将视觉-语言-动作模型引导为反探索:一种测试-时规模化方法
25年12月来自中国电信、中科大、清华和港科大的论文“Steering Vision-Language-Action Models as Anti-Exploration: A Test-Time Scaling Approach”。视觉-语言-动作(VLA)模型通过流匹配或扩散目标进行训练,擅长从大规模多模态数据集(例如,人类远程操作、脚本策略)中学习复杂行为。然而,由于VLA在预训练阶段整合多
25年12月来自中国电信、中科大、清华和港科大的论文“Steering Vision-Language-Action Models as Anti-Exploration: A Test-Time Scaling Approach”。
视觉-语言-动作(VLA)模型通过流匹配或扩散目标进行训练,擅长从大规模多模态数据集(例如,人类远程操作、脚本策略)中学习复杂行为。然而,由于VLA在预训练阶段整合多种数据模态,且微调数据集通常包含以运动学次优或不理想方式收集的演示数据,因此存在与下游任务成功动作模式无关的冗余动作模式。具体而言,在对预训练的VLA进行监督微调后,各种采样噪声之间存在严重的推理-时脆弱性。本文将这种不稳定性归因于VLA策略与下游任务数据集中稳定成功模式所诱导的策略之间分布偏移。因此,提出TACO,一个测试-时规模化(TTS)框架,该框架应用轻量级伪-计数估计器作为动作片段的高保真验证器。集成TACO的VLA模型可以从所有采样的动作片段中执行具有最大伪-计数的动作,从而防止分布偏移,同时由于约束仅在推理阶段应用,因此保留VLA的泛化能力。本文方法类似于离线强化学习(RL)中的经典反探索原则,并且由于无需梯度计算,与RL更新相比,它具有显著的计算优势,特别是对于由于去噪过程而难以执行RL更新的基于流或扩散的VLA。
反探索与离线强化学习。在在线强化学习中(Sutton,1999),智体主动与环境交互以探索状态-动作空间(Yang ,2021)。相比之下,离线强化学习仅从固定的、预收集的数据集中学习策略,而无需进一步的环境交互(Levine ,2020a;Rashidinejad ,2021)。由于生成数据的行为策略与正在学习的目标策略之间存在分布偏移,这种设置带来了巨大的挑战——即使对于离线策略方法也是如此(Wu ,2019)。具体而言,离线数据集反映行为策略的访问分布,这可能与学习策略的访问分布存在显著差异(Agarwal,2019)。这种差异会导致在估计分布外(OOD)状态-动作对的值时出现严重的泛化误差(Kumar ,2020;Bai ,2022)。在 VLA 的 SFT 阶段也会出现类似的分布偏移,其中 VLA 模型编码广泛且冗余的动作模式,而下游任务中的成功行为通常占据更窄的区域。因此,在基于流或扩散的过程中采样动作时,策略可能会生成次优行为(Lipman ,2023;Ho ,2020)。
VLA 中的测试-时间规模化。通过规模化推理来提高测试-时间性能的方法已在大语言模型(LLM)中得到广泛验证(Ehrlich ,2025;Chen ,2024;Brown ,2024)。在 VLA 研究中,许多工作通过内部“思考”机制实现性能提升,但大多数方法需要带有标注推理轨迹的数据集(Zhao ,2025)。相比之下,测试-时间规模化引入一个额外的评分模块来选择更好的候选方案,从而实现生成-验证机制,在不修改网络权重的情况下进一步提升策略性能,例如利用优势函数(Zhang ,2025d)和状态-动作值函数(Nakamoto ,2024)的方法,以及其他变型,例如考虑似然的无验证器方法(Jang ,2025)。最近的工作(Du & Song,2025)还探索利用学习的世界模型(Hafner ,2019,2020;Zhang ,2025a,b)表示中的目标距离作为指标来引导基础策略。重复采样与验证器相结合的方法在一些工作中也被证明是有效的(Song ,2021;Kwok ,2025);然而,这些方法通常涉及复杂的强化学习训练或依赖于具有大量参数的验证器。目前还没有任何工作利用 VLA 的内部特征来构建轻量级高效的验证器,该验证器可以充分利用模型的理解能力,而无需修改骨干网络。
本文从反探索的角度探讨分布偏移问题,并提出基于伪计数的测试-时反探索方法(TACO)。反探索原理(Rezaeifar,2022)源于离线强化学习(RL)(Levine,2020b),其目标是防止策略访问数据集支持范围之外的状态或动作。类似地,在视觉-语言-动作(VLA)模型的推理过程中,目标是将生成的动作限制在SFT数据集中存在的成功模式的支持范围内,从而避免探索预训练或不完善的微调数据中保留的冗余或不相关的动作模式。在TACO中,通过测试-时规模化(TTS)而不是策略优化来实现反探索,因为基于流匹配或扩散的VLA模型涉及复杂的采样动力学,这些动力学不易于使用标准的RL方式更新方法进行优化。相反,TTS在不修改VLA参数的情况下调整动作采样过程,因此无需计算梯度。用一个经典的硬币-翻转网络(CFN)(Lobel,2023),并增强其内部表示机制,以估计SFT数据集中每个观察-指令-动作块对的伪计数。直观地说,伪计数较高的动作块与SFT数据中频繁观察的(即成功的)行为更加一致,因此更受青睐。在推理过程中,TACO使用CFN生成的伪计数作为验证器,从多个候选动作块中选择最可靠的动作块,最终执行伪计数最高的动作块。为了减轻测试-时重复前向传播带来的计算开销,进一步引入一个共享的观察KV缓存,通过跨样本重用视觉-语言表示,显著降低了延迟。
注:硬币-翻转网络(Coin Flipping Network,CFN)(Lobel,2023)是一种神经网络估计器,它利用每次遇到某个状态时进行的 Rademacher 试验(或抛硬币)的采样分布来计算状态访问次数。给定一个状态 s,每次出现状态 s 时,都会将其与一个随机二元向量 c_i ∼ {−1, 1} 配对,从而形成数据集 D_cfn = {(s_i , c_i )}。参数为 φ 的 CFN f_φ 通过求解一个简单的回归问题进行学习。
TACO,是一个将伪计数估计器视为现成验证器的框架,用于扩展 VLA 的测试-时间计算,从而实现反探索原则。值得注意的是,TACO 可以直接集成到使用离散token自回归(例如 OpenVLA (Kim et al., 2024))或基于分数的生成公式(例如 RDT (Liu et al., 2025)、π0 (Black et al., 2024)、π0.5 (Black et al., 2025))来建模动作分布的 VLA 中。TACO 的概述如图所示: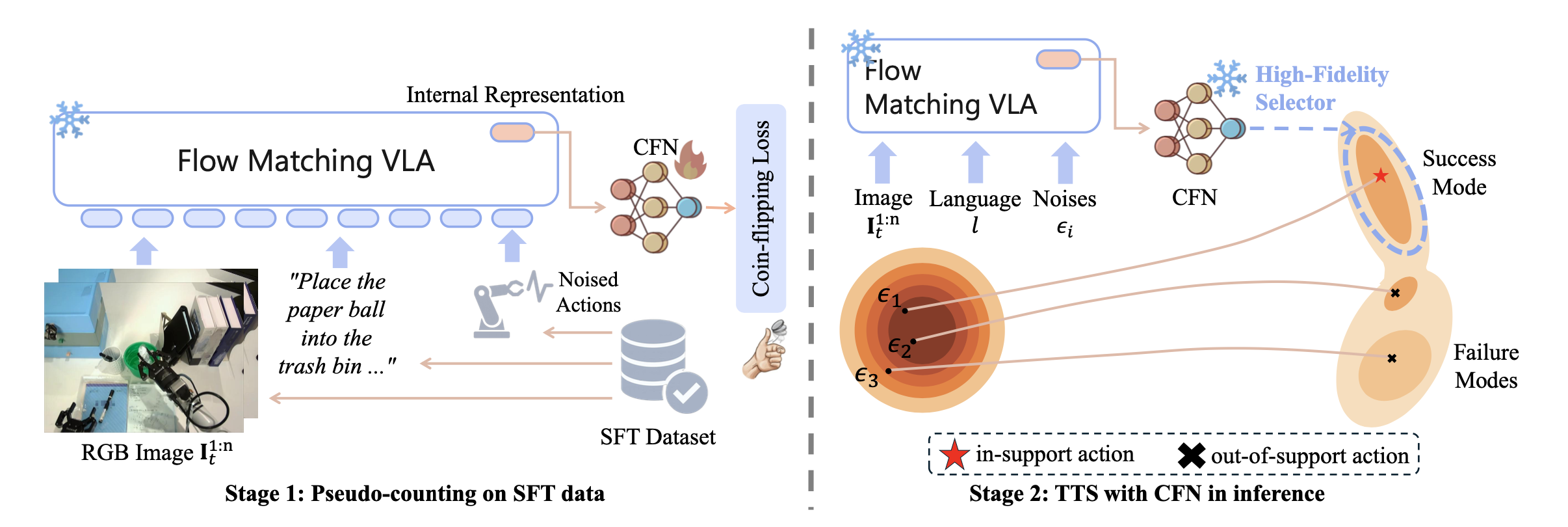
推理不稳定性作为 OOD 问题
首先正式确定推理-时不稳定性的来源。通过 SFT(Black et al., 2024; Liu et al., 2025)训练的 VLA 被迫近似整个数据集分布 p_D(a | s)。该数据集通常是不完美的混合分布 p_D = w_1 π∗ +sum(w_k p_k)_k>1,其中 π∗ 是所需的成功模式,p_k>1 表示次优或意外模式。因此,得到的策略 π_θ ≈ p_D 本质上是多模态的。当 π_θ 从不需要的模式生成动作 a_j ∼ p_j>1(a | o, l) 时,就会出现不稳定性。然而,通过离线模仿学习 (IL) 训练的 π_θ 是模式无关的,无法区分成功模式和不成功模式。
这种范式反映离线强化学习 (Levine et al., 2020b) 中的核心挑战:减轻外推误差 (Fujimoto et al., 2019; Kumar et al., 2019, 2020; Kostrikov et al., 2022)。从非期望模式 p_j>1 生成一个动作,类似于离线强化学习智体采样一个相对于目标成功模式 π∗ 超出支持范围的动作。离线强化学习中的一种原则性解决方案,是反探索 (Rezaeifar et al., 2022),它优化一个惩罚值函数,以限制策略保持在数据集的支持范围内。
为了将此目标与测试-时推理框架联系起来,首先引入一个理想化的简化设置:将任务建模为上下文多臂老虎机(bandit),其中给定 (o, l) 执行动作序列 a_1:H 会产生二元或成功 (r = 1) 或失败 (r = 0) 的奖励。在这种情况下,Q 函数等价于成功概率:Q(o, l, a_1:H ) = P (r = 1 | o, l, a_1:H )。因此,反探索目标转化为 a∗_1:H。为了解决这个问题,引入核心假设:用于 VLA 微调的下游数据集 D_sft 具有示范性。也就是说,假设示范的密度与任务成功率相关;高密度模式对应于理想策略 π∗,低密度模式对应于 p_k。
令反探索惩罚为基于计数的奖励 b(o, l, a_1:H ) = 1/N_D_sft (o, l, a_1:H),其中 N_D_sft (o, l, a_1:H) 是数据集 D_sft 中相应的访问计数。
这种实例化正式地将原则性的离线强化学习目标简化为等效目标:找到访问计数(即密度)最大的动作序列。这一结果为方法提供强有力的理论依据。测试-时规模化框架旨在寻找最高密度(即在支持范围内)的动作,而不仅仅是一种启发式方法。这构成离线强化学习中反探索目标标准的原则性且理论上等效的实现。
用于 VLA 的耦合伪计数估计
为了实现反探索原则,必须估计访问计数 N_D_sft (o_t, l, a)。通过在 D_sft 上训练一个伪计数的估计器 f_φ,可以用伪计数 Nˆ_D_sft做替换。受最近伪计数应用于大语言模型偏好优化方面取得的成功(Lobel,2023;Bai,2025)的启发,将此估计器实例化为一个硬币-翻转网络 (CFN)。
耦合估计器。一个关键的设计选择是输入表示 z = Enc(o, l, a)。没有训练单独的编码器,而是假设 VLA π_θ 本身提供最丰富的表示。将 CFN f_φ 实例化为一个简单轻量级的 MLP 头,它以 VLA 的内部表示 h_θ 作为输入。这种耦合估计器设计效率极高,利用 VLA 的计算,并受益于其广泛的预训练。
基于去噪 VLA 的高保真特征搜索。这种耦合设计对基于扩散或基于流VLA(Black,2024;Liu,2025;Black,2025)提出了一个关键挑战。这些模型仅在加噪动作 {a_σ} 上进行训练,因此在训练期间从未见过干净的数据动作 {a}。直接通过输入 a ∈ D_sft 提取 h_θ 可能不会落在 VLA 的特征空间上,从而产生无信息的表示。
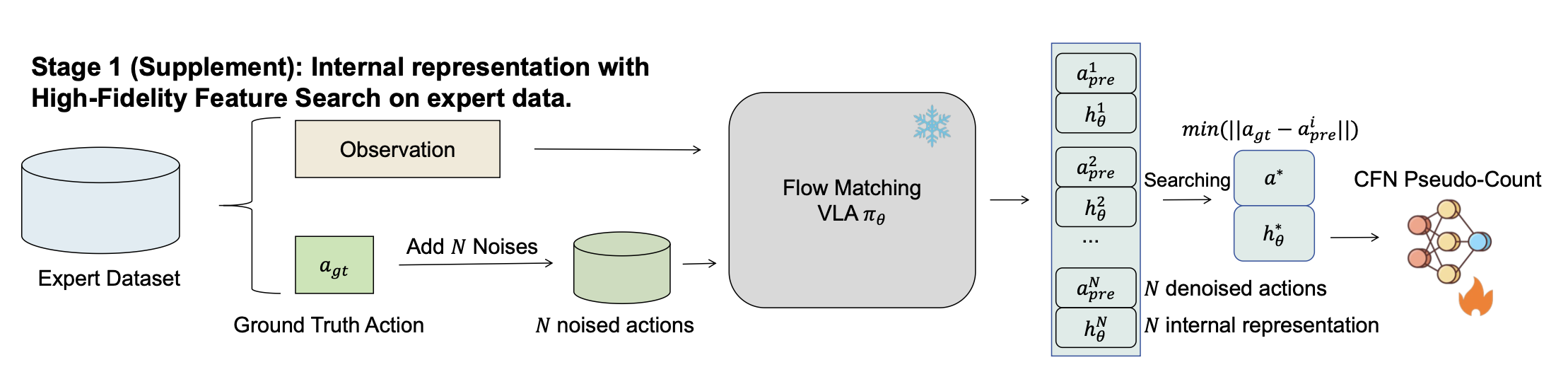
目标是找到一个分布内特征 h_θ,使其能够最佳地代表干净动作 a。提出一种高保真特征搜索程序。对于每个数据点 (o, l, a) ∈ D_sft,用不同的噪声水平 {σ_i} 对 VLA 进行 N 次查询。然后,选择其对应动作预测 a(i⋆)_pre 最接近真实值 a 的特征 h(i⋆)_θ。
由此得到的特征 h(i⋆)_θ 既属于 VLA 的分布内(因为它是由加噪输入 a_σ_i⋆ 生成的),又具有高保真度(因为它被证实能够代表 a)。
估计器训练。此搜索程序生成一个高保真特征集 D_h = {h(i⋆)_θ},代表了原始数据集 D_sft。现在,可以在任何 VLA 的最后一个隐状态之上训练 CFN 头部 f_φ。根据 (Lobel et al., 2023) 的方法,CFN f_φ 通过优化回归来学习。训练 CFN 后,特征 h_θ 的伪计数自然而然地得到。
耦合估计器得到的伪计数与真实动作之间的 L2 距离呈现出很强的相关性。这意味着,耦合 CFN 可以有效地充当验证器,用于惩罚超出支持范围的动作。
测试-时规模化作为反探索机制
通过推理过程中的两阶段生成-验证程序来实现反探索框架。首先,在生成阶段,给定观察结果 o_t 和语言指令 l,利用已在下游数据集 D_sft 上微调过的 VLA π_θ 作为候选生成器。对于扩散模型或基于流的模型,这可以通过采样 M 个不同的初始噪声向量 {ε_i} 并以批处理并行的方式执行完整的去噪过程来实现,从而生成一批 M 个候选动作块 {aˆ_t:t+H(i)}。至关重要的是,在生成过程中同时提取它们对应的内部表示 {h(i)_θ}。
其次,在验证阶段,部署训练的 CFN f_φ 作为验证器。CFN 根据其特征 h(i)_θ 对每个候选动作 aˆ_t:t+H(i) 进行评分,有效地估计其伪计数 Nˆ_D_sft (o_t, l, aˆ_t:t+H(i)) = 1/||f_φ(h(i)_θ)||2。最后,选择使该伪计数最大化的单个动作 aˆ∗_t:t+H。
此过程是前面原则性目标的直接实现。没有从 VLA 潜在的不稳定多模态分布中随机采样,而是确定性地选择与 D_sft 的成功模式最相关的动作(即计数最高的动作)。
通过 KV 缓存优化实现高效推理。简单地采样 M 个候选动作会引入令人望而却步的 O(M) 开销,使方法不切实际。通过昂贵的 VLA 计算(例如,Transformer 主干网络)仅依赖于共享上下文token (o, l) 来解决这个问题。因此,只需计算一次此共享上下文的 Key (K) 和 Value (V) 缓存,并在所有 M 个并行动作生成(例如,去噪)过程中重复使用它们。这种优化是方法的关键,使额外候选动作的边际成本最小化。当采样次数M=32时,方法与朴素的多批次并行推理方法相比,推理时间缩短73.2%,从而使高性能反探索采样方法具有实用性。
如算法 1 所示,提供推理阶段动作过滤过程的算法描述,阐述 CFN 验证器如何利用内部表示来获取伪计数,以及 KV 缓存优化的工作流程。在此,以基于流的 VLA 为例进行说明。
算法 2 概述如何在VLA之上训练耦合伪-计数估计器。目标是在不同噪声条件下反复查询VLA,从而高效地获得分布内的高保真特征,然后选择与干净动作最匹配的表示。在这些耦合特征之上训练一个轻量级CFN,可以得到一个伪计数估计器,该估计器能够可靠地反映候选动作与数据集D_sft支持集之间的接近程度,从而在推理过程中实现有效的反探索。这里,也以基于流VLA为例进行说明。
训练实现
内部表示细节。对于策略 π0 和 π0.5,基于 Lerobot 框架(Cadene,2024)构建训练和部署流程。首先修改模型的动作输出函数,使其同时返回动作和内部表示。具体来说,从最终隐层提取第一个动作 token。由于最终隐层编码整个输入序列的抽象表示——并且通过自注意机制,最后一个 token 的向量包含整个序列的上下文信息——将此向量视为输入的紧凑表示。由于 π0 和 π0.5 中使用的动作专家都采用双向注意 Transformer 架构,因此在实践中,将动作专家内部最终隐层的第一个 token 作为内部表示。其维度为 1024。对于 OpenVLA,则将其最终隐层的最后一个 token 作为内部表示,其维度为 4096。将温度设置为 1,并利用解码中的固有随机性来采样不同的动作和特征。
基础策略和表示数据集。以 Robotwin1.0(Mu,2025)为例,首先使用提供的脚本策略为每个任务收集 50 条轨迹来构建数据集。通过脚本策略收集的专家数据通常可以避免大量人为噪声,从而以低成本构建高质量数据集(Jing,2025)。然后,采用 LeRobot 在 Hugging Face 上发布的基础模型 π0,并使用 NVIDIA H100 对所有任务数据进行全参数微调,批量大小为 48,训练 3 万步,得到基础策略。将 10% 的噪声注入到真实动作中,并使用 π0 动作专家执行单步去噪,以获得内部表示。
如图所示,对于每个三元组 (o, l, a),额外采样 N = 50 个噪声实例来生成 N 个 {(a(i)_pre, h(i)_θ )},并选择与真实动作最接近的样本 a(*)_pre,然后将其存储作为后续训练的输入。
对于 Robotwin2.0 (Chen et al., 2025),同样使用 Hugging Face 上的 LeRobot π0 基础模型,并在 NVIDIA H100 上以 32 的批量大小对所有任务进行 10k 步的微调。在获取内部表示时,凭经验将噪声水平设置为相对于真实动作的 100%。所有其他设置保持不变。
对于 Libero (Liu et al., 2023a),直接使用官方的 LeRobot 模型 pi0_libero_finetuned 以及 Hugging Face 上提供的开源模型 openvla-7b-finetuned-libero-10 作为基础策略。
对于 Simpler (Li et al., 2024b),用 Bridge V2 数据集,并在 8 个 NVIDIA H100 GPU 上以 256 的批量大小对 π0 进行全参数微调,并将其作为基础策略。
训练参数。以 RobotWin2.0 上的训练参数为例,其余训练配置大致相似。由于 Adam 优化器在处理稀疏梯度方面效率较高,因此选择 Adam 优化器进行参数更新;采用 OneCycleLR 调度器动态调整学习率:在训练的前半部分,学习率从初始值 (10−4) 线性增加到最大值 (10−3),然后在后半部分使用余弦退火将学习率降低到较低值,这有助于平衡收敛速度和泛化性能;采用梯度累积,步长为 2,即在更新模型参数之前累积 2 个连续批次的梯度。这有效地模拟更大的批量大小,同时避免过多的 GPU 内存消耗。
仿真实验
基准测试。在 Simpler(Li ,2024b)、Libero(Liu ,2023a)、Robotwin1.0(Mu ,2025)和 Robotwin2.0(Chen ,2025)基准测试上评估测试-时规模化框架。Simpler 是一个基于 SAPIEN 模拟器和 ManiSkill2 基准测试构建的真实世界到模拟环境的基准测试。它为 WindowX 和 Google Robot 平台提供模拟任务环境;本文主要使用为 WindowX 设计的任务。Libero 是一个用于决策终身学习 (LLDM) 的基准测试,包含四个任务套件。重点关注最具挑战性的套件,因为之前的研究已经在其他套件上取得接近完美的成功率。Robotwin1.0 和 Robotwin2.0 主要关注双臂抓取操作,具有多种多样的资产和任务类型,并提供脚本策略用于自动数据收集。
基线。主要在基于流匹配的 VLA 策略上评估框架,包括 π0(Black,2024)和 π0.5(Black,2025)。为了证明框架的通用性,还将测试-时规模化应用于基于自回归的 OpenVLA(Kim,2024)框架,并将其与 RoboMonkey(Kwok,2025)进行比较,后者也是一个测试-时规模化框架。RoboMonkey 基于 LLaVA-7B(Touvron,2023)构建,并采用偏好学习来训练动作验证器。为了进行更全面的比较,还报告 RT-1-X(O’Neill,2024)、Octo(Team,2024)、RoboVLM(Li,2024a)、SpatialVLA(Qu,2025)和 RDT(Liu,2025)在选定基准测试上的成功率。
真实实验
设置。在类似办公室的环境中使用 RealMan75 双臂机器人构建真实世界实验设置。该实验设置包含五个任务,涉及各种常见物品,例如书籍、钢笔、柜子、充电器、笔记本电脑和纸球。这五个任务如下:接收书籍,机器人接收人类递过来的书籍并将其放回书架;存放充电器,机器人拿起充电器头,将其放入柜子,然后关上柜门;纸和笔,机器人拿起纸球和钢笔,分别将它们放入垃圾桶和笔筒;笔记本电脑,机器人合上笔记本电脑盖子,拔下充电器插头,然后将其放回柜子;以及取书,机器人的左右手臂同时拿起并抬起一本书。
这些任务涵盖广泛的技能和场景,包括人机交互、双臂协调和长时程任务执行,从而全面评估策略的通用能力。为了收集数据,用遥控操作为每个任务记录 100 个回合。然后,将收集的数据用于微调基础策略 π0,并在其基础上部署提出的测试-时规模化框架。在实际实验中,在每个决策步骤同时采样 30 个动作块,每个动作块的长度为 20。
如图所示,平台由一台 Realman RM75-6F 双臂机器人、两个 Robotiq 2F 机械手、一个用作主视图摄像头的 Intel RealSense L515 摄像头以及两个安装在机械臂腕部的 Intel RealSense D405 摄像头组成。其中包含一个主视图摄像头和两个腕部摄像头。一台配备 RTX 4090 GPU 的工作站用于模型部署和推理。
测试期间,每个物体随机放置在约 3 cm × 4 cm 的区域内。整个任务执行过程如上图所示。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 26
26 0
0- 0



 已为社区贡献174条内容
已为社区贡献174条内容

所有评论(0)