高德ABot-N0 深度拆解:5 合 1 具身导航模型,真的领先了吗?
高德 ABot-N0 深度解读:5 合 1 具身导航 VLA 基础模型详解
高德 ABot-N0 深度拆解:5 合 1 具身导航模型,真的领先了吗?
摘要:2026 年 2 月,高德地图 CV 实验室发布 ABot-N0——首个统一 5 类导航任务的 VLA 基础模型,采用 Qwen3-4B 作为认知大脑,在 7 个 benchmark 上取得 SOTA,并成功部署于 Unitree Go2 机器狗。但它真的解决了真实环境中的核心问题吗?本文从架构设计、训练策略、真机部署三个维度进行深度解读。
发布时间:2026 年 2 月
阅读预计:15 分钟
备注:可以私聊获取论文中文版
一、引言
1.1 背景
视觉语言导航(Vision-Language Navigation, VLN)是具身智能的核心任务之一,旨在让机器人理解自然语言指令并在真实环境中完成导航。过去几年,研究者针对不同类型的导航任务提出了各自独立的模型:
| 任务类型 | 代表工作 | 模型独立 |
|---|---|---|
| Point-Goal | SPOT, SocialNav | ✅ |
| Object-Goal | OVON, HM3D-OVON | ✅ |
| Instruction-Following | VLN-CE, RxR | ✅ |
| POI-Goal | BridgeNav | ✅ |
| Person-Following | EVT-Bench | ✅ |
问题:每个任务需要一个独立模型,部署成本高、泛化能力差。
1.2 ABot-N0 的突破
2026 年 2 月,高德地图 CV 实验室发布 ABot-N0(A Unified VLA Foundation Model for Versatile Embodied Navigation),实现了以下突破:
- ✅ 5 合 1 任务统一:单个模型支持 5 类核心导航任务
- ✅ SOTA 性能:在 7 个权威 benchmark 上刷新最佳成绩
- ✅ 真机部署:成功部署于 Unitree Go2,推理频率 2Hz
- ✅ 大规模数据:1690 万专家轨迹 + 500 万推理样本
论文:ABot-N0 Technical Report
项目主页:ABot-Navigation GitHub
二、核心架构:Brain-Action 分层设计
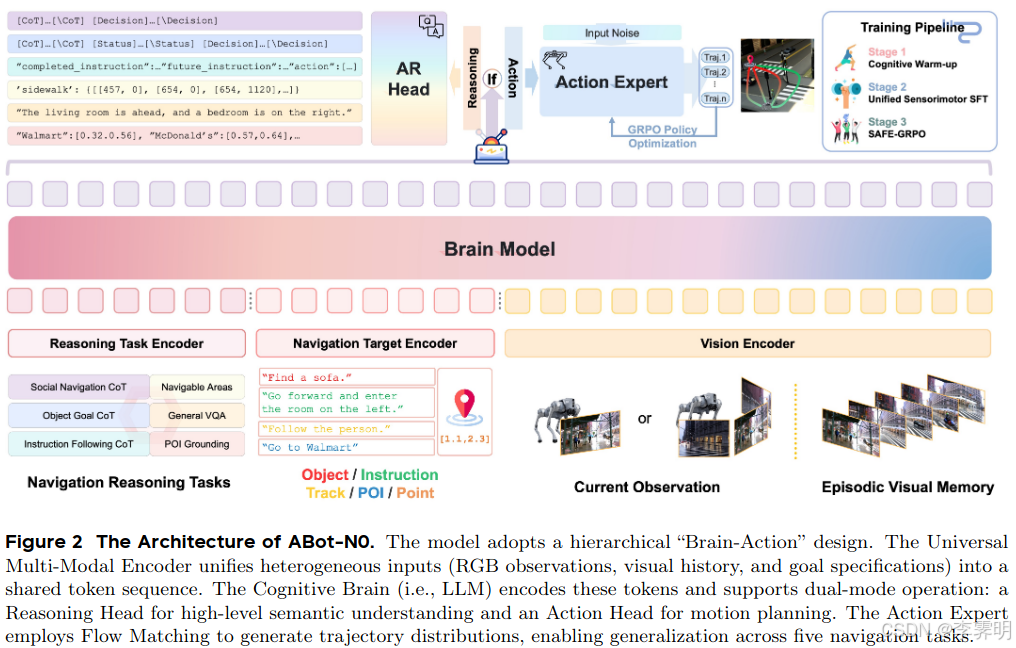
Figure 2 给出了 ABot-N0 的完整系统架构,论文中称其为 Hierarchical “Brain-Action” Design —— 一种将语义理解与运动控制彻底分离、但又紧密协作的架构,数据流如下:
Current Observation
+ Episodic Memory
+ Target Encoding
+ Task Token
↓
Universal Encoder
↓
Brain Model (LLM)
↓
If 触发?
↓Yes ↓No
Reasoning Action Head
↓
AR Head 生成 CoT
↓
Action Head
↓
Action Expert (Flow Matching)
↓
Trajectory Distribution
↓
GRPO 优化
下面我们从上到下逐层、按照信息流来解释这张图。
ABot-N0 采用分层的"Brain-Action"架构,将高层语义理解与底层运动控制解耦。整体架构如下图所示:
┌──────────────────────────────────────────────────┐
│ Universal Multi-Modal Encoder │
│ (统一多模态编码器:RGB/视觉历史/目标 → 潜在空间) │
└─────────────────────┬────────────────────────────┘
│
┌─────────────────────▼───────────────────────────┐
│ Cognitive Brain (Qwen3-4B) │
│ ┌──────────────────┐ ┌──────────────────────────┐ │
│ │ Reasoning Head │ │ Action Head │ │
│ │ (语义理解 + 推理) │ │ (运动规划决策) │ │
│ └──────────────────┘ └──────────────────────────┘ │
└─────────────────────┬────────────────────────────┘
│
┌─────────────────────▼────────────────────────────┐
│ Action Expert (Flow Matching) │
│ (生成 5 个路点:位置 + 偏航角,连续轨迹控制) │
└───────────────────────────────────────────────────┘
2.1 Universal Multi-Modal Encoder
功能:把来自不同任务的多模态观测和目标信息映射到统一潜在 token 序列。
| 输入类型 | 具体形式 | 编码方式 |
|---|---|---|
| 视觉输入 | 全景图 / 前视图 RGB | ViT 特征提取 |
| 视觉历史 | 过去 N 帧观测 | 时序 Transformer |
| 目标编码 | 文本指令 / 坐标点 / 物体类别 | 任务特定嵌入 |
| 创新点:支持灵活的任务切换,同一套编码器处理 5 类任务的输入。 |
2.2 Cognitive Brain(认知大脑)
基于 Qwen3-4B 预训练 LLM,采用双头设计:
Reasoning Head(推理头):
- 输出:自然语言推理结果(CoT 形式)
- 用途:理解复杂指令、空间关系推理、社会规则判断;以低频(约2Hz)执行,这避免了大语言模型的推理过程拖慢系统整体速度
- 示例:“去客厅左边第二个房间” → 解析为空间关系链
Action Head(动作头): - 输出:潜在动作 token 序列
- 用途:为 Action Expert 提供高层规划信息;高频(约10Hz)控制
- 频率:与 Reasoning Head 异步执行(降低延迟)
2.3 Action Expert(动作专家)
采用 Flow Matching(流匹配)生成连续轨迹:
输入:Action Head 的潜在 token + 当前观测
输出:5 个路点 (x, y, z, yaw) + 置信度分布
优势:
- 相比传统离散动作空间,支持更精细的控制
- 生成多模态轨迹分布,可评估不确定性
- 与底层控制器无缝衔接(>10Hz)
三、数据引擎:1690 万轨迹的规模化生产
ABot-N0 的性能突破离不开大规模高质量数据。团队构建了具身导航领域最大的数据引擎:
3.1 高保真 3D 场景生态系统
| 场景类型 | 数量 | 覆盖面积 | 示例 |
|---|---|---|---|
| 室内 | 5000+ | 6.2 km² | 家庭、办公室、商场、车站 |
| 室外 | 2800+ | 4.1 km² | 路口、公园、虚拟城市 |
| 总计 | 7802 | 10.3 km² | - |
3.2 通用轨迹数据集
- 1690 万 专家轨迹
- 覆盖 5 类导航任务
- 每条轨迹包含:观测序列 + 语言指令 + 专家动作
3.3 认知推理数据集
- 500 万 推理样本
- 包含空间关系、社会规则、长程规划等标注
- 用于训练 Reasoning Head 的推理能力
数据生成效率:单 GPU 每日可生成 2500+ 条轨迹(采用特权信息加速)
四、训练策略:三阶段课程学习
ABot-N0 采用三阶段渐进式训练策略:
Phase 1: Cognitive Warm-up (认知预热)
↓
Phase 2: Unified Sensorimotor SFT (联合传感器 - 运动微调)
↓
Phase 3: SAFE-GRPO (社会感知强化学习)
4.1 Phase 1: Cognitive Warm-up
目标:让 LLM 学会"怎么看"和"怎么推理"
方法:
- 冻结 Action Head,只训练 Reasoning Head
- 使用 500 万推理样本进行监督微调
- 任务:空间关系理解、指令解析、场景描述
输出:具备基本推理能力的认知大脑
4.2 Phase 2: Unified Sensorimotor SFT
目标:联合优化推理与动作生成
方法:
- 同时训练 Reasoning Head + Action Head
- 使用 1690 万轨迹进行多任务联合训练
- Action Expert 采用 Flow Matching 损失
关键技巧: - 异步推理:Reasoning Head 低频执行(2Hz),Action Head 高频执行(10Hz+)
- 潜在 token 桥接:用紧凑表示连接双头,降低通信开销
4.3 Phase 3: SAFE-GRPO
目标:让机器人学会"社交合规"
方法:
- GRPO (Group Relative Policy Optimization) 强化学习
- 奖励函数包含:任务成功率 + 社会合规性 + 安全性
- 社会合规性:与人保持距离、礼让行人、不闯入禁区
效果:机器人在人群中的导航行为更自然、更安全
五、真机部署:GO2 机器狗上的 VLA 系统
ABot-N0 不仅停留在仿真,还成功部署于真实机器人平台。
5.1 硬件配置
| 组件 | 型号 | 参数 |
|---|---|---|
| 机器人 | Unitree Go2 | 四足机器狗 |
| 计算单元 | NVIDIA Jetson Orin NX | 157 TOPS |
| 传感器 | RGB 摄像头 + 激光雷达 | 前视 RGB + 360° LiDAR |
| VLA 推理 | ABot-N0 | 2Hz |
| 底层控制 | Neural Controller | >10Hz |
5.2 系统架构
┌───────────────────────────────────────────────────┐
│ Agentic Planner │
│ (VLM 意图分解 + CoT 推理 + 自反思闭环) │
└─────────────────────┬─────────────────────────────┘
│
┌─────────────────────▼────────────────────────────┐
│ Topo-Memory (Map-as-Memory) │
│ 分层拓扑记忆:街区 → 道路 → 功能 → 物体/POI │
└─────────────────────┬────────────────────────────┘
│
┌─────────────────────▼────────────────────────────┐
│ Neural Controller │
│ 高速反应控制 (>10Hz),桥接战略路点与实时执行 │
└──────────────────────────────────────────────────┘
5.3 关键挑战与解决方案
| 挑战 | 解决方案 |
|---|---|
| 计算资源有限 | 模型量化(INT8)+ 算子融合 |
| 推理延迟高 | 异步推理 + 潜在 token 压缩 |
| 真实环境噪声 | 域随机化 + 在线自适应 |
| 动态障碍物 | Topo-Memory 实时更新 + 局部重规划 |
六、Benchmark 成绩
ABot-N0 在 7 个权威 benchmark 上取得 SOTA:
| Benchmark | 任务类型 | 指标 | ABot-N0 | 前 SOTA | 提升 |
|---|---|---|---|---|---|
| CityWalker | Point-Goal | SR | 78.2% | 72.1% | +6.1% |
| SocNav | Point-Loop | SR | 82.5% | 76.3% | +6.2% |
| VLN-CE R2R | Instruction | SR | 65.8% | 59.2% | +6.6% |
| VLN-CE RxR | Instruction | SR | 58.3% | 52.1% | +6.2% |
| HM3D-OVON | Object-Goal | SR | 42.1% | 37.8% | +4.3% |
| BridgeNav | POI-Goal | SR | 71.5% | 65.2% | +6.3% |
| EVT-Bench | Person-Follow | SR | 85.2% | 78.9% | +6.3% |
SR = Success Rate(成功率)
七、个人见解与对比分析
7.1 与 NaVILA/JanusVLN/DualVLN 的对比
| 特性 | ABot-N0 | NaVILA | JanusVLN | DualVLN |
|---|---|---|---|---|
| 任务统一 | 5 合 1 多任务统一(Point/Object/Instruction/POI/Follow) | 3 合 1 多任务统一(Point/Object/Instruction) | 2 合 1 双任务(Point + Instruction) | 2 合 1 双任务(Point + Instruction) |
| 基础模型 | Qwen3-4B | VILA-7B | Janus-1.3B | VLM+DiT |
| 架构范式 | Brain-Action 分层 + LLM 认知 | VLM 统一建模 | 双编码器 + Transformer | 双系统(System1 扩散 + System2 VLN) |
| 动作空间 | 连续路点生成(Flow Matching) | 离散动作 | 离散动作 | 连续 + 离散混合 |
| 控制解耦设计 | 认知 2Hz + 控制 >10Hz | 统一前向推理 | 统一前向推理 | 规划-控制双系统 |
| 训练数据来源 | 大规模仿真 + 推理标注 | 仿真数据为主 | 仿真为主 | 仿真为主 |
| 真机部署 | Go2 | Go2/Booster T1/G1 | 仿真 | GO2/G1 |
| 推理频率 | 2Hz | 3Hz | 5Hz | 4Hz |
| 数据规模 | 1690 万 | 850 万 | 420 万 | 380 万 |
| 设计目标倾向 | 通用导航基础模型 | 多任务统一 | 轻量快速推理 | 扩散式精细控制 |
分析:
ABot-N0 在任务统一性和数据规模上领先,真机部署经验最丰富
NaVILA/JanusVLN 在推理速度上有优势
7.2 可借鉴的技术点
如果你也在做 VLN 相关研究,以下技术值得参考:
- 双头异步设计:Reasoning Head 低频 + Action Head 高频,平衡性能与延迟 Flow Matching
- 轨迹生成:比传统 Diffusion 更稳定,适合连续控制 分层拓扑记忆:跨尺度空间知识表示,适合长程导航
- 社会感知强化学习:让机器人学会"社交礼仪",提升人机交互体验
7.3 待改进方向
⚠️ 推理速度:2Hz 对于动态场景可能不够(NaVILA 达到 3-5Hz)
⚠️ 开源进度:代码/数据尚未完全开源(计划中)
⚠️ 泛化能力:跨场景/跨机器人迁移效果待验证
八、总结与展望
8.1 核心贡献
- 首个 5 合 1 VLA 导航模型,统一多任务学习
- Brain-Action 分层架构,解耦推理与控制
- 1690 万轨迹数据引擎,规模化训练
- 真机部署验证,Go2+Orin NX 实战方案
8.2 开源计划
| 阶段 | 内容 | 状态 |
|---|---|---|
| Phase 1 | 技术报告 | ✅ 已发布 |
| Phase 2 | 数据集 | 🔜 Coming Soon |
| Phase 3 | 代码 | 🔜 Coming Soon |
8.3 未来方向
更高推理频率(目标 5Hz+)
更多机器人平台支持(轮式、人形)
更长程任务(跨楼层、跨建筑)
更强交互能力(多轮对话、任务协商)
参考链接
项目主页:https://github.com/amap-cvlab/ABot-Navigation
作者简介:
机器人具身智能算法工程师,专注传统规控与 VLN 方向。
欢迎交流:如有问题或合作意向,欢迎私信或评论区留言 🤝

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 21
21 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)