《VLA 系列》汇总分析 | 自回归离散预测 | 扩散模型 | 流匹配
本文分析了VLA(视觉-语言-动作)模型的三大范式:自回归离散预测、扩散模型和流匹配。自回归离散预测(如RT-2、OpenVLA)推理简单但存在误差累积和串行推理慢的问题;扩散模型(如Octo、Dream-VLA)并行生成且抗长程误差,但计算成本高;流匹配(如π₀系列)结合了扩散的全局建模优势和高效训练/采样特性,是当前VLA连续动作生成的前沿方向。文章梳理了各类范式的代表性模型、最新进展和高性能
本文汇总分析VLA常见的三类范式——自回归离散预测、扩散模型、流匹配,分别梳理其代表性模型、最新模型、高性能模型、SOTA模型,并附核心特点与发布/进展时间,便于快速对比。
- 🐳
自回归离散:推理简单、语言理解强;但误差累积、串行推理慢、高频/连续动作不友好 - ⌚️
扩散模型:并行、全局一致性、抗长程误差;但采样步骤多、计算成本高、推理延迟 - 🚀
流匹配:兼具扩散全局建模+更高效训练/采样、平滑连续动作、适配高频控制;是当前VLA连续动作生成的前沿方向
一、自回归离散预测 VLA
核心机制:将连续动作离散化为token,以左到右自回归方式逐token预测,复用VLM的下一个token预测(NTP)目标,实现端到端训练
| 模型名称 | 论文全称 | 开源地址 | 核心定位 |
|---|---|---|---|
| RT-2 | RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control |
项目页:https://robotics-transformer2.github.io/ | VLA奠基之作,将互联网规模VLM知识迁移至机器人控制,实现涌现的语义推理与符号理解(CoRL 2023,Google DeepMind) |
| OpenVLA (7B) | OpenVLA: An Open-Source Vision-Language-Action Model |
GitHub: https://github.com/openvla/openvla 项目页: https://openvla.github.io/ |
开源通用VLA基座,基于Llama 2+CLIP自回归生成离散动作token,97万真实演示训练,支持跨本体零样本(斯坦福/伯克利等) |
| π₀-FAST | FAST: Efficient Action Tokenization for Vision-Language-Action Models |
GitHub: https://github.com/Physical-Intelligence/openpi | π₀自回归变体,采用FAST动作分词将连续动作编码为离散token序列,兼容π0接口(Physical Intelligence) |
1. 代表性模型
- RT-2:谷歌DeepMind,VLA奠基之作,将机器人动作离散化为token,融入PaLM-E等VLM,实现基础视觉-语言-动作闭环(CoRL 2023)
OpenVLA:斯坦福等2024,基于Prismatic-7B/Llama 2,融合DINOv2+SigLIP视觉特征,在97万真实机器人演示上训练,开源通用VLA基座标杆
2. 最新模型(2025下半年-2026初)
- π₀-FAST:Physical Intelligence 2025,在π₀基础上引入FAST动作分词,将连续动作编码为离散token序列,兼容π0接口,提升自回归动作生成效率
3. 高性能模型
- OpenVLA 7B:开源标杆,在BridgeData、Language-Table等机器人基准上性能优异,支持参数高效微调(LoRA/QLoRA),适配多机械臂
- RT-2 (fine-tuned):持续迭代优化,在真实场景指令跟随、长程任务中保持高可靠性,具备涌现的语义推理能力
二、扩散模型 VLA
核心机制:将动作视为连续信号/离散token序列,通过迭代去噪生成;并行生成、全局优化、抗误差累积,适合长程规划、轨迹级动作
| 模型名称 | 论文全称 | 开源地址 | 核心定位 |
|---|---|---|---|
| Octo | Octo: An Open-Source Generalist Robot Policy | GitHub: https://github.com/octo-models/octo | 基于Transformer的通用机器人策略,采用Diffusion Head生成动作,支持多机器人平台与灵活任务微调(93M参数,伯克利等) |
| Dream-VLA | Dream-VL & Dream-VLA: Open Vision-Language and Vision-Language-Action Models with Diffusion Language Model Backbone |
GitHub: https://github.com/DreamLM/dream-vlx 项目页: https://dreamlm.github.io/dream/ |
基于离散扩散LLM骨干,实现长时规划与复杂任务推理(港大/华为) |
| LLaDA-VLA | LLaDA-VLA: Vision Language Diffusion Action Models |
GitHub: https://github.com/wenyuqing/llada-vla | 基于掩码扩散(Masked Diffusion)的层级轨迹预测,优化动作一致性 |
| DiVLA | DiffusionVLA: Scaling Robot Foundation Models via Unified Diffusion and Autoregression | GitHub: https://github.com/juruobenruo/DexVla | 扩散+自回归混合:自回归推理规划,扩散策略生成动作,平衡语言理解与连续控制(北大) |
| HybridVLA | HybridVLA: Collaborative Diffusion and Autoregression in a Unified Vision-Language-Action Model | GitHub: https://github.com/PKU-HMI-Lab/Hybrid-VLA | 扩散+自回归协作:单模型内扩散负责动作生成、自回归负责语义推理,缓解模态断裂(北大) |
1. 代表性模型
- Octo:伯克利等2024,基于Transformer的通用机器人策略,采用Diffusion Head生成动作(非自回归),支持多机器人平台与灵活任务微调(93M参数)
LLaDA-VLA:2025,首个大语言扩散模型(LLaDA)拓展的VLA,掩码扩散+层级动作解码,改善轨迹一致性- Dream-VLA (Dream-7B):港大/华为2025,离散扩散LLM+视觉对齐,双向上下文、并行生成,长时规划领域代表
- DiVLA (DiffusionVLA):北大2025,扩散+自回归混合:自回归推理规划,扩散策略生成动作,引入推理注入模块平衡语言理解与连续控制
2. 最新模型(2025下半年-2026初)
- HybridVLA:北大2025,融合自回归与扩散生成于单模型、统一token序列,单模型内扩散负责动作生成、自回归负责语义推理,缓解动作连续性断裂问题
- WAM-Diff:复旦2025,端到端自动驾驶VLA,离散掩码扩散+MoE+在线RL优化,提升全局一致性与长时规划性能
3. 高性能模型
- Dream-VLA:长程轨迹、全局一致性任务表现突出,在多模态指令跟随、多步操作中降低误差累积
- LLaDA-VLA:在SimplerEnv、CALVIN仿真、WidowX真实机械臂上性能领先,优于OpenVLA等自回归模型
4. SOTA模型
- 掩码扩散路线:LLaDA-VLA
- 离散扩散路线:Dream-VLA
- 混合范式:DiVLA(兼顾语言推理与连续动作鲁棒性)、HybridVLA(单模型内双范式协作)
三、流匹配(Flow Matching) VLA
核心机制:学习连续速度场,将高斯噪声平滑映射到目标动作分布;相较扩散训练更简单(单MSE损失)、采样效率更高(更少步骤);
本质是扩散的数学推广,建模连续动作、适合高频控制
| 模型名称 | 论文全称 | 开源地址 | 核心定位 |
|---|---|---|---|
| π₀ (pi0) | π₀: A Vision-Language-Action Flow Model for General Robot Control |
GitHub: https://github.com/Physical-Intelligence/openpi | 首个流匹配VLA,基于PaliGemma,50Hz高频动作块生成,支持复杂灵巧操作(Physical Intelligence) |
| π₀.5 | π₀.5: A Vision-Language-Action Model with Open-World Generalization |
GitHub: https://github.com/Physical-Intelligence/openpi | π₀升级,多源异构数据协同训练,实现开放世界泛化与长时精细操控(CoRL 2025) |
| π₀.6 | π*₀.6: Reinforced Flow Matching for Complex Dexterous Manipulation (Model Card) | (没开源)技术报告:https://pi.website/blog/pistar06 | 基于π0.5的增强版,采用RECAP框架(离线RL+在线RL+人类纠正),当前流匹配路线综合SOTA(Physical Intelligence) |
| AsyncVLA | AsyncVLA: Asynchronous Flow Matching for Vision-Language-Action Models | GitHub: https://github.com/yuhuajiang2002/asyncvla | 异步流匹配架构,解耦感知-预测与动作执行,实现自校正与更高控制频率(上海AI Lab) |
| πRL | πRL: Online Reinforcement Learning for Flow-based Vision-Language-Action Models |
GitHub:https://github.com/RLinf/RLinf | 首个在线RL微调流式VLA(π0/π0.5)框架,提出Flow-Noise与Flow-SDE两种方法实现精确对数似然估计,突破模仿学习局限(清华) |
| SmolVLA | SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics | GitHub: https://github.com/huggingface/lerobot | 轻量级VLA(450M参数),基于流匹配动作专家,单GPU可训练、CPU可部署,支持异步推理(Hugging Face开源) |
| DM0 | DM0: Embodied Spatial Reasoning Enhanced Flow Matching VLA | GitHub: https://github.com/Dexmal/dexbotic | 具身空间推理增强,构建四层分层辅助预测目标(子任务→BBox→轨迹→离散动作)形成空间思维链,支持操作与导航 |
1. 代表性模型
π₀ (pi0):Physical Intelligence 2025,首个流匹配VLA;基于PaliGemma,VLM主干+流匹配动作头,50Hz高频、动作块并行生成;摒弃离散token,直接建模连续动作,适配灵巧操作- SmolVLA:Hugging Face 2025,轻量级VLA(450M参数),基于流匹配动作专家,单GPU可训练、CPU可部署,支持异步推理,兼顾通用多模态能力与具身控制
2. 最新模型(2025下半年-2026初)
- π₀.5:Physical Intelligence 2025年4月,π₀升级;多源异构数据协同训练、分层决策、开放世界泛化显著提升,支持10-15分钟长时精细操控(CoRL 2025)
- π*₀.6 (RECAP增强版):Physical Intelligence 2025年11月;基于π0.5采用RECAP框架(离线RL+在线RL+人类纠正),解决流模型无显式log概率梯度难更新问题;意式浓缩咖啡、衣物折叠等复杂任务表现优异,暂未完全开源
- AsyncVLA:上海AI Lab 2025年末,异步流匹配,解耦感知-预测与动作执行,选择性动作再生、异步时间嵌入;自校正优化,刷新机器人操作SOTA
- DiG-Flow:北大等2025末,差异引导流匹配(Discrepancy-Guided),通过不匹配信号增强特征表示,提升分布偏移、复杂多步任务下的鲁棒性
- πRL:清华2026初,首个在线RL微调流式VLA(π0/π0.5)框架,提出Flow-Noise与Flow-SDE两种方法实现精确对数似然估计,突破模仿学习局限
- DM0:Dexmal 2026初,具身空间推理增强流匹配VLA,构建四层分层辅助预测目标(子任务→BBox→轨迹→离散动作)形成空间思维链,支持操作与导航双任务
3. 高性能模型
- π₀.5:兼顾全局一致性与高频执行,适配7种机械臂、开放场景零样本泛化
- π*₀.6:当前π系列性能最强;强化微调+流匹配结合,融合RL与监督学习,突破纯模仿学习上限
- SmolVLA:小参数规模(450M)下实现高性能,支持边缘部署与异步推理,训练成本极低
4. SOTA模型
- 流匹配VLA当前综合SOTA:π*₀.6;在真实机器人复杂灵巧操作、长时任务、分布外泛化上处于领先水平
- 空间推理增强SOTA:DM0;通过四层分层空间思维链,实现从高层语义到低层动作的渐进式约束
- 在线RL微调SOTA:πRL;首个实现流匹配VLA的在线RL微调,突破传统模仿学习局限
四、VLA排行榜
以下信息截止更新于:2026/02/26,官网排行榜会持续更新的~
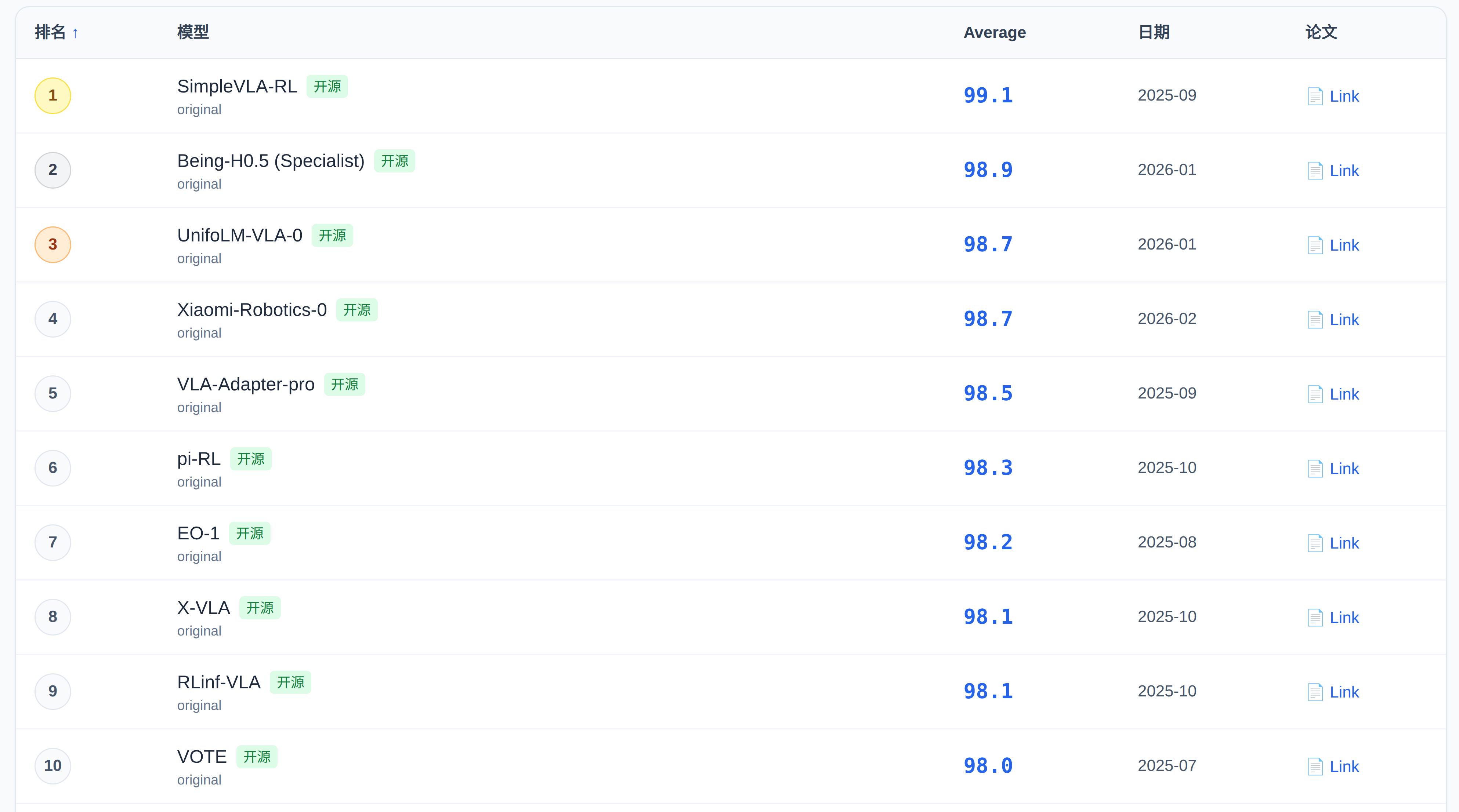
1、LIBERO 基准测试榜单
LIBERO 是一个终身机器人学习基准,包含 130 个语言条件操作任务。
排行地址:https://sota.evomind-tech.com/benchmarks/libero/
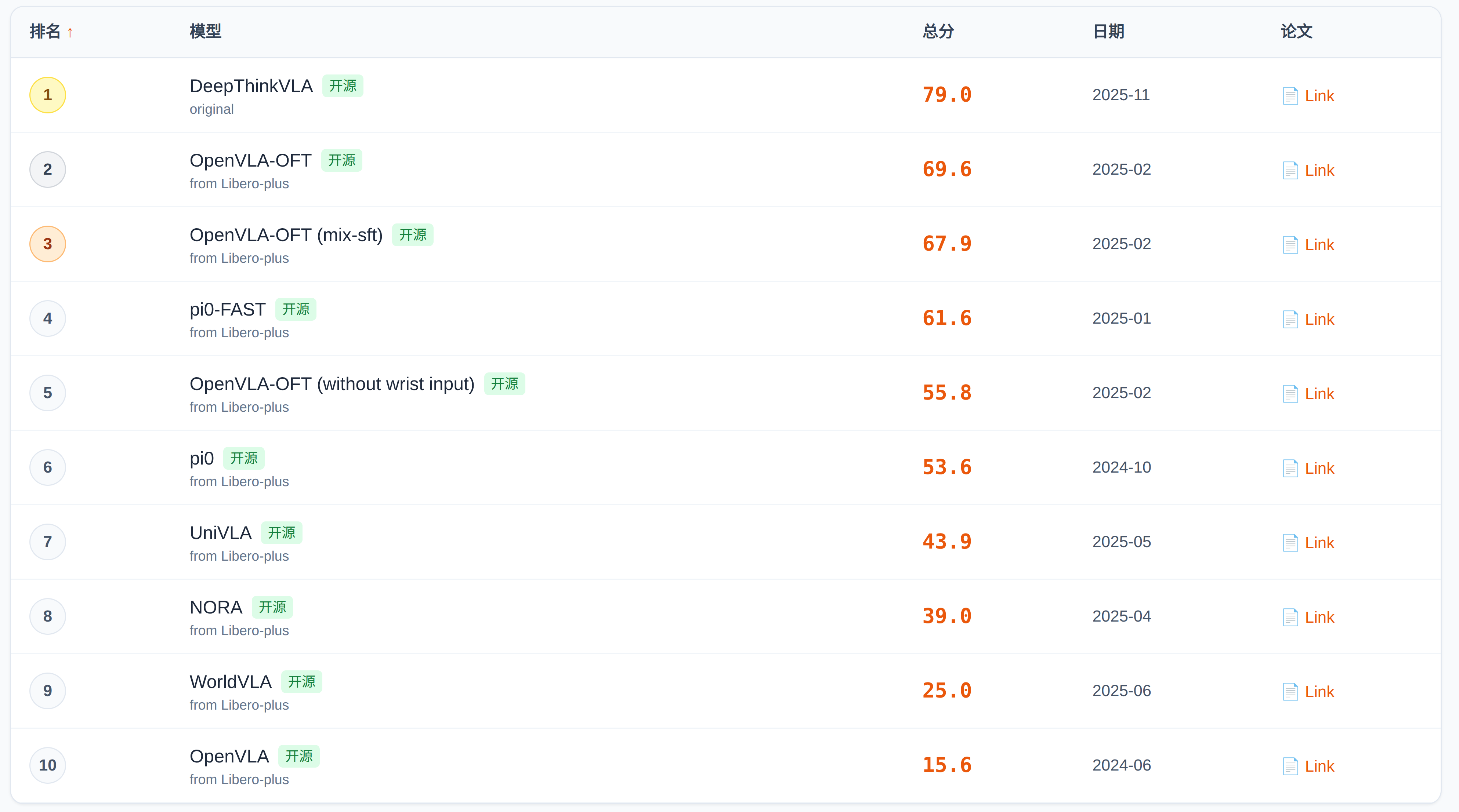
2、LIBERO Plus 基准测试榜单
LIBERO Plus 是一个扩展基准测试,测试模型在 7 个扰动维度上的鲁棒性:相机、机器人、语言、光照、背景、噪声和布局。
排行地址:https://sota.evomind-tech.com/benchmarks/liberoplus/
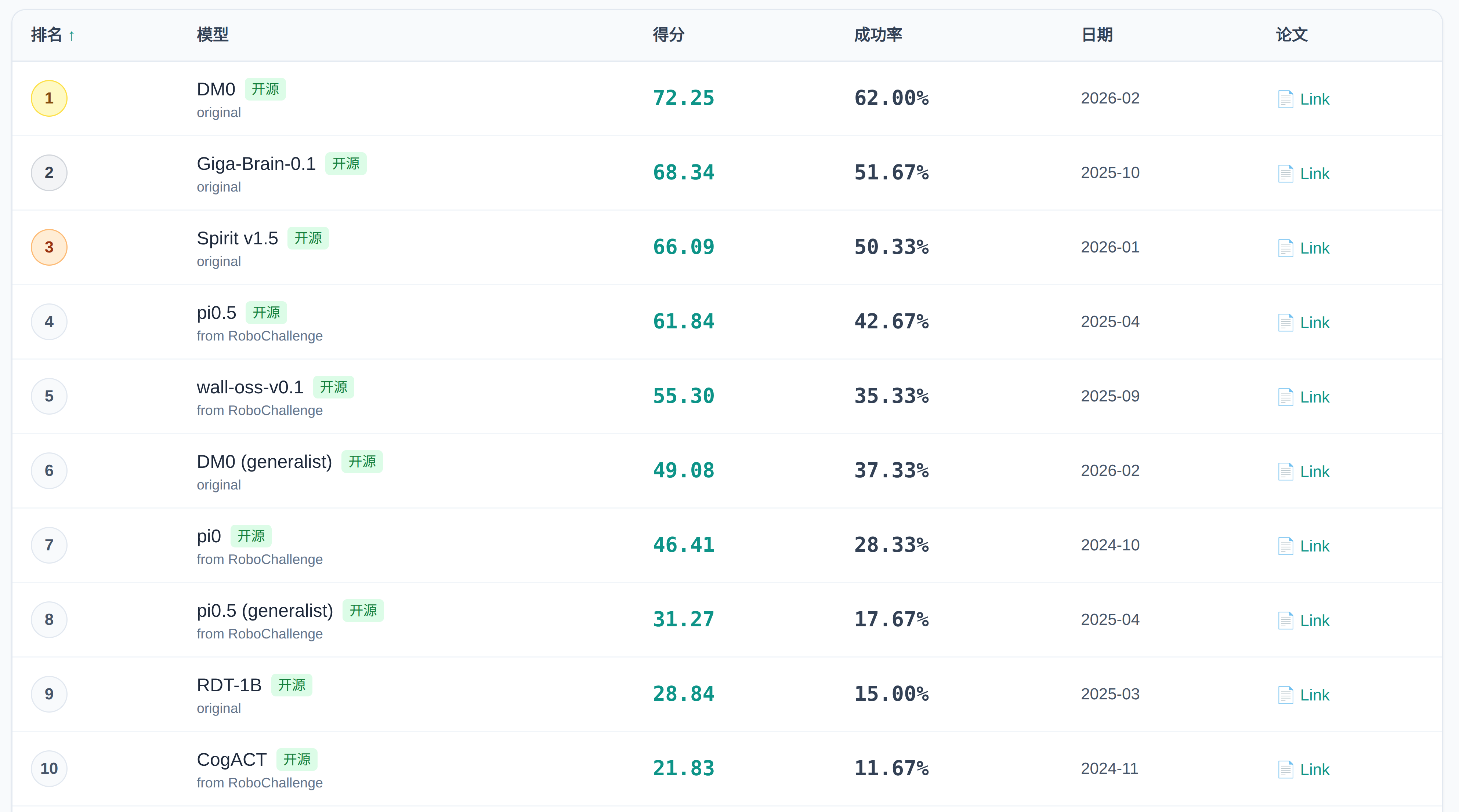
3、RoboChallenge 基准测试榜单
RoboChallenge 是一个综合性基准测试,用于评估具身智能体在真实世界机器人操作任务中的表现,涵盖多样化的物体和场景。
排行地址:https://sota.evomind-tech.com/benchmarks/robochallenge/
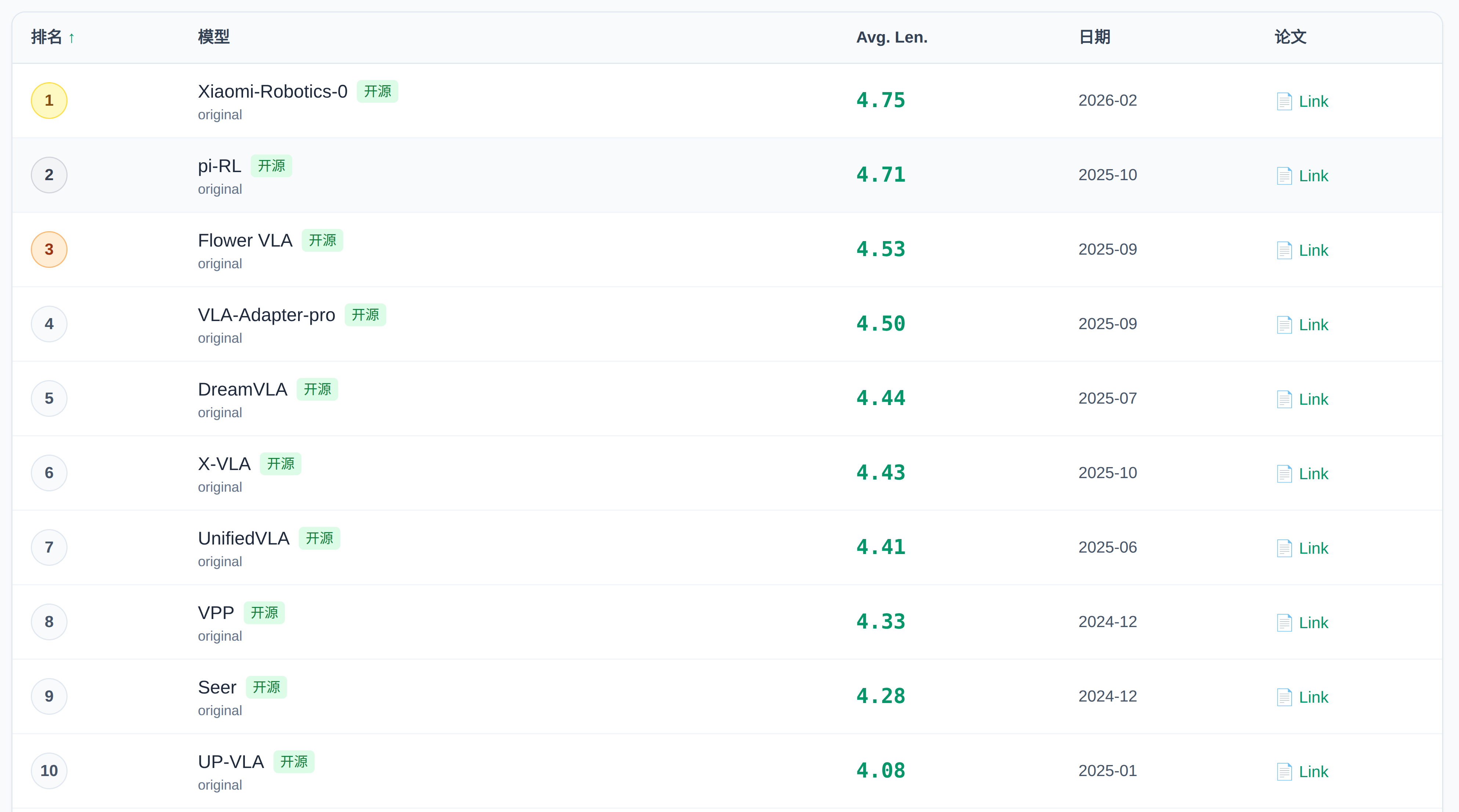
4、CALVIN 基准测试榜单
CALVIN 是一个在桌面操作环境中学习长视野语言条件任务的基准。
排行地址:https://sota.evomind-tech.com/benchmarks/calvin/
五、VLA训练框架/工具
5.1、Dexbotic 一站式 具身智能 VLA开发工具箱
Dexbotic 是一个基于 PyTorch 构建的开源 VLA 模型工具,面向具身智能领域的研究者和开发者,提供一站式的 VLA 研究服务。
开源地址:https://github.com/Dexmal/dexbotic
🏗️ 系统架构,如下图所示:
从数据来源到模型训练、推理,再到仿真与真实世界部署,形成了一个闭环的具身智能开发体系。

核心模块拆解
| 模块 | 核心作用 | 关键组件/特性 |
|---|---|---|
| Embodiments(具身载体) | 提供多源机器人数据输入 | 支持 UR5、Franka、ALOHA 等主流机械臂及其他机器人平台,产生原始数据(Raw Data) |
| Data Layer(数据层) | 统一数据格式与处理 | - Dexdata Format:定义标准化数据结构,兼容多源机器人数据 - Dexdata Process:提供数据清洗、格式转换(如 LeRobot/RLDS → Dexdata) |
| Modular Framework(模块化框架) | 核心模型训练与推理引擎 | - Vision Encoder:CLIP、sigLIP、PE 等视觉编码器 - LLM:Qwen、StepFun、PaliGemma 等大语言模型 - Action Expert: 扩散模型、流匹配、离散自回归预测 等动作生成策略- VLA模型: 支持 π0、 π0.5、DM0、OFT、CogACT、MemVLA 等主流 VLA 模型 - 微调算法: SFT监督微调、 GRPO 等 |
| Experiment Layer(实验层) | 管理训练与推理全流程 | - Experiment Centric:以实验为核心的配置与调度 - Training PPL:分布式训练管线(支持 DeepSpeed 优化)- Inference PPL:实时推理服务(支持 API 调用) |
| Simulation & Real World(仿真与真实视觉) | 模型评估与验证 | - 仿真环境:用于快速迭代与基准测试 - 真实世界:验证模型在物理场景中的泛化能力 |
| Infra(基础设施) | 提供灵活算力支持 | - 云服务:阿里云、火山引擎等大规模云端训练平台- 消费级 GPU:RTX 4090/5090 等本地训练部署 |
🌟 核心特性
统一的模块化 VLA 框架
- 围绕 VLA 模型构建,兼容主流大语言模型的开源接口
- 整合具身操作与导航能力,支持多种领先的具身操作/导航策略
- 预留全身控制接口,适配未来技术演进
多机器人训练与部署支持
- 支持 UR5、Franka、ALOHA 等主流机器人平台
- 提供统一的训练数据格式与通用化部署脚本
- 持续扩展更多主流机器人平台适配
云/本地灵活训练
- 支持阿里云、火山引擎等大规模云端训练平台
- 适配消费级 GPU(如 RTX 4090)的本地训练场景
标准化数据体系
- 定义统一的 Dexdata 数据格式,兼容多源机器人数据
- 提供 LeRobot、RLDS(Libero)等数据集的转换脚本
5.2、RLinf 为具身智能和智能体而生的强化学习框架
RLinf 是一个灵活且可扩展的开源框架,专为具身智能和智能体而设计。
名称中的 “inf” 既代表 Infrastructure,强调其作为新一代训练坚实基础的作用;也代表 Infinite,寓意其支持开放式学习、持续泛化以及智能发展的无限可能。
代码地址:https://github.com/RLinf/RLinf
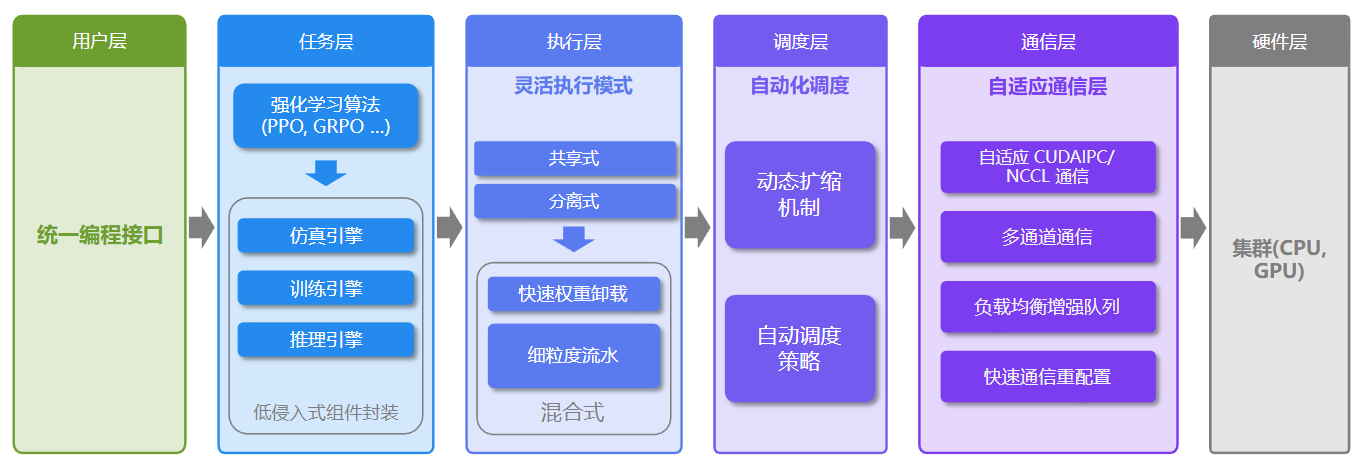
🌟 核心特性
RLinf具有高度灵活性,可支持多种强化学习训练工作流(PPO、GRPO、SAC等),同时隐藏了分布式编程的复杂性。用户无需修改代码即可轻松将强化学习训练扩展至大量GPU节点,满足强化学习训练日益增长的计算需求。
这种高灵活性使 RLinf 能够探索更高效的调度与执行模式。在具身强化学习中,混合执行模式的吞吐量可达现有框架的 2.434 倍。
多后端集成支持
- FSDP + HuggingFace/SGLang/vLLM: 快速适配新模型与新算法,非常适合初学者和快速原型验证。
- Megatron + SGLang/vLLM: 针对大规模训练进行了优化,为专家用户提供最大化效率。
具身智能
| 模拟器 | 真机 | 模型 | 算法 |
|---|---|---|---|
|
|
智能体强化学习
| Single-Agent | Multi-Agent |
|---|---|
|
|
5.3、LeRobot
LeRobot 提供基于 PyTorch 的机器人模型、数据集和工具,以应用于现实世界的机器人项目。目标是降低准入门槛,让每个人都能参与共享数据集和预训练模型的开发并从中受益。
开源地址:https://github.com/huggingface/lerobot/tree/main
-
🤗 全面支持开源生态系统。一个与硬件无关、Python 原生的接口,可标准化跨各种平台的控制,从低成本机械臂(SO-100)到人形机器人。
-
🤗 标准化的、可扩展的 LeRobotDataset 格式(Parquet + MP4 或图像)托管在 Hugging Face Hub 上,可实现海量机器人数据集的高效存储、流式传输和可视化。

-
LeRobot 提供统一的Robot类接口,将控制逻辑与硬件细节解耦。它支持多种机器人和远程操作设备。
-
支持的硬件: SO100、LeKiwi、Koch、HopeJR、OMX、EarthRover、Reachy2、游戏手柄、键盘、手机、OpenARM、Unitree G1。
-
可以轻松地实现 Robot 接口,从而利用 LeRobot 的数据采集、训练和可视化工具来开发自己的定制机器人。参考链接:https://huggingface.co/docs/lerobot/integrate_hardware
下面是支持的模型与方案:
| Category | Models |
|---|---|
| Imitation Learning | ACT, Diffusion, VQ-BeT |
| Reinforcement Learning | HIL-SERL, TDMPC & QC-FQL (coming soon) |
| VLAs Models | Pi0Fast, Pi0.5, GR00T N1.5, SmolVLA, XVLA |
下面是提供参考学习的:
综述汇总 awesome-embodied-vla-va-vln:https://github.com/jonyzhang2023/awesome-embodied-vla-va-vln
综述汇总 Awesome-RL-VLA:https://github.com/Denghaoyuan123/Awesome-RL-VLA
综述汇总 Awesome-VLA:https://github.com/yueen-ma/Awesome-VLA
分享完成,后续会持续更新~

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 12
12 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)