李飞飞&李曼玲空间智能新作:首次量化具身智能的空间认知能力 | ICLR 2026
这项研究的开创性价值,在于跳出传统 “被动推理” 或 “任务驱动” 的评估框架,提出首个聚焦 “空间信念构建” 的专属体系,将自主探索本身作为核心研究对象,还通过认知地图探测打破模型黑箱。研究表明,提供距离和角度参考图像可小幅提升性能,但仍需从模型架构层面优化——例如引入专门的视觉空间注意力机制,或预训练视觉-空间关系的映射能力,减少感知噪声对信念构建的干扰。:通过“虚假信念范式”(探索后移动/旋

首次系统地审视模型的“主动空间智能”
——行业性“出厂缺陷”
目录
大模型在被动感知任务上的表现早已无需赘述,但当它们需要像人类一样主动探索、构建空间认知时,究竟行不行?
美国西北大学李曼玲团队联合斯坦福李飞飞、吴佳俊等发表于ICLR 2026的研究《THEORY OF SPACE》,首次系统性地撕开了这一盲区,填补了具身智能空间认知的评估体系空白。
这项研究的开创性价值,在于跳出传统 “被动推理” 或 “任务驱动” 的评估框架,提出首个聚焦 “空间信念构建” 的专属体系,将自主探索本身作为核心研究对象,还通过认知地图探测打破模型黑箱。
同时也为空间具身智能的优化指明了方向 ——
模型需要的或许不仅是更多的数据,而是一种主动构建并动态维护世界模型的根本能力。
01 重构空间智能评估

以往空间智能研究存在两大局限:
-
一是评估场景脱离“部分可观测”的真实环境,智能体无需主动探索即可获得完整信息;
-
二是将智能体视为黑箱,仅通过最终任务结果推断其空间理解能力,无法追溯错误根源。
THEORY OF SPACE的核心创新,在于建立了一套“任务无关的主动探索+显式信念探测”的评估体系,实现了三大突破:
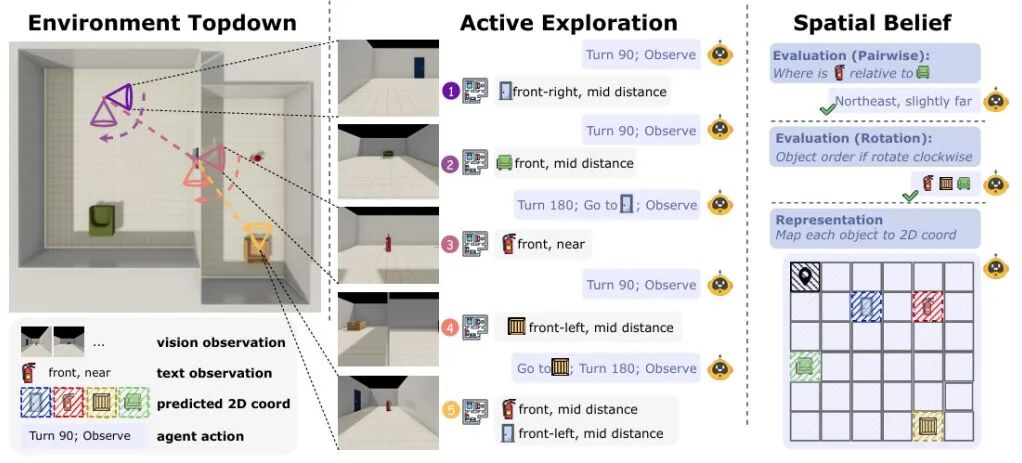
▲图|THEORY OF SPACE 框架的整体示意图
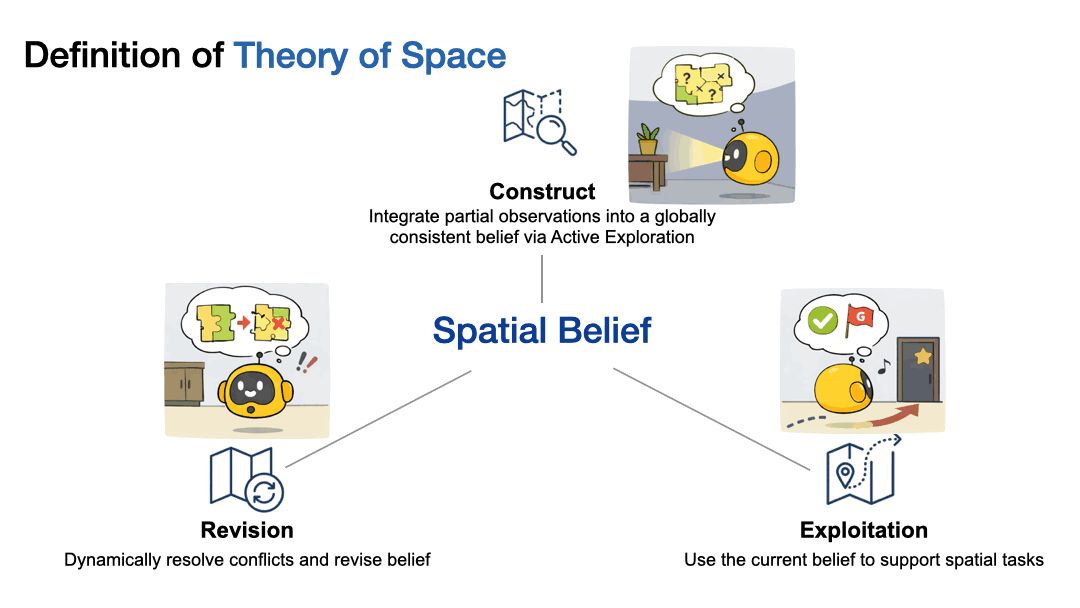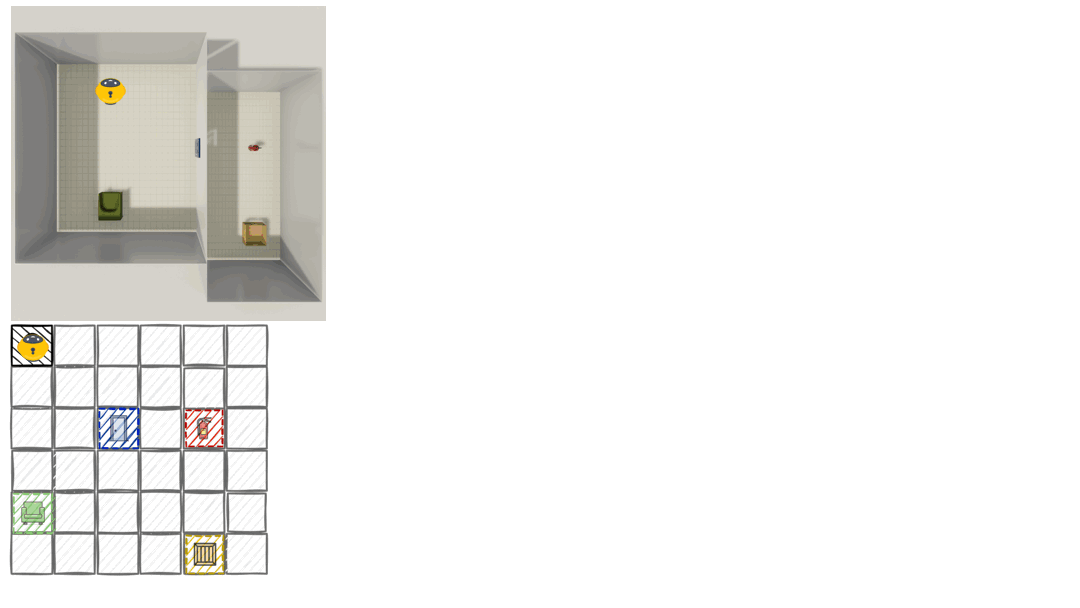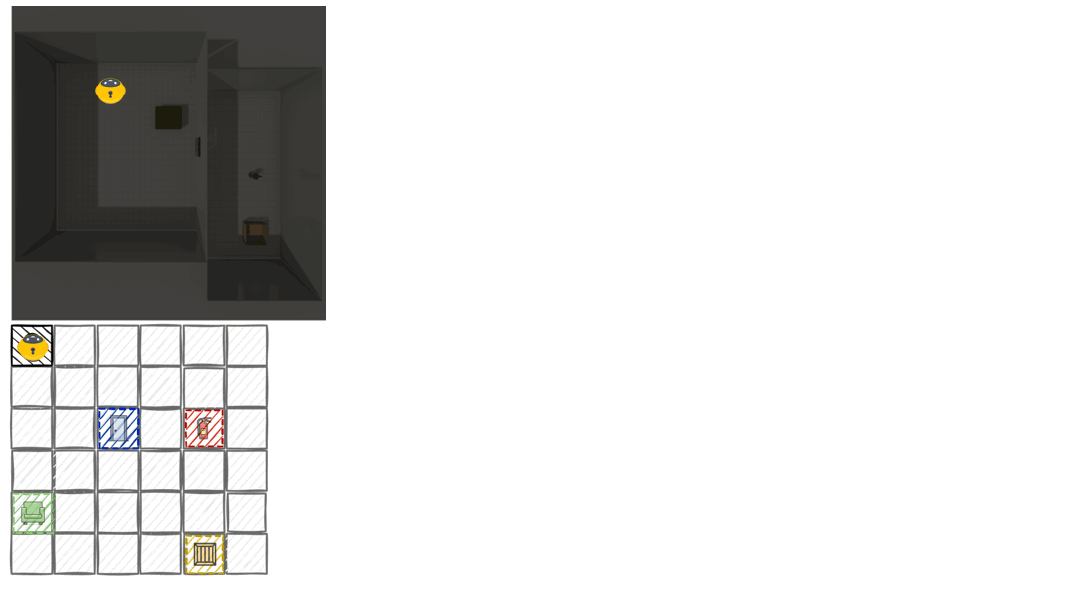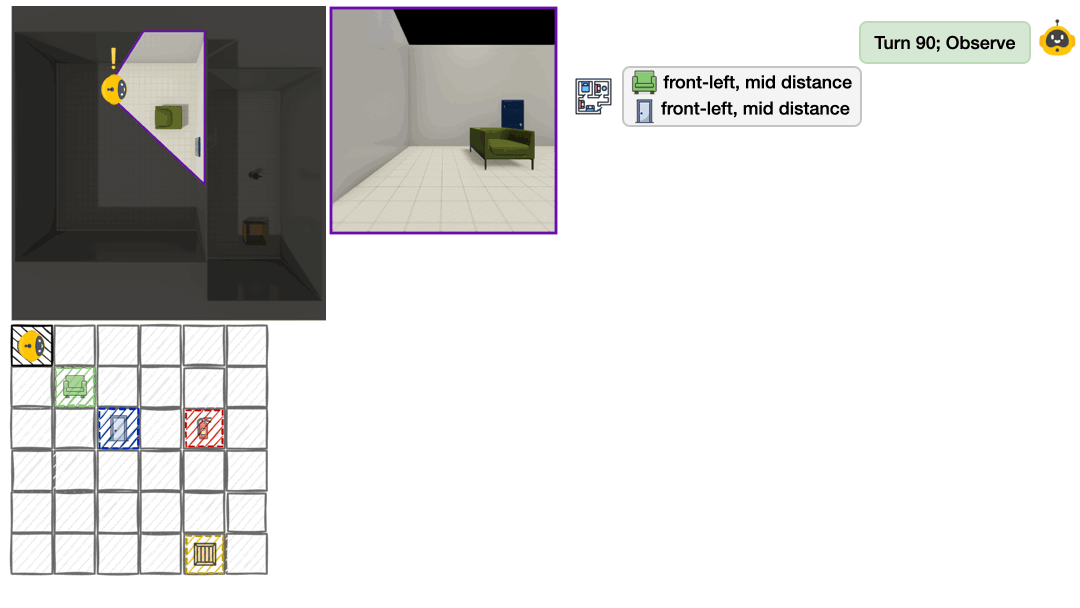
定义THEORY OF SPACE:空间信念的三大核心操作
研究将THEORY OF SPACE定义为:
智能体通过自主探索,从序列化、部分观测中构建、修订并利用内部空间信念的能力。
这一能力包含三个关键操作:
-
构建(Construct):主动收集部分观测信息,整合为全局一致的空间信念,本质是对环境真实空间结构的概率逼近;
-
修订(Revise):在环境发生变化时,通过进一步探索解决新观测与原有信念的冲突,更新内部模型;
-
利用(Exploit):运用已有的空间信念完成各类空间任务,体现信念的实用价值。
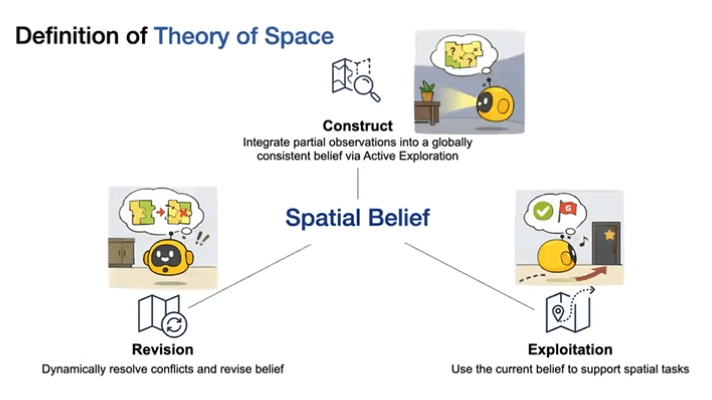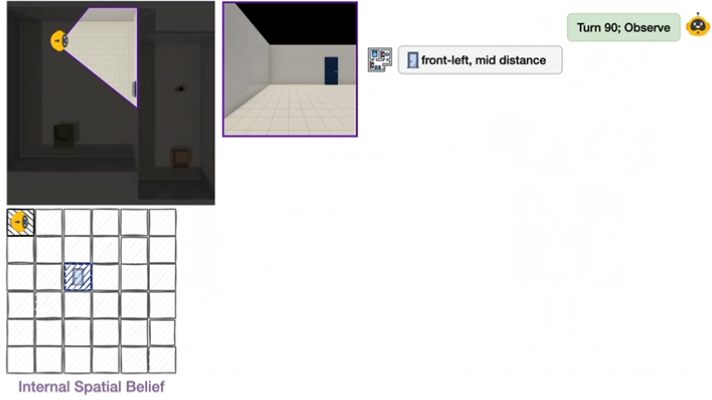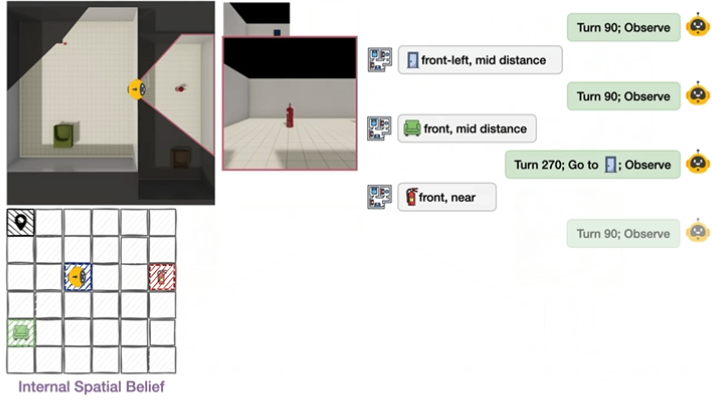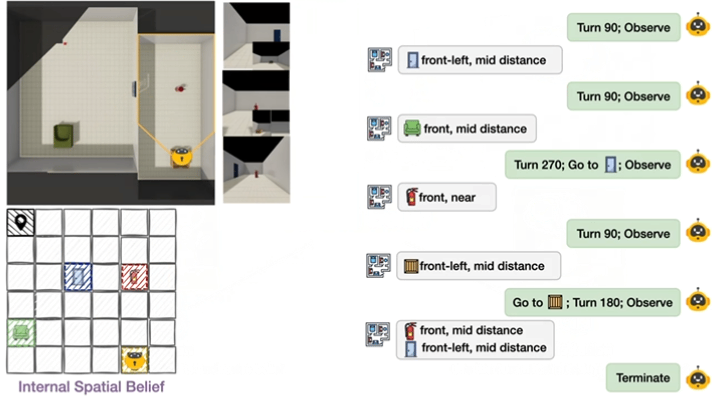
▲空间理论分解为构建、修正和利用internal spatial belief.
这一定义与“心理理论(Theory of Mind)”形成概念呼应——
后者聚焦建模他人的隐藏心理状态,前者则聚焦建模物理世界的隐藏空间结构。
共同构成智能体与世界交互的核心认知能力。
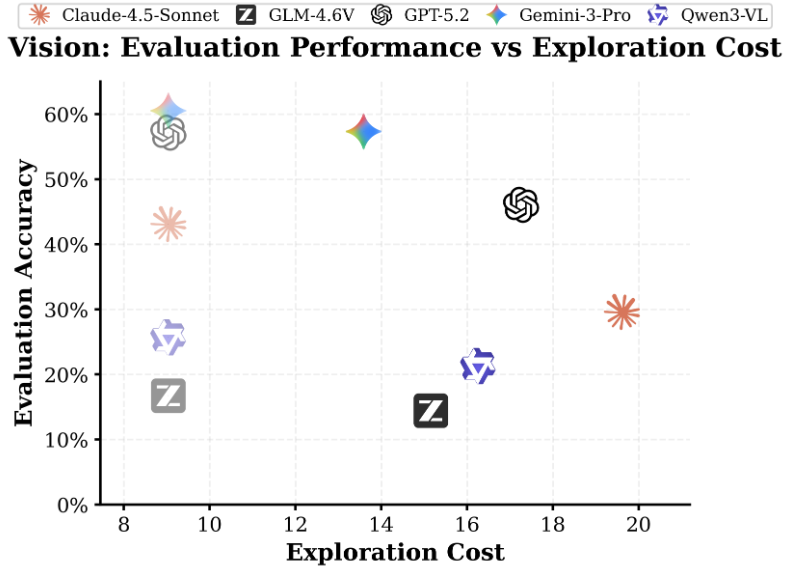
▲图| 视觉任务:评估性能 vs 探索成本
双环境基准设计:分离感知与推理的失败根源
为精准定位模型失效原因,研究构建了文本和视觉并行的多房间环境:
-
文本世界(Text World):提供符号化观测(如“椅子在左前方,近距离”),剥离感知干扰,仅测试纯空间推理能力;
-
视觉世界(Vision World):通过ThreeDWorld引擎生成第一视角RGB图像,要求模型从视觉信息中提取空间关系,同时测试感知与推理能力。
两种环境共享相同的空间布局和任务设计,使得研究能够清晰区分模型失败是源于视觉感知缺陷,还是核心推理能力不足。
这一设计解决了以往多模态模型评估中“感知与推理故障难以拆解”的痛点。
认知地图探测:打开空间信念的“黑箱”
传统评估仅关注任务结果,无法判断模型是“真理解”还是“假正确”。
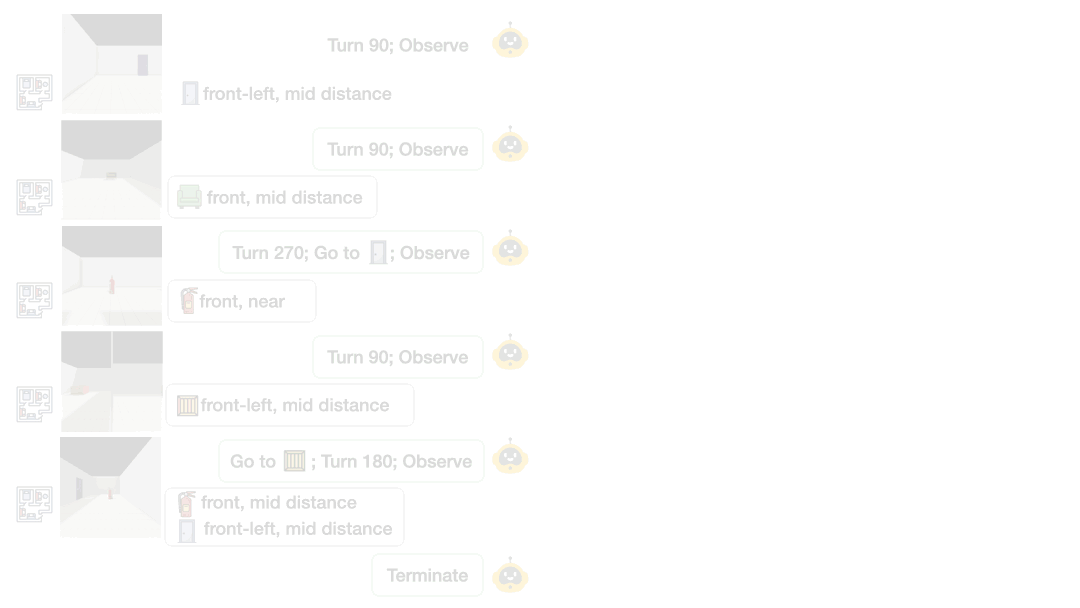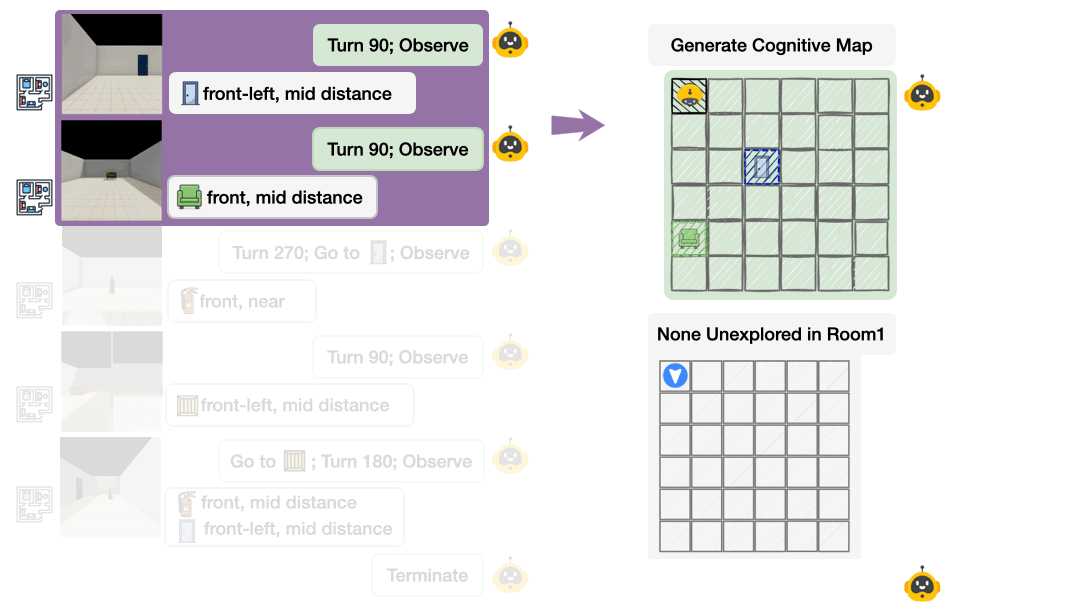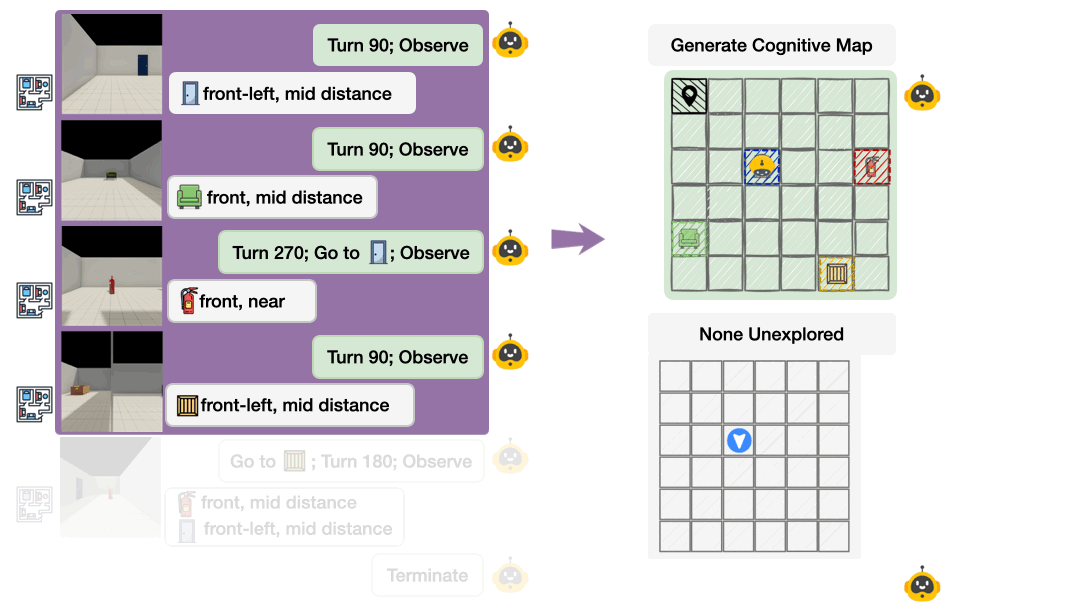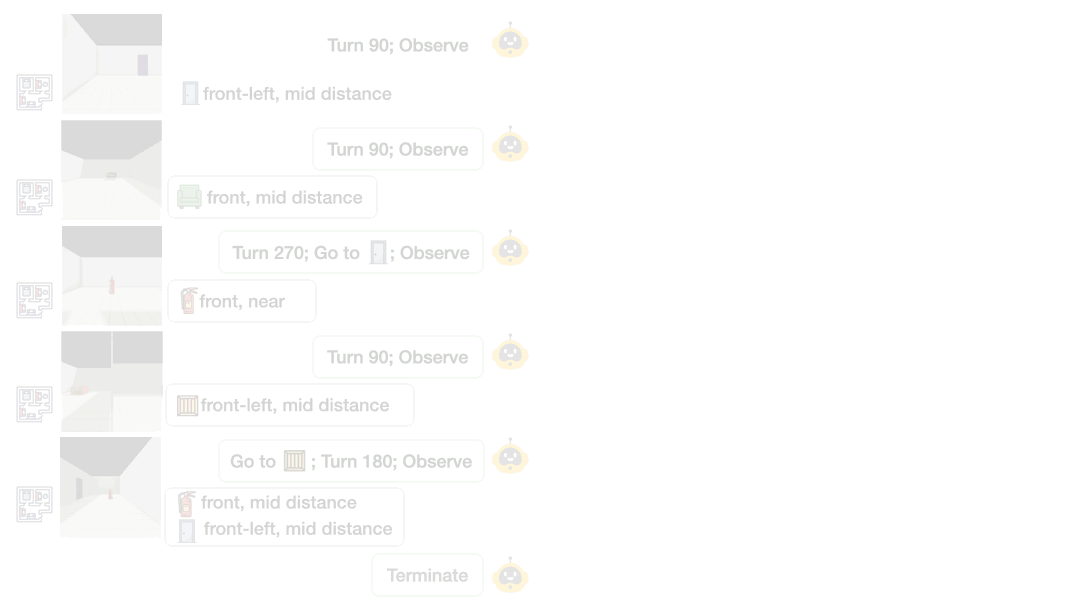
THEORY OF SPACE引入了空间信念探测机制:在探索的每一步,要求模型输出结构化的认知地图(以JSON格式呈现),包含物体的2D坐标、朝向等关键信息。通过这一机制,研究可以直接衡量:
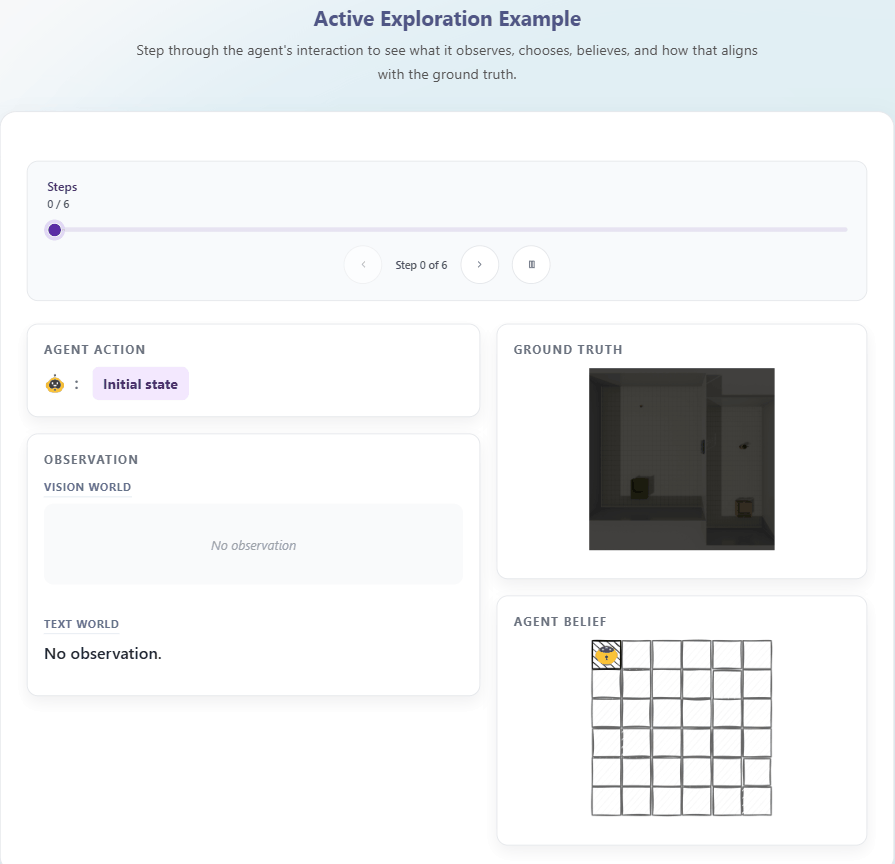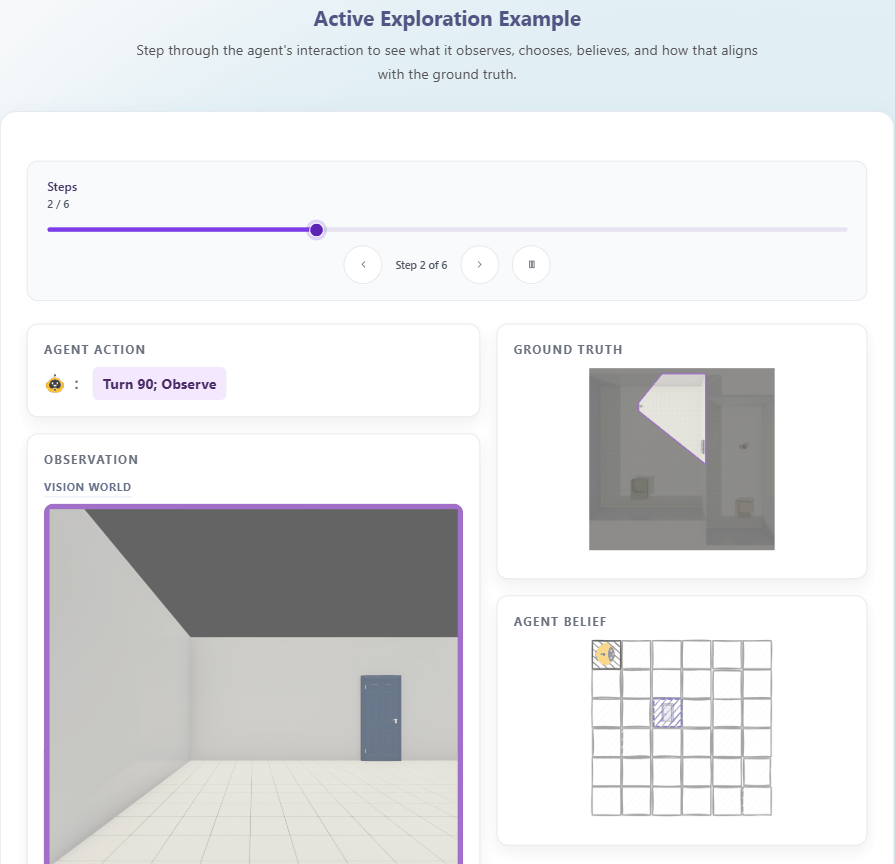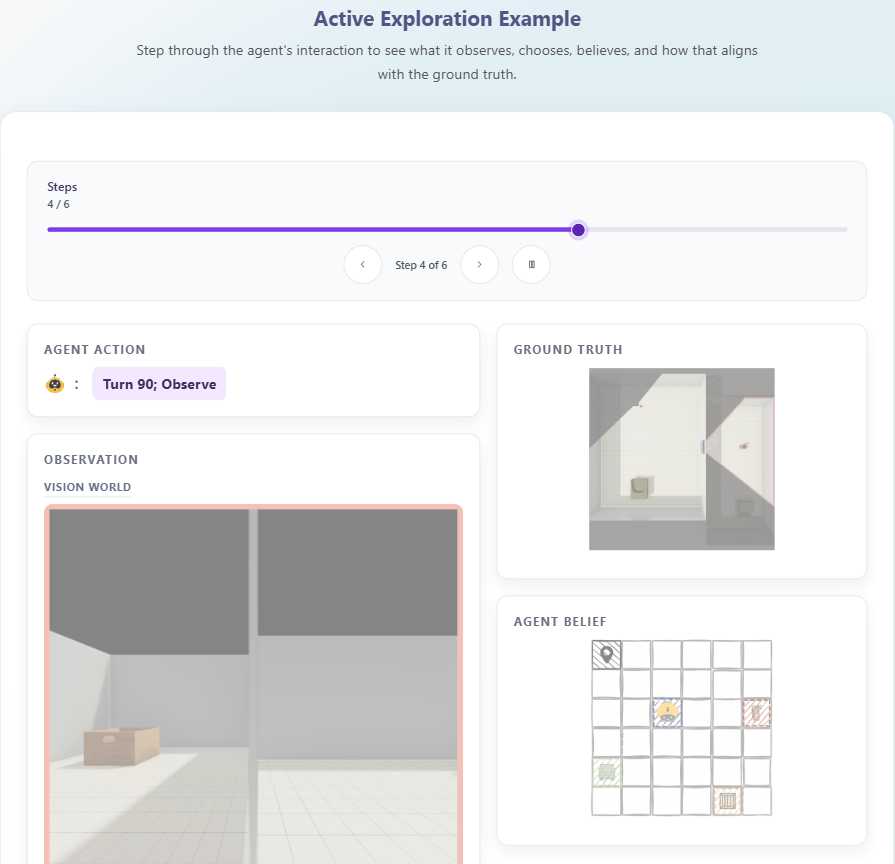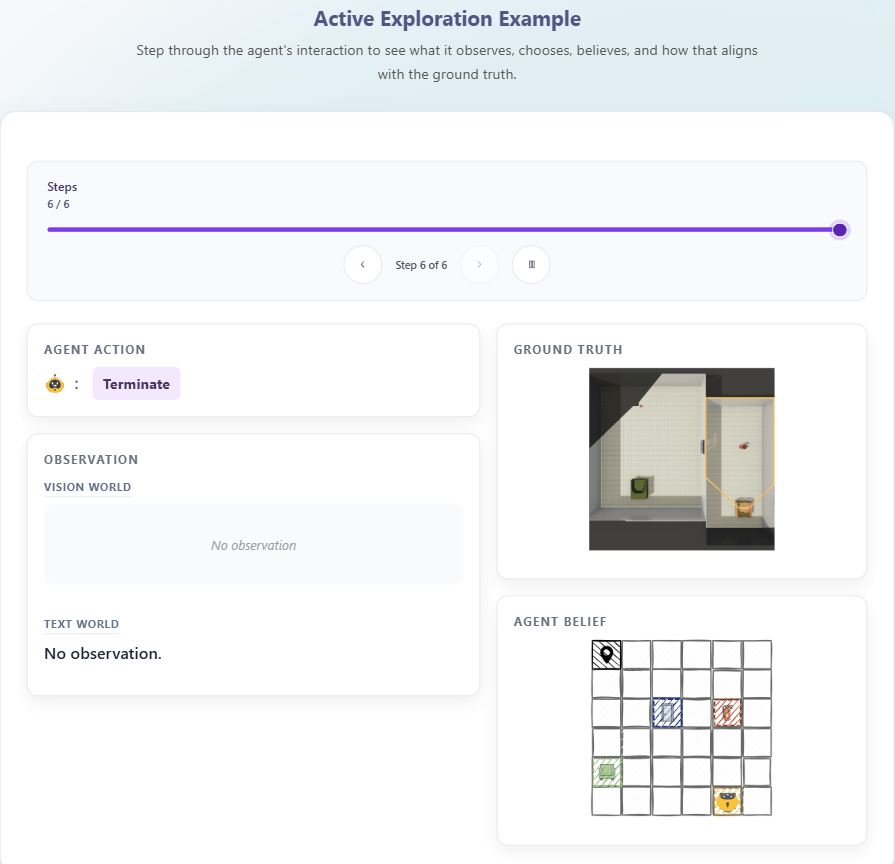
-
信念正确性:预测的空间关系与真实环境的吻合度;
-
信念稳定性:已正确感知的空间信息是否会随后续探索退化;
-
不确定性建模:模型能否准确识别未探索区域。
这种“过程+结果”的双重评估,让空间信念从不可观测的内部状态,转变为可量化、可分析的诊断指标。
02 任务设计与评估维度
THEORY OF SPACE的基准设计围绕“探索-推理”两阶段展开,通过多样化任务和多维度评估,全面覆盖空间智能的核心能力:
探索阶段:任务无关的自主信息收集
智能体需在部分可观测的多房间环境中,自主选择“移动(Goto)”“旋转(Rotate)”“观测(Observe)”等动作。
目标是以最少步骤构建完整、准确的空间信念,而非完成特定任务。
这一设计模拟了人类“好奇心驱动的探索”行为,重点评估模型的不确定性感知和探索策略优化能力。

▲图| 文本世界
为分离探索与推理能力,研究还设计了两种脚本代理(SCOUT和STRATEGIST)作为基准:
前者通过360度旋转确保全覆盖观测,后者基于不确定性主动选择最优观测视角。
通过对比模型与脚本代理的表现,可精准判断模型失败是源于探索策略低效,还是推理能力不足。

▲图| 将探索能力与推理能力分开
推理阶段:覆盖路线级与测绘级的空间任务
探索结束后,模型需完成两类空间任务,全面评估信念利用能力:
-
路线级信念任务(Route Belief):
基于自我中心视角的路径推理,如判断两个物体的相对方向、根据动作序列预测最终观测等,考验分步式空间推理能力;
-
测绘级信念任务(Survey Belief):
基于鸟瞰视角的全局映射,如预测所有物体的2D坐标、通过旋转推理物体出现顺序等,考验全局空间抽象能力。
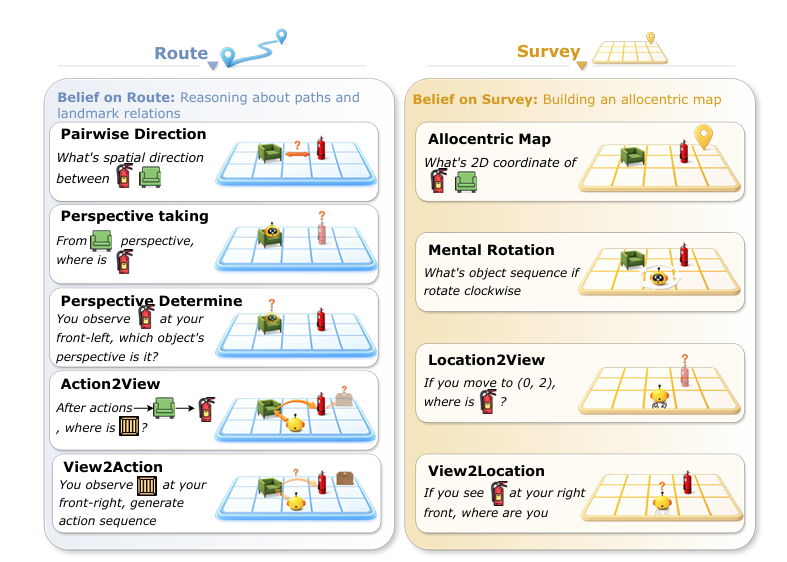
▲图| 空间利用任务套件:路线级自我中心推理与勘测级异中心地图构建
所有任务均采用开放式问答设计,避免模型通过选项猜测答案,确保评估结果的真实性。
五维度评估:量化信念构建的全流程
研究从五个维度构建了完整的评估体系,覆盖信念构建、修订、利用的全流程:
(1)信念构建效率:衡量模型减少空间不确定性的速度,文本环境中采用信息增益 metric,视觉环境中采用节点覆盖率;
(2)认知地图质量:包括信念正确性(位置、方向、朝向的准确率)和动态指标(感知精度、自我定位精度、信念稳定性等);
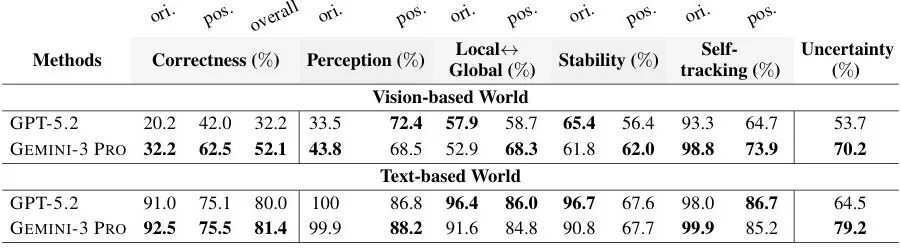
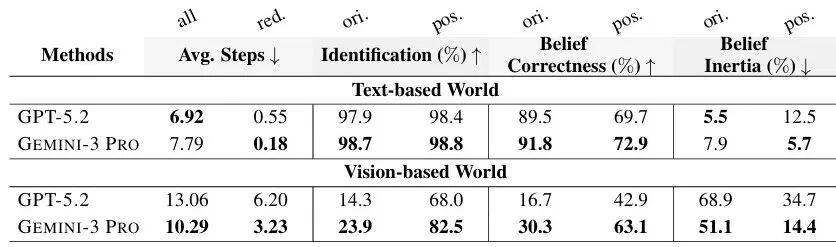
▲图| 认知地图质量核心数据表
(3)不确定性建模:评估模型识别未探索区域的能力,通过F1分数量化;
(4)信念修订能力:通过“虚假信念范式”(探索后移动/旋转物体)测试模型更新过时信念的能力,定义“信念惯性”指标衡量模型对旧有信念的依赖程度;
(5)信念利用成功率:各类空间任务的完成精度,如方向判断准确率、坐标预测相似度等。
03 四大空间推理瓶颈
通过对GPT-5.2、Gemini-3 Pro、Claude-4.5 Sonnet等6款主流大模型的评估,研究揭示了当前大模型在空间主动探索中的核心缺陷:
主动-被动性能鸿沟(Active-Passive Gap)
所有模型在主动探索场景中的表现均显著低于被动场景:
-
GPT-5.2在视觉世界的被动推理准确率为57.1%,而主动探索准确率仅46.0%;
-
Gemini-3 Pro从60.5%降至57.3%。
这一差距表明,即使模型具备较强的空间推理能力,也难以自主规划高效的探索路径——
“知道如何推理”不等于“知道该探索什么”。
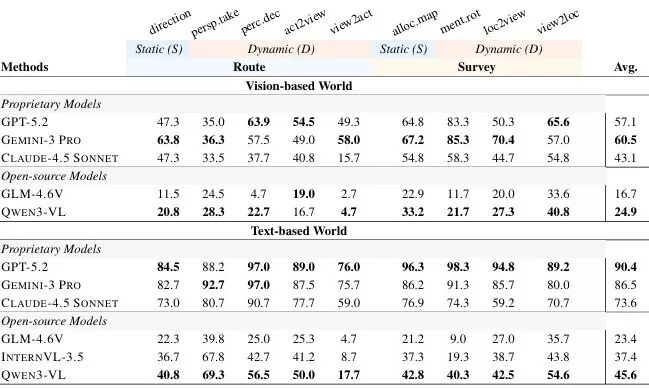
▲图| 基于被动观测的信念构建利用性能对比(%)
探索效率低下,存在严重冗余
规则脚本代理(SCOUT/STRATEGIST)仅需约9步即可实现目标覆盖,而大模型平均需要14步以上,且步数增加并未带来信念精度的提升。
不同模型呈现出不同的低效探索模式:
-
GPT-5.2倾向于发现门后立即跳转,导致当前房间探索不完整;
-
Claude-4.5 Sonnet则缺乏明确探索策略,存在大量重复观测。
模态鸿沟显著,视觉感知成为致命短板
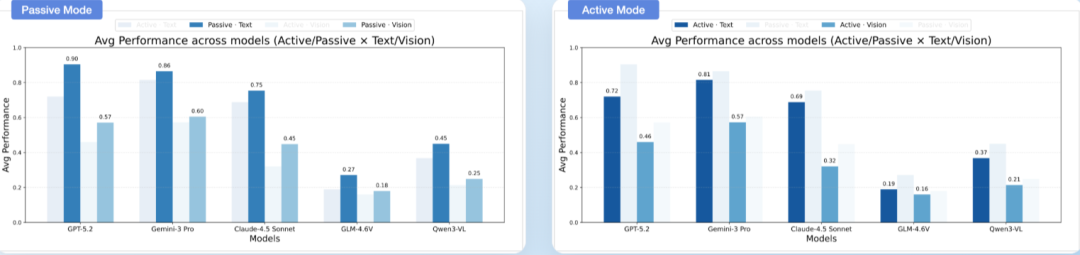
▲图| 基于文本的环境在空间信念建构和利用方面始终优于基于视觉的环境
文本世界中,顶尖模型(如Gemini-3 Pro)的平均任务准确率可达81.5%,而视觉世界中最高仅57.3%。
认知地图探测显示,视觉环境中的模型面临双重困境:
-
一是物体朝向感知准确率接近随机水平,导致视角转换任务表现极差;
-
二是信念稳定性不足,即使初始观测正确,后续更新也可能覆盖正确信息,出现“信念漂移”现象。
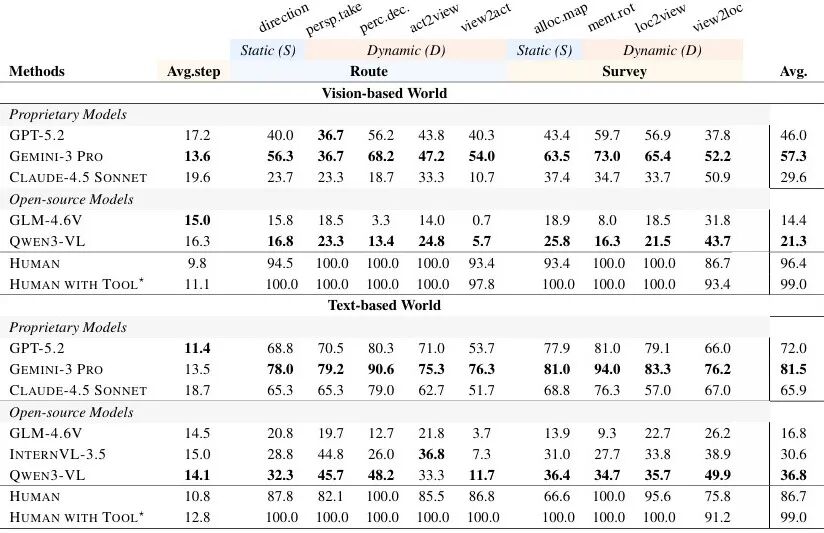
▲图| 文本与视觉世界中,模型在探索成本、路线级推理及勘测级推理上的表现评估
信念惯性(Belief Inertia):难以更新过时信念
在虚假信念任务中,模型普遍存在“旧信念依赖”:
即使通过新观测发现物体位置或朝向已改变,仍倾向于维持初始信念。
这一现象在视觉模型中尤为严重:
GPT-5.2在视觉环境中的位置信念惯性达68.9%,朝向信念惯性达34.7%,而文本环境中分别仅为5.5%和12.5%。
这表明模型缺乏对空间变化的敏感性和信念更新的灵活性。
▲图| 文本与视觉世界中,智能体在变化检测、重探索成本及信念正确性上的表现评估
04 空间智能研究优化方向
THEORY OF SPACE的价值不仅在于提供了一套标准化评估工具,更通过精细化诊断,为后续大模型空间智能优化指明了三大方向:
优化探索策略:不确定性感知与高效路径规划
当前模型探索低效的核心原因,是缺乏对“未知区域”的精准判断。
未来研究可引入不确定性量化模块,让模型明确自身空间知识的缺口,优先探索信息增益最大的区域;同时借鉴脚本代理的“旋转-扫描-推进”策略,减少路径冗余。
增强视觉空间感知:聚焦朝向与距离的精准提取
视觉模型的最大短板是从图像中提取精确空间关系。
研究表明,提供距离和角度参考图像可小幅提升性能,但仍需从模型架构层面优化——例如引入专门的视觉空间注意力机制,或预训练视觉-空间关系的映射能力,减少感知噪声对信念构建的干扰。
设计稳健的信念更新机制:缓解信念惯性与漂移
针对信念不稳定和惯性问题,可在模型训练中引入“动态环境适应”任务,强化模型对空间变化的敏感度;
同时采用增量更新而非全盘重写的信念维护策略,保护已验证的正确空间信息,仅修正与新观测冲突的部分。
05 空间智能研究的下一步
THEORY OF SPACE虽构建了全面的空间智能评估体系,但仍存在局限:
仅聚焦单智能体探索,未涉及多智能体空间信念共享与协调;
环境变化仅涵盖物体移动、旋转,未覆盖形变、遮挡等复杂动态场景;
信念探测依赖结构化JSON输出,存在模型潜在信念与外部化表达不一致的鸿沟。
未来研究可从三方面拓展:
延伸至多智能体协作场景、引入复杂动态环境、优化信念探测方式以降低信息损失;
同时,大模型在主动探索、视觉感知与信念更新上的瓶颈,也暴露了其被动推理与主动交互能力的巨大差距。
同步优化探索策略、感知精度与信念稳定性,才能进一步让大模型具备真实环境中的自主空间智能。
Ref
论文题目:Theory of Space: Can Foundation Models Construct Spatial Beliefs through Active Exploration?
论文作者:Pingyue Zhang, Zihan Huang, Yue Wang, Jieyu Zhang, Letian Xue, Zihan Wang, Qineng Wang, Keshigeyan Chandrasegaran, Ruohan Zhang, Yejin Choi, Ranjay Krishna, Jiajun Wu, Li Fei-Fei, Manling Li
论文地址:https://arxiv.org/pdf/2602.07055
项目地址:https://theory-of-space.github.io/
代码地址:https://github.com/mll-lab-nu/Theory-of-Space

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 19
19 0
0- 0



 已为社区贡献88条内容
已为社区贡献88条内容

所有评论(0)