模型推理理论: KV Cache 原理分析和vla-cache代码实操
本文深入解析了KVCache技术在大模型推理中的关键作用。随着LLM生成序列长度的增加,注意力计算成为性能瓶颈。KVCache通过缓存历史Token的Key和Value矩阵,避免重复计算,将复杂度从O(n²)降至O(n)。文章详细阐述了KVCache的设计原理、实现方案(从早期手动拼接演进为标准Cache类)及其显存开销(线性增长特性),并探讨了长序列场景下的优化方向(量化、分页管理等)。最后通过
文章原理说明部分搬运自:KV Cache 原理分析 ,后文加上了自己的代码实操帮助理解。
如需访问更多原文信息,请访问上面的链接。
随着 LLM 的发展,模型生成的 Token 长度不断增加,注意力计算成为推理性能核心瓶颈。KV Cache 是解决这一问题的关键措施,它通过缓存已计算的 Key 和 Value 矩阵,避免自回归生成过程中重复计算历史 Token 的注意力分数,从而显著降低推理延迟、提升吞吐量。
本节旨在对 KV Cache 技术进行全面梳理。我们将从大模型推理的基本流程出发,解析其计算瓶颈与 KV Cache 的设计动机;在此基础上,深入阐述 KV Cache 的核心原理与具体实现方案;最后通过定量分析,明确 KV Cache 的显存开销特征及长序列场景下的挑战。
2. 大模型推理流程
2.1 推理阶段划分
大模型推理的核心是自回归生成:模型依据历史 Token 序列 预测下一个最可能的 Token ,生成的 Token 会与输入序列拼接,作为下一轮推理的输入 ,重复该过程直至遇到终止符或达到最大长度。
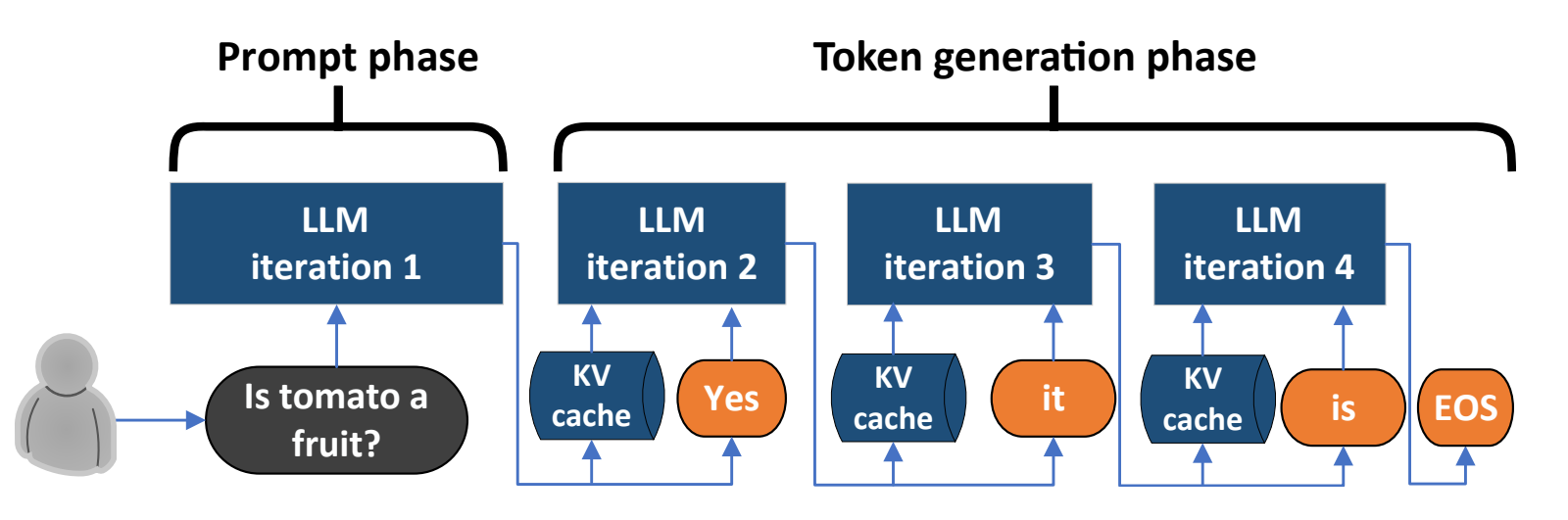
为实现高效推理,该过程被划分为两个核心阶段,二者在计算方式、并行度上存在显著差异:
-
Prefill 阶段(Prompt 处理阶段):一次性并行处理用户输入的全部 Prompt,计算所有 Token 的 K、V 向量及初始注意力状态,为第一个新 Token 生成提供基础。
-
Decode 阶段(Token 生成阶段):逐一生成新 Token,每一步仅输入上一轮生成的单个 Token,利用历史缓存的 KV 向量计算注意力,避免重复处理已有的历史序列。
2.2 推理计算瓶颈分析
在未启用 KV Cache 时,推理过程的核心计算流程如下(以单个 Token 自回归为例),各模块依次执行:
-
Embedding 层:将输入 Token 映射为固定维度的词向量(Embedding Vector)。
-
QKV 计算:词向量与权重矩阵 、、 相乘,生成 Query(查询)、Key(键)、Value(值)向量。
-
Causal Attention 层:计算当前 Token 与所有历史 Token 的注意力分数,且仅允许关注“当前及之前”的 Token(通过掩码屏蔽未来位置)。
-
FFN 层:注意力输出经 FFN 变换后,作为当前层输出(或用于最终 Token 预测)。
整个过程的核心是注意力计算,其基础公式为:
其中,、、 矩阵由输入序列 与对应权重矩阵相乘得到:
为缩放因子( 为 Key 向量维度),用于缓解注意力分数过大导致的 softmax 梯度消失问题,后续公式中为简化表述暂不体现。
由于因果注意力的约束,第 个 Token 的注意力计算仅依赖前 个 Token 的 K、V 向量,公式可展开为:
其中
为直观展示计算过程,下文用 表示 softmax 运算后的结果。
无 KV Cache 时计算冗余
以生成序列“hello”为例,分步拆解无 KV Cache 时的注意力计算:
-
输入“h”(),生成“e”():
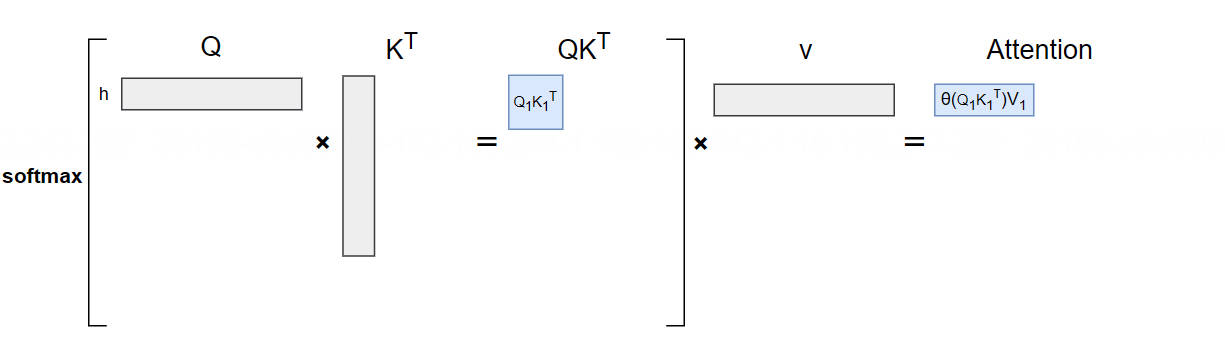
计算公式:
-
输入“he”(),生成“l”():
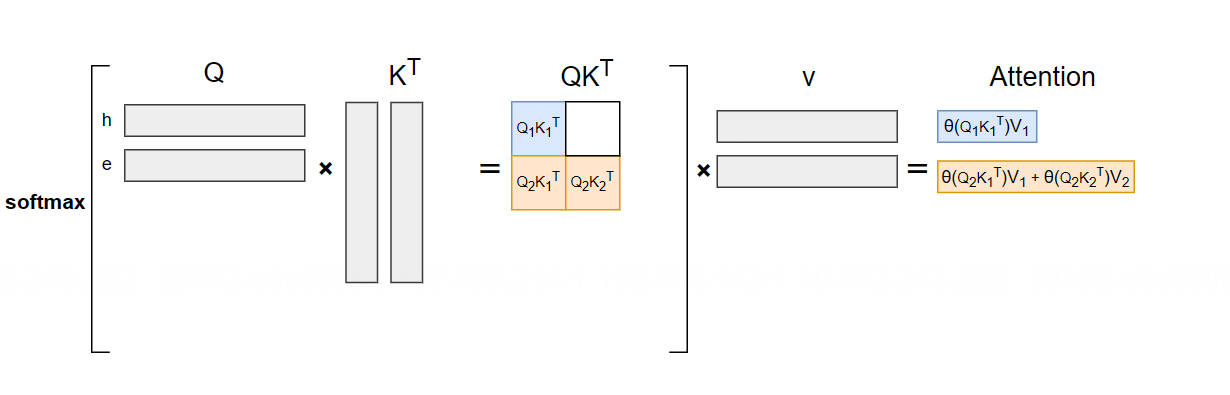
计算公式:
-
输入“hel”(),生成“l”():
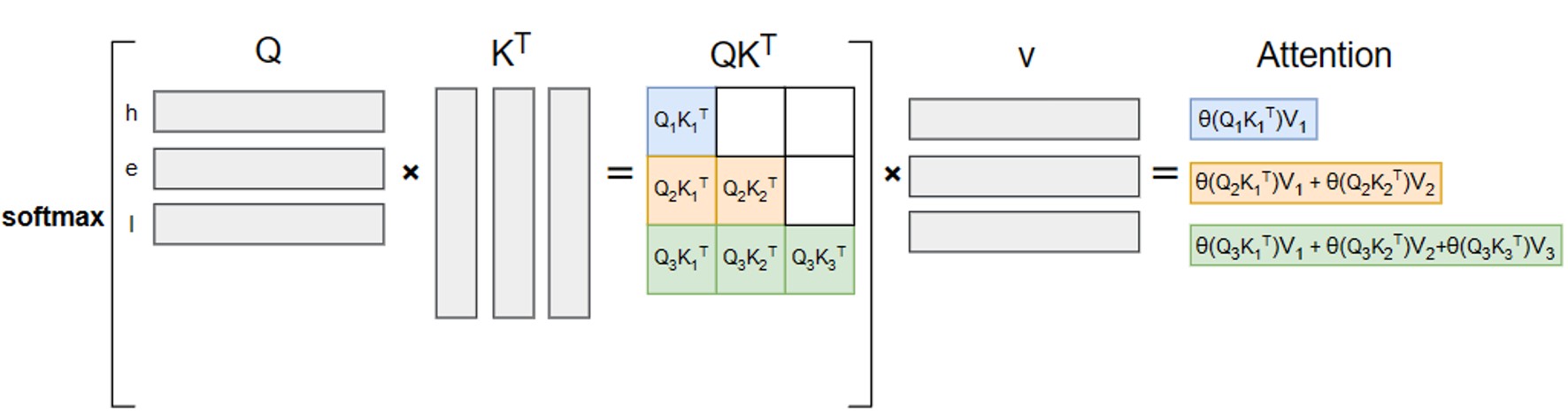
计算公式:
可见,无 KV Cache 时,每一步生成新 Token 都需重新输入全部历史序列,重复计算所有历史 Token 的 K、V 向量及注意力分数。这导致总计算复杂度与生成序列长度 呈平方关系()——当序列长度达到 1k、10k 时,计算量会呈指数级增长,推理延迟急剧升高,完全无法满足实际应用需求。
3. KV Cache 核心原理
3.1 设计核心前提
KV Cache 的优化逻辑源于一个关键观察:因果注意力中,历史 Token 的 K、V 向量是“静态不变”的。
在自回归生成过程中,第 个 Token 的 K、V 向量仅由其自身的词向量和模型权重决定,与后续生成的 Token 无关。一旦计算完成,这些 K、V 向量在后续所有步骤中都不会改变,可被永久复用。
基于这一前提,自然的优化思路是:将历史 Token 的 K、V 向量缓存至显存,后续生成新 Token 时,仅需计算当前 Token 的 Q 向量,直接与缓存的 K、V 矩阵进行注意力计算,无需重复处理历史序列。
3.2 优化后计算流程
仍以生成“hello”的第三步(输入“hel”生成“l”)为例,启用 KV Cache 后的计算流程如下:
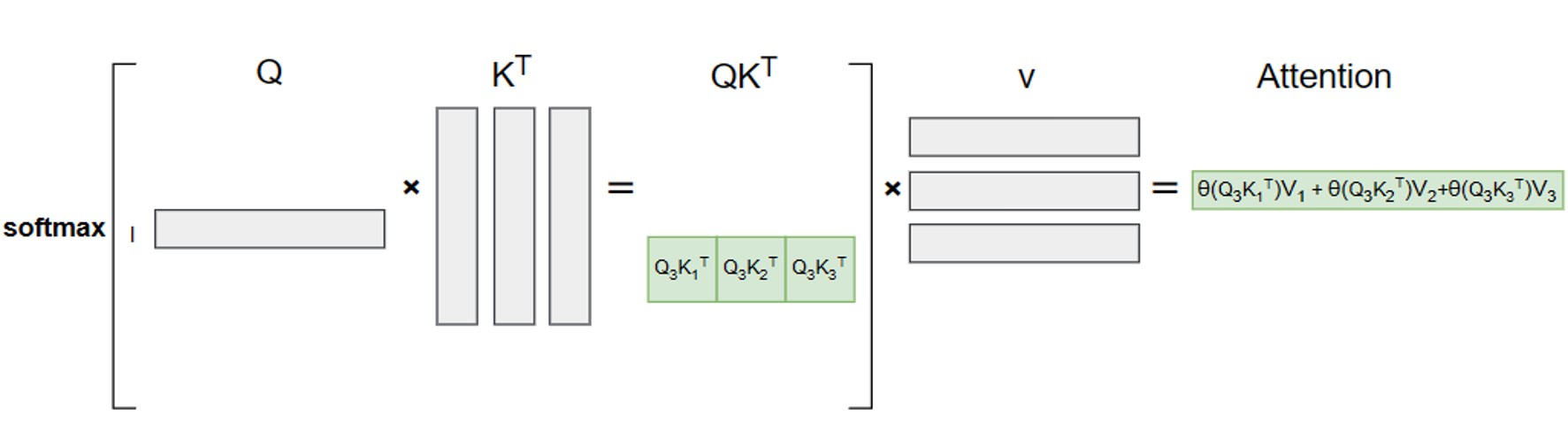
此时,注意力计算仅需两步:
-
计算当前 Token()的 Q 向量 ;
-
直接调用缓存的历史 K 矩阵()和 V 矩阵(),与 计算注意力分数,再叠加当前 Token 的 、 结果。
计算公式简化为:
其中 、 为缓存的历史 K、V 矩阵。
3.3 有无 Cache 对比
下图直观展示了 KV Cache 的优化效果:
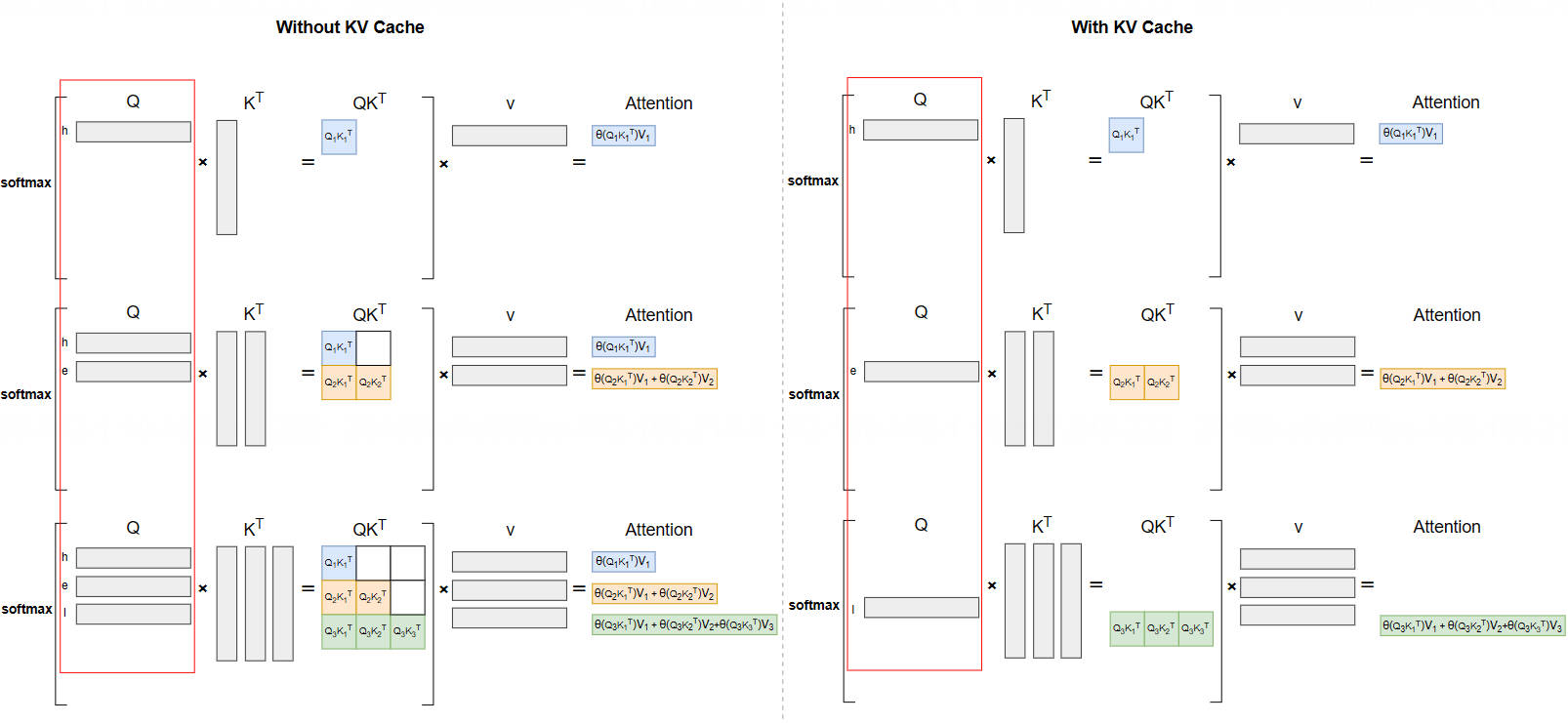
-
无 KV Cache:每步需输入全部历史序列,重复计算所有 K、V 向量,计算量随序列长度平方增长;
-
有 KV Cache:仅需输入当前 Token,复用历史 K、V 缓存,计算量随序列长度线性增长(),大幅降低推理开销。
3.4 为何无需缓存 Q 向量
一个关键疑问是:为何仅缓存 K、V 而非 Q?核心原因是Q 向量的“使用场景唯一性”:
-
K、V 向量的作用是“提供历史信息”,所有后续 Token 的注意力计算都需要调用;
-
Q 向量的作用是“查询历史信息”,仅用于当前 Token 的注意力计算,后续 Token 生成时无需复用(每个 Token 的 Q 向量都是独立的)。
缓存 Q 向量不仅无法降低计算量,还会额外占用显存,因此 KV Cache 仅聚焦于 K、V 矩阵的缓存。
3.5 完整工作流程
KV Cache 在大模型推理中的完整流程如下:
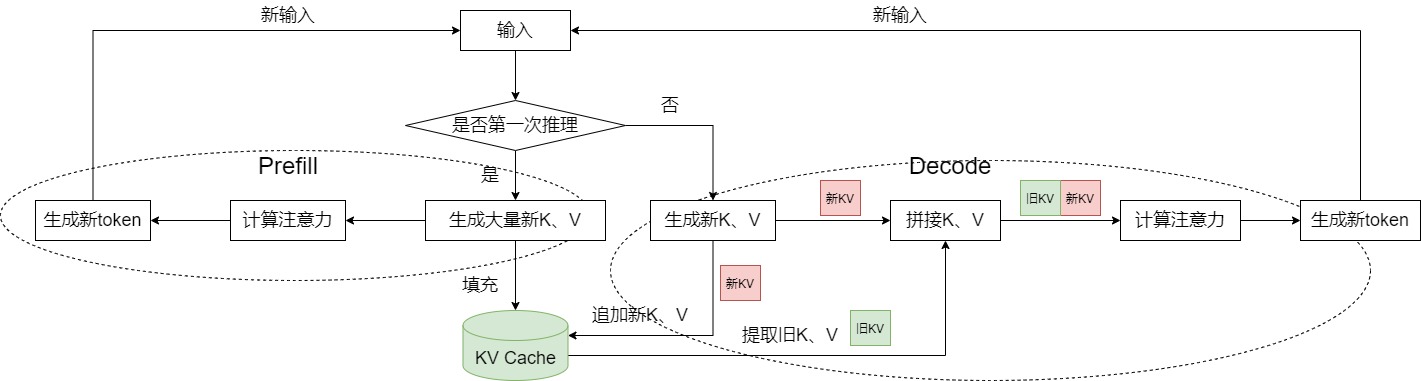
-
Prefill 阶段:并行处理输入 Prompt 的所有 Token,计算每个 Token 的 K、V 向量,缓存至显存,同时完成初始注意力计算,生成第一个新 Token;
-
Decode 阶段:
-
输入上一轮生成的单个 Token,计算其 Q、K、V 向量;
-
将新 Token 的 K、V 向量拼接至缓存的 KV 矩阵中,更新 Cache;
-
用新 Token 的 Q 向量与更新后的 KV 矩阵计算注意力分数,经 FFN 后生成下一个 Token;
-
-
重复 Decode 阶段,直至生成终止符或达到最大序列长度。
4. KV Cache 实现方案
KV Cache 的核心实现逻辑是“缓存历史 K、V 向量 + 新向量拼接更新”,随着大模型框架的发展,实现方式从早期的手动拼接演进为标准化的 Cache 类封装,灵活性和扩展性显著提升。
4.1 早期手动拼接实现
以 Hugging Face Transformers 库中 GPT-2 的早期实现为例,KV Cache 通过元组(Tuple)存储,手动进行张量拼接更新:
# 检查是否存在上一轮的缓存 (layer_past)
if layer_past is not None:
past_key, past_value = layer_past
# 将之前的 key 和当前计算出的 key 拼接(维度:-2 对应序列长度维度)
key = torch.cat((past_key, key), dim=-2)
# 将之前的 value 和当前计算出的 value 拼接
value = torch.cat((past_value, value), dim=-2)
if use_cache is True:
# 将拼接后、更新过的 key 和 value 作为新的缓存 (present) 准备返回
present = (key, value)
else:
present = None缓存数据结构说明
早期实现中,layer_past 存储每层每个注意力头的 K、V 向量,维度为 [2, batch_size, num_heads, seq_len, head_dim],各维度含义如下:
-
第一维(2):固定存储 Key(索引 0)和 Value(索引 1);
-
第二维(batch_size):推理批次大小(如同时处理 16 条请求则为 16);
-
第三维(num_heads):注意力头数量(如 GPT-2 每层 12 个头);
-
第四维(seq_len):当前缓存的序列长度(Prompt 长度 + 已生成 Token 数);
-
第五维(head_dim):单个注意力头的向量维度(如 GPT-2 总隐藏层维度 768,12 个头则为 64)。
4.2 标准 Cache 类实现
早期手动拼接方案存在明显缺陷:代码冗余(每个模型需重复实现拼接逻辑)、扩展性差(无法适配复杂缓存策略)。为此,Transformers 库引入了 Cache API(transformers/src/transformers/cache_utils.py),将 KV 缓存封装为专用类,统一管理存储、更新、重排等逻辑。
Cache 类核心接口
class Cache:
"""
所有缓存类的基类(抽象类),具体逻辑由子类实现
"""
is_compileable = False
def __init__(self):
super().__init__()
def update(
self,
key_states: torch.Tensor,
value_states: torch.Tensor,
layer_idx: int,
cache_kwargs: Optional[dict[str, Any]] = None,
) -> tuple[torch.Tensor, torch.Tensor]:
"""
核心更新方法:将新计算的 K/V 向量更新到指定层缓存
参数:
key_states/value_states:当前 Token 的 K/V 向量
layer_idx:当前层索引(如第 3 层 Transformer 块)
cache_kwargs:额外参数(如 cache_position 指定拼接位置)
返回:更新后的完整 K/V 向量
"""
raise NotImplementedError("Make sure to implement `update` in a subclass.")
def get_seq_length(self, layer_idx: Optional[int] = 0) -> int:
"""返回指定层缓存的序列长度"""
def get_max_cache_shape(self) -> Optional[int]:
"""返回缓存的最大容量(支持的最大序列长度)"""
def get_usable_length(self, new_seq_length: int, layer_idx: Optional[int] = 0) -> int:
"""根据新输入序列长度,返回当前缓存的可用长度(适配滑动窗口等策略)"""
def reorder_cache(self, beam_idx: torch.LongTensor):
"""为束搜索(Beam Search)重排缓存:根据选定的束索引调整 K/V 顺序"""模型集成方式
现在模型仅需调用 Cache 类的 update 方法即可完成缓存管理,无需关注底层拼接逻辑,代码简洁且可复用:
# 检查是否存在缓存对象 (past_key_value)
if past_key_value is not None:
if isinstance(past_key_value, EncoderDecoderCache):
if is_cross_attention: # 交叉注意力层:取出对应的交叉注意力缓存
past_key_value = past_key_value.cross_attention_cache
else: # 自注意力层:取出自注意力缓存
past_key_value = past_key_value.self_attention_cache
# 缓存更新参数(cache_position 标记新 Token 的序列位置)
cache_kwargs = {"cache_position": cache_position}
# 调用 update 方法更新缓存,返回完整 K/V 向量
key_states, value_states = past_key_value.update(
key_states, value_states, self.layer_idx, cache_kwargs=cache_kwargs
)启用/关闭方式
Transformers 库的 generate 方法通过 use_cache 参数控制 KV Cache:
-
use_cache=True(默认):启用 KV Cache,优先保证推理速度; -
use_cache=False:关闭 KV Cache,节省显存(适用于显存不足的场景)。
4.3 核心优化点
标准化 Cache 类的设计带来两大核心优势:
-
支持复杂缓存策略:如
SinkCache(抛弃早期 Token 以支持超长序列)、SlidingWindowCache(滑动窗口缓存,仅保留最近 N 个 Token 的 K/V)等,可通过子类扩展实现; -
兼容模型并行与分布式推理:缓存对象可被多个 GPU 节点共享,支持跨设备缓存同步,适配大规模模型部署。
5. KV Cache 显存开销分析
KV Cache 虽能降低计算量,但会显著占用显存——其显存开销与序列长度呈线性增长,是长序列推理的核心显存瓶颈。
5.1 显存占用公式
KV Cache 的显存占用可通过以下公式精确计算:
各参数含义:
-
2:需同时缓存 K 和 V 两个矩阵; -
num_layers:模型的 Transformer 块层数(如 GPT-3 为 96 层); -
batch_size:推理批次大小(同时处理的请求数); -
seq_len:缓存的序列总长度(Prompt 长度 + 已生成 Token 数); -
hidden_size:模型的总隐藏层维度(如 GPT-3 为 12288); -
precision_bytes:数据精度对应的字节数(FP32=4、FP16=2、BF16=2、INT8=1、INT4=0.5)。
5.2 典型模型量化示例
以 GPT-3 175B 模型为例,对比不同序列长度、精度下的 KV Cache 显存占用(批次大小=16):
|
模型参数 |
数值 |
|---|---|
|
参数量 |
175B |
|
层数(num_layers) |
96 |
|
隐藏层维度(hidden_size) |
12288 |
常规序列长度(seq_len=1024)
-
FP32 精度: GB;
-
FP16/BF16 精度: GB;
-
INT8 量化: GB;
-
INT4 量化: GB。
可见,FP16 精度下 KV Cache 显存占用已达 72 GB,约为 GPT-3 模型参数量(FP16 下约 350 GB)的 20%——这一开销在多批次、长序列场景下会急剧扩大。
5.3 长序列场景瓶颈
当前大模型推理逐渐向超长上下文(如 32k、64k、128k)演进,而 KV Cache 显存占用与序列长度呈线性增长,成为核心制约因素。
仍以 GPT-3 175B 模型(batch_size=16、FP16 精度)为例,当序列长度扩展至 32k 时:
2.25 TB 的显存需求远超当前单卡最大显存(如 A100 为 80 GB、H100 为 80/160 GB),即使采用多卡模型并行,也需数十张 GPU 才能满足——未经优化的 KV Cache 完全无法支撑超长序列推理。
5.4 显存优化技术方向
长序列场景下的 KV Cache 显存瓶颈,催生了一系列针对性优化技术:
-
量化压缩:如 FP8/INT8/INT4 量化 KV Cache,在保证精度损失可控的前提下降低显存占用;
-
分页管理:如 PagedAttention,将 KV Cache 拆分为固定大小的块,动态分配显存,减少碎片;
-
滑动窗口注意力:仅缓存最近 N 个 Token 的 KV,丢弃早期 Token(如 Llama 3 的 128k 上下文依赖此技术);
-
稀疏注意力:仅计算当前 Token 与关键历史 Token 的注意力,减少 KV Cache 存储量。
6. 总结与思考
KV Cache 的本质是以空间换时间,通过缓存历史 Token 的 K、V 矩阵,将注意力计算复杂度从 降至 ,是大模型推理效率提升的关键技术。
Decode 阶段仅需输入当前 Token,计算其 Q 向量后,与缓存的 KV 矩阵直接进行注意力计算,无需重复处理历史序列;新 Token 的 K、V 向量会拼接至缓存,供后续步骤复用。
KV Cache 显存占用公式为 ,与序列长度呈线性增长,是长序列推理的核心显存瓶颈。
7.vla-cache中的显存分析
在4060ti本地部署vla-cache,遭遇OOM 并修复
原始 VLA-Cache 在推理时有三重显存压力,我们对应解决了三个:
| 问题 | 大小 | 解决方案 |
|---|---|---|
| ① output_attentions=True 累积 32 层注意力矩阵在 GPU | ~1.5 GB | AttentionHookCapture:每层注意力算完立刻移到 CPU,GPU 只占 1 层的 47 MB |
| ② INT4 bitsandbytes 反量化工作空间(每个 FFN 层 86 MB × 32 层) | 峰值 ~2.7 GB | KV cache 在 forward 前移到 CPU,forward 后移回 GPU |
| ③ autograd 保存 softmax 输出(梯度计算用)31 层 × 22 MB | ~693 MB + Q/K saved tensors = ~3.6 GB(理论估计值) | torch.no_grad() |
更加详细的vla-cache运行时的显存分析和我们对应的修复方式将在下一篇博客中详细说明。
【TODO】
引用与参考
[1] Liu C, Chen Y, Zhou F, et al. Fast Inference of Large Language Models with Dynamic Speculative Decoding(Preprint/OL). (2023-11-30) (2025-11-03). https://arxiv.org/pdf/2311.18677.
[2] 机器学习算法与 Python 学习。大模型推理优化: speculative decoding 原理与实践 (EB/OL). (2023-05-12) (2025-11-03). https://zhuanlan.zhihu.com/p/624740065.
[3] rossiXYZ. 深入解析 vLLM 推理框架的性能优化技巧 (EB/OL). (2024-04-10) (2025-11-03). https://www.cnblogs.com/rossiXYZ/p/18799503.
[4] 人工智能前沿科技。大模型分布式推理:模型并行与数据并行实践 (EB/OL). (2023-06-08) (2025-11-03). https://zhuanlan.zhihu.com/p/630832593.
[5] 深度学习算法工程师。大模型 KV Cache 优化:从原理到工程实现 (EB/OL). (2023-09-15) (2025-11-03). https://zhuanlan.zhihu.com/p/662498827.
Taoqick. (2024, March 18). vLLM inference framework deployment and performance tuning guide. CSDN. https://blog.csdn.net/taoqick/article/details/137476233
Ningyanggege. (2023, November 10). Large model inference memory optimization: PagedAttention and video memory scheduling strategies. CSDN. https://blog.csdn.net/ningyanggege/article/details/134564203

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)