IEEE/ASME Transactions on Mechatronics | 院士团队让移动机器人在复杂环境中学会主动避障
移动机器人在复杂动态环境中运动规划,既要快又要稳,还要安全。现有方法各有短板:MPC依赖精确模型,在线优化计算量大;RL数据效率低,训练好了也未必能应对未知障碍。

论文信息
英文题目: Vector Field Augmented Reinforcement Learning for Adaptive Motion Planning of Mobile Robots
中文题目:面向移动机器人自适应运动规划的向量场增强强化学习
作者: Yang Lu, Weijia Yao, Cong Li, Yongqian Xiao, Xin Xu, Xinglong Zhang, Yaonan Wang, Dingbang Xiao
作者单位:国防科技大学、湖南大学、湖南第一师范学院
期刊: IEEE/ASME Transactions on Mechatronics(IF 6.4,中科院一区,JCR Q1)
发表时间: 2025年9月26日
链接: https://doi.org/10.1109/TMECH.2025.3593610
引文格式: Lu Y, Yao W, Li C, et al. Vector field augmented reinforcement learning for adaptive motion planning of mobile robots[J]. IEEE/ASME Transactions on Mechatronics, 2026, 31(1): 191-205.
01 全文速览
移动机器人在复杂动态环境中运动规划,既要快又要稳,还要安全。现有方法各有短板:MPC依赖精确模型,在线优化计算量大;RL数据效率低,训练好了也未必能应对未知障碍。
国防科技大学王耀南团队提出了一种向量场增强的强化学习(VF-RL)框架,把传统向量场的“导航直觉”和数据驱动的RL的“自适应能力”拧在一起。图1展示了VF-RL的整体架构:复合向量场提供实时安全引导(模块A),深度Koopman模型在线补偿动力学不确定性(模块B),滚动时域RL在安全边界和作动器约束下生成最优控制。
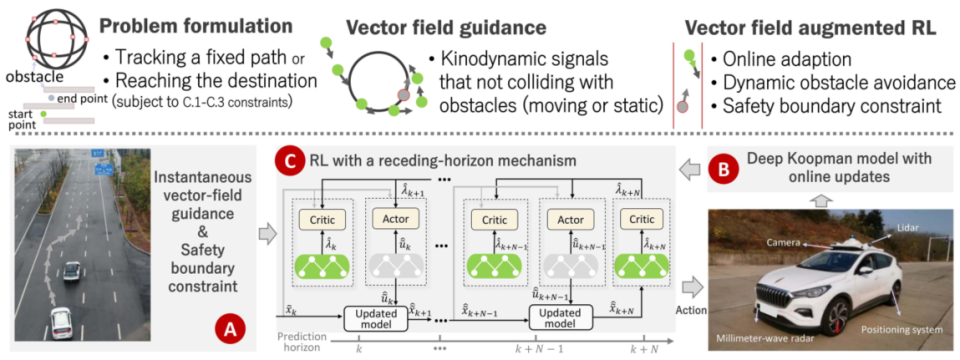
图 1 VF-RL框架:向量场引导 + 在线建模 + 滚动时域强化学习
VF-RL的核心逻辑:先让机器人知道“大概往哪走”(向量场给出无碰撞参考路径),再让RL在局部微调,同时用稀疏高斯过程在线修正模型误差。仿真和实车实验表明:VF-RL比LMPCC、MPC-CBF等优化方法计算更快(<0.01s/步),路径更短,且在动态障碍物、非结构化道路场景下均能稳定运行,最高车速3m/s。
核心亮点:
✅复合向量场再升级:引入虚拟障碍物和指数平滑函数,彻底解决传统向量场“突变”和“死锁”问题
✅ Koopman + 稀疏GP在线补偿:用深度Koopman建立线性化模型,再用稀疏高斯过程在线修正未建模动态
✅滚动时域RL:在预测时域内用核函数网络近似最优策略,收敛性和稳定性均有理论证明
✅实车验证:红旗E-HS3平台,静态/动态避障、路径跟踪、越野场景全通过
✅跨平台通用:四旋翼仿真同样验证,证明框架对机器人类型不敏感
02 研究内容
🧭 2.1 复合向量场:给机器人一条“有提前量”的安全路径
传统向量场在机器人进入障碍物反应区时,指引方向会突然跳变,导致机器人急转甚至失控。作者在原有复合向量场(图2)基础上引入了虚拟障碍物和指数平滑函数。
图2展示了原复合向量场的行为:在exR(灰色)、exQ∩inR(绿色)、inQ(蓝色)三个区域内,机器人分别执行路径跟踪、混合跟踪+避障、纯避障。但在黄色圆圈附近,向量方向突变,违反运动学约束。
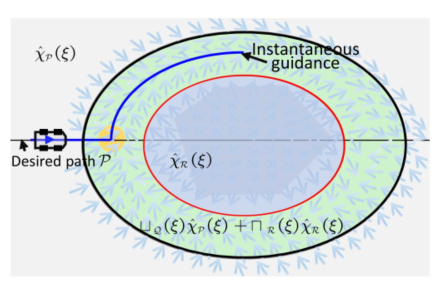
图 2 原复合向量场在黄色圆圈处发生突变
改进后的设计如图3所示:在真实障碍物(灰色椭圆)外围添加一个虚拟障碍物(蓝色虚线椭圆),二者之间的缓冲区域内,向量场会平滑地将机器人引向虚拟障碍物的排斥边界,使其提前偏转方向,避免进入真实障碍物反应区时出现急弯。指数函数 \(s_i(\xi)\) 保证机器人在进入真实反应区后虚拟障碍物不再起作用。
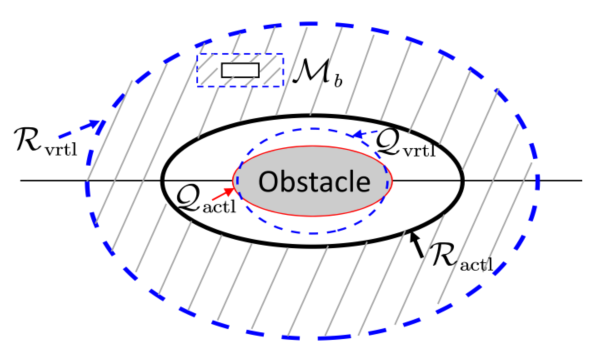
图 3 改进后的复合向量场:虚拟障碍物提前引导方向
最后,将向量场预计算在网格地图上,实时查表获取当前引导方向,再根据最大向心加速度约束进行速度规划,确保高速行驶不侧滑。
🧠 2.2 实时自适应建模:深度Koopman + 稀疏GP
机器人动力学往往是非线性的,且模型参数会随工况变化。作者先用深度神经网络学习Koopman算子,把非线性系统映射到一个高维线性空间:
![]()
但这个离线模型仍然存在误差。于是引入稀疏高斯过程(FITC),用在线数据实时补偿:
![]()
将
![]()
建模为GP,得到补偿后的线性模型(14),并可以解析求出雅可比矩阵(15)。这个模块就是图1中的模块B,让VF-RL能够在模型失配和外部扰动下依然保持稳定。
图4对比了有/无在线模型补偿(VF-RL w/ ML vs w/o ML)的横向跟踪误差。可以看到,w/ ML的平均误差显著更低,尤其在里程后半段(模型已在线更新)差距更明显。
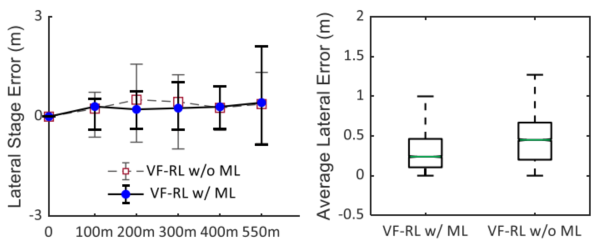
图 4 在线模型补偿显著降低横向跟踪误差
🎮 2.3 滚动时域强化学习:在安全边界内寻优
在向量场给出的参考路径附近,RL负责生成最优控制输入。作者设计了一个指数型障碍函数
![]()
![]()
,当机器人接近安全边界时代价指数上升。同时,在预测时域
![]()
内用两个核函数网络(actor/critic)近似最优值函数和最优策略,并给出迭代更新规则(31)。
Theorem 1 证明了值函数序列和控制序列收敛到最优解;Theorem 2 通过构造Lyapunov函数证明了闭环系统稳定。
图5直观展示了安全边界约束下的机器人轨迹,不同时刻的快照清楚显示了车辆始终保持在允许区域内。
图 5 安全边界约束下的轨迹快照
💻 2.4 仿真与实车验证
仿真1:静态+动态避障(CarSim)
图6对比了VF-RL与LMPCC、MPC-CBF、RHRL-KDP、CFS五种方法。VF-RL提前偏转方向,路径最平滑、长度最短;MPC-CBF用圆形包络椭圆导致绕远;CFS和LMPCC出现紧急避障导致超调;RHRL-KDP受约束影响网络发散。表I定量显示:VF-RL的综合代价J_MC最低(45.84),单步计算时间<0.01s,远低于其他方法的0.07~0.15s。
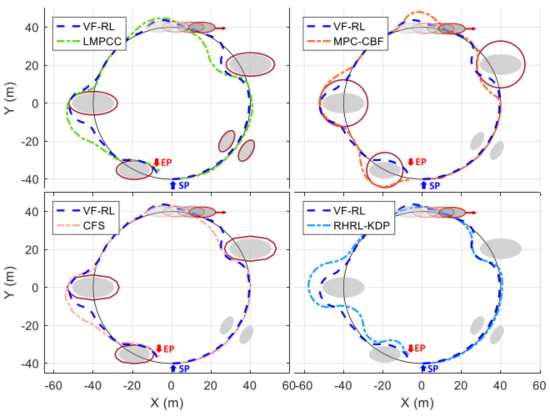
图 6 五种方法避障轨迹对比
仿真2:多动态障碍物
图7和表II中,VF-RL路径长度最短(48.37m)、平均曲率最小(0.178 m⁻¹),计算效率依然最高。
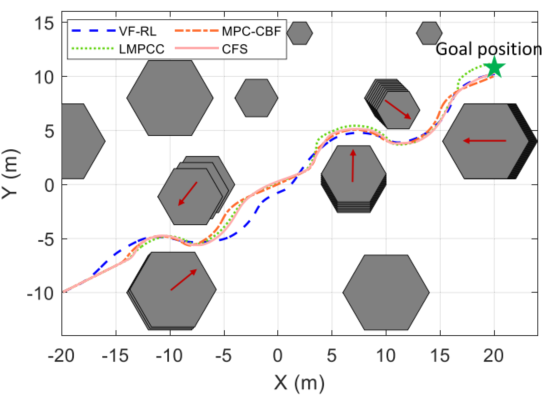
图 7 多动态障碍物场景结果
仿真3:四旋翼
图8展示了VF-RL在四旋翼上的3D轨迹跟踪,成功避开静态和突然出现的动态障碍物,证明了框架对不同机器人平台的通用性。
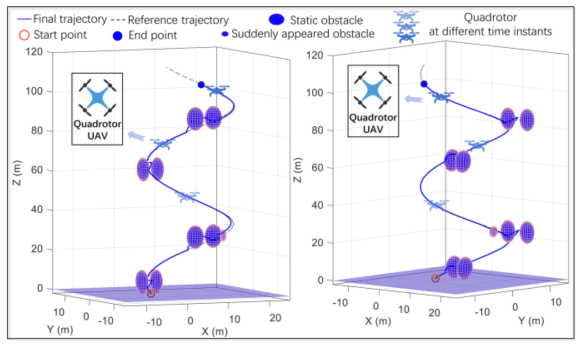
图 8 四旋翼3D避障轨迹
实车实验:红旗E-HS3
图9展示了四个典型场景:静态八字绕桩避障、多动态障碍物主动避让、带边界约束的路径跟踪、以及图10的越野场景。所有测试中车辆稳定运行,最高车速3m/s,证明了VF-RL在真实非结构化环境中的鲁棒性和实时性。
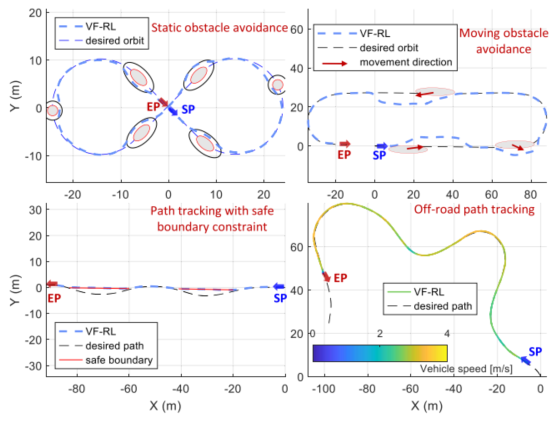
图 9 红旗E-HS3实车实验结果

图 10 越野场景俯视图
03 创新点
①向量场+RL的深度耦合,而非简单拼接
以往向量场只作为路径规划器输出给下层控制器,VF-RL把向量场嵌入RL的优化框架——向量场给出“安全方向”作为参考,RL在此基础上修正。虚拟障碍物的引入让向量场本身也具备了“预判”能力,彻底解决了传统向量场的死锁和突变问题。
②在线模型补偿的工程化实现
深度Koopman+稀疏GP的组合,既利用了Koopman的全局线性化优势,又用GP在线补偿残差,且雅可比矩阵可解析求导,可直接用于RL的策略梯度。图8的对比很有说服力。
③滚动时域RL的收敛性与稳定性证明
在预测时域内用核函数网络近似最优策略,并给出actor-critic的更新规则(31),Theorem 1和2分别证明了收敛性和稳定性,这在RL+MPC的混合方法中并不多见。
④多平台、多场景的充分验证
从CarSim仿真到四旋翼,再到红旗实车,从静态避障到动态避障再到越野道路,实验设计非常全面。特别是实车3m/s的速度,在非结构化越野场景中已经相当有挑战性。
⑤计算效率的显著优势
单步计算<0.01s,比传统非线性MPC(0.15s)快一个数量级。这意味着VF-RL可以跑在更低成本的嵌入式平台上,工程部署潜力大。
04 总结与展望
这篇工作的最大启发是:与其让RL从零摸索避障规则,不如先给RL一个“安全驾驶手册”。向量场提供的就是这样一个手册——它不完美,但方向正确;RL负责在手册的基础上应对动态变化和模型误差。两者结合,既保留了传统方法的可解释性和安全性,又吸收了数据驱动方法的适应性。
当然,当前框架也有局限:向量场生成的路径只考虑了运动学和向心加速度,未完全满足高阶动力学约束;RL策略的安全保证仍然是概率性的,极端情况下可能失效。
未来研究将聚焦于以下几个方向:
🔸动力学的深度耦合:当前向量场主要考虑几何路径和速度上限,未来可融入更复杂的动力学约束(如横摆角速度、侧向加速度变化率),生成真正“可执行”的引导路径。
🔸安全备份策略:RL策略的收敛性虽然理论上有保证,但实际训练中仍可能偶发异常。可设计一个基于CBF或势函数的备份控制器,在RL输出可疑时接管。
🔸多机器人协同:将单机VF-RL扩展到多机器人场景,向量场需要处理机器人之间的互斥避让,RL则需要学习协调策略。
🔸端到端视觉-动作:当前框架依赖状态观测(位置、速度),未来可直接从视觉输入端到端学习,但需要解决向量场在图像空间中的定义问题。
在您的机器人项目中,您更倾向于使用纯优化方法(如MPC)还是学习方法(如RL)?欢迎在评论区分享您的看法。
声明:本文仅供学术交流,版权归原作者所有。如有错误或侵权,请联系更正或删除,欢迎留言探讨。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)