科研前沿篇---常见数据集规模
面向2026年,数据集规模正在经历"两极分化"的深刻变革:一方面,语言和多模态数据逼近互联网语料的理论上限,万亿token级数据集成为常态;另一方面,工业级推荐系统数据已突破百亿交互量级。以下从分类、检测、预测、推荐、多模态、具身智能六大任务维度梳理当前常见的数据集规模,文末附有Mermaid总结框图。
不同类型任务常见数据集规模全景
1. 图像分类任务
经典规模(万级)
以CIFAR-10/100为代表的经典分类数据集,包含6万张32×32彩色图像,其中5万张训练、1万张测试。这类小规模数据集仍是算法快速验证和教学的首选。
主流规模(百万级)
ImageNet作为计算机视觉的基石,包含超过1400万张标注图像,覆盖2.1万个类别。尽管2010年代就已发布,但截至2026年,ImageNet仍是预训练和迁移学习的核心基准,每年仍在数千篇论文中被引用。
前沿规模(千万级)
Google Open Images Dataset V7包含超过900万张图像,其中1500万个边界框覆盖600个类别,280万个实例分割掩码。这一量级支撑着大规模视觉模型的预训练。
专用大规模(百万级)
ICONIC-444是2026年新发布的工业图像数据集,包含310万张RGB图像,覆盖444个类别,专门用于分布外(OOD)检测研究。
2. 目标检测与分割任务
经典规模(十万级)
Microsoft COCO数据集包含33万张图像,超过150万个对象实例,覆盖80个核心类别。COCO以其丰富的上下文场景和精细的实例分割标注,成为目标检测和分割领域的事实标准,2025年单年被引用超6万次。
中大规模(百万级)
Open Images的检测子集包含1500万个边界框,规模远超COCO。Pascal VOC虽然只有约2万张图像、20个类别,但因标注质量高、格式简洁,仍是模型快速验证和小型项目的常用选择。
专用检测(十万级)
工业场景下的检测数据集规模通常在数万至数十万级别,如自动驾驶领域的Cityscapes约5000张精细标注图像,但每张包含密集的像素级标注。
3. 时间序列预测任务
小规模(百级样本)
经典预测竞赛数据集如NN3包含111条月度时间序列,每条序列长度为50~126个观测点。这类小规模基准适合传统统计方法和轻量级模型的对比验证。
中大规模(万级样本/千级序列)
时间序列预测的数据集规模通常以时间步长和序列数量衡量。近年来涌现的大规模基准如Monash Time Series Repository包含数十万条序列,覆盖经济、交通、能源等多领域。
前沿时空数据集(百万级时空点)
HouseTS是2026年发布的美国住房市场时空数据集,覆盖6000多个邮政编码区,包含2012年3月至2023年12月的月度信号,总数据点达百万量级。这类数据集支撑着时空预测、多模态预测等前沿方向。
4. 推荐系统任务
经典规模(千万级交互)
MovieLens系列是推荐系统领域沿用最久的基准:ML-10M包含1000万条评分,ML-20M包含2000万条评分。2026年新发布的M3L-10M/20M在此基础上增加了电影海报、预告片、剧情等多模态特征,拓展了推荐系统的研究边界。
中大规模(亿级交互)
Tenrec数据集包含来自两个匿名平台的1.42亿条交互记录。KuaiRec提供1250万条密集交互,矩阵密度达99.6%。这类规模已接近工业级但可控。
工业级大规模(百亿级交互)
2026年发布的VK-LSVD(VK Large Short-Video Dataset)是当前最大的公开推荐系统数据集,包含400亿条用户-视频交互记录,来自1000万用户和近2000万短视频,时间跨度6个月。这一量级真实反映了工业推荐系统的数据规模,支持序列推荐、冷启动、多行为建模等前沿研究。
比较视角:不同推荐数据集规模
| 数据集 | 用户数 | 物品数 | 交互数 | 时间跨度 |
|---|---|---|---|---|
| VK-LSVD (2026) | 1000万 | 2000万 | 400亿 | 6个月 |
| RecFlow (2024) | 4.2万 | 8200万+900万 | 38亿+19亿 | 37天 |
| MicroLens (2023) | 3450万 | 114万 | 10亿 | 1年 |
| MovieLens-20M | 13.8万 | 2.7万 | 2000万 | 20年 |
| KuaiRec (2022) | 7200 | 1.1万 | 1250万 | 2个月 |
数据来源:VK-LSVD论文
5. 自然语言处理与多模态任务
语言数据规模(万亿token级)
根据Epoch团队2022年的分析,语言数据集以每年超50%的速度增长,截至2022年10月最大数据集已达2万亿词。但关键洞察在于:高质量语言数据(书籍、论文、新闻)将在2023-2027年间耗尽,而低质量语言数据(社交媒体、网页)可持续至2030-2050年。这一预测在2026年已成为行业共识,推动数据效率研究和合成数据发展。
多模态图文数据(千万级对)
S1-MMAlign是2026年发布的大规模科学图文数据集,包含1550万高质量图像-文本对,源自250万篇开放获取科学论文。覆盖物理、生物、工程等多学科,经过语义增强处理,图文对齐质量提升18.21%。
图像数据规模(十亿级图像)
图像数据总存量估计在8万亿至23万亿张之间,最大训练数据集已达30亿张。图像数据预计在2030-2060年间耗尽,远晚于语言数据。
6. 具身智能与机器人任务
触觉-视觉多模态(万分钟级)
白虎-VTouch数据集是2026年发布的全球最大跨本体视触觉多模态数据集,总规模超6万分钟,首批开源6000分钟。包含视触觉传感器数据、RGB-D数据、关节位姿数据,覆盖轮臂机器人、双足机器人、手持终端等本体构型。任务类型达380多种,涵盖家居家政、工业制造、餐饮服务、特种作业等4大类真实场景。
仿真数据(无限生成)
随着合成数据技术成熟,具身智能领域越来越依赖仿真环境生成的无限数据。但真实物理交互数据仍是稀缺资源,白虎-VTouch的6万分钟真实交互数据具有极高价值。
7. 数据集规模演化的核心趋势
趋势一:高质量语言数据触及天花板
高质量语言数据存量仅比当前最大数据集大不到一个数量级,2023-2027年间将耗尽。这一预测在2026年已显现——主流大模型训练开始依赖多轮数据复用、课程学习和合成数据。
趋势二:推荐系统数据进入百亿时代
VK-LSVD的400亿交互标志着推荐系统公开数据从"实验室可控"走向"工业级真实"。研究者需面对更大规模、更稀疏、时序依赖更强的数据挑战。
趋势三:多模态成为标准配置
新发布数据集普遍配备多模态信息:M3L-10M/20M增加视觉/音频特征、S1-MMAlign提供图文对、HouseTS融合遥感影像与文本、白虎-VTouch集成视触觉。
趋势四:专用领域数据集涌现
从工业检测(ICONIC-444)到住房预测(HouseTS),从科学图文(S1-MMAlign)到具身触觉(白虎-VTouch),2026年见证了专用领域大规模数据集的集中爆发。
趋势五:数据效率成为新焦点
面对数据耗尽预期,少样本学习、数据高效训练、主动学习、合成数据生成等方向成为研究热点。数据集不再追求"更大",而是"更精"。
Mermaid 总结框图
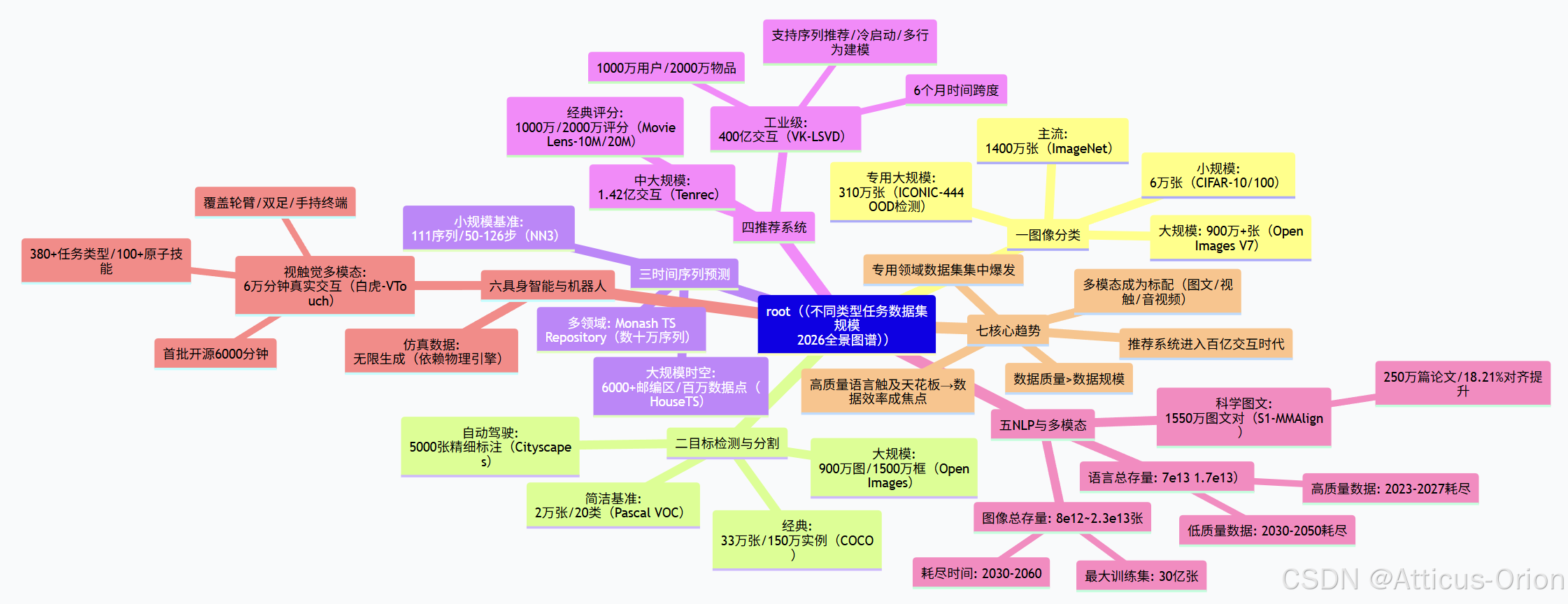
框图解读:
该图从六大任务维度系统梳理了2026年常见数据集规模,并归纳了核心演化趋势:
-
图像分类:从CIFAR的万级到ImageNet的千万级,覆盖不同需求
-
目标检测:COCO以33万张成为标准,Open Images以900万张支撑大规模预训练
-
时间序列:从小规模基准到百万级时空数据集,跨度显著
-
推荐系统:VK-LSVD的400亿交互标志着工业级数据成为公开资源
-
NLP与多模态:高质量语言数据逼近耗尽阈值,推动数据效率革命;多模态数据集规模达千万级
-
具身智能:真实物理交互数据稀缺,6万分钟已属大规模
关键数字速查:
-
图像分类最大:900万+张(Open Images)
-
目标检测实例数:1500万框(Open Images)
-
推荐系统交互数:400亿(VK-LSVD)
-
多模态图文对:1550万(S1-MMAlign)
-
具身真实数据:6万分钟(白虎-VTouch)
-
高质量语言剩余:<10倍当前最大集(即将耗尽)

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 31
31 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)