HoloBrain-0:地平线开源的具身智能VLA框架深度解读
摘要: 2025-2026年,具身智能领域正从模块化架构转向端到端的视觉-语言-动作(VLA)模型。地平线机器人实验室开源的HoloBrain-0框架解决了当前VLA模型的三大痛点:1)通过RoboOrchard基础设施降低数据采集成本;2)引入摄像头参数和运动学先验实现跨本体泛化;3)采用异步推理减少动作延迟。该框架包含0.2B参数的轻量级版本和1.1B参数的高性能版本,通过分层设计(VLM骨干
1. 引言:具身智能走到了什么阶段
2025年至2026年,具身智能(Embodied AI)领域正在经历一场深刻的范式转换。传统的机器人系统依赖感知、状态估计、运动规划、控制等模块化流水线,虽然在结构化环境中表现尚可,但面对开放世界的复杂场景时,这种"拼积木"式的架构暴露出严重的泛化瓶颈。与此同时,视觉-语言-动作模型(Vision-Language-Action, VLA)的兴起为机器人智能提供了一条端到端的新路径——将视觉感知、语言理解和动作控制统一到单一神经网络中,让机器人能够直接从原始观测和自然语言指令生成低层控制信号。
Physical Intelligence 公司发布的 pi_0 和 pi_0.5 模型率先验证了这一范式的可行性,展示了通用机器人策略在多任务、多本体场景下的潜力。NVIDIA 的 GR00T-N1、开源社区的 OpenVLA 等工作也在不断推进这一方向。然而,将 VLA 模型从实验室演示推向大规模商业化部署,仍然面临三个核心瓶颈:训练数据采集成本高昂、跨本体泛化能力不足、以及模型推理延迟导致的动作卡顿。对应Github项目。
正是在这一背景下,地平线机器人实验室于2026年2月开源了 HoloBrain-0 框架。这不是一个孤立的模型发布,而是一套完整的生态系统——包含预训练基础模型、后训练检查点、以及名为 RoboOrchard 的全栈基础设施。其最小版本仅有 0.2B 参数,却能在多个仿真和真实世界基准测试中达到或超越参数量大数倍的竞品。
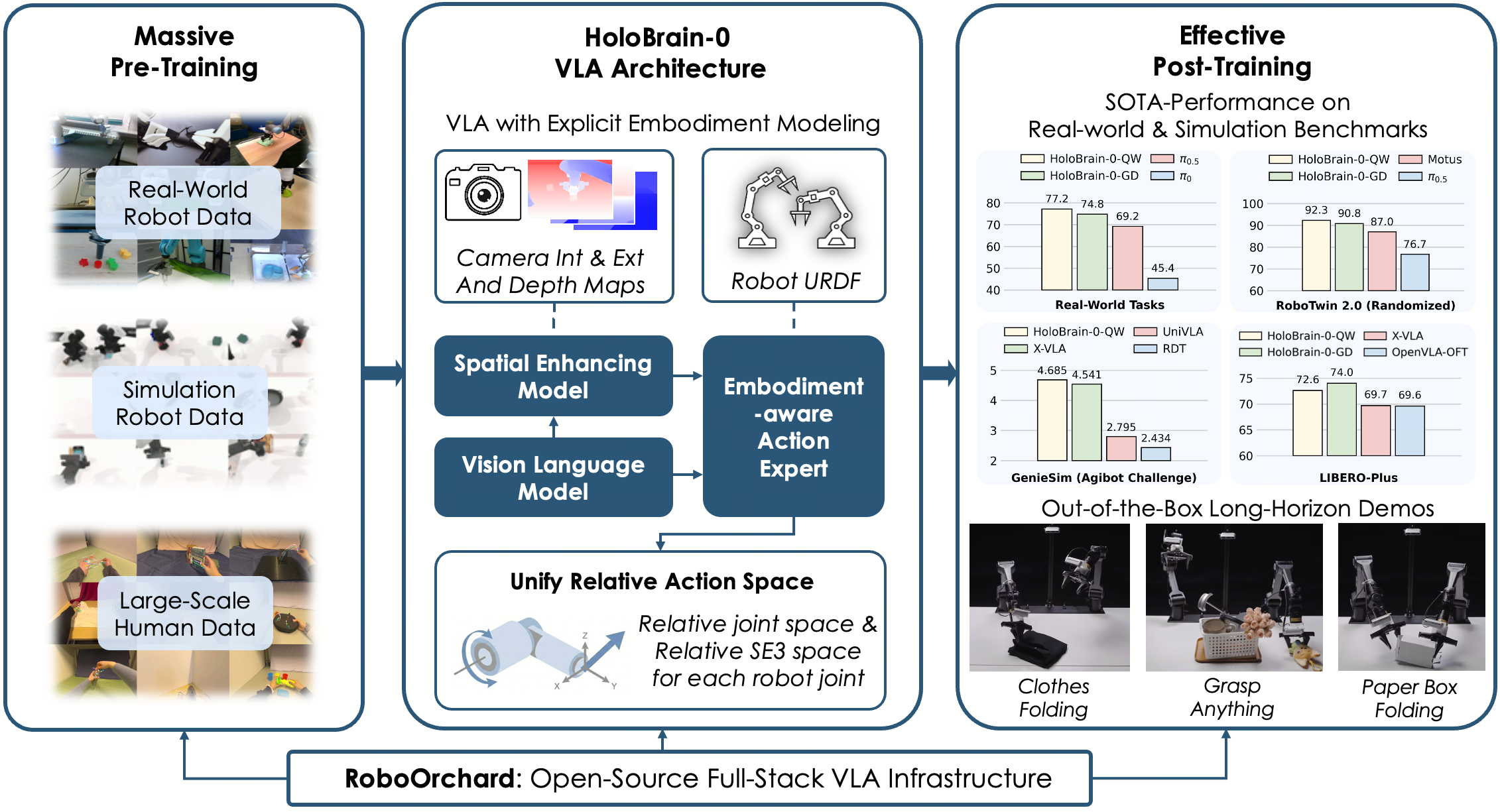
图1:HoloBrain-0 系统总览。通过显式具身建模(摄像头参数与运动学描述),模型能够统一训练来自异构机器人的数据。配合全栈基础设施 RoboOrchard 和测试驱动的数据策略,HoloBrain-0 在真实世界和仿真操作基准测试中均取得了领先性能。
2. 传统VLA的三大痛点
在深入 HoloBrain-0 的技术细节之前,有必要先理解它试图解决的问题。当前主流 VLA 模型在走向规模化落地时,普遍面临以下三个结构性挑战:
第一,数据采集成本居高不下。 高质量的机器人操作演示数据需要人类操作员通过遥操作系统逐条采集,每条轨迹通常需要数十秒到数分钟。对于复杂的长时程任务(如叠衣服、折纸盒),一个任务可能需要数千条演示才能训练出可用的策略。更棘手的是,朴素的数据扩展策略效率递减——随着数据量增加,新增数据中包含的有效信息密度不断下降。
第二,跨本体泛化能力薄弱。 大多数 VLA 模型将机器人本体视为黑盒,直接学习从视觉观测到关节动作的映射。这意味着在一个机器人平台上训练的策略,换到另一个平台(即使是同类型但不同型号的机械臂)时,往往需要重新采集数据、重新训练。不同机器人的关节零位定义、旋转方向、URDF 描述各不相同,这些差异在隐式学习中会造成严重的分布偏移。
第三,推理延迟导致动作不连贯。 当前主流 VLA 模型参数量通常在 3B 到 7B 之间,单次推理耗时可达数百毫秒甚至超过一秒。在同步推理模式下,机器人必须等待模型输出完整的动作序列后才能执行,这导致明显的"停顿-执行-停顿"节奏,无法胜任需要流畅连续动作的精细操作任务。
3. 问题形式化:条件动作生成
HoloBrain-0 将机器人操作任务形式化为一个条件动作生成问题。在每个时间步,系统接收以下输入:
- 多视角 RGB 图像 I ∈ R N × H × W × 3 I \in \mathbb{R}^{N \times H \times W \times 3} I∈RN×H×W×3 及对应深度图 D ∈ R N × H × W × 1 D \in \mathbb{R}^{N \times H \times W \times 1} D∈RN×H×W×1
- 机器人当前本体感受状态(关节状态) S ∈ R N j S \in \mathbb{R}^{N_j} S∈RNj
- 自然语言任务指令 T T T
- 摄像头参数 C C C(内参与外参)
- 机器人运动学先验 E E E(URDF 描述)
完整输入空间定义为:
{ I , D , S , T } ∪ { C , E } \{I, D, S, T\} \cup \{C, E\} {I,D,S,T}∪{C,E}
给定这些输入,模型生成后续 t o u t t_{out} tout 步的动作序列 S o u t ∈ R N j × t o u t S_{out} \in \mathbb{R}^{N_j \times t_{out}} Sout∈RNj×tout。
这个形式化的关键创新在于 { C , E } \{C, E\} {C,E} 的引入——传统 VLA 模型的输入空间中不包含摄像头参数和运动学描述,而 HoloBrain-0 将这些物理先验显式地纳入模型输入,这是其实现跨本体泛化的基础。用 Python 伪代码表达这一输入构造过程:
@dataclass
class MultiArmManipulationInput:
"""多臂操作流水线的输入数据结构,定义了策略所需的各模态输入。"""
image: dict[str, list[TENSOR_TYPE]] | None = None
"""摄像头名称 → RGB 图像列表,支持多视角"""
depth: dict[str, list[TENSOR_TYPE]] | None = None
"""摄像头名称 → 深度图列表"""
intrinsic: dict[str, TENSOR_TYPE] | None = None
"""摄像头名称 → 内参矩阵"""
t_world2cam: dict[str, TENSOR_TYPE] | None = None
"""摄像头名称 → 世界坐标系到相机坐标系的变换矩阵(外参)"""
t_robot2world: TENSOR_TYPE | None = None
"""机器人基座坐标系到世界坐标系的变换"""
t_robot2ego: TENSOR_TYPE | None = None
"""机器人基座坐标系到自我中心坐标系的变换"""
history_joint_state: list[TENSOR_TYPE] | None = None
"""历史关节状态序列(本体感受历史)"""
instruction: str | None = None
"""自然语言任务指令"""
urdf: str | None = None
"""机器人 URDF 描述(运动学与动力学先验)"""
remaining_actions: TENSOR_TYPE | None = None
"""上一步未执行完的动作序列(SimpleRTC 使用)"""
delay_horizon: int | None = None
"""动作执行延迟步数(SimpleRTC 使用)"""
4. 模型架构:三大核心模块
HoloBrain-0 的整体架构由三个核心模块组成,形成一个端到端的推理流水线。
4.1 视觉-语言骨干网络(VLM Backbone)
作为语义推理的"大脑",HoloBrain-0 提供了两种 VLM 骨干选择:
- GroundingDINO Tiny:一个 2D 检测基础模型,用于构建轻量级的 HoloBrain-0-GD 版本(总参数 0.2B)
- Qwen2.5-VL-3B:一个基于 LLM 的视觉-语言模型,用于构建更强大的 HoloBrain-0-QW 版本(总参数 1.1B)
值得注意的是,对于 Qwen2.5-VL-3B,团队冻结了视觉编码器和文本编码器以保留预训练能力,并且只保留了 LLM 的第一层 Transformer,丢弃了后续所有层。这一激进的裁剪策略大幅降低了计算开销,同时保留了足够的语义表征能力。
| 模型版本 | 视觉编码器 | 语言模型 | 空间增强器 | 动作专家 | 可训练参数 | 总参数 |
|---|---|---|---|---|---|---|
| HoloBrain-0-GD | 29.64M | 130.80M | 2.28M | 20.79M | 74.81M | 183.70M |
| HoloBrain-0-QW | 668.68M | 388.24M | 2.09M | 20.79M | 412.17M | 1080.86M |
表1:两个版本的参数量对比。动作专家模块仅有约 20M 参数,体现了"VLM 负责语义推理、动作专家专注执行"的分层设计哲学。
4.2 透视感知空间增强器(Spatial Enhancer)
空间增强器是连接 2D 视觉语义与 3D 空间几何的桥梁。它利用摄像头内外参数和深度图,将多视角的 2D 图像特征沿各自的摄像头视锥投影到统一的 3D 坐标系中。
具体而言,该模块:
- 利用摄像头内外参数采样 3D 点
- 预测离散深度分布(可接入深度传感器输入)
- 聚合生成深度感知的 3D 位置编码
- 将位置编码与图像特征融合,产生全局一致的几何感知 3D 表征
一个关键的设计决策是:将 3D 投影的坐标系从机器人本体基座坐标系改为中心固定摄像头坐标系(如第三人称视角或头戴摄像头视角)。这带来两个重要优势:
- 消除了不同机器人平台因基座定义不一致而导致的学习干扰,实现跨本体泛化
- 能够无缝接入以人为中心的数据(如 EgoDex 数据集),这类数据天然缺少固定的机器人"基座"坐标系,但拥有自然的头戴视角
class DepthFusionSpatialEnhancer(nn.Module):
"""深度融合空间增强器:将多视角 2D 特征投影到统一 3D 空间。"""
def __init__(self, embed_dims=256, feature_3d_dim=32,
num_depth_layers=2, min_depth=0.25,
max_depth=10, num_depth=64, ...):
super().__init__()
# 深度概率预测网络
self.pts_prob_fc = MLP(dim, dim, self.num_depth, self.num_depth_layers)
# 3D 点特征投影层
self.pts_fc = nn.Linear(3, self.feature_3d_dim)
# 多模态融合层
self.fusion_fc = nn.Sequential(
FFN(embed_dims=fusion_dim, feedforward_channels=1024),
nn.Linear(fusion_dim, self.embed_dims),
)
self.fusion_norm = nn.LayerNorm(self.embed_dims)
def forward(self, feature_maps, inputs, feature_3d=None, **kwargs):
feature_2d, spatial_shapes, _ = deformable_format(feature_maps)
# 利用内外参沿视锥采样 3D 点
pts = self.get_pts(
spatial_shapes, inputs["image_wh"],
inputs["projection_mat"], # 摄像头投影矩阵(内参×外参)
feature_2d.device, feature_2d.dtype,
)
# 预测离散深度概率分布
if self.with_feature_3d:
feature_3d = deformable_format(feature_3d)[0]
depth_prob_feat = torch.cat(
[self.pts_prob_pre_fc(feature_2d), feature_3d], dim=-1
)
depth_prob = self.pts_prob_fc(depth_prob_feat).softmax(dim=-1)
feature_fused = [feature_2d, feature_3d]
else:
depth_prob = self.pts_prob_fc(feature_2d).softmax(dim=-1)
feature_fused = [feature_2d]
# 深度感知 3D 位置编码:加权聚合视锥点特征
pts_feature = self.pts_fc(pts)
pts_feature = (depth_prob.unsqueeze(-1) * pts_feature).sum(dim=-2)
# 融合 2D 语义特征与 3D 几何特征
feature_fused.append(pts_feature)
feature_fused = torch.cat(feature_fused, dim=-1)
feature_fused = self.fusion_fc(feature_fused) + feature_2d # 残差连接
feature_fused = self.fusion_norm(feature_fused)
return feature_fused, depth_prob, loss_depth
4.3 具身感知动作专家(Embodiment-Aware Action Expert)
动作专家是 HoloBrain-0 架构中最具创新性的模块。与大多数现有方法直接复用 LLM 结构来生成动作不同,HoloBrain-0 设计了一个专门的动作专家网络,其核心是关节图注意力机制(Joint-Graph Attention)。
输入状态表征的改进。 传统方法将关节角度作为机器人状态的主要表征,但不同机器人的关节零位定义、旋转方向、URDF 规范各不相同,这些差异会严重干扰跨本体学习。HoloBrain-0 采取了一个大胆的策略:遮蔽关节角度信息,仅将每个关节的 6D 位姿(3D 位置 + 四元数旋转)输入模型。
对于第 i i i 个关节,输入状态定义为:
s i = [ − 1 ] ⊕ [ x , y , z , q w , q x , q y , q z ] 如果 m i = 1 (遮蔽) s_i = [-1] \oplus [x, y, z, q_w, q_x, q_y, q_z] \quad \text{如果} \ m_i = 1 \ \text{(遮蔽)} si=[−1]⊕[x,y,z,qw,qx,qy,qz]如果 mi=1 (遮蔽)
s i = [ θ ] ⊕ [ x , y , z , q w , q x , q y , q z ] 否则 s_i = [\theta] \oplus [x, y, z, q_w, q_x, q_y, q_z] \quad \text{否则} si=[θ]⊕[x,y,z,qw,qx,qy,qz]否则
其中二值掩码 m i = 1 m_i = 1 mi=1 表示该关节的标量角度 θ \theta θ 被排除(设为遮蔽值 -1)。在实际实现中,除了夹爪开合度(以米为单位)之外,所有关节角度均被遮蔽。这一设计的核心洞察是:笛卡尔空间中的连杆位姿提供了统一的几何参考,不受具体本体定义的影响。
混合相对动作空间。 在输出端,模型预测每个关节的混合相对变换,同时包含关节角度空间和笛卡尔位姿空间的变化量:
a t = { [ Δ θ , Δ x , Δ y , Δ z , Δ q w , Δ q x , Δ q y , Δ q z ] i ∣ 1 ≤ i ≤ N j } a_t = \{[\Delta\theta, \Delta x, \Delta y, \Delta z, \Delta q_w, \Delta q_x, \Delta q_y, \Delta q_z]_i \mid 1 \leq i \leq N_j\} at={[Δθ,Δx,Δy,Δz,Δqw,Δqx,Δqy,Δqz]i∣1≤i≤Nj}
注意这里预测的是相对变化量而非绝对值,且基于当前机器人状态计算,不做归一化。这种双空间预测带来两个显著优势:一是支持灵活部署,既兼容底层关节位置控制,也兼容高层末端执行器位姿控制;二是便于在异构数据集上训练,包括没有显式关节角度标注的人类视频数据。
def apply_joint_mask(robot_state, joint_mask, constant_value=-1):
"""对关节状态施加遮蔽,将指定关节的角度值设为常数。
Args:
robot_state: [bs, num_joint, num_steps, c]
其中 c >= 1,第 0 通道为关节角度,后续通道为 6D 位姿
joint_mask: [bs, num_joint] 布尔掩码,True 表示遮蔽该关节
constant_value: 遮蔽值,默认 -1
"""
masked_joint_state = torch.where(
joint_mask[..., None, None],
robot_state.new_tensor(constant_value), # 遮蔽 → -1
robot_state[..., :1], # 保留(如夹爪开合度)
)
robot_state = torch.cat(
[masked_joint_state, robot_state[..., 1:]], dim=-1
)
return robot_state
def get_prediction(self, model_pred, hist_robot_state,
joint_scale_shift, joint_mask):
"""将模型输出转换为绝对预测结果,支持四种预测模式。
model_pred: [bs, num_steps, num_joint, c] 模型原始输出
hist_robot_state: [bs, num_hist_steps, num_joint, c] 历史状态
"""
origin_model_pred = model_pred.clone()
if not self.pred_scaled_joint:
model_pred = apply_scale_shift(
model_pred, joint_scale_shift, scale_only=True
)
if self.prediction_type == "relative_joint_relative_pose":
# 混合相对动作空间:关节角度和位姿均为相对变化量
pred = model_pred + hist_robot_state
elif self.prediction_type == "absolute_joint_relative_pose":
pred = torch.cat([
model_pred[..., :1],
model_pred[..., 1:] + hist_robot_state[:, -1:, :, 1:],
], dim=-1)
elif self.prediction_type == "relative_joint_absolute_pose":
pred = torch.cat([
model_pred[..., :1] + hist_robot_state[:, -1:, :, :1],
model_pred[..., 1:],
], dim=-1)
elif self.prediction_type == "absolute_joint_absolute_pose":
pred = model_pred
# 被遮蔽的关节使用原始预测(非相对值)
if joint_mask is not None and self.prediction_type.startswith("relative"):
pred_joint_state = torch.where(
joint_mask[:, None, :, None],
pred[..., :1],
origin_model_pred[..., :1],
)
pred = torch.cat([pred_joint_state, pred[..., 1:]], dim=-1)
return pred
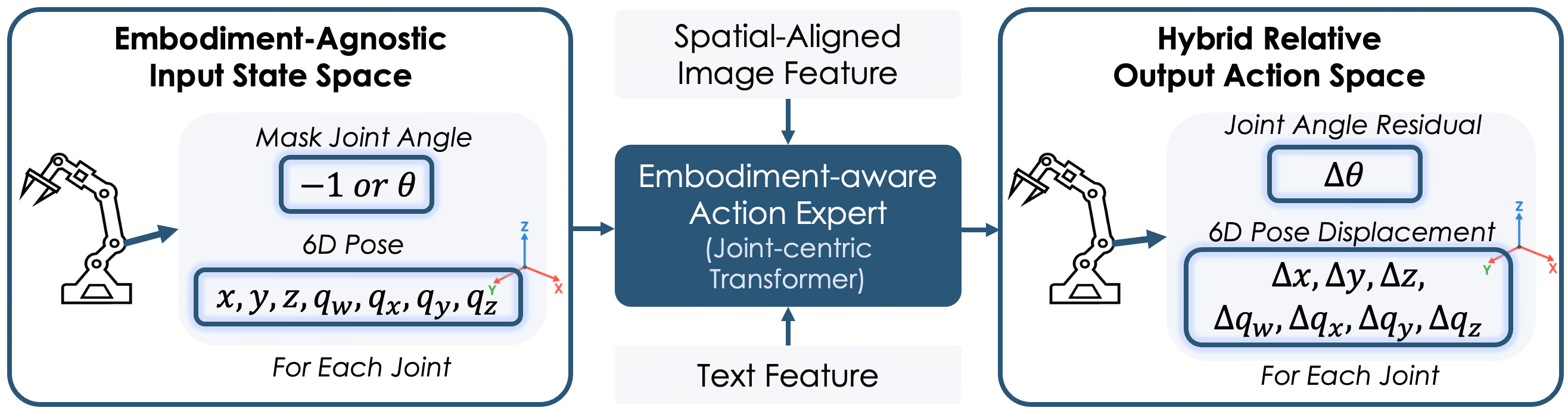
图2:动作专家的输入状态表征与输出动作空间可视化。左侧展示了关节状态的编码方式,右侧展示了混合相对动作空间的预测目标。
…详情请参照古月居

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 19
19 0
0- 0



 已为社区贡献69条内容
已为社区贡献69条内容

所有评论(0)