具身智能演示深解---从盲行到跑酷:深度视觉如何赋予足式机器人极限运动能力
深度视觉技术正推动足式机器人从基础行走迈向跑酷能力。本文系统梳理了强化学习在足式运动控制中的演进历程,重点分析了深度视觉引入的关键作用。从ETH的奠基性工作开始,到IsaacGym并行训练框架的确立,再到教师-学生框架、非对称Actor-Critic等技术的成熟,为跑酷任务奠定了技术基础。深度相机的引入解决了跑酷所需的前瞻性环境感知问题,但也带来渲染开销、噪声处理等新挑战。当前主流技术栈结合GPU
1. 引言:为什么需要深度视觉
在过去数年间,基于强化学习的足式机器人运动控制取得了长足进展。早期的工作——以ETH的legged_gym框架和IsaacGym并行训练环境为代表——已经证明,仅依靠本体感知(关节编码器、IMU等)就能训练出在连续复杂地形上鲁棒行走的策略。这类方法通常被称为"Blind Locomotion",即机器人不借助任何外部视觉传感器,完全依赖对自身状态的感知来适应地形变化。DreamWaQ(KAIST, ICRA 2023)等工作进一步证明,通过非对称Actor-Critic框架配合隐式地形估计,四足机器人甚至可以在户外多样地形上实现长距离鲁棒行走。
然而,Blind Locomotion存在一个根本性的局限:机器人无法预知前方地形的具体形态。当面对跳箱、深沟、高台阶等需要提前规划动量和轨迹的极限地形时,纯本体感知的策略往往力不从心。跑酷(Parkour)场景要求机器人在接近障碍物之前就判断出障碍物的高度、宽度和距离,并据此调整步态、积累动量、选择起跳时机。这些决策必须依赖对前方环境的主动感知——深度视觉由此成为从"能走"到"能跑酷"的关键技术跳板。
本文将系统梳理近年来将深度视觉引入足式机器人跑酷运动控制的代表性工作,重点分析三个开源项目——Extreme Parkour(CMU)、WMP(SJTU)和VMTS(2025)——的技术架构与实现细节,并深入解读PIE(ZJU, RAL 2024)框架的隐式-显式估计机制及其与AMP运动先验的结合路径。
2. 技术背景:深度视觉在足式运控中的演进
2.1 从特权信息到可部署感知
足式机器人强化学习运控的核心难题在于sim-to-real gap。在仿真环境中,策略可以直接访问地形高度图、摩擦系数、接触力等"特权信息"(Privileged Information),但这些信息在真实部署时无法获取。为解决这一矛盾,研究者发展出了两条主要技术路线:
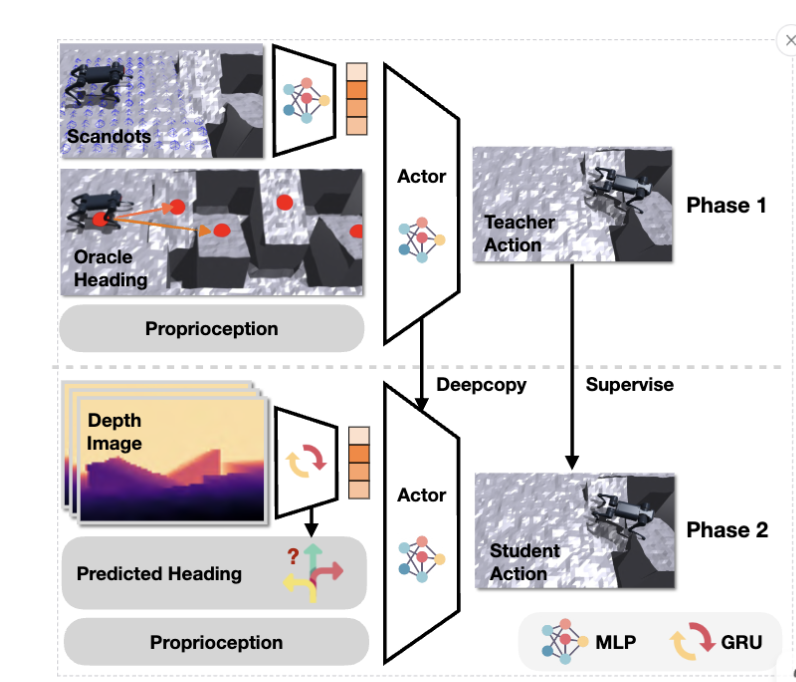
第一条是教师-学生(Teacher-Student)框架。ETH在2020年的工作(Learning quadrupedal locomotion over challenging terrain, Science Robotics)首次提出了这一范式:教师策略在仿真中利用特权信息学习最优行为,随后通过在线模仿学习(DAgger)将知识蒸馏给仅使用可观测数据的学生策略。学生策略通常引入一个额外的编码器,从历史本体观测中隐式估计那些无法直接获取的环境信息。
第二条是非对称Actor-Critic框架。KAIST在2022年的工作(Concurrent Training of a Control Policy and a State Estimator, RAL)提出了一种更简洁的方案:Actor网络仅接收可观测信息,而Critic网络在训练时直接使用特权信息的真实值。这种非对称结构避免了两阶段训练的复杂性,同时保留了特权信息对价值估计的指导作用。DreamWaQ进一步在此基础上引入了beta-VAE来学习隐式地形表征。
2.2 深度相机的引入
当任务从连续地形行走升级为跑酷时,仅靠本体感知的隐式估计已不足以提供足够的环境信息。深度相机(如Intel RealSense)的引入为策略提供了前方地形的显式几何信息。但深度图像的引入也带来了新的挑战:
- 仿真中的深度渲染开销:IsaacGym的GPU相机渲染需要额外的计算资源,且渲染频率通常低于控制频率
- 深度图像的噪声与延迟:真实深度相机存在测量噪声、边缘失真和固有延迟
- 高维输入的处理:原始深度图像维度远高于本体观测,需要高效的特征提取网络
- sim-to-real的视觉域差异:仿真渲染的深度图与真实深度图之间存在系统性差异
针对这些挑战,研究者发展出了多种技术方案。其中最具代表性的是"scandots-to-depth蒸馏"范式:先用地形扫描点(scandots,即仿真中直接采样的地形高度值)训练基础策略,再训练一个深度编码器将真实深度图像映射到与scandots编码器相同的隐空间,从而实现从特权感知到可部署视觉感知的迁移。
2.3 训练框架的技术栈
当前主流的深度视觉跑酷训练框架基本遵循以下技术栈:
仿真环境: IsaacGym (NVIDIA, GPU并行)
训练框架: legged_gym + rsl_rl (ETH开源)
RL算法: PPO (Proximal Policy Optimization)
网络结构: MLP Actor-Critic + CNN/Transformer 深度编码器
部署格式: ONNX / TorchScript JIT
这一技术栈最早由ETH在2021年的里程碑工作(Learning to Walk in Minutes Using Massively Parallel Deep Reinforcement Learning, CoRL)中确立,此后被几乎所有后续工作所采用或改进。IsaacGym提供的GPU并行仿真能力使得数千个环境可以同时运行,将训练时间从数天压缩到数小时。
3. 全网深度视觉跑酷项目梳理
最近人形机器人如火如荼,其中基于强化学习和sim-to-real的运控算法更是关键。但人形机器人的强化学习运控算法也是从四足机器人的运控算法中迭代而来。本节首先梳理RL足式运控的技术演进脉络——从四足到人形的关键论文,再聚焦深度视觉跑酷的代表性工作。
背景提示:
- 在IsaacGym(2021年)之前,大多数训练基于ETH开源的RaiSim框架,使用CPU采样。基于IsaacGym的开源训练代码基本源自ETH开发的legged_gym + rsl_rl项目。
- Domain randomization ≈ Dynamics randomization,前者强调测试和训练时的环境差异(来自domain adaptation领域),后者强调机器人/环境的动态模型属性,基本可以混用。
- RL足式运控的核心难点在于sim-to-real gap。方案上大致经历了 SysID → 电机模型 → Teacher-Student → 非对称框架 的演进,同步引入domain randomization来缩小迁移gap。
- 算法和仿真能cover的sim-to-real gap有限,机器人本体性能参数(电气设计、电机稳定性、扭矩、驱动延迟)以及URDF准确性,都决定了算法迁移到本体的能力上限。大部分成功迁移的机器人都是串联杆机构,因为并联杆和软体机器人难以被现有刚体模拟器准确建模。
3.1 RL足式运控技术演进脉络
3.1.1 ETH Robotics System Lab 系列
ETH首先在ANYmal四足机器人上证明了基于强化学习的运控算法的有效性,这一系列工作奠定了整个领域的技术基础。
1. Learning Agile and Dynamic Motor Skills for Legged Robots (Science Robotics, 2019)
强化学习做四足运控的奠基之作。通过利用real数据训练的电机网络模型在sim中补偿的方式训练策略模型,配合RL + dynamics randomization,成功在ANYmal上部署,实现了鲁棒的locomotion策略,包括以特定速度奔跑、跌倒恢复等。
2. Learning quadrupedal locomotion over challenging terrain (Science Robotics, 2020)
同样是奠基之作。首次提出两阶段教师-学生框架:教师策略利用模拟器里的特权信息学习最优运动策略,再通过在线模仿学习(DAgger)蒸馏给可部署的学生策略(引入额外encoder估计隐式特权信息)。同时提出地形课程学习,实现鲁棒的复杂连续地形行走。注意此时ETH的控制策略还比较复杂——网络仅用于辅助足端轨迹生成,还需借助IK求解得到最终target joints,现在主流工作都是直接用策略输出target joints。
3. Learning to Walk in Minutes Using Massively Parallel Deep RL (CoRL, 2021)
真正意义上的里程碑工作。首次开发和验证了IsaacGym并行训练 + domain randomization的强化学习运控训练方案,开源了legged_gym项目。这一技术栈此后被几乎所有后续工作所采用。
4. Learning robust perceptive locomotion for quadrupedal robots in the wild (Science Robotics, 2022)
将外部视觉信号集成到足式locomotion策略中的标志性工作。在ANYmal上集成本体感知和外部视觉信号,通过学习从深度相机估计局部高程图,实现了楼梯、隧道、雪山、浓雾、森林、碎岩等极端条件下的鲁棒行走。给出了"学习带外感知策略"的完整范例——策略不直接使用原始深度图,而是先编码为局部高程图估计。这一思路深刻影响了后续所有视觉跑酷工作。
5. Elevation Mapping for Locomotion and Navigation using GPU (IROS, 2022)
提出利用GPU高效构建高程图的方法,通过接收外部传感器点云信息和位姿信息快速构建周围地形高程图。代码已开源。但在复杂环境中里程计漂移仍是实时建图最大的挑战。
6. Advanced Skills through Multiple Adversarial Motion Priors in RL (ICRA, 2023)
增强版本的AMP,允许多种可离散切换的风格。在轮腿四足机器人上展示了躲避、行走,以及在四足和双足模式(站立)之间切换的风格。
7. Curiosity-Driven Learning of Joint Locomotion and Manipulation Tasks (CoRL, 2023)
主要亮点在于用轮腿四足学习了用腿当manipulator的loco-manipulation策略。
8. Learning Agile Locomotion on Risky Terrains (IROS, 2024)
可能是第一篇基于RL运控走离散地形的工作(虽然不是全向行走),demo效果很不错。
9. ANYmal Parkour: Learning agile navigation for quadrupedal robots (Science Robotics, 2024)
提出多层级框架(感知模块 + 导航模块 + 运动模块),首篇实现ANYmal四足机器人动态跑酷。感知模块重建环境信息,导航模块驱动运动模块选择合适的运动技能。
10. DTC: Deep Tracking Control (Science Robotics, 2024)
将Model-based和Learning-based方法有效结合。上层TO模块根据环境和动力学实时优化机身与足端轨迹,底层RL模块严格跟踪上层优化轨迹,实现了梅花桩、深沟、野外废墟等极端地形的精确运动。改善了此前将运动控制制定为机身速度跟踪而牺牲灵活落足点选择的不足。
3.1.2 KAIST 系列
韩国KAIST的机器人学者开发了很多经典的强化学习运控算法方案,主要在Raibo(MIT Mini Cheetah)和宇树机器狗上验证。
1. Concurrent Training of a Control Policy and a State Estimator for Dynamic and Robust Legged Locomotion (RAL, 2022)
提出一阶段的非对称学习方式(无需教师-学生):策略网络同时训练一个关键状态估计器(估计linear velocity、foot height、contact probability,输入为历史可观测数据),而critic直接拿到关键状态真实值,配合dynamics randomization和PPO训练。最终策略可成功穿越多样的连续复杂地形。
2. DreamWaQ: Learning Robust Quadrupedal Locomotion With Implicit Terrain Imagination via Deep RL (ICRA, 2023)
非对称强化学习结构,状态估计器从可观测信息中估计速度和隐式地形信息z,利用β-VAE学习。在宇树A1上实现了鲁棒的长距离多样户外地形行走。证明了非对称Actor-Critic框架可以实现四足机器人在复杂环境中的鲁棒运动,运动能力甚至可以超过特权学习中学生策略的能力。
3. Learning quadrupedal locomotion on deformable terrain (Science Robotics, 2023)
针对当前simulator仅能仿真刚性接触动力学的局限,修改了RaiSim底层接触动力学计算模型,建模了granular media颗粒接触动力学,实现了Raibo在沙滩和海绵垫等松软地形的敏捷鲁棒运动。采用非对称训练框架,进一步证明了该框架的有效性。此后非对称成为腿足式机器人强化学习运控的主流框架。
4. A Learning Framework for Diverse Legged Robot Locomotion Using Barrier-Based Style Rewards (ICRA, 2025)
通过引入松弛对数障碍函数方法,设计了基于运动模式特征的软约束奖励机制,有效引导机器人趋向预设运动形态参数(周期性步态生成、关节运动范围限制等)。值得注意的是本文未使用运动先验却生成了多种仿生四足步态,其中四足站立的仿人行走和模拟动物奔跑Gallop步态令人印象深刻。
5. Learning-based legged locomotion: state of the art and future perspectives (IJRR, 2025)
一篇基于学习方法的腿足式机器人运动控制综述,系统概括了过去几年学术界和工业界的研究成果并展望了未来发展方向。来自Gatech。
3.1.3 其他关键贡献
除ETH和KAIST外,还有很多研究者在足式机器人运控算法上做出了重要贡献。
1. Sim-to-Real: Learning Agile Locomotion For Quadruped Robots (RSS, 2018)
同样算强化学习做四足运控的奠基之作,启发了ETH的ANYmal系列。基于Ghost Robotics的Minitaur四足机器人,提出了RL + 解析式电机模型 + dynamics randomization解决sim-to-real迁移问题,实现了灵巧的locomotion行为。
2. Learning Agile Robotic Locomotion Skills by Imitating Animals (UCB, RSS, 2020)
在宇树早期的Leika狗上,基于Motion Retargeting和DeepMimic的motion tracking方案,学习动物自然风格的运动行为。代码已开源。
3. Sim-to-Real Learning of All Common Bipedal Gaits via Periodic Reward Composition (ICRA, 2021)
较早提出了基于概率周期函数定义的足式步态(站立、行走、跳跃、跑步、单脚跳),在Cassie上测试。为每种步态单一训练策略,以及一个多步态切换策略。被后续很多工作参考。
4. AMP: Adversarial Motion Priors for Stylized Physics-Based Character Control (UCB, SIGGRAPH, 2021)
虽非足式机器人工作,但框架本身有重要迁移价值。用GAN作为隐式metric获得风格引导奖励来学习控制策略,后被广泛应用于四足和人形机器人的自然运动学习。
5. RMA: Rapid Motor Adaptation for Legged Robots (CMU, RSS, 2021)
整体方案接近ETH的教师-学生框架,teacher-student + adaptation module。没有使用地形课程,通过随机采样地形 + domain randomization + RaiSim并行训练,在宇树A1上实现了无外感知的复杂连续地形穿越。代码已开源。
6. Walk These Ways: Tuning Robot Control for Generalization with Multiplicity of Behavior (MIT, CoRL, 2022)
在宇树Go1上定义并实现了可细粒度调整步态的鲁棒locomotion策略,可控参数包括速度、步态(pronking、trotting、bounding、pacing、galloping)、步频、机身高度、俯仰角、触地时间、抬腿高度等。代码已开源。
7. Rapid Locomotion via Reinforcement Learning (MIT, RSS, 2022)
提出速度网格自适应采样课程,机器人可根据自身运动能力最大程度挖掘速度上限,避免了手工调整速度课程,最大限度减少专家知识干预。代码已开源。
8. Adversarial Motion Priors Make Good Substitutes for Complex Reward Functions (UCB, ICRA, 2022)
首次将AMP方法应用到四足机器人,仅通过任务奖励和风格奖励就能学会自然运动行为,推动了后续基于模仿学习的四足运控研究。代码已开源。WMP项目直接引用了该工作的开源实现(AMP_for_hardware)。
9. Deep Whole-Body Control: Learning a Unified Policy for Manipulation and Locomotion (CMU, CoRL, 2022)
在宇树Go1 + WidowX机械臂上首次利用强化学习运控实现臂-腿协同控制(基于遥操作)。基于RMA提出了ROA,将环境隐变量z由两阶段估计变为一阶段在线估计。基于IsaacGym + rsl_rl开发,代码已开源。
10. Learning robust and Agile Legged Locomotion Using Adversarial Motion Priors (SJTU, RAL, 2023)
使用教师-学生训练框架,在仅用本体感知的情况下在宇树Go1上实现了鲁棒的复杂连续地形行走。亮点在于使用AMP引导四足机器人在复杂地形上也能学习到自然步态运动,自然步态数据利用轨迹优化在平地上生成。WMP项目的AMP集成方案直接参考了该工作。
11. Lifelike Agility and Play on Quadrupedal Robots using RL and Generative Pre-trained Models (Tencent, Nature Machine Intelligence, 2023)
利用生成模型的强大表现能力,在预训练阶段学习来自动物的大规模运动数据,在第二阶段的环境交互中复用第一阶段所学运动技能。是腾讯Robotics X的经典代表作。
12. Learning Agile Skills via Adversarial Imitation of Rough Partial Demonstrations (CoRL, 2023)
从部分不完整的动作演示中学习四足机器人的动态运动,数据集来源于人为手工操作机器人收集,在低成本机器人上实现了后空翻动作。
13. Extreme Parkour with Legged Robots (CMU, ICRA, 2024) & Robot Parkour Learning (Stanford+上海期智, CoRL, 2024)
两篇同期工作,用domain randomization + 外感知将宇树A1四足机器人的连续地形locomotion能力推到极致,可实现跳箱、翻越、夹缝行走等多种行为。两者均为本文重点分析的开源项目。
14. Visual Whole-Body Control for Legged Loco-Manipulation (UCSD, CoRL, 2024)
在宇树B1 + Z1机械臂上首次验证了基于视觉输入的、基于模仿学习和强化学习训练的双层策略、利用sim-to-real方式实现自动移动抓取任务的可行性。基于IsaacGym + rsl_rl开发,代码已开源。
15. PIE: Parkour with Implicit-Explicit Learning Framework for Legged Robots (ZJU, RAL, 2024)
跑酷运动的plus版本,进一步提高了四足机器人运动的动态能力,实现了在挑战环境中的高速运动并成功迁移到野外环境。本文第七节将详细分析其技术架构。
16. Expressive Whole-Body Control for Humanoid Robots (UCSD, RSS, 2024) & Exbody2 (2024)
基于motion sequence retargeting学习人形机器人的运动序列,实现了表达性丰富的全身控制。
- 论文:ExBody arxiv:2402.18294 / ExBody2 arxiv:2412.13196
17. Open-TeleVision: Teleoperation with Immersive Active Visual Feedback (UCSD, CoRL, 2024)
开源的基于VR人形机器人遥操作框架(上半身)。后续Mobile-TeleVision(arxiv:2412.07773)工作展示了全身控制方式,其中locomotion控制器结合了Exbody的方式。
18. HOVER: Versatile Neural Whole-Body Controller for Humanoid Robots (CMU, ICRA, 2025)
总结和统一了几种现有的人形机器人全身控制方式(root velocity tracking、joint angle tracking、key-point tracking等)。
19. HugWBC: A Unified and General Humanoid Whole-Body Controller for Fine-Grained Locomotion (SJTU+上海AI Lab, 2025)
在人形上实现了可细粒度调整步态的鲁棒locomotion策略,可控参数包括步态(走、跳、站、单脚跳)、步频、机身高度、俯仰角、触地时间、抬腿高度等。基于多项式足端轨迹引导的抬腿奖励引导出自然步态,利用上肢介入课程实现上肢自由控制,可作为可扩展的基础人形控制器。某种意义上是人形版的Walk These Ways。
20. Learning Humanoid Standing-up Control across Diverse Postures (上海AI Lab, RSS, 2025)
效果很好的倒地起身。同期另一篇 Learning Getting-Up Policies for Real-World Humanoid Robots(arxiv:2502.12152,UIUC, RSS, 2025)也解决了类似问题。
21. BeyondMimic: From Motion Tracking to Versatile Humanoid Control via Guided Diffusion (Berkeley+Stanford, 2025)
效果很好的motion tracking,调试和部署都做得不错。还包括一个guided diffusion做task-specific control at test time using simple cost functions。
3.2 四足深度视觉跑酷代表作
以下工作直接将深度视觉引入足式机器人跑酷或极限地形运动,是本文后续章节深度分析的核心对象。ETH 2022年的视觉locomotion工作(见3.1.1第4篇)为这些工作奠定了技术基础。
Extreme Parkour with Legged Robots (CMU, ICRA 2024)
由Xuxin Cheng等人提出,是四足机器人视觉跑酷的里程碑工作之一。该方法采用两阶段训练:第一阶段用地形扫描点(scandots)作为特权信息训练基础策略,第二阶段将前置深度相机的图像通过CNN编码器蒸馏到与scandots相同的隐空间。在宇树A1四足机器人上实现了跳箱(高度达机器人身高两倍)、跨越深沟(宽度达机器人体长两倍)、倒立、斜坡攀爬等极限动作。整个系统使用单一神经网络策略,从深度图像直接输出关节指令,无需人工遥操作。
Robot Parkour Learning (Stanford + 上海期智, CoRL 2024)
由Ziwen Zhuang等人提出,与Extreme Parkour同期发表。该方法同样基于深度相机的端到端视觉策略,但在训练策略上有所不同:采用了从软动力学约束(允许穿透障碍物)到硬动力学约束的渐进式训练方法。在低成本四足机器人上实现了攀爬、跳跃、匍匐、挤过窄缝等多种跑酷技能,且单一端到端策略可以在真实环境中自主选择和执行合适的跑酷动作。该工作获得了CoRL 2023最佳系统论文提名。
PIE: Parkour with Implicit-Explicit Learning Framework for Legged Robots (ZJU, RAL 2024)
由浙江大学团队提出,是DreamWaQ方法在跑酷场景下的重要拓展。PIE的核心创新在于提出了一种多头自编码器(multi-head auto-encoder)机制,将本体感知的历史观测和深度图像通过MLP编码器、CNN编码器和Transformer编码器进行跨模态融合,再经过GRU实现时序记忆,同时输出速度估计、足端离地高度、高度图显式估计和隐式环境变量四个头。这种隐式-显式双重估计机制使得低成本四足机器人能够在障碍物高度达自身三倍、间隙宽度达自身三倍的极限场景中完成跑酷,并成功实现了零样本sim-to-real迁移。
ANYmal Parkour (ETH, Science Robotics, 2024)
ETH提出的多层级跑酷框架(感知 + 导航 + 运动),首篇实现ANYmal动态跑酷。详见3.1.1第9篇。
WMP: World Model-based Perception for Visual Legged Locomotion (SJTU, 2024)
由上海交通大学团队提出,创新性地将世界模型(World Model)引入视觉足式运控。不同于直接将深度图像编码为隐变量的传统方法,WMP基于DreamerV3框架构建了一个环境世界模型,通过RSSM(循环状态空间模型)学习环境动态的内部表征。世界模型的确定性状态(200维)作为额外特征输入策略网络,同时结合AMP(对抗运动先验)保证运动自然性。该方法在仿真和真实环境中均超越了现有基线方法。
- 代码:https://github.com/wmp-loco(项目主页:https://wmp-loco.github.io/)
- 论文:https://arxiv.org/abs/2409.16784
3.3 人形深度视觉运控方向
Humanoid Parkour Learning (CoRL 2024)
由Ziwen Zhuang等人将四足跑酷的经验拓展到人形机器人,在CoRL 2024上发表。该工作将深度视觉跑酷的技术路线从四足延伸到了人形平台,面临的额外挑战包括更高的自由度、更复杂的平衡控制以及上肢协调。
VMTS: Vision-Assisted Teacher-Student RL for Multi-Terrain Locomotion in Bipedal Robots (2025)
针对双足机器人的视觉辅助教师-学生强化学习框架。该工作在PointFoot双足机器人上实现了基于深度视觉的多地形行走,采用了教师-学生架构配合深度编码器,支持MoE(混合专家)和PIE等多种策略架构。其特色在于使用Warp框架进行GPU加速的光线投射深度渲染,以及针对双足步态的精细化奖励设计。
- 代码:https://github.com/chenfu-user/VMTS(pointfoot-legged-gym)
- 论文:https://arxiv.org/abs/2503.07049
3.4 技术基础工作总结
以下表格汇总了为深度视觉跑酷提供关键技术基础的工作(详细介绍见3.1节):
| 工作 | 年份 | 来源 | 核心贡献 | 与深度视觉跑酷的关系 |
|---|---|---|---|---|
| Sim-to-Real Agile Locomotion | 2018 | RSS | RL+电机模型+DR的sim2real | 奠定四足RL运控基础 |
| Learning Agile Motor Skills | 2019 | ETH | 电机网络补偿+DR | ANYmal系列起点 |
| Teacher-Student Framework | 2020 | ETH | 教师-学生+DAgger蒸馏 | 蒸馏范式的源头 |
| Imitating Animals | 2020 | UCB | Motion Retargeting+DeepMimic | 动物运动模仿先驱 |
| AMP | 2021 | UCB | GAN隐式风格奖励 | 为跑酷自然运动提供先验 |
| IsaacGym+legged_gym | 2021 | ETH | GPU并行训练框架 | 所有后续工作的技术栈基础 |
| RMA | 2021 | CMU | 快速电机适应+adaptation module | Teacher-Student的CMU变体 |
| Periodic Reward Composition | 2021 | ICRA | 周期函数定义步态 | 双足步态设计参考 |
| Walk These Ways | 2022 | MIT | 细粒度步态可控locomotion | 步态切换参考 |
| Rapid Locomotion | 2022 | MIT | 速度自适应采样课程 | 课程学习设计参考 |
| AMP for Hardware | 2022 | UCB | AMP首次应用于四足 | WMP项目直接引用 |
| Concurrent Training | 2022 | KAIST | 非对称Actor-Critic框架 | PIE/DreamWaQ的框架基础 |
| Elevation Mapping | 2022 | ETH | GPU高效高程图构建 | 地形感知基础工具 |
| Perceptive Locomotion | 2022 | ETH | 深度相机估计高程图 | 视觉跑酷的直接前驱 |
| DreamWaQ | 2023 | KAIST | β-VAE隐式地形估计 | PIE的直接前驱 |
| AMP Agile Locomotion | 2023 | SJTU | AMP+复杂地形自然步态 | WMP的AMP方案参考 |
| DTC | 2024 | ETH | Model-based+Learning-based | 精确落足点控制思路 |
| HugWBC | 2025 | SJTU | 人形细粒度步态控制 | 人形版Walk These Ways |
3.5 开源项目间的引用关系
通过分析三个核心开源项目的代码和致谢,可以清晰看到技术传承脉络:
ETH legged_gym + rsl_rl (2021)
├── Extreme Parkour (CMU, 2024)
│ └── 被 WMP 致谢引用
├── WMP (SJTU, 2024)
│ ├── 引用 dreamerv3-torch (NM512)
│ ├── 引用 AMP_for_hardware (UCB)
│ └── 引用 Robot Parkour Learning (ZiwenZhuang)
└── VMTS (2025)
├── 支持 PIE 架构(来自 ZJU)
└── 支持 MoE 架构
这一引用关系图揭示了几个重要事实:(1)ETH的legged_gym是整个生态的根基,三个项目均基于此构建;(2)WMP是引用最广泛的项目,融合了DreamerV3、AMP和Parkour三条技术线;(3)VMTS作为最新的工作,集成了PIE等前沿架构,代表了该领域的最新技术整合趋势。
更完整的论文列表可参考:awesome-rl-for-legged-locomotion
4. 开源项目深度分析:Extreme Parkour
4.1 整体架构
Extreme Parkour项目由CMU的Xuxin Cheng等人开发,基于ETH的legged_gym + rsl_rl框架构建,针对宇树A1四足机器人。项目的核心设计思想是将视觉跑酷问题分解为两个阶段:先用特权信息训练一个强大的基础策略,再通过知识蒸馏将视觉编码器对齐到特权编码器的隐空间。
项目目录结构如下:
extreme-parkour/
legged_gym/ # 仿真环境、地形生成、奖励函数
envs/ # 环境定义与配置
scripts/ # 训练、推理、模型导出脚本
utils/ # 地形生成工具
rsl_rl/ # RL训练算法与网络结构
algorithms/ # PPO算法实现
modules/ # Actor-Critic、深度编码器
runners/ # 训练循环管理
4.2 两阶段训练流程
第一阶段:基础策略训练(scandots)
基础策略使用132维的地形扫描点(scandots)作为特权地形感知输入。这些扫描点是在机器人周围12x11的网格上直接采样的地形高度值,覆盖范围为前方1.2米、两侧各0.75米。扫描点通过一个专用的Scan Encoder编码为32维隐变量:
# Scan Encoder 结构(rsl_rl/modules/actor_critic.py)
# 输入: 132维 scandots
# 网络: 132 -> 256 -> 256 -> 256 -> 32 (Tanh激活)
# 输出: 32维隐变量 scan_latent
Actor网络的完整输入由四部分拼接而成:本体观测(53维)、scan_latent(32维)、显式特权信息(3维:地形等级、摩擦系数、基座质量)和隐式特权隐变量(4维)。Actor输出12维动作,对应A1四足机器人的12个关节目标角度。
训练命令:
python train.py --exptid xxx-xx-DESCRIPTION --device cuda:0
# 训练10-15k迭代,RTX 3090上约8-10小时
# 6144个并行环境,每步32个时间步 = 196,608个transition/batch
第二阶段:深度蒸馏训练(camera)
第二阶段冻结基础策略的Actor权重,训练一个深度编码器将前置深度相机的图像映射到与Scan Encoder相同的32维隐空间。深度编码器的架构分为两层:
# 深度CNN骨干网络(rsl_rl/modules/depth_backbone.py)
# DepthOnlyFCBackbone58x87:
# Conv2d(1, 32, kernel=5) -> MaxPool2d(2) -> ELU
# Conv2d(32, 64, kernel=3) -> ELU -> Flatten
# Linear(64*25*39, 128) -> ELU
# Linear(128, 32)
# 输出: 32维深度特征
# 循环深度骨干网络(RecurrentDepthBackbone):
# [深度特征(32) + 本体观测(53)] -> MLP(128 -> 32)
# -> GRU(input=32, hidden=512)
# -> MLP(512 -> 34) # 32维隐变量 + 2维辅助输出
# -> Tanh
蒸馏损失函数的核心是让深度编码器的输出逼近scandots编码器的输出:
# 蒸馏损失(rsl_rl/algorithms/ppo.py)
depth_encoder_loss = ||scandots_latent - depth_latent||_2
训练命令:
python train.py --exptid yyy-yy-DESCRIPTION --device cuda:0 \
--resume --resumeid xxx-xx --delay --use_camera
# 训练5-10k迭代,RTX 3090上约5-10小时
4.3 深度相机处理流水线
深度图像在仿真中的获取和处理经过以下步骤:
IsaacGym GPU相机渲染 (106x60原始分辨率)
-> 裁剪边缘 (左右各30px, 底部2px)
-> 双三次插值缩放至 87x58
-> 深度范围裁剪 [0, 2m]
-> 归一化: (depth - near) / (far - near) - 0.5
-> 2帧堆叠 (时序信息)
相机配置参数:
# 相机安装位置: [0.27, 0, 0.03] (机器人前方)
# 俯仰角范围: [-5°, 5°]
# 水平视场角: 87°
# 更新频率: 每5个控制步更新一次
4.4 地形系统与奖励设计
Extreme Parkour的地形系统是其成功的关键因素之一。项目定义了19种地形类型,其中跑酷相关地形占80%的比例:
跑酷地形分布:
hurdle (跨栏): 20%
flat (平地): 20%
step (台阶): 20%
gap (间隙): 20%
其他地形: 20%
地形采用课程学习(Curriculum Learning)机制,共10个难度等级,40列不同地形变体。机器人根据表现自动升降难度等级。
奖励函数的设计兼顾了目标跟踪和运动质量两个维度:
# 核心奖励项及权重
tracking_goal_vel = 1.5 # 朝目标方向的速度跟踪
tracking_yaw = 0.5 # 朝向跟踪
lin_vel_z = -1.0 # 抑制垂直方向速度振荡
ang_vel_xy = -0.05 # 抑制横滚/俯仰角速度
collision = -10.0 # 碰撞惩罚(非足部接触)
action_rate = -0.1 # 动作平滑性
feet_edge = -1.0 # 足端踩在边缘的惩罚
dof_error = -0.04 # 关节偏离默认位置的惩罚
值得注意的是,项目使用了"仅保留正奖励"(only_positive_rewards=True)的策略,将负的总奖励裁剪为零,避免了早期终止导致的训练不稳定问题。
4.5 Domain Randomization
为缩小sim-to-real gap,项目实施了全面的域随机化:
# 域随机化参数
friction_range = [0.6, 2.0] # 摩擦系数
added_mass_range = [0., 3.] kg # 额外质量
added_com_range = [-0.2, 0.2] m # 质心偏移
motor_strength_range = [0.8, 1.2] # 电机力矩系数
push_interval = 8s # 外部推力间隔
max_push_vel = 0.5 m/s # 最大推力速度
此外,第二阶段训练中引入了渐进式动作延迟(action delay),从0步逐渐增加到5步,模拟真实部署中的通信和计算延迟。
5. 开源项目深度分析:WMP
5.1 核心思想:用世界模型替代蒸馏
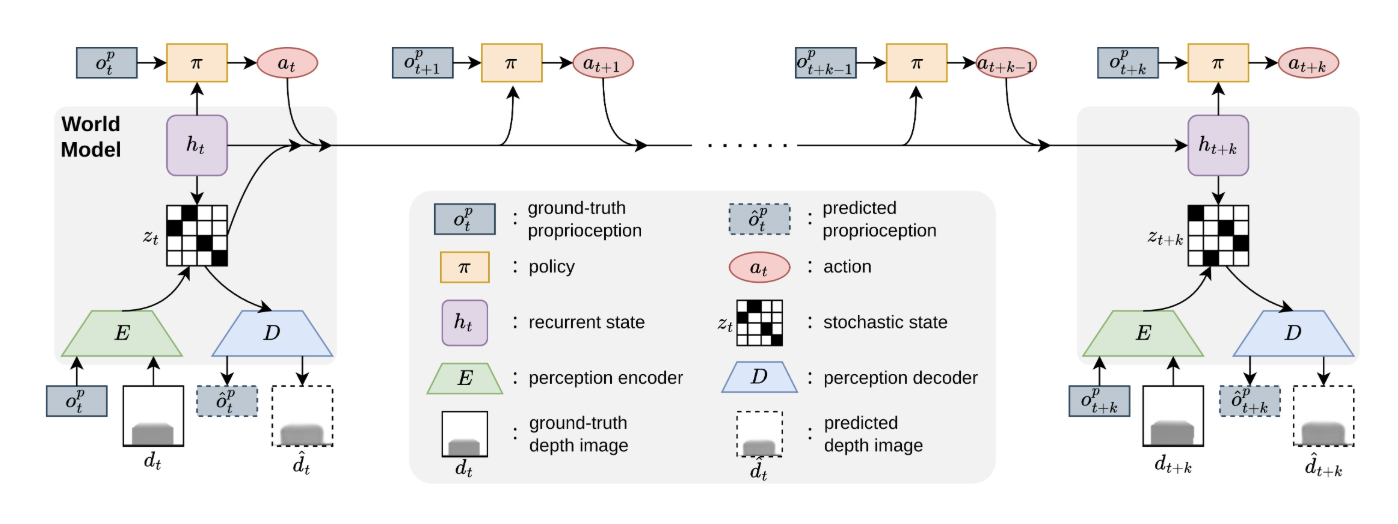
WMP(World Model-based Perception)的设计哲学与Extreme Parkour截然不同。Extreme Parkour采用"先用特权信息训练,再蒸馏到视觉"的两阶段范式,而WMP则提出了一个更为根本的问题:能否让机器人像动物一样,通过建立对环境的内部模型来学习运动策略?
传统的教师-学生蒸馏方法存在一个固有的"信息瓶颈"——学生策略的性能上限受限于蒸馏过程中的信息损失。WMP通过引入世界模型绕过了这一瓶颈:世界模型直接从深度图像和本体感知中学习环境动态的内部表征,策略网络则基于这一表征做出决策。
5.2 项目架构
WMP项目在legged_gym + rsl_rl的基础上增加了dreamer模块,形成了三模块协同的架构:
WMP/
legged_gym/ # 仿真环境(基于A1四足机器人)
envs/a1/ # A1环境配置与AMP集成
scripts/ # 训练与可视化脚本
dreamer/ # 世界模型(基于DreamerV3)
models.py # WorldModel类定义
networks.py # RSSM、编码器、解码器网络
configs.yaml # 世界模型超参数
rsl_rl/ # RL算法与策略网络
runners/wmp_runner.py # WMP专用训练循环
modules/actor_critic.py # ActorCriticWMP策略
modules/depth_predictor.py # 深度预测辅助任务
algorithms/amp_discriminator.py # AMP判别器
datasets/ # AMP运动捕捉数据
5.3 世界模型的构建与训练
WMP的世界模型基于DreamerV3的RSSM(Recurrent State Space Model)架构,但针对足式运控场景做了适配。世界模型的核心组件包括:
# 世界模型架构(dreamer/models.py)
# 输入观测空间:
# prop: (33,) -- 本体感知(关节位置/速度、基座状态)
# image: (64, 64, 1) -- 深度图像
# RSSM参数:
# dyn_deter = 200 -- 确定性状态维度(输出给策略的特征)
# dyn_stoch = 32 -- 随机状态维度
# dyn_hidden = 200 -- 隐藏层维度
# dyn_discrete = False -- 使用连续隐变量
# 编码器: MultiEncoder
# 本体感知分支: MLP(33 -> hidden -> feature)
# 深度图像分支: CNN(64x64x1 -> feature)
# 解码器: 从隐状态重建观测
# 奖励头: 从隐状态预测任务奖励
世界模型的训练与策略训练交替进行。在每个训练迭代中,世界模型首先从收集到的轨迹数据中学习环境动态,然后策略网络利用世界模型提供的200维确定性状态特征作为额外输入来更新策略。
5.4 策略网络与AMP集成
WMP的策略网络(ActorCriticWMP)在标准Actor-Critic基础上增加了世界模型特征的处理通道:
# ActorCriticWMP 网络结构
# Actor输入: 历史观测(5步) + 世界模型特征(200维)
# 编码器: [256, 128] hidden dims
# WM编码器: [64, 64] hidden dims
# Actor主干: [256, 128, 64] -> 12维动作
# Critic输入: 特权观测(含真实高度图和接触力)
# Critic主干: [512, 256, 128] -> 1维价值估计
AMP(Adversarial Motion Prior)的集成是WMP的另一个重要特色。AMP判别器从运动捕捉数据中学习自然运动的分布,为策略提供风格奖励,确保机器人在执行跑酷动作时保持自然的运动姿态:
# AMP配置(a1_amp_config.py)
amp_reward_coef = 0.5 * 0.02 # AMP奖励系数
amp_task_reward_lerp = 0.3 # 任务奖励与AMP奖励的混合比例
amp_discr_hidden_dims = [1024, 512] # 判别器隐藏层
amp_replay_buffer_size = 1000000 # 经验回放缓冲区
amp_num_preload_transitions = 2000000 # 预加载的运动数据量
训练命令:
python legged_gym/scripts/train.py --task=a1_amp --headless --sim_device=cuda:0
# 训练约23GB GPU显存,建议至少10k迭代
5.5 深度预测器:辅助任务
WMP还引入了一个深度预测器(Depth Predictor)作为辅助训练任务。该模块从本体感知状态预测深度图像,其目的是增强本体感知编码器对环境几何信息的敏感性:
# 深度预测器配置
learning_rate = 3e-4
training_interval = 10 # 每10个迭代训练一次
training_iterations = 1000 # 每次训练1000步
batch_size = 1024
loss_scale = 100
5.6 数据流总览
WMP的完整数据流可以概括为:
IsaacGym仿真 (4096并行环境)
|
v
观测: [本体感知(33) + 特权信息(53) + 高度图(187) + 动作(12)]
深度相机: 64x64深度图像 (每5步更新)
|
v
世界模型编码器: 本体感知 + 深度图 -> 隐状态
RSSM: 生成200维确定性状态特征
|
v
策略网络: 历史观测 + WM特征 -> 12维关节动作
Critic: 特权观测 -> 价值估计
AMP判别器: 评估运动自然性 -> 风格奖励
|
v
PPO + AMP联合损失 -> 更新策略
深度预测器: 本体感知 -> 预测深度图 (辅助任务)
6. 开源项目深度分析:VMTS
6.1 从四足到双足:新的挑战
VMTS(Vision-assisted Multi-Task Student)是2025年发表的工作,将深度视觉辅助的强化学习运控从四足机器人拓展到了双足(PointFoot)机器人。双足机器人相比四足面临更严峻的平衡控制挑战:支撑多边形更小、重心更高、步态周期中存在单腿支撑相,这些因素使得策略对环境感知的精度要求更高。VMTS的核心贡献在于设计了一套适配双足机器人的视觉辅助教师-学生框架,并支持多种策略架构的灵活切换。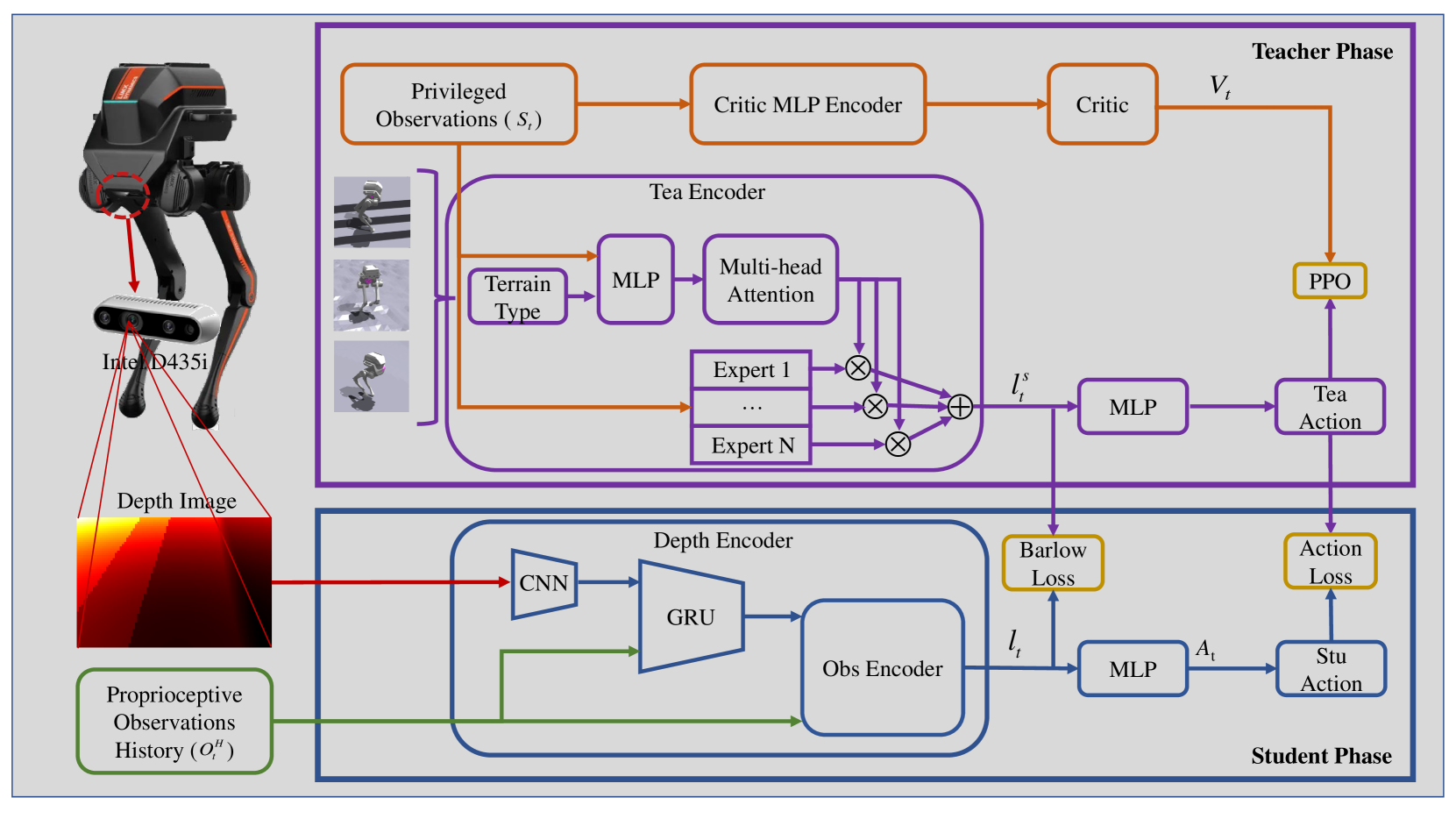
6.2 项目架构与策略类型
VMTS基于pointfoot-legged-gym框架构建,支持四种策略架构:
pointfoot-legged-gym/
legged_gym/
envs/pointfoot/
point_foot.py # 主环境(含深度视觉集成)
reward.py # 30+奖励函数
flat/pointfoot_flat_config.py # 平地配置
mixed_terrain/pointfoot_rough_config.py # 复杂地形配置
scripts/
train.py # 训练入口
play.py # 推理(支持教师/学生/深度切换)
export_policy_as_onnx.py # ONNX导出
四种策略架构各有侧重:
- ActorCriticTS:标准教师-学生架构,教师使用特权观测,学生使用本体感知历史
- ActorCriticMoe:混合专家(Mixture of Experts)架构,多个专家网络处理不同地形
- ActorCriticMoeS:MoE的学生版本
- ActorCriticPie:集成PIE隐式-显式估计机制的架构
6.3 深度视觉的Warp渲染
VMTS的一个技术特色是使用NVIDIA Warp框架进行GPU加速的光线投射深度渲染,而非IsaacGym内置的相机渲染。Warp渲染的优势在于更高的灵活性和更低的延迟:
# 深度渲染配置
# 分辨率: 58 x 87 像素
# 渲染方式: Warp GPU光线投射(ray casting)
# 深度缓冲: [num_envs, history_frames, 58, 87]
# 图像处理: torchvision BICUBIC插值缩放
深度编码器将58x87的深度图像编码为121维隐变量,该隐变量与本体感知观测拼接后输入策略网络:
# 推理时的深度处理流程(play.py)
depth_image = env.depth_buffer[:, -2] # 取倒数第二帧
depth_latent = depth_encoder(depth_image, student_obs[:, -29:])
# depth_latent: 121维
actions = policy_depth(combined_obs, depth_latent)
depth_encoder.detach_hidden_states() # 清除RNN隐状态
6.4 双足步态奖励设计
VMTS针对双足机器人设计了超过30个奖励函数,其中步态相关的奖励尤为精细。双足行走的核心难点在于步态周期的稳定性——机器人需要在单腿支撑相和双腿支撑相之间平滑切换,同时保持重心在支撑多边形内。
# 步态相关核心奖励(reward.py)
_reward_feet_contact_number() # 足端接触数与步态相位对齐
_reward_feet_air_time() # 摆动腿离地时间约束
_reward_target_feet_height() # 抬腿高度跟踪(随步态周期变化)
_reward_no_fly() # 禁止双脚同时离地
# 足端放置奖励
_reward_feet_alignment_x() # 横向足端对齐
_reward_feet_alignment_y() # 纵向足端对齐
# 运动平滑性奖励
_reward_action_rate() # 动作变化率惩罚
_reward_action_smoothness() # 动作加速度惩罚
_reward_dof_acc() # 关节加速度惩罚
步态相位通过正弦函数生成参考接触模式,目标抬腿高度随步态周期在0到最大值之间变化,周期约0.5秒。这种基于相位的步态生成方式避免了手工设计步态状态机的复杂性。
6.5 三个项目的对比总结
| 特性 | Extreme Parkour | WMP | VMTS |
|---|---|---|---|
| 机器人平台 | 宇树A1(四足) | 宇树A1(四足) | PointFoot(双足) |
| 视觉方案 | scandots蒸馏到深度 | 世界模型+深度 | 教师-学生+深度 |
| 训练阶段 | 两阶段 | 单阶段(交替训练) | 两阶段 |
| 深度编码器 | CNN+GRU | DreamerV3 RSSM | CNN+RNN |
| 运动先验 | 无 | AMP | 无/可选PIE |
| 深度分辨率 | 87x58 | 64x64 | 58x87 |
| 隐变量维度 | 32 | 200(WM)+32 | 121 |
| 并行环境数 | 6144 | 4096 | 4096 |
7. PIE框架详解:隐式-显式双重估计
7.1 设计动机
PIE(Parkour with Implicit-Explicit Learning Framework)的设计出发点是一个实际观察:在跑酷场景中,机器人需要在接近障碍物边缘时做出精确判断,而深度相机在边缘区域的测量恰恰最不可靠——存在严重的噪声、遮挡和延迟。如果策略完全依赖深度图像的显式地形重建,那么在最关键的决策时刻反而最容易失败。
PIE的解决方案是同时维护两套估计:显式估计直接重建高度图,提供可解释的地形几何信息;隐式估计通过VAE学习一个压缩的环境表征,捕捉那些难以显式建模的环境特性(如摩擦、地形材质、动态障碍物等)。两套估计互为补充,共同输入策略网络。
7.2 网络架构
PIE采用与DreamWaQ相同的非对称Actor-Critic框架,但在估计器(Estimator)的设计上做了根本性的改进。整个系统由策略网络、价值网络和多头自编码器三部分组成。
策略网络(Actor) 的输入由四个分量拼接而成:
策略输入 = [本体观测 o_t (45维),
速度估计 v_hat_t (3维),
高度图显式估计 z_t^m (低维压缩),
隐式环境变量 z_t (隐变量维度)]
输出: 12维关节目标角度
其中本体观测包含身体角速度(3维)、本体坐标系下的重力矢量(3维)、速度指令(3维)、关节位置(12维)、关节角速度(12维)和上一帧动作(12维)。
价值网络(Critic) 在训练时使用特权观测,包括本体观测、真实线速度和真实高度图扫描点:
Critic输入 = [本体观测 o_t, 真实线速度 v_t, 真实高度图 m_t]
输出: 状态价值估计 V(s)
7.3 多头自编码器:PIE的核心创新
PIE最关键的技术贡献是其多头自编码器(Multi-Head Auto-Encoder)。该模块负责从本体感知历史和深度图像中同时提取显式和隐式的环境表征。理解这一模块的设计逻辑,是理解PIE整体架构的关键。
编码器(Encoder) 的输入包括两个模态:历史本体观测序列(H2=10个时间步)和历史深度图像序列(H1=2帧)。两个模态分别通过各自的特征提取器处理后,再通过Transformer编码器进行跨模态融合: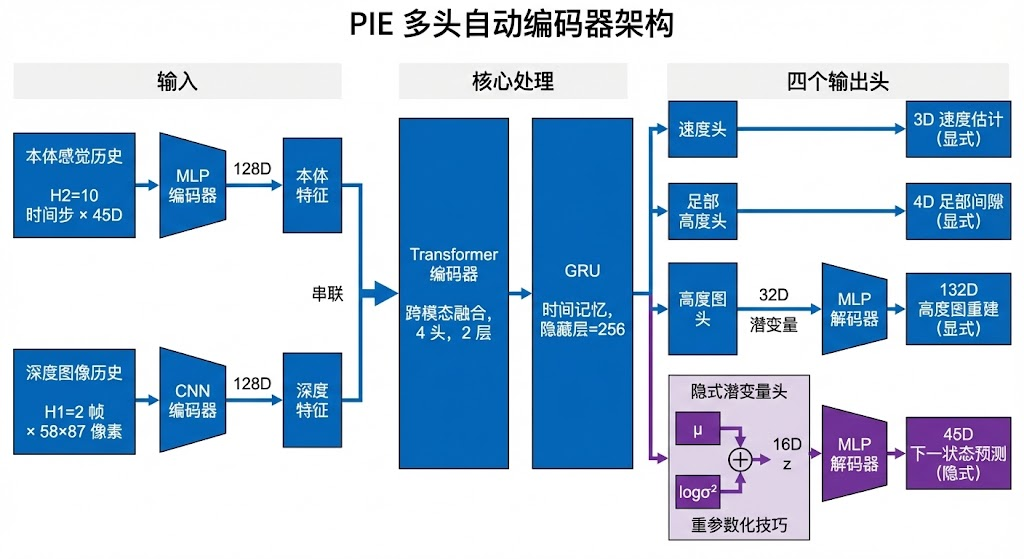
这里的设计有几个值得注意的细节。
首先,CNN编码器处理的是原始深度图像而非预处理后的高度图,这意味着网络需要自行学习从透视深度图中提取地形几何信息。这一设计选择的背后逻辑是:高度图的构建本身就是一个有损过程,直接从深度图学习可以保留更多原始几何信息。
其次,Transformer编码器的引入使得本体感知和视觉感知之间可以进行双向的注意力交互——本体感知可以"询问"视觉信息中与当前运动状态相关的部分,视觉信息也可以利用本体感知来消歧。具体而言,当机器人正在执行跳跃动作时,本体感知中的高角速度和关节加速度信号会引导注意力机制关注深度图像中的着陆区域;反过来,当深度图像检测到前方有深沟时,视觉特征会通过注意力机制影响本体感知的编码,使其更关注与跳跃准备相关的状态量。
最后,GRU层赋予了整个估计器时序记忆能力,使其能够在深度图像暂时不可用或严重噪声时,依靠历史信息维持合理的估计。这一点在实际部署中尤为重要——深度相机在快速运动时容易产生运动模糊,在强光或反射表面上容易失效,GRU的记忆机制为这些退化场景提供了鲁棒性保障。
解码器(Decoder) 包含四个解码头,分别对应显式和隐式两类估计:
- 地形显式估计头:将 z_t^m 通过MLP解码器重建高维高度图 m_t。这是最直接的地形感知输出,策略网络可以据此判断前方障碍物的几何形态
- 状态隐式估计头:将GRU的完整隐状态通过MLP解码器预测下一步本体观测 o_{t+1}。这一预测任务迫使隐式表征捕捉环境动态——只有理解了地形的物理特性(摩擦、弹性、坡度等),才能准确预测机器人在该地形上的下一步状态
- 速度显式估计头:直接输出线速度估计 v_hat_t(3维),为策略提供当前运动状态的精确反馈
- 足端高度显式估计头:输出各足端离地高度 h_hat_t^f(4维,对应四条腿),为精确的落足点控制提供依据
这四个头的设计体现了PIE的核心哲学:显式估计提供可解释、可直接使用的物理量(高度图、速度、足端高度),隐式估计则通过预测任务学习那些难以直接测量的环境特性。两者互为补充,共同构成策略决策的信息基础。
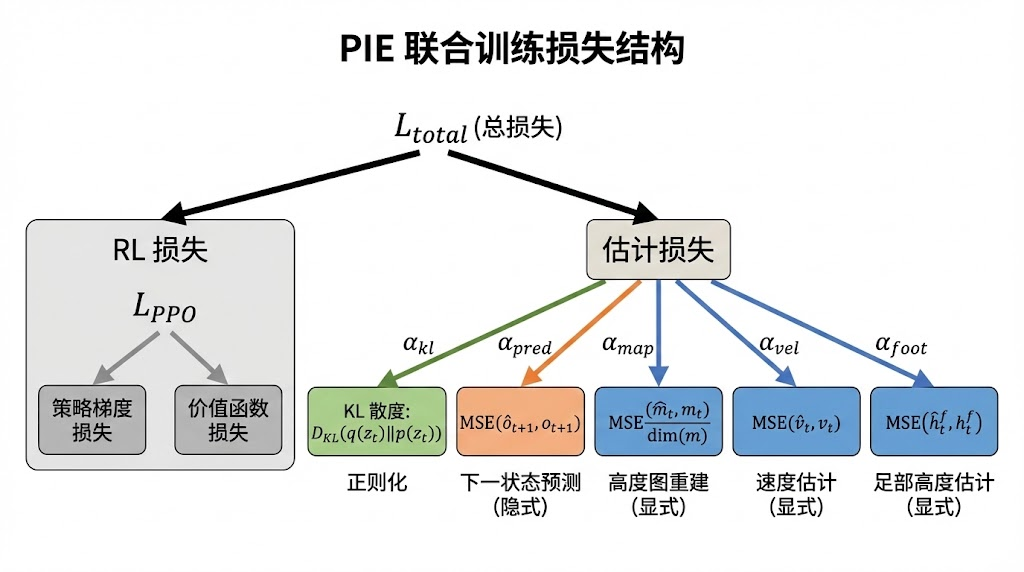
7.4 训练损失函数
PIE的总损失函数由五项组成,体现了VAE框架下显式与隐式估计的联合优化:
L = D_KL(q(z_t | o_t^H1, d_t^H2) || p(z_t)) # KL散度正则化
+ MSE(o_hat_{t+1}, o_{t+1}) # 下一步状态预测损失
+ MSE(m_hat_t, m_t) # 高度图重建损失
+ MSE(v_hat_t, v_t) # 速度估计损失
+ MSE(h_hat_t^f, h_t^f) # 足端高度估计损失
各项损失的作用机制如下:
KL散度项约束隐变量 z_t 的后验分布 q(z_t | o_t^H1, d_t^H2) 接近标准正态先验 p(z_t) = N(0, I)。这一正则化有两个目的:一是防止隐空间退化为确定性映射(即编码器忽略输入直接输出固定值),二是保证隐空间的连续性和平滑性,使得相似的环境状态被映射到隐空间中相近的区域。PIE采用beta-VAE的思路,通过一个可调的beta系数控制KL项的强度——权重过大会导致posterior collapse,权重过小则失去正则化效果。
下一步状态预测损失 MSE(o_hat_{t+1}, o_{t+1}) 是驱动隐式估计学习的核心。这一损失要求GRU的隐状态必须包含足够的环境动态信息,才能准确预测机器人在当前地形上的下一步状态。例如,在高摩擦地面上机器人的减速更快,在弹性地面上着地后会有反弹,在斜坡上重力分量会导致侧向漂移。这些物理特性无法通过高度图显式表达,但会直接影响下一步状态,因此隐式估计被迫学习这些信息。
高度图重建损失 MSE(m_hat_t, m_t) 驱动显式地形估计的学习。需要注意的是,高度图的维度通常在100-200之间,其MSE的量级远大于3维速度估计的MSE。因此在实际训练中,需要对各项损失进行归一化或加权。一种常见的做法是将高度图重建损失除以高度图维度,使其与其他损失项在同一量级。
速度估计损失和足端高度估计损失则提供了直接可用的物理量监督,量级较小但梯度信号清晰,有助于在训练早期快速建立有意义的表征。
这五项损失与PPO的策略梯度损失联合优化,完整的训练目标可以写为:
L_total = L_PPO(策略梯度 + 价值函数)
+ alpha_kl * D_KL(q || p)
+ alpha_pred * MSE(o_hat_{t+1}, o_{t+1})
+ alpha_map * MSE(m_hat_t, m_t) / dim(m)
+ alpha_vel * MSE(v_hat_t, v_t)
+ alpha_foot * MSE(h_hat_t^f, h_t^f)
…详情请参照古月居

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 15
15 0
0- 0



 已为社区贡献69条内容
已为社区贡献69条内容

所有评论(0)