打通AI落地闭环:OpenClaw系统云端镜像部署与Sufy推理平台接入指南
具身智能正从实验室走向产业应用,OpenClaw成为企业构建自动化业务的核心引擎。文章探讨了OpenClaw私有化部署的实践方案,包括利用预置镜像简化配置、优化算力配置平衡CPU与GPU需求,以及通过对象存储实现智能体数据的安全管理。同时提出构建包含算力、算法和存储的全栈生态,采用私有化部署与云端服务结合的混合模式,既保障数据安全又保持技术前沿性,为企业数字员工系统建设提供模块化解决方案。
从实验室到生产线,具身智能(Embodied AI)正在经历关键的“最后一公里”跨越。企业不再满足于只会聊天的虚拟助手,而是迫切需要能操控软件、执行复杂工作流的“数字员工”。在这个背景下,OpenClaw产业应用正迅速成为企业构建自动化业务闭环的核心引擎。不同于简单的脚本自动化,OpenClaw 提供了一套完整的智能体编排框架,能够像人类一样感知屏幕、操作键鼠。然而,对于金融、医疗等对数据隐私极其敏感的行业,公有云方案往往难以通过合规审查。因此,构建一套自主可控的 OpenClaw私有化部署 方案,成为了企业将具身智能落地的必经之路。
告别繁琐配置:企业级私有化部署实战
许多技术团队在尝试落地 OpenClaw企业级私有化部署教程 时,常常卡在环境配置这一步。依赖库冲突、Docker 容器编排复杂、网络穿透配置繁琐,这些“拦路虎”消耗了大量宝贵的开发时间。
为了解决这一痛点,最高效的路径并非从零开始编译,而是利用成熟的云端镜像技术。在构建基础环境时,推荐直接在云端控制台选用预置好的 openclaw系统镜像。这一镜像方案最大的优势在于“开箱即用”,底层依赖和运行环境已经经过严格测试和优化,企业无需再为系统兼容性头疼,只需专注于业务逻辑的开发。这种方式不仅大幅缩短了部署周期,还为后续的 数字员工企业应用 提供了稳定的基座。
部署完成后,如何让 OpenClaw 这个“大脑”更聪明?算力配置是关键。适合OpenClaw的云端算力配置 并不意味着盲目堆砌昂贵的 GPU。对于大多数 RPA(机器人流程自动化)类任务,CPU 的多核并发能力往往比单卡显存更重要;但如果涉及复杂的视觉识别(如读取票据、识别动态验证码),则需要引入强大的推理引擎。此时,接入高性能的 AI大模型推理服务 便是点睛之笔。通过 API 调用 Claude 或 DeepSeek 等顶级模型,可以让本地部署的 OpenClaw 具备“深度思考”能力,精准理解模糊指令,处理非结构化数据,真正实现从“自动化”向“智能化”的跃迁。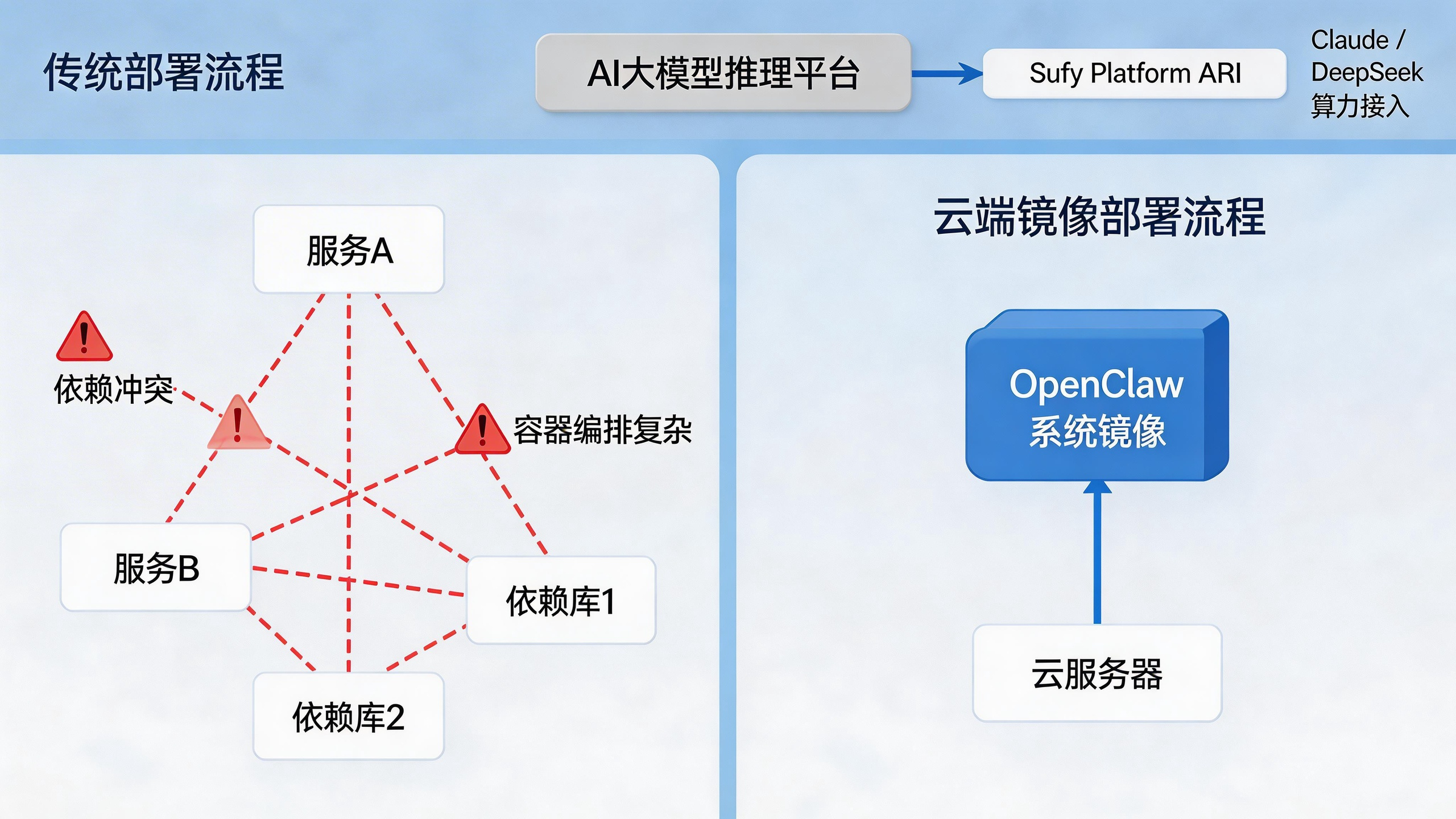
具身智能的数据心脏:安全与效率的平衡
当 OpenClaw 智能体开始在业务系统中穿梭,它会产生海量的过程数据:操作日志、屏幕截图、DOM 树结构快照等。这些数据不仅是审计的依据,更是优化智能体行为的宝贵资产。OpenClaw智能体数据安全存储方案 的设计,直接决定了系统的长期可用性。
传统的本地磁盘存储在面对 OpenClaw具身智能落地案例解析 中常见的高并发场景时,容易出现 IO 瓶颈,且数据安全性难以保障。企业应构建存算分离的架构,将计算节点(OpenClaw 运行环境)与存储节点解耦。
利用 对象存储 Kodo 来承接这些非结构化数据是一个理想选择。Kodo 提供的海量存储能力支持中心和边缘的双重部署模式,这意味着企业既可以在总部建立统一的数据湖,也可以在各个业务分部实现低延迟的数据写入。对于需要长期留存的 智能体数据存储(如合规性录屏),Kodo 的生命周期管理功能可以自动将冷数据归档,大幅降低存储成本,同时确保数据在需要时随时可查,为 具身智能解决方案 的持续迭代提供坚实的数据支撑。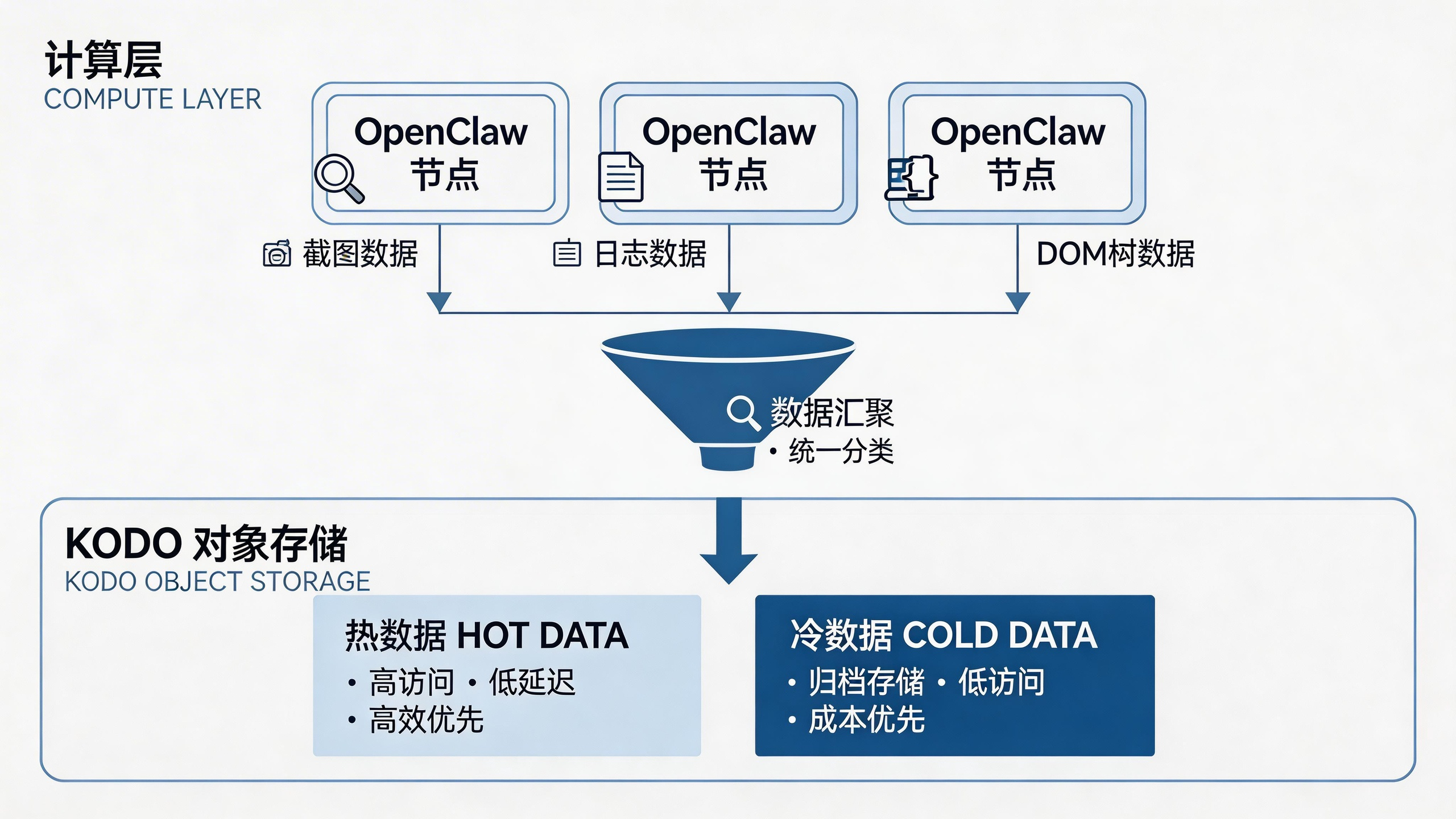
构建全栈闭环:从工具到生态
真正的产业落地,不仅仅是部署一个软件,而是构建一套包含算力、算法、数据存储在内的全栈生态。OpenClaw 作为核心执行单元,配合云端镜像的快速部署能力、大模型的认知推理能力以及对象存储的数据管理能力,共同构成了一个可进化的数字员工系统。
企业在规划 如何构建OpenClaw数字员工系统 时,应摒弃单点突破的思维,转而采用这种模块化、可扩展的架构。通过私有化部署确保核心业务数据的安全边界,同时利用标准化的云服务接口引入外部的先进算力,这种“主权在内、能力在外”的混合模式,将是未来 OpenClaw 产业应用的主流形态。这不仅解决了当下的效率问题,更为未来接入更高级的通用人工智能(AGI)预留了接口,让企业的自动化体系始终保持在技术前沿。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 42
42 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)