【ICLR 2026】赋能具身智能感知!SAGE:打破静态采样瓶颈,视觉位置识别的动态图探索新框架
我们模型针对现有方法中“采样策略静态化”与“模型学习动态化”之间的矛盾,团队创新性地提出了一种 “慢思考”式的动态挖掘范式。通过在训练过程中在线重构地理-视觉亲和图,并结合轻量级的 Soft Probing 特征交互模块,SAGE 能在冻结基础模型(DINOv2)的前提下,实现对高难度样本的自适应挖掘与学习,为全天候自动驾驶与机器人自主导航提供了强有力的感知支撑。
ICLR 2026 赋能具身智能感知!SAGE:打破静态采样瓶颈,视觉位置识别的动态图探索新框架
视觉位置识别(VPR)通过在带有地理标签的图像数据库中检索最佳匹配项,来实现对查询图像位置的粗略定位。近日,北京邮电大学联合齐鲁工业大学山东省计算中心、无界智慧的研究员们提出了 SAGE (Spatial-visual Adaptive Graph Exploration)这一专注于解决复杂环境下VPR难题的全新训练框架,提高了位置识别过程的精度和效率。
该模型针对现有方法中“采样策略静态化”与“模型学习动态化”之间的矛盾,团队创新性地提出了一种 “慢思考”式的动态挖掘范式。通过在训练过程中在线重构地理-视觉亲和图,并结合轻量级的 Soft Probing 特征交互模块,SAGE 能在冻结基础模型(DINOv2)的前提下,实现对高难度样本的自适应挖掘与学习,为全天候自动驾驶与机器人自主导航提供了强有力的感知支撑。

论文链接: https://arxiv.org/abs/2509.25723
开源代码: https://github.com/chenshunpeng/SAGE
引言:视觉位置识别面临的“静态”瓶颈
视觉位置识别(VPR)是自动驾驶和机器人导航中的核心能力,要求模型在光照、季节、视角剧烈变化下仍能精准定位。现有的 VPR 方法,无论是基于 CNN 还是 Vision Transformer,通常依赖于固定的采样策略(如离线聚类)来挖掘难样本。这种“一次思考,处处执行(Think-once, act-always)”的静态策略忽略了一个关键事实:样本的难度是随着模型 Embedding 空间的演变而动态变化的。
这就导致了一个瓶颈:旧的难样本随着训练进行变得不再具有挑战性,而新的难点却未被挖掘。为了解决这一问题,我们提出了 SAGE,一种集成了在线图构建、动态采样与特征增强的统一框架,旨在让模型始终聚焦于当前阶段最有信息量的样本区域。
我们的主要贡献如下:
SoftP 特征交互 (SoftP Feature Interaction):提出了 SoftP,这是一个轻量级模块,利用数据驱动的残差加权来增强具有判别力的局部补丁(local patches)。同时引入了 InteractHead 来建模图像间片段的关联,从而提高描述子在不同视角下的一致性 。
动态地理-视觉图挖掘 (Dynamic Geo-Visual Graph Mining):提出了一种在线策略,在每个训练 epoch 动态重建地理-视觉亲和图。这种方法使得挖掘过程能够与模型不断演变的嵌入空间保持同步,同时优先筛选出信息量最大的样本,从而加快模型收敛 。
加权贪婪团扩展 (Weighted Greedy Clique Expansion):设计了一种权重引导的采样算法,该算法从具有高亲和力的锚点(anchors)开始,迭代扩展最具挑战性的邻域。这种方式能生成效用平衡的训练批次,迫使模型专注于学习细致的空间和视觉差异 。
高效与 SOTA 精度: 基于冻结的 DINOv2 主干网络和参数高效微调(PEFT)实现,SAGE 在八个 VPR 基准测试中均达到了 SOTA水平。值得注意的是,该方法仅使用 4096 维的全局描述子就在 SPED 数据集上达到了 100% 的 Recall@10。
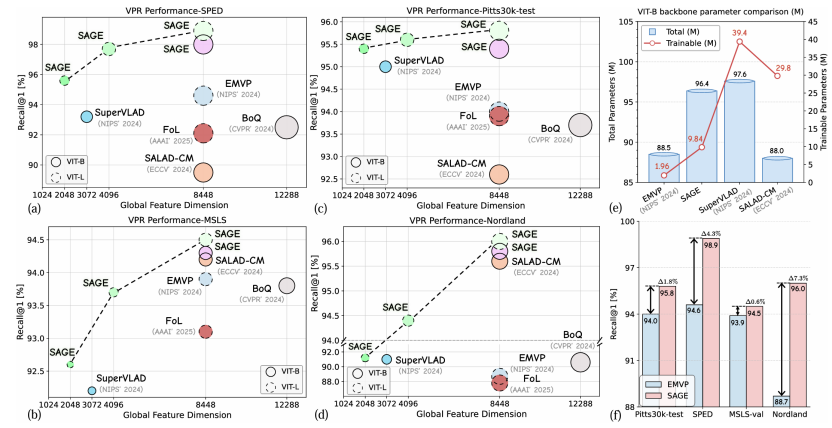
图1. SAGE的性能和参数效率对比
SAGE 模型的核心突破
现有视觉地点识别方法主要依赖于离线聚类或固定的采样策略,忽略了模型特征空间随训练过程演变的动态特性。SAGE 框架创新性地将在线图构建与特征自适应机制引入训练闭环,通过以下三个层面的算法突破,实现了对高难度样本的自适应挖掘与精准表征。
在线地理-视觉图构建
SAGE 在每一个 Epoch 都会重构训练样本之间的拓扑关系。我们不再单纯依赖地理坐标,而是构建一个融合了地理邻近性与视觉相似性的亲和矩阵。对于图中的任意节点 i i i和 j j j,我们定义其亲和力权重 W i j W_{ij} Wij为:
W i j = − ( d g e o ( i , j ) ⋅ d v i s ( i , j ) ) W_{ij}=-(d_{geo}(i,j)\cdot d_{vis}(i,j)) Wij=−(dgeo(i,j)⋅dvis(i,j))
其中, d g e o d_{geo} dgeo代表物理距离, d v i s ( i , j ) = ∣ ∣ F i − F j ∣ ∣ 2 d_{vis}(i,j)=||F_{i}-F_{j}||_{2} dvis(i,j)=∣∣Fi−Fj∣∣2 代表当前模型特征空间中的欧氏距离。这个公式意味着,只有当两个样本地理位置接近且视觉特征也高度相似(易混淆)时,它们的连接权重才会被最大化。这迫使模型在训练中直面那些“看着像但其实是不同地点”的真难样本。
贪婪加权团扩展
为了从上述动态图中挖掘出信息量最大的样本簇(Clique),我们设计了一套贪婪采样算法。
种子选择:首先,计算每个节点的“种子分数” S ( i ) S(i) S(i),即该节点与其他所有节点的亲和力总和,选取 S ( i ) S(i) S(i)最高的节点作为 Anchor。
团扩展(Clique Expansion):随后,我们通过最大化平均亲和力来迭代加入新节点 v ∗ v^{*} v∗,扩展当前的样本团 C C C:
v ∗ = arg max v ∉ C 1 ∣ C ∣ ∑ u ∈ C W u , v v^{*}=\arg\max_{v\notin C}\frac{1}{|C|}\sum_{u\in C} {W_{u,v}} v∗=argv∈/Cmax∣C∣1u∈C∑Wu,v
这种基于图密度的扩展方式,确保了每个 Batch 都是一个互为难样本的集合,从而实现高效的梯度下降。
轻量级特征探测
为了在冻结大模型 Backbone 的前提下挖掘细粒度特征,我们设计了 SoftP 模块。不同于粗暴的重加权,SoftP 引入了一种数据驱动的残差机制。对于局部特征 X i X_{i} Xi,我们计算其 l 2 l_{2} l2范数响应 s i s_{i} si,并通过 Sigmoid 函数生成一个有界的标量系数 β i β_{i} βi。最终的特征调制公式为:
X i ˉ = X i + β i X i = ( 1 + β i ) X i \bar{X_{i}}=X_{i}+β_{i}X_{i}=(1+β_{i})X_{i} Xiˉ=Xi+βiXi=(1+βi)Xi
这种形式 ( 1 + β i ) (1+β_{i}) (1+βi)类似于一种“软注意力”。数学推导证明,它能选择性地增大高响应区域(如独特建筑纹理)的方差贡献,同时通过残差连接保留原始特征的几何结构,提升了描述子在极端视角下的鲁棒性。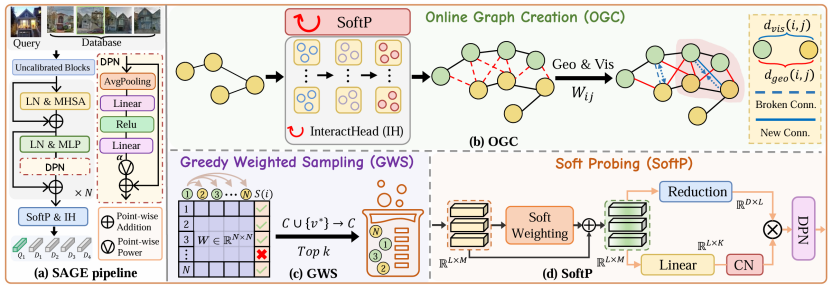
图2. SAGE框架介绍
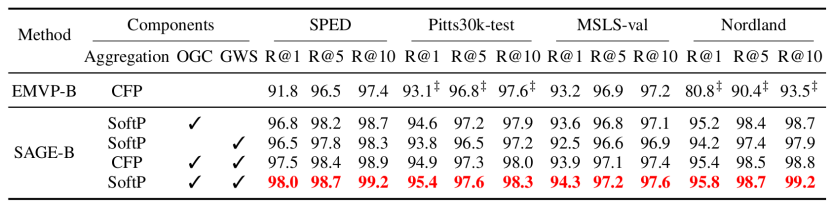
实验结果:性能与效率的显著优势
与领先方法的比较
我们在 Pitts30k, MSLS, Nordland, SPED, Tokyo24/7 等 8 个数据集上进行了广泛的评测。实验结果表明,SAGE 在所有测试基准上均优于现有的单阶段检索方法(如EMVP, SuperVLAD, SALAD-CM等)和复杂的两阶段重排序方法(如FoL, SelaVPR等)。
表1. 在VPR基准数据集上的SoTA方法比较
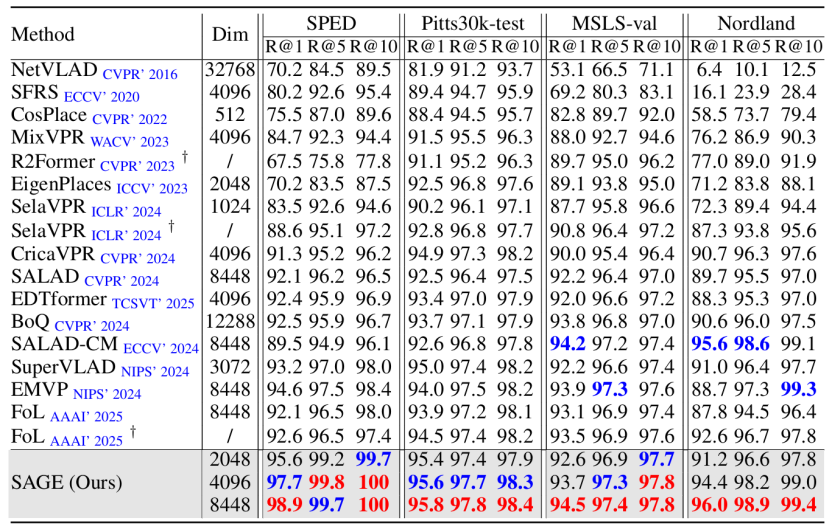
表2. 在更具挑战性的数据集上与SoTA方法的比较结果
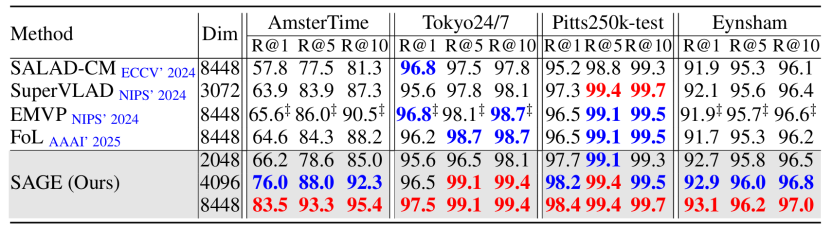

图3. 定性结果与Importance Heatmaps的视觉比较
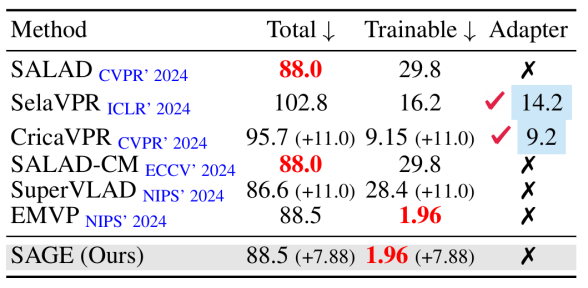
极致的参数效率 (Parameter Efficiency)
SAGE 采用了 PEFT (Parameter-Efficient Fine-Tuning) 范式。我们冻结了 DINOv2 骨干网络,仅微调轻量级的 DPN 层和新增模块。相比于引入大量 Adapter 的方法(如 SelaVPR),SAGE 的总参数量更低。相比于微调部分 Encoder 的方法(如 SALAD),SAGE 的可训练参数量大幅减少,但在性能上却实现了反超。
表3. 使用DINOv2-B骨干网络的多种VPR方法参数(M)比较。
消融实验
消融实验证实了 SAGE 的协同效应。如表3 所示,在应对 Nordland 这种剧烈季节变化的场景时,引入在线图构建 (OGC) 使得 Recall@1 从基线的 80.8% 激增至 95% 以上,证明了动态挖掘对于克服环境差异的重要作用;同时,Soft Probing (SoftP) 相比传统聚合模块展现了更强的特征辨别力。最终,当 SoftP、OGC 与GWS 三者结合时,SAGE 在所有基准上均刷新了最佳成绩,有力证明了“自适应特征增强+动态难样本挖掘”的闭环机制是突破 VPR 性能瓶颈的关键。
表3. 消融实验
应用前景与未来方向
赋能全天候自动驾驶定位: SAGE 在极端视角变化、光照差异及季节更替场景下展现出的卓越鲁棒性 ,使其非常适用于自动驾驶系统中的闭环检测(Loop Closure Detection)与重定位(Relocalization)任务。通过解决长期运行中的环境变化难题 ,SAGE 有望降低高精地图维护的频率与成本,提升自动驾驶车辆在复杂城市环境中的定位可靠性。
适配资源受限的移动机器人: 得益于冻结骨干网络与参数高效微调(PEFT)的架构设计 ,SAGE 在保持 SOTA 精度的同时大幅降低了可训练参数量 。这种“轻量化”特性使其具备极高的部署价值,能够集成到算力与功耗受限的端侧嵌入式系统中,为服务机器人、无人机等移动平台提供高效的视觉导航支持。
拓展动态场景理解与具身智能: 面向未来,我们将探索结合 SAM等语义分割大模型,进一步过滤动态物体(如车辆、行人)干扰 ,实现对场景的深层语义理解。同时,SAGE 提出的“动态图探索”范式具有较强的通用性 ,未来可推广至行人重识别及其他度量学习任务 ,为构建更通用的具身智能感知系统提供新的思路。
作者介绍

第一作者:陈顺鹏是北京邮电大学在读博士生,研究方向主要聚焦于计算机视觉、多模态学习、具身智能与机器人及视觉位置识别,致力于解决机器人自主导航中的环境感知难题。其相关学术成果已在 ICLR、AAAI、IROS 等国际顶级会议及 TCSVT、Information Fusion 等高水平期刊上发表。

指导老师:王常维是齐鲁工业大学山东省计算中心特聘副研究员,硕士生导师,中国科学院院长特别奖获得者,齐鲁青创学者,博士毕业于中国科学院自动化研究所多模态人工智能系统全国重点实验室。研究方向为多模态人工智能、三维视觉、具身智能、模型轻量化等,在国际顶级期刊(IEEE TPAMI,IEEE TIP,IEEE TNNLS,IEEE TMM等)和会议(ICCV,CVPR,ICML,NeurIPS,AAAI,ICRA等)上发表论文 51篇,包括中科院一区和CCF-A类论文37篇,其中第一作者/通讯作者(含共同)发表中科院一区和 CCF-A 类论文18篇,ESI 高被引论文 3 篇,CCF-B 类会议最佳论文入围 1 篇, IEEE Transactions 封面文章 1 篇,研究成果已应用于华为等多家知名企业。担任CVPR, ECCV, NeurIPS, ICLR, AAAI, IJCAI, KDD, IEEE TIP, IEEE TMM等国际知名会议和期刊的程序委员或审稿人,中国计算机学会、中国图形图像学会会员。
指导老师:许镕涛是无界智慧联创兼CTO,Rongtao-Xu.github.io。MBZUAI研究员。中科院自动化所多模态人工智能国重(前NLPR)博士, 在学期间曾获得中科院院长奖、两次IEEE旗舰会议最佳论文提名奖、国奖、北京市和中科院优秀毕业生。华中科技大学数学与计算机双学士学位。研究方向为具身智能与机器人,提出全球首个基于空间可供性操作大模型A0,曾在银河通用共同主导全球首个具身导航大模型NaVid。在相关领域顶级学术期刊和会议上共发表论文80余篇,其中以第一作者或通讯作者发表论文近40篇,含ESI高被引论文3篇。曾在NeurIPS、AAAI、ICRA等会议上发表多篇Oral论文, 谷歌学术引用近2000次。拥有多项发明专利,研究成果应用于YOLO系列,以及无界智慧、银河通用、华为、Momenta等多款产品。
指导老师:徐士彪是北京邮电大学 教授、博士生导师,人工智能学院 副院长,北京市杰青,国家重点研发计划首席科学家。目前主要研究方向集中在多模态人工智能领域,具体包括空间计算与模型蒸馏、具身智能体、智能医学等方向。在相关领域学术期刊和会议上共发表论文120余篇(顶级SCI国际期刊及顶级国际会议论文约70篇,ESI高被引论文5篇),授权发明专利11项,获“昌聚工程”青年人才(2024)、小米青年学者(2024)、中国图学学会科技进步二等奖(2021)、陕西高等学校科学技术一等奖(2017)及中国科学院青年创新促进会人才专项(2021)、北京邮电大学教育教学成果一等奖(2025)。主持/参与国家重点研发计划项目、工信部和应急管理部重大项目课题、国家自然科学基金国际合作重点项目、北京市杰青项目及多项国家自然科学基金面上项目;成果应用于多家知名企业。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 11
11 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)