多模态大语言模型发展历程
一、早期探索阶段(2017-2020):奠基与探索
多模态大语言模型的历史根植于深度学习在自然语言处理(NLP)和计算机视觉(CV)两大领域的独立突破。2017年Vaswani等人提出的Transformer架构以其强大的并行计算能力和对长距离依赖的建模优势彻底改变了NLP领域。这一成功激发了研究者们将其扩展到多模态领域的雄心。这一时期的核心议题是:如何有效地融合基于Transformer的语言理解能力与视觉表示以解决跨模态的理解任务。因此这一阶段可以被视为多模态大语言模型的奠基与探索期其主要特征是双流架构的流行和对比学习的萌芽。
1、视觉-语言模型的起源:双流架构的探索
在Transformer的启发下第一批真正意义上的视觉-语言预训练模型(Vision-Language Pre-training,VLP)在2019年集中涌现。其中的代表性工作是ViLBERT和LXMERT。这些模型开创性地采用了双流(Two-Stream)架构。其核心思想是为视觉和文本模态分别设置独立的Transformer编码器以充分学习各自模态内的特征然后再通过一个跨模态(Cross-Modal)Transformer编码器进行深度融合。
以LXMERT为例其架构包含一个对象关系编码器(基于Faster R-CNN提取的区域特征)、一个语言编码器和一个跨模态编码器。这种设计允许模型在融合前对每个模态进行独立的上下文建模。
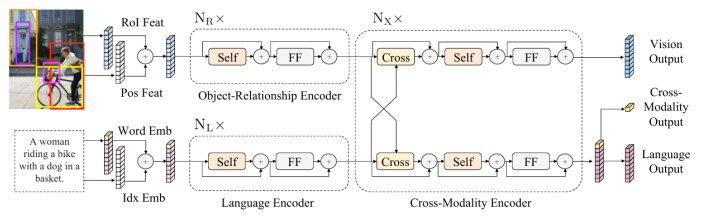
为了训练这些复杂的模型研究者们设计了一系列新颖的预训练任务。这些任务借鉴了NLP领域的成功经验(如BERT的掩码语言模型)并将其扩展到多模态场景。常见的任务包括:
掩码多模态建模(Masked Multi-Modal Modeling):随机掩盖输入文本中的部分单词或图像中的部分区域特征然后让模型根据剩余的上下文进行预测。这迫使模型学习模态内部和模态之间的细粒度关联。
跨模态对齐预测(Cross-Modal Alignment Prediction):向模型输入一对图像和文本让其判断两者是否匹配。这个任务旨在让模型学习更高层次的图文语义对应关系。
这些早期的双流模型在多个下游视觉-语言任务(如视觉问答VQA、视觉常识推理VCR、图文检索)上取得了显著的性能提升证明了大规模跨模态预训练的有效性。然而它们也存在明显的局限:复杂的网络结构导致计算成本高昂且模态间的交互仅发生在顶层的融合模块限制了更深层次的特征融合。
2、跨模态对齐的突破:CLIP与对比学习
双流模型证明了跨模态预训练的可行性OpenAI在2021年初发布的CLIP(Contrastive Language-Image Pre-training)则彻底改变了该领域的游戏规则。CLIP的贡献是革命性的它摒弃了复杂的融合模块和像素级的预测任务转而采用一种更为简洁、高效且可扩展的对比学习(Contrastive Learning)范式。
CLIP的核心思想是:直接从互联网上收集的海量(4亿)图文对数据中学习一种统一的跨模态嵌入空间。它包含一个图像编码器和一个文本编码器。
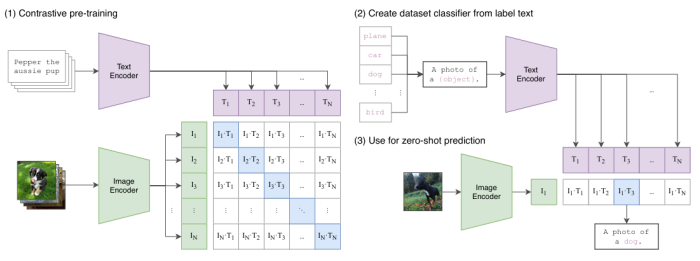
在训练过程中对于一个批次内的N个图文对模型的目标是正确地将N个图像与其对应的N个文本描述匹配起来同时将不匹配的N²-N个组合推开。通过这种方式CLIP学习到的视觉特征与自然语言在语义上深度对齐。
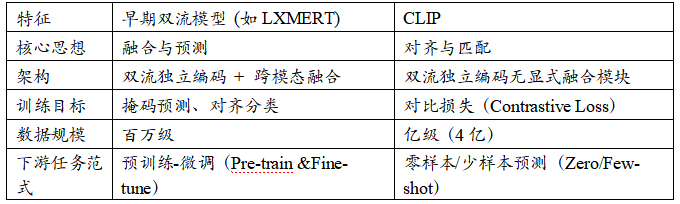
表2:早期双流模型与CLIP的对比
CLIP最惊人的能力在于其强大的零样本泛化能力。由于其视觉概念是与自然语言直接关联的因此无需任何微调就可以通过构建文本提示(如“一张...的照片”)来完成任意视觉分类任务其性能甚至超过了在特定数据集上监督训练的ResNet模型。这一突破打破了长期以来“预训练-微 调”的范式为后续的多模态大语言模型发展指明了新的方向:即利用海量自然监督信号通过对比学习构建一个统一的、可泛化的多模态语义空间。
3、技术局限与挑战
尽管取得了显著进展但这一早期探索阶段的多模态模型仍面临诸多挑战这些挑战也预示了未来的研究方向:
生成能力的缺失:无论是双流模型还是CLIP其设计都主要面向理解任务。它们能够判断图文是否匹配或对图像进行分类但无法根据文本描述生成一张全新的图像。这种生成能力的缺失是该阶段模型最大的局限。
模态融合的深度不足:双流模型虽然有跨模态融合模块但融合发生在较高层次限制了模态间更底层的交互。而CLIP则完全没有显式的融合机制其对齐是“全局”而非“局部”的难以处理需要细粒度对应关系的任务(如视觉定位)。
对高质量标注数据的依赖:早期的VLP模型依赖于经过清洗和标注的数据集(如COCO,Visual Genome)规模受限。虽然CLIP使用了更大规模的带噪声网络数据但如何有效利用这些数据以及数据偏见带来的问题仍是悬而未决的挑战。
计算资源的巨大消耗:双流架构的复杂性和大规模预训练的需求使得这些模型的训练成本极高只有少数大型研究机构能够承担阻碍了更广泛的研究和应用。
总而言之2017年至2020年的早期探索阶段成功地将Transformer架构引入多模态领域并通过双流架构和对比学习两种不同的路径验证了大规模预训练在视觉-语言任务上的巨大潜力。特别是CLIP的出现为后续研究奠定了“对齐”这一核心思想。然而生成能力的缺失和模态融合的浅层性等问题也为下一阶段的技术突破埋下了伏笔。
二、快速发展阶段(2021-2023):LLM驱动的范式革命
进入2021年尤其是在2022年末ChatGPT发布之后大型语言模型(LLMs)展现出的强大零样本学习、指令遵循和上下文学习能力为整个人工智能领域带来了深刻的范式革命。多模态领域迅速捕捉到这一变革信号研究重心从“从零开始设计复杂的跨模态融合架构”转向“如何将强大的预训练LLM适配到多模态任务中”。这一阶段的核心特征是LLM作为多模态智能的核心以及视觉指令微调(Visual Instruction Tuning)成为主流技术路线。
1、大语言模型的崛起及其对多模态的启发
GPT-3的发布及其后续模型的演进揭示了一个关键事实:当模型规模足够大并在海量文本数据上进行预训练后会涌现出惊人的泛化能力。模型不再仅仅是学习语言的统计规律而是开始具备一定程度的常识推理和世界知识。这为多模态研究者提供了新的思路:与其构建复杂的专用模型不如利用LLM已经具备的强大推理和语言能力仅需教会它“看懂”图像即可。
这一思路的转变带来了几个关键优势:
继承LLM的强大能力:可以直接利用LLM的语言生成、代码理解、逻辑推理等高级能力并将其自然地迁移到多模态对话和任务中。
简化架构设计:无需再设计复杂的跨模态融合模块只需一个轻量级的“适配器”将视觉特征连接到LLM即可。
提升数据效率:由于LLM已经经过大规模预训练多模态的训练过程可以更聚焦于学习“对齐”从而降低对海量图文对数据的依赖。
2、视觉-语言预训练的突破:BLIP系列的演进
在将LLM与视觉模态结合的道路上Salesforce研究院的BLIP系列工作扮演了至关重要的角色。它们通过一系列创新的架构和预训练任务高效地实现了视觉模态与语言模型的对齐。
BLIP(2022):针对网络图文对数据中普遍存在的噪声问题BLIP提出了一种多模态混合编码器(Multimodal Mixture of Encoder-Decoder,MED)并设计了“字幕与过滤”(Captioning and Filtering,CapFilt)机制能够自动生成高质量的字幕并过滤掉噪声数据显著提升了预训练的效率和效果。
BLIP-2(2023):BLIP-2是这一阶段的标志性工作。
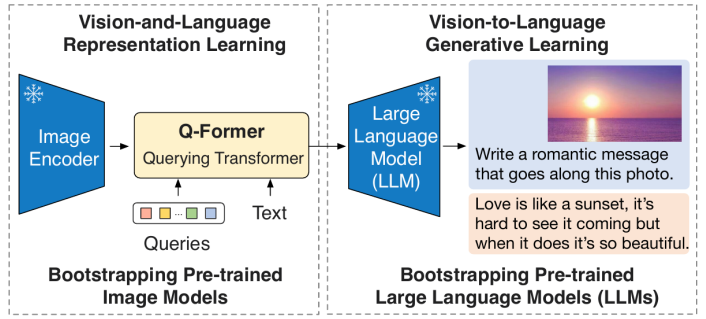
它提出了一个名为Q-Former(Querying Transformer)的轻量级对齐模块。Q-Former充当了冻结的视觉编码器(如CLIP ViT)和冻结的LLM之间的“桥梁”。它通过一小组可学习的查询向量从视觉编码器中提取与文本最相关的视觉特征然后将这些精炼后的特征输入给LLM。这种“冻结主干只训练适配器”的设计极大地降低了训练成本使得在消费级硬件上训练强大的多模态模型成为可能。BLIP-2的成功为后续几乎所有的视觉指令微调工作奠定了架构基础。
3、多模态指令微调的兴起:LLaVA的开创性工作
BLIP-2提供了高效的架构LLaVA(Large Language and Vision Assistant)则开创了高效的训练方法。
2023年4月发布的LLaVA首次将LLM领域的“指令微调”(Instruction Tuning)概念成功地引入多模态领域。
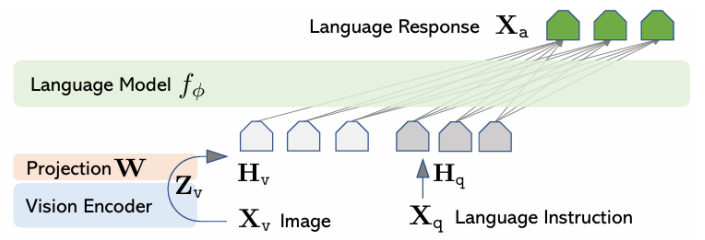
LLaVA的洞察非常简洁:人类是通过语言指令与世界交互的那么也应该通过指令来教模型理解图像。其核心贡献在于构建了一个名为LLaVA-Instruct-158K的数据集。该数据集利用GPT-4强大的API将COCO数据集中已有的图像标注(如边界框、描述)转化为更丰富的多轮对话或问答形式。例如对于一张包含“一只猫在沙发上”的图像GPT-4可以生成诸如“这张图里有什么?”、“猫是什么颜色的?”、“它在做什么?”等一系列指令和回答。
LLaVA的训练过程分为两个简单的阶段:
特征对齐阶段:使用简单的图文对数据训练一个线性投影层将CLIP视觉编码器的输出映射到LLM的词嵌入空间实现初步的模态对齐。
指令微调阶段:使用LLaVA-Instruct-158K数据集对整个模型(包括LLM部分)进行端到端的微调教会模型遵循指令进行多模态对话。
LLaVA以其简洁的架构、高效的训练方法和令人印象深刻的对话能力迅速引爆了开源社区。它证明了即使使用相对较小规模的指令数据也能“解锁”LLM在多模态场景下的强大能力。一时间基于LLaVA进行改进和扩展的工作层出不穷如InstructBLIP、MiniGPT-4等共同推动了多模态指令微调技术的成熟。
4、开源生态的繁荣
这一阶段的快速发展离不开开源社区的巨大推动力。特别是Meta在2023年发布的LLaMA系列模型其卓越的性能和开放的许可证为研究者们提供了一个强大的、可自由修改的LLM基座。这一时期几乎所有主流的开源多模态模型(包括LLaVA、MiniGPT-4等)都是基于LLaMA构建的。这形成了一个良性循环:强大的开源LLM基座降低了多模态研究的门槛而涌现出的优秀多模态模型又进一步丰富了LLM的生态吸引了更多开发者投身其中。
总结而言2021年至2023年是多模态技术由LLM驱动、发生范式革命的快速发展阶段。以BLIP-2的Q-Former架构和LLaVA的指令微调方法为两大支柱研究者们找到了一条将LLM的强大能力高效迁移到多模态场景的康庄大道。开源生态的繁荣则为这场技术革命提供了源源不断的动力。然而这一阶段的模型大多仍停留在“看懂”和“描述”的层面如何实现更高级的“生成”和“全模态”处理成为了下一阶段亟待解决的核心问题。
三、统一建模阶段(2024):走向理解与生成的融合
随着多模态指令微调技术的成熟研究界的目光在2024年转向了一个更具挑战性的目标:在单一模型内统一多模态的理解与生成能力。此前理解任务(如VQA)和生成任务(如文生图)通常由不同的模型负责。这一阶段的核心议题是打破两者之间的壁垒构建能够“既看懂又会画”的统一模型。这一时期的探索呈现出多样化的技术路径主要特征是早期融合架构的尝试、混合生成范式的出现以及全模态模型的初步探索。
1、理解与生成的统一尝试:Chameleon与VITRON
2024年5月Meta AI发布的Chameleon是这一阶段的开创性工作。它大胆地提出了一种早期融合(Early-fusion)的思路。与此前主流的“晚期融合”(即先分别编码再连接)不同Chameleon在模型的最底层就将图像和文本转换为统一的离散Token序列然后将这些混合模态的Token序列直接输入到一个标准的、仅包含解码器(Decoder-only)的LLM中进行处理。这种设计的优势在于它最大程度地保留了LLM的原始架构理论上可以实现更深层次的模态交互。
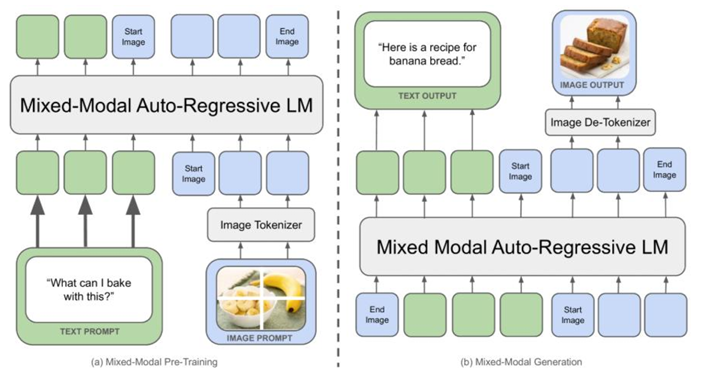
Chameleon通过一个新颖的图像分词器(Image Tokenizer)将图像转换为离散的Token其方式类似于文本的分词。这使得图像和文本可以在同一个序列中被LLM无差别地处理从而自然地统一了理解(模型根据图文上下文预测文本Token)和生成(模型根据图文上下文预测图像Token)任务。
几乎在同一时期来自昆仑万维、新加坡国立大学、新加坡南洋理工大学团队的研究者们发布了VITRON提出了另一种统一建模的思路。VITRON的核心是统一的像素级视觉表示。
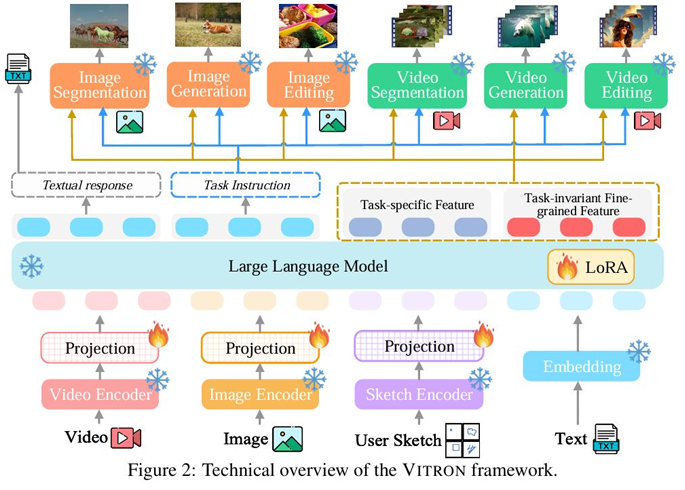
它将各种视觉任务无论是高级语义理解(如VQA)还是低级像素处理(如图像分割、编辑)都统一为“像素到像素”的生成任务。通过这种方式VITRON在单一模型内实现了对图像的理解、生成、分割和编辑四大核心能力展现了强大的通用视觉能力。
2、混合生成范式的出现:Show-o的探索
在探索统一建模的过程中如何平衡生成质量、速度和多样性成为一个关键挑战。传统的自回归(Autoregressive,AR)模型虽然在文本生成上表现出色但在图像生成上存在速度慢、容易出现重复性伪影等问题。而扩散模型(Diffusion Models)虽然生成质量高但推理速度又是一大瓶颈。
为了解决这一问题Show-o提出了一种创新的混合生成范式。
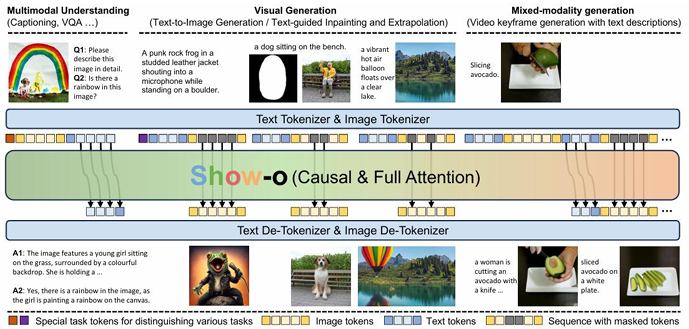
它巧妙地将自回归模型和离散扩散模型结合在同一个统一的Transformer架构中。在生成图像时模型首先以自回归的方式快速生成一个全局的、低分辨率的草图(或称之为“计划”)然后再利用离散扩散模型对这个草图进行逐步的细化和高清化。这种“先规划后细化”的策略既利用了自回归模型在结构化预测上的优势又发挥了扩散模型在细节纹理生成上的长处实现了生成质量和效率的有效平衡。Show-o的成功为后续的生成模型发展开辟了新的思路即不同生成范式并非相互排斥而是可以协同工作的。
3、全模态模型的萌芽
在视觉-语言统一建模取得进展的同时研究者们也开始将目光投向更广阔的“全模态”领域即在模型中进一步整合音频(Audio)和视频(Video)模态。这一时期的探索尚处于萌芽阶段主要通过在现有视觉-语言模型的基础上进行扩展。
例如一些工作开始尝试将音频频谱图(Spectrogram)作为一种特殊的“图像”输入给模型从而利用已有的视觉编码器来处理音频信号。对于视频则通常采用采样关键帧并将其作为多张图像输入的方式进行处理。这些早期的尝试虽然在架构上略显“朴素”但它们验证了将更多模态纳入统一LLM框架的可行性为2025年全模态模型的爆发积累了宝贵的经验。
4、工业界的激烈竞争:GPT-4V与Gemini
2024年也是工业界巨头在多模态领域激烈竞争的一年。OpenAI正式向公众发布了其强大的多模态模型GPT-4V(ision)其在复杂的视觉推理、OCR和少样本学习任务上展现出的惊人能力为整个领域树立了新的标杆。紧随其后Google也发布了其原生多模态模型Gemini系列特别是其旗舰版本Gemini Ultra在多个多模态基准测试中都表现出与GPT-4V相媲美甚至超越的性能。这两大闭源模型的发布一方面展示了多模态技术巨大的商业潜力另一方面也激发了开源社区更大的追赶热情形成了“闭源引领开源追赶”的竞争格局。
总结来说2024年是多模态技术从“分离”走向“统一”的关键一年。研究者们通过早期融合、混合生成范式等多种路径成功地在单一模型内实现了理解与生成的统一。同时对音频、视频等更多模态的整合也开始萌芽。工业界巨头的入场则进一步加速了技术的成熟和应用落地。然而这一阶段的统一模型在架构上仍有待完善生成质量和效率仍有提升空间这些都为2025年更深层次的技术变革创造了契机。
四、全模态爆发阶段(2025):迈向“全能”与“实时”
2024年是统一建模的探索年2025年则是多模态技术全面爆发、走向“全能”与“实时”的一年。在这一年里技术演进的核心驱动力从“如何在单一模型中统一理解与生成”转向“如何更高效、更高质量地统一所有主流模态并实现流畅的实时交互”。一系列具有里程碑意义的工作集中涌现它们在模型架构、生成范式和应用体验上都取得了质的飞跃。这一阶段的主要技术特征是解耦设计的成熟、流模型的崛起、原生全模态架构的实现以及交错生成能力的突破。
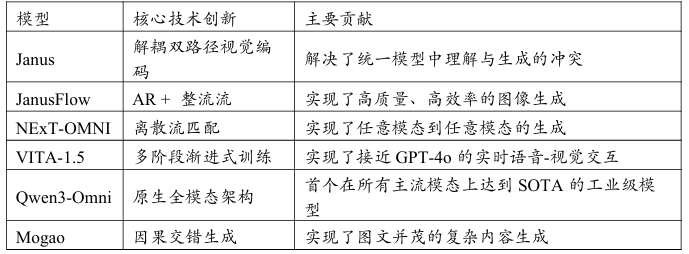
1、解耦设计的突破:Janus的启示
2024年末由DeepSeek、香港大学、北大联合团队提出的Janus模型为解决早期融合架构(如Chameleon)中存在的理解与生成能力难以兼顾的问题提供了全新的“解耦设计”(Decoupled Design)思路。Janus的核心洞察是:视觉理解任务需要的是全局、抽象的语义信息而视觉生成任务则更需要局部、精细的像素级细节。将两者耦合在同一个视觉编码路径中必然会导致性能上的妥协。
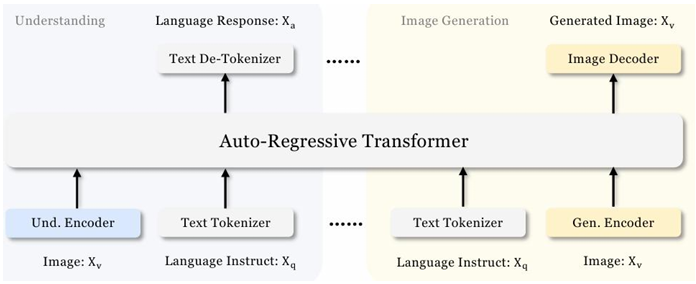
为此Janus创新性地设计了双路径视觉编码器:
理解路径(Understanding Path):使用一个类似于CLIP的视觉编码器将图像编码为一组紧凑的、蕴含高级语义的特征向量专门用于VQA、图像描述等理解任务。
生成路径(Generation Path):使用一个VQ-VAE等图像分词器将图像转换为离散的、保留了丰富空间细节的视觉Token专门用于图像生成和编辑任务。
这两条路径的输出被同时输入到LLM中。LLM可以根据当前任务的需要自主选择关注来自哪条路径的视觉信息。这种解耦设计使得模型的理解和生成能力可以得到独立的、更充分的优化从而在两大类任务上都取得了当时的最先进性能。Janus的设计理念迅速被后续的许多工作所借鉴成为2025年高性能多模态模型的主流架构思想。
2、流模型的崛起:JanusFlow与NExT-OMNI
在生成范式上2025年见证了流模型(Flow Models)的全面崛起。相比于需要多次迭代去噪的扩散模型流模型旨在学习一个能够将简单的高斯噪声分布一步或数步映射到复杂数据分布的常微分方程(ODE)。
JanusFlow:作为Janus的后续工作JanusFlow将整流流(Rectified Flow)这一新兴的流模型技术引入多模态生成。它通过一种巧妙的方式协调了自回归(AR)模型和整流流。在生成时模型首先以AR方式生成一个“草稿”然后利用整流流进行一次或几次精炼即可得到高质量的图像。这种“AR + Flow”的混合范式在保持高质量的同时显著提升了推理速度通常只需1-8个采样步骤即可完成生成远快于扩散模型动辄数十上百步的采样。
NExT-OMNI:该工作则探索了另一种更前沿的流模型技术——离散流匹配(Discrete Flow Matching)。它将所有模态(文本、图像、音频、视频)都统一为离散的Token序列然后通过学习这些Token序列之间的流场变换实现了“任意模态到任意模态”(Any-to-Any)的生成。NExT-OMNI是首个能够处理四种主流模态并实现任意转换的统一模型代表了全模态生成技术的前沿方向。
3、实时交互的实现:VITA-1.5的突破
在提升用户体验方面实现流畅的实时交互是2025年的一个核心目标。VITA-1.5在这方面取得了重大突破。
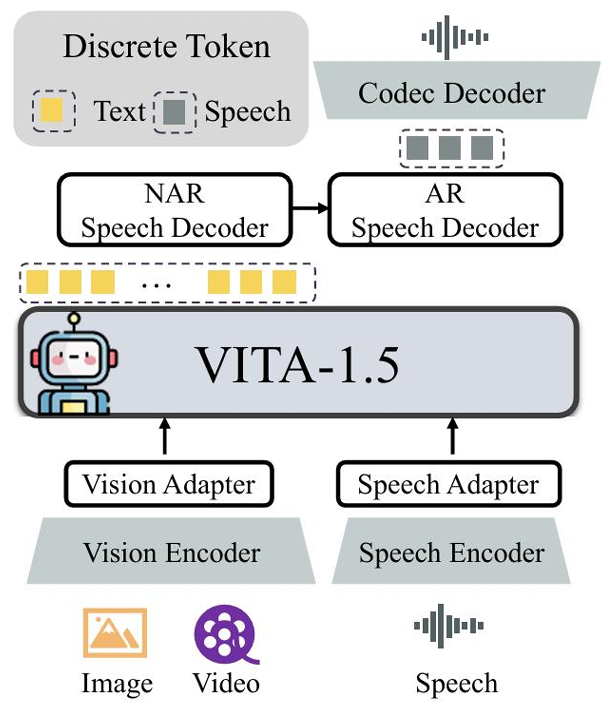
该模型通过精心设计的多阶段渐进式训练方法成功地将视觉和语音信息高效地整合到一个LLM中。其最引人注目的成就是实现了接近GPT-4o水平的实时视觉-语音交互能力。用户可以向模型流式地输入语音指令同时展示摄像头捕捉到的实时画面模型能够即时地理解并作出语音回应延迟极低。这一突破极大地提升了多模态模型的实用性使其有望成为真正的个人智能助手。
4、原生全模态的成熟:Qwen3-Omni的工业级实现
阿里巴巴在2025年9月发布的Qwen3-Omni代表了原生全模态(Natively Omni-Modal)技术在工业界的成熟落地。与那些依赖外部工具或模块拼接的模型不同Qwen3-Omni在一个统一的、端到端的架构内原生支持文本、图像、音频、视频四种模态的输入和输出。
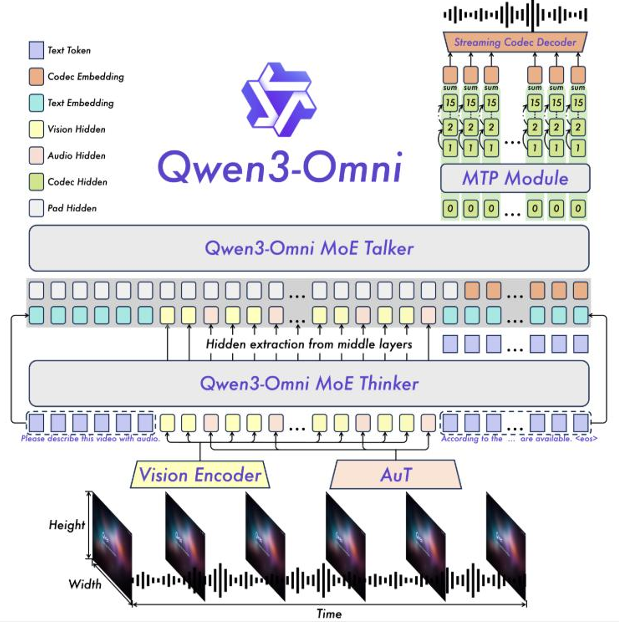
据其技术报告显示Qwen3-Omni是首个在所有四种模态的主流基准测试上全面达到最先进性能的单一模型。这标志着全模态技术已经从理论走向实践具备了构建强大、可靠的商业应用的基础。
5、交错生成的创新:Mogao的涌现能力
除了处理单一模态的输入输出2025年的另一个重要进展是交错多模态生成(Interleaved Multi-Modal Generation)。Mogao在这方面做出了开创性贡献。
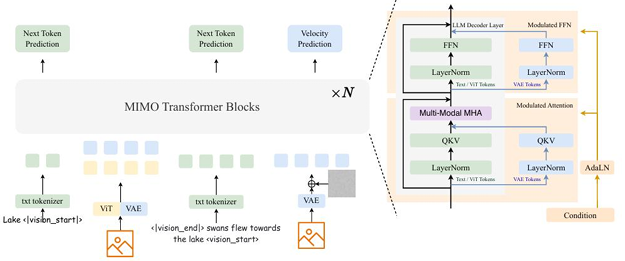
它能够生成包含文本、图像等多种模态交错出现的内容序列例如生成一篇图文并茂的博客文章。Mogao通过一种基于因果建模的方法实现了这一能力并且展现出了令人惊奇的“涌现能力”如零样本的图像编辑和组合生成。这种能力使得AI不再仅仅是任务执行的工具更有可能成为内容创作的合作伙伴。
表3:2025年代表性多模态大语言模型技术特征
6、多模态走进物理世界
具身智能是2025年最激动人心的应用方向。VLA“视觉-语言-动作”(Vision-Language-Action, VLA)模型通过统一视觉、语言和动作数据,使机器人能够跨任务、跨具身形态、跨环境泛化。OpenVLA作为首个完全开源、可商用的VLA模型,在2024年6月发布后迅速成为机器人研究的基础模型。
7、国内代表性模型的崛起与特色
在2025年全球多模态技术浪潮中 ,中国科技力量同样取得了举世瞩目的成就,涌现出一批具有鲜明技术特色和强大实力的代表性模型。这些模型不仅在性能上追赶甚至超越了国际顶尖水平,更在架构设计和应用场景上展现了独特的创新思路。
深度求索DeepSeek-OCR:DeepSeek-AI另辟蹊径,从“光学压缩”这一独特视角切入,推出了DeepSeek-OCR。该模型的核心创新在于将高分辨率的文档页面高效压缩为极少量的视觉token,再由一个轻量级的MoE语言模型进行解码。这种“视觉作为压缩介质”的范式,在保证高精度OCR的同时,将处理长文档的token开销降低了7-20倍,为解决LLM的长上下文难题提供了一条极具潜力的技术路径。
通义千问Qwen3-VL:阿里巴巴发布的Qwen3-VL系列 是其中的佼佼者。它不仅在传统的图文理解任务上表现出色,更通过增强的交错MRoPE和DeepStack等架构创新,实现了对长视频和复杂文档的深度理解。其原生支持256K的交错上下文处理能力,使其在长视频问答、文档分析等场景中具备显著优势,标志着国内模型在长上下文多模态处理能力上达到了新的高度。
文心5.0原生全模态:百度发布的文心5.0是中国首个真正意义上的“原生全模态”大模型。其核心理念是从训练伊始就将文本、图像、音频、视频等所有主流模态置于统一架构下进行联合建模,而非后期“拼接”。这种原生设计使得模型能够在底层形成跨模态的内在关联,从而在全模态的理解与生成任务上展现出更强的协同效应和一致性。其高达2.4万亿的参数规模和超稀疏激活的MoE架构,也代表了国内在大模型规模化探索上的最新成果。
智源Emu3.5:北京智源人工智能研究院(BAAI)开源的Emu3.5则将多模态模型的能力边界从“理解世界”推向了“模拟世界”。作为一个大规模多模态世界模型,Emu3.5不仅能处理交错的视文输入输出,更重要的是能够原生预测世界的下一个状态,展现出时空一致的世界探索和开放世界具身操作的能力。其提出的DiDA(离散扩散适配)技术,在不牺牲性能的前提下将推理速度提升20倍,为世界模型的实际应用扫清了障碍。
这些模型的涌现,不仅丰富了全球多模态技术生态,也展示了中国在AI核心技术领域的深厚积累和创新活力。它们在不同技术路线上进行的探索,共同推动了多模态技术向着更高效、更通用、更智能的方向发展。
综上所述,2025年是多模态大语言模型技术发展史上承前启后、全面爆发的一年。在这一年里模型架构、生成范式和交互体验都迈上了新的台阶。解耦设计解决了核心的性能瓶颈流模型提供了更优的生成方案而实时交互和原生全模态的实现则宣告了“全能AI助手”时代的曙光。
本报告共计分为“序言、多模态大语言模型发展历程、核心技术架构与训练方法的进化、数据来源与评估基准、应用场景与实践、当前挑战与未来展望”六大部分内容。本文为“多模态大语言模型发展历程”内容节选。
完整版报告,请扫描下方二维码下载。

END

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 9
9 0
0- 0



 已为社区贡献48条内容
已为社区贡献48条内容

所有评论(0)