OpenVLA学习记录(论文解读与复现微调)
3.安装核心计算库PyTorch避开 NGC 系统源干扰,强制安装兼容 Flash Attention 的 CUDA 12.1 版本 PyTorch。我们现在的状态是:Conda 环境 (openvla) 已激活,PyTorch 已就位。请依次执行以下步骤,完成 OpenVLA 和 LIBERO 的最终部署。第一步:安装仿真环境与 OpenVLA 源码第二步:安装 Flash Attention
文章目录
OpenVLA原文解读
一、摘要
在大规模互联网视觉-语言数据和多样化机器人演示的组合上预训练的大型策略,具有改变我们教机器人新技能方式的潜力:我们可以微调此类视觉-语言-动作 (VLA) 模型以获得稳健、可泛化的视觉运动控制策略,而不是从头开始训练新的行为 。
然而,VLA 在机器人技术中的广泛采用一直面临挑战,原因在于:
- 现有的 VLA 大多是封闭的,公众无法访问;
- 以前的工作未能探索针对新任务高效微调 VLA 的方法,而这是其被采用的关键一环 。
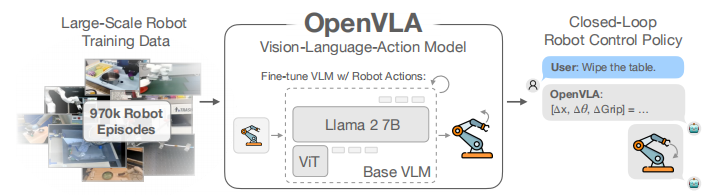
为了解决这些挑战,我们推出了 OpenVLA,这是一个 70 亿参数的开源 VLA,在包含 97 万个真实世界机器人演示的多样化集合上进行了训练 。OpenVLA 建立在 Llama 2 语言模型之上,并结合了一个融合了 DINOv2 和 SigLIP 预训练特征的视觉编码器 。
作为数据多样性增加和新模型组件的产物,OpenVLA 在通用操控方面表现出强大的结果。在涉及 29 项任务和多种机器人实体的测试中,其绝对任务成功率比封闭模型(如 550 亿参数的 RT-2-X)高出 16.5%,而参数量仅为后者的七分之一 。
我们进一步表明,我们可以有效地针对新环境微调 OpenVLA,特别是在涉及多个对象的多任务环境中表现出极强的泛化结果和强大的语言落地 (language grounding) 能力,并且比 Diffusion Policy 等表现力强的从头开始模仿学习方法高出 20.4% 。我们还探索了计算效率;作为一个单独的贡献,我们展示了 OpenVLA 可以通过现代低秩自适应 (LoRA) 方法在消费级 GPU 上进行微调,并通过量化 (quantization) 进行高效服务,且不会降低下游任务的成功率 。最后,我们发布了模型检查点、微调笔记 以及我们的 PyTorch 代码库,其中内置了在 Open X-Embodiment 数据集上大规模训练 VLA 的支持 。
二、引言
利用在互联网规模数据上训练的强大基础模型,视觉-语言-动作 (VLA) 模型(如 RT-2)展现出了令人印象深刻的鲁棒性,以及泛化到新物体和新任务的能力,为通用机器人策略设立了新标准。然而,目前有两个关键原因阻碍了现有 VLA 模型的广泛使用:
-
模型封闭:目前的模型(如 RT-2 等)通常是封闭的,外界对其模型架构、训练过程和数据混合情况知之甚少,这限制了社区的进一步研究和复现。
-
缺乏微调方案:现有的工作没有提供将 VLA 部署和适配到新机器人的最佳实践。虽然预训练模型很强大,但让其适应特定的新环境或新机器人实体往往是实际应用中的关键需求,而目前缺乏高效的微调方法。
为了解决这些挑战,我们介绍了 OpenVLA。 OpenVLA 由一个预训练的视觉条件语言模型 (visually-conditioned language model) 主干组成,该主干能够捕捉多粒度的视觉特征。我们在 Open X-Embodiment 数据集的一个庞大且多样化的子集(包含 97 万条机器人操控轨迹)上对其进行了微调。该数据集涵盖了广泛的机器人实体、任务和场景。
作为数据多样性增加和新模型组件的产物,OpenVLA 在通用操控方面表现出强大的结果。在 WidowX 和 Google Robot 机器人的 29 项评估任务中,OpenVLA 的绝对任务成功率比之前的最先进 VLA 模型——参数量高达 550 亿的 RT-2-X——还要高出 16.5%,而 OpenVLA 的参数量仅为 70 亿(7B)。
OpenVLA 采用了一种更端到端的方法,通过将机器人动作视为语言模型词表中的 token,直接微调视觉条件语言模型来生成机器人动作。
主要贡献: 我们在本文中的主要贡献如下:
-
OpenVLA 模型:我们发布了 OpenVLA,这是一个 7B 参数的开源 VLA 模型。它在通过大规模模仿学习训练的通用机器人操控策略方面设立了新的技术水平 (SOTA)。
-
高效微调与部署:我们展示了现代参数高效微调 (Parameter-Efficient Fine-Tuning, PEFT) 方法在 VLA 上的有效性。同时这也是首个证明可以通过现代低秩自适应 (LoRA) 和模型量化 (Quantization) 方法在消费级 GPU 上高效微调和部署 VLA 的工作,且不牺牲模型性能。这打破了以往 VLA 需要昂贵服务器集群的限制。
-
完全开源:为了支持未来的研究,我们开源了所有的模型检查点 (checkpoints)、训练与微调代码、以及数据加载工具。我们希望这将成为机器人学习社区的一个强大且易用的基座。
三、相关工作
作者将现有研究分为三个主要流派,并明确了 OpenVLA 在其中的位置和创新点。
2.1. 视觉条件语言模型 (Visually-Conditioned Language Models, VLMs)
-
核心趋势:现代 VLM(如 LLaVA 等)逐渐收敛到一种简单的架构——“Patch-as-Token”。即把预训练视觉变换器 (ViT) 输出的图像块特征 (patches) 直接视为语言模型中的 token,投影到语言模型的输入空间中。
-
OpenVLA 的选择:
-
为了利用这种简单架构的可扩展性,OpenVLA 选择了 Prismatic-7B 作为骨干网络。
-
关键差异:不同于通过 CLIP 或仅 SigLIP 提取特征,Prismatic 融合了双视觉编码器:
-
DINOv2:提供低层次的空间信息(对机器人精准操作至关重要)。
-
SigLIP:提供高层次的语义理解(有助于视觉泛化)。
-
-
这种多粒度特征融合是 OpenVLA 具备强大空间推理能力的基础。
-
2.2. 通用机器人策略 (Generalist Robot Policies)
-
背景:机器人领域的一个趋势是基于大规模多样化数据集(如 Open X-Embodiment)训练多任务通用策略。
-
与 Octo 的对比:
-
Octo (现有技术):采用“缝合”式架构,将预训练的语言/视觉组件与从头初始化的组件拼接,并在训练中学习如何结合它们。
-
OpenVLA (本文方法):采用更彻底的端到端方法。它直接微调整个 VLM,将机器人动作视为语言词表中的 token 进行生成。
-
-
优势:实验证明,这种简单的端到端管道在性能和泛化能力上显著优于 Octo 这类“缝合”策略。
2.3. 视觉-语言-动作模型 (Vision-Language-Action Models, VLAs)
-
定义:直接微调大型预训练 VLM 来预测机器人动作的模型(如 Google 的 RT-2)。
-
三大优势:
-
对齐优势:利用互联网规模的视觉-语言数据进行了预先对齐。
-
基建复用:通用架构使得机器人领域可以直接复用现代 VLM 训练的可扩展基础设施(如训练几十亿参数模型的工具),无需为机器人定制复杂架构。
-
技术红利:直接受益于 VLM 领域的快速进步。
-
-
与 RT-2-X 的对比 (关键): 虽然 RT-2-X (55B) 是此前的 SOTA,但 OpenVLA 在四个方面做出了改进:
-
性能更强且更小:OpenVLA (7B) 通过结合更强的开源 VLM 骨干和更丰富的预训练数据,性能超越了 RT-2-X,且参数量仅为后者的 1/8。
-
支持微调:RT-2-X 未探索微调,而 OpenVLA 深入研究了针对新场景的微调方法。
-
高效性:首次证明了 PEFT (参数高效微调) 和量化在 VLA 上的有效性。
-
开源:OpenVLA 是首个完全开源的通用 VLA,支持社区对训练数据、目标函数和推理进行深入研究。
-
四、OpenVLA模型
架构如下:
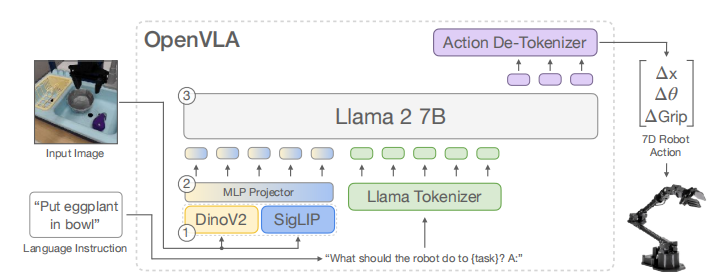
上图展示了 OpenVLA 的整体工作流程,描述了从输入到输出的端到端过程:
- 输入 :
- 图像观测 (Input Image):机器人的当前视角图像。
- 语言指令 (Language Instruction):例如 “Put eggplant in bowl”。
- 处理流程:
- 视觉编码器:图像并非通过单一网络,而是同时通过两个预训练编码器:
- DINOv2:捕捉低层次的空间几何特征。
- SigLIP:捕捉高层次的语义特征。
- 这两个特征向量被串联起来。
- 投影器 (Projector):一个 MLP 投影层,将视觉特征映射到语言模型的输入空间(Embedding Space)。
- 主干网络:Llama 2 7B 模型,接收图像特征和语言指令作为输入。
- 去词元化 (Action De-Tokenizer):Llama 2 输出的 token 被解码为离散的动作编号。
- 输出:7 维机器人动作:包含位置变化 ( Δ x , Δ y , Δ z \Delta x, \Delta y, \Delta z Δx,Δy,Δz)、旋转 ( Δ θ r o l l , Δ θ p i t c h , Δ θ y a w \Delta \theta_{roll}, \Delta \theta_{pitch}, \Delta \theta_{yaw} Δθroll,Δθpitch,Δθyaw) 和 夹爪状态 (Gripper)。
4.1 节:预备知识:视觉-语言模型 (Preliminaries: Vision-Language Models)
当前 VLA 研究的一个空白:关于开发 VLA 模型的最佳实践(如最佳骨干网络、数据集、超参数)仍然充满未知。这一节详细解释了 OpenVLA 为什么选择特定的组件,并深入探讨了 VLM 的架构演变。
-
现代 VLM 的标准架构: 大多数现代 VLM(如 LLaVA 等)都遵循一个由三部分组成的架构:
-
视觉编码器:将图像映射为多个“图像块嵌入” (image patch embeddings)。
-
投影器:将视觉嵌入映射到语言模型的输入空间。
-
LLM 主干:用于处理多模态输入并生成文本。
-
-
OpenVLA 的选择:Prismatic-7B: 作者没有从头构建,而是基于 Prismatic-7B VLM 进行开发。选择它的核心原因在于其独特的视觉处理方式:
-
双视觉编码器:
-
Prismatic 不像传统方法那样只使用 CLIP 或 SigLIP,而是融合了 SigLIP 和 DINOv2。
-
图像块 (patches) 分别通过这两个网络,输出的特征向量在通道维度上进行串联。
-
-
为什么这么做?
-
SigLIP 提供语义理解(“这是什么物体”)。
-
DINOv2 提供精确的空间布局信息(“物体在哪里”)。
-
文中特别指出:DINOv2 的加入显著提升了空间推理能力,这对于机器人控制任务(需要精确操作)至关重要。
-
-
-
预训练数据背景:
-
这些组件(SigLIP, DINOv2, Llama 2)各自在万亿级别的互联网数据上进行了预训练。
-
Prismatic VLM 本身还在 LLaVA 1.5 数据混合(包含约 100 万条图文对)上进行了微调,进一步对齐了视觉和语言能力。
-
4.2 节:OpenVLA 训练过程 (OpenVLA Training Procedure)
作者首先介绍了如何将机器人控制问题转化为 VLM 能够处理的格式。
-
核心思路:将动作预测问题建模为“视觉-语言”任务。
-
输入:观察图像 + 自然语言指令。
-
输出:一串代表机器人动作的 token。
-
-
动作离散化:
-
挑战:语言模型输出的是离散的词 (tokens),而机器人动作是连续的数值。
-
方法:跟随 Google 的 RT-2 (Brohan et al.),将动作的每个维度单独离散化为 256 个分箱 (bins)。
-
改进点 (关键细节):
-
RT-2 使用的是“最大值-最小值”来划分区间。
-
OpenVLA 改进为使用分位数 (Quantiles),具体是取训练数据中第 1% 到第 99% 的分位数区间进行均匀划分。
-
原因:这可以忽略数据中的离群值 (outliers),防止因极端的异常动作数值导致分箱区间过大,从而保证了动作控制的精度(粒度)。
-
-
-
Tokenizer 的“黑客”式修改:
-
问题:动作需要 256 个独立的 token(对应 0-255 的整数)。OpenVLA 使用的 Llama Tokenizer 预留的“特殊 token”只有 100 个,不够用。
-
解决方案:作者选择了一种简单粗暴但有效的方法——直接覆盖Llama 词表中使用频率最低的最后 256 个 token,将其挪作动作 token 使用。
-
训练目标:动作被处理成 token 序列后,模型使用标准的下一个 token 预测任务进行训练,仅计算预测动作 token 时的交叉熵损失。
-
4.3 节:训练数据 (Training Data)
这一节详述了 OpenVLA 如何构建其庞大的训练集,目标是覆盖尽可能多的机器人实体、场景和任务。
-
数据基座:使用 Open X-Embodiment (OpenX) 数据集作为基础。这是一个包含 70 多个独立数据集、超过 200 万条机器人轨迹的大型集合。
-
数据清洗与筛选: 为了保证训练的可行性,作者进行了严格筛选:
-
输入一致性:仅保留那些包含至少一个第三人称视角相机的数据集。
-
输出一致性:仅保留使用单臂且为末端执行器控制的数据集。
-
-
数据配比:
-
直接沿用了 Octo 模型的配比策略:
-
降低权重:对多样性较低的数据集进行降权或移除。
-
增加权重:对任务和场景多样性较高的数据集进行加权。
-
-
关于 DROID 数据集:DROID 是一个高质量的大规模数据集。作者最初尝试以 10% 的权重加入它,但发现模型在 DROID 上的动作预测准确率始终很低(可能需要更大的模型容量)。为了不影响最终模型的质量,作者在训练的最后三分之一阶段移除了 DROID 数据。
-
4.4 节:OpenVLA 设计决策 (OpenVLA Design Decisions)
作者首先声明,为了提高迭代速度并降低计算成本,这些设计决策的实验是在较小的 BridgeData V2 数据集上进行的,而不是在全量 OpenX 数据集上。通过这些小规模实验,他们探索了 VLM 骨干网络的选择、图像分辨率、是否微调视觉编码器等关键问题。
- VLM 骨干网络的选择
- 候选模型:作者比较了三种微调方案:
- Prismatic (最终选择)
- IDEFICS-1 (80B 参数模型的 9B 版本)
- LLaVA (7B, 基于 CLIP)
- 实验发现:
- 单物体任务:LLaVA 和 IDEFICS-1 表现相当。
- 多物体/语言落地任务:LLaVA 显著优于 IDEFICS-1(成功率高 35%),证明了其更强的语言理解能力。
- 最终胜者:Prismatic 表现最好。它在简单的单物体任务和复杂的多物体语言落地任务上,平均绝对成功率比 LLaVA 还要高出约 10%。
- 原因分析:作者将这一性能提升归功于 Prismatic 独特的 SigLIP + DINOv2 融合视觉骨干,这种组合提供了更强的空间推理能力。
- 图像分辨率 (Image Resolution)
- 对比:测试了 224 × 224 224 \times 224 224×224 像素和 384 × 384 384 \times 384 384×384 像素两种输入分辨率。
- 结果:
- 在机器人任务评估中,并未发现两者有明显的性能差异。
- 但是, 384 × 384 384 \times 384 384×384 分辨率会导致图像 patch token 数量增加,使得训练上下文变长,导致训练时间增加了 3 倍。
- 决策:为了效率,最终 OpenVLA 选用了 224 × 224 224 \times 224 224×224 px。
- 注:作者提到这与通常的 VLM 趋势不同(通常 VLM 提高分辨率会有帮助),但在目前的 VLA 任务中尚未体现出优势。
- 微调视觉编码器
- 背景:在传统的 VLM 训练中,为了保留预训练特征的鲁棒性,通常会冻结视觉编码器。
- OpenVLA 的发现:在 VLA 训练中,解冻并微调视觉编码器至关重要。
- 原因假设:预训练的视觉骨干(如 SigLIP/DINOv2)虽然强大,但可能缺乏对“场景中关键部位”的细粒度空间细节的捕捉能力,而这些细节对精准的机器人控制是必须的。因此,必须让视觉编码器在机器人数据上通过梯度更新来学习这些细节。
- 训练轮数
- 对比:通常 LLM 或 VLM 只训练 1-2 个 epoch。
- OpenVLA 的发现:机器人策略需要更久的训练。实验显示,随着训练进行,真实机器人的性能会持续上升,直到动作 token 的预测准确率超过 95%。
- 最终设置:OpenVLA 最终训练了 27 个 epoch。
- 学习率
- 设置:在扫描了多个数量级后,发现 2e-5 的固定学习率效果最好(这与 Prismatic 预训练时的学习率一致)。
- Warmup:未发现学习率预热有任何益处。
4.5 节:训练与推理基础设施 (Infrastructure for Training and Inference)
这一节披露了训练 OpenVLA 所需的硬件资源,也侧面印证了为何“开源”如此重要(普通人很难复现从头训练)。
-
训练资源:
-
硬件:64 张 A100 GPU 的集群。
-
时长:训练了 14 天。
-
总算力:共计 21,500 个 A100 小时。
-
批次大小:2048。
-
-
推理资源:
-
显存需求:加载 bfloat16 精度(无量化)模型需要 15GB GPU 显存。
-
速度:在单张 NVIDIA RTX 4090 上,运行速度约为 6Hz(未做特殊优化)。
-
量化潜力:作者提到可以通过量化进一步降低显存需求,这将在第 6.4 节详细展示。
-
五、OpenVLA 代码库
作者在本页开头强调了开源代码库的重要性,这不仅是为了复现,更是为了推动社区发展。OpenVLA 代码库具有以下核心特性:
-
基于 Prismatic VLM 库构建:代码库构建在一个名为 Prismatic 的轻量级、模块化 VLM 训练库之上。
-
支持现代训练技术:
-
内置了 PyTorch FSDP (Fully Sharded Data Parallel),支持跨多节点的大规模分布式训练。
-
集成了 Flash-Attention 等显存优化技术,极大地提高了训练效率。
-
-
灵活性与可扩展性:
-
支持从 10 亿到 340 亿参数量的各种 VLM 架构。
-
提供了对不同视觉编码器(SigLIP, CLIP, DINOv2)和语言模型(Llama 2, Mistral 等)的开箱即用支持。
-
原生微调支持:代码库内置了对 LoRA和 Full Fine-Tuning 的支持,使得用户可以轻松地在自己的数据集上微调模型。
-
六、实验
这一章旨在通过实证研究回答三个核心问题:
-
通用性能:OpenVLA 能否作为一种有效的“开箱即用”通用策略,控制多种不同的机器人?
-
微调能力:我们能否通过参数高效微调 (LoRA),让 OpenVLA 快速适应新的机器人领域和任务?
-
计算效率:OpenVLA 的参数量和推理成本是否足够低,从而能够在消费级 GPU 上进行高效的训练和推理?
6.1 节:通用策略性能 (Performance as a Generalist Policy)
这一节展示了 OpenVLA 在不进行额外微调的情况下,直接控制机器人的能力。
-
对比基线: 作者将 OpenVLA 与当前最先进的闭源和开源模型进行了对比:
-
RT-2-X (55B):Google DeepMind 的闭源 SOTA 模型,参数量是 OpenVLA 的 ~8 倍。
-
Octo:基于 Transformer 的开源通用策略(非 VLA 架构)。
-
RT-1-X & BridgeData V2 策略:较小的专用模型。
-
-
评估设置: 在两个截然不同的机器人平台上进行了大规模的实机评估:
-
WidowX 机器人:基于 BridgeData V2 数据集涵盖的任务(如“把茄子放进锅里”)。
-
Google Robot:基于 RT-1 数据集涵盖的任务(如“捡起可乐罐”)。
- 共计测试了 29 个任务,涵盖了不同的物体、场景和指令。
-
-
核心结果:
-
超越 SOTA:OpenVLA 在所有测试任务上的平均成功率达到了 SOTA 水平。
-
关键数据:OpenVLA (7B) 的绝对任务成功率比 RT-2-X (55B) 高出了 16.5%。
-
原因分析:作者认为这得益于 OpenVLA 更强的视觉骨干(DINOv2 + SigLIP)以及更有效的端到端动作生成架构,相比于 RT-2-X 仅使用较旧的 PaLI-X 或 PaLM-E 架构,OpenVLA 在空间推理和动作生成的对齐上做得更好。
-
-
图表说明:
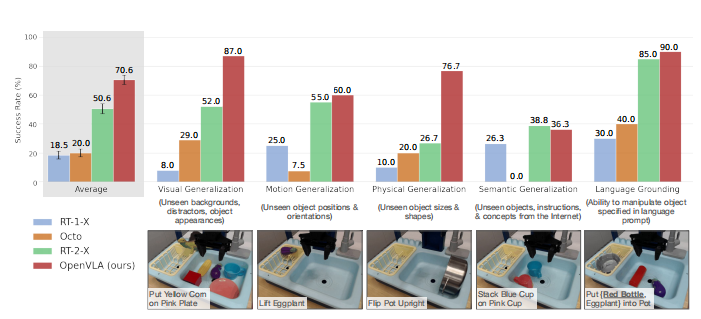
直观展示了各模型在不同任务簇(如“可见物体”、“遮挡物体”、“新物体”)上的成功率对比。OpenVLA 在处理未见过的物体 和 复杂指令时优势尤为明显。
6.2 节:针对新机器人设置的数据高效微调
这一部分详细展示了 OpenVLA 如何适应全新的真实世界机器人设置,并与当前的 SOTA 模仿学习算法进行了对比。
-
实验设置: 作者选择了两种截然不同的 Franka 机器人配置来测试微调效果:
-
Franka-Tabletop:固定安装的机械臂,控制频率 5Hz。
-
Franka-DROID:安装在移动桌子上的机械臂(来自 DROID 数据集配置),控制频率 15Hz。
- 数据量:每个任务仅使用 10-150 条演示数据,模拟真实世界中数据稀缺的场景。
-
-
对比基线:
-
Diffusion Policy:当前最强的模仿学习算法,从头开始训练。
-
Octo (Fine-tuned):当前最好的支持微调的通用策略。
-
OpenVLA (Fine-tuned):本文提出的方法。
-
OpenVLA (Scratch):消融实验,不使用预训练权重,直接从头在目标数据上训练 Prismatic VLM。
-
Diffusion Policy (Matched):消融实验,去掉了“动作分块 ”和“历史观测”,使其输入输出与 OpenVLA 一致,用于公平对比架构差异。
-
-
核心实验结果:
-
单一指令任务: 在简单的、重复性高的任务(如“把胡萝卜放进碗里”)上,Diffusion Policy 表现极佳,甚至略优于 OpenVLA。这是因为 Diffusion Policy 使用了动作分块 (Action Chunking)(一次预测未来一串动作),使得动作非常平滑且精确。
-
多样化/语言落地任务: 在涉及多个物体、需要理解语言指令(如“把玉米倒进锅里” vs “把玉米放进碗里”)的复杂任务中,OpenVLA 和 Octo (Fine-tuned) 显著优于从头训练的 Diffusion Policy。
-
预训练的重要性: OpenVLA (Fine-tuned) 的表现远好于 OpenVLA (Scratch),这直接证明了在 Open X-Embodiment 数据集上进行的大规模预训练让模型学会了鲁棒的视觉表示和物理常识。
-
总体评价: OpenVLA 是唯一一个在所有测试任务上都能达到 50% 以上成功率的方法。作者认为 OpenVLA 是目前最适合作为默认首选的策略,特别是对于那些指令多样的任务。
-
-
局限性讨论: 作者坦诚地指出,对于极度依赖灵巧操作的窄任务,Diffusion Policy 仍然具有优势。这主要是因为 OpenVLA 目前是单步预测,没有像 Diffusion Policy 那样预测一整块未来的动作轨迹。作者将引入动作轨迹 Action Chunking 列为未来的工作方向。
6.3 节:参数高效微调 (Parameter-Efficient Fine-Tuning, PEFT)
这一节旨在解决 VLA 模型训练成本高昂的问题。上一节的全参数微调需要 8 张 A100 GPU,这对普通实验室来说太贵了。
-
目标:探索是否可以在消费级 GPU(如 RTX 3090/4090)上微调 OpenVLA,且不损失性能。
-
对比方法:
-
全量微调 (Full Fine-Tuning):更新所有 7B 参数。
-
LoRA:冻结主干,仅训练低秩适配器(参数量极小)。
-
Last Layer (Head-Only):冻结所有层,仅训练最后的动作解码头。
-
-
初步结论:
-
LoRA 效果拔群:实验显示,使用 LoRA 微调的 OpenVLA 在下游任务上的成功率与全量微调几乎一致(甚至在某些任务上略好),但显存占用和计算需求大幅降低。
-
Last Layer 效果差:仅微调最后一层不足以让模型适应新的机器人动力学或新物体,性能显著下降。
-
-
选型建议:如果你的任务很简单且单一,用 Diffusion Policy;如果你需要处理多物体、多指令或新场景,OpenVLA 是最佳选择。
-
降本增效:正式推荐使用 LoRA 进行微调,这直接将 OpenVLA 从“大厂专用”变成了“人人可用”的消费级模型。
-
LoRA 的设置: 作者使用了 LoRA技术,针对模型中的所有线性层进行微调,并尝试了不同的秩值。
-
消融实验结果: 为了验证 LoRA 的有效性,作者对比了其他几种节省计算量的微调变体:
-
仅微调最后一层:只更新动作解码头 (Action Head)。
- 结果:性能很差。这说明仅调整输出层不足以让模型适应新的物理动力学或新物体。
-
冻结视觉编码器:只微调语言模型主干。
- 结果:性能不佳。这再次印证了 OpenVLA 的一个核心发现:为了精准控制机器人,必须允许视觉特征适应目标场景(即微调视觉编码器)。
-
Sandwich Fine-Tuning:这是一种特殊的 LoRA 变体。
- 结果:表现优于上述两种简单方法,但标准 LoRA 仍然是最稳健的选择。
-
-
结论: LoRA 是最佳的轻量级微调方案。它在保持极低显存占用(允许在消费级 GPU 上训练)的同时,达到了与全参数微调 (Full Fine-Tuning) 相当的成功率。
6.4 节:通过量化实现高效推理 (Efficient Inference via Quantization)
这一节探讨了如何降低 OpenVLA 部署时的硬件门槛。
-
挑战: 作为 7B 参数的模型,OpenVLA 在默认半精度 (bfloat16) 下加载需要 15GB 显存。虽然能在 RTX 4090 (24GB) 上运行,但对于更低端的显卡(如 12GB/16GB 显存)来说捉襟见肘,且无法同时运行多个模型。
-
解决方案:模型量化,作者测试了两种现代 LLM 量化技术:
-
8-bit 量化
-
4-bit 量化 (使用 bitsandbytes 库)
-
-
核心发现:
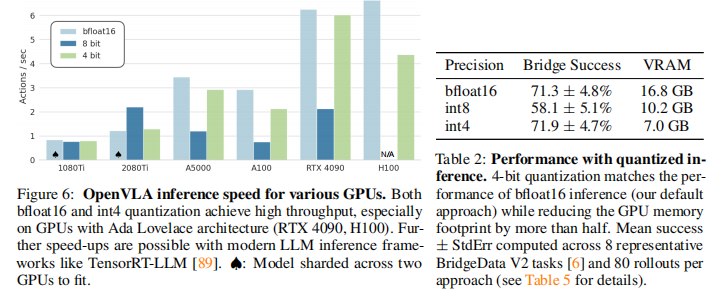
-
显存大幅降低:
-
bfloat16 (默认):~15GB 显存。
-
4-bit 量化:显存占用降至 一半以下 (<8GB)。这意味着 OpenVLA 可以在 RTX 3080 甚至更低端的显卡上运行。
-
-
性能无损:
- 令人惊讶的是,4-bit 量化模型的任务成功率与全精度 (bfloat16) 模型完全一致。这表明 VLA 模型在推理时具有极高的参数冗余。
-
速度反直觉:
-
4-bit:推理速度较快,吞吐量高(因为显存传输数据量变小了,抵消了反量化的计算开销)。
-
8-bit:推理速度反而变慢了(比 bfloat16 还慢)。
-
原因:8-bit 量化的计算开销较大,且未能像 4-bit 那样显著减少显存传输时间,导致“得不偿失”。
-
-
-
推理速度(上图):
-
在 NVIDIA RTX 4090 上:OpenVLA (4-bit) 可以达到 >10Hz 的推理控制频率,完全满足实时机器人控制的需求。
-
在 H100 等服务器显卡上:速度更快,适合大规模并行推理。
-
实验结果表格: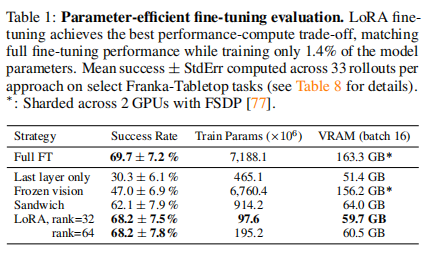
-
表格:不同微调策略的对比作者对比了不同微调方法在 BridgeData V2 任务上的成功率、可训练参数量和显存占用:
-
全量微调 (Full FT):
-
成功率:69.7%
-
显存:163.3 GB (极高,需要 A100 集群)
-
-
LoRA (Sandwich / Standard):
-
成功率:62.1% (与全量微调相当接近)
-
显存:显著降低(允许在消费级显卡上训练)。
-
-
仅微调最后一层 (Last layer only):
- 成功率:30.3% (性能崩塌,证明仅调输出层不可行)。
-
冻结视觉 (Frozen vision):
- 成功率:47.0% (性能显著下降,证明必须微调视觉编码器)。
-
-
表格:量化推理对比 (Quantization Results) 展示了不同精度下的成功率与显存需求(测试环境 RTX 4090):
-
bfloat16 (半精度):
-
成功率:71.3%
-
显存:16.8 GB
-
-
int8 (8-bit 量化):
- 成功率:58.1% (性能下降,原因是推理速度变慢导致控制延迟)。
-
4-bit (4-bit 量化):
-
成功率:71.3% (与全精度完全一致!)。
-
显存:< 8 GB (大幅降低,人人可用)。
-
-
七、讨论与局限性
在正文的最后,作者非常诚恳地讨论了 OpenVLA 目前存在的不足,并为未来的研究指明了方向:
- 推理速度与高频控制:
-
问题:虽然 OpenVLA 达到了 ~10Hz,但对于像 ALOHA 这样需要 50Hz 控制频率的高动态任务(如接球、快速避障)来说,目前的 VLM 推理速度仍然太慢。
-
未来方向:作者建议探索动作分块 (Action Chunking)(一次预测未来多个动作)或推测性解码 (Speculative Decoding) 来提升推理吞吐量。
- 可靠性:
-
问题:尽管 OpenVLA 优于其他通用策略,但其绝对成功率通常在 90% 以下。对于工业级应用来说,这还不够可靠。
-
现状:目前的 VLA 更多是作为研究基座,距离完美解决机器人操控还有距离。
- 计算限制带来的未解之谜: 由于训练 VLA 极其消耗算力,作者坦言还有很多设计问题没来得及探索:
-
模型大小:更大的 VLM 基座(如 13B, 34B, 70B)会带来多大的性能提升?
-
联合训练:如果同时在“机器人动作数据”和“互联网视觉-语言数据”上进行联合训练 (Co-training),是否会比现在的“预训练-微调”模式更好?
-
视觉特征:是否有比 SigLIP + DINOv2 更适合机器人的视觉表示?
ManiSkill2 与 LIBERO 框架选择指南
一、核心定位区分
| 框架/基准 | 核心定位 | 核心目标 |
|---|---|---|
| ManiSkill2 | 机器人操作技能泛化基准 | 提升单任务/多任务的跨物体、跨场景泛化能力 |
| LIBERO | 机器人操作终身学习基准 | 实现持续学习新任务时不遗忘旧知识,优化知识迁移效率 |
二、关键差异速览
| 对比维度 | ManiSkill2 | LIBERO |
|---|---|---|
| 核心场景 | 拾取、堆叠、插入等通用操作 | 长时任务序列、动态场景变化、多任务持续学习 |
| 数据支持 | 2000+物体模型、400万+演示帧,数据丰富 | 聚焦任务迁移与遗忘抑制,演示数据相对精简 |
| 上手难度 | 低-中,文档完善、快速搭建实验 | 中-高,需具备终身学习基础,任务设计复杂 |
| 适用研究方向 | 操作技能泛化、模仿学习、强化学习 | 终身学习、持续学习、知识迁移鲁棒性 |
三、备注
两者的核心定位是「基于仿真平台的任务基准 + 算法评估框架」—— 本身不提供底层物理仿真功能,而是依赖成熟仿真平台构建标准化任务、提供数据工具,用于评估机器人操作学习算法的性能。
- 依赖的仿真平台:均基于 SAPIEN(Intel 开源的高性能物理仿真平台);
- 核心价值:解决机器人操作学习领域「任务不统一、评估标准混乱」的问题,让不同算法能在同一套任务体系下公平对比。
复现Base Model
服务器是在无问芯穷租赁的,相关配置如下:
一、LIBERO方案
- 初始化系统与 Conda (开机第一步)
由于 NGC 镜像默认不带 Conda,且系统盘较小,需在数据盘手动安装。
# 1. 进入数据盘
cd /datadisk
# 2. 安装系统级渲染依赖 (LIBERO/MuJoCo 必须)
apt-get update && apt-get install -y libosmesa6-dev libgl1-mesa-glx libglfw3 patchelf git vim
# 3. 安装 Miniconda
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.sh -b -p /datadisk/miniconda3
rm Miniconda3-latest-Linux-x86_64.sh
# 4. 初始化环境变量
/datadisk/miniconda3/bin/conda init bash
source ~/.bashrc
- 解决协议与创建环境
解决 Anaconda 的 ToS 协议报错,并建立隔离环境(若和我使用相同镜像,这一步请跟着做)。
# 1. 接受协议 (防止报错)
conda config --set channel_priority flexible
conda tos accept --override-channels --channel https://repo.anaconda.com/pkgs/main
conda tos accept --override-channels --channel https://repo.anaconda.com/pkgs/r
# 2. 创建并激活环境
conda create -n openvla python=3.10 -y
conda activate openvla
3.安装核心计算库PyTorch
避开 NGC 系统源干扰,强制安装兼容 Flash Attention 的 CUDA 12.1 版本 PyTorch。
pip install torch==2.3.0 torchvision==0.18.0 torchaudio==2.3.0 --index-url https://download.pytorch.org/whl/cu121 --extra-index-url https://pypi.org/simple
我们现在的状态是:Conda 环境 (openvla) 已激活,PyTorch 已就位。 请依次执行以下步骤,完成 OpenVLA 和 LIBERO 的最终部署。
第一步:安装仿真环境与 OpenVLA 源码
cd /datadisk
# 1. 创建项目文件夹
mkdir -p my_project/openvla_root
cd my_project
# 2. 安装 LIBERO 和 MuJoCo
pip install mujoco
# pip install libero下来的版本可能很老
git clone https://github.com/Lifelong-Robot-Learning/LIBERO.git
cd LIBERO
pip install -e .
cd ..
# 3. 克隆 OpenVLA 代码
git clone https://github.com/openvla/openvla.git
cd openvla
# 4. 安装其余依赖
pip install -r requirements-min.txt
第二步:安装 Flash Attention 2 (A800 核心加速)
这是最耗时的一步(通常需要 5-10 分钟编译),请耐心等待不要中断。
pip install packaging ninja
pip install flash-attn --no-build-isolation
第三步: 登录huggingface下载模型权重
我们需要去官网生成对应token,注意不能使用香港节点进行注册,注册好后认证邮箱,接下来可以去settings中生成token并复制下来,这样就获得了后续下载的权限。
pip install huggingface_hub
export HF_ENDPOINT=https://hf-mirror.com # 连接国内镜像站
hf auth login # 输入刚刚生成的token,遇到 Add token as git credential? (Y/n) 时,输入 n 并回车
第四步: 登录成功后,我们马上创建一个脚本,一次性验证 Flash Attention (GPU加速)、LIBERO (仿真) 和 OpenVLA (模型加载) 是否全部正常。
# 1. 回到项目根目录 (不要在 openvla 源码文件夹里跑测试,防止 import 路径混淆)
cd /datadisk/my_project
# 2. 创建测试脚本
vim test_final.py
在编辑器中粘贴以下代码(按 i 进入编辑模式 -> 粘贴 -> 按 Esc -> 输入 :wq 保存退出):
import os
import torch
from transformers import AutoModelForVision2Seq, AutoProcessor
# --- 1. 基础环境检查 ---
print("="*50)
print("[Step 1] Checking Hardware & Drivers...")
print(f"PyTorch Version: {torch.__version__}")
print(f"CUDA Available: {torch.cuda.is_available()}")
device_name = torch.cuda.get_device_name(0)
print(f"GPU Device: {device_name}")
# 检查 Flash Attention 是否可用 (A800 必备)
try:
# 尝试导入 flash_attn 包
import flash_attn
print("Flash Attention 2 Package: INSTALLED ✅")
use_flash = True
except ImportError:
print("Flash Attention 2 Package: NOT FOUND ❌ (Running slow mode)")
use_flash = False
# --- 2. 仿真环境检查 ---
print("\n[Step 2] Checking Simulation Environment...")
# 强制使用 EGL 后端 (因为服务器没有显示器)
os.environ['MUJOCO_GL'] = 'egl'
try:
import mujoco
import libero.libero
print("MuJoCo & LIBERO: IMPORT SUCCESS ✅")
except Exception as e:
print(f"LIBERO Error: {e} ❌")
# --- 3. 模型加载测试 ---
print("\n[Step 3] Loading OpenVLA-7B (Downloading ~15GB)...")
print("⚠️ This may take 5-10 minutes. Please wait...")
model_id = "openvla/openvla-7b"
try:
# 加载处理器
processor = AutoProcessor.from_pretrained(model_id, trust_remote_code=True)
# 加载模型 (自动使用 Flash Attention 2)
vla = AutoModelForVision2Seq.from_pretrained(
model_id,
attn_implementation="flash_attention_2" if use_flash else "eager",
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
trust_remote_code=True
).to("cuda:0")
print("\n🎉🎉🎉 SUCCESS! OpenVLA loaded on " + device_name)
print("Environment is 100% READY for experiments.")
except Exception as e:
print(f"\n❌ Model Load Failed: {e}")
print("Possible reasons: HF Token not valid, Network issue, or Flash Attn mismatch.")
print("="*50)
此时再执行如下命令:
# 1. 补齐缺失的 Python 包
pip install accelerate
# 2. 设置渲染环境变量 (解决 LIBERO 报错的关键)
export PYOPENGL_PLATFORM=egl
# 3. 再次运行测试脚本
python test_final.py
此时大概率虽然模型好了,但日志里还有一行红字: LIBERO Error: ‘NoneType’ object has no attribute ‘eglQueryString’ ❌
这意味着仿真环境(机器人模拟器)还是坏的。虽然模型加载了,但机器人“看不见”东西。这是因为我们是租的卡,服务器没有显示器,我们需要安装一个支持“无头模式”渲染的库。
故接下来请执行如下指令完善环境:
# 1. 安装缺少的系统级 EGL 库 (解决报错的核心)
apt-get update && apt-get install -y libegl1 libegl1-mesa
# 2. 将渲染配置写入系统文件 (防止下次重启失效)
echo 'export PYOPENGL_PLATFORM=egl' >> ~/.bashrc
echo 'export MUJOCO_GL=egl' >> ~/.bashrc
source ~/.bashrc
conda activate openvla
# 3. 再次验证
python test_final.py
此时会出现提示Do you want to specify a custom path for the dataset folder? (Y/N):
我们选择Y,接着它会问你路径,请输入:
/datadisk/my_project/libero_data
后续的提示也一律输入Y即可。
由于租来的服务器没有屏幕,我们无法实时看到机器人,所以我们的目标是:运行一段推理代码,让 OpenVLA 控制机器人完成一个任务,并生成一个视频文件供你查看。
第一步:创建推理脚本
我们将创建一个名为 quick_start.py 的脚本。这个脚本会做以下几件事:
-
启动 LIBERO 仿真环境(任务:拿起一个黑色碗)。
-
加载 OpenVLA 模型。
-
循环执行: 机器人看一眼 -> 问大模型该怎么动 -> 大模型输出动作 -> 机器人执行。
-
最后保存一个 .mp4 视频文件。
请在终端执行:
cd /datadisk/my_project
vim quick_start.py
效仿上面的vim操作,将下列内容写入脚本保存退出:
import torch
import numpy as np
from PIL import Image
from transformers import AutoModelForVision2Seq, AutoProcessor
from libero.libero.envs import OffScreenRenderEnv
import os
import imageio
# --- 配置 ---
MODEL_PATH = "openvla/openvla-7b"
BDDL_FOLDER = "libero_spatial"
BDDL_FILE = "pick_up_the_black_bowl_between_the_plate_and_the_ramekin_and_place_it_on_the_plate.bddl"
DEVICE = "cuda:0"
# --- 关键修改:使用通用数据集统计量 ---
# 原始模型不包含 'libero_spatial',必须使用 'bridge_orig' 作为通用代理
UNNORM_KEY = "bridge_orig"
print("="*50)
print("[1/4] Initializing LIBERO Simulation Environment...")
if "BDDL_FILES" not in os.environ:
raise ValueError("❌ Error: BDDL_FILES environment variable is missing. Please run 'source ~/.bashrc' first.")
env_args = {
"bddl_file_name": os.path.join(os.environ["BDDL_FILES"], BDDL_FOLDER, BDDL_FILE),
"camera_heights": 256,
"camera_widths": 256,
"camera_depths": False,
}
try:
env = OffScreenRenderEnv(**env_args)
env.reset()
print(f"✅ Simulation Ready. Loaded: {BDDL_FILE}")
except Exception as e:
print(f"❌ Failed to load environment: {e}")
exit()
print("\n[2/4] Loading OpenVLA Model (Flash Attention)...")
# 加载 Processor 和 Model
processor = AutoProcessor.from_pretrained(MODEL_PATH, trust_remote_code=True)
vla = AutoModelForVision2Seq.from_pretrained(
MODEL_PATH,
attn_implementation="flash_attention_2",
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
trust_remote_code=True
).to(DEVICE)
print("✅ Model Loaded.")
print("\n[3/4] Starting Robot Inference Loop (30 steps demo)...")
# 提示词格式
prompt = "In: What action should the robot take to {}?\nOut:"
instruction = "pick up the black bowl between the plate and the ramekin and place it on the plate"
frames = []
obs = env.reset()
for step in range(30):
img_array = obs["agentview_image"]
image = Image.fromarray(img_array[::-1])
frames.append(img_array[::-1])
# 准备输入
inputs = processor(text=prompt.format(instruction), images=image, return_tensors="pt").to(DEVICE, dtype=torch.bfloat16)
# 推理动作
with torch.inference_mode():
# 这里使用了修正后的 UNNORM_KEY="bridge_orig"
action = vla.predict_action(**inputs, unnorm_key=UNNORM_KEY, do_sample=False)
# 执行动作
obs, reward, done, info = env.step(action)
print(f"\rStep {step+1}/30: Action Generated -> Executed", end="", flush=True)
print("\n\n[4/4] Saving Video...")
video_path = "robot_demo.mp4"
imageio.mimsave(video_path, np.stack(frames), fps=10)
print(f"🎉🎉🎉 Video saved to: {os.path.abspath(video_path)}")
print("="*50)
第二步:安装视频处理库
我们需要 imageio 来把图片合成视频:
pip install imageio[ffmpeg]
第三步: 运行脚本
每次运行都需要保证激活了环境且加载了环境变量,即:conda activate openvla与source ~/.bashrc
python quick_start.py
第四步: 因为服务器没有显示器,要查看刚刚生成的视频文件 robot_demo.mp4,需要把它下载到你自己的电脑上。
若和我一样是使用VSCode进行的连接,可以按照如下操作进行查看:
-
在 VS Code 左侧的 “资源管理器” (Explorer) 栏中。
-
通过路径导航找到 /datadisk/my_project
-
找到 robot_demo.mp4 文件。
-
右键点击它,选择 “Download” 。
-
保存到电脑桌面,双击就能播放了。
此时我遇到了一个问题,上述mp4视频时间过短,机械臂还没有动起来就结束了,且关闭终端后重新运行时断网了。我们在上一步代码里加上 local_files_only=True (强制离线模式)并修改视频时长来解决这个问题,此时我们新建脚本:
vim quick_start_offline.py
粘贴下列内容:
import torch
import numpy as np
from PIL import Image
from transformers import AutoModelForVision2Seq, AutoProcessor
from libero.libero.envs import OffScreenRenderEnv
import os
import imageio
# --- 配置 ---
MODEL_PATH = "openvla/openvla-7b"
BDDL_FOLDER = "libero_spatial"
BDDL_FILE = "pick_up_the_black_bowl_between_the_plate_and_the_ramekin_and_place_it_on_the_plate.bddl"
DEVICE = "cuda:0"
UNNORM_KEY = "bridge_orig"
print("="*50)
print("[1/4] Initializing LIBERO Simulation Environment...")
if "BDDL_FILES" not in os.environ:
raise ValueError("❌ Error: BDDL_FILES environment variable is missing.")
env_args = {
"bddl_file_name": os.path.join(os.environ["BDDL_FILES"], BDDL_FOLDER, BDDL_FILE),
"camera_heights": 256,
"camera_widths": 256,
"camera_depths": False,
}
try:
env = OffScreenRenderEnv(**env_args)
env.reset()
print(f"✅ Simulation Ready.")
except Exception as e:
print(f"❌ Failed to load environment: {e}")
exit()
print("\n[2/4] Loading OpenVLA Model (OFFLINE MODE)...")
# --- 关键修改:添加 local_files_only=True ---
try:
processor = AutoProcessor.from_pretrained(
MODEL_PATH,
trust_remote_code=True,
local_files_only=True # <--- 强制离线
)
vla = AutoModelForVision2Seq.from_pretrained(
MODEL_PATH,
attn_implementation="flash_attention_2",
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
trust_remote_code=True,
local_files_only=True # <--- 强制离线
).to(DEVICE)
print("✅ Model Loaded from local cache.")
except Exception as e:
print(f"❌ Failed to load model offline. Ensure model is downloaded. Error: {e}")
exit()
print("\n[3/4] Starting Robot Inference Loop (100 steps demo)...")
prompt = "In: What action should the robot take to {}?\nOut:"
instruction = "pick up the black bowl between the plate and the ramekin and place it on the plate"
frames = []
obs = env.reset()
# --- 保持之前的暴力调试逻辑 ---
for step in range(100):
img_array = obs["agentview_image"]
image = Image.fromarray(img_array)
frames.append(img_array[::-1])
inputs = processor(text=prompt.format(instruction), images=image, return_tensors="pt").to(DEVICE, dtype=torch.bfloat16)
with torch.inference_mode():
action = vla.predict_action(**inputs, unnorm_key=UNNORM_KEY, do_sample=False)
# 打印前3个数值(XYZ移动量)
if step % 10 == 0:
print(f"Step {step}: Action XYZ = {action[:3]}")
# 暴力放大动作 (Hack)
action = action * 10.0
obs, reward, done, info = env.step(action)
print(f"\rStep {step+1}/100", end="", flush=True)
print("\n\n[4/4] Saving Video...")
video_path = "robot_demo_debug.mp4"
imageio.mimsave(video_path, np.stack(frames), fps=20)
print(f"🎉 Video saved to: {os.path.abspath(video_path)}")
print("="*50)
接下来重新运行并寻找生成的视频robot_demo_debug.mp4即可。
打开视频观看后大概率发现,机械臂几乎没动或者乱动,此时我们需要进行微调。
二、ManiSkill2方案(我自己的失败参考,不用看这里)
因为OpenVLA运行大概需要14G,加上仿真平台等,在最初我选择的是在autodl上租24G的RTX40来尝试。在选择镜像时需要注意,很多老库不支持python3.11及以上,最好死守python3.10;RTX40需要配合12.X,pytorch选择官方的2.2.0最好,否则选择2.1.0或者2.3.0, 因为2.4.0和官方的2.2.0差距过大。
打开新终端,通常显示是在/root下
# 1. 更新系统软件源
apt-get update
# 2. 安装仿真器必须的图形库(这步不装后面会报错)
apt-get install -y libvulkan1 libgl1-mesa-glx libosmesa6-dev ffmpeg
我租的这个卡配的系统没有预置学术加速的脚本,所以直接换源
cat > ~/.condarc <<EOF
channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/menpo/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/bioconda/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
show_channel_urls: true
EOF
虽然我加了清华源,但 Conda 还是“头铁”地去尝试连接国外的官网,我们可以采用下面的指令让它忽略默认源,强制走镜像
conda create -n vla python=3.10 -c https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main -y --override-channels
conda activate vla # 后续每次连接服务器均需激活
pip install torch==2.2.0 torchvision==0.17.0 torchaudio==2.2.0 -i https://pypi.tuna.tsinghua.edu.cn/simple # 同样是告诉pip指定清华源
cd /root
git clone https://mirror.ghproxy.com/https://github.com/openvla/openvla.git
cd openvla
pip install -r requirements-min.txt -i https://pypi.tuna.tsinghua.edu.cn/simple # 安装OpenVLA的精简版依赖文件
pip install mani_skill2 -i https://pypi.tuna.tsinghua.edu.cn/simple # 单独把仿真器装上(因为精简版依赖里不包含仿真环境)
因为 AutoDL 的服务器在国内,而这些 3D 资源存放在国外的 HuggingFace 上,直接下载会被限速。故我们使用以下操作流程:
mkdir -p /root/data # 在 /root 下建一个专门放素材的文件夹,方便管理
cd /root/data
# 1. 设置镜像
export HF_ENDPOINT=https://hf-mirror.com
# 2. 下载 YCB 压缩包
huggingface-cli download haosulab/ManiSkill2 data/mani_skill2_ycb.zip --repo-type dataset --local-dir . --local-dir-use-symlinks False
apt-get update
apt-get install -y unzip
unzip -o mani_skill2_ycb.zip
ls -F
# 预期输出: mani_skill2_ycb/ mani_skill2_ycb.zip
# 写入环境变量
cat >> ~/.bashrc <<EOF
export MANISKILL2_ASSET_DIR="/root/data"
EOF
source ~/.bashrc
cd /root/openvla
touch run_demo.py
code run_demo.py
将下列内容放入run_demo.py:
import torch
import gymnasium as gym
import numpy as np
from transformers import AutoModelForVision2Seq, AutoProcessor
from PIL import Image
import mani_skill2.envs
# -------------------------------------------------------------------------
# 1. 设置配置
# -------------------------------------------------------------------------
# 使用 OpenVLA-7B 模型 (HuggingFace 自动下载)
MODEL_PATH = "openvla/openvla-7b"
# 仿真环境任务:机器臂抓取方块
ENV_NAME = "PickCube-v1"
print("正在初始化环境,准备下载模型(第一次运行会比较久,请耐心等待 5-10 分钟)...")
# -------------------------------------------------------------------------
# 2. 加载模型 (OpenVLA)
# -------------------------------------------------------------------------
processor = AutoProcessor.from_pretrained(MODEL_PATH, trust_remote_code=True)
# 使用 4-bit 量化加载以节省显存 (如果没有 bitsandbytes,这里可能需要改为 torch.float16)
try:
model = AutoModelForVision2Seq.from_pretrained(
MODEL_PATH,
trust_remote_code=True,
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True
).to("cuda:0")
except ImportError:
print("未检测到量化库,尝试使用标准半精度加载...")
model = AutoModelForVision2Seq.from_pretrained(
MODEL_PATH,
trust_remote_code=True,
torch_dtype=torch.bfloat16
).to("cuda:0")
print("✅ 模型加载完成!")
# -------------------------------------------------------------------------
# 3. 启动仿真环境 (ManiSkill2)
# -------------------------------------------------------------------------
# obs_mode="rgbd" 表示我们需要图像输入
env = gym.make(ENV_NAME, obs_mode="rgbd", control_mode="pd_joint_delta_pos", render_mode="rgb_array")
obs, _ = env.reset()
print(f"✅ 仿真环境 {ENV_NAME} 已启动")
# -------------------------------------------------------------------------
# 4. 主循环:让机器人动起来
# -------------------------------------------------------------------------
# 简单的指令
instruction = "Pick up the red cube and move it to the green goal."
for step in range(20): # 我们先试运行 20 步
# 获取当前摄像头的画面
image_rgb = obs['image']['hand_camera']['rgb'] # 获取手眼相机的图像
image = Image.fromarray(image_rgb)
# 构造 Prompt
prompt = f"In: What action should the robot take to {instruction}?\nOut:"
# 预处理输入
inputs = processor(images=image, text=prompt, return_tensors="pt").to("cuda:0", torch.bfloat16)
# 模型推理 (生成动作)
with torch.inference_mode():
action = model.predict_action(**inputs, unnorm_key=ENV_NAME, do_sample=False)
# 执行动作
obs, reward, terminated, truncated, info = env.step(action)
print(f"Step {step+1}: 动作已执行")
if terminated or truncated:
obs, _ = env.reset()
print("🎉 恭喜!Demo 运行结束,环境配置完全成功!")
env.close()
然后Ctrl+S保存后即可运行:
python run_demo.py
到这里就出现了一些难以解决的问题了,gemini给出的解释如下:
在尝试了gemini给我的所有办法后仍然失败,故放弃在这个框架下进行复现。
微调OpenVLA
一、训练
在 /datadisk/my_project/ 下创建一个名为 download_data.py 的文件,代码如下:
import os
from huggingface_hub import snapshot_download
# 数据保存路径 (建议放在 datadisk 这种大盘里)
DATA_ROOT = "/datadisk/datasets/openvla-libero-spatial"
os.makedirs(DATA_ROOT, exist_ok=True)
print(f"正在准备下载数据到: {DATA_ROOT} ...")
# 下载 LIBERO-Spatial 数据集 (针对空间方位理解的任务)
# 这是一个很好的起点,数据量适中 (约 15GB)
snapshot_download(
repo_id="openvla/modified_libero_rlds",
repo_type="dataset",
local_dir=DATA_ROOT,
allow_patterns="*libero_spatial*", # 只下载 spatial 相关数据,节省时间
resume_download=True
)
print("✅ 下载完成!Dataset Download Complete!")
由于网络问题,后续我会去github下载源码到我的本地,再拖入vscode。
dlimp源码压缩包下载
将其拖入/datadisk/my_project/目录
unzip dlimp-main.zip
mv dlimp-main dlimp
rm dlimp-main.zip
cd dlimp
pip install -e .
cd ..
HF_ENDPOINT=https://hf-mirror.com python download_data.py # 运行数据下载 (利用国内镜像跑通)
此时我们可以开始准备训练脚本:在 /datadisk/my_project/openvla/ 目录下,新建一个文件,命名为 train_libero.sh,内容如下(注意在脚本倒数第三行修改自己的用户名):
#!/bin/bash
export HF_ENDPOINT=https://hf-mirror.com
# 显存优化配置:如果你不想登录 wandb,可以取消下面这行的注释
# export WANDB_MODE=offline
# 设置多卡/单卡端口,防止冲突
export MASTER_PORT=29505
# 启动训练
# A800 专属配置:
# 1. 不使用 --load_in_4bit (保持 BFloat16 高精度,效果更好)
# 2. batch_size 设为 16 (显存大,跑得更快)
torchrun --standalone --nnodes 1 --nproc-per-node 1 vla-scripts/finetune.py \
--vla_path "openvla/openvla-7b" \
--data_root_dir "/datadisk/datasets/openvla-libero-spatial" \
--dataset_name "libero_spatial_no_noops" \
--run_root_dir "/datadisk/checkpoints" \
--adapter_tmp_dir "/datadisk/adapter_tmp" \
--lora_rank 32 \
--batch_size 16 \
--grad_accumulation_steps 1 \
--learning_rate 5e-4 \
--image_aug True \
--wandb_project "openvla-finetune" \
--wandb_entity "zsccyd" \
--save_steps 1000 \
--max_steps 5000
此时训练脚本默认会连接 wandb (Weights & Biases) 来画 Loss 曲线图,我们在终端输入:
wandb login
再去wandb.ai官网进行注册拿到API Key,再输入终端,接下来输入:
cd /datadisk/my_project/openvla/
# 赋予脚本执行权限
chmod +x train_libero.sh
# 安装 draccus 以及微调必须的 peft (LoRA库) 和 bitsandbytes (显存优化)
pip install draccus peft bitsandbytes wandb
# 升级 transformers 和 accelerate
pip install --upgrade transformers accelerate
# 这一步会把 prismatic 包注册到环境里,以后在哪里都能 import 到了
pip install -e .
# 降级 bitsandbytes 等以适配 Torch 2.2.0
pip install bitsandbytes==0.43.1
pip uninstall -y flash-attn
pip install flash-attn --no-build-isolation
# 运行!
./train_libero.sh
到这一步你可能就要遇到问题了,接下来请看后面的“训练时可能遇到的问题”章节进行解决。
二、训练时可能遇到的问题
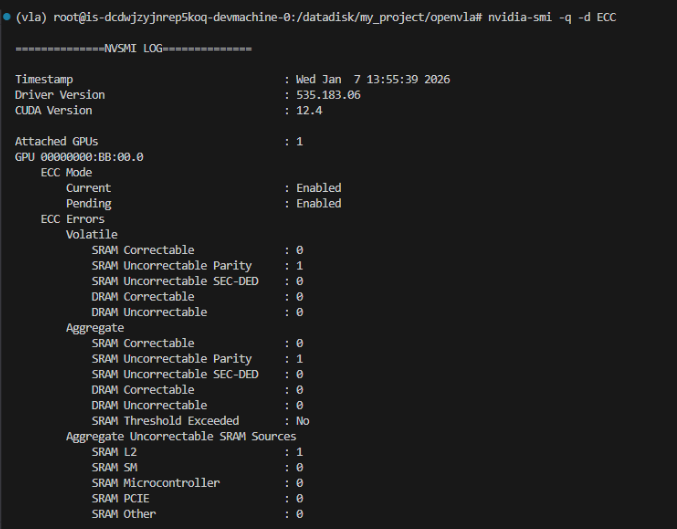
1、把训练挂在那里,我离开了工位。第二天来到工位,居然告诉我服务器异常了,气煞我也!我重启了服务器,但依旧面临同样的问题,最后根据gemini的指示逐一排查,发现可能是显卡过热造成物理损坏了。
我们可以尝试改配,选择不恢复系统盘数据,配置相同的预置镜像,再换一个型号的卡就好了。
此时只需要再重装一下之前针对A800的加速包,会自动匹配好适配的新加速包,我们只需执行如下指令:
/datadisk/miniconda3/bin/conda init bash
source ~/.bashrc
conda activate openvla
# 1. 卸载旧的(避免冲突)
pip uninstall -y flash-attn
# 2. 重新安装(会自动识别新架构进行编译,大约需要 2-5 分钟)
pip install flash-attn --no-build-isolation
cd /datadisk/my_project/openvla
./train_libero.sh
2、另一个遇到的问题是,由于训练是连接到云服务器,本地网络也要确保流畅,一定要记得在训练时关闭加速器以免网络波动造成断连
3、如果云服务器的网络不行,遇到其他文件无法clone等问题时,可以效仿微调OpenVLA中下载到本地再拖进vscode的方法。同时如果网络不好,大概率登录不了wandb,请将脚本中的# export WANDB_MODE=offline注释取消掉
4、换卡后我的内存只有28G,训练时由于脚本设置每1000轮保存一次。当第1001轮进行保存时内存爆了,因为程序不仅要存 LoRA 参数,还要把整个巨大的Embedding层(词向量表)读到内存里存下来。我最开始的思路是既然物理内存(28GB)不够,可以利用你的数据盘划出一部分作为虚拟内存。虽然速度慢,但能防止程序因为瞬间内存峰值而崩溃。
# 1. 创建一个32G的文件
sudo fallocate -l 32G /swapfile
# 2. 修改权限
sudo chmod 600 /swapfile
# 3. 设置为swap空间
sudo mkswap /swapfile
# 4. 启用swap
sudo swapon /swapfile
# 5. 验证是否生效 (看 Swap 一栏是否变为了 32G)
free -h
如此操作后仍然不行,执行free -h后发现,由于我目前使用的这个云服务器环境是一个 Docker 容器,它没有权限修改系统内核级的 Swap 设置,宿主机把这个权限锁死了,所以实际上我并没有成功创建虚拟内存。而将保存时的训练轮次改小并没有用,不管如何都是保存LoRA文件和词表矩阵,整体参数也仍然是7B。
在 7B 模型中,Embedding 层非常巨大。如果你的微调任务只是让机器人学动作(通常不需要修改语言模型的词表),我们完全可以不保存这一层。故可以打开微调脚本 vla-scripts/finetune.py ,找到
# 原代码
save_dir = adapter_dir if cfg.use_lora else run_dir
并将其改成:
# 修改后
save_dir = run_dir
并将如下代码注释掉:
# Wait for processor and adapter weights to be saved by main process
dist.barrier()
# ================= ✂️ 从这里开始注释/删除 ✂️ =================
# Merge LoRA weights into model backbone for faster inference
# if cfg.use_lora:
# base_vla = AutoModelForVision2Seq.from_pretrained(
# cfg.vla_path, torch_dtype=torch.bfloat16, low_cpu_mem_usage=True, trust_remote_code=True
# )
# merged_vla = PeftModel.from_pretrained(base_vla, adapter_dir)
# merged_vla = merged_vla.merge_and_unload()
# if distributed_state.is_main_process:
# if cfg.save_latest_checkpoint_only:
# # Overwrite latest checkpoint
# merged_vla.save_pretrained(run_dir)
# print(f"Saved Model Checkpoint for Step {gradient_step_idx} at: {run_dir}")
# else:
# # Prepare to save checkpoint in new directory
# checkpoint_dir = Path(str(run_dir) + f"--{gradient_step_idx}_chkpt")
# os.makedirs(checkpoint_dir, exist_ok=True)
# # Save dataset statistics to new directory
# save_dataset_statistics(vla_dataset.dataset_statistics, checkpoint_dir)
# # Save processor and model weights to new directory
# processor.save_pretrained(checkpoint_dir)
# merged_vla.save_pretrained(checkpoint_dir)
# print(f"Saved Model Checkpoint for Step {gradient_step_idx} at: {checkpoint_dir}")
# ================= ✂️ 到这里结束 ✂️ =================
# Block on Main Process Checkpointing
dist.barrier()
此时再进行微调即可,LoRA文件应该是保存在/datadisk/checkpoints里面。
三、微调效果验证
我们先验证微调模型是否可用,在/datadisk/my_project下创建验证脚本test_model.py并注意更改LoRA权重路径:
import torch
from transformers import AutoModelForVision2Seq, AutoProcessor
from peft import PeftModel
from PIL import Image
import requests
# 1. 你的 LoRA 权重路径 (请根据你的实际文件夹修改这里!)
# 通常在 runs/ 下面,找到那个以 checkpoint-5000 结尾或者最新的文件夹
# 示例路径,你需要改成你机器上真实存在的那个路径:
ADAPTER_PATH = "/datadisk/checkpoints/openvla-7b+libero_spatial_no_noops+b16+lr-0.0005+lora-r32+dropout-0.0--image_aug"
# 注意:要把上面这个路径改成你 ls runs/ 看到的那个真实路径
# 2. 基础模型路径
BASE_MODEL_PATH = "openvla/openvla-7b"
print("正在加载基础模型...")
# 加载处理器
processor = AutoProcessor.from_pretrained(BASE_MODEL_PATH, trust_remote_code=True)
# 加载基础模型 (以 bfloat16 加载节省显存)
model = AutoModelForVision2Seq.from_pretrained(
BASE_MODEL_PATH,
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
trust_remote_code=True
).to("cuda")
print(f"正在挂载微调权重: {ADAPTER_PATH}")
# 加载你训练好的 LoRA "外挂"
model = PeftModel.from_pretrained(model, ADAPTER_PATH)
model.merge_and_unload() # 这一步在显存里合并,方便推理
print("模型加载成功!准备测试...")
# 3. 搞一张测试图片 (这里用一张网上的示例图,或者你可以换成你自己的本地图片)
print("⚠️由于网络限制,正在使用本地生成的测试图片...")
# 创建一张 224x224 的纯黑图片,足以用来测试模型通道是否打通
image = Image.new('RGB', (224, 224), color='black')
# 4. 输入一条指令 (Prompt)
prompt = "In: What action should the robot take to [pick up the yellow block]?\nOut:"
# 5. 处理输入
inputs = processor(prompt, image).to("cuda", dtype=torch.bfloat16)
# 6. 预测动作
print("正在预测动作...")
action = model.predict_action(**inputs, unnorm_key="bridge_orig", do_sample=False)
print("\n====== 预测结果 ======")
print(f"指令: {prompt}")
print(f"模型生成的动作向量: {action}")
print("======================")
保存后在终端执行:
HF_ENDPOINT=https://hf-mirror.com python test_model.py # 使用了huggingface的国内镜像
看到打印出数字向量后就证明模型可用,其中前 3 个数表示机械臂在空间中的位移 (x, y, z),中间 3 个数:机械臂的旋转角度 (roll, pitch, yaw),最后 1 个数:夹爪的开合状态 (0. 代表闭合或保持原状)。
因为我们使用的是 libero_spatial 数据集微调的,所以最有价值的测试是跑 Libero 模拟器评估,看看成功率是多少。OpenVLA 代码库通常自带评估脚本,我们先找到位置:
find /datadisk/my_project -name run_libero_eval.py
大概率得到如下结果(后续使用注意改成你自己的实际路径):
/datadisk/my_project/openvla/experiments/robot/libero/run_libero_eval.py
此时我们带上正确路径,包括我们之前找到的训练后的checkpoints文件,运行评估(我也加上了 HF_ENDPOINT,防止加载模型时联网报错):
HF_ENDPOINT=https://hf-mirror.com python /datadisk/my_project/openvla/experiments/robot/libero/run_libero_eval.py \
--model_family openvla \
--pretrained_checkpoint /datadisk/checkpoints/openvla-7b+libero_spatial_no_noops+b16+lr-0.0005+lora-r32+dropout-0.0--image_aug \
--task_suite_name libero_spatial \
--center_crop True
此时我遇到了如下报错:
(openvla) root@is-dcdwjzyjnrep5koq-devmachine-0:/datadisk/my_project# HF_ENDPOINT=https://hf-mirror.com python /datadisk/my_project/openvla/experiments/robot/libero/run_libero_eval.py \
--model_family openvla \
--pretrained_checkpoint /datadisk/checkpoints/openvla-7b+libero_spatial_no_noops+b16+lr-0.0005+lora-r32+dropout-0.0--image_aug \
--task_suite_name libero_spatial \
--center_crop True
Traceback (most recent call last):
File "/datadisk/my_project/openvla/experiments/robot/libero/run_libero_eval.py", line 29, in <module>
from libero.libero import benchmark
ModuleNotFoundError: No module named 'libero'
最初我认为是虽然有OpenVLA的代码,但评估脚本依赖的 Libero 仿真环境库并没有被安装到我的 Python 环境中。所以我又重装了一遍,但依旧有相同报错。在向gemini排查后,认为是因为Python的导入路径冲突。 评估脚本 run_libero_eval.py 位于 /datadisk/my_project/openvla/experiments/robot/libero/。注意看,这个路径里有一个文件夹也叫 libero。
当我们运行脚本时,Python 会优先把当前脚本所在的文件夹作为模块搜索路径。所以当我们代码里写 from libero.libero import benchmark 时,Python 会傻傻地去 …/robot/libero/(脚本所在目录)里找 libero 模块,而不是去刚才我们重装的那个系统库里找。这就导致了“李鬼撞李逵”的问题。
在尝试“自动检测”和“标准安装”都失效之后,我们直接用最简单粗暴的方法:“硬编码绝对路径”:
vim /datadisk/my_project/openvla/experiments/robot/libero/run_libero_eval.py
将下面的代码粘贴到文件开头替代原有文件(从第一行直到@dataclass class GenerateConfig…之前):
"""
run_libero_eval.py
"""
import sys
import os
# ==============================================================================
# 💀 暴力修复区 (不要动这里)
# ==============================================================================
# 1. 强制添加 LIBERO 库的绝对路径
# (根据你之前的 ls 结果,源码在 /datadisk/my_project/LIBERO)
sys.path.insert(0, "/datadisk/my_project/LIBERO")
# 2. 强制添加 OpenVLA 项目根目录
# (让脚本能找到 experiments 模块)
sys.path.insert(0, "/datadisk/my_project/openvla")
# 3. 杀掉当前脚本所在的目录,防止同名文件夹冲突
# (把 /datadisk/my_project/openvla/experiments/robot/libero 从搜索路径里踢出去)
current_dir = os.path.dirname(os.path.abspath(__file__))
if current_dir in sys.path:
sys.path.remove(current_dir)
# ==============================================================================
from dataclasses import dataclass
from pathlib import Path
from typing import Optional, Union
import draccus
import numpy as np
import tqdm
import wandb
# 这里的 import 应该能正常工作了
try:
from libero import benchmark
except ImportError:
# 如果还是不行,尝试从子文件夹导入 (兼容不同版本的 Libero)
from libero.libero import benchmark
# 继续导入项目内部模块
from experiments.robot.libero.libero_utils import (
get_libero_dummy_action,
get_libero_env,
get_libero_image,
quat2axisangle,
save_rollout_video,
)
from experiments.robot.openvla_utils import get_processor
from experiments.robot.robot_utils import (
DATE_TIME,
get_action,
get_image_resize_size,
get_model,
invert_gripper_action,
normalize_gripper_action,
set_seed_everywhere,
)
# 下面紧接着就是 @dataclass class GenerateConfig...
此时再运行:
cd /datadisk/my_project/openvla
HF_ENDPOINT=https://hf-mirror.com python experiments/robot/libero/run_libero_eval.py \
--model_family openvla \
--pretrained_checkpoint /datadisk/checkpoints/openvla-7b+libero_spatial_no_noops+b16+lr-0.0005+lora-r32+dropout-0.0--image_aug \
--task_suite_name libero_spatial \
--center_crop True
遇到Do you want to specify a custom path for the dataset folder? (Y/N): 时回答N即可。
此时又报错:AttributeError: ‘NoneType’ object has no attribute ‘eglQueryString’。这说明代码逻辑跑通了,Libero 库也找到了,配置也加载了。现在的报错 AttributeError: … eglQueryString 是渲染引擎的问题。简单来说就是我们的服务器没有显示器,但模拟器试图找显卡驱动来渲染画面,结果迷路了。我们需要告诉 Python我们是在服务器上,使用 EGL 模式来进行后台渲染。
我们只需要在运行命令前,多加两个渲染环境变量:MUJOCO_GL=egl 和 PYOPENGL_PLATFORM=egl即可:
为了确保系统里有 EGL 的基础库,我们先执行如下命令:
apt-get update && apt-get install -y libegl1 libgl1-mesa-glx
此时再重新运行评估
cd /datadisk/my_project/openvla
HF_ENDPOINT=https://hf-mirror.com MUJOCO_GL=egl PYOPENGL_PLATFORM=egl python experiments/robot/libero/run_libero_eval.py \
--model_family openvla \
--pretrained_checkpoint /datadisk/checkpoints/openvla-7b+libero_spatial_no_noops+b16+lr-0.0005+lora-r32+dropout-0.0--image_aug \
--task_suite_name libero_spatial \
--center_crop True
继续报错:ModuleNotFoundError: No module named ‘gym’
说明虽然安装了 robosuite,但它依赖的 Gym 库没有被正确安装(或者版本不对,导致 Python 找不到它)。
这在机器人强化学习环境中很常见,因为新版库都迁移到了 gymnasium,但 LIBERO 代码比较旧,还在用老版 gym。
安装 Gym 为了最大程度兼容 LIBERO 这种老代码,建议安装 0.26 之前的版本(通常是 0.21.0 或 0.25.2)。但为了避免编译错误,我们先试着直接安装一个兼容版本:
pip install "gym<0.26"
此时运行评估应该能看到仿真任务相关数据了:
cd /datadisk/my_project/openvla
HF_ENDPOINT=https://hf-mirror.com MUJOCO_GL=egl PYOPENGL_PLATFORM=egl python experiments/robot/libero/run_libero_eval.py \
--model_family openvla \
--pretrained_checkpoint /datadisk/checkpoints/openvla-7b+libero_spatial_no_noops+b16+lr-0.0005+lora-r32+dropout-0.0--image_aug \
--task_suite_name libero_spatial \
--center_crop True
四、结果分析
Libero Spatial 有 10 个不同的任务,我们每个执行50次。但是不幸的是我运行到第58次,也就是第二个任务时欠费中止了,先将就看看。演示我放在个人github上了,在文章最顶部有链接。
前50次是第一个任务,日志显示成功率为7/50,后面8次是第二个任务,成功率为1/8
但我自己在路径/datadisk/my_project/openvla/rollouts打开仿真视频发现:有非常多的假阴性。
视频显示我实际成功率为:第一个任务13/50,第二个任务5/8。
对此我猜测有如下几个原因:
- 运行评估时的 --center_crop True 指令。Libero 的相机视野比较广,如果开启 Center Crop(中心裁剪),它会把图片四周切掉,只留中间。此时如果物体刚好在桌子边缘,或者模型训练时见过的是“全景图”,那么裁剪后的图片会导致模型产生严重的空间错觉(比如它觉得杯子在中间,实际上杯子在旁边)。
因此我准备关闭裁剪,让模型看全图进行对比:
HF_ENDPOINT=https://hf-mirror.com MUJOCO_GL=egl PYOPENGL_PLATFORM=egl python experiments/robot/libero/run_libero_eval.py \
--model_family openvla \
--pretrained_checkpoint /datadisk/checkpoints/openvla-7b+libero_spatial_no_noops+b16+lr-0.0005+lora-r32+dropout-0.0--image_aug \
--task_suite_name libero_spatial \
--center_crop False
此时遇到新报错,原因是脚本检测到你的模型文件名里包含 image_aug(图像增强),所以它强制你必须开启 center_crop,如果不开它就报错阻止你。我们需要修改对应脚本文件,打开:/datadisk/my_project/openvla/experiments/robot/libero/run_libero_eval.py
将101与102行代码注释掉,注释后代码如下:
# if "image_aug" in cfg.pretrained_checkpoint:
# assert cfg.center_crop, "Expecting `center_crop==True` because model was trained with image augmentations!"
此时重复刚刚的运行指令:
HF_ENDPOINT=https://hf-mirror.com MUJOCO_GL=egl PYOPENGL_PLATFORM=egl python experiments/robot/libero/run_libero_eval.py \
--model_family openvla \
--pretrained_checkpoint /datadisk/checkpoints/openvla-7b+libero_spatial_no_noops+b16+lr-0.0005+lora-r32+dropout-0.0--image_aug \
--task_suite_name libero_spatial \
--center_crop False
最后日志显示成功率仅3/50,更低了,故排除这个问题。
- 另外的可能原因是没训练够足够多的轮次。
我们可以点开具体的仿真视频:
-
如果是“帕金森”式抖动:说明 Action Chunking 或者归一化参数不对。
-
如果是“甚至是没抓到”:说明训练步数不够,视觉感知还没对齐。
-
如果是“抓到了掉了”:说明夹爪的控制信号有问题。
而我的视频里机器人动作看起来很流畅,只是差一点点,那说明这个模型其实是可以用的,只是需要多训练一会儿。
- 还有一部分原因是日志中的成功率判定依据、判定条件极其严苛。
Libero/Robosuite 的成功判定是基于数学坐标的,不是基于图像的。以下原因都会导致将动作判定为Fail:
-
高度不够:比如任务是“拿起杯子”。系统设定必须拿起 0.05米 才算赢。如果你的机器人拿起了 0.049米,肉眼看着悬空了,但系统判定 Height condition failed -> Fail。
-
位置偏差:比如“把碗放在炉子上”。系统设定目标区域是一个半径 3cm 的圆。机器人放偏了 1mm,肉眼看在炉子上,系统判定 Target zone mismatch -> Fail。
同时它还有稳定性检测(手抖),这是 OpenVLA 这类模型最常见的问题。
-
现象:机器人确实抓住了东西,也举起来了。但是因为这是扩散模型生成的动作,机械臂末端可能有轻微的高频颤抖。
-
判定逻辑:模拟器为了防止物体是“被撞飞”误判为“被拿起”,通常会要求物体在空中保持稳定 X 帧。
-
结果:因为手抖,物体一直在轻微位移,系统认为状态不稳定,直到时间耗尽都没触发 Success 信号。
另外还有时间步限制,超时也会视作Fail,比如脚本默认设定了 max_steps(比如 600 步),有时候机器人动作慢悠悠的,在第 590 步刚刚抓好,正准备往目标点放,或者刚刚放到位,还没有等到“稳定检测”通过,第 600 步到了。虽然第 601 步它就成功了,但系统记录为 Fail。
- 还有一个原因,第一个任务的难度可能显著高于第二个,从我们实际的成功率也可以看出来。大家有时间的话可以继续运行下去进行对比验证。
不过,大家不要被那个日志中低的成功率打击到。在机器人领域,尤其是 OpenVLA 这种大模型研究中,人工检查的权重往往高于自动脚本的评分。我们的仿真视频已经证实了:
我们的模型是有效的,它真的学会了任务,动作是流畅有规律的,而不是在乱动。可能只是需要额外的训练轮次。
同时我们也证明了Center Crop 是对的, center_crop=True 确实让模型看清了物体。
接下来可以再尝试继续微调,或者换一个训练集,我暂时先操作到这里,后续如果重新微调了再继续更新。
五、结果更新
时隔许久我又继续训练了3000轮,共计8000轮。在libero-spatial上的成功率为38%,实际观测为58%,比之前好了一些。但是值得注意的是,成功的情况抓取都非常顺利,但失败的情况机械臂全是完全没有移动。
这实际上揭示了模型处于过拟合或者策略坍缩的边缘,在模仿学习中非常典型。下面是我根据AI回答整理的原因:
- 为什么会出现“不动”的现象?(死锁问题)
“不成功的都是机械臂没动的”,在学术界通常被称为 “Freezing” 或 “Action Collapse”。
- 原因 A:过拟合导致的不确定性抑制 (Overfitting to Specific States)
在 8000 步时,模型可能已经“背过”了训练集里的特定轨迹。而评估时,环境是随机生成的(初始位置会有微小变化)。如果当前的初始画面和训练集里的画面哪怕有一点点不一样,过拟合的模型就会变得极其保守。
OpenVLA 的输出本质上是概率分布。当它对当前状态感到困惑时,它可能输出了很多接近“零速度”的动作 token,导致机械臂“不敢动”。
- 原因 B:学到了“停止”的伪相关性
训练数据里包含了很多“静止”的片段(比如任务刚开始的前几帧,或者任务结束后的等待)。随着训练步数增加(8000步),模型可能错误地赋予了“静止”状态过高的权重。一旦开局没有立刻检测到极其强烈的“抓取信号”,它就陷入了“保持静止”的局部最优解。
- 为什么 5000 步和 8000 步表现截然不同?
这完美体现了模型训练的Bias-Variance Tradeoff(偏差-方差权衡):
- 5000 步(高方差,低偏差):
状态: 模型还在“探索”阶段,它知道要动,要伸手,但手眼协调还没练好。
表现: 敢于尝试,动作幅度大,但是精度不够(抓不准,或者抓起来掉了)。
你的观察: “失败几乎都是抓取不准确”。
- 8000 步(低方差,高偏差):
状态: 模型已经收敛,甚至开始过拟合。它对确定的事情非常有把握,对不确定的事情非常抗拒。
表现:
Case 1(遇到熟悉的场景): 完美执行,一气呵成(一动都成功)。
Case 2(遇到陌生的初始角度): 彻底由于,输出 0 动作(不动)。
你的观察: “不成功的都是没动的”。
- 为什么成功率统计有差异?(38% vs 58%)
- 原因:评估脚本的判定极其严格。
Libero 任务的成功判定通常依赖于模拟器底层的几何状态。
Example: 任务是“把碗放在盘子上”。
你的视角: 碗已经在盘子上了,算成功。
脚本视角: 碗必须在盘子中心 2cm 范围内,且倾斜角度小于 5 度,且保持静止 2 秒。
结论: 58% 是真实的“功能性成功率”,脚本的 38% 是“完美执行率”。不用太纠结这个差异,以脚本为准(因为它是一致的 benchmark),但你的观察证明模型其实比脚本认为的要强。
- 💡 核心建议:下一步怎么优化?
既然出现了“不动”的情况,说明 8000 步可能已经练过了(Over-trained),或者正则化不够。建议尝试以下 3 个操作,通常能把成功率拉升到 60%+:
- 方案一:使用“早停”权重 (Early Stopping)
你既然有 5000 和 8000 的权重,中间有没有保存 6000 或 7000 步的?
往往 6000-7000步 是最佳甜点,既修正了 5000 步的抓取不准,又没到 8000 步的“不敢动”。
Action: 尝试评估 checkpoint-6000 或 checkpoint-7000。
- 方案二:增加 Dropout (关键!)
我们之前的指令:dropout-0.0。而Dropout 为 0 极易导致过拟合,也就是你现在的“不动”现象。
Action: 如果你需要重新训练,请将 Dropout 设置为 0.1。这会强迫模型不依赖特定的像素特征,从而解决“初始画面稍微不一样就不敢动”的问题。
- 方案三:在评估时增加“噪声注入” (如果你不想重训)
这是一个 trick。既然模型因为画面微小差异而不敢动,我们可以强制给它的动作加一点点随机噪声,帮它“打破僵局”。
Action: 虽然 OpenVLA 默认脚本可能不支持直接调节,但你可以多跑几次(增加 --n_eval_episodes 到 20 或 50),看看是不是某些特定初始化导致的。
- 总结
现在的模型(8000步)其实是一个**“偏科生”:会的题全对,不会的题交白卷。相比之下,5000步的模型是一个“粗心的学生”**:每道题都做,但老是算错数。通常来说,回退到 6500-7000 步左右的权重,效果是最好的。
- 再更:6500steps确实效果更好,评估脚本显示成功率为52%,肉眼看有65%,此项目就到此结束!谢谢各位能看到最后的同学,我们一起加油!

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 35
35 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)