TGRPO:通过轨迹 GRPO 微调 VLA 模型
25年6月来自吉林大学的论文“TGRPO: Fine-tuning Vision-Language-Action Model via Trajectory-wise Group Relative Policy Optimization“。视觉-语言-动作 (VLA) 模型的最新进展已在大规模数据集上进行预训练,展现出跨多种场景、任务和机器人平台的强大泛化能力。然而,这些模型在新环境中仍然需要针对特
25年6月来自吉林大学的论文“TGRPO: Fine-tuning Vision-Language-Action Model via Trajectory-wise Group Relative Policy Optimization“。
视觉-语言-动作 (VLA) 模型的最新进展已在大规模数据集上进行预训练,展现出跨多种场景、任务和机器人平台的强大泛化能力。然而,这些模型在新环境中仍然需要针对特定任务进行微调,而这一过程几乎完全依赖于使用静态轨迹数据集的监督微调 (SFT)。此类方法既不允许机器人与环境交互,也无法利用实时执行的反馈。此外,它们的成功与否关键取决于所收集轨迹的大小和质量。强化学习 (RL) 通过实现闭环交互并将学习的策略与任务目标直接对齐,提供了一种颇具前景的替代方案。本研究借鉴 GRPO 的思想,提出了基于轨迹的组相对策略优化 (TGRPO) 方法。通过融合步级和轨迹级优势信号,该方法改进 GRPO 的组级优势估计,从而使该算法更适用于 VLA 的在线强化学习训练。
TGRPO 概述如图所示:
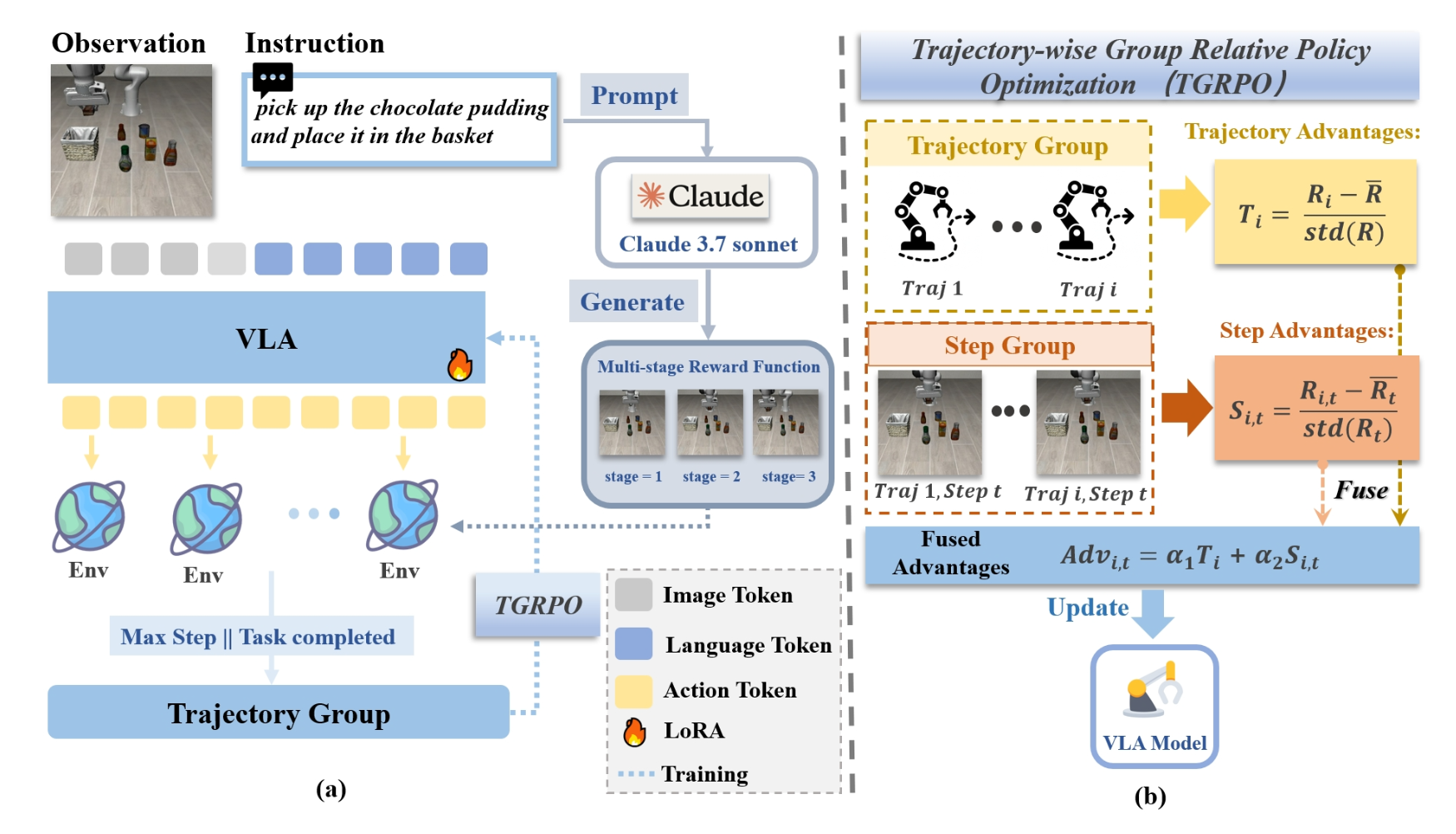
先前的研究,例如 GRAPE [38] 和 ConRFT [7],已经利用强化学习来微调 VLA,并在此领域做出了重大贡献。然而,ConRFT 需要两阶段训练和额外的人工参与,而本文方法更加端到端,无需人工干预。GRAPE 与本文工作更相似,但它更类似于离线训练:它首先收集大量轨迹,然后使用类似于直接策略优化 (DPO) [30] 的方法进行训练。这导致用于数据采样的模型和用于训练的模型之间存在显著差异。相比之下,本文方法中数据收集和训练之间的更快交替确保了模型训练与实时环境更加一致,使其更适合在线训练。本文主要在 LIBERO 模拟环境 [21] 中进行评估,并使用 OpenVLA 作为 VLA 模型。与 GRAPE 类似,首先在相应的任务数据集上使用经过 LoRA 微调 [15] 的 OpenVLA 权重,然后基于这些权重进行 TGRPO 训练。由于 GRAPE 采用迭代训练,而本文通过与环境的在线交互直接训练 VLA,因此训练效率是 GRAPE 的两到三倍。此外,在 LIBERO-Object 的 10 个任务中,该方法优于基线。
群体相对策略优化 (GRPO)
整体工作基于 GRPO(群体相对策略优化)[33]。DeepSeek R1 [12] 因其在大语言模型 (LLM) 中激发思考和推理能力而备受关注,随后 VLA(视觉-语言-动作模型)的主干网络也是由 LLM 构成的。受 GRPO 的启发,本文工作旨在评估其是否能够类似地提升 VLA 的任务执行性能。
群体相对策略优化 (GRPO) 主要基于近端策略优化 (PPO) [32] 算法发展而来。PPO 采用 Actor-Critic [26] 架构,在训练过程中限制新旧策略之间的差异,以避免策略更新过大导致的不稳定,并使用优势函数来指导策略学习。
因此,PPO 通常在训练过程中与策略一起训练价值函数。然而,训练价值函数并非易事,尤其对于 LLM 而言,训练通常只奖励最终输出的 token,而价值函数则会计算每个 token 的奖励。为了解决这个问题,组相对策略优化 (GRPO),消除了 PPO 中所需的额外价值函数近似。相反,GRPO 使用针对同一输入问题生成的多个输出平均奖励作为基准。
在 GRPO 中,优势是如何计算的?对于给定的问题,策略模型会采样多个输出,然后奖励模型会为每个输出分配一个奖励分数。这些输出构成一个“组”。为了计算优势,首先计算组内所有奖励分数的平均值和标准差,然后分别确定每个输出奖励分数的相对优势。
基于轨迹的组相对策略优化(TGRPO)
将 GRPO 算法应用于机器人领域,尤其是在预训练 VLA 模型中,需要强调两个关键考虑因素:1)如何分组;2)如何计算每个组内的相对优势。
对于分组,LLM 训练通常按问题进行划分,但在机器人任务中,由于每一步的动作或视觉输入可能不同,这种划分并不适用。因此,可以按任务或轨迹阶段进行分组。本研究采用任务级分组,将同一任务的所有步骤归为一类。关于相对优势的计算,GRPO 在其原生场景中是逐步处理的,而机器人执行具有强时间依赖性的连续轨迹。单步优势不足以反映其对最终任务成败的影响。
在 Libero 模拟环境中,用多阶段密集奖励函数来对每一步进行评分。然而,如果所有环境同步获得相同的奖励(例如,所有奖励均为 2),即使部分轨迹已经完成任务,单步优势仍然为零,从而无法体现关键步骤的重要性。
为了解决这个问题,本文引入整个轨迹的相对优势。因此,每一步的损失更新不仅考虑了瞬时奖励的相对表现,还隐式地捕捉了该步骤对整体任务结果的影响。在使用 TGRPO 算法时,仅针对单个任务进行在线强化学习训练,因此优化目标也针对单个任务的多个相同环境。
使用 TGRPO 进行在线训练
在改进相对优势的计算方法后,将其集成到完整的在线强化学习算法中。其中一项关键要求是多阶段奖励函数。在原始的 GRPO 框架中,奖励是二进制的——正确响应为 1,否则为 0。虽然这对于语言模型来说已经足够,但在机器人技术中,它会导致反馈过于稀疏:只有在轨迹结束时才能评估成功,这会阻碍学习,尤其是在需要逐步反馈的单步 VLA 中。为了解决这个问题,设计一个多阶段奖励方案。例如,机器人在接近目标物体时会获得增量奖励,从而在整个训练过程中提供信息丰富的、分阶段的指导。为了与 GRPO 保持一致,为每个阶段分配离散分数——给定阶段内的每一步都共享相同的奖励值。在构建奖励函数的过程中,主要使用 Claude 3.7 sonnet 根据任务本身的描述生成多阶段奖励函数。
整体框架使用强化学习在多个相同环境中针对单个任务训练 VLA 模型。在此设置中,VLA 会在每个环境中逐步采样动作,直到任务完成或达到最大步数,此时轨迹终止。并行采样的这些轨迹集合构成一个组。组形成后,VLA 模型将按如下方式更新:首先,计算组内轨迹之间的相对优势,以获得轨迹级优势。鉴于所有轨迹同时终止,因此长度相同,在每个时间步提取轨迹的步级数据(例如,奖励、动作的对数概率)。然后,这些数据将用于计算步级相对优势。轨迹级和步级的优势合并,最终计算损失以更新模型参数。该框架包含两个可手动调整的超参数,这些超参数与任务高度相关。如何充分平衡轨迹和步长层面的优势仍是一个悬而未决的研究课题。实验结果表明,轨迹层面的优势通常对性能产生更大的影响。整体训练算法的伪代码如算法 1 所示。

实验设置
用 OpenVLA-7B [20] 作为基础 VLA 模型进行实验,并在强化学习训练期间通过 LoRA 对其进行微调。所有强化学习更新均使用 AdamW 优化器以 1 × 10−5 的固定学习率进行。与 [38] 的设置一致,选择 LIBERO [21] 机器人模拟器作为测试平台。LIBERO 简洁的 Python 风格 API 能够直接访问物体状态、机器人关节角度和其他场景信息,从而能够轻松构建密集且信息丰富的奖励函数。在 LIBERO 环境中,专注于从 LIBERO-Object 基准测试中选取的十个操作任务。这十个任务总共涉及十个不同的物体和一个篮子,每个任务都会向机器人展示这些物品的子集(包括干扰物)。机器人必须找到目标物品,抓住它并将其放入篮子中。这些任务的主要意义在于评估模型对物体类型分布变化的泛化能力,包括其识别各种形状、大小和功能的物品并将其成功抓取/放入篮子的能力——即使物体以新的配置出现或作为不同任务子集的一部分出现。重要的一点是,既遵循原始 GRPO 算法的程序,使用监督学习对 LLM 进行微调,又按照 [38] 的实验设置,使用从 OpenVLA-7B 的任务特定监督微调中获得的权重。注:在单个 NVIDIA A100 GPU 上进行这些实验。
附:
LIBERO 是专为机器人终身学习领域设计的基准测试环境,旨在系统地评估和提升机器人在持续学习过程中的知识迁移能力。LIBERO 包含 130 项任务,分为四个套件:LIBERO-Spatial、LIBERO-Object、LIBERO-Goal 和 LIBERO-100。每个套件旨在测试不同类型的知识迁移能力。其中,LIBERO-Object 套件专注于研究机器人在操控不同目标时的知识迁移能力,这对于提升机器人在复杂场景下的泛化能力具有重要意义。
利用 LLM 根据任务描述生成多阶段奖励函数,以辅助 VLA 模型的 TGRPO 训练。提供给 LLM 的提示模板如下:“请根据此任务描述、LIBERO 模拟环境的代码以及机器人任务强化学习的特点,生成一个特定于任务的多阶段奖励函数。当机器人达到特定阶段(由接近度阈值确定)时,该阶段的奖励将保持恒定。奖励值会随着每个阶段逐渐增加,完成任务将获得显著更高的奖励。”
LLM 生成的奖励函数的伪代码如下面算法 2 所示。


DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 18
18 0
0- 0



 已为社区贡献211条内容
已为社区贡献211条内容

所有评论(0)