《VLA 系列》π0 | 流匹配 | 开山之作 | VLA
π₀是一种新型视觉-语言-动作(VLA)框架,采用流匹配技术实现高灵巧度机器人控制。该模型创新性地结合了预训练VLM骨干(SigLIP+Gemma)和流匹配动作模块,支持50Hz的高频连续动作输出。通过动作块设计和跨体化适配,π₀能统一控制7种不同构型的机器人,完成68项任务。其核心优势在于:1)流匹配替代传统自回归离散化,实现连续动作建模;2)动作专家模块(MoE设计)专门处理机器人状态;3)多
π₀是首个基于流匹配的VLA框架,支持50Hz的高灵巧度任务控制
模型使用VLM骨干 + 流匹配动作模块的混合架构,专为机器人高灵巧度连续动作控制设计
- 放弃自回归离散化,首次将
预训练VLM 与 流匹配(扩散的变体)结合,设计出流匹配型 VLA 模型,直接建模连续动作分布 - 并引入
动作块架构,支持最高 50Hz 的高频率动作生成 将预训练 VLM 骨干与流匹配动作生成深度融合,既继承了扩散在连续动作生成上的优势,又获得了 VLM 的语义推理、语言指令跟随能力,提升泛化能力。
论地地址:π0: A Vision-Language-Action Flow Model for General Robot Control
开源地址:https://github.com/Physical-Intelligence/openpi
推理性能:在NVIDIA GeForce RTX 4090 GPU上,端到端推理仅73ms,离线推理(含网络延迟)86ms
1、VLA技术流派对比(流匹配、自回归离散化生成、扩散模型)
下面的表格,对比π₀的流匹配、自回归离散化生成、扩散模型的技术思路流程、模型组成、模型特点三个维度:
| 对比维度 | 自回归离散化生成(传统VLA,如OpenVLA) | 扩散模型(如Diffusion Policy) | π₀的流匹配(流匹配+VLM) |
|---|---|---|---|
| 思路流程 | 1. 输入:多模态观测(图像+语言指令) 2. 处理:VLM编码多模态信息 3. 动作处理:连续动作→离散令牌 4. 生成:自回归逐令牌输出 5. 输出:离散令牌映射回连续动作 |
1. 输入:机器人观测(图像+本体状态) 2. 处理:观测编码器编码输入 3. 动作处理:对真实动作逐步加噪 4. 生成:多步去噪预测噪声 5. 输出:去噪后得到连续动作 |
1. 输入:多模态观测(图像+语言指令+本体状态) 2. 处理:PaliGemma VLM编码多模态语义 3. 动作处理:动作专家接收VLM输出+噪声 4. 生成:流匹配路径建模连续动作分布 5. 输出:动作块+前向欧拉积分推理连续动作序列 |
| 模型组成 | 核心模块: - 预训练VLM骨干(如PaLM-E) - 动作离散化/量化模块 - 自回归令牌解码器 |
核心模块: - 观测编码器(视觉/本体状态) - 扩散去噪解码器 - 噪声调度模块 |
核心模块: - PaliGemma VLM骨干(SigLIP+Gemma) - 3亿参数动作专家模块 - 线性高斯流匹配路径模块 - 动作块(H=50)生成模块 |
| 模型特点 | - 优势:继承VLM的语言指令跟随能力 - 不足:动作离散化损失精度;单步生成效率低,控制频率<10Hz;无法适配高灵巧操作 |
- 优势:直接建模连续动作分布,动作鲁棒性强 - 不足:无预训练VLM,缺乏语言理解能力;泛化性弱,依赖单任务数据 |
- 优势:融合VLM语义能力+流匹配连续动作建模;动作块设计支持50Hz高频率控制;跨7种机器人构型,适配长时高灵巧任务 - 不足:需10000小时大规模预训练数据支撑 |
简单来说:
自回归离散化的动作表示方式,无法支持高频率、高灵巧度的连续动作控制,动作生成的流畅性和精度受限,这是传统 VLA 模型在复杂灵巧任务中性能不佳的核心原因。扩散动作生成方式,用扩散建模机器人动作的概率分布,生成连续、多样的动作,核心优势是提升了动作生成的鲁棒性和对复杂物理交互的适配性。这类模型未结合预训练VLM骨干,仅基于机器人具身数据从头训练,缺乏互联网级的语义知识、语言理解能力和跨任务泛化能力,无法实现语言指令驱动的零样本控制,通用性差。流匹配方式,放弃自回归离散化,首次将预训练 VLM 与流匹配(扩散的变体)结合,设计出流匹配型 VLA 模型,直接建模连续动作分布,并引入 动作块架构(Action Chunking) 支持最高 50Hz 的高频率动作生成。将预训练 VLM 骨干与流匹配动作生成深度融合,既继承了扩散在连续动作生成上的优势,又获得了 VLM 的语义推理、语言指令跟随能力,提升泛化能力。
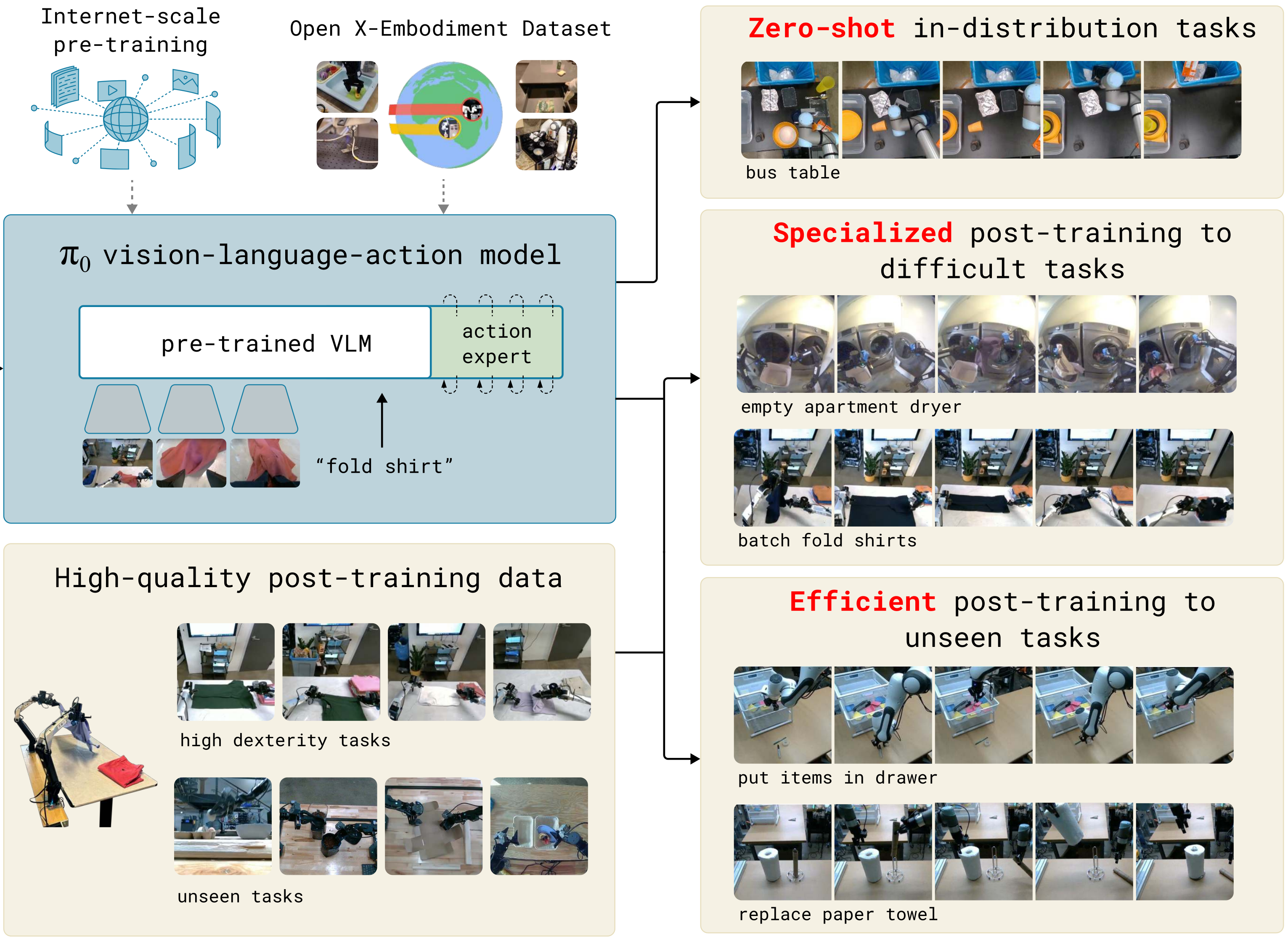
如下图所示,π₀流匹配模型以互联网级预训练、开源跨体化数据集为基底(预训练 VLM + 动作专家架构),
结合高灵巧任务、未见过任务的高质量后训练数据,可实现三类能力:零样本完成分布内任务、专项后训练应对复杂难任务、高效后训练适配未见过的新任务。
以下是π₀的流匹配、自回归离散化生成、扩散模型的详细差异对比表:
| 对比维度 | 自回归离散化生成(如OpenVLA) | 扩散模型(如Diffusion Policy) | π₀的流匹配(流匹配+VLM) |
|---|---|---|---|
| 技术原理 | 将连续动作离散为令牌,通过自回归方式逐令牌生成,映射回连续动作 | 对动作逐步加噪→建模噪声分布→多步去噪生成连续动作 | 扩散变体(流匹配路径)建模连续动作分布,结合预训练VLM实现多模态约束 |
| 动作表示 | 离散令牌(连续动作→量化为有限离散值) | 连续动作向量 | 连续动作块(一次性生成H=50步连续动作) |
| 动作生成 | 单步自回归生成(逐令牌输出) | 多步去噪生成(通常10-20步) | 动作块+流匹配前向欧拉积分(10步) |
| 支持的控制频率 | 低(单步生成效率低,通常<10Hz) | 中(多步去噪,通常10-20Hz) | 高(动作块设计,最高50Hz) |
| 语言指令跟随能力 | 有(依赖VLM预训练,但离散化损失语义精度) | 无(未结合VLM,仅依赖机器人具身数据) | 强(结合PaliGemma VLM,实现视觉-语言-动作语义对齐) |
| 泛化能力 | 弱(单任务/少数机器人,离散化限制跨场景适配) | 中(单一/少数机器人,无VLM泛化语义知识) | 强(跨7种机器人构型、68项任务,预训练+精调范式) |
| 适配任务类型 | 简单任务(如物体重定位、抽屉开关) | 中等灵巧任务(如抓取、放置) | 高灵巧长时任务(如叠衣、盒子组装,耗时5-20分钟) |
| 核心缺陷 | 动作离散化损失精度,控制频率低,无法适配高灵巧操作 | 无语言理解能力,泛化性差,依赖单任务数据 | (无明显缺陷)需大规模预训练数据支撑 |
2、模型架构
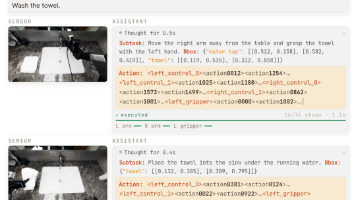
如下图所示,展示π₀的思路流程,“数据输入→多模态处理→动作生成→机器人适配”
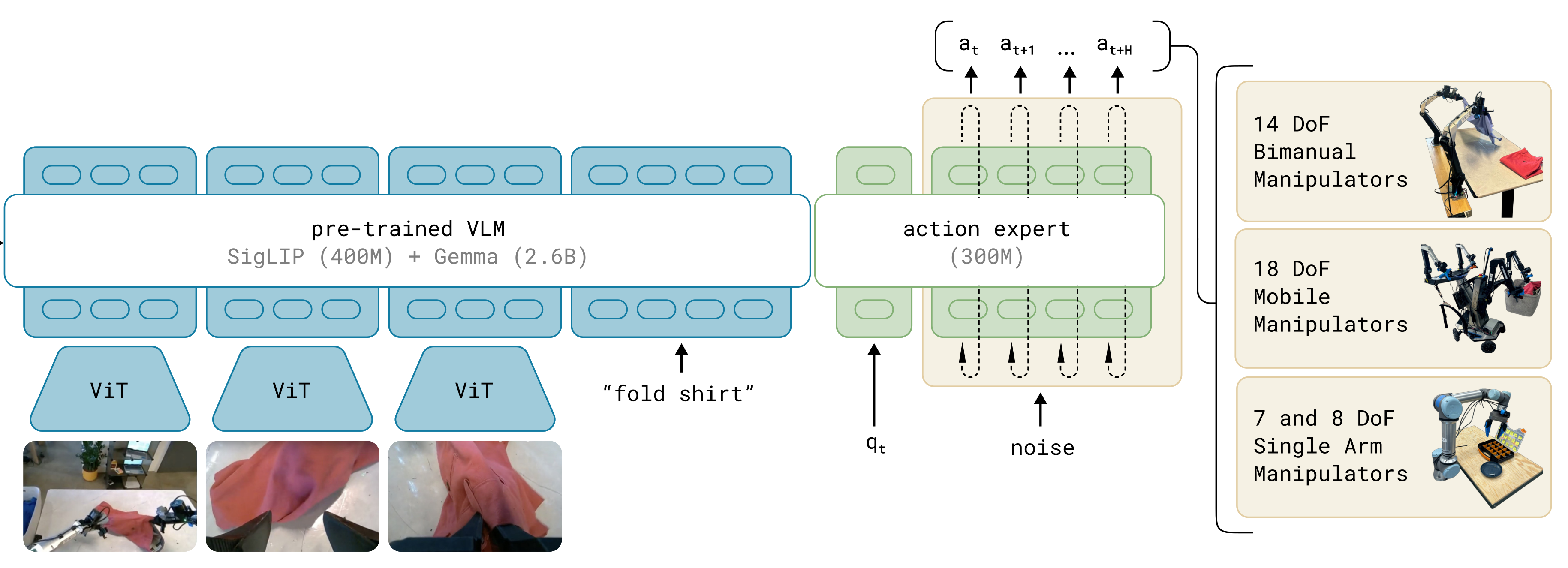
核心展现π₀模型“多源信息驱动→VLM推理语义理解→动作专家生成适配动作”的设计逻辑,细节如下:
步骤1:多模态输入层
这是模型接收任务信息的入口,包含两类核心输入:
- 视觉输入:机器人的多视角观测图像(如图中叠衣服的场景图),每张图像通过独立的**ViT(视觉Transformer)**编码为向量,将图像的空间特征转化为可与语言对齐的嵌入表示;
- 语言输入:自然语言任务指令(如“fold shirt”),直接输入后续的VLM模块,作为任务的语义约束。
步骤2:多模态语义融合(图中间:预训练VLM模块)
该模块是π₀“理解任务语义”的核心,由 SigLIP(400M参数)+Gemma(2.6B参数)组成:
SigLIP负责**视觉-语言的语义对齐**:将ViT编码后的图像向量,与语言指令的向量映射到同一语义空间,让模型理解“图像中的场景(叠衣服)”与“语言指令(fold shirt)”是对应的任务;Gemma负责**语言语义的深度理解**:解析指令的任务意图,为后续动作生成提供明确的语义目标;- 最终输出:整合“视觉场景+语言指令”的多模态语义表征,作为动作生成的任务约束。
步骤3:动作生成(图中间右侧:action expert模块)
该模块是π₀“输出机器人动作”的核心(300M参数),接收三类输入并生成连续动作块:
- 输入1:VLM输出的多模态语义表征(明确“要做什么任务”,“当前环境的情况如何“);
- 输入2: q t q_t qt(机器人的本体感知状态,如关节角度,反映“机器人当前处于什么状态”);
- 输入3:噪声(流匹配的核心输入,用于建模连续动作的概率分布);
- 输出:连续动作块 [ a t , a t + 1 , . . . , a t + H ] [a_t, a_{t+1}, ..., a_{t+H}] [at,at+1,...,at+H](图中 H H H为动作块长度,π₀中 H = 50 H=50 H=50,即一次性生成50步连续动作)。
步骤4:跨机器人动作适配(图右侧)
动作专家生成的动作块,通过跨体化设计适配不同自由度(DoF)的机器人:
统一动作空间:将所有机器人的动作空间对齐为18DoF(适配双6DoF臂+移动基座+躯干);零样本适配:低自由度机器人(如7/8DoF单臂、14DoF双臂)的动作/状态向量,通过“零填充”补齐至18DoF;- 最终效果:单一模型可直接控制三类机器人(14DoF双臂、18DoF移动操作器、7/8DoF单臂),实现跨构型的通用控制。
π₀的核心工作流:用多模态输入明确“任务+场景+机器人状态”→用预训练VLM锚定语义目标→用动作专家生成连续动作块→用跨体化设计适配多类型机器人,最终实现“语言指令驱动+高灵巧动作+跨机器人通用”的控制目标。
3、架构与数学表示
π₀模型核心技术,实现VLM语义知识与流匹配连续动作生成的深度融合
聚焦架构设计、数学表征、训练机制、推理流程四大核心维度:
3.1、整体架构:VLM骨干+动作专家的混合专家(MoE)双权重架构(核心创新)
基础基底:基于PaliGemma(30亿参数开源VLM)初始化,采用VLM经典晚融合设计,机器人图像观测经编码器嵌入与语言令牌相同的空间,保留视觉-语言语义对齐能力。核心改造:新增3亿参数的动作专家模块,构建双权重集,令牌路由规则严格:- 图像、语言指令→走VLM骨干(复用预训练语义知识);
- 机器人本体感知状态(关节角度)、动作→走动作专家(从头初始化,定制化适配机器人任务)。
关键细节:两套权重仅通过Transformer自注意力层交互,既实现多源信息融合,又避免机器人专属输入干扰VLM预训练知识,杜绝分布偏移。
3.2、数学表征:观测与动作的统一端到端定义(训练/推理的基础)
所有符号为机器人控制任务定制,无冗余维度,核心定义:
- 观测: o t = [ I t 1 , . . . , I t n , ℓ t , q t ] o_t=[I_{t}^{1}, ..., I_{t}^{n}, \ell_{t}, q_{t}] ot=[It1,...,Itn,ℓt,qt]
- I t i I_{t}^{i} Iti:2-3张机器人RGB图像(每台机器人固定配置); ℓ t \ell_{t} ℓt:语言指令令牌序列; q t q_{t} qt:机器人关节角度等本体感知向量;
- 核心:将视觉、语言、本体状态三类异构输入统一表征,实现多模态端到端处理。
- 动作块: A t = [ a t , a t + 1 , . . . , a t + H − 1 ] A_{t}=[a_{t}, a_{t+1}, ..., a_{t+H-1}] At=[at,at+1,...,at+H−1]
- 固定 H = 50 H=50 H=50,模型一次性生成未来50步连续动作;
- 核心:动作块设计是实现50Hz高频率控制的关键,解决传统自回归VLA单步生成的低效率问题。
4、流匹配推理-前向欧拉积
前向欧拉积,是π₀流匹配推理的“去噪迭代工具”,通过10次小步长的向量场更新,把纯噪声的动作块逐步转化为真实的机器人连续动作块,既保证了动作生成的平滑性和精度,又实现了实时推理的效率要求,是连接训练好的模型与实际机器人控制的核心桥梁。
4.1、先明确公式与核心目标
π₀中前向欧拉积分是流匹配推理的核心计算方法,目的是通过小步迭代的方式,让纯噪声的动作块逐步去噪,最终生成符合任务要求的真实机器人连续动作块;
推理的核心是从 τ = 0 \tau=0 τ=0(动作块全是噪声)到 τ = 1 \tau=1 τ=1(动作块为真实无噪状态)的逐步更新,前向欧拉积分就是实现这一连续去噪过程的工程化公式,也是π₀能高效生成动作的关键。
π₀中前向欧拉积分核心公式:
A t τ + δ = A t τ + δ ⋅ v θ ( A t τ , o t ) A_{t}^{\tau+\delta}=A_{t}^{\tau}+\delta \cdot v_{\theta}\left(A_{t}^{\tau}, o_{t}\right) Atτ+δ=Atτ+δ⋅vθ(Atτ,ot)
4.2、公式逐符号拆解(π₀机器人推理场景专属)
所有符号均承接论文中观测、动作块、向量场的定义,物理意义直接对应机器人推理的实际过程:
| 符号/表达式 | 具体含义(π₀模型中) | 机器人推理的物理意义 |
|---|---|---|
| A t τ A_{t}^{\tau} Atτ | τ时刻的带噪动作块(τ∈[0,1]) | 推理迭代到第τ步时,仍带有噪声的机器人50步连续动作块;τ=0为初始纯噪声动作块,τ越接近1,噪声越少、越接近真实动作 |
| A t τ + δ A_{t}^{\tau+\delta} Atτ+δ | 迭代一步后(τ+δ时刻)的带噪动作块 | 用模型预测的去噪方向更新后,新的机器人动作块,比更新前更接近真实无噪状态 |
| δ \delta δ | 欧拉积分步长 | 每次迭代的“去噪步长”,π₀中固定 δ = 0.1 \boldsymbol{\delta=0.1} δ=0.1,是论文为平衡推理精度和推理效率的定制化设计 |
| v θ ( A t τ , o t ) v_{\theta}\left(A_{t}^{\tau}, o_{t}\right) vθ(Atτ,ot) | 模型预测的去噪向量场 | 模型根据当前τ时刻的带噪动作块和机器人实时观测 o t o_t ot,输出的动作去噪方向+幅度;简单说就是「模型告诉动作块:该往哪个方向调整、调整多少,才能去掉一点噪声」 |
| ⋅ \cdot ⋅ | 数乘运算 | 将步长δ与去噪向量场相乘,控制每次去噪的“力度”,避免单次调整幅度过大导致动作块偏离真实值 |
| + + + | 向量加法运算 | 将当前带噪动作块与δ倍的去噪向量场相加,得到更新后更接近真实值的动作块 |
4.3、公式的核心物理意义(贴合流匹配去噪逻辑)
前向欧拉积分是一种一阶数值积分方法,π₀将其用于流匹配推理,本质是把“从τ=0到τ=1的连续去噪过程”拆分为多个小步迭代,用“小步调整、逐步逼近”的方式,从纯噪声动作块生成真实动作块。
对应公式的物理意义,可以简单理解为:
新的带噪动作块 = 原来的带噪动作块 + 本次迭代的去噪调整量
其中「本次迭代的去噪调整量」= 积分步长δ × 模型预测的去噪向量场 v θ v_{\theta} vθ,
核心是通过固定小步长,让去噪过程平稳、可控,保证生成的机器人动作块连续、平滑、符合物理运动规律(避免动作跳变、机械臂抖动)。
4.4、推理步骤
上面的公式结合π₀的流匹配推理流程、推理效率优化形成完整的工程化方案,论文中固定为10步积分迭代(因δ=0.1,10步刚好从τ=0到τ=1),具体执行步骤与公式一一对应:
步骤1:推理初始化(τ=0)
从标准正态分布采样纯噪声动作块 A t 0 ∼ N ( 0 , I ) A_{t}^{0} \sim N(0, I) At0∼N(0,I),作为积分的初始值(此时动作块无任何有效信息,全是噪声);同时缓存机器人实时观测 o t o_t ot的注意力键值(K/V),为后续迭代提速。
步骤2:10次欧拉积分迭代(公式的核心执行,τ从0→1)
重复执行公式10次,每次迭代τ增加0.1(δ=0.1),直到τ=1,每次迭代仅重新计算动作块部分,观测部分复用缓存:
- 第1次迭代:τ=0,代入公式得 A t 0.1 = A t 0 + 0.1 ⋅ v θ ( A t 0 , o t ) A_{t}^{0.1}=A_{t}^{0} + 0.1 \cdot v_{\theta}(A_{t}^{0}, o_{t}) At0.1=At0+0.1⋅vθ(At0,ot);
- 第2次迭代:τ=0.1,代入公式得 A t 0.2 = A t 0.1 + 0.1 ⋅ v θ ( A t 0.1 , o t ) A_{t}^{0.2}=A_{t}^{0.1} + 0.1 \cdot v_{\theta}(A_{t}^{0.1}, o_{t}) At0.2=At0.1+0.1⋅vθ(At0.1,ot);
- ……
- 第10次迭代:τ=0.9,代入公式得 A t 1.0 = A t 0.9 + 0.1 ⋅ v θ ( A t 0.9 , o t ) A_{t}^{1.0}=A_{t}^{0.9} + 0.1 \cdot v_{\theta}(A_{t}^{0.9}, o_{t}) At1.0=At0.9+0.1⋅vθ(At0.9,ot)。
步骤3:输出真实动作块
迭代结束后,得到 τ = 1 \tau=1 τ=1时的无噪真实动作块 A t 1.0 A_{t}^{1.0} At1.0,将其输出给机器人,机器人按顺序执行块内的50步连续动作,完成一次推理。
4.5、π₀选择前向欧拉积分的核心原因(贴合机器人实时推理需求)
论文未选择更复杂的积分方法(如龙格-库塔),而是用前向欧拉积分,核心是为了适配机器人的实时控制要求,兼顾推理效率和工程实现难度,这也是π₀能实现73ms端到端推理的关键:
- 计算量极小:一阶数值积分,仅需简单的数乘+向量加法,无复杂运算,适配机器人实时推理的低延迟要求;
- 工程实现简单:易与π₀的注意力键值缓存结合,每次迭代仅更新动作块部分,大幅减少重复计算;
- 去噪过程平稳:固定小步长δ=0.1,10步慢迭代,保证动作块去噪过程平滑,生成的机器人动作连贯、无跳变,符合机械臂等机器人的物理运动规律;
- 精度足够:结合π₀的流匹配向量场 v θ v_{\theta} vθ的精准预测,一阶欧拉积分的精度完全能满足机器人50Hz高灵巧度控制的需求。
添加个插图,寓意流匹配的VLA起飞了

5、训练机制:条件流匹配
π₀采用条件流匹配损失,目的是让模型学会一个去噪向量场,能将带噪声的机器人动作块逐步还原为符合观测 o t o_t ot、满足任务要求的真实连续动作块;
损失的本质是:用均方误差量化「模型预测的去噪方向」和「客观真实的去噪方向」的差距,通过最小化这个差距,让模型掌握精准的连续动作生成能力。
核心公式:
L τ ( θ ) = E p ( A t ∣ o t ) , q ( A t τ ∣ A t ) ∥ v θ ( A t τ , o t ) − u ( A t τ ∣ A t ) ∥ 2 L^{\tau}(\theta)=\mathbb{E}_{p\left(A_{t} | o_{t}\right), q\left(A_{t}^{\tau} | A_{t}\right)}\left\| v_{\theta}\left(A_{t}^{\tau}, o_{t}\right)-u\left(A_{t}^{\tau} | A_{t}\right)\right\| ^{2} Lτ(θ)=Ep(At∣ot),q(Atτ∣At)∥vθ(Atτ,ot)−u(Atτ∣At)∥2
所有符号均对应π₀的观测、动作块、流匹配训练设计,物理意义直接贴合机器人控制:
| 符号/表达式 | 具体含义(π₀模型中) | 机器人场景的物理意义 |
|---|---|---|
| L τ ( θ ) L^\tau(\theta) Lτ(θ) | 流匹配**时间步 τ \tau τ**下的模型损失, θ \theta θ为模型所有可训练参数(VLM骨干+动作专家) | 衡量 τ \tau τ时刻,模型对机器人动作的去噪预测能力与真实去噪要求的差距 |
| E p ( A t ∣ o t ) , q ( A t τ ∣ A t ) \mathbb{E}_{p(A_t|o_t), q(A_t^\tau|A_t)} Ep(At∣ot),q(Atτ∣At) | 对两个分布求数学期望 1. p ( A t ∣ o t ) p(A_t|o_t) p(At∣ot):给定观测 o t o_t ot的真实机器人动作块分布 2. q ( A t τ ∣ A t ) q(A_t^\tau|A_t) q(Atτ∣At):真实动作块 A t A_t At在 τ \tau τ时刻的带噪分布 |
让损失在所有可能的观测-动作组合、所有流匹配阶段都最小,保证模型泛化性,避免过拟合单一机器人任务/场景 |
| ∥ ⋅ ∥ 2 \|\cdot\|^2 ∥⋅∥2 | 欧几里得范数的平方,即均方误差(MSE) | 适配机器人连续动作值(如关节角度、机械臂位移)的损失计算方式,替代离散化的交叉熵损失 |
| v θ ( A t τ , o t ) v_\theta(A_t^\tau, o_t) vθ(Atτ,ot) | 模型预测的去噪向量场 | 模型根据当前观测 o t o_t ot和带噪动作块 A t τ A_t^\tau Atτ,判断出的动作去噪方向+幅度(即“带噪动作该往哪调、调多少,才能接近真实动作”) |
| u ( A t τ ∣ A t ) u(A_t^\tau|A_t) u(Atτ∣At) | 真实的去噪向量场 | 由真实动作块 A t A_t At和其带噪版本 A t τ A_t^\tau Atτ推导的客观去噪方向+幅度(即“带噪动作要回到真实动作,实际需要怎么调”) |
| τ \tau τ | 流匹配时间步, τ ∈ [ 0 , 1 ] \tau \in [0,1] τ∈[0,1] | π₀中 τ = 0 \tau=0 τ=0→动作块全是高斯噪声; τ = 1 \tau=1 τ=1→动作块为真实无噪状态;训练覆盖 0 → 1 0 \to 1 0→1全阶段,让模型学会逐步去噪,生成平滑连贯的机器人动作 |
5.1、工程化简化(纯公式无法训练,π₀专属改造)
上述公式是理论形式,为适配机器人实时训练/推理,做了两大核心简化,直接推导出可计算的真实向量场 u u u和带噪动作块 A t τ A_t^\tau Atτ,这是公式能落地的关键:
简化1:固定线性高斯概率路径,定义 q ( A t τ ∣ A t ) q(A_t^\tau|A_t) q(Atτ∣At)
π₀指定带噪动作块的分布为正态分布:
q ( A t τ ∣ A t ) = N ( τ A t , ( 1 − τ ) I ) q(A_{t}^{\tau} | A_{t})=N(\tau A_{t},(1-\tau) I) q(Atτ∣At)=N(τAt,(1−τ)I)
- 均值 τ A t \tau A_t τAt:τ越大,带噪动作块越接近真实动作块;
- 方差 ( 1 − τ ) I (1-\tau)I (1−τ)I:τ越大,动作块的噪声越小;
- I I I为单位矩阵,保证噪声在动作的各个维度独立。
简化2:推导出可直接计算的 A t τ A_t^\tau Atτ和 u ( A t τ ∣ A t ) u(A_t^\tau|A_t) u(Atτ∣At)
基于上述分布,通过采样标准高斯噪声 ϵ ∼ N ( 0 , I ) \epsilon \sim N(0, I) ϵ∼N(0,I),将带噪动作块和真实去噪向量场简化为显式计算公式,也是π₀训练中实际使用的形式:
- 带噪动作块: A t τ = τ A t + ( 1 − τ ) ϵ \boldsymbol{A_t^\tau = \tau A_t + (1-\tau)\epsilon} Atτ=τAt+(1−τ)ϵ
- 真实去噪向量场: u ( A t τ ∣ A t ) = ϵ − A t \boldsymbol{u(A_t^\tau|A_t) = \epsilon - A_t} u(Atτ∣At)=ϵ−At
5.2、π₀的实际训练三步法
结合上述简化,π₀将条件流匹配的公式损失,转化为可工程实现的训练流程,公式是理论依据,三步法是实际操作,一一对应:
- 采样基础数据:从真实分布 p ( A t ∣ o t ) p(A_t|o_t) p(At∣ot)采样「观测 o t o_t ot-真实动作块 A t A_t At」对;随机采样标准高斯噪声 ϵ ∼ N ( 0 , I ) \epsilon \sim N(0,I) ϵ∼N(0,I),并从贝塔分布采样流匹配时间步 τ \tau τ(π₀侧重低τ/高噪声,贴合机器人动作预测特性);
- 计算带噪样本与真实目标:用简化公式计算 A t τ A_t^\tau Atτ(带噪动作块)和 u u u(真实去噪向量场);
- 计算损失并更新参数:将 A t τ A_t^\tau Atτ和 o t o_t ot输入π₀模型,得到预测向量场 v θ v_\theta vθ;代入核心公式计算损失 L τ ( θ ) = ∥ v θ − u ∥ 2 L^\tau(\theta)=\|v_\theta - u\|^2 Lτ(θ)=∥vθ−u∥2,通过梯度下降最小化损失,更新模型参数 θ \theta θ。
5.3、π₀选择条件流匹配损失的核心原因(贴合机器人控制需求)
相比传统VLA模型的自回归交叉熵损失,该损失完全适配π₀50Hz高灵巧度连续动作控制的目标:
- 适配连续动作:机器人控制为连续值输出,MSE损失比离散化的交叉熵更贴合,无需将动作拆分为令牌;
- 保证动作平滑性:逐步去噪的训练方式,让π₀生成的50步动作块连贯无跳变,符合机器人物理运动规律;
- 提升鲁棒性:加噪-去噪的训练逻辑,让模型能应对真实场景中的微小扰动(如物体位置偏移、机械臂微小误差);
- 支持动作块生成:可一次性建模50步连续动作的分布,实现50Hz高频率控制,解决自回归单步生成的低效率问题。
6、模型效果
采用的机器人(包含 6-7 自由度的单 / 双臂操作器、全向与非全向移动操作器),π₀在这些不同构型的平台上开展了联合训练
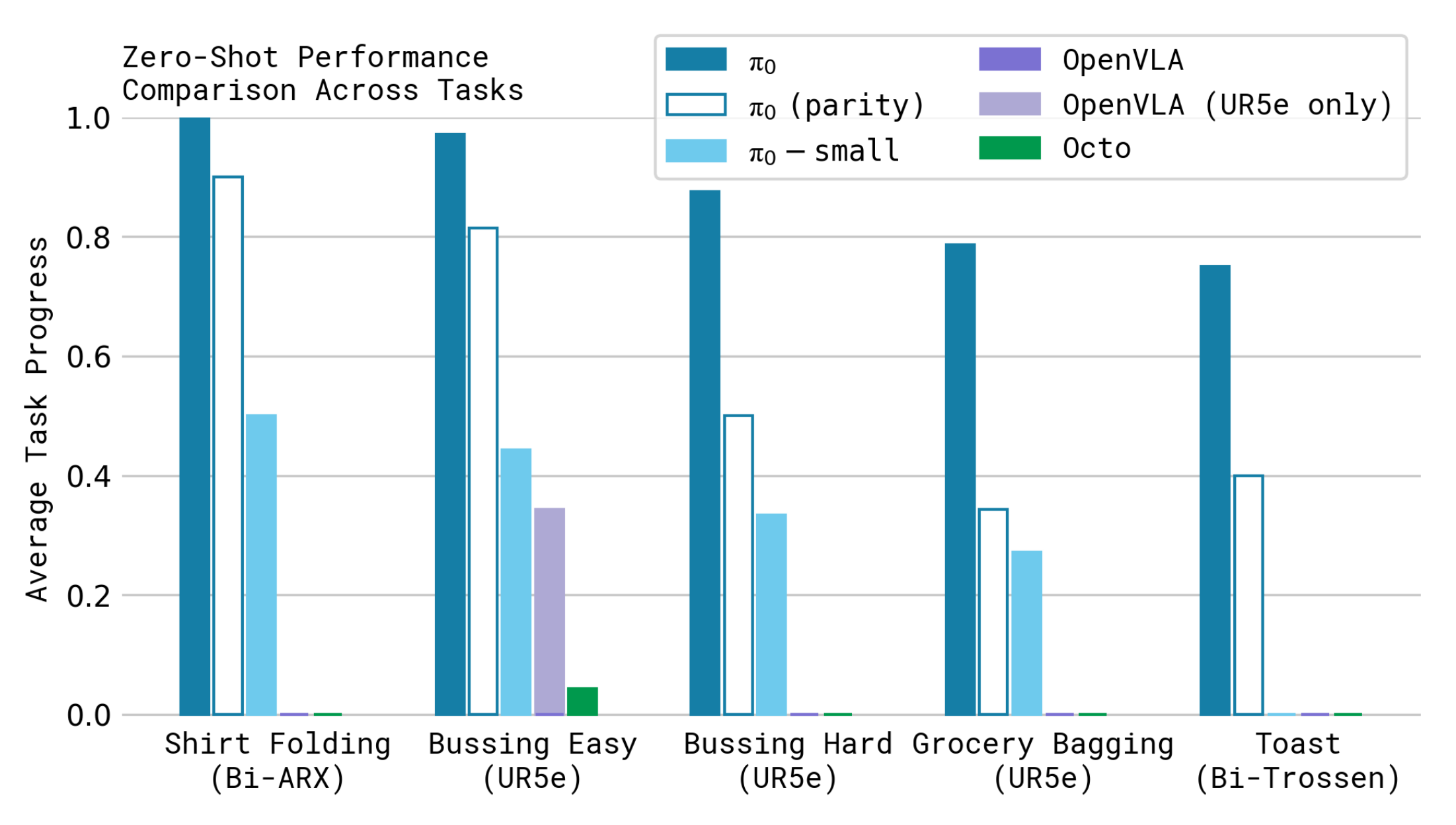
如下图所示,零样本评估结果:
- 评估了三类模型:训练完整 70 万步的 π₀、训练 16 万步的版本(其更新次数与基线模型一致)、π₀-small,以及三个基线模型
分享完成~

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 17
17 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)