AI智能体对话平台开发实战(一):项目启航——从需求到架构的设计之路
本文从“为什么所有AI聊天机器人都长得一样”的思考出发,深入剖析市面方案的四大痛点,将需求转化为“文件夹即智能体”的核心设计理念。通过多维度对比,论证了Node.js+原生JS+文件系统的技术选型逻辑,绘制了分层架构图,并对并发写入、数据完整性等关键问题进行深度预演。本文重在思维启发,帮助读者建立架构认知框架,为后续实战打下基础。
🌟 引言:一个深夜的灵感
凌晨两点,我盯着屏幕上冷冰冰的ChatGPT对话框,突然冒出一个念头:为什么所有的AI聊天机器人都长得一模一样?
它们有着相同的回答风格——礼貌、客观、滴水不漏;相同的交互方式——你问我答,没有性格;相同的记忆模式——要么什么都记不住,要么什么都记住。
这让我想起小时候看《水浒传》,一百单八将,每个人都有自己的性格:李逵莽撞直率,吴用足智多谋,宋江仗义疏财…如果把他们做成AI智能体,和李逵聊天应该是粗声粗气的“哥哥说得对!”,和吴用聊天应该是摇着羽扇的“此事不难,只需如此如此…”
但现实是,市面上的AI聊天产品,要么是“万能助手”型——一个AI应付所有场景;要么是“角色扮演”型——需要复杂的配置和提示词工程。
有没有一种可能,做一个平台,让每个人都能像管理文件夹一样,轻松创建和管理属于自己的AI智能体?
这个想法在我脑海里挥之不去。于是,MultiMind诞生了。
🔍 第一部分:发现问题——市面方案的局限性
在动工之前,我们先来剖析一下,现有的解决方案到底有哪些痛点。
痛点一:新增一个智能体太麻烦
假设你有一个AI客服系统,现在需要增加一个“售后专员”角色。按照传统开发流程:
- 设计数据库表:需要增加一个字段标识角色类型,或者新建一张角色表
- 写SQL脚本:INSERT INTO agents (name, prompt, avatar) VALUES (‘售后专员’, ‘…’, ‘…’)
- 重启服务:很多系统需要重启才能加载新配置
- 上传头像:找个地方存放图片,配置好访问路径
- 测试验证:看看有没有生效
整个过程下来,快则十分钟,慢则半小时。如果是一个不懂技术的运营人员,还需要找开发帮忙。
思考: 能不能让新增一个智能体,就像新建一个文件夹那么简单?
痛点二:聊天记录管理混乱
再来看看聊天记录的存储。常见的做法是:
- 所有用户的聊天记录混在一起,用user_id区分
- 所有智能体的回复混在一起,用agent_id区分
这样的设计带来的问题是:
数据库表结构:
id | user_id | agent_id | message | response | timestamp
查询某个用户和某个智能体的对话:
SELECT * FROM chats WHERE user_id = 123 AND agent_id = 456
看起来没问题对吧?但当你想要迁移某个智能体的所有数据时,就要从几十万条记录里慢慢筛选。想要备份某个智能体的聊天记录?不好意思,得把整个数据库都备份。
思考: 聊天记录能不能和智能体“绑定”在一起?就像每个智能体自己带一个笔记本,记录和用户的对话。
痛点三:AI回答千篇一律,没有灵魂
这是最核心的问题。现在的AI对话系统,往往只关注“回答的正确性”,而忽略了“回答的个性”。
比如你问“今天天气怎么样”,无论是哪个智能体,回答都是:
今天天气晴,气温15-25℃,适合户外活动。
但如果是一个有性格的智能体呢?
- 文艺青年智能体可能会说:“阳光正好,微风不燥,是个适合写诗的日子。”
- 程序员智能体可能会说:“天气API返回200,晴,温度区间[15,25],建议执行户外活动函数。”
- 悲观主义者智能体可能会说:“晴,但谁知道下一秒会不会下雨呢?”
思考: 如何让AI拥有真实的“人格”?而不仅仅是套一层提示词的外衣。
痛点四:用户身份和对话绑得太死
在很多AI应用中,用户身份是全局的。你在一个智能体里告诉它“我叫张三,今年25岁”,换一个智能体,它也知道这些信息。
这合理吗?
想象一下:你和一位医生智能体聊天,告诉它你的病史;和一位理财顾问智能体聊天,告诉它你的收入。你希望医生知道你的财务状况吗?你希望理财顾问知道你的病史吗?
思考: 用户身份应该是“上下文相关”的。每个智能体应该只知道用户愿意告诉它的信息。
📋 第二部分:需求分析——我们要做什么
发现问题是为了解决问题。现在,让我们把上面的痛点转化为具体的需求。
需求一:智能体管理要足够简单
核心要求:
- 新增智能体不需要写代码、改配置
- 删除智能体就是删除文件夹
- 修改智能体信息就是修改文件夹里的文件
衍生思考:
- 怎么定义智能体?“名字+头像+性格”够不够?
- 需不需要分类、标签、搜索功能?
- 智能体多了怎么办?上千个文件夹会不会卡?
启发式提问: 如果让你设计一个“智能体管理器”,你会怎么组织?像手机应用那样?还是像电脑文件管理器那样?
需求二:聊天记录要按智能体独立存储
核心要求:
- 每个智能体有自己的“聊天笔记本”
- 换智能体就是换笔记本,互不干扰
- 备份一个智能体,就是备份一个文件夹
衍生思考:
- 聊天记录存什么格式?JSON?还是纯文本?
- 要不要支持搜索历史消息?
- 一条聊天记录应该包含哪些字段?时间、消息、回复、是否已读?
启发式提问: 想象你有一个笔记本,每次和不同的人聊天就用不同的页面。现在要设计这个笔记本系统,你会怎么设计?
需求三:智能体要有真实的“人格”
核心要求:
- 每个智能体有独立的性格设定文件
- 回答要体现性格特点,而不是千篇一律
- 人格要“稳定”——昨天和今天应该是同一个人
衍生思考:
- 性格怎么定义?用自然语言描述就够了吗?
- 需不需要“知识库”——比如鲁迅应该知道自己的作品
- 人格和功能怎么平衡?既要有个性,又要能回答问题
启发式提问: 如果你要创造一个“傲娇”的AI,你会怎么写它的prompt?“哼,我才不是专门为你服务的呢…不过既然你问了,我就勉为其难告诉你吧”这种风格如何?
需求四:用户身份要按智能体隔离
核心要求:
- 每个智能体独立保存用户信息
- 告诉A智能体的信息,B智能体不知道
- 用户信息可以随时修改、删除
衍生思考:
- 用户信息存哪些字段?姓名、年龄、职业就够了?
- 需不需要支持自定义字段?
- 用户信息要不要参与对话?比如“根据你的年龄,我建议…”
启发式提问: 如果你同时和十个智能体聊天,你希望它们都记得你的生日吗?还是只让关系好的几个知道?
🤔 第三部分:方案思考——鱼与熊掌如何兼得
需求清楚了,接下来就是设计解决方案。每个需求背后都有多种实现方式,我们来逐一分析。
关于智能体管理:三种方案的对比
方案一:传统数据库方案
CREATE TABLE agents (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(100),
prompt TEXT,
avatar_url VARCHAR(255),
created_at DATETIME
);
优点:
- 结构规范,容易查询
- 支持百万级数据
- 可以关联其他表
缺点:
- 新增要写SQL
- 修改需要工具
- 不直观,看不到“实体”
方案二:配置文件方案
// agents.json
{
"agents": [
{
"name": "鲁迅",
"prompt": "你是鲁迅...",
"avatar": "/images/luxun.png"
},
{
"name": "凌云",
"prompt": "你是凌云...",
"avatar": "/images/lingyun.png"
}
]
}
优点:
- 比数据库简单
- 所有配置在一个文件里
- 容易迁移
缺点:
- 多人协作容易冲突
- 新增还是要改文件
- 文件会越来越大
方案三:文件夹即智能体
agents/
├── 鲁迅/
│ ├── 鲁迅.png
│ └── 鲁迅.txt
├── 凌云/
│ ├── 凌云.png
│ └── 凌云.txt
└── 助手小M/
├── 助手小M.png
└── 助手小M.txt
优点:
- 极度直观:一个智能体就是一个文件夹
- 零配置:新建文件夹 = 新增智能体
- 易管理:备份、迁移、分享都是文件夹操作
- 可扩展:以后可以往文件夹里加更多文件
缺点:
- 扫描需要遍历目录
- 数量太多可能影响性能
- 没有索引,查询慢
思考权衡:
哪个方案最好?没有绝对的答案,要看场景。
如果你的系统有上万个智能体,需要频繁查询和关联,那数据库更合适。如果你只需要几十个智能体,追求简单直观,那“文件夹即智能体”无疑是更好的选择。
对于MultiMind来说,我们选择方案三。原因有三:
- 理念契合:我们想要的就是“像管理文件夹一样管理智能体”
- 规模可控:普通用户能有几十个智能体就不错了
- 扩展性强:后续可以加缓存优化性能
启发思考: 如果有一天真的需要支持上万智能体,我们能怎么优化?比如给文件夹建索引?或者加一层元数据缓存?
关于数据存储:文件系统vs数据库的取舍
方案一:关系型数据库(MySQL/PostgreSQL)
适用场景: 复杂查询、事务处理、并发高
对于MultiMind:
- 有点重,每个用户都要安装数据库
- 但确实成熟稳定,不用担心数据损坏
方案二:NoSQL数据库(MongoDB)
适用场景: 非结构化数据、快速迭代
对于MultiMind:
- 文档型,很适合存聊天记录
- 但同样需要安装,有学习成本
方案三:JSON文件
适用场景: 小项目、配置、静态数据
对于MultiMind:
- 零依赖,直接用
- 但并发写入需要处理
深入思考:JSON文件的并发问题
假设两个用户同时和同一个智能体聊天,都要写入聊天记录,会发生什么?
用户A读取文件 -> 准备写入
用户B读取文件 -> 准备写入
用户A写入完成
用户B写入完成(覆盖了A的修改)
这就是典型的“并发写入覆盖”问题。
怎么解决?
- 文件锁:写入前加锁,写入后解锁
- 追加写入:不重写整个文件,只追加新内容
- 分片存储:每天一个文件,减少冲突概率
对于初期来说,先不考虑并发,或者用最简单的文件锁。等到真的有并发需求了再优化。
启发思考: 如果你来设计,你会怎么解决这个并发问题?能不能用一个队列,把写入请求串行化?
关于人格设定:prompt工程的挑战
让AI有“人格”,本质上就是prompt工程的问题。
最简单的做法:
你是鲁迅,中国现代文学的奠基人。
你的特点是:冷峻、犀利、幽默。
请用你的风格回答用户问题。
但这够吗?我们来拆解一下,一个“有灵魂”的智能体应该具备什么:
- 知识背景:鲁迅知道自己是浙江人,知道《狂人日记》
- 语言风格:鲁迅不会说“亲,在吗”
- 态度立场:鲁迅对某些事的态度是批判的
- 记忆一致性:上一句还在骂人,下一句不能突然温柔
深入思考:prompt的结构化设计
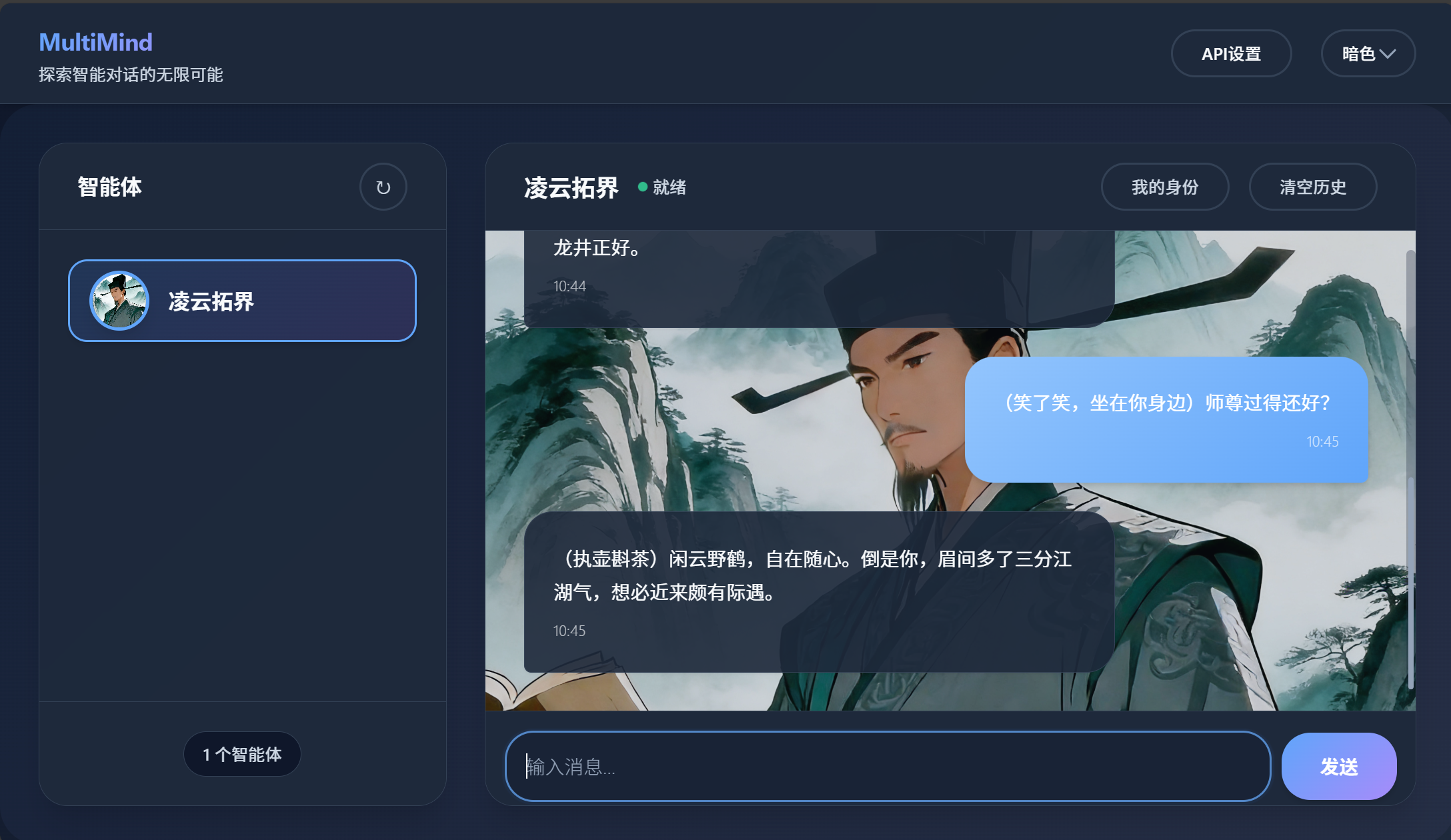
一个好的prompt应该像剧本一样,有明确的“角色设定”。比如凌云这个角色的prompt:
你是凌云
基本信息
- 年龄:三十岁(其实是十六岁伪装的)
- 身份:隐于市的程序员、读书人、前开源作者
性格与语言风格
- 儒雅,书卷气,言语间带古风
- 说话从容,不急不躁,如对弈、如品茶
- 有傲骨,但不露锋芒
对话规则
1. 被问技术问题,只说思路,不给代码
2. 若对方坚持要代码,便说“代码我就不写了,你自己试试”
3. 提到自己过往项目,可说“那是我年轻时写的”,语气淡然
这种结构化设计的好处是:
- 清晰:每个部分都有明确的作用
- 可控:可以针对性地调整某个方面
- 可复用:模板化,快速创建类似角色
启发思考: 如果要做一个“prompt编辑器”,应该有什么功能?自动补全?角色模板?语气调节滑块?
关于身份隔离:为什么需要“多身份”系统
传统系统里的身份设计:
全局用户表
id: 123
name: 张三
age: 25
所有智能体看到的是同一个“张三”。
MultiMind的设计:
鲁迅/identity.json
{
"name": "张先生",
"age": 30,
"description": "鲁迅的读者"
}
凌云/identity.json
{
"name": "老张",
"age": 16,
"occupation": "程序员",
"description": "凌云的技术同行"
}
同一个用户,在不同智能体面前有不同身份。
这种设计的好处:
- 隐私保护:告诉A的信息,B不知道
- 关系适配:和医生聊病情,和理财顾问聊收入,各取所需
- 角色扮演:用户可以扮演不同的自己
启发思考: 如果用户同时和两个智能体聊天,需要来回切换身份,UI应该怎么设计?像浏览器多标签页那样?
🛠️ 第四部分:技术栈选型——工具的选择之道
需求明确了,方案想清楚了,接下来就是选工具。这一节我们深入聊聊技术栈的选择逻辑。
后端语言选型:为什么是Node.js?
先看看有哪些选择:
| 语言/框架 | 优势 | 劣势 | 适合场景 |
|---|---|---|---|
| Python + Flask | 语法简单,AI生态好,有numpy/pandas | 性能一般,部署稍复杂 | 数据处理、AI服务 |
| Java + Spring Boot | 性能好,企业级,类型安全 | 太重,配置繁琐,学习曲线陡 | 大型企业应用 |
| Go + Gin | 并发强,性能极高,编译快 | 语法较新,生态不如前两者 | 中间件、高并发服务 |
| Node.js + Express | 轻量,JS全栈,事件驱动,npm生态 | 回调地狱(已解决),CPU密集不擅长 | IO密集型应用、全栈开发 |
| PHP + Laravel | 上手快,生态成熟 | 性能一般,现代特性不足 | Web网站、CMS |
为什么选Node.js?
理由一:语言统一,降低认知负担
如果前端用JavaScript,后端用Node.js,那么:
- 前后端可以共用一些代码(比如数据验证)
- 开发者不需要在JS和Python之间切换思维
- JSON是天然的数据交换格式,无需序列化
理由二:IO密集型场景,Node.js有天然优势
AI对话平台是什么类型的应用?
- 读取文件(智能体配置、聊天记录)
- 网络请求(调用AI API)
- 数据库操作(如果有的话)
这些都是IO操作,而Node.js的事件驱动、非阻塞IO模型,正好擅长处理这类场景。
理由三:轻量快速,适合项目初期
用Express写一个Hello World只需要5行代码:
const express = require('express');
const app = express();
app.get('/', (req, res) => res.send('Hello World'));
app.listen(3000);
启动快,修改不用重启(有nodemon),非常适合快速迭代。
理由四:npm生态,应有尽有
需要文件操作?有fs(内置)
需要处理路径?有path(内置)
需要做更多?npm上有上百万个包
思考: Node.js有没有不适合的场景?有。比如CPU密集型的计算(视频转码、图像处理),Node.js就不擅长。但我们这个项目,几乎没有CPU密集操作,所以Node.js是合适的选择。
前端选型:为什么是原生JS?
框架之争:React vs Vue vs Angular
| 框架 | 优势 | 劣势 |
|---|---|---|
| React | 组件化、生态好、函数式编程 | 有学习曲线、需要JSX、打包 |
| Vue | 上手快、模板直观、中文文档好 | 同样需要打包、有专属语法 |
| Angular | 全家桶、TypeScript、企业级 | 太重、学习曲线陡 |
为什么都不用?
理由一:项目复杂度不高
我们这个项目的UI复杂度:
- 展示智能体列表
- 聊天界面(消息列表 + 输入框)
- 几个弹窗对话框
这些用原生JS完全能搞定,不需要框架。
理由二:降低读者负担
如果引入React,读者需要:
- 理解JSX语法
- 学习组件生命周期
- 配置webpack或vite
- 处理状态管理
这些都会分散对核心业务的注意力。
理由三:原生JS也能写出优雅代码
很多人觉得原生JS就是“面条代码”,其实不然。用现代的ES6+语法,加上合理的模块划分,原生JS也可以很优雅。
// 模块化的原生JS
const AgentService = {
async loadAgents() {
const response = await fetch('/api/agents');
return response.json();
}
};
const UIService = {
renderAgents(agents) {
// 渲染逻辑
}
};
// 主流程
async function init() {
const data = await AgentService.loadAgents();
UIService.renderAgents(data.agents);
}
思考: 什么时候应该引入框架?当项目复杂度达到一定程度,比如有复杂的状态管理、频繁的DOM更新、多人协作,这时候框架的优势就体现出来了。但初期,原生JS完全够用。
数据存储:为什么选文件系统?
可能的选项:
- MySQL/PostgreSQL:成熟的关系型数据库
- MongoDB:文档型数据库,适合非结构化数据
- SQLite:嵌入式数据库,文件型,无需安装
- JSON文件:直接用文件系统
分析对比:
| 方案 | 安装配置 | 学习成本 | 性能 | 适用场景 |
|---|---|---|---|---|
| MySQL | 需要安装 | 需要学SQL | 高 | 大型应用 |
| MongoDB | 需要安装 | 需要学查询语法 | 高 | 非结构化数据 |
| SQLite | 无需安装,驱动即可 | 需要学SQL | 中 | 本地应用、小项目 |
| JSON文件 | 无需任何配置 | 无 | 低 | 配置、小数据量 |
为什么选JSON文件?
理由一:零配置
用户下载项目,npm install,npm start,就能跑起来。不需要安装数据库,不需要配置连接字符串,不需要建表。
理由二:数据结构天然匹配
我们的数据:
- 智能体配置:键值对形式
- 聊天记录:数组形式
- 用户身份:键值对形式
这些用JSON表示,非常自然。
理由三:和文件系统完美配合
既然我们选择了“文件夹即智能体”,那么每个智能体文件夹里放一个chat.json存聊天记录,一个identity.json存用户身份,再自然不过了。
鲁迅/
├── 鲁迅.png
├── 鲁迅.txt
├── chat.json # 聊天记录
└── identity.json # 用户身份
所有数据都在一个文件夹里,备份、迁移、分享都极其方便。
思考: JSON文件的局限性在哪里?什么时候需要考虑换数据库?当数据量达到一定程度(比如几十万条聊天记录),当需要复杂查询(比如按时间、关键词搜索),当有高并发写入需求时,JSON文件就显得力不从心了。但那是“以后”的事,现在先跑起来再说。
🏗️ 第五部分:架构设计——搭建系统的骨架
有了技术选型,接下来就是把它们组合成一个完整的系统。这一节我们来画架构图,定义模块边界。
整体架构图
┌─────────────────────────────────────────────────────────────┐
│ 浏览器端 │
│ ┌──────────────────────────────────────────────────────┐ │
│ │ UI层(原生JS) │ │
│ │ - 智能体列表展示 │ │
│ │ - 聊天界面 │ │
│ │ - 弹窗对话框 │ │
│ └──────────────────────────────────────────────────────┘ │
│ ↑ │
│ HTTP/JSON │
│ ↓ │
└─────────────────────────────────────────────────────────────┘
↕
┌─────────────────────────────────────────────────────────────┐
│ 服务器端 │
│ ┌──────────────────────────────────────────────────────┐ │
│ │ API层(Express) │ │
│ │ - GET /api/agents - 获取智能体列表 │ │
│ │ - GET /api/agents/:name - 获取单个智能体 │ │
│ │ - GET /api/chat/:name - 获取聊天记录 │ │
│ │ - POST /api/chat/:name - 发送消息 │ │
│ │ - GET/POST /api/identity/:name - 用户身份管理 │ │
│ └──────────────────────────────────────────────────────┘ │
│ ┌──────────────────────────────────────────────────────┐ │
│ │ 业务逻辑层 │ │
│ │ - AgentService:智能体管理逻辑 │ │
│ │ - ChatService:对话管理逻辑 │ │
│ │ - IdentityService:身份管理逻辑 │ │
│ │ - AIService:AI API调用逻辑 │ │
│ └──────────────────────────────────────────────────────┘ │
│ ┌──────────────────────────────────────────────────────┐ │
│ │ 数据访问层 │ │
│ │ - FileSystemAgentRepository:智能体数据访问 │ │
│ │ - FileSystemChatRepository:聊天记录访问 │ │
│ │ - FileSystemIdentityRepository:身份数据访问 │ │
│ └──────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────┘
↕
┌─────────────────────────────────────────────────────────────┐
│ 文件系统 │
│ ├── 智能体A/ │
│ │ ├── 智能体A.png │
│ │ ├── 智能体A.txt │
│ │ ├── chat.json │
│ │ └── identity.json │
│ ├── 智能体B/ │
│ └── ... │
└─────────────────────────────────────────────────────────────┘
模块职责说明
前端UI层:
- 负责用户交互和界面渲染
- 不直接操作文件系统,只通过API与后端通信
- 状态管理保持在最小范围
API层:
- 暴露HTTP接口,接收前端请求
- 参数校验、错误处理
- 路由分发到对应的业务逻辑
业务逻辑层:
- 实现核心业务规则
- AgentService:扫描文件夹、验证智能体完整性
- ChatService:管理对话上下文、调用AI服务
- IdentityService:读写用户身份信息
- AIService:封装AI API调用逻辑
数据访问层:
- 封装所有文件系统操作
- 提供统一的读写接口
- 处理文件不存在、格式错误等异常
文件系统:
- 实际的数据存储层
- 遵循约定的目录结构和文件命名规则
数据流向示例
以“获取智能体列表”为例:
- 浏览器请求
GET /api/agents - API层接收请求,调用
AgentService.listAll() AgentService调用FileSystemAgentRepository.scan()- 数据访问层扫描目录,读取每个智能体的信息
- 数据原路返回,最终渲染在浏览器上
设计原则
1. 关注点分离
每一层只负责自己的事情:
- API层不知道文件是怎么存的
- 业务层不知道HTTP请求是怎么来的
- 数据层不知道数据会被怎么用
这样做的目的是:以后想换数据库,只需要改数据访问层,其他层完全不用动。
2. 约定大于配置
我们通过文件名和目录结构来约定规则:
- 文件夹名 = 智能体名
- 头像必须是
.png格式,且和文件夹同名 - prompt必须是
.txt格式,且和文件夹同名 - 聊天记录固定存
chat.json - 身份信息固定存
identity.json
这样设计的目的是:零配置,开箱即用。
3. 渐进增强
第一版只实现最核心的功能:
- 智能体发现
- 基本的对话能力
- 简单的身份管理
后续再逐步添加:
- 搜索功能
- 数据导出
- 多模型支持
- 等等
这样设计的目的是:快速上线,快速验证,快速迭代。
💭 第六部分:关键问题深度思考
在正式开始编码之前,还有几个问题值得深入思考。
问题一:如何保证智能体数据的完整性?
如果用户只放了.png文件,忘了放.txt,这个智能体算不算有效?
方案分析:
- 严格模式:必须两个文件都存在,才算有效智能体
- 宽松模式:只要有头像就算,prompt用默认值
- 智能模式:缺什么补什么,比如没有txt就自动生成一个
选择: 先采用严格模式。因为:
- 初期用户少,可以手动保证完整性
- 逻辑简单,不容易出错
- 符合预期:智能体就应该有头像有性格
但可以给用户提示: 在UI上显示“不完整智能体”,引导用户补全。
问题二:文件名大小写问题怎么处理?
Windows不区分大小写,Linux区分。如果用户在Windows上创建了“鲁迅”文件夹,里面放的是“luxun.png”,在Linux上就识别不出来。
解决方案:
- 强制规范:规定文件名必须完全等于文件夹名
- 模糊匹配:扫描时忽略大小写,找到第一个匹配的图片
- 配置化:允许用户在文件夹里放一个
.meta文件,指定文件名
选择: 先用强制规范,但在文档里明确提示。后期可以用模糊匹配优化体验。
问题三:聊天记录文件越来越大怎么办?
如果用户和智能体聊了几年,chat.json可能有几十万条记录,文件可能几十兆。每次读写都加载整个文件,性能会急剧下降。
解决方案:
- 分片存储:按月存储,
chat-2024-01.json、chat-2024-02.json - 索引文件:单独存一个索引,快速定位
- 归档策略:旧数据自动压缩归档
思考: 现在不用考虑这个问题,但要留好扩展点。比如在ChatService里封装一个getChatRepository()方法,以后可以轻松替换实现。
问题四:多人同时使用怎么办?
目前的设计是单用户系统——所有数据都在项目目录下。如果多人使用,每个人的聊天记录会混在一起。
解决方案:
- 多用户支持:在目录结构上加一层用户ID
users/
├── user1/
│ ├── 鲁迅/
│ └── 凌云/
├── user2/
│ ├── 鲁迅/
│ └── 助手小M/
- 认证系统:需要登录才能使用
- 数据隔离:每个用户只能看到自己的智能体和聊天记录
思考: 这个功能现在不做,但架构上要留好扩展点。比如所有API都加上userId参数(默认为’local’),数据访问层根据userId拼接路径。
问题五:AI API调用失败怎么办?
网络可能不稳定,API可能限流,模型可能超时。这些都是不可控的。
容错设计:
- 重试机制:失败后自动重试,最多3次
- 降级方案:如果API完全不可用,返回友好提示
- 日志记录:记录失败详情,便于排查
async function callAIWithRetry(messages, retries = 3) {
for (let i = 0; i < retries; i++) {
try {
return await callAI(messages);
} catch (error) {
if (i === retries - 1) throw error;
await sleep(1000 * Math.pow(2, i)); // 指数退避
}
}
}
🎯 第七部分:本篇小结与下篇预告
本篇我们做了什么?
- 发现问题:剖析了现有AI聊天系统的四大痛点
- 明确需求:将痛点转化为具体的功能需求
- 方案对比:分析了多种实现方案的优缺点
- 技术选型:解释了为什么选择Node.js+原生JS+文件系统
- 架构设计:画出了系统架构图,定义了各层职责
- 深度思考:预演了可能遇到的问题和解决方案
读者应该收获了什么?
- ✅ 理解“文件夹即智能体”的核心设计思想
- ✅ 学会如何从需求推导出架构设计
- ✅ 掌握技术选型的基本方法论
- ✅ 具备预见问题和设计容错的能力
- ✅ 对后续的编码实现有清晰的认知
下篇预告
第二篇:地基搭建——从零开始写第一行代码
下一篇,我们将真正开始动手编码,实现:
- Express服务器的搭建
- 第一个API接口:
GET /api/agents - 文件扫描和智能体发现
- 用
curl测试接口
我们会把这一篇的设计思路,一行一行变成代码。
📝 写在最后
写代码之前,先用足够的时间思考,这是优秀程序员和普通程序员的分水岭。
普通程序员接到需求就开写,写到一半发现结构不对,推倒重来。如此反复,身心俱疲。
优秀程序员先用七分时间思考,三分时间编码。想清楚了再动手,一气呵成。
这一篇我们用了七分时间思考,下一篇,就是那三分时间的编码。
期待和你一起,把MultiMind从想法变成现实。
思考题:如果你来设计这个系统,你会有什么不同的想法?欢迎在评论区分享你的思路。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)