清华大学:首次将“环境感知”与“全身运动跟踪”,统一到端到端强化学习框架
Deep Whole-body Parkour 提供了一个“如何让机器人既会做精细全身动作,又能适应环境变化”的可行路径。以前的人形控制,要么是“感知强、动作弱”,要么是“动作强、感知弱”,这次的融合思路,其实更贴近人类的运动模式——我们做跑酷动作时,也是边看障碍物边调整手、脚的位置,而不是先背一套动作再硬套。当然,这条融合路径未来要走的路还很长:比如如何让机器人自主选择动作?如何处理弹性、可变形

人形机器人控制从“环境无感复现”向“感知交互协同”的关键转变
——范式融合
目录
人形机器人运动控制长期存在两大范式分野:
一边是 “感知驱动” 运动范式:能适应复杂地形但交互维度受限(“足部交互依赖”);
另一边是 “模仿驱动” 运动跟踪范式:能复现复杂技能但缺乏环境适应性。
近日,清华大学、上海期智实验室团队的最新研究:深度全身跑酷框架(Deep Whole-body Parkour),直接打通了这两个技术方向的壁垒——

将深度感知直接融入全身运动追踪的端到端框架,突破了传统方法对固定轨迹或单一交互模式的依赖。
此外,研究还构建了运动-场景对齐的数据集,并开发了高效的大规模并行训练架构。
标志着人形机器人控制从“环境无感复现”向“感知交互协同”的关键转变。
01 人形机器人“全身跑酷”难在哪?
要理解这项研究的价值,得先看清过去人形控制领域的“双范式困局”:感知locomotion和运动追踪。
两个方向各有所长,却始终无法兼顾“动作复杂度”和“环境适应性”:

感知 locomotion:能“走稳”却不会“用手”
这类方法的核心是“靠感知调整步态”,比如融合深度图、高度图等外感受数据,让机器人能实时适应不平坦地形,甚至完成跳跃、跨障等动态动作。
近年来四足机器人的“跑酷”、人形机器人的快速行走,都属于这个范畴。
但它的局限很明显:交互方式太单一,只靠脚。机器人的上肢(手臂、手掌)仅用于维持平衡,完全不参与环境接触。
比如遇到1米高的箱子,感知 locomotion 只能尝试“跳过去”,却做不到人类常见的“用手撑箱”。
本质问题是:这类方法的控制目标是“稳定 locomotion”,而非“全身多接触交互”,导致机器人面对需要手、脚、躯干共同参与的动作时,完全没有应对能力。

▲图1| Deep Whole-Body Parkour:深度感知直接融入全身运动追踪框架
运动追踪:会“耍帅”却看不见“路”
另一类方法聚焦“复刻复杂动作”,比如 DeepMimic、AMP 等,靠模仿人类运动数据(比如动捕数据),让机器人在模拟或实验室环境里完成后空翻、武术、跑等精细动作,甚至能跨越“sim-to-real 鸿沟”,在真实硬件上复现。
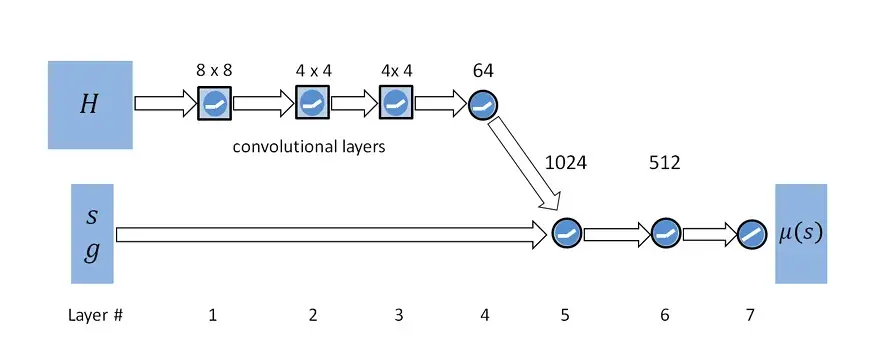
图2| DeepMimic视觉运动策略网络的结构示意图
但它的致命缺陷是环境无关性:机器人只“死记硬背”预录的动作轨迹,完全不感知周围环境的几何信息。
举个具体例子:要让机器人 vault(撑物跳跃) 上一个箱子,运动追踪策略会精确复刻“在空旷空间里的 vault 动作”,但如果箱子的实际高度比预录时高10cm、距离远20cm,机器人既不会调整跳跃时机,也不会修正手的接触位置。

▲图5 | 基于非结构化动作数据的框架 —— 物理模拟角色以风格化行为完成挑战任务(AMP)
简单说:这类方法是“闭着眼睛做动作”,只能在环境参数完全匹配的场景里生效,一旦换个障碍物位置,就成了“无用功”。
推荐阅读:盘点 | 8年模仿学习“霸权”史:为何它仍是人形机器人运动控制的“头号解”?

02 破局关键
Deep Whole-body Parkour 的核心思路很直接:把两个范式的优势捏合在一起——
让运动追踪拥有“感知环境的能力”,同时让感知 locomotion 能处理“全身多接触动作”。
具体怎么做?
研究从“数据构建”“训练框架”“sim-to-real 适配”三个层面,搭建了一套完整的解决方案。
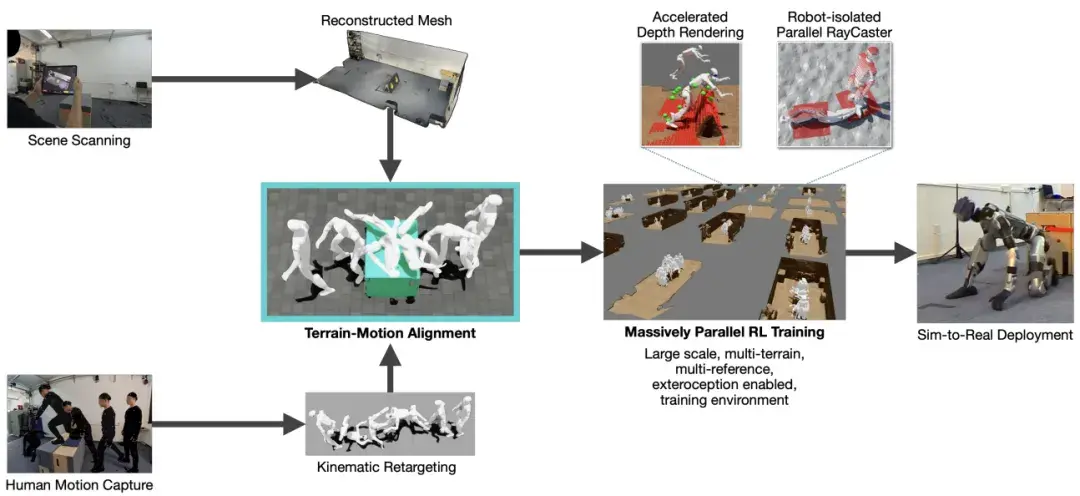
▲图6 | 数据驱动的人形机器人全身控制框架 —— 从场景扫描、动作捕捉到虚实部署的全流程
第一步:先搞“动作-地形”配对数据,解决“学什么”的问题
要让机器人学会“看环境做动作”,首先得有“动作+对应环境”的训练数据——
以往的 AMASS(人体运动数据集)只有动作没有环境,OMOMO(物体操作数据集)没有全身跑酷类动作
因此,研究构建了运动-场景对齐的数据集。
(1)“录”动作+“扫”环境,保证空间对齐
- 人类演示录制
用光学动捕系统记录专业跑酷演员的动作,包括 vault、dive roll、跪爬、跳坐等4个核心全身动作,每个动作都在真实障碍物(三角形坡道、0.5m×0.6m×0.4m 木箱、平地)上完成。

▲Human Motion Capture
- 环境同步扫描
同时用带 LiDAR 的 iPad Pro(3D Scanner App)扫描场景,生成高精度环境 mesh(网格模型),并和动捕轨迹做空间对齐。
比如演员手撑箱子的位置,会精确对应到 mesh 上的箱子表面。
确保“动作接触点”和“环境几何”完全匹配。

▲Scene Scanning
(2)动作“翻译”:让机器人能“学”
人类的动作不能直接给机器人用(体型、关节数都不一样),因此研究用 GMR 框架把人类动作“retarget(迁移)”到 Unitree G1 人形机器人上:
- 先通过优化做“ kinematic 滤波”,去掉人类动作中机器人做不到的姿势(比如过度弯腰);
- 再手动调整关键帧,确保动作满足机器人的物理约束:比如手、脚的接触点必须在环境表面,不能穿模;关节角度不能超过硬件限制;
- 最后去掉动捕数据里的高频噪声,避免机器人“抖腿”“手抖”。
▲Kinematic Retargeting
(3)环境“瘦身”:避免机器人“学死”一个场景
如果只在实验室的固定场景里训练,机器人会“过拟合”——换个箱子位置就不会动了。研究做了两步处理:
- 提取核心几何:
把扫描的环境 mesh 里的“无关信息”(比如实验室的墙、天花板、桌子)删掉,只保留障碍物本身(比如箱子、坡道);
- 随机化部署:
在 NVIDIA Isaac Lab(机器人模拟平台)里,把“迁移后的动作+对应的障碍物 mesh”作为一个“动作-地形对”,随机放在模拟空间里——比如这次箱子在左边1米,下次在右边0.8米,让机器人学会“看障碍物位置做动作”,而不是记死位置。

▲Reconstructed Mesh
第二步:优化训练效率,解决“怎么高效学”的问题
要训练“感知+全身运动”的策略,需要大规模并行模拟(比如同时跑上千环境),但传统模拟有两个效率瓶颈:深度图渲染慢、机器人“看到”其他环境的干扰。

▲大规模并行强化学习训练大规模、多地形、多参考点、外周感知支持的训练环境
(1)10倍渲染提速:分组光线投射
Isaac Lab 虽然支持 GPU 加速,但默认的深度渲染会让一个环境里的机器人“看到”其他环境的机器人,而且每个光线要遍历所有 mesh,速度慢。
比如环境A的机器人能看到环境B的机器人,形成“幽灵干扰”。
因此,研究自研 Massively Parallel Grouped Ray-Casting(大规模并行分组光线投射) 算法:

- 预计算分组:
给静态地形(比如地面、箱子)分配统一组 ID(-1),每个机器人分配唯一组 ID;
- 光线只扫“自己该看的”:
机器人的光线会先扫静态地形,再扫自己组的动态物体(比如自己的手臂),完全忽略其他组的物体——
这样每个光线的搜索范围从“所有 mesh”缩小到“自己组+静态”,渲染速度直接提升10倍。
(2)不做“无效功”
传统训练是“从头到尾反复练”,效率低。团队设计了两个关键机制:
① 自适应采样:哪个难练练哪个
把每个动作分成1秒的“时间片”(), 训练时记录每个时间片的失败次数:
- 比如某个动作的“手撑箱子瞬间”失败多,就多采样这个时间片的初始状态;
- 用指数平滑把“离散失败次数”变成“连续失败分数”,避免某一次失败导致训练波动;
- 最后按失败分数加权采样,让机器人把时间花在“容易翻车”的环节,而不是反复练已经会的部分。

② Stuck 检测:提前止损
如果机器人卡在“不可能的状态”(比如脚穿进箱子里、手悬在半空够不到障碍),继续训练只会产生无效数据。
因此,研究会检测这种“stuck 状态”,提前截断训练回合,避免浪费计算资源。
(3)相对帧设计:让机器人“边追动作边调位置”
这是整个训练框架的“点睛之笔”——以往运动追踪用“绝对帧”,要么追不准动作,要么适应不了环境。
因此, 研究设计了相对帧 (), 结合两者的优点:
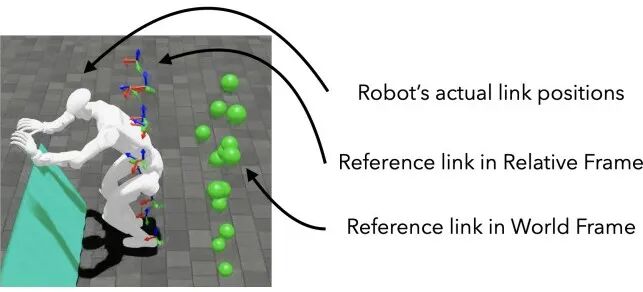
▲图7| 相对帧基本概念示意图 —— 融合机器人基坐标系与参考坐标系的坐标组合方式
- 位置融合:相对帧的 xy 坐标用机器人的实际位置(保证机器人能根据环境调整位置),z 坐标用参考动作的高度(保证动作不会跳太高或太矮);
- 姿态融合:相对帧的偏航角(yaw,左右转)用机器人的实际角度(保证机器人面对障碍物),滚转角(roll)和俯仰角(pitch)用参考动作的姿态(保证动作规范性,比如不会歪着身子 vault)。
简单说:机器人会“看着障碍物调整自己的位置和朝向,同时按参考动作的姿态做动作”,既不会跑偏,也不会动作变形。
第三步:从模拟到真实,解决“落地难”的问题
(1)模拟端:模拟真实噪声
在模拟的深度图里加两种噪声,让它看起来和真实的一样:
- Gaussian 噪声:模拟传感器噪声;
- 补丁伪影(patched artifacts):模拟真实场景里的反光(比如金属箱子)、运动模糊(机器人快速移动时)、 stereo 算法误差(深度图里的小空洞)。

(2)真实端:保证帧率
真实世界用 Intel RealSense D435i 深度相机,同时用 GPU 版 OpenCV 的 inpainting(修复)算法:
- 实时填补深度图里的小空洞;
- 平滑反光导致的“飞点”;
- 最终保证深度图输出帧率稳定在50Hz,满足实时控制需求。

▲图8| 深度可视化的虚实鸿沟弥合示意图 —— 真实与模拟场景下的深度数据处理对比
03 实验
研究在 Unitree G1 上面做了大量实测,从室内到室外,从位置偏差到干扰物,全方位测试策略的鲁棒性。
硬件与部署
(1)硬件配置
- 机器人:Unitree G1(29个自由度,2025年9月版本);
- 感知:RealSense D435i 深度相机装在头部,单独开一个进程采集深度图,避免占用推理资源;
- 计算:Jetson 开发板,用 ONNX 加速神经网络推理(CPU 版,足够实时);
- 框架:ROS2 部署,把“走路平衡策略”和“跑酷策略”做了状态机切换——平时用走路策略保持平衡,到障碍物前触发跑酷策略,完成后切回走路。

(2)部署流程(无精确里程计)
以往运动追踪需要机器人精确站在预设起点(误差不能超过5cm),这次完全不用:
让机器人用走路策略走到障碍物前的“大致区域”(比如离箱子1-2米,不用精确测量);
手动触发对应的跑酷策略(比如“vault 动作”);
机器人通过深度相机实时看箱子的位置,调整步长和身体姿态;
完成动作后,自动切回走路策略,离开场景。
不需要额外的日志系统——在哪都能跑。
深度视觉:位置偏了能修正
这是最核心的实验:测试机器人在初始位置偏离时,能不能靠深度图“修正”。
(1)测试设置
- 训练时:初始位置只在参考位置的0.3m×0.3m 范围内随机;
- 测试时:初始位置扩大到0.5m×0.5m(远超训练范围),甚至1.2m×1.2m 的大网格;
- 指标:看机器人能否调整步态,最终让手、脚接触到正确位置,完成动作。
(2)结果:位置方差快速收敛
如图所示,机器人刚开始的 xy 位置方差很大(因为初始位置随机),但随着动作推进(比如走向障碍物的过程中),方差快速下降到接近0。
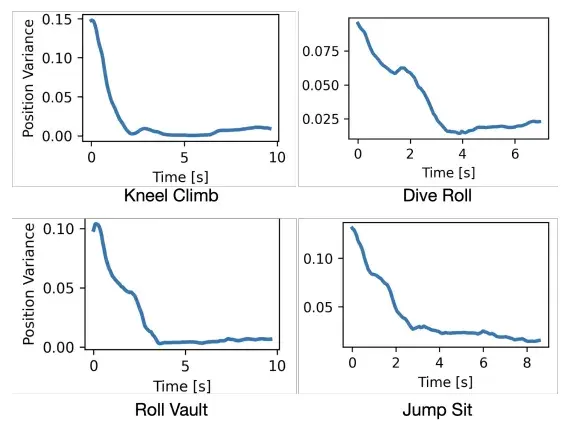
▲图9| 不同动作的 xy 位置方差随时间变化曲线 —— 深度视觉赋能端到端运动追踪系统的位置校正能力展示
说明机器人靠深度图“看到”障碍物后,主动缩短或拉长步长,把自己“挪”到了正确的动作起始位置。
即使是1.2m×1.2m 的网格搜索,机器人的动作成功率几乎是100%,只有在最边缘(离参考位置0.6m 以上)才会失败。
没深度的 BeyondMimic 在0.3m 偏差时就会撞箱子,而本文方法的容错范围直接翻了2倍。
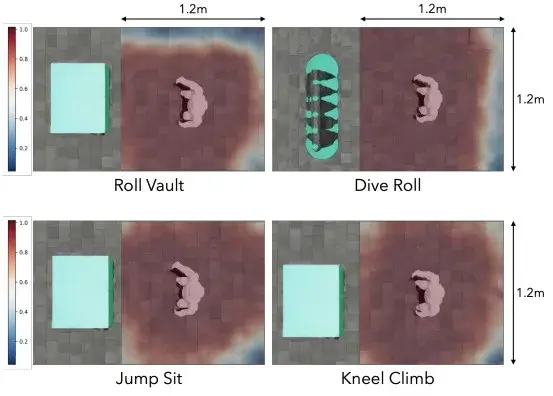
▲图10| 不同动作在 1.2m×1.2m 起始位置区域的网格搜索成功率热力图 —— 红色对应 100% 成功、深蓝色对应 0% 成功
(3)数据对比:有深度 vs 没深度
从表1能看出来,在“无位置随机”时,有无深度的差距不大;但一旦加入“位置随机”,没深度的 BeyondMimic 就崩了:
- dive roll 误差高了66%);
- 跳坐动作的误差高了41%;
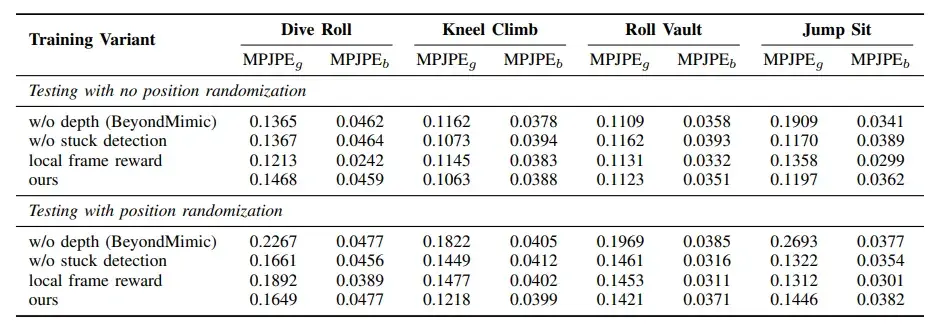
▲表1| 不同训练变体在四个动作下的性能对比表
而本文方法的 MPJPE 基本稳住,甚至比“没 stuck 检测”的变体更优——说明深度视觉确实能对抗位置偏差。
抗干扰能力:加“障碍物”也不怕?
- 宽梁干扰物:横跨在机器人前方,不挡动作轨迹,但会出现在深度图里;
- 平面干扰物:长平台,部分挡住机器人的动作路径(比如会改变落地位置);
- 墙干扰物:在障碍物旁边立一面墙,不挡动作但占深度图视野。

结果:对“不挡路”的干扰物很鲁棒
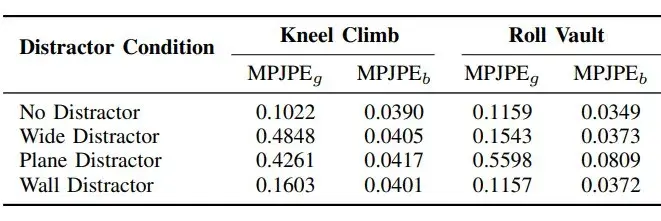
▲表2| 不同干扰物条件下的运动追踪性能评价表
从上表得出:机器人对“不影响物理交互”的干扰物(墙、宽梁)很鲁棒,但对“改变动作动力学”的干扰物(长平台)会有误差。
04 价值与局限
客观来讲,这项工作的核心价值在于:
- 统一了“感知”和“全身运动”两个范式
以往要做“能适应环境的全身动作”,需要分别开发“感知模块”和“运动模块”,再做复杂的接口对接——
比如用感知模块输出障碍物位置,再用运动模块生成对应动作。
而这项研究把两者融成一个端到端策略:输入是深度图+动作参考,输出是机器人关节指令,不用中间接口,部署更简单。
- 不依赖里程计,降低真实部署门槛
很多人形机器人研究需要激光雷达、GPS 做全局定位,才能保证动作起始位置准确——但室内没 GPS,复杂环境激光雷达会被遮挡。
这项研究完全不用里程计:靠相对帧和深度图,机器人“自己看”障碍物位置调整,哪怕在室外没有任何定位设备,只要把机器人放在障碍物前,就能触发动作,大大降低了应用成本。
- 为“大规模动作库”打基础
现在只训练了4个动作,但框架是通用的——以后要加“爬楼梯”“用工具开门”“跨越栏杆”等动作,只需要按同样的流程:录人类动作→扫环境→迁移到机器人→加入模拟训练,不用重构整个系统。
这为以后做人形机器人的“动作库”提供了可行路径。

但同时,这项工作离“通用人形控制”还有一定距离:
-
动作库太“少”
目前只测试了4个跑酷类动作,没有涉及更实用的日常操作(比如开柜门、搬东西、用勺子吃饭)——
这些更复杂的“接触模式”更复杂,能不能用这套框架做,还需要验证。
-
动作选择靠“人”,不是“机器人自主”
现在要做哪个动作,需要人工触发状态机(比如“看到箱子就触发 vault 动作”)——机器人自己不会判断“遇到矮箱子该 vault,遇到高箱子该爬”。
未来需要加“动作决策模块”,让机器人根据环境自主选动作,才算真正的“智能”。
05 总结
Deep Whole-body Parkour 提供了一个“如何让机器人既会做精细全身动作,又能适应环境变化”的可行路径。
以前的人形控制,要么是“感知强、动作弱”,要么是“动作强、感知弱”,这次的融合思路,其实更贴近人类的运动模式——我们做跑酷动作时,也是边看障碍物边调整手、脚的位置,而不是先背一套动作再硬套。
当然,这条融合路径未来要走的路还很长:比如如何让机器人自主选择动作?如何处理弹性、可变形物体?如何降低训练成本?
Ref
论文名称:Deep Whole-body Parkour
论文作者:Ziwen Zhuang, Shaoting Zhu, Mengjie Zhao, Hang Zhao
论文地址:https://arxiv.org/pdf/2601.07701v1.pdf
项目网站:https://project-instinct.github.io/deep-whole-body-parkour

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 11
11 0
0- 0



 已为社区贡献88条内容
已为社区贡献88条内容

所有评论(0)