浙大 × 西湖大学最新:超越π0.5,融合人类数据与世界模型的高效VLA训练框架
FRAPPE提出了一种面向VLA模型的高效微调新范式:通过表征对齐与多源数据顺滑融合,在可接受的推理开销的前提下,显著提升模型的泛化能力、长时序能力与隐式世界建模能力。
将预测未来动态的世界建模能力和具身策略模型 (VLA) 相结合对提升机器人推理能力和泛化能力至关重要。然而,当前的方法面临两个主要问题:1. 训练目标迫使模型过度关注像素级重建,这限制了语义学习和泛化能力;2. 在推理过程中依赖预测的未来观察结果,往往会导致误差积累。为了解决这些挑战,本文提出了通过并行渐进扩展实现的未来表示对齐 (FRAPPE) 方法。在 RoboTwin 基准测试和实际任务中的实验表明,经过 FRAPPE 训练后的策略在性能上超越了RDT-1B, π0.5等先进模型,并在长时程和未见过的场景中表现出强大的泛化能力。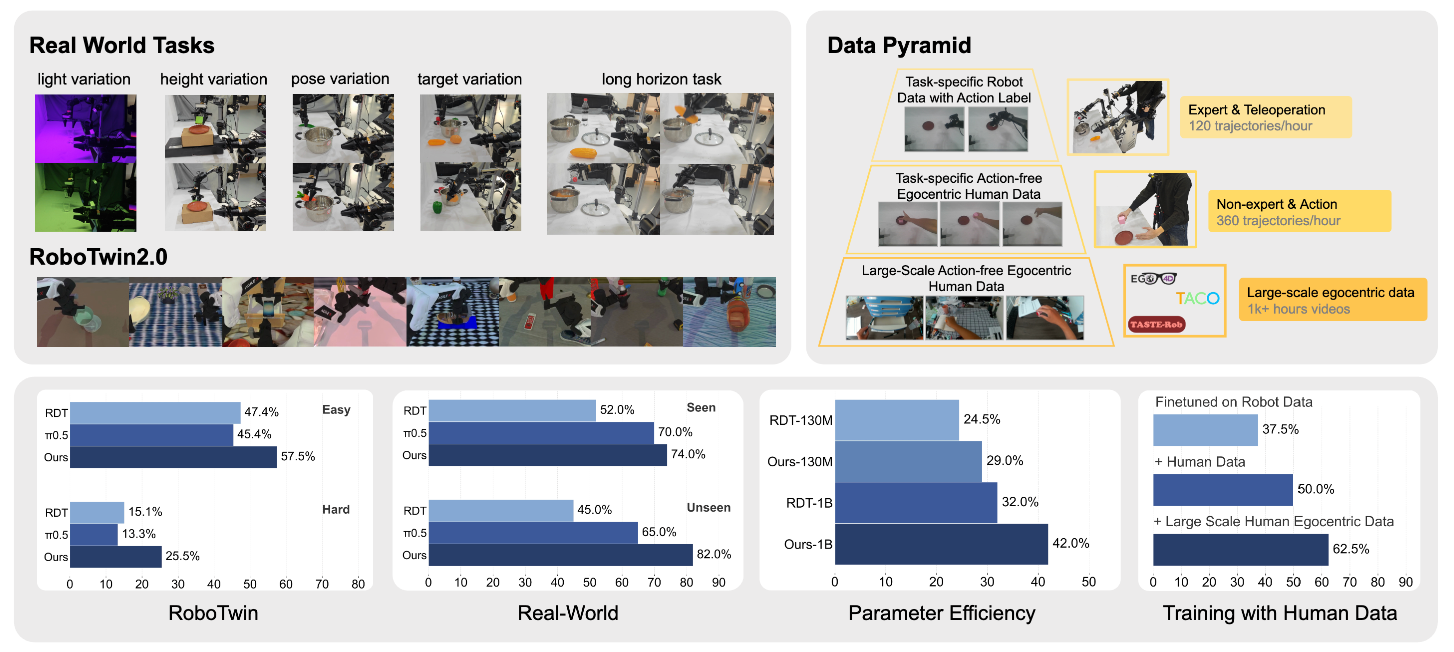
- 论文题目:FRAPPE: Infusing World Modeling into Generalist Policies via Multiple Future Representation Alignment
- 论文链接:https://arxiv.org/abs/2602.17259
- 项目主页:https://h-zhao1997.github.io/frappe/
- 论文时间:Feb, 20, 2025
- 作者单位:浙江大学,西湖大学,香港科技大学(广州),华南理工大学,上海科技大学,清华大学
🛠️ 方法概述
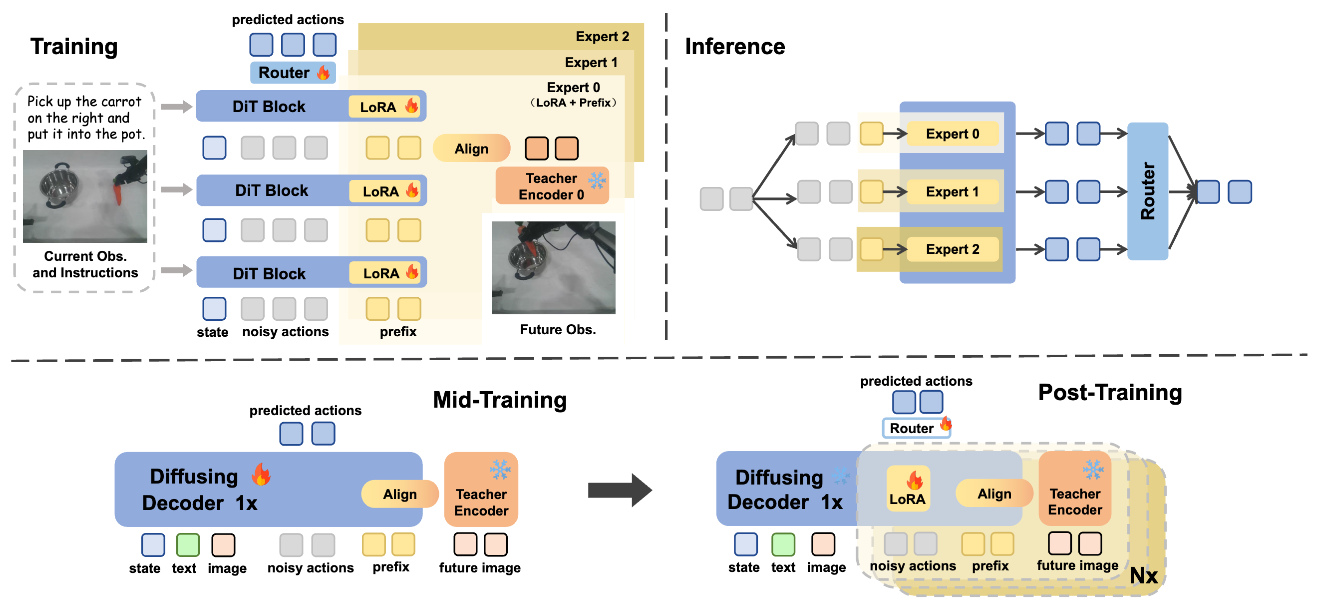
FRAPPE的设计哲学是通过渐进式扩展来提升模型的世界建模能力和参数,方案聚焦于训练机制和模型结构两个层面对已有的基础模型进行后训练优化:
1. 训练机制:隐式世界建模(Implicit World Modeling)
模型不采取显式生成未来观测的像素这一显式建模,而是通过对未来观测在隐空间的表征进行对齐,使模型能够在统一的语义空间中理解动作与视觉信息,提升跨任务泛化能力。
2. 模型结构:并行扩展(Parallel Scaling)
FRAPPE 将具有单一推理流的VLA模型进行扩展,通过复制多个输入进行并行的前向计算,每个流对齐一个独立的视觉编码器(实验中采取的并行度为3,分别对齐DINOv2,CLIP和ViT的表征),同时学习多个教师表征,避免模型学习单一的归纳偏置。
🧩 训练方案
具体实践中,FRAPPE 采取渐进式扩展训练:
-
Mid-Training阶段,模型进行全参数微调并和单一的视觉编码器 Theia 进行对齐,这一步保证了预训练模型可以适应世界建模训练的训练范式;
-
Post-Training阶段引入并行扩展机制,通过多个prefix和LoRA模块将模型转换为混合专家架构并进行多教师特征对齐的并行训练。
🧪 实验验证
1. 仿真结果
在RoboTwin Benchmark的8个子任务中,FRAPPE 在平均成功率上超越了采用naive fine-tuning的VLA base model(RDT-1B、π0、π0.5)、小模型基线 (DP) 以及基于预测表征的生成式基线 (VPP)。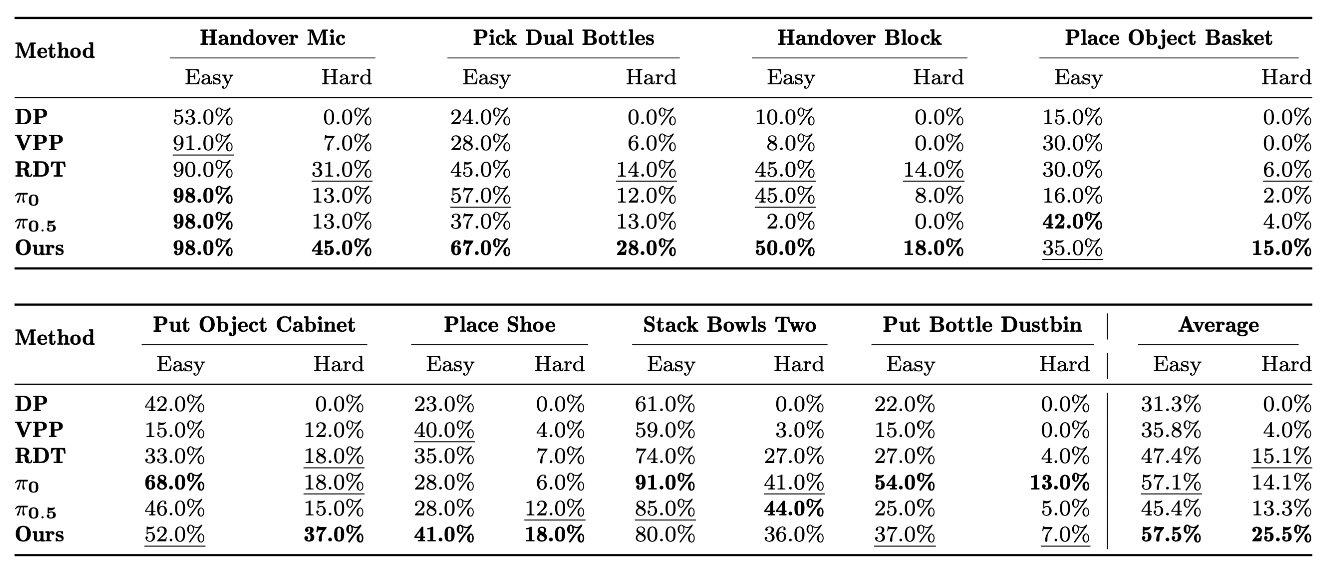
在更小参数模型的仿真实验中,RDT-130M使用 FRAPPE 进行后训练,在RoboTwin上的性能可以与RDT-1B持平,展现出了该方案在小参数模型中仍然适用,并对性能和泛化性有显著提升。

2. 真机实验
在真机实验中,FRAPPE 的性能在四个基本的双臂操作任务上超过了 RDT-1B 和 π0.5,并且在未见的复杂场景下展示出了更优越的泛化性。
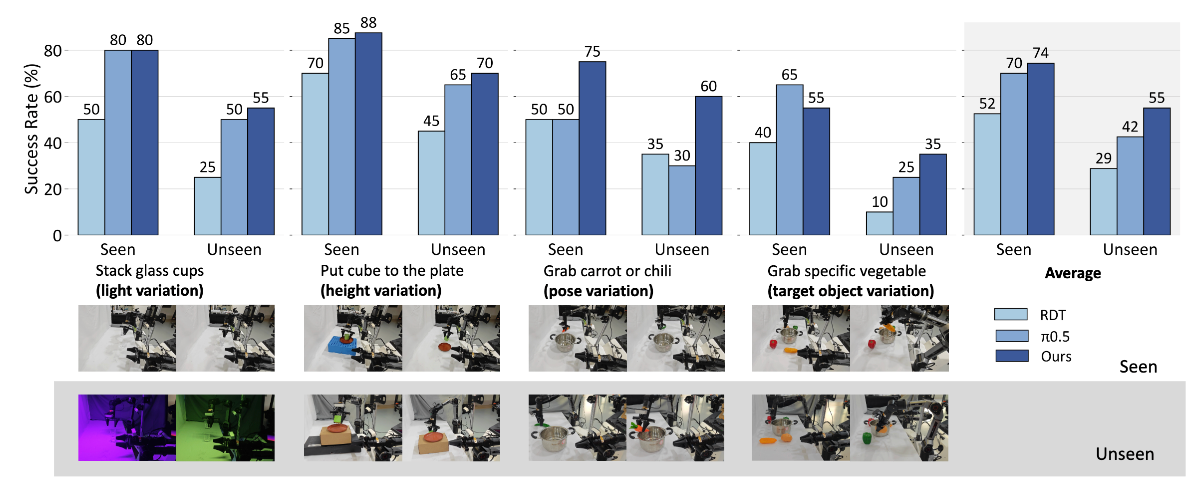
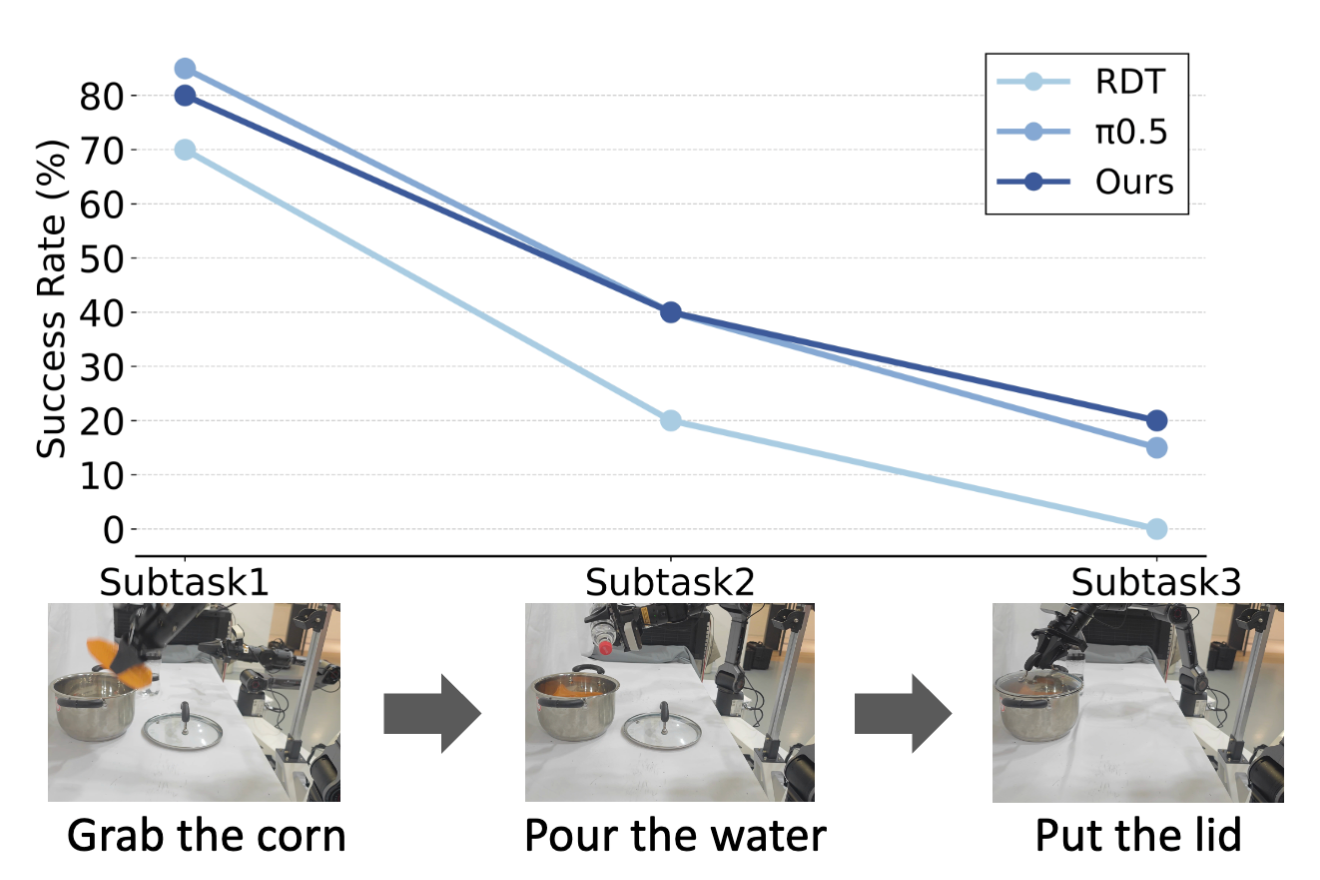
在包含三个子任务的长程任务中,在最终成功率上 FRAPPE 和 π0.5 表现相当。作为对比,RDT-1B 则无法成功按顺序完成三个子任务。
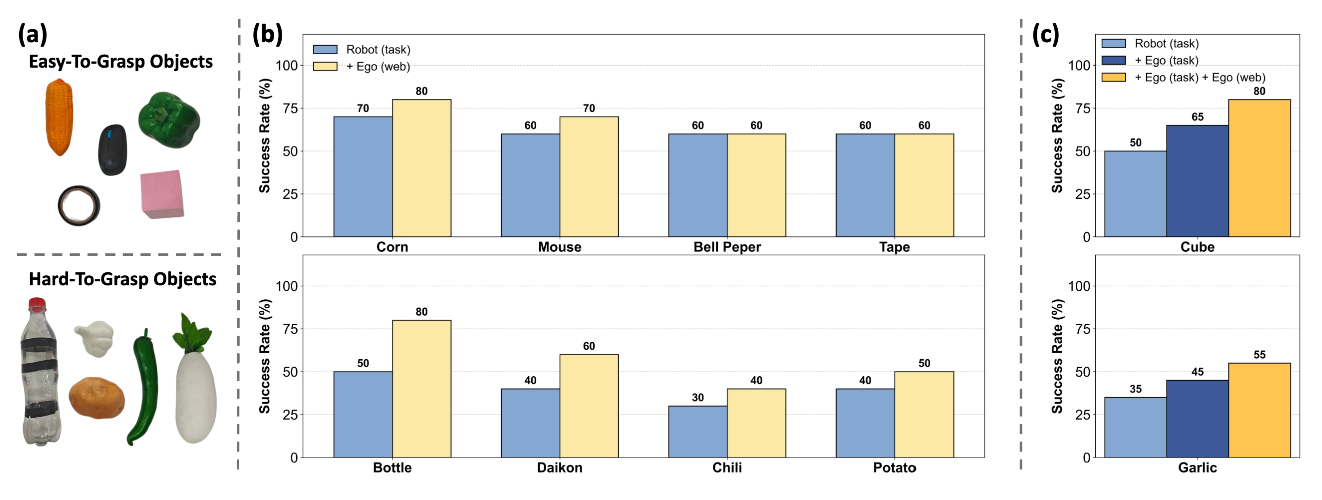
3. 人类数据协同训练
与其他工作类似,没有动作标签的人类视频也可以增益训练世界模型的训练过程。本文在大规模的人类视频擦操作数据集 (Ego (Web)) 和人类执行相同下游任务的数据 (Ego (Task)) 两种数据源上都进行了实验。实验表明两种数据都能够提升下游任务的成功率,可以极大的减少遥操作数据的采集规模,降低数据成本。
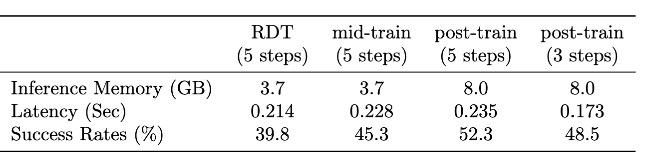
⚡️ 计算效率
尽管在推理中由于并行扩展架构引入了额外的参数和计算量,模型仍然可以保持和RDT-1B相近的推理延迟以及可接受的显存占用。
✅ 总结与展望
FRAPPE提出了一种面向VLA模型的高效微调新范式:
通过表征对齐与多源数据顺滑融合,在可接受的推理开销的前提下,显著提升模型的泛化能力、长时序能力与隐式世界建模能力。
具身求职内推来啦
国内最大的具身智能全栈学习社区来啦!
推荐阅读
从零部署π0,π0.5!好用,高性价比!面向具身科研领域打造的轻量级机械臂
工业级真机教程+VLA算法实战(pi0/pi0.5/GR00T/世界模型等)
具身智能算法与落地平台来啦!国内首个面向科研及工业的全栈具身智能机械臂
VLA/VLA+触觉/VLA+RL/具身世界模型等!具身大脑+小脑算法与实战全栈路线来啦~
MuJoCo具身智能实战:从零基础到强化学习与Sim2Real
Diffusion Policy在具身智能领域是怎么应用的?为什么如此重要?
1v1 科研论文辅导来啦!

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 12
12 0
0- 0



 已为社区贡献106条内容
已为社区贡献106条内容

所有评论(0)