PolarDB一站式记忆管理重磅上线:让记忆成为数据库最有温度的力量
阿里云PolarDB-PG推出全新一站式记忆管理系统,解决大模型跨会话记忆丢失问题。该系统融合图+向量记忆库、开放记忆引擎和模型算子能力,支持智能体长期保留用户偏好和历史交互信息。核心优势包括:1)端到端一站式管理;2)图式与向量式记忆融合,提升召回率40%;3)百亿级规模毫秒级响应;4)多租户资源隔离。支持纯向量记忆库(适合客服场景)和向量+图组合方案(适合医疗诊断等复杂场景)。目前已应用于新能
大型语言模型(LLM)在理解和生成上下文连贯的对话方面取得了巨大成功。然而,它们固有的“记忆缺陷”——即有限的上下文窗口——严重制约了其在跨会话、跨应用的长时间交互中保持一致性的能力。一旦对话超出上下文长度,LLM 就会像一个“失忆”的伙伴,忘记用户的偏好、重复提问,甚至与之前确立的事实相矛盾。想象一下这个场景:你告诉一个AI助手你是素食主义者且不吃乳制品。几天后,当你向它寻求晚餐建议时,它却推荐了烤鸡。这种体验无疑会削弱用户对AI的信任和依赖。
为此,阿里云瑶池旗下的云原生数据库PolarDB PostgreSQL版(以下简称PolarDB-PG)全新推出一站式记忆管理AI应用,使智能体能够跨会话、跨应用持续保留用户偏好、事实背景与历史交互信息,解决大模型有限上下文窗口和跨会话记忆丢失的核心痛点。
一、构建智能体记忆面临的挑战
开发、运维效率低:当前主流记忆框架均为检索式记忆系统,后端需要对接关系库、向量库甚至图库等多种记忆库资源,数据一致性难以保障;对于AI快速驱动业务演进而言,企业客户很难对记忆引擎、存储/数据库、模型服务等底层设施做到完全兜底。
记忆生成、检索效果不佳:不少企业客户希望自建记忆系统,但遇到记忆事实、偏好等提取不全导致关键信息遗漏;因记忆系统整体链路长导致记忆检索延迟高,导致交互问答不流畅;在记忆推理需求场景,因只能提供向量化记忆导致检索结果相关性欠强;另外,模型算法与提示词配置的灵活度,也直接决定了方案迭代的速度。
系统成本压力大:随用户规模增长,系统在并发度、存储规模等方面缺乏弹性扩缩容能力;数据库、记忆引擎等多license系统,系统费用成本叠加;对于持续爆发增长的记忆库,缺乏支撑记忆生命周期管理的有效机制等。
二、PolarDB一站式记忆管理系统
针对上述挑战,PolarDB-PG推出全新AI应用——一站式长记忆管理系统正式发布上线。PolarDB-PG记忆管理真正融合了图 + 向量一站式记忆库 + 开放记忆引擎 + 模型算子能力,提供了全面白屏化的参数配置,提示词策略管理以及模型算法混池加速能力,支撑“记忆读写 → 上下文注入 → 模型推理 → 结果反馈”的完整闭环。一期已接入Mem0(发音为 "mem-zero")记忆引擎,兼容开源 Mem0社区生态,使智能体能够跨会话、跨应用持续保留用户偏好、事实背景与历史交互信息,从而实现真正的个性化和持续学习体验。
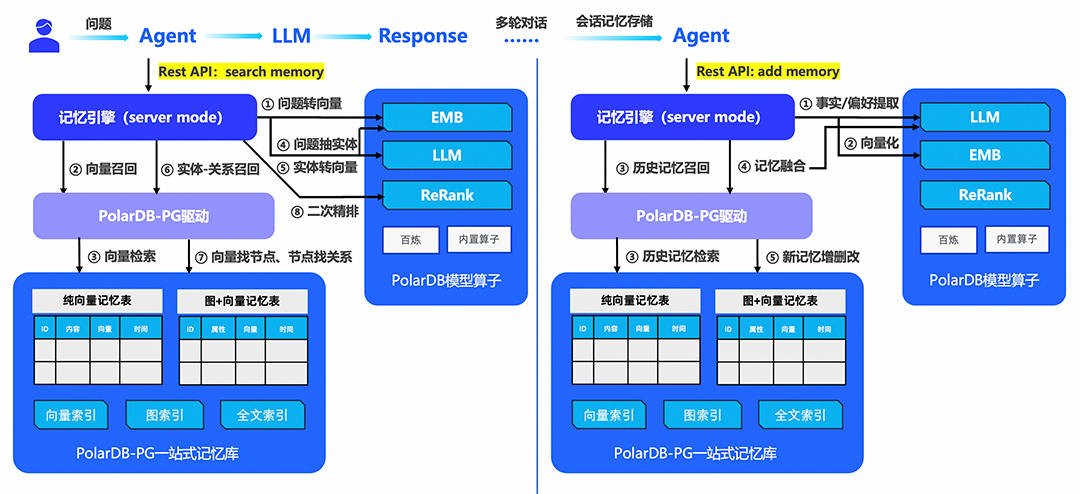
PolarDB-PG一站式记忆管理系统架构
1、记忆引擎
目前,PolarDB-PG已支持Mem0框架,全面兼容开源项目Mem0社区生态;支持Mem0(向量基础版)和Mem0g(图增强版);对开源Mem0系统实现了系列增强,包括:中英文模型接入能力;支持根据userid多图管理功能;支持根据userid向量分区管理功能;同步、异步记忆写出能力;增加sslmode连接参数,支持ssl连接;支持提示词模版的定制优化以及Mem0企业版的部分功能对齐等。后续PolarDB-PG还将和MemOS合作,为AI构建专属的“记忆操作系统”,实现记忆全生命周期的精细化管理与动态调度。
2、一站式记忆库
PolarDB-PG向量数据库引擎 + 图数据库引擎一站式组合。其中,向量数据库引擎采用经优化的PGVector插件;PGVector在PG社区已经被广泛应用,具备十分良好的AI生态支持。图数据库引擎兼容开源AGE(A Graph Extension,为Apache软件基金会的顶级项目),且经过PolarDB-PG与云原生能力的增强融合以及在大量图客户上的多年应用改进和性能优化,不仅表现成熟稳定,且具备在百亿级规模图场景下仍然保持万级以上QPS和百毫秒以下的查询延迟的极佳表现。记忆库支持云原生集中式版本或分布式版本,无需担心扩展性风险。
3、PolarDB模型算子
统一采用PolarDB模型算子提供模型部署、推理、调度体系化能力。模型在记忆管理中扮演了核心的角色,其中:大语言模型LLM负责从用户与智能体的对话中自动提取出具有长期价值的关键事实与偏好,同时用于新记忆与已有记忆的融合(增删改)以及基于图的实体三元组信息抽取;嵌入模型EMB负责将关键信息转化为高维向量,实现高效的语义检索;Rerank模型则用于记忆召回后的精排序。
模型调用和推理的效率占据了用户体验的关键一环,本方案支持多种形式的模型对接途径,包括:a. 数据库自有模型算子形式;b. 百炼模型服务形式;通过高度优化的链路,大幅提升记忆相关推理效率。
4、图形化控制台
PolarDB-PG记忆管理在PolarDB系统中属于AI应用的一种形式,提供了全面图形化的管理界面:
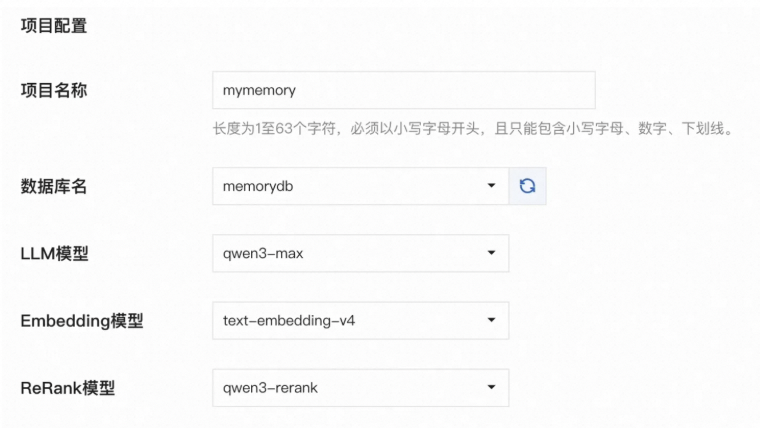
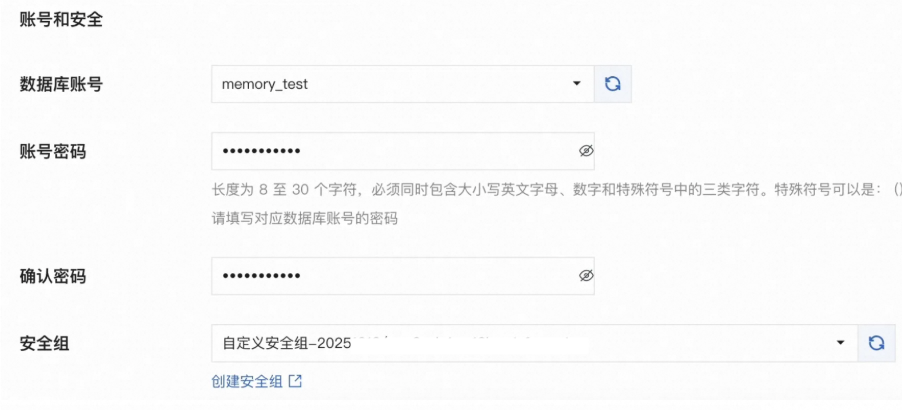
支持灵活的模型算法与数据库配置
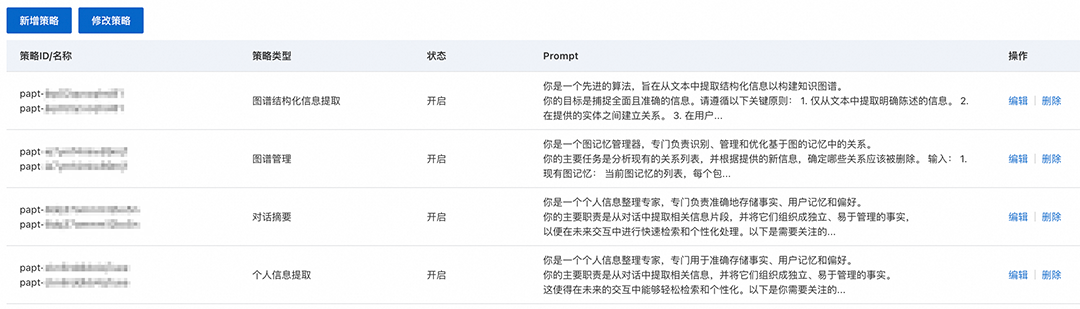
支持各类记忆提取策略配置
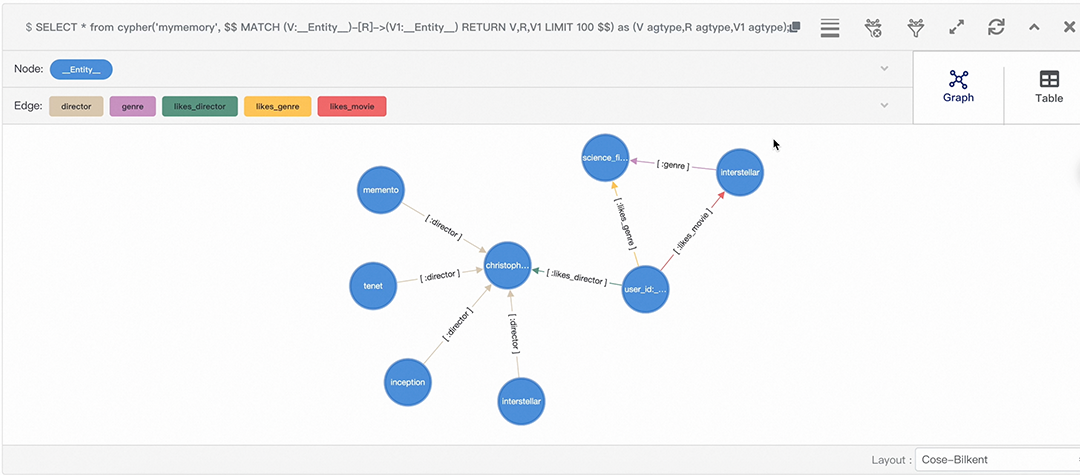
控制台支持记忆图谱查询的可视化
5、AI应用构建平台
支持沿用Mem0已对接周边生态,包括:Langchain、LangGraph、AgentOps、LlamaIndex等框架/平台;支持将PolarDB记忆引擎作为插件加入到Dify框架实现任务流定制;支持与阿里云AgentRun企业级 AI Agent 一站式基础设施平台和AgentScope开源智能体开发框架的一体化整合应用。
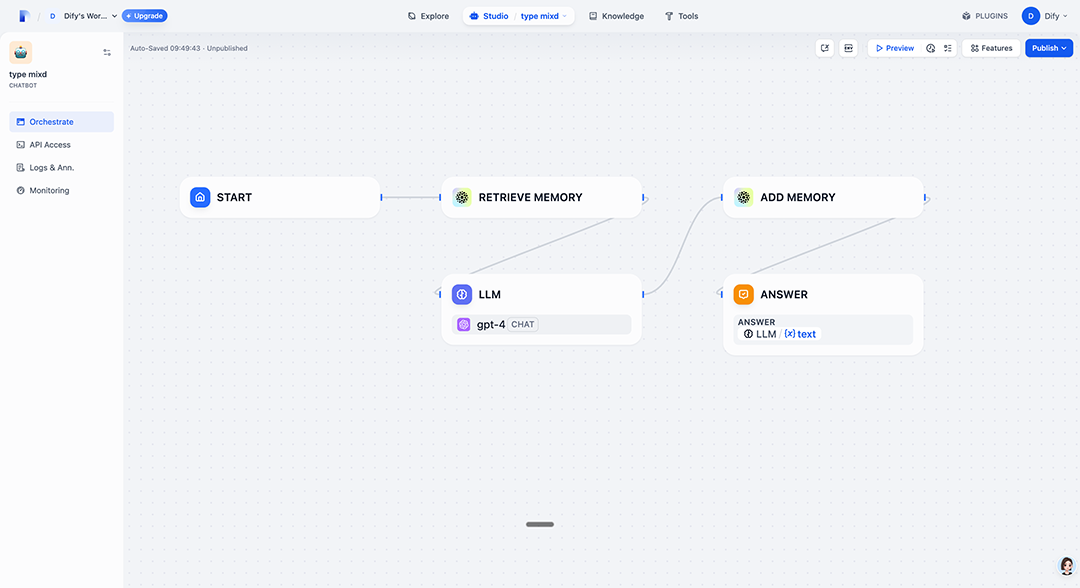
PolarDB记忆管理支持Dify的插件化应用
三、系统核心优势
1、端到端一站式记忆管理
开箱即用,融合记忆引擎、记忆库、模型算子服务以及KVCache加速能力,免去多系统联调、维护成本。
2、图形化配置,简单易用
支持多项目的记忆管理能力,记忆项目配置完全采用图形化的界面形式;支持对记忆引擎、模型服务、记忆提取策略(提示词)等选项的配置;提供极简REST API或客户端SDK,自动完成记忆事实提取、记忆融合以及记忆搜索。
3、图式记忆和向量式记忆融合,记忆更准,成本更低
支持纯向量记忆库模式和图(Graph)+ 向量融合的高级记忆库模式;可借助图结构的关系推理提升记忆召回率40%;一站式解决图库、向量库和关系库,大幅降低TCO成本。
4、深度对接大模型推理服务,保障服务稳定
支持细粒度配置LLM、Embedding、Rerank等模型算子;采用灵活的模型服务路由策略,优先使用百炼模型服务,高并发时自动扩展备用通道,保障服务高可用;自有模型算子VPC内网部署,模型推理延迟可进一步提升30%+。
5、多租户、多图粒度管理,资源可扩展
支持按项目、业务线等维度划分独立的记忆空间,保障资源隔离、数据安全与规模可扩展;支持按UserID自动切子图管理,记忆规模不受限,同等记忆规模下召回效率提升50%+。
6、百亿级记忆规模,毫秒级响应
经历百亿级规模向量、图谱数据客户最佳实践,满足万级高QPS、<50ms低延迟在线服务高标准;跨会话长记忆+会话内基于KVCache Token加速,请求延迟下降88.3%(上下文长度200k,30并发)。
四、记忆库应用场景适配
PolarDB记忆管理支持两类长记忆方案,基于纯向量记忆库方案,和向量记忆库+图记忆库的组合方案,分别适用于以下场景:
1、纯向量记忆库方案
应用场景:需要快速语义检索的对话场景,例如在线客服、实时聊天机器人等。
技术特点:
-
通过LLM提取对话关键事实并向量化存储。
-
采用动态阈值控制检索范围,平衡召回率与精准度。
2、向量记忆库+图记忆库组合方案
应用场景:医疗诊断(跟踪患者病史和药物相互作用)、旅行规划(整合航班、酒店、景点等关系)等复杂关系推理场景,以及长期知识管理场景。
技术特点:
-
向量库处理语义搜索,图库存储实体间关联关系。
-
支持时间感知或因果推理的动态知识图谱更新。
-
基于Mem0g方案的改进,通过两阶段流水线实现结构化记忆。
两种方案的互补性体现在:向量+图虽能处理复杂关系,但检索效率上带来更大挑战;而纯向量方案在简单场景中更高效,但缺乏对深层关系的建模能力。实际部署时,可结合业务复杂度与实时性需求进行混合架构设计。
五、应用展望
目前,PolarDB记忆管理已落地新能源车企开发助手、教育伴学等场景,在文本记忆、多模态记忆等多种场景进行了全面适配,大幅提升个性化交互沉浸感。除以上场景外,PolarDB记忆管理还在企业知识库、游戏虚拟人、旅游规划、电商导购等多个关键领域展现出客户价值,成为推动AI应用从“对话机器人”迈向“智能伙伴”的关键基础设施。PolarDB与Mem0/MemOS的深度整合,让每一位开发者都能轻松构建真正“记得住、懂你心、扛得住、响应快”的记忆系统。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)