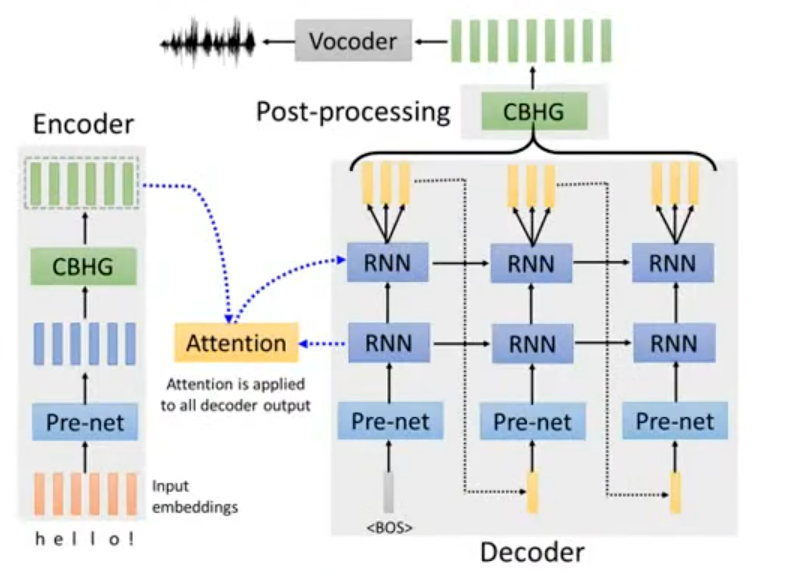
- 输入:长度为
- 输出:长度为
- 输入是文本序列,输出是语音时间序列,长度不固定。图中的 Tacotron 架构是典型的 Seq2seq+Attention 实现,Encoder(含 CBHG 模块)编码文本序列,Decoder(RNN+Attention)生成声学特征序列,最终通过声码器(Vocoder)转为语音,完全遵循 Seq2seq 的 “编码 - 解码” 序列映射逻辑。
- 输入:长度为
- 聊天机器人(Chatbot):
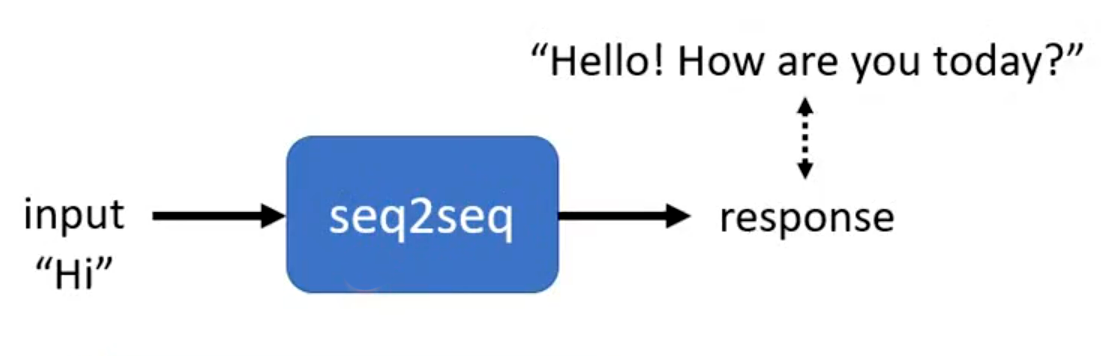
- 输入:用户输入的对话文本序列(如 “Hi”)
- 输出:机器人生成的回复文本序列(如 “Hello! How are you today?”)
- 将对话建模为 “用户输入序列→机器人回复序列”的映射,训练数据为对话对(输入 - 回复),模型学习从输入序列生成符合语境的输出回复序列,输入输出长度可变,是 Seq2seq 在对话系统的经典应用。
- 问答系统(Question Answering, QA):

- 输入:“问题(Question)+ 上下文(Context)” 组成的文本序列(如问题 “What is a major importance... + 上下文...Southern California is a major economic center...”)
- 输出:“答案(Answer)”文本序列(如 “major economic center”)
- 将 QA 任务抽象为 “问题 + 上下文序列→答案序列” 的映射,直接用 Seq2seq 生成答案(而非分类 / 抽取),输入输出长度可变。
上述任务(语音识别、机器翻译、语音翻译、TTS、聊天机器人、问答系统)核心都围绕语言 / 语音序列的处理,因此绝大多数属于自然语言处理(NLP)或语音处理(Speech Processing,NLP 的交叉领域)。
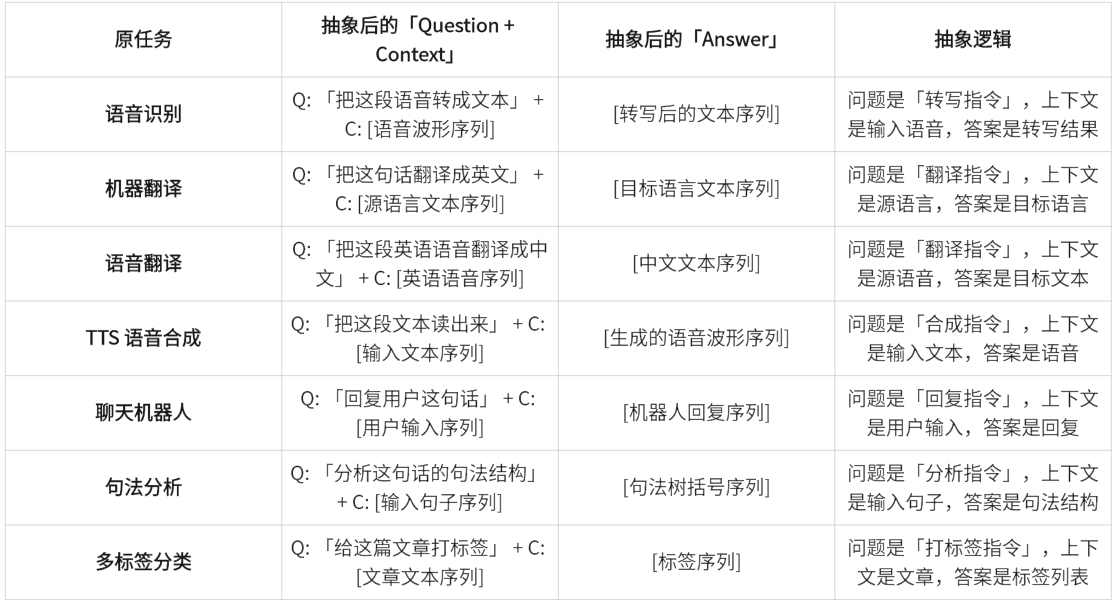
并且,所有的Seq2seq NLP 任务都可以统一抽象为「Question-Answering(QA)」范式,核心是把 “输入序列” 定义为问题(Question)+ 上下文(Context),把 “输出序列” 定义为答案(Answer),本质是 “给定问题 ,生成对应答案”。各任务转换为QA范式如下:
所有 Seq2seq 任务都可以被统一到 QA 框架下,这也是大语言模型(LLM)能通过 “指令微调” 统一所有 NLP 任务的核心原理。
Seq2seq在非传统NLP任务中的应用:
- 句法分析(Syntactic Parsing):句法分析的目标是给输入的自然语言句子,生成对应的句法树(标注句子的语法结构,如名词短语 NP、动词短语 VP、形容词短语 ADJV 等)。
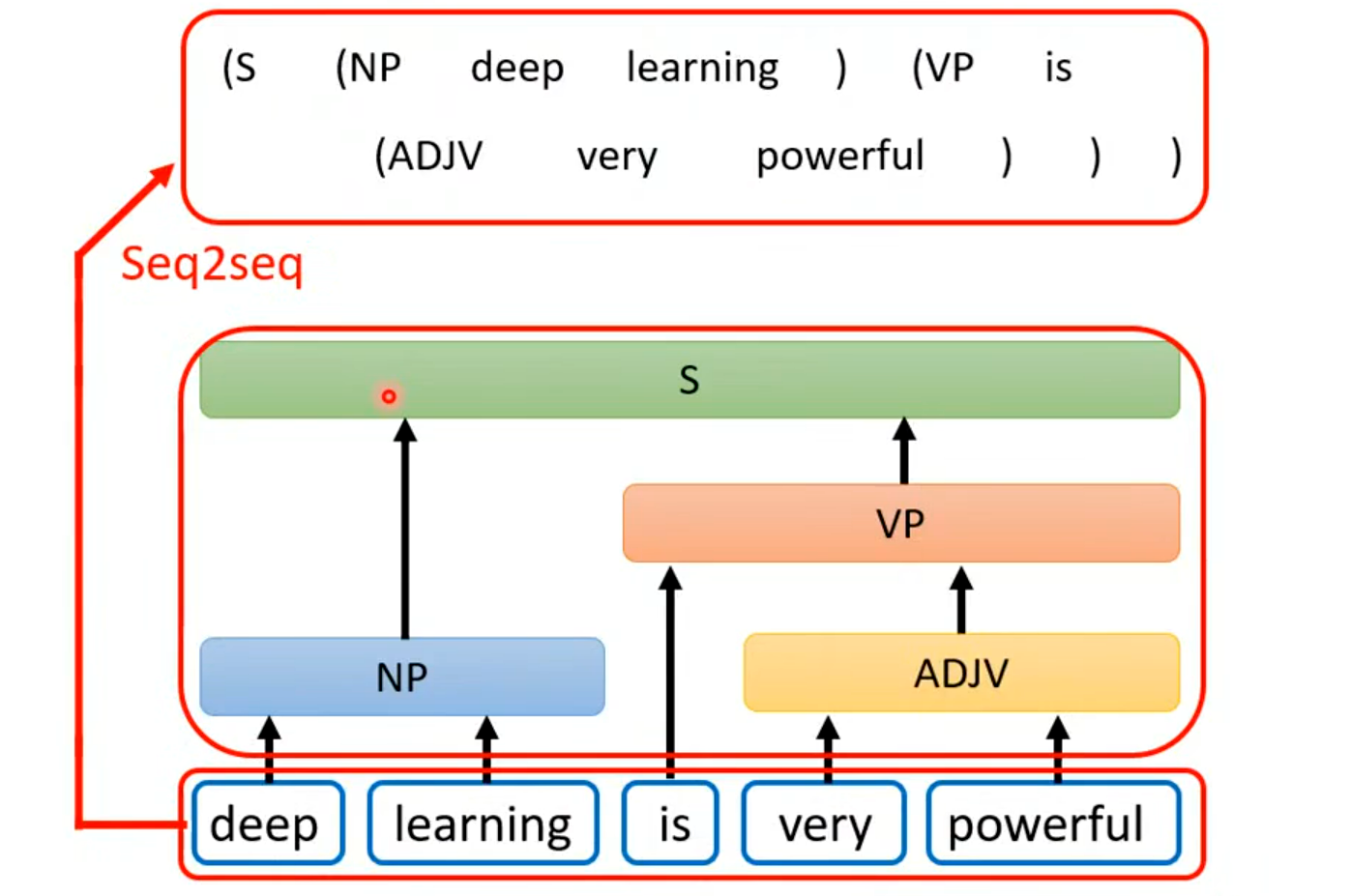
- 输入:长度为
deep learning is very powerful5 个单词组成的序列) - 输出:长度为
的线性化句法树序列(如
(S (NP deep learning ) (VP is (ADJV very powerful ))),用括号表示的树形结构的线性序列)
- 输入:长度为
- 多标签分类(Multi-label Classification):多标签分类的目标是给一个输入样本(如一篇文章、一张图片),预测它属于多个类别标签(一个样本可同时属于多个类,区别于单标签分类)。

- 输入:输入样本的特征序列(如文本序列、图像特征序列,图中以文档为例)
- 输出:长度为
的标签序列(如
Class 9, Class 7, Class 13,按顺序生成的标签列表) - 传统多标签分类是 “多分类问题”,需要固定标签数量、用 softmax 输出每个标签的概率;而 Seq2seq 的思路是把标签集合转化为标签序列生成问题。
- 目标检测(Object Detection):目标检测的目标是给输入图像,检测出图像中的所有物体,输出每个物体的类别和bounding box(边界框)坐标。
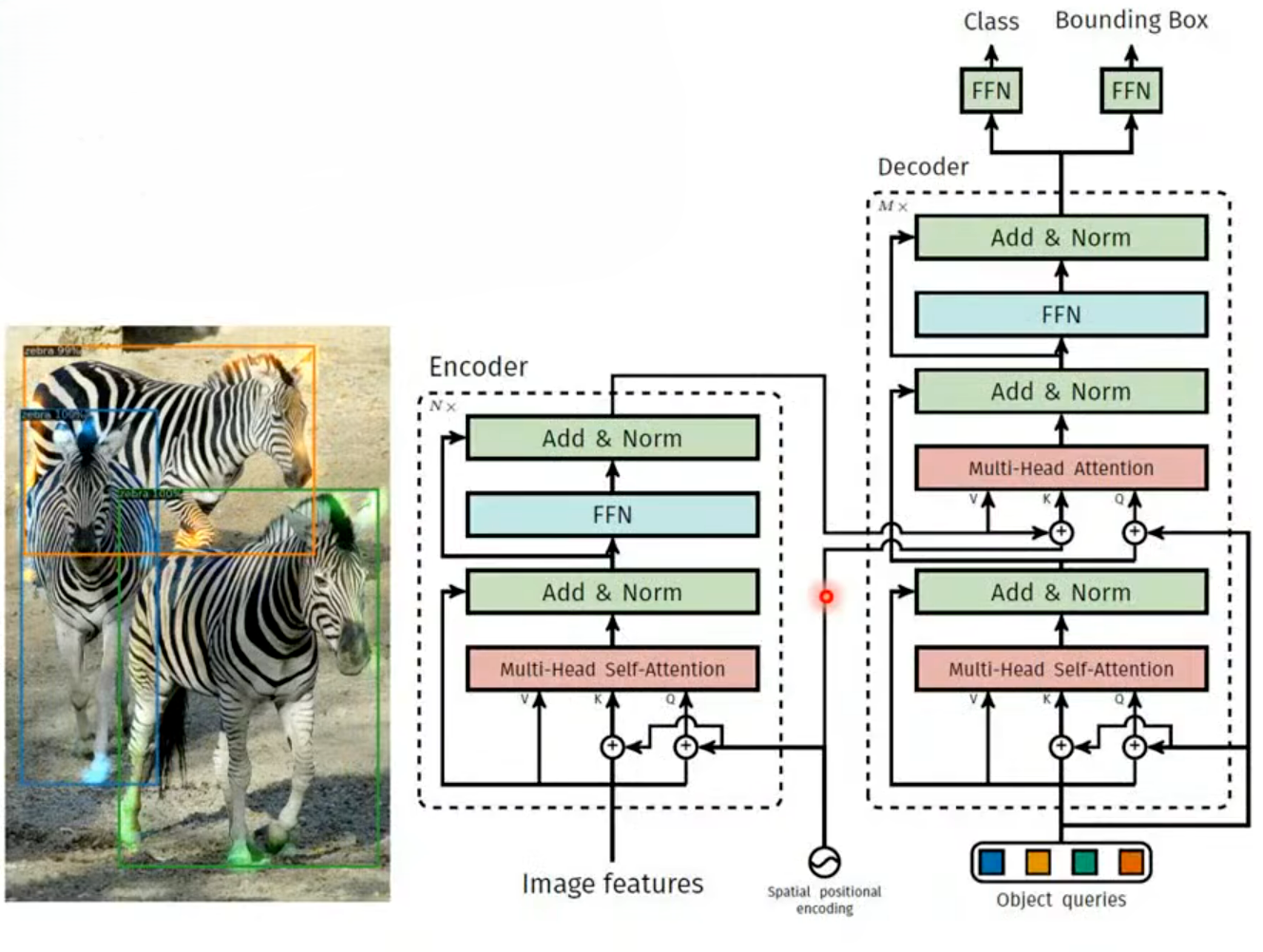
- 输入:图像的视觉特征序列(CNN 提取的图像特征,加上空间位置编码,组成长度为
- 输出:长度为
- 上图使用的模型是DETR,传统目标检测(如 Faster R-CNN、YOLO)是 “锚框 + 分类” 的范式,而 DETR(Detection Transformer)首次把目标检测完全转化为Seq2seq 问题,结构就是标准的 Transformer Encoder-Decoder
- 输入:图像的视觉特征序列(CNN 提取的图像特征,加上空间位置编码,组成长度为
Seq2seq 的本质不是 “语言模型”,而是 “序列到序列的通用映射框架”,只要任务可以被抽象为 “输入一个任意长度的序列 → 输出一个任意长度的序列”,就可以用 Seq2seq(尤其是 Transformer)解决。
Seq2seq结构
Sequence-to-sequence(Seq2seq)的本质是 “编码器 - 解码器(Encoder-Decoder)” 的通用建模框架,核心目标是将任意长度的输入序列 ,映射为任意长度的输出序列
(
与
可完全不相等)。无论后续如何升级(加 Attention、换 Transformer),Seq2seq 的核心逻辑始终不变:
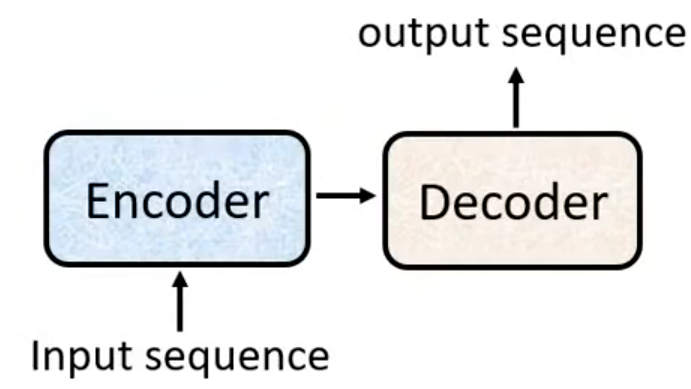
- Encoder(编码器):理解输入,将输入序列压缩为上下文信息。一般Encoder 的输入序列长度与输出序列长度相等(如Transformer Encoder、BERT、大多数视觉 Encoder(如 DETR 的视觉 Encoder)),这是因为Encoder 本质是特征提取器 / 映射函数,它的核心任务是对序列中的每个元素进行深度特征变换,并建模元素间的依赖关系;但也有少数不相等的时候,比如经典 RNN Encoder、CNN Encoder、语音识别中的 Conv 层,这些模型之所以Encoder输出于输入序列长度不相等,主要是为了降低计算量,或者将局部特征聚合为更粗粒度的特征。
- Decoder(解码器):生成输出,基于上下文信息逐词生成目标序列。
- 注意力机制(Attention):连接编码器与解码器,动态传递相关信息。
Seq2seq的原始版本完全基于循环神经网络(RNN/LSTM/GRU)实现:
- Encoder(编码器):将输入序列
编码为一个固定长度的上下文向量
,用
实现上是用一个单向 / 双向循环神经网络(RNN/LSTM/GRU),逐时间步处理输入序列,更新隐藏状态,最终用最后一个时间步的隐藏状态作为上下文向量 - Decoder(解码器):基于上下文向量
,逐时间步生成当前输出
,直到生成结束符
<EOS>(End of Sequence)。将编码器压缩的全局信息,解码为符合任务要求的目标序列,完成 输入→输出 的最终映射。
实现上是用另一个独立的循环神经网络,每个时间步的输入包含三部分:上一个时间步的输出、上下文向量
。
在RNN中我们说过,当输入序列很长时,早期的输入信息会被后期信息覆盖,导致解码器无法获取长序列的完整信息,性能急剧下降。
针对经典 RNN 版的长序列缺陷,引入注意力机制(Attention),彻底解决固定长度上下文的问题,是 Seq2seq 的里程碑式改进。Transformer完全抛弃 RNN,用自注意力(Self-Attention) 建模序列,解决了 RNN 的并行化差、长距离依赖弱的问题,是当前所有大模型、目标检测(DETR)、TTS 等任务的标准 Seq2seq 架构。
Transformer Encoder
Transformer的Encoder架构如下所示:
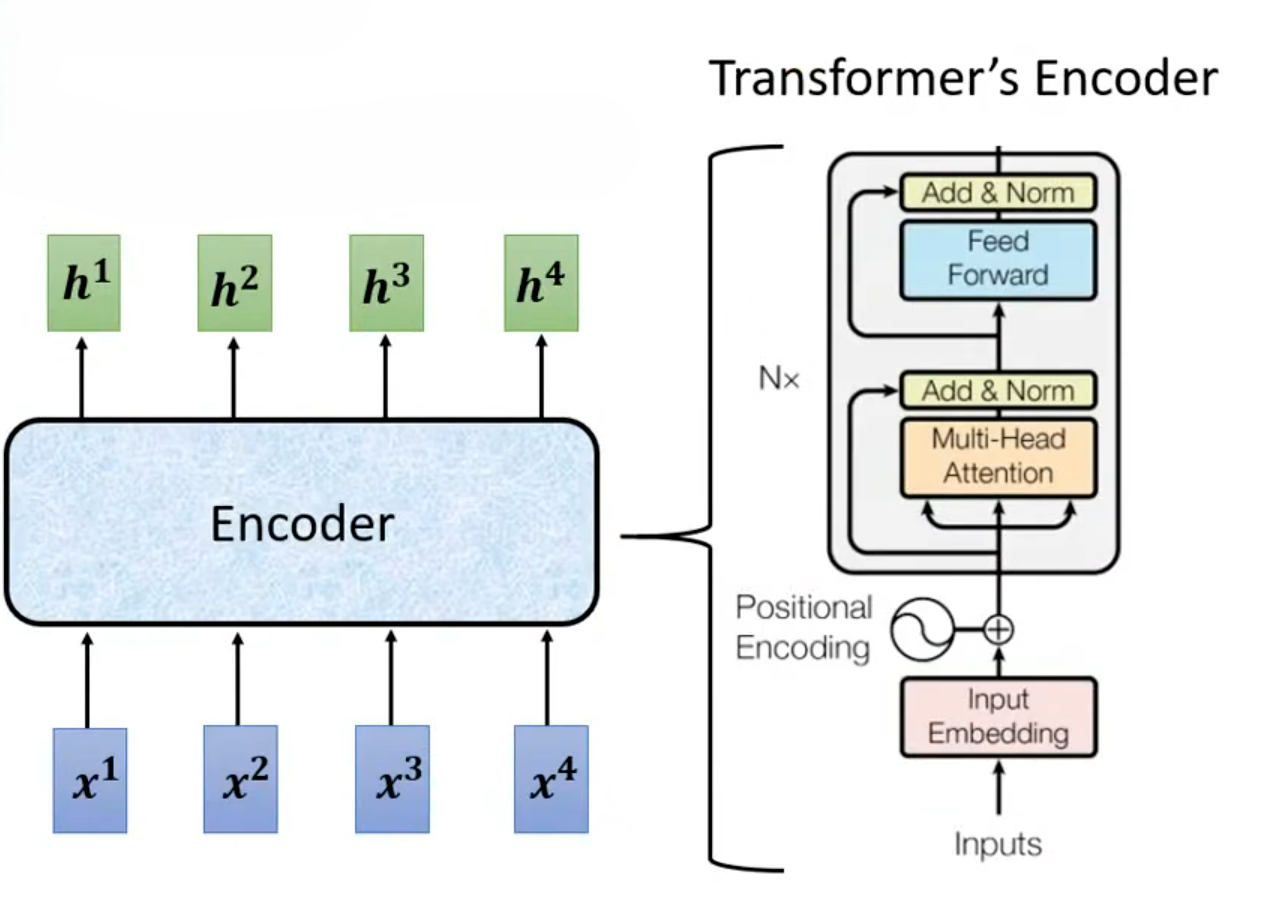
Encoder实际上是一个模型,或者说是一个由堆叠 Block 组成的深层网络架构。为了构建深度模型,提升特征表达能力,Encoder由多个Block堆叠而成,底层Block提取局部特征、语法结构(如单词的邻近关系),高层Block提取全局语义、长距离依赖(如主语和宾语的关系)。
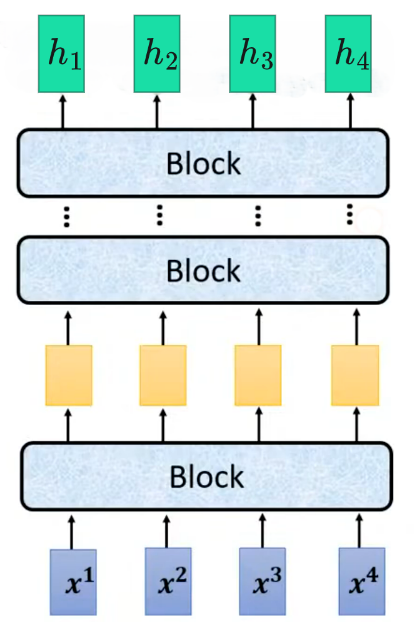
在Transformer中这个Block的内部结构如图所示:将输入的离散 token 序列(如文本、特征序列),转化为融合全局上下文信息的稠密向量序列
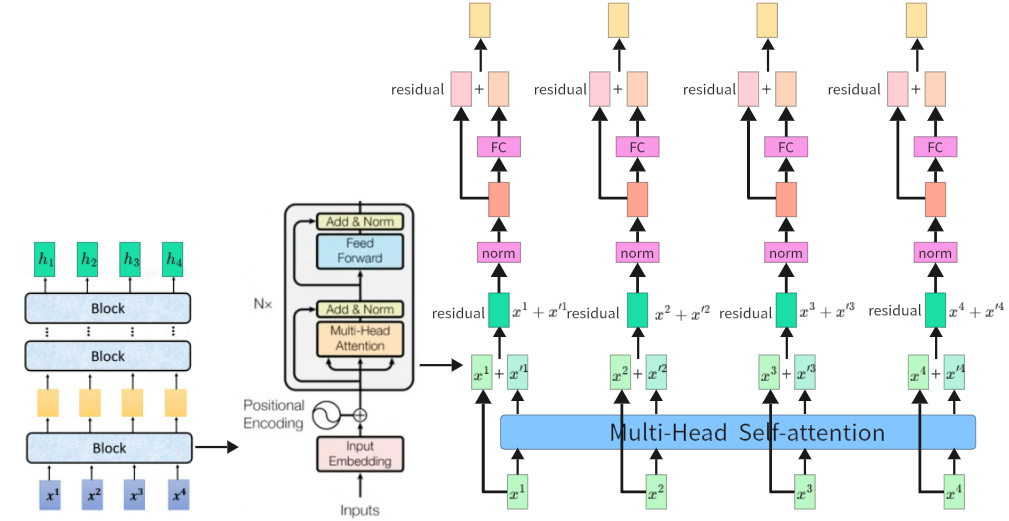
- 输入处理层:Input Embedding + Positional Encoding:
- Input Embedding(输入嵌入层):将输入的离散 token(如文本单词、子词,对应
)映射为低维稠密的连续向量(对应黄色块),把离散符号转化为模型可处理的数值表示,同时学习 token 的语义信息(相似语义的 token 向量更接近)。
具体实现过程是通过可训练的嵌入矩阵,将编码的token映射为
维向量,即
。
- Positional Encoding(位置编码层):Transformer 的自注意力是位置无关的(仅计算 token 间的相关性,不感知顺序),因此必须给每个 token 注入位置信息,让模型能区分序列中不同位置的 token,捕捉顺序依赖。
具体实现过程是将位置编码向量与嵌入向量逐元素相加,经典方案为正弦余弦位置编码,也可使用可学习的位置编码。
- Input Embedding(输入嵌入层):将输入的离散 token(如文本单词、子词,对应
- Encoder Block(编码层):Encoder Block 是 Encoder 的核心计算单元,重复堆叠
,原版 Base 为
,Large 为
),每个 Block 结构完全一致,包含 4 个核心子层:
- Multi-Head Self-Attention(多头自注意力层):建模输入序列中所有 token 之间的全局依赖关系,无论 token 距离远近,都能直接计算相关性,彻底解决 RNN 的长距离依赖问题;同时支持全序列并行计算,大幅提升训练效率。
- Add & Norm(残差连接 + 层归一化):
残差连接可以缓解深度网络的梯度消失问题,让梯度可通过残差边直接回传,支持训练数十层的深度网络;同时保留原始输入的特征信息,防止深层网络丢失底层特征。
层归一化对每个样本的特征维度做归一化(而非 BatchNorm 的 batch 维度),公式为,
是单个样本特征的均值和标准差,
是可训练的缩放、偏移参数。
- Feed Forward Network(前馈神经网络,FFN):对自注意力输出的每个 token 的表示做独立的非线性变换,提取更高层的语义特征,与自注意力的全局依赖建模形成互补。自注意力负责建模 token 间的关联,FFN 负责对单个 token 做特征变换,增强模型的非线性表达能力。
- 第二个Add & Norm(残差连接 + 层归一化)
- 最终输出:全局上下文编码序列。经过
,其中每个
对应输入 token
的最终稠密表示,融合了整个输入序列的全局上下文信息。
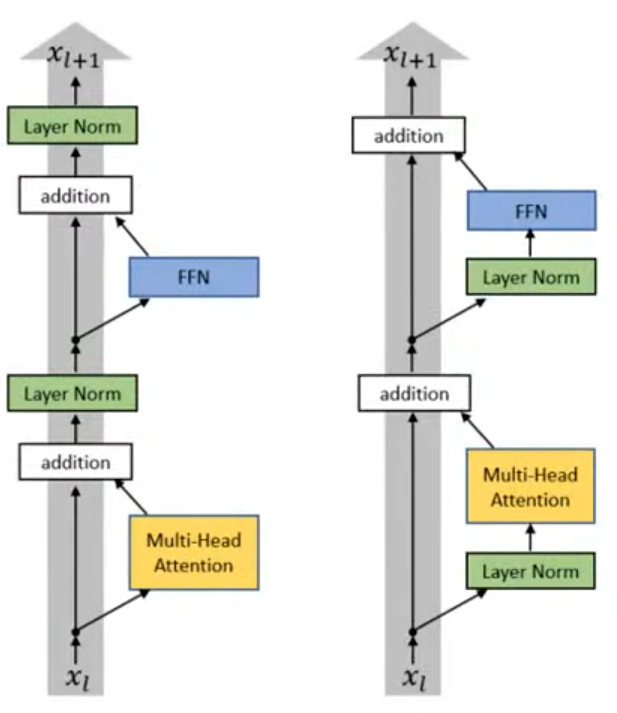
Transformer 中归一化的设计对模型训练的决定性影响:
原始Transformer采用Post-LayerNorm(后归一化,Post-LN,如下左图所示),即先做 Attention/FFN,再做残差相加,最后归一化。这样会导致深层模型中梯度需要经过多层 LayerNorm 和子层,容易出现梯度消失 / 爆炸,训练极不稳定,需要严格调参(如学习率、 warm-up)。仅在小模型、特定任务(如机器翻译)中表现稳定,不适合大模型训练。
Pre-LayerNorm(前归一化,现代大模型标准结构,如下右图所示),即先做归一化,再做 Attention/FFN,最后残差相加,是 BERT、GPT、T5 等几乎所有现代大模型的标准结构,这样做可以使梯度流更顺畅,残差边直接传递梯度,无需经过 LayerNorm,解决深层模型梯度不稳定问题,训练更稳定、收敛更快。
Transformer Decoder
Seq2seq 的核心是Encoder 编码输入,Decoder 自回归生成输出:
- Encoder:将任意长度的输入序列(如语音、文本)压缩为包含全局上下文的稠密表示,为 Decoder 提供输入信息。
- Decoder:基于 Encoder 的上下文,自回归(Autoregressive) 逐词 / 逐帧生成目标序列,每一步的输出依赖于之前所有已生成的输出,输入输出长度可变,由模型自主决定。
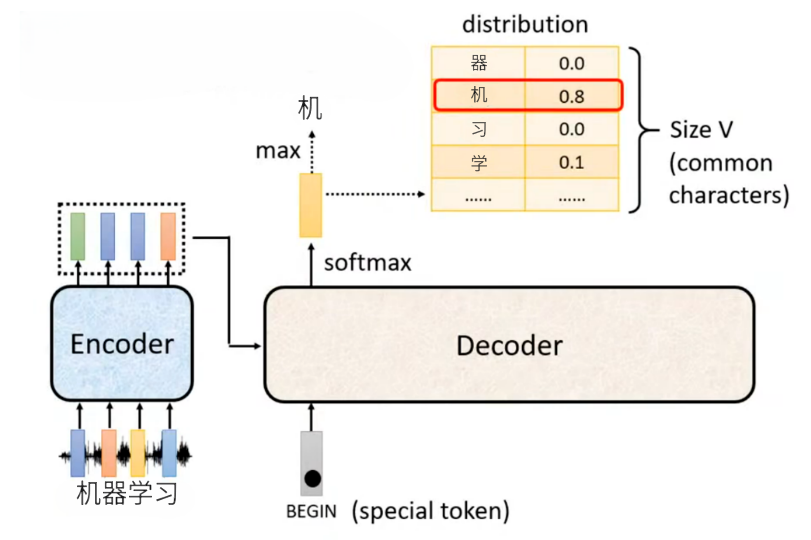
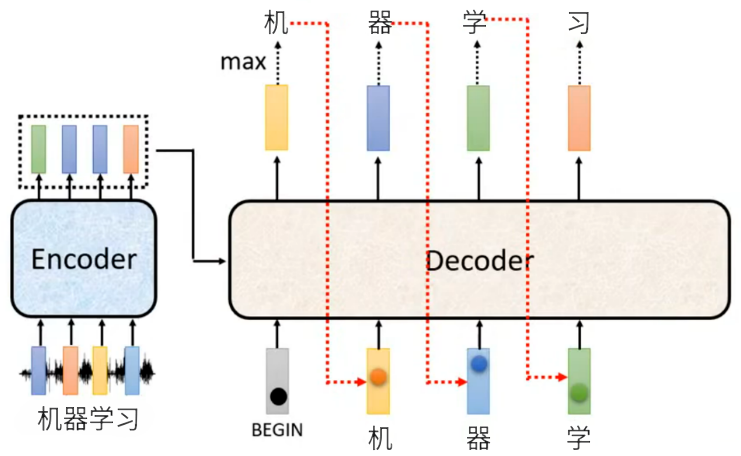
自回归解码的完整流程(以上图为例):
- Encoder编码输入:输入是 “机器学习” 的语音波形序列,Encoder(RNN/Transformer)将语音逐帧编码,最终输出全局上下文向量(上图中 Encoder 上方的 4 个彩色块),完整承载输入语音的信息,传递给 Decoder。
- 初始化编码:Decoder 的第一个输入是特殊起始符
<BEGIN>,结合 Encoder 的上下文向量,Decoder 计算当前时间步的输出概率分布:- 概率分布的大小为词表大小
V(所有常用字符 和 结束符<EOS>),图中 "机" 的概率为 0.8(最高),“習” 为 0.1,其他字符为 0。 - 取概率最大的 token得到第一个输出为 “机”。
- 概率分布的大小为词表大小
- 自回归迭代生成完整序列:自回归的核心是 “前一个输出作为下一个输入”,逐字生成:
- 将上一步生成的 “机” 作为 Decoder 的下一个输入,结合 Encoder 上下文,Decoder 计算下一个概率分布,取 max 得到第二个输出 “器”。
- 将 “器” 作为输入,生成第三个输出 “学”。
- 将 “学” 作为输入,生成第四个输出 “习”。
- 直到生成特殊结束符
<EOS>,停止解码,最终得到完整输出序列 “机器学习”。
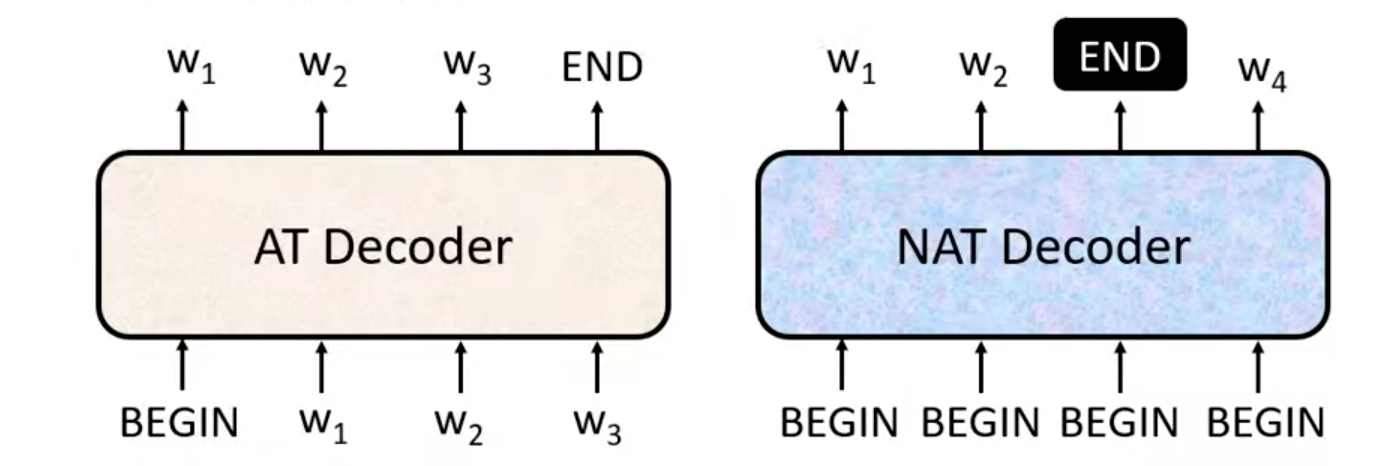
上述介绍的自回归解码(Autoregressive Decoding, 简称 AT),是 Transformer 的原生设计。它天然建模序列内 token 的强依赖关系,每一步生成都依赖历史输出,贴合自然语言 “顺序依赖、上下文关联” 的特性,是所有主流 Transformer(翻译、大模型、语音识别)的默认解码方案,生成质量最高,但推理是串行的,速度受序列长度限制。
与之对应的非自回归解码(NAT),是为了解决 AT 串行推理慢的问题,提出的并行解码架构,所有时间步的输入完全相同,都是起始符
<BEGIN>,不依赖任何历史生成的 token。模型一次性并行生成所有位置的 token,不需要等待前一个 token 生成,所有位置同时输出。NAT不依赖历史输出,实现全并行推理,但牺牲了对序列内依赖的建模能力。
AT 的输出长度由模型自回归生成到
<END>自然决定,而 NAT 是一次性生成,必须提前确定输出长度,以下给出了两种经典解决方案:
- 额外添加长度预测器:先训练一个独立的模型 / 模块,根据 Encoder 的输入,直接预测目标序列的长度
;然后让 NAT Decoder 生成
<END>,得到最终输出。- 生成长序列 + 截断:直接让 NAT 生成一个远大于最大可能长度的序列(比如生成 100 个 token);找到序列中第一个
<END>token,将其之后的所有 token 全部截断,得到最终输出。NAT的优势在于并行推理的快速性以及可控的输出长度,但是它无法建模序列内的依赖关系,在序列生成任务(如机器翻译、语音识别)中,同一个源输入,对应多个合理的目标输出序列(比如同一个中文句子,有多种语法正确、语义通顺的英文翻译;同一段语音,有多种合理的转写),这些目标序列的 token 之间存在强顺序依赖,NAT模型在预测每个位置的 token 时,只能独立预测,可能会导致生成的 token 之间逻辑混乱、不连贯,甚至出现语义矛盾。
为了弥补NAT的缺陷,也出现了很多改进方案,例如迭代 NAT(Iterative NAT)、知识蒸馏(Knowledge Distillation)、GLAT(Glancing Transformer)等等。这里不再展开介绍。
Transformer Decoder的核心是 “自回归生成 + 并行训练”:
- 用Masked Multi-Head Self-Attention保证自回归生成的正确性(只能看到历史输出,不能偷看未来 token)
- 用Encoder-Decoder Attention对齐 Encoder 的输入上下文;
- 用全注意力结构替代 RNN,实现训练时的全序列并行计算,解决 RNN 长距离依赖弱、训练慢的问题。
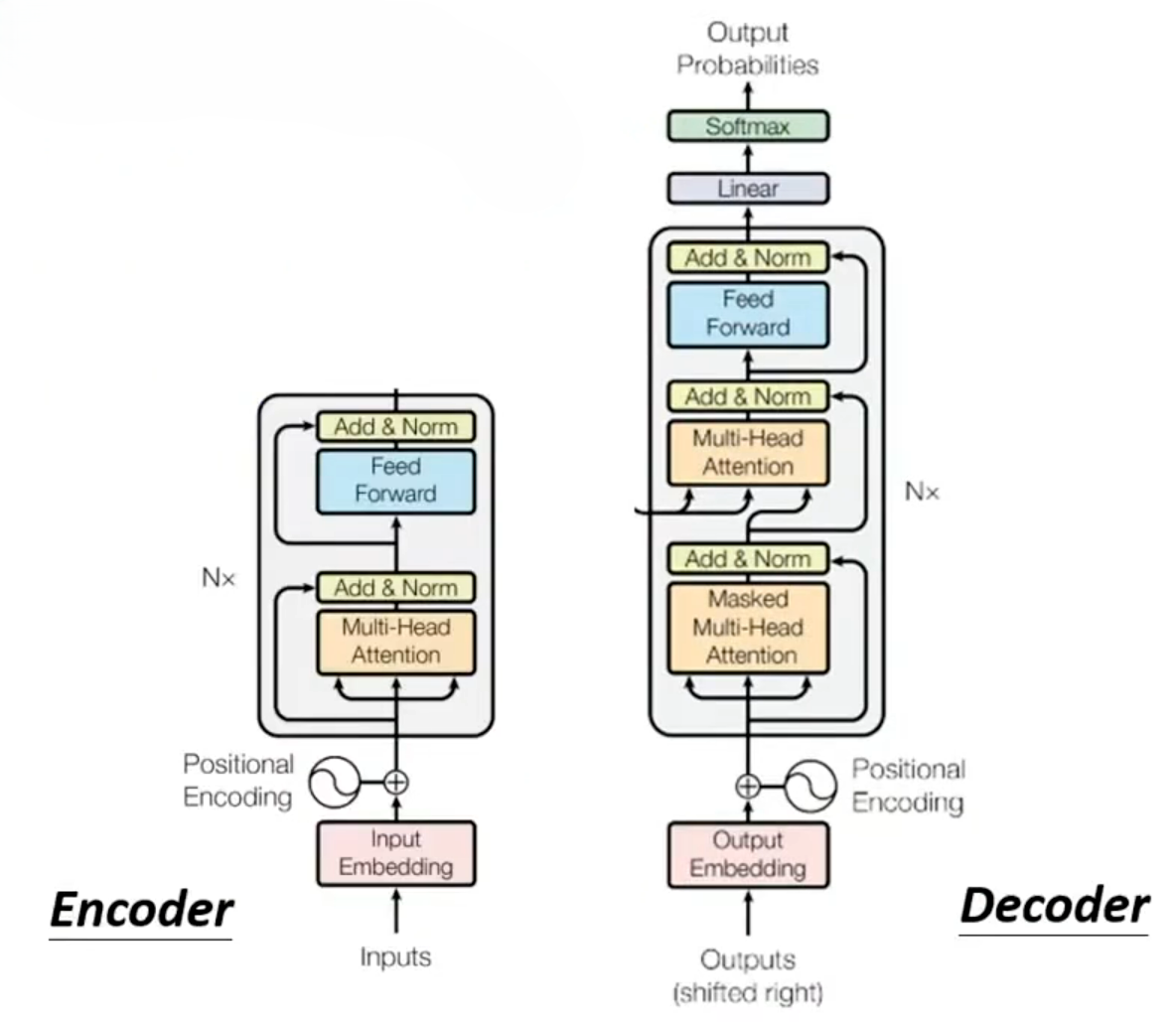
输入处理层
(1)Output Embedding(输出嵌入层):将 Decoder 的输入(上一步的输出,如<START>、机、器、学)映射为低维稠密向量,学习 token 的语义表示,和 Encoder 的 Input Embedding 作用一致。
(2)Positional Encoding(位置编码层):Transformer 自注意力是位置无关的,因此给每个 token 注入位置信息(正弦余弦编码 / 可学习编码),和 Embedding 相加后输入,让模型感知序列顺序,和 Encoder 的位置编码作用一致。
堆叠 N 个 Decoder Block
(1)Masked Multi-Head Self-Attention(掩码多头自注意力)
普通的Self-attention是无掩码的,每次输入token ,每个token都能看到所有其他 token(
能看到
能看到
为例,每个输入token
生成
(查询)、
(键)、
(值)向量。普通的Self-attention会计算
与所有
的乘积来得到相似度分数
,但是掩码操作会将
的
(键)给忽略,即只计算
与
和自身的相关性分数。对所有位置重复操作,
只能看到
,
只能看到
只能看到
,
。
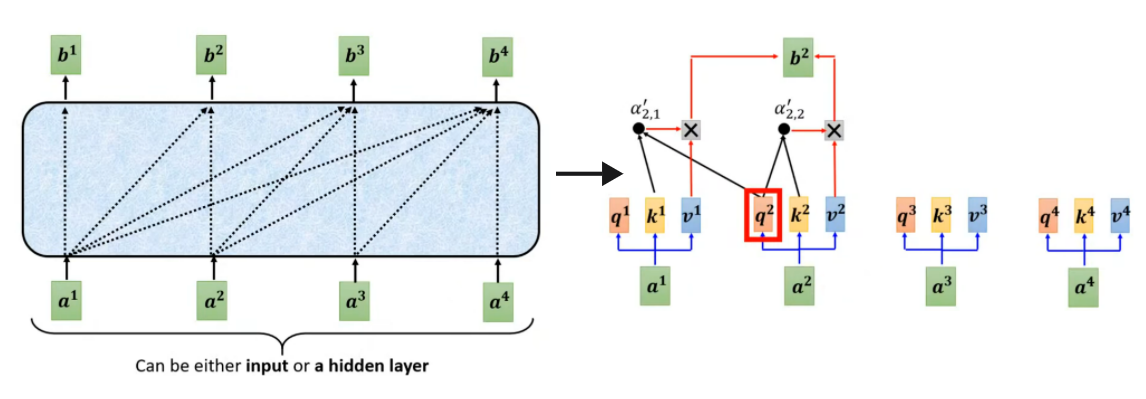
之所以要这样做,是因为Decoder 的任务是自回归生成序列,生成第个 token 时,只能依赖于已经生成的前
个 token,不能看到未来的 token,强制模型学习序列的顺序依赖,符合自然语言、语音等序列的顺序特性,让模型能学习到语言的语法、语义结构。
Encoder-Decoder Multi-Head Attention(交叉注意力,Encoder-Decoder Attention)
下图红框部分即为交叉注意力,是Encoder连接到Decoder的桥梁。
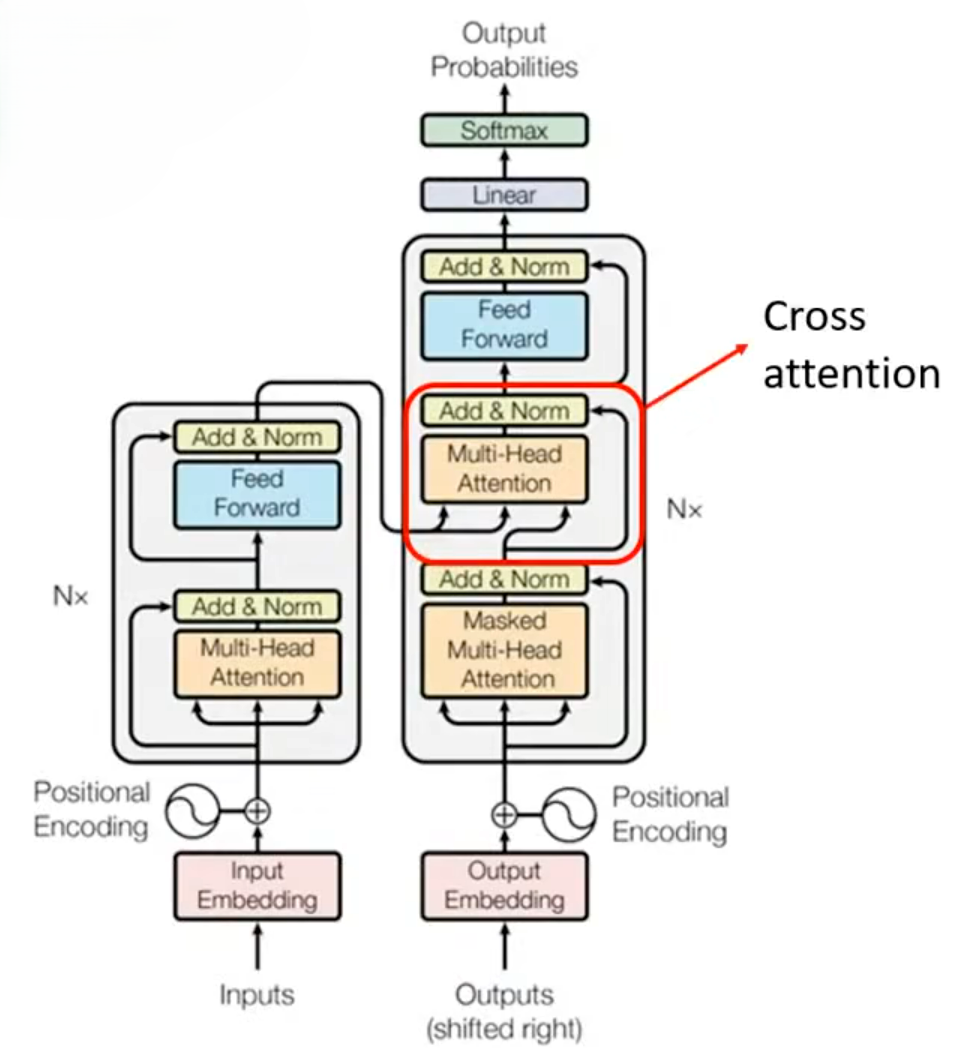
Encoder-Decoder Multi-Head Attention的核心任务是让 Decoder 在生成每一个 token 时,动态地从 Encoder 的输出中 “提取” 与当前生成步骤最相关的信息,从而实现输入序列与输出序列的精准对齐。其计算遵循“Q-K-V 注意力机制”,与普通自注意力一致,但数据来源完全不同:
(Query,查询向量)来自Decoder,代表 “当前 Decoder 正在生成什么”,去 Encoder 里找相关信息
(Key,键向量)来自Encoder,代表 “Encoder 里存储了哪些信息”,供 Decoder 查询
(Value,值向量)来自Encoder,代表 “Encoder 里信息的具体内容”,最终被加权求和输出
以下图所示的生成序列第一个 token(输出)时的交叉注意力计算流程为例,说明其步骤:
- 生成Query(
BEGIN或上一步生成的 token)经过 Masked Self-Attention处理后,得到当前位置的隐藏状态,将该隐藏状态通过一个线性层(全连接层),映射为 查询向量 - Encoder 生成 Key (
。Encoder 的每个隐藏状态
分别通过两个独立的线性层,映射为 Key 向量
和 Value 向量
。
- 计算注意力分数与权重:计算
的点积得到
。为了防止点积过大导致 Softmax 进入饱和区,通常除以
(
为
,即
。权重越大,表示 Decoder 当前生成步骤与 Encoder 该位置的信息越相关。
- 加权求和与输出:将每个注意力权重
与对应的 Value 向量
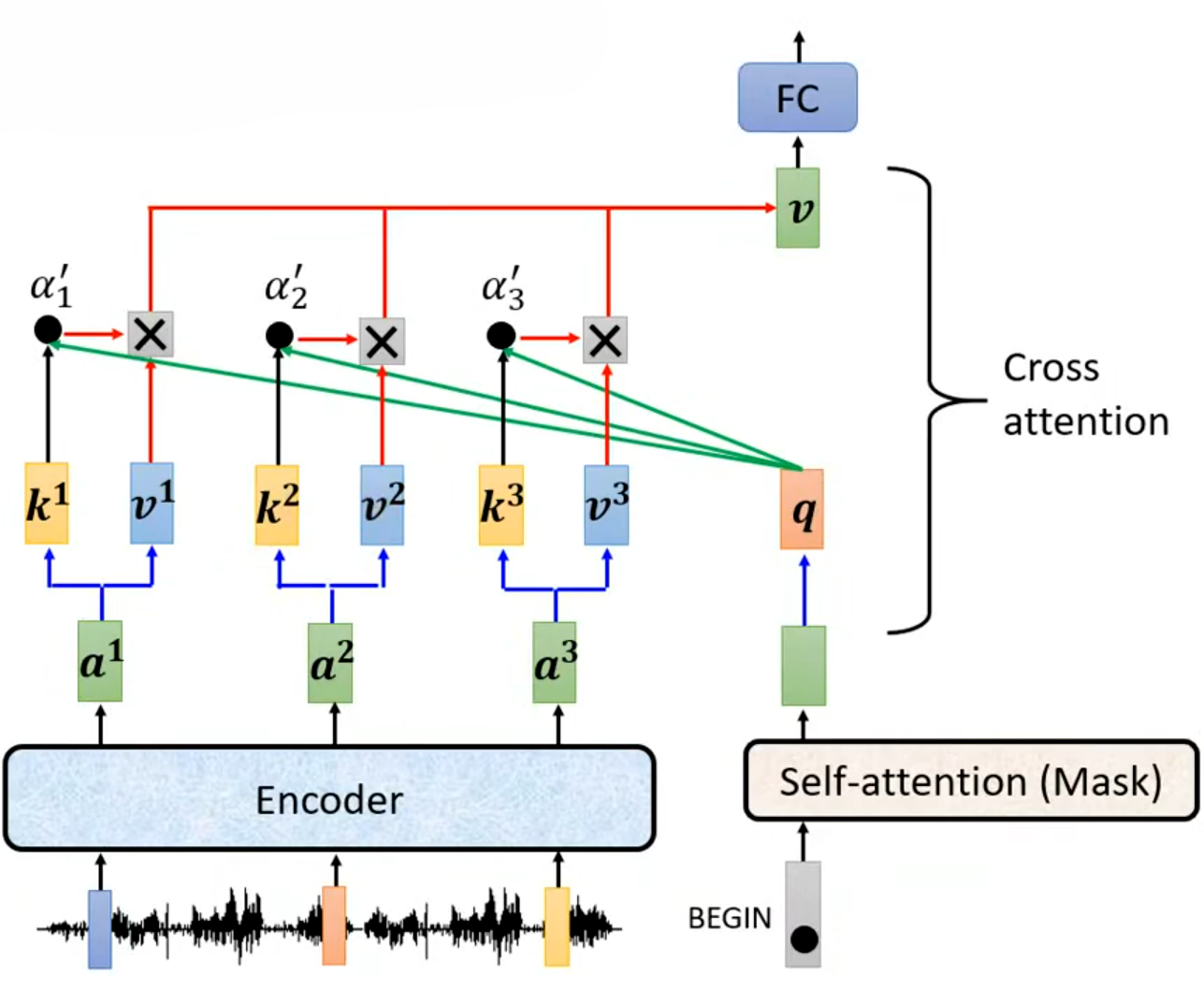
传统的标准 Transformer 只使用 Encoder 的最后一层输出(Final Layer)来计算 Cross Attention,但这是特定设计选择,而非绝对强制。
Encoder和Decoder均有很多 Block 堆叠组成,传统Transformer认为Encoder经过
源,单向传递。但是,Encoder 前几层提取的低级特征(如语音识别中的音素、机器翻译中的词法)被层层过滤,到最后一层可能丢失或难以被 Decoder 直接获取。所以,可以使用其它的连接路径:
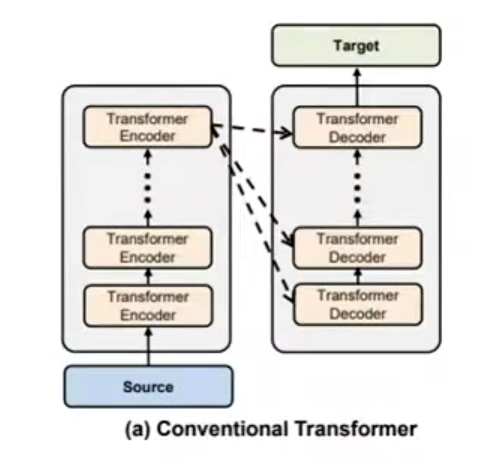
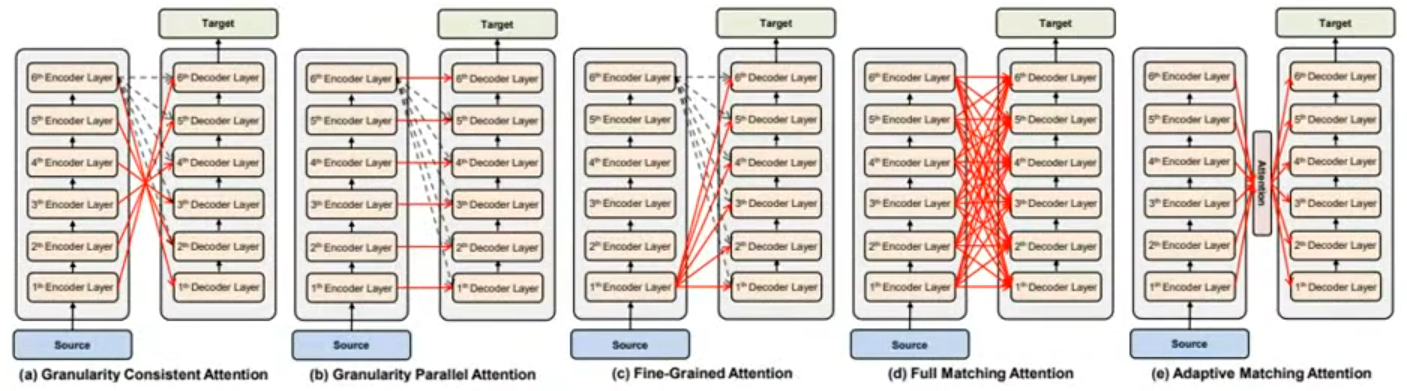
多头注意力机制(Multi-Head Attention):上面介绍的都是单头注意力,而完整的 Transformer 采用 Multi-Head,将
分别线性投影到
个不同的子空间,在每个子空间独立计算注意力,计算完
不同的头可以关注不同类型的依赖关系(例如:有的头关注语音识别的音素对齐,有的头关注语义关联),让模型能同时捕捉多种复杂的输入输出映射关系,显著提升模型性能。
Transformer Input
在机器翻译、聊天机器人等语言处理任务中,通常输入的是一串语言文字,例如“I love China”、“我爱中国”等。为了让模型能够处理这些文字,会先创建一个词汇表(词汇表内包括所有文字,每一列对应一个文字),然后给这些文字一个唯一标签ID(例如“我”对应ID 1,“爱”对应ID 2),每个ID对应词典中对应列索引。之后将每个文字编码为一个向量,即使用一个向量来表示一个token(词 / 子词),为了方便说明,我们假设一个单词/字用一个向量表示,这个向量称为词嵌入向量(Word Embedding)。将所有token向量拼接到一起就得到了一个矩阵,称为词嵌入矩阵(Embedding Matrix),它的每一列对应词汇表(vocabulary)中一个 token(词 / 子词)的嵌入向量,维度为
,
是词汇表大小(GPT3约 5 万个 token),
是嵌入维度。当要输入一段文字给模型时,会先在词汇表中找到每个文字对应ID,然后取出ID对应词嵌入向量,之后拼成词嵌入矩阵输入模型。
词嵌入矩阵(Embedding Matrix)
的嵌入维度
;对于BERT/GPT等大模型

一般的One-hot、ASCII等固定编码是给每个字符 / 单词分配一个唯一的ID 号,其向量数值是人工定义的、固定的。而Transformer 里的编码是语义嵌入(Token Embedding),即给每个 token 分配一个语义特征向量,承载语义、语法、上下文关系,它的向量数值是不固定的,由训练学习得到。这是因为我们需要的不是标识单词,而是理解语义,而语义只能通过数据驱动的训练来学习。
模型在学习海量文本数据的过程中,不断调整每个 token 的向量数值,这个过程让语义相似的 token,在高维嵌入空间中距离更近(比如cat/dog/pet的向量会被调整到相邻区域),让语义不同的 token,在嵌入空间中距离更远(比如cat和car的向量会被推远)。最终让每个 token 的向量都承载语义相似度、句法关系、上下文联系等信息。
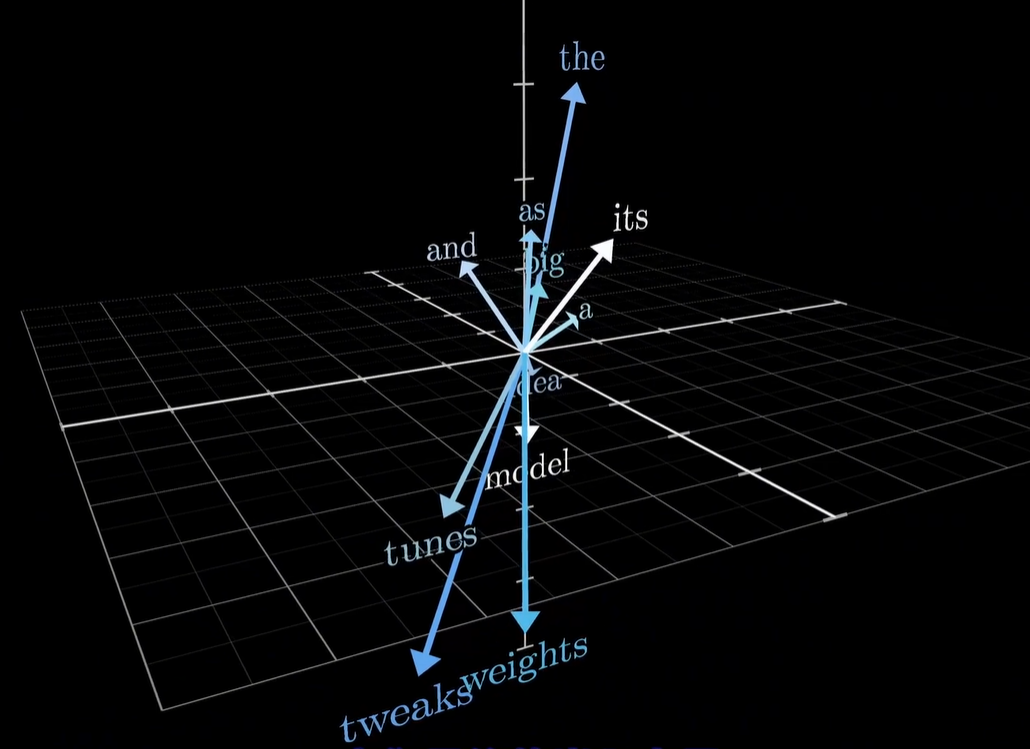
嵌入矩阵的训练是和整个 Transformer 模型端到端(end-to-end)同步完成的,核心是反向传播 + 梯度下降,以输入 “今” 预测 “天” 这个极简任务为例,用具体数据演示词嵌入矩阵的更新过程:
首先假设词汇表大小,其索引ID
分别对应 ["<pad>", “今”, "天", "好"],假设词嵌入维度
。训练开始时会随机初始化的词嵌入矩阵
(如正态分布
、均匀分布),此时向量是无意义的随机数:
为了简便,我们省略 Decoder 中间层,直接把嵌入向量投影到词表得到 logits
- 模型输入:输入token “今” → ID=1。查词汇表得到词向量矩阵
- 得到输出 logits(词表上的分数):
(
表示Decoder整个模型),得到 4 个词的分数
- 经过softmax转为概率分布:
,
- 构造标签:真实词是 “天” → ID=2。将标签转为one-hot向量(只有正确位置为 1,其余 0),
- 计算交叉熵损失:只有标签为 1 的位置有效
- 反向传播:
- 梯度下降更新公式:
经过 “词嵌入 + 位置编码” 后,最终输入序列向量为:
该序列向量会与不同的矩阵相乘线性投影得到
::
其中
都是可学习参数矩阵。所以
Transformer训练与推理过程
虽然基础的Transformer包括Encoder和Decoder,但并不是所有的模型都同时用到两者。具体使用Encoder、Decoder还是两者都用取决于用的是哪种 Transformer 架构,原始 Seq2Seq 版 Transformer(机器翻译)训练、推理都要同时用 Encoder+Decoder;但现在主流的 BERT、GPT 等变体,只用到其中一半。
下面我们先详细介绍原始标准Encoder-Decoder Transformer语音识别的训练过程。之后会介绍Encoder-Decoder Transformer机器翻译场景中Encoder和Decoder训练时和推理输入输出、Decoder-only架构中Decoder训练时和推理时输入输出以及Encoder-only架构中Encoder训练时和推理时输入输出。通过不同的输入输出就可以看出三者之间的显著区别,进一步了解为什么只用Encoder或Decoder。
Encoder-Decoder训练过程
原始的 Encoder-Decoder Tranformer架构主要用来做机器翻译、语音识别等这种有两个独立序列(英文源句、中文目标句)的任务,这种任务需要需要 Encoder 编码源句来获取整个句子的语义,Decoder 再通过交叉注意力去查 Encoder 的信息来得到输出。
Encoder-Decoder Transformer训练核心是 “Encoder 编码输入 + Decoder 并行解码 + Teacher Forcing + 交叉熵损失”。先以语音识别任务(输入语音、输出文本 “机器学习”)为例,完整流程如下:
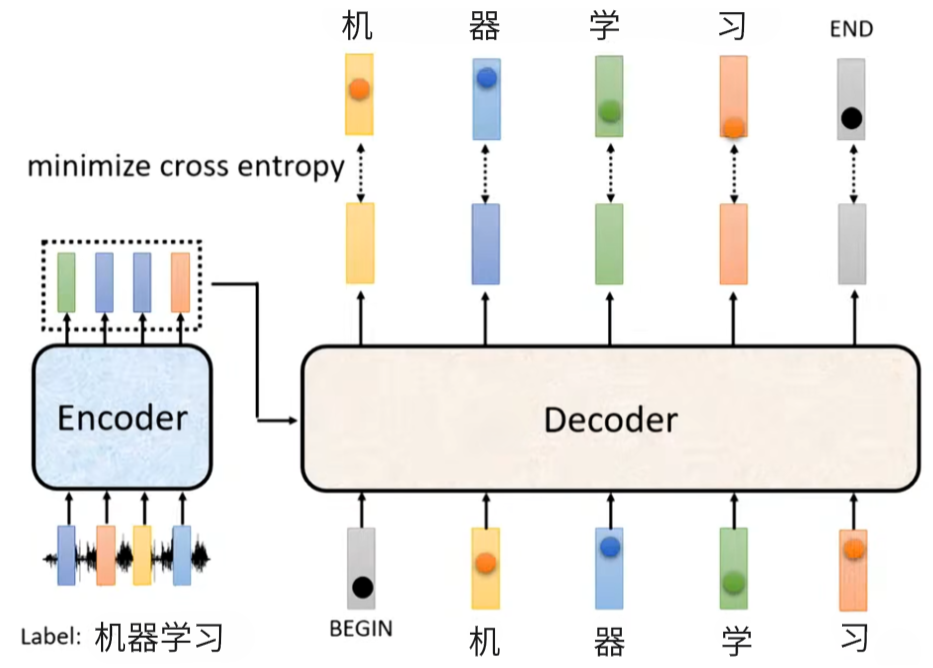
1.数据与输入
- Encoder 输入:
- 原始输入:源序列(语音波形。需要通过特定方式转换成向量)
- 预处理:输入经过Input Embedding(嵌入层) + Positional Encoding(位置编码),将离散符号 / 语音特征转化为带位置信息的稠密向量,输入 Encoder。
- Decoder输入:
- 输入序列:[<BEGIN>, 机, 器, 学, 习]
- 目标序列(Ground Truth):[机, 器, 学, 习,<END>]
- Teacher Forcing:训练时 Decoder 的每一步输入,直接使用真实标签(Ground Truth),而非模型上一步生成的 token。
Teacher Forcing 的作用:
- 避免自回归生成的误差累积,训练时每一步输入都是正确的 token,模型不会因为早期错误导致后续训练崩溃,大幅提升收敛速度。
- Transformer 可以一次性输入整个目标序列,并行计算所有时间步的注意力和 FFN,实现大规模快速训练。
2.前向传播流程
(1)Encoder 编码阶段:源序列经过 层堆叠的 Encoder Block(每层为 “Multi-Head Self-Attention → Add&Norm → FFN → Add&Norm” ),最终输出编码后的上下文向量序列(图中 Encoder 上方的彩色块),该序列完整承载了输入的全局信息,作为 Decoder 的 “交叉注意力” 的 Key 和 Value。
(2)Decoder 解码阶段:输入序列经过Output Embedding + Positional Encoding,输入N 层堆叠的 Decoder Block。
(3)输出层:Decoder 的最终输出经过Linear 全连接层,将隐藏维度映射为词表大小的维度,再经过Softmax 激活函数,得到每个时间步的词表概率分布。
3.损失计算与反向传播
每个时间步独立计算交叉熵损失,公式为:
![]()
:Ground Truth 标签(如真实 token “机” 对应 1,其他字符为 0)
:模型预测的概率分布(如 “机” 预测概率为0.7)
:词表大小
所有时间步的损失累加 / 取平均,作为整个模型的总损失。
总损失通过反向传播算法,更新 Encoder 和 Decoder 的所有可训练参数(注意力层、FFN 层、Embedding 层等),重复迭代直到模型收敛。
Exposure Bias
Teacher Forcing 虽然让训练高效稳定,但训练阶段Decoder 的输入是100% 正确的 Ground Truth,模型从未接触过错误的输入。而在推理阶段Decoder 是自回归生成,每一步的输入是模型上一步生成的 token,若某一步生成错误(如把 “器” 错生成为 “气”),下一步的输入就是错误的 “气”,模型在训练时从未处理过这种错误输入,导致后续生成持续出错,误差不断累积,最终输出完全偏离预期。Teacher Forcing 让训练快,但训练和推理的输入分布不一致,导致模型在推理时性能大幅下降,这就是 Exposure Bias。
Scheduled Sampling
Scheduled Sampling 是经典的缓解 Exposure Bias 的训练策略,核心是在训练时 “混合使用 Ground Truth 和模型生成的输入” ,让模型在训练时就接触到 “自己生成的、可能错误的输入”,学会处理错误,减少推理时的误差累积。其基本过程是以一个随训练轮数动态衰减的概率
,随机选择 Decoder 的下一个输入:
- 首先定义一个随训练 epoch
衰减的概率
,其中
- 对 Decoder 的每一个时间步
生成一个 0~1 之间的随机数
,如果
则使用 Ground Truth 真实标签作为下一个时间步的输入(Teacher Forcing),如果
则使用模型上一步生成的 token作为下一个时间步的输入(模拟推理自回归)
通过Scheduled Sampling可以做到:
- 训练初期:
- 训练中期:
- 训练后期:
Parallel Scheduled Sampling
原始 Scheduled Sampling 针对 RNN 设计(串行训练),Transformer 是并行训练,因此有Parallel Scheduled Sampling。其基本过程如下(以目标序列
[机, 器, 学, 习]为例):
- 并行贪心前向,生成 “全序列预测 tokens”:给 Decoder 输入纯 Ground Truth 序列(Teacher Forcing 标准输入)模型一次性并行前向传播,算出所有位置
- 生成采样掩码矩阵:生成一个和序列等长的二进制随机掩码 Mask,以概率
选 Ground Truth ,以概率
选模型预测
。例如
,则下一次训练时的输入序列为
。掩码是随机、逐位置独立的。
- 最终混合输入序列为 [机,
, 学,
],将构造好的混合输入送入 Decoder,一次性并行计算所有位置的输出。下一次训练过程同上。
Scheduled Sampling可以有效缓解 Exposure Bias,提升推理时的生成质量,减少误差累积,但是仍存在一定的分布差距(训练时混合输入,推理时全自回归),现在大模型更多采用强化学习(RLHF)、Speculative Decoding 等更先进的方案,但 Scheduled Sampling 是经典的基线方法。这里不再赘述。
Transformer “损失 - 评估指标不匹配” 问题及其解决方法
我们在训练时使用的是逐 token 交叉熵损失计算,而最终的任务评估指标是序列级指标,关注的是生成序列的整体质量。具体解释如下:
- 标准监督训练(逐 token 优化,交叉熵损失)(左图):Decoder以Teacher Forcing的方式,输入Ground Truth,逐时间步生成每个 token 的概率分布,取概率最大的 token 作为输出,训练的优化目标是逐 token 最小化交叉熵损失,也就是让模型在每一个时间步,都尽可能预测对当前的真实 token。
- 本质:token 级(词级)的局部优化。优化的是每一步的单 token 预测准确率,而非整个生成序列的最终质量。
- 核心缺陷:逐 token 最大化概率,不代表最终生成的完整序列是最优的。例如某一步选择次优概率的 token,后续生成的整个序列可能更符合真实标签、BLEU 分数更高,但交叉熵会惩罚这一步的次优选择,导致模型陷入局部最优。
损失与评估指标完全脱节,任务的最终评估是序列级指标,而交叉熵是 token 级损失,两者的优化目标完全不一致。- 序列级优化(直接优化评估指标)(右图):这是我们真正想要的训练目标。Decoder 不再输入 Ground Truth,而是自回归生成完整的输出序列,然后直接计算这个完整序列的评估指标(图中标注
BLEU score,即 BLEU 分数,机器翻译 / 生成任务的经典评估指标),目标是最大化整个序列的评估指标,而非逐 token 的概率。
- 本质:sequence-level(序列级)的全局优化,优化目标和人类评估模型的标准完全对齐,追求最终生成序列的整体质量最优。
- 核心缺陷:评估指标(如 BLEU)是不可导的离散函数,无法用传统的反向传播(梯度下降)直接优化。
解决方法一:Beam Search(束搜索)
目前工业界和学术界,大部分的 Transformer 训练依然直接使用交叉熵损失(Token-level),因为它更简单、收敛更快、算力消耗少。虽然损失函数是 Token 级,但在推理时往往配合 Beam Search(束搜索) 来寻找近似的序列最优解。
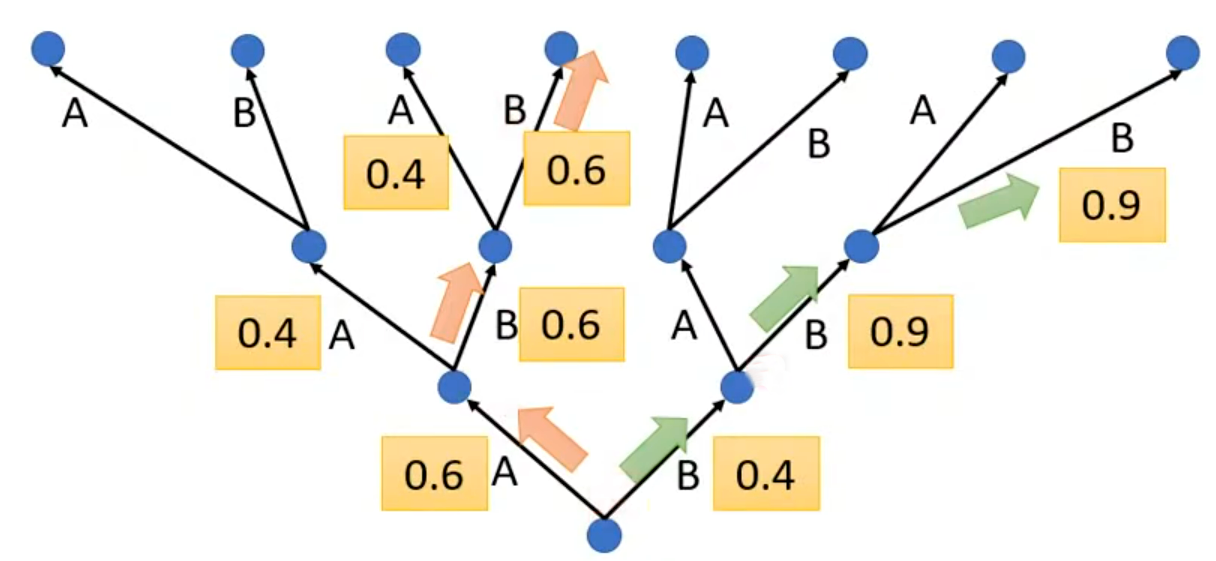
Beam Search是自回归序列生成模型(如 Seq2seq、Transformer)的经典解码(推理)算法,是 贪心搜索(Greedy Decoding)和 穷举搜索(Exhaustive Search) 的折中方案。它的出现是为了解决自回归生成中两个矛盾:
- 贪心搜索的 局部最优 ≠ 全局最优 :贪心搜索就是我们上面说的标准监督训练逐 token 优化,每一步只选当前概率最高的 token,但这无法保证最终生成的完整序列是全局最优的。例如上图我们假设只有A和B两个token,红色路径第一步选概率 0.6 的 A(局部最优),后续每一步选当前最高概率,最终序列累积概率仅为
0.6×0.6×0.6=0.216;绿色路径(全局最优)第一步选概率 0.4 的 B(局部次优),但后续两步概率 0.9,最终累积概率0.4×0.9×0.9=0.324,远高于 Greedy 路径。- 穷举搜索的计算爆炸:如果要找真正的全局最优,需要穷举所有可能的序列,计算量为
(
Beam Search 将计算量严格控制在(所以Beam Search的目的是在可控的计算成本内,最大化生成序列的整体质量(如 BLEU 分数、转写准确率),实现局部最优到近似全局最优的跨越,让生成的完整序列更符合任务需求(如翻译准确、语音转写正确)。其工作过程如下(以3-token(A/B/C)词表、beam size
,序列长度
为例),为了演示,我们假设Decoder 在每个时间步输出的概率如下:
- 生成第一个 Token (
):从词表中,选出 2 个 概率最高的 token,作为初始候选。由于
所以我们只保留
最优候选。
- 扩展并筛选第二个 Token (
):对每一个保留的候选,分别扩展所有 3 个 token,生成 2×3=6 个新候选,再从中筛选出 2 个最优。
基于Beam 1(A)扩展:
序列, 序列
,序列
基于Beam 2(B)扩展:
序列, 序列
,序列
其中序列概率最高,为最优候选,保留。
- 扩展并筛选第三个 Token (
):
基于Beam 1()扩展:
序列, 序列
,序列
基于Beam 2()扩展:
序列, 序列
,序列
最终Beam Search 选择累积概率最高的序列:实际训练 / 推理中用
替代原始概率,将乘法转为加法,避免浮点下溢,计算更稳定。除此之外,还要注意长序列的累积概率天然低于短序列,因此添加长度惩罚项,避免模型倾向于生成过短的序列。
Beam Search 并非所有场景都适用,仅在 “追求准确率” 的任务中表现优异,在 “追求多样性 / 创造性” 的开放域生成任务中存在严重缺陷:
- 追求 “准确率” 的任务:机器翻译(准确对应原文)、语音识别(准确转写语音)、文本摘要(忠实原文),这类任务的核心目标是 “生成内容与参考 / 输入尽可能匹配”,Beam Search 最大化序列的累积概率,能生成最符合模型分布、最准确的序列,直接提升 BLEU、WER 等评估指标,完全匹配任务需求。
- 追求 “多样性 / 创造性” 的开放域生成任务:对话系统(聊天机器人)、故事创作、诗歌生成、开放域文本生成,Beam Search 为了最大化累积概率,会倾向于生成高频、安全、重复的文本(因为高频词的概率更高,模型会反复选择),Beam Search 是确定性算法,每次生成的序列几乎完全一致,没有创造性。
解决方法二:强化学习(Reinforcement Learning, RL)
强化学习把 Seq2seq 的生成过程完全建模为 RL 的标准马尔可夫决策过程(MDP)。针对评估指标不可导的问题,用策略梯度算法实现端到端优化,核心逻辑是通过采样多个模型生成的序列,用序列的奖励(BLEU 分数)加权更新模型参数,让模型更倾向于生成 奖励更高(评估指标更好) 的序列。
关于强化学习部分,不是这里的重点内容,本文章不做详细介绍。
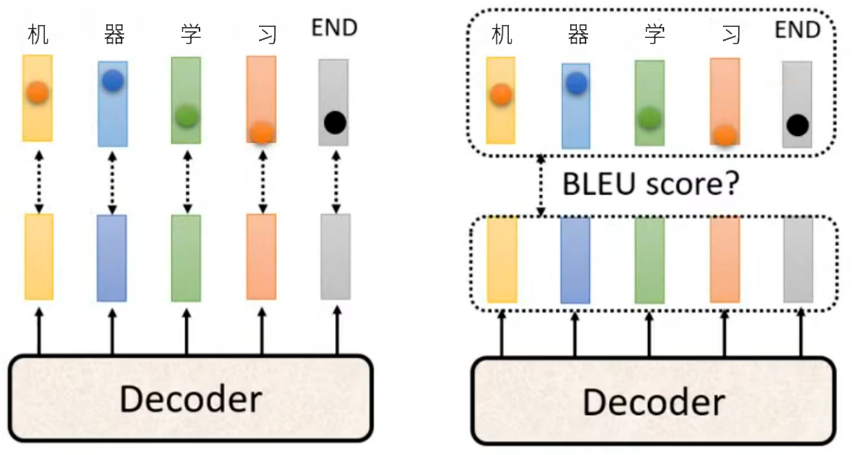

(选读)
Copy Mechanism(复制机制)
复制机制就是让模型能直接从输入序列中,复制关键的专有名词、实体、低频词到输出序列,保证生成内容的准确性和连贯性,例如用户姓名或者专有名词这种模型没有见过的词语,复制机制可以让模型完整复制到了自己的回复中,避免了把姓名当成未登录词(OOV)、用
<UNK>替代或错写的问题,保证了实体的准确性。经典实现复制机制的模型是Pointer-Generator Network(指针生成网络),本文章不做介绍。
Guided Attention(引导注意力)
Guided Attention(也叫单调注意力 Monotonic Attention / 位置感知注意力 Location-aware Attention),是专门针对输入输出存在严格单调对齐的序列任务(如语音识别、TTS,语音前半段对应文本前几个字,后半段对应后几个字)设计的注意力约束机制。它的逻辑是给标准 Seq2seq/Transformer 的无约束注意力添加 “强制单调右移” 的引导约束,让模型的注意力分布严格符合任务的输入输出顺序对应特性,从根本上避免错误对齐。
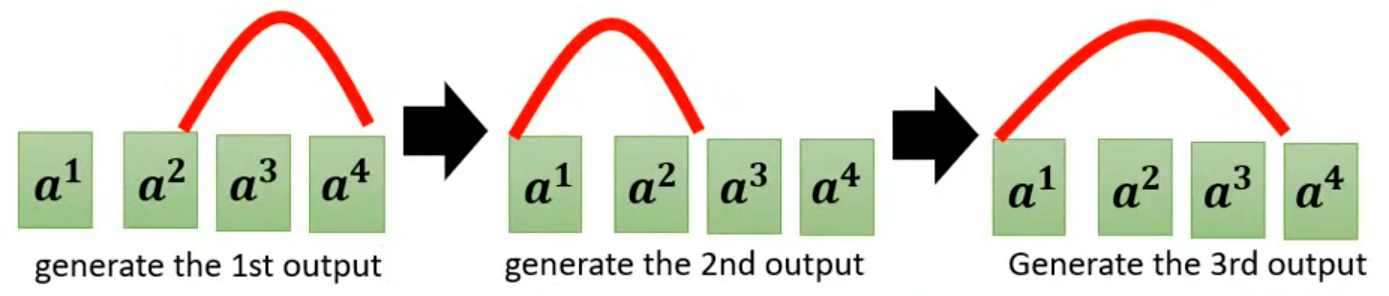
标准无约束注意力(普通 Multi-Head Attention)没有顺序约束(下图红色曲线表示注意力分数):
- 第 1 个输出:注意力峰(红色曲线最高点)在 a²、a³;
- 第 2 个输出:注意力峰往左跳到 a¹、a²,位置比第一个输出的注意力峰更靠左;
- 第 3 个输出:再跳回 a³、a⁴。
- 上述这种对齐完全违背了语音 / 文本的顺序对应,模型生成时会出现漏字、错字、重复、语义混乱
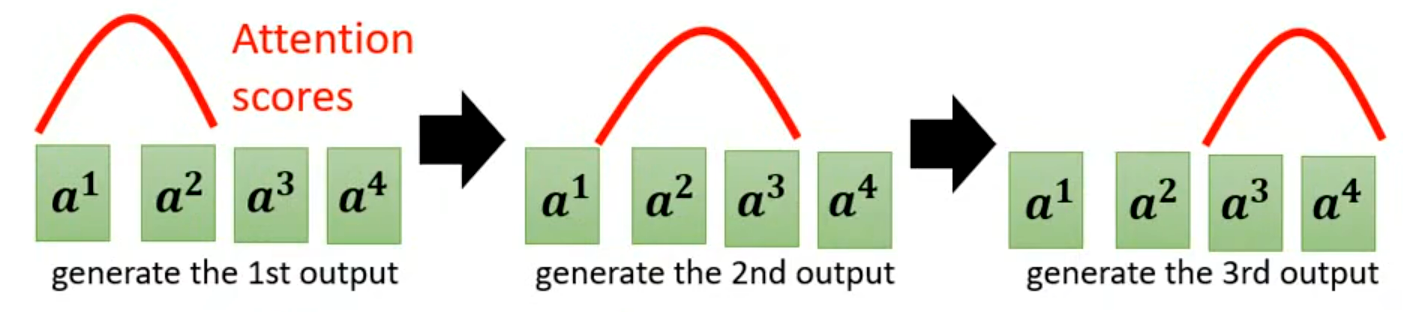
符合单调对齐的正确注意力分布:
- 第 1 个输出:注意力峰在输入的最左侧(a¹、a²),模型关注输入的前部分;
- 第 2 个输出:注意力峰单调右移到 a²、a³,关注输入的中间部分;
- 第 3 个输出:注意力峰继续右移到 a³、a⁴,关注输入的后部分。
- 注意力峰严格从左到右单调移动,完全贴合输入输出的顺序对应,是正确的对齐方式。
注意要和Masked Multi-Head Self-Attention(掩码多头自注意力,Masked MHSA)做区分,Masked MHSA作用于Decoder内部的自注意力层,保证 Decoder 内部的自回归顺序正确;而Guided Attention作用于Encoder-Decoder之间的交叉注意力(Cross Attention)层,给交叉注意力添加 “强制单调右移” 的约束,惩罚 “注意力回退、错位” 的分布,让模型学习到生成第
个输出的右侧。
Encoder-Decoder(机器翻译场景)输入输出(训练时)
对于机器翻译任务的Encoder-Decoder,以 “I love China” 翻译为 “我爱中国” 为例:
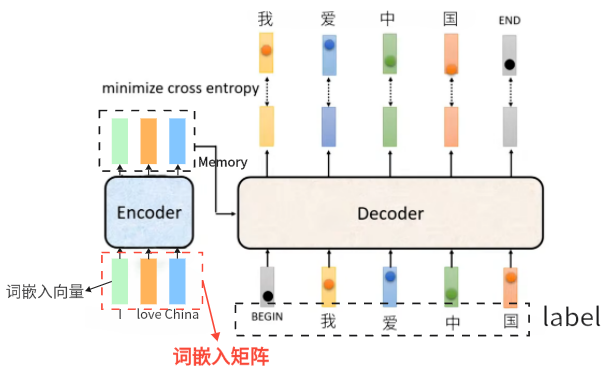
- Encoder输入:
原句子 “I love China”分词为 [I, love, China],在词汇表中找到其对应的词嵌入向量,然后拼成输入矩阵再加上位置编码输入到Encoder中。
最终Encoder输入为 (序列长度, - Encoder输出:
经过多层 Encoder 后,输出一组源语言上下文语义表示,形状仍为 (序列长度, - Decoder有两个输入:
- 来自 Encoder 的 Memory(用于交叉注意力)
- 目标语言的 “右移” 序列(Teacher Forcing):目标真实句子是 “我爱中国”,训练时不会让它从零生成,而是直接喂标准答案,但要向右错开一位,即 [<begin>, "我", "爱", "中", "国"],同时加上掩码(Mask)(通过掩码多头注意力机制),让每个位置只能看到前面的词,看不到未来的词。
- Decoder输出:
Decoder 最终输出一个形状为 (目标序列长度,目标词典大小) 的张量(即每个Decoder的每个输入都对应一个输出,输出为一个大小为词典大小的向量),再经过 Softmax 变成概率分布。它要预测的是每一步的下一个字,例如
输入 [<begin>] 预测 “我”
输入 [<begin>, "我"] 预测 “爱”
输入 [<begin>, "我", "爱"] 预测 “中”
输入 [<begin>, "我", "爱", "中"] 预测 “国”
模型用这个输出和真实标签["我", "爱", "中", "国", "end"]计算交叉熵损失。
Encoder-Decoder(机器翻译场景)输入输出(推理时)
推理时没有 “标准答案” (label)输入,是自回归生成。
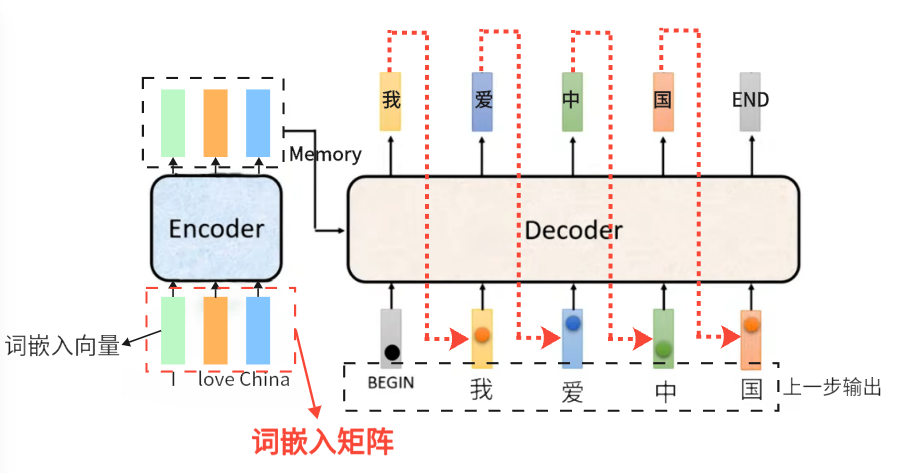
- Encoder输入输出和训练时完全一样。
- Decoder输入:
第一步输入 [<begin>]
第二步输入 [<begin>, "我"]
第三步输入 [<begin>, "我", "爱"]
第四步输入 [<begin>, "我", "爱", "中"]
第五步输入 [<begin>, "我", "爱", "中", "国"]
每一步都同时使用 Encoder 输出的Memory - Decoder输出:
每一步输出词典上的概率分布,取概率最大的 token 作为当前生成结果:
输入<begin>→ 输出概率最大 →我
输入<begin>我→ 输出爱
输入<begin>我 爱→ 输出中国
输入<begin>我 爱 中国→ 输出<end>
遇到<end>生成结束,最终翻译结果 “我爱中国”
Decoder-only输入输出(训练时)
Chatbot、对话、QA、文本续写等任务使用Decoder而舍弃Encoder,这类任务本质上 “给定上文,不断预测下一个单词” 的任务,基本过程是给定一段上文文本(或问题),输出下一个最合理的 token(字 / 词),把生成的词拼回上文,再继续预测下一个,直到生成结束符,整段回答就出来了,称为因果语言模型(Causal Language Model, CLM)。
Decoder-only的任务只有一个连续序列(上文 + 下文),不存在 “另一组需要单独编码的源文本”,直接用前文信息预测后文,完全不需要额外 Encoder来获得所有上下文信息。
以给定句子 “今天天气不错” 为例。Decoder-only的训练目标是 “给定前面所有字,预测下一个字”,根据给定的文本来学习语义:
- Decoder输入:
先将句子分词 [今, 天, 天, 气, 不, 错] ,然后查找词嵌入向量拼成词嵌入矩阵作为输入(一次性将整个token输入到网络中),即输入是一个 (序列长度,
其核心训练机制也是Teaching Forcing(喂标准答案),所以其标签label为[天,天,气,不,错](实际上应该是索引ID值,这里为了便于理解直接用文字代替) - 在训练时,由于掩码多头注意力机制,每个位置,只能看到自己及左边的字,看不到右边的字,保证模型是靠前文推理下文。
- Decoder输出:
并行计算,同时算:
看到 “今” 预测 “天”
看到 “今天” 预测 “天”
看到 “今天天” 预测“气”
看到 “今天天气”预测“不”
看到 “今天天气不”预测“错”
所以最终输出也是一个 (序列长度, - 最终计算损失时会将“今” 预测 “天”、“今天” 预测 “天”、“今天天” 预测“气”、“今天天气”预测“不”、 “今天天气不”预测“错”的损失全部叠加,一起更新嵌入和所有参数。
- Decoder-only的训练过程和Encoder-Decoder类似,都是Teacher Forcing一次性输入全部正确标签 token,不使用上一步预测值;都是并行计算,输入 N 个 token,输出 N 个预测,一起算损失;都在学 “上下文→下一个词” 的映射。
Decoder-only输入输出(推理时)
推理时没有标准答案喂给模型,只能自回归逐词生成。以预测 “今天天气真好,我要去___”为例:
- Decoder输入:
[今, 天, 天, 气, 真, 好, ,, 我, 要, 去] - Decoder输出:
输入序列长度为10,最终输出也有10个向量,最后一个向量是来预测下一个字的,所以只使用最后一个向量,此向量经过变换后得到的概率最大的字是“公”。 - 把刚生成的 “公” 拼到输入后面 ,此时输入变成[今, 天, 天, 气, 真, 好, ,, 我, 要, 去, 公],此时模型输出11个向量,取出最后一个向量经过变换后得到的概率最大的字是“园”。重复上述过程最后得到“今天天气真好,我要去公园玩”。
Encoder-only输入输出(训练时)
只用 Encoder 的模型,典型代表是 BERT、RoBERTa、ALBERT 这类,核心做文本理解类任务,完全不需要 Decoder,比如:
- 情感分析(正面 / 负面 / 中性)
- 文本分类(新闻分类、垃圾邮件识别)
- 命名实体识别 NER(识别人名、地名、机构名)
- 句子相似度匹配、问答抽取
- 句法分析、语义理解
Encoder 用双向自注意力(能看到整个句子的前后文),只做判别 / 分类 / 标注,不做文本生成。
以 “这部 电影太好看了,强烈推荐!”判断句子情感是正面还是负面为例:
- Encoder输入:[这, 部, 电, 影, 太, 好,看, 了, ,, 强, 烈, 推, 荐, !]。查找词嵌入向量拼成词嵌入矩阵作为输入,一次性将整个token输入到网络中。输入是一个 (序列长度,
- Encoder输出:Encoder 会输出每个位置的语义特征向量,形状仍为 (序列长度,
- 把模型输出的概率,和真实标签(正面)计算交叉熵损失,反向传播更新 Encoder 所有参数(Embedding、注意力权重、全连接层)。
Encoder-only在推理阶段的Encoder输入输出与训练阶段一致,这里不再介绍。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 14
14 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)