RL-100——基于真实世界RL的高性能灵巧操作:先基于人类演示做模仿学习预训练,再做迭代式离线RL,最后真机在线RL
前言
我司虽然于去年25年做了不少双足人形的项目,但双足在工厂落地的局限性,这一两年还是比较大
故今年上半年,会更多做『轮式和纯机械臂』智能化落地的项目,依然包括且不限于搬运 分拣 叠衣服 拧螺丝 插拔 装配
说到工厂,现实世界中工厂机器人操作需要具备接近或超越熟练人类操作员的可靠性、效率和鲁棒性,对此,有研究者提出了RL-100,这是一个基于扩散视觉运动策略的现实世界强化学习框架
- RL-100 在去噪过程内,通过施加一个统一的、类似PPO 的目标函数,将模仿学习和强化学习进行统一,从而在离线和在线阶段都实现保守且稳定的性能提升
- 且为满足部署时的时延要求,作者采用轻量级的一致性蒸馏,将多步扩散压缩为一步控制器,以实现高频控制
另,该框架与任务、本体和表示无关,并同时支持单步动作控制和动作分块控制
PS,本文会涉及很多RL的技术/概念,包括且不限于PPO,如果你此前对RL还不了解或熟悉,则可以参见此文《强化学习极简入门:通俗理解MDP、DP MC TD和Q学习、策略梯度、PPO》
第一部分 RL-100: Performant Robotic Manipulation with Real-WorldReinforcement Learning
1.1 引言与相关工作
1.1.1 引言
近年来,在
- 生成式扩散策略
Chi et al. 2023,即Diffusion policy
Ze et al.2024,即DP3 - 基于扩散的机器人基础模型
Black et al.2024a,即π0
Intelligence et al. 2025),即π0.5 - sim-to-real 强化学习(RL)
Yuan et al. 2025,即Hermes: Human-to-robot embodied learning from multi-source motion data for mobile dexterous manipulation,提出了一种利用多源运动数据实现移动灵巧操纵的人机具身学习框架
Lin et al.2025,即Sim-to-real reinforcement learning for vision-based dexterous manipulation on humanoids - 真实世界 RL
Luo et al. 2025, 2024,即HIL-SERL、Serl
等方向上的学习式方法取得了进展缩小了这一差距,并展示出类人水平的操作能力
- 尤其是,生成式策略与基础模型在不同规模的、高质量的、由人类采集的真实机器人数据集上进行训练或微调,由此注入了强有力的人类先验,使机器人能够习得熟练遥操作员所使用的高效策略
- 然而,高质量的真实机器人数据依然稀缺:遥操作受到感知与控制延迟的限制,往往导致动作缓慢且保守
Guo et al.2025,即Demospeedup: Accelerating visuomotor policies via entropy-guided demonstration acceleration,提出通过熵引导的演示加速技术来克服人类远程操作带来的速度慢和动作保守的问题
此外,大规模数据采集依赖熟练操作员,既耗费人力又成本高昂。其结果是,状态–动作空间的覆盖度有限,从而削弱了泛化能力与可靠性
————
因此,这一监督范式受到“模仿上限”的约束:在纯监督目标下,性能实际上被示范者的技能所界定,并会继承人类的低效性、偏差以及偶发错误
好在RL提供了一条互补路径,它不是优化对示范的模仿保真度,而是优化与环境交互所获得的回报,从而能够发现在人类示范中罕见甚至不存在的策略
与此同时,仿真到真实(sim-to-real)的强化学习必须应对仿真与现实之间在视觉和动力学上的差距,而在真实硬件上天真地训练一个基于学习的生成式策略既有风险又低效
- 这引出了一个核心问题:如何构建一种机器人学习系统,使其既能利用强有力的人类先验,又能通过自主探索不断自我完善?
- 一个有用的类比来自人类学习:婴儿在父母监督下学会走路,然后通过自主练习不断强化这项技能,直到熟练掌握,并最终能够在不同地形上迁移这一能力
类似地,一个具有良好泛化能力的机器人学习系统应当将熟练的人类先验与自我提升相结合,从而在可靠性、效率和鲁棒性方面达到——并在某些情况下超越——人类的能力
对此,来自1 Shanghai Qizhi Institute、2 Shanghai Jiao Tong University、3 The University of Hong Kong, HKSAR、4 IIIS, Tsinghua University、5 University of North Carolina at Chapel Hill, USA、6 Carnegie Mellon University, USA、7 Chinese Academy of Sciences的研究者出 RL-100

它在基于模仿的扩散策略之上引入了一个真实世界的RL后训练阶段,在保留其表达能力优势的同时,在温和的人类引导探索下,显式优化部署指标——成功率、完成时间以及鲁棒性
- 其paper地址为:RL-100: Performant Robotic Manipulation with Real-World Reinforcement Learning
其作者包括
Kun Lei1,2,*, Huanyu Li1,2,*, Dongjie Yu1,3,*, Zhenyu Wei5,*, Lingxiao Guo6 , Zhennan Jiang7 , Ziyu Wang4 , Shiyu Liang2 and Huazhe Xu1,4 - 其项目地址为:lei-kun.github.io/RL-100
其GitHub地址为:截止到26年2月中旬,暂未开源
简而言之,作者从人类先验出发,对齐以人为基础的目标,并超越人类水平的表现。其包含三个阶段,它们在角色和成本上各不相同
- 在遥操作示范数据上进行模仿学习(IL)预训练,提供一个能力强、方差低的基础,就像蛋糕的海绵层,为后续学习奠定根基
- 迭代式离线RL后训练(在策略回放的滚动缓冲区上进行离线更新)在成功率和效率方面带来了大部分的提升,这类似于添加奶油层
- 在线且 on-policy 的 RL 后训练提供了“最后一公里”的可靠性,专门针对迭代式离线学习后仍然残留的罕见失效模式,相当于点缀在顶上的樱桃
————
但它在真实硬件上非常耗费资源(参数调优、复位、审批等)
因此,作者将大部分学习预算分配给迭代式离线更新,只用少量且有针对性的在线预算,把性能从较高的成功率(如95%)进一步推升到接近完美(如 99%+)
此外,RL-100 与具体表征无关:它在基于视觉的场景中运行,并且支持三维点云以及 2D RGB 图像,只需替换观测编码器即可,而无需修改框架的其余部分
- 虽然作者的真实机器人实验使用 3D 点云作为主要表示,但仿真中的消融实验表明,在使用 2D 输入时也呈现出相同的性能趋势
- 具体而言,作者提出了一种为 RL 后训练量身定制的自监督视觉编码器,在整个策略探索和更新过程中提供稳定且与任务相关的特征
在策略展开过程中,人类操作员在需要时提供稀疏的成功信号,控制器则遵循保守的运行边界
- 作者在迭代的离线与在线两个阶段中使用统一的策略梯度目标,对扩散采样器的短时域去噪调度进行微调
Ho et al. 2020a,即DDPM
这种对齐带来了跨阶段的稳定更新,以及很高的微调样本效率 - 此外,作者交替加入一种轻量级的蒸馏损失,将 K 步扩散策略压缩为用于部署的一步一致性『Song et al. 2023,即Consistency models,其提出了一致性模型,能够通过单步前向传播直接生成样本,显著降低传统扩散模型的推理延迟』策略,在降低推理时延的同时,保持或提升效率和鲁棒性
1.1.2 相关工作
第一,对于基于生成扩散模型的强化学习
将生成式扩散模型与强化学习(RL)相结合,在策略表示与优化方面带来了范式转变
- 基于扩散模型的奠基性工作
Ho et al. 2020a,即DDPM
Song et al.2020,即Score-based generative modeling through stochastic differential equations,建立了扩散模型与随机微分方程(SDE)之间的联系,为生成模型提供了统一的数学框架
以及流匹配flow matching
Lipmanet al. 2023,即Flow matching for generative modeling,提出了一种基于概率路径向量场匹配的新型生成模型框架,避免了传统扩散模型的复杂公式
近期研究表明,这些生成式框架在刻画强化学习问题中固有的复杂、多模态动作分布方面具有强大能力
Diffusion Q-Learning,即DQL
Wang et al. 2023,即Diffusion policies as an expressive policy class for offline reinforcement learning,率先将条件扩散模型引入离线强化学习,取代传统的高斯策略以捕捉复杂的多模态动作分布
率先在离线强化学习中采用条件扩散模型替代传统的高斯策略,从而解决了参数化策略在建模多模态行为时的根本局限 - 这一方法沿多个方向得到了发展:加权回归方法
Kang et al. 2023,即Efficient diffusion policies for offline reinforcement learning,探索了通过重要性权重目标训练扩散策略,以最大化学习到的Q函数,提升离线RL效率
通过重要性加权目标来训练扩散策略,以最大化学习到的 Q 函数;
重参数化梯度方法
Psenka et al. 2024,即Learning a diffusion model policy from rewards via q-score matching,利用梯度下降优化方法和Q-score匹配技术,直接从奖励中学习扩散模型策略
He et al. 2023
Ding and Jin 2023
在存在时间反向传播挑战的情况下,仍然采用基于梯度的优化;
而基于采样的方法
Chen et al. 2024,Score regularized policy optimization through diffusion behavior
则提供了有效但计算代价高的解决方案
更近期地,基于一致性的扩展
Li etal. 2024,Generalizing consistency policy to visual rl with prioritized proximal experience regularization,将一致性策略推广到视觉强化学习领域,并引入了优先级的近端经验正则化技术
进一步将扩散策略和一致性策略推广到了视觉强化学习 - 近期的工作还探索了使用 RL 直接优化扩散模型,突破了传统的基于似然的训练范式
Black 等人2024b,Training diffusion models with reinforcement learning,展示了如何通过强化学习对扩散模型进行微调,以最大化任意定义的奖励函数
展示了如何用 RL 对扩散模型进行微调,以最大化任意奖励函数
而 Fan 等人2023,Reinforcement learning for fine-tuning text-to-image diffusion models,
则将类似技术专门应用于结合人类反馈的文本到图像生成,将强化学习技术应用于文生图扩散模型的微调,以更好地结合人类反馈
Ren 等人2024——即DPPO,Diffusion policy policy optimization,为基于扩散的策略量身定制了策略梯度方法(DPPO),实现了有效的在线优化
提出了针对基于扩散的策略而定制的策略梯度方法,在保持扩散模型表达能力优势的同时,实现了高效的在线优化 - 为了解决扩散模型固有的计算瓶颈,Park 等人2025,即Flow q-learning
提出了 Flow Q-Learning(FQL),该方法利用 flow-matching 策略来建模复杂的动作分布,同时避免在去噪过程中的递归反向传播
通过训练一个独立的单步策略去匹配流模型的输出,FQL 在不牺牲表达能力的前提下实现了计算效率的提升,并在离线强化学习基准上展现出最先进的性能,且在计算上具有显著优势,尤其是在离线到在线微调(offline-to-online fine-tuning)场景中表现突出
同样地,One-Step Flow Q-Learning(OFQL,即Revisiting diffusion q-learning: From iterative denoising to one-step action generation)在这一框架基础上扩展,使得单步动作生成更加高效
第二,对于机器人领域中的生成式扩散模型
扩散模型在机器人领域的应用,已经在视觉运动控制、轨迹规划以及真实世界部署方面带来了变革性进展
- Diffusion Policy通过将动作分布建模为条件扩散过程,在视觉运动控制中展现了突破性性能,依托视觉条件化与滚动时域控制,在处理多模态行为方面尤为出色
这一方法启发了包括
DiffClone,DiffClone: Enhanced behaviour cloning in robotics with diffusion-driven policy learning,通过扩散驱动的策略学习增强了传统的机器人行为克隆技术
和
Diffusion Model-Augmented BehavioralCloning
在内的一系列扩展工作,这些方法利用扩散模型的强大表达能力,进一步改进了传统的行为克隆 - 与此同时,将其与预训练视觉表征相结合,包括 R3M、VC-1以及MoCo,已被证明在跨视觉变化的泛化方面特别有效
最近关于 3D Diffusion Policy的工作将这些能力扩展到点云观测,而
FlowPolicy,即Flowpolicy: Enabling fast and robust 3d flow-based policy via consistency flow matching for robot manipulation,引入了一致性流匹配技术,为机器人操纵实现了快速且稳健的3D流策略
则引入了一致性流匹配,用于稳健的 3D 操作任务
且Lu 等(2025)提出了一种三重层次扩散策略,将复杂的机器人平台和任务,加速从实验室演示向实用机器人系统的转变
第三,对于离线到在线强化学习
从离线预训练过渡到在线微调,在实现持续改进的同时,在处理分布偏移和防止灾难性遗忘方面带来了独特的挑战
- Conservative Q-Learning,即CQL
通过悲观的价值估计为安全的离线强化学习建立了基础框架,从而避免了对分布外动作的价值高估
Advantage-Weighted Regression,即AWR提供了一个具有良好扩展性的框架,对后续大量工作产生了影响,不过其对高斯策略的限制削弱了对复杂行为模式的表达能力 - Calibrated Q-Learning (Cal-QL)通过确保保守的 Q 值经过适当缩放以支持有效的在线微调,从而解决了初始化难题,并为成功的离线到在线迁移提供了关键洞见
详见此文《Calibrated Q-learning(简称Cal-QL)——为高效在线微调而对“离线RL预训练”做校准:让学到的Q值有上界(保持CQL已做到的不盲目乐观),更有底线(不盲目悲观)》
Uni-O4,即Uni-o4: Unifying online and offline deep reinforcement learning with multi-step on-policy optimization,直接应用PPO目标函数来统一离线和在线学习,消除了额外的正则化需求
直接将 PPO的目标应用于统一离线与在线学习,因而无需额外正则化 - 最新研究聚焦于通过混合策略高效利用离线与在线数据
RLPD,详见此文《RLPD——利用离线数据实现高效的在线RL:不进行离线RL预训练,直接应用离策略方法SAC,在线学习时对称采样离线数据》
通过混合离线与在线经验,实现了高样本效率的在线学习,表明精心设计的数据混合策略可以显著加速学习
Nair et al.(2020)建立了结合离线预训练与在线微调的基本框架,表明与纯在线或纯离线方法相比,混合方法在样本效率上更具优势
由 Wagenmaker et al 2025,即Steering your diffusion policy with latent space reinforcement learning
提出的工作体现了离线到在线自适应的一种范式转变,该工作提出了 DSRL(Diffusion Steeringwith Reinforcement Learning),其在预训练扩散策略的潜在噪声空间中完全进行强化学习,而不是直接修改基础策略的权重
第四,对于真实世界强化学习
真实世界强化学习(Real-world RL)直接在真实机器人动力学上进行训练,优化部署指标(可靠性、速度、安全性),并在不存在仿真到真实(sim-to-real)鸿沟的前提下,实现能够持续适应扰动的鲁棒性能
其关键需求包括:高样本效率、高维感知条件下的稳定性、安全的连续运行,以及自动化的奖励与重置机制
- 早期工作已经展示了端到端视觉—运动控制学习
Levine etal. 2016,即End-to-end training of deep visuomotor policies,早期展示了通过深度学习进行端到端视觉运动策略训练的开创性工作
以及利用离策略方法实现的大规模抓取
Kalashnikov et al. 2018,即Scalable deep reinforcement learning for vision-based robotic manipulation,建立了利用离策略(off-policy)方法进行大规模机器人抓取任务的范式
随后的一系列进展奠定了关键的算法基础:
用于提升数据效率的离策略actor-critic方法
如
SAC,即Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor,提出了软行为者-评论者(SAC)算法,通过最大熵框架显著提升了数据的利用效率
TD3,即Addressing function approximation error in actor-critic methods,提出了 TD3 算法,解决了行为者-评论者方法中常见的函数近似误差问题
用于加速样本利用的基于模型的方法
Chua et al. 2018,即Deep reinforcement learning in a handful of trials using probabilistic dynamics models,其利用概率动力学模型的模型驱动(model-based)方法来加速样本获取
Janner et al. 2019,即When to trust your model: Model-based policy optimization,研究了在模型驱动策略优化中何时以及如何信任预测模型,以加速学习过程
面向自主运行的免重置学习(reset-free learning)
Eysenbach et al. 2018,Leave no trace: Learning to reset for safe and autonomous reinforcement learning,探索了无需人工干预的重置(reset-free)学习,以实现机器人的自主强化学习
Gupta et al. 2021,Reset-free reinforcement learning via multi-task learning: Learning dexterous manipulation behaviors without human intervention,通过多任务学习框架实现了无需人工干预的灵巧操纵行为学习
以及从视觉分类器或人类反馈中学习得到的奖励规范
Singhet al. 2019,即End-to-end robotic reinforcement learning without reward engineering,提出了一种无需手动设计奖励函数的端到端机器人强化学习方法,通过视觉分类器等手段指定目标
Christiano et al. 2017,即Deep reinforcement learning from human preferences,引入了从人类偏好反馈中学习奖励函数的技术,为复杂任务提供了目标规范,这便是ChatGPT中RLHF奠基论文,详见此文《ChatGPT技术原理解析:从RL之PPO算法、RLHF到GPT4、instructGPT》的1.5.2 RLHF:基于人类偏好的深度强化学习
尽管如此,大多数系统仍然需要大量工程化工作、针对具体任务的精细调参,或极长的训练时间,才能获得可靠的性能 - 这些分散的进展在 SERL中汇聚,该框架是一个综合性体系,集成了高更新与数据比率的离策略学习、自动复位以及视觉奖励指定,从而完成若干操作任务
然而,SERL 完全依赖于在需要高精度或从失败中恢复的任务上进行演示时往往表现吃力
HIL-SERL通过在训练过程中引入实时的人类纠正来弥补这些局限,使策略能够从错误中学习,并在包括双臂协同和动态操控在内的各类任务中实现完美的成功率
尽管SERL 和HIL-SERL 在界定良好的桌面技能上报告了令人印象深刻的机器人学习效率和可靠性,但其评估通常采用动作空间整形(例如,限制腕部旋转并鼓励近平面末端执行器运动),并聚焦于控制维度较低的短时域情形
此类约束在安全性和样本效率方面是务实的,但会削弱策略的表达能力,并可能限制在姿态敏感、接触丰富或组合结构复杂任务上的性能上限 - 在日常家庭和工厂场景中,许多技能本质上需要完整的SE(3) 控制和大幅度重定向,包括:带有扭转和再抓取的可变形体操作(例如叠毛巾)
在受限腔体中伴随大角度倾斜变化的插入/取出(例如榨橙汁)
依赖容器倾斜的流体和颗粒物控制(例如可控倒液)
涉及动态释放和轨迹塑形的操作(例如灵活保龄球投掷)
具有离面旋转的电缆布线或布料铺放
以及双臂重定向操作
相比之下,RL-100系统在没有硬性旋转约束的情况下保留完整的6 自由度控制,并通过以下方式针对这些尚未充分探索的情形:
- 使用扩散/一致性视觉-运动策略来捕捉多样的人类策略
- 通过带有OPE 门控的PPO 风格目标统一离线到在线的改进,以实现近似单调提升
- 通过一步一致性蒸馏实现高频控制,从而在双臂、可变形体和动态任务中获得更强的跨物体泛化能力
1.1.3(选读) 预备知识
第一,对于强化学习
作者将机器人操作问题表述为一个马尔可夫决策过程(MDP),其中
为状态空间,
为动作空间,
为转移动力学,
为奖励函数,
为折扣因子
- 机器人策略
在状态
选择动作
以最大化折扣累计回报
- 价值函数
被定义为衡量机器人从给定状态开始时的性能
- 而Q 函数
则从给定的开始
此外,RL-100的后训练遵循离线到在线(offline-to-online)的范式。遵循 LEI 等人2024-即Uni-O4,作者采用一种基于近端策略优化PPO风格的目标函数
- Schulman et al. 2017,即为PPO
- Zhuang et al. 2023,即为BPPO,Behavior proximal policy optimization,提出了一种名为行为近端策略优化(BPPO)的算法,旨在进一步优化 PPO 风格在不同数据分布下的表现
来统一这两个阶段
核心学习目标通过引入重要性采样来实现近端策略更新:
其中
是由策略π 诱导的平稳状态分布
为重要性比率
- 且
为优势函数
离线阶段与在线阶段的关键区别在于优势估计
- 离线:Implicit Q Learning (IQL) 风格(Kostrikov 等人2022)价值函数:
- 在线:广义优势估计(GAE) (Schulman 等2016):
以平衡方差和偏差
第二,对于扩散模型
在接下来的两个小节中,作者将下标 从在 MDP 中表示时间步,重载为在扩散过程中的步数索引
扩散模型学习逆转一个逐渐将干净数据污染为高斯噪声的过程,以重建原始干净数据的分布
- 给定一个日程
,其中
从干净分布中抽取的样本,其前向加噪过程遵循一个闭式形式——定义为公式2a、2b:
- 一个去噪器
通过以下方式被训练,用于识别带噪样本内部的噪声:
以还原出干净的样本
第三,对于具有随机形式的 DDIM 采样
去噪扩散隐式模型(Denoising Diffusion ImplicitModels, DDIM)提供了一族在确定性与随机生成之间插值的采样器
- 给定一个已学习的去噪器
的预测干净样本通常写作
其中
表示累积噪声调度 - 作者考虑用于采样的(可能)较粗的时间子序列
,其中
(例如,
且
)
为了用统一的记号同时涵盖单步() 和子采样(
) 两种情形,作者将从时刻
(其中
)的一个一般转移记为
然后,DDIM 将带有方差参数的随机更新定义为公式5a
该式子中的根式需要满足约束——定义为公式6
——————
以下则是公式5b
特别是,当时,可以恢复确定性的DDIM更新(此时分布退化为在
处的狄拉克分布)。相反,
的正值会向该转移中注入随机性
第四,对于策略视角和对数似然
当时,从
到
的转移可以被视为一个高斯子策略——分别定义7a、7b
其中C 是与参数θ 无关的常数。注意,(7b) 仅在时有效;当
此时密度变为奇异,且该转移最好被描述为确定性映射
,或者等价地说,是一个Dirac分布
完整的DDIM采样过程通过串联子策略,从
出发,恢复出一个干净样本
- 在实践中,可以将
- 如果之后将(7b) 中的对数似然用作目标或微调准则的一部分,在处理σt→m →0 极限时必须小心(例如,将基于似然的项限制在方差严格为正的步上)
在整篇论文中,作者将 MDP 的时间步与扩散(去噪)时间步区分开
- 环境时间步记作
并被写为上标(例如)
- 从时间
(对于子采样时间表,这通常写作
方差参数统一索引为(在不产生歧义时可简写为
)
作者始终强制满足约束
从而保证出现在DDIM 更新中的所有平方根都是实数。当时,相应的转移退化为一个确定性映射(Dirac),并且高斯对数密度未定义
因此,任何基于似然的目标函数(例如使用log π 的策略梯度)都必须只使用方差严格为正的步长
第五,对于一致性模型
一致性模型(Song 等,2023)学习从任意噪声水平的噪声输入到干净数据的单步映射。将一致性模型记为,其中上标表示扩散索引(与上文符号约定一致)
给定一个冻结的扩散教师——例如一个遵循相同子采样时间表
) 的
步DDIM 教师,一致性蒸馏最小化平方回归目标——定义为公式9
其中sg [·] 表示停止梯度,是教师在将教师的去噪链从
运行到(近似)
后得到的输出。教师必须使用与学生将要模拟或蒸馏的相同的子采样时间表
来运行
在推理阶段,一致性模型只需要进行一次评估:
第六,扩散策略与强化学习微调
扩散策略(diffusion policy)在以观测为条件的情况下,对机器人动作执行扩散。给定一观测o,沿着K 步子采样的时间表展开:
其中 遵循以
为条件的DDIM 调度(公式5)
然后可以从所谓的扩散策略中恢复一个无噪声动作
RL 形式化
- 现在再将 K 步扩散过程作为一个子 MDP嵌入到机器人操作 MDP(Ren et al. 2024)中的单一步骤中
- 每一步去噪都可以视为从式 (7a)
中的高斯子策略中采样出一个更“干净”的噪声动作 aτk−1
因而,作者将该过程建模为一个具有 K 步的子 MDP,如下:
- Initial state:
with
- State:

- Action:
从去噪子策略
中采样
- Transition:

- Reward: 该子MDP 仅从上层环境MDP 接收终端奖励
随后,由(7b)中定义的对数似然来计算子策略的密度,从而能够相对于去噪子策略,通过策略梯度更新(例如PPO(Schulman et al. 2017))对任务回报进行端到端优化
1.2 RL-100的完整方法论:先模仿学习、再离线RL和在线RL
总之,RL-100 是一个将 IL 与 RL 相结合的统一机器人学习框架,如图 2 所示,其具体包含三个阶段『首先通过基于扩散策略的模仿学习从人类示范中学习,然后在数据扩展的基础上执行迭代式离线强化学习,最后通过在线微调进行最终性能优化』:
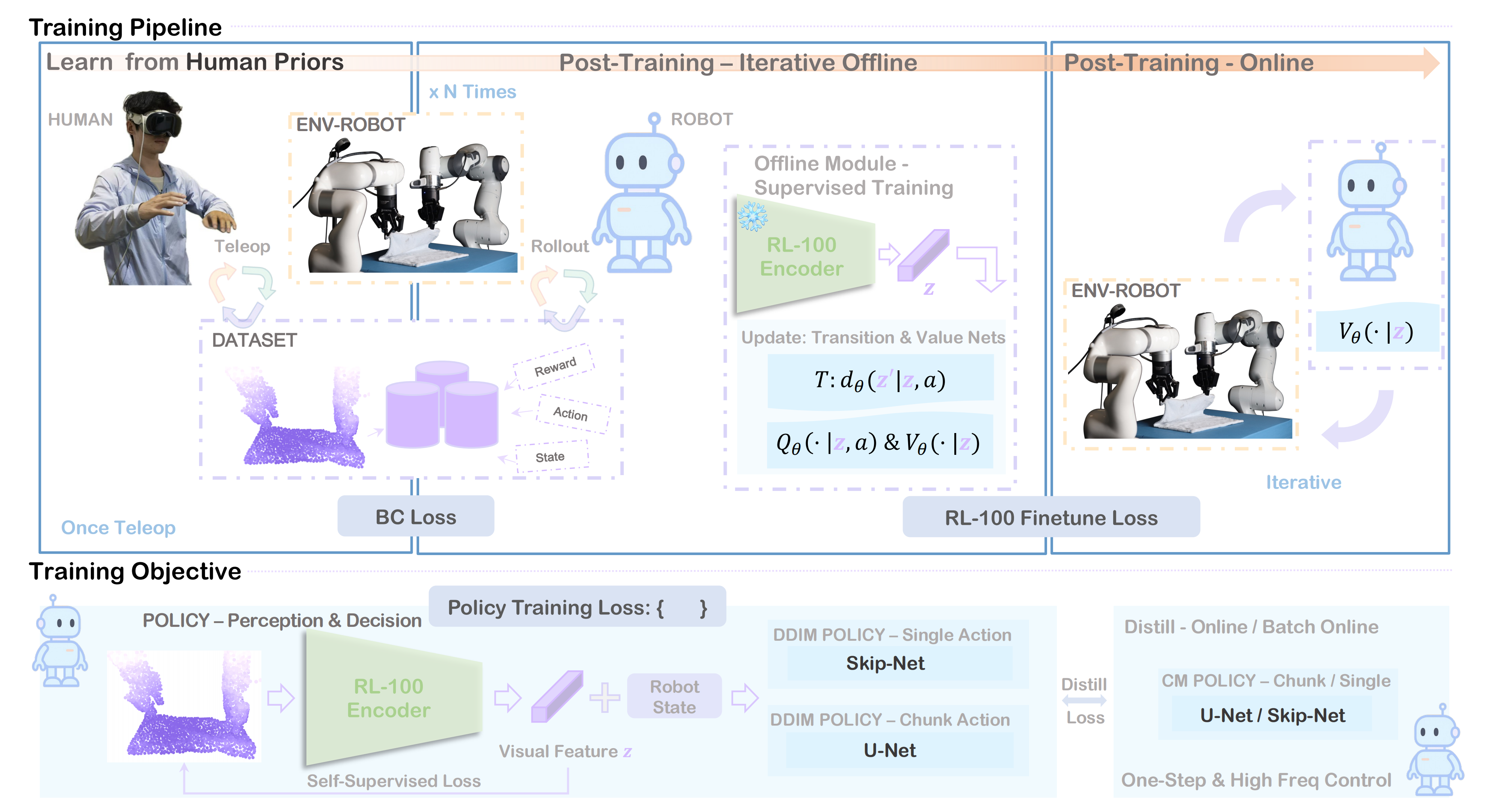
- 基于人类示范的模仿学习
- 通过逐步扩充数据的迭代式离线强化学习
- 在线微调
其关键创新点在于:通过在扩散去噪步骤上施加共享的、类似 PPO 的目标函数,将离线与在线强化学习统一起来
1.2.1 针对扩散策略的模仿学习预训练
第一,作者通过对人类遥操作产生的轨迹进行行为克隆来初始化策略
作者的方法采用条件扩散,从示范数据中学习鲁棒的视觉运动策略
每个episode都提供同步元组
其中
为视觉观测(RGB 图像或 3D 点云)
表示机器人的本体感知(关节位置/速度、夹爪状态)
- 并且动作要么是单步动作,要么是一个动作片段
第二,对于条件与预测时间范围
- 作者将最近的观测融合为一个条件向量
其中感知编码器处理最近的
帧(通常
),并且[·] 是连接多个向量的算子
- 干净的扩散目标
在时间步t 被设为
单个动作
或一个动作块
其中是块大小(通常为8-16)
动作在每个维度上进行归一化;在适用的情况下,作者预测末端执行器位姿的增量
第三,扩散参数化
- 沿着动作上的条件扩散,作者通过前向过程(Eq. (2))
,以将
- 去噪器
通过噪声预测目标进行训练——定义为公式14:
其中D 是示例数据集索引一个K 步的调度方案,并且
策略骨干在各控制模式之间共享;只有输出头不同:(单步)或
(分块)
第四,对于视觉和本体感受编码器
- 对于RGB 输入,作者使用预训练的ResNet/ViT 骨干网络;
- 对于点云输入,作者采用3D 编码器DP3,并加入重建正则化以在RL 微调过程中保持稳定性
视觉嵌入被投影并与本体感受特征拼接以形成。所有编码器都使用公式(14) 进行端到端训练
不过,在适用的情况下,作者加入重构(Recon)和变分信息瓶颈(VIB)正则化
其中
- o 和q 表示观测到的点云和本体感受向量
和
是在给定编码嵌入
时重建的观测
是两组点云之间的Chamfer 距离
如此,综上,完整的模仿学习目标变为
在RL 微调期间,作者将 和
减少10 倍,以在保持表征稳定性的同时允许策略改进
第五,对于推理与控制
在部署阶段,K 步 DDIM 采样——基于上面的公式 5
用于生成动作:
- 单步控制会立即执行
- 分块控制则在随后的
单步控制在反应性任务中表现出色(例如动态保龄球),而动作分块在精度任务中可以减少抖动(例如装配)
这两种模式共享相同的架构,从而实现任务自适应部署
1.2.2 统一的离线与在线强化学习微调
第一,处理单个动作与动作块
作者的框架同时支持单步与分块的动作执行方式,这会影响价值计算和信用分配:
- 单步动作:具有每步奖励
和折扣因子
的标准MDP 形式
- 动作分块:每个包含
该分块获得累积奖励,且分块之间的等效折扣因子为
为了便于说明,作者在下文先给出单动作情形;分块情形的处理方式类似,只需将每一步的量替换为其对应的分块量即可
第二,两层级 MDP 结构
本方法在两个时间尺度上运行
- 环境 MDP:具有状态
- 去噪 MDP:生成每个
去噪 MDP 被嵌入到每一个环境时间步之中,从而形成一种层次化结构,在该结构中,K 个去噪步骤产生一个环境动作
第三,跨去噪步骤统一的 PPO 目标
给定这种两层 MDP 结构,作者在每次迭代 的每个时间步
上,针对 K 步扩散过程,通过对所有去噪步骤 k 求和来优化 PPO 目标——定义为公式18
且损失函数为——定义为公式19
其中
是每个去噪步的重要性比率
是与环境时间步
- 这里,
表示在第
次PPO 迭代时的行为策略
其关键见解是在所有K 个去噪步骤之间共享相同的环境级优势,在保持与环境奖励结构一致的同时,为整个去噪过程提供密集的学习信号
有了上述3个层面,接下来咱们便可以看下离线强化学习(OfflineRL)了
1.2.2.1 离线强化学习(OfflineRL)
- 首先是设定
给定一个离线数据集D,使用从IL 获得的扩散策略来初始化行为策略:
在这一纯离线阶段不收集任何新数据 - 在D 上的策略改进
在离线迭代第
使用离线策略比率
并采用标准裁剪
离线优势的计算方式为
其中评估器在
上按照IQL(Kostrikov 等人,2022)进行预训练
这通过在 - OPE 门控和迭代推进
作者使用 AM-Q(LEI 等,2024)进行离线策略评估(OPE),在无需与环境进一步交互的情况下,将候选策略与当前行为策略进行比较:
其中是一个学习得到的转移模型
仅当满足以下条件时,才接受该候选并推进行为策略迭代
通过将更新后的策略设为行为策略:
否则,拒绝并保持行为策略不变()
在实践中,作者设置作为自适应阈值
这个基于OPE 的门控规则在D 上产生保守的、单调的行为策略改进
给定估计到的优势,离线RL 的损失函数等于式(19):
- 共享并冻结的编码器
为确保表示学习稳定且计算高效,作者的离线 RL 流水线中的所有组件共享同一个在模仿学习阶段预训练好的、固定的视觉编码器
在离线 RL 过程中,作者保持不变,仅更新各个模块的任务特定头
1.2.2.2 在线强化学习
在线阶段使用基于当前策略(on-policy)的组件
作者在每一个扩散步中使用一个 on-policy 比率
并使用 GAE 来计算优势:
在所有产生时间t 环境动作的K 个去噪步骤中共享相同的,最小化总损失——定义为公式21:
其中是折扣回报,
为价值函数损失的权重
1.2.3 蒸馏到单步一致性策略
高频控制对于机器人应用至关重要。尽管扩散策略表现出色,但K 步去噪过程会引入延迟,从而限制其实时部署
为了解决这一问题,作者联合训练了一种一致性模型,使其学习在单步中直接将噪声映射为动作,从多步扩散教师πθ 中蒸馏知识
在离线和在线强化学习训练过程中,作者都会在策略优化目标中加入来自式 (9)
的一致性蒸馏损失
其中
- 要么是离线目标使用基于IQL 优势的公式(19)
- 要么是在线目标(使用GAE 的公式(21)
一致性损失LCD 遵循公式(9),其中教师是扩散策略πθ,在给定观测的条件下执行K 步去噪。停止梯度算子确保教师策略在通过RL 目标持续改进的同时,也可以作为蒸馏的目标
在工业环境中实现机器人的实际部署,高频控制至关重要
- 首先,更快的控制回路可以直接转化为更高的任务完成效率,比如以 20 Hz 运行的机器人,相比 10 Hz运行,可以用一半的时间执行相同轨迹,从而显著提高工厂自动化中的吞吐量,因为节拍时间直接影响生产率
- 其次,许多操作任务从本质上就需要高频反馈才能可靠地执行
诸如抓取运动物体、在滑动运动过程中保持接触、或从意外扰动中恢复等动态任务,都要求小于50 ms 的响应时间,而多步扩散无法提供这种能力
此外,涉及顺应控制、力反馈或人机协作的任务,当控制频率下降到低于关键阈值,因为系统无法足够快速地作出响应来防止过大的力,或维持稳定接触
在推理过程中,一致性模型在一次前向传播中生成动作:,实现了
的加速(例如,将延迟从100ms 降低到10 ms),同时保持扩散策略的性能
这个数量级的改进使其能够部署在真实的制造场景中,在这些场景中,机器人必须保持一致的循环时间、响应传送带速度,并在与人类工人并行作业时安全运行——而这些要求使用标准的多步扩散策略是难以实现的
1.2.4 整体训练框架
尽管上述各个组件可以独立使用,作者提出了一种将它们组合起来以实现逐步改进的迭代过程。确并非在一组固定示例上仅运行一次离线RL,而是在以下步骤之间交替:
- 在当前数据集上训练IL策略
- 利用带有保守更新的离线RL对其进行改进,再使用改进后的策略收集新数据,并在扩展后的数据集上重新训练IL
- 最后,在线RL
该过程在算法1(Algo.1)中进行了总结

这样就形成了一个良性循环:更好的策略会生成更好的数据,而更好的数据又进一步促使学得更优的策略
为什么 IL 重新训练很重要。使用 IL 在扩展后的数据集上进行重新训练(算法1第13行)之所以至关重要,原因有以下几点:
- 分布移位:随着更高质量的轨迹被加入,IL 能够自然而然地适应不断演化的数据分布
- 稳定性:在混合质量的数据上,监督学习比 RL 更加稳定
- 多模态性:IL 保留了扩散策略对多种解模式进行建模的能力
- 蒸馏:IL 能够将人类演示和 RL 的改进有效蒸馏到一个统一的策略中
最终的在线微调,在迭代式离线过程收敛之后,作者应用在线 RL 进行最终的性能优化。该阶段受益于:
- 通过迭代式离线训练获得的强初始化
- 能够加速学习的预训练价值函数
- 用于回放和正则化的多样化数据集
此外,为了在 RL 微调期间确保学习过程稳定,作者引入在随机 DDIM 采样过程中进行方差裁剪。具体来说,作者在每一个去噪步骤中约束标准差:
其中 是来自式(5b)
的原始DDIM 方差参数,并且定义了允许的范围
这个修改有效地约束了behavior policy的随机性,从而避免了以下两种情况的发生:
- 当
过大时会导致过度探索,这可能会产生分布外动作,从而破坏训练的稳定性或在物理系统中引发安全违规
- 当
在实践中,作者设置,以在后期去噪步骤中仍然保持最小程度的探索,并将
,以防止在早期步骤中出现具有破坏性的探索
这样的有界方差确保重要性比率
在PPO 更新过程中保持良好性质,因为避免了当前策略与行为策略之间极端的方差差异
且作者将通过实证表明,这一简单的改动对于获得稳定的微调性能至关重要
// 待更

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 21
21 0
0- 0



 已为社区贡献77条内容
已为社区贡献77条内容

所有评论(0)