π0: A Vision-Language-Action Flow Model for General Robot Control
模型结构
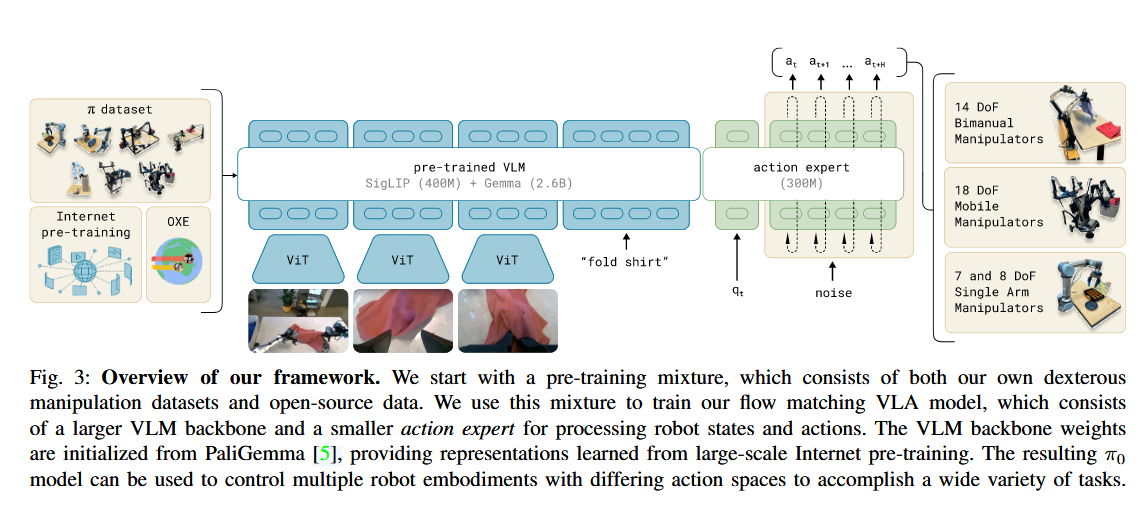
1. 模型架构:双专家协作(Vision-Language + Action Expert)
π0并没有从零开始发明一个新架构,而是采用了类似 混合专家模型(MoE) 的变体,将“语义理解”和“动作控制”解耦:
- VLM 主干(大脑): 基础是 PaliGemma (3B)
- 它负责处理图像输入(通过 SigLIP 编码器)和文字指令(通过 Gemma 2B 语言模型)。
- 这部分继承了互联网的海量常识。比如它知道“杯子”是什么,也知道“洗碗”通常包含哪些步骤。
- 动作专家(Action Expert,肌肉神经): 这是一个额外增加的 300M 参数 模块。
- 权重隔离: 图像和文字标记(Tokens)走 VLM 权重;而机器人的关节状态(Proprioception)和动作标记(Action Tokens)走“动作专家”权重。
- 注意力共享: 关键点在于,虽然权重不同,但它们在 Transformer 的自注意力层(Self-Attention)是互通的。这意味着“动作标记”可以随时查阅“图像标记”提取出的特征,从而实现精准避障。
2. 动作生成机制:条件流匹配(Conditional Flow Matching)
这是 π0 最核心的技术创新。传统的机器人模型(如 RT-1)通过分类(离散化)预测动作,而 π0 使用的是连续生成。
为什么不用扩散模型(Diffusion)而用流匹配(Flow Matching)?
扩散模型(如之前著名的 Diffusion Policy)是通过不断“去噪”来生成动作,虽然效果好,但在实时性要求极高的机器人领域,计算成本略高且路径复杂。
流匹配的工作原理:
- 定义“流”: 模型学习的是一个向量场(Vector Field)。想象一下,你有一堆乱七八糟的随机噪声点(代表完全随机的动作),流匹配的目标是寻找一条最短的直线路径,将这些噪声点推向真实的动作轨迹。
- 动作块(Action Chunking):
π0 不是一次预测一个动作,而是一次预测未来 50 个时间步(H=50) 的动作序列。 - 推理过程(Inference):
- 从高斯噪声 A0 开始。
- 利用模型预测的“速度场” vθ,通过 10 步欧拉积分(Euler Integration)。
- 每一层积分都让动作更接近真实轨迹。
- 优势: 相比扩散模型,它的路径更直(概率路径更简单),收敛更快,生成的动作轨迹更加平滑且高频(最高支持 50Hz 控制)。
3. 数据处理:跨形态兼容(Cross-Embodiment)
需要同时指挥不同的机器人(有的 7 轴,有的 14 轴,有的有底盘),它是如何做到的?
- 最大动作空间对齐:
模型定义了一个统一的向量空间(例如 18 维),这是所有机型中最大的动作自由度。- 如果是一个只有 7 维动作的单臂机器人,剩下的维度就填充零(Zero-padding)。
- 通过这种方式,同一个神经网络可以输入不同维度的状态并输出对应的控制指令。
- 图像掩码(Masking):
有的机器人有 3 个摄像头,有的只有 2 个。模型会对缺失的图像位置进行掩码处理,使其不干扰决策。
4. 训练过程:预训练与后训练的“食谱”
论文强调,模型的效果很大程度上取决于训练数据的组合方式:
第一阶段:大规模预训练 (The “Foundation”)
- 目标: 获取通用物理常识和鲁棒性。
- 数据: 10,000+ 小时数据,包含大量的“非完美”操作。
- 作用: 让机器人学会“即便被推了一下,或者物体滑落了,该如何补救”。它学会的是基本的物理规则。
第二阶段:后训练/微调 (The “Alignment”)
- 目标: 获取高精度的技能。
- 数据: 针对特定复杂任务(如折衣服、组装纸箱)的高质量演示数据。
- 作用: 这类似于 LLM 的指令微调(SFT)。通过高质量数据,让机器人学会“优雅、高效、连贯”地完成任务,而不仅仅是“能动”。
总结:
- 输入: 机器人拍下当前的几张照片,加上关节角度 qt,再加上人类说的一句“把桌子清理干净”。
- 编码: 图像变 Patch,文字变 Embedding,动作初值是一堆噪声。
- 计算: VLM 部分理解场景,动作专家部分结合场景特征,通过流匹配计算出接下来 50 步的“推力方向”。
- 积分: 经过 10 次迭代,动作序列从噪声变成了平滑的轨迹。
- 执行: 机器人快速执行这组动作,并在 0.5 秒后再次循环整个过程(闭环控制)。
公式
1. 预测目标:动作块 (Action Chunking)
公式:
A t = [ a t , a t + 1 , … , a t + H − 1 ] A_t = [a_t, a_{t+1}, \dots, a_{t+H-1}] At=[at,at+1,…,at+H−1]
- 数学拆解:
- A t A_t At:机器人输出的“动作大礼包”。
- a t a_t at:每一个瞬间的具体指令(如:手肘转动 5 度)。
- H H H:预测的时间跨度(论文中设定为 50 个时间步)。
- 大白话翻译:
“未雨绸缪”: 机器人不再是动一下想一下,而是一次性规划好未来 50 个瞬间的所有动作。这就像你投篮时,大脑预先算好了从起跳到出手的整套路径,而不是落地后再想下一步。
2. 感官输入:机器人看到了什么 (Observation)
公式:
o t = [ I t 1 , … , I t n , ℓ t , q t ] o_t = [I^1_t, \dots, I^n_t, \ell_t, q_t] ot=[It1,…,Itn,ℓt,qt]
- 数学拆解:
- I t n I^n_t Itn:多个相机的图像(眼睛看到的画面)。
- ℓ t \ell_t ℓt:人类的语言指令(耳朵听到的要求)。
- q t q_t qt:机器人当前的关节角度(身体感觉到的姿态)。
- 大白话翻译:
“眼耳手脑协同”: 模型在做决定前,会同时审视:画面里有什么、主人让干什么、以及我的手现在伸到了哪里。
3. 生成机制:流匹配路径 (Probability Path)
流匹配(Flow Matching)的目标是将随机噪声(无序)平滑地转化成精准动作(有序)。
公式:
q ( A t τ ∣ A t ) = N ( τ A t , ( 1 − τ ) I ) q(A^\tau_t | A_t) = \mathcal{N}(\tau A_t, (1 - \tau)I) q(Atτ∣At)=N(τAt,(1−τ)I)
- 数学拆解:
- τ \tau τ (Tau):时间轴,从 0 0 0(纯噪声)逐渐变到 1 1 1(目标动作)。
- A t A_t At:理想的真动作。
- I I I:标准噪声(乱码)。
- 大白话翻译:
“洗照片的过程”: 想象你在洗照片。刚开始是一张模糊的白纸( τ = 0 \tau=0 τ=0),随着显影液作用,照片一点点变清晰,直到最后出现完美图像( τ = 1 \tau=1 τ=1)。这个公式定义了动作从“混乱”到“清晰”的演变路径。
4. 训练目标:学习那个“推力” (Loss Function)
我们要训练模型学会:看到模糊的动作,该往哪个方向“推”才能变回正确动作。
公式:
L τ ( θ ) = E ∥ v θ ( A t τ , o t ) − u ( A t τ ∣ A t ) ∥ 2 L^\tau(\theta) = \mathbb{E} \| v_\theta(A^\tau_t, o_t) - u(A^\tau_t | A_t) \|^2 Lτ(θ)=E∥vθ(Atτ,ot)−u(Atτ∣At)∥2
- 数学拆解:
- L L L:损失函数(数值越小,模型越聪明)。
- v θ v_\theta vθ:模型预测出的“推力”(它的猜测)。
- u u u:真实的“推力方向”(标准答案)。
- 大白话翻译:
“寻找修正力”: 我们给机器人看一个被噪声污染的废动作 A t τ A^\tau_t Atτ,问它:“想变回真动作,该往哪儿使劲?”模型给个答案( v θ v_\theta vθ),我们拿它跟标答( u u u)比对。差距越小,说明机器人纠错能力越强。
5. 推理执行:如何一步步产生动作 (Inference)
在实验室干活时,机器人通过多次微调(迭代)来生成最终动作。
公式:
A t τ + δ = A t τ + δ v θ ( A t τ , o t ) A^{\tau+\delta}_t = A^\tau_t + \delta v_\theta(A^\tau_t, o_t) Atτ+δ=Atτ+δvθ(Atτ,ot)
- 数学拆解:
- A t τ A^\tau_t Atτ:当前的动作草稿。
- δ \delta δ (Delta):每一步修正的小幅步长。
- v θ v_\theta vθ:模型给出的修正指导。
- 大白话翻译:
“十步成画”:
- 初始: 先随手瞎画一个动作(噪声 A 0 A^0 A0)。
- 修画: 问模型“怎么改?”,模型指个方向,机器人就把动作往那边挪一点点( δ \delta δ)。
- 循环: 同样的步骤重复 10 次。
- 结果: 10 步之后,最初的“瞎画”就变成了能够折衣服、摆碗筷的精准指令。
总结:向量 A A A 到底长什么样?
最后生成的向量 A A A 在计算机里是一个 50行 × 18列 的数字矩阵:
- 列(18维): 代表机器人的“物理维度”(如 14 个手臂关节电机、2 个夹爪开合、2 个底盘轮子速度)。
- 行(50行): 代表未来的“时间刻度”(每行代表 0.02 秒后的动作)。
π 0 \pi_0 π0 的本质就是:利用大模型的大脑理解环境信息( o t o_t ot),通过流匹配的推力( v θ v_\theta vθ),把一团乱麻(噪声)梳理成一份完美的 50 步行动方案( A A A)。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)