REALM:用于机器人操作泛化能力的真实-仿真验证基准测试
25年12月来自布拉格捷克理工大学和阿姆斯特丹大学的论文“REALM: A Real-to-Sim Validated Benchmark for Generalization in Robotic Manipulation”。视觉-语言-动作(VLA)模型使机器人能够理解并执行自然语言指令描述的任务。然而,一个关键挑战在于它们能否超越训练时所处的特定环境和条件进行泛化,而这在现实世界中评估起来既
25年12月来自布拉格捷克理工大学和阿姆斯特丹大学的论文“REALM: A Real-to-Sim Validated Benchmark for Generalization in Robotic Manipulation”。
视觉-语言-动作(VLA)模型使机器人能够理解并执行自然语言指令描述的任务。然而,一个关键挑战在于它们能否超越训练时所处的特定环境和条件进行泛化,而这在现实世界中评估起来既困难又昂贵。为了弥补这一不足,REALM是一个旨在评估VLA模型泛化能力的仿真环境和基准测试平台。REALM特别强调通过高保真视觉效果和精准的机器人控制,建立仿真性能与现实世界性能之间的强相关性。该环境提供15种扰动因子、7种操作技能以及超过3500个物体。最后,构建两个任务集作为基准测试平台,并评估π0、π0-FAST和GR00T N1.5 VLA模型,结果表明,泛化能力和鲁棒性仍然是亟待解决的难题。更广泛地说,仿真提供一个有价值的现实世界的替代指标,能够系统地探测和量化VLA的弱点和故障模式。
评估机器人操作中的泛化能力。几乎所有用于评估机器人操作泛化能力的基准测试[17-20, 22, 23, 25-28]都是基于仿真的,这是因为需要可复现性,并且需要涵盖各种不同的物体、场景和扰动。即使在样本量相对较小的情况下,在真实环境中评估泛化能力仍然需要数百次的测试[16],这很快就会变得难以持续,并且难以充分复现。诸如RoboArena[15]之类的项目是朝着扩展真实世界评估迈出的重要一步,它利用分布式评估站网络对远程托管的策略进行盲A/B测试,但这种方法无法系统地探究各个扰动因素下的泛化能力,而且设置可能会频繁变化,这阻碍了可复现性。对大型行为模型 (LBM) 的数据缩放和预训练效果的严格测试 [29] 同样需要数百次可复现的评估,并高度依赖高保真度仿真来获得关于策略性能的统计显著信号。
真实与仿真之间的差距。由于真实与仿真之间固有的差距,仿真评估通常需要使用领域内数据进行协同训练,这种差距体现在两个截然不同的挑战 [20]:(1) 视觉保真度,和 (2) 控制对齐。许多广泛使用的仿真框架缺乏高保真度的视觉效果,导致分布偏移,使得基于真实数据训练的视觉策略偏离分布,进而人为地降低了其性能。尽管高保真度仿真器 [25, 30] 可以缓解视觉差距,但其底层控制往往存在错位,导致在仿真和现实中执行相同动作所产生的状态出现差异。
在策略评估过程中,如何缩小真实环境与仿真环境之间的差距是一个已知的难题[20, 31, 32]。例如,SureSim[33]使用少量真实环境评估数据,并结合可扩展的仿真环境进行增强,从而获得可靠的结果。目前,人们也在积极探索如何利用仿真环境进行自动真实环境到仿真环境的重建[24, 34–37],以用于策略评估和训练。目前只有SIMPLER基准测试[20]能够对基于真实数据训练的策略进行可靠的全仿真评估。虽然这是一个令人振奋的进步,但SIMPLER仅考虑了有限数量的机器人技能和目标,并且仅支持单一视角。
为了克服当前仿真基准测试的局限性,本文使用高保真仿真来缩小视觉差距,并优化机器人物理特性以实现逼真的控制,同时提供丰富的技能、场景和目标。
基准测试平台借鉴 DROID [45] 平台,旨在评估 VLA 和机器人基础模型的泛化能力,而无需显式地在模拟数据上进行联合训练。如表所示,真实性、系统性扰动和多样性的结合能够建立可靠的评估协议,并探究被测模型的失效模式。
基准设计。在初始版本中,支持源自 DROID 数据集中常见操作任务的 7 项技能:抓取、放置、推动、旋转、堆叠、打开和关闭。对于基准测试,基于 DROID 数据集中的现有场景定义两个任务集:(i) REALM-base,包含 8 个测试抓取放置技能的任务;(ii) REALM-articulated,包含 2 个测试在铰接式橱柜抽屉上进行打开和关闭操作技能的任务。任务示例如图所示。
扰动的选择。为了评估VLA在不同条件下的鲁棒性,实施扰动,改变任务和环境的视觉、行为和语义属性。下表列出所有扰动及其分类和实现方式。
采用 ⋆-Gen 分类法 [16] 中的 22 个扰动中的 14 个,并引入单独的 V-LIGHT 扰动用于场景光照。如图展示一个示例。为了生成改变语言指令的语义扰动,用一个现成的 VLM [47]。
指标。为了捕捉比二元成功率更精细的指标,为每项技能定义一个分层进度,即一系列需要按特定顺序实现的离散状态,如表所示。进度值从 0 到 1,其中 0 表示完全失败(例如,未能到达操作对象),1 表示按顺序实现了特定技能的所有状态。每个中间阶段的权重相同。在设计和评估任务进阶时,遵循经验评估的最佳实践[48]。
模型选择。由于在仿真和现实中精确调整机器人控制的复杂性较高,选择DROID[45]作为唯一的目标模型。DROID是目前最大的开源机器人学习数据集之一,并且该平台被广泛使用,包括在众包的真实世界评估站RoboArena[15]中。
系统辨识。为了提高仿真的真实性,目标是缩小真实机器人手臂和仿真机器人手臂执行一系列动作时的控制差距,如图所示。在方法中,底层控制器根据真实的 DROID 平台重新实现并进行参数化,从而留下 14 个自由参数用于学习仿真关节摩擦 (θ_friction) 和电枢 (θ_armature)。在 IsaacSim [30](仿真所用的框架)中,摩擦力模拟关节运动的机械阻力,而电枢则代表关节电机的反射惯性,这有助于提高仿真稳定性。在优化过程中,选取关节位置空间 D = {{(qreal_i,t, qsim_i,t),其中 t 是一个episode中的时间步,i 是一个episode对的索引,q_i,t 是一个 7 维关节角度向量。最小化数据集 D 上的控制对齐损失。在优化过程中,频繁地重放仿真轨迹会消耗大量计算资源,尤其是在缺乏异构并行仿真能力的情况下,而使用的底层仿真器版本并不支持这种能力。因此,用较小的 N = 3 条轨迹,并使用 CMAES [49] 进化算法优化指定的参数以获得初始估计值,然后使用退火值进行参数搜索。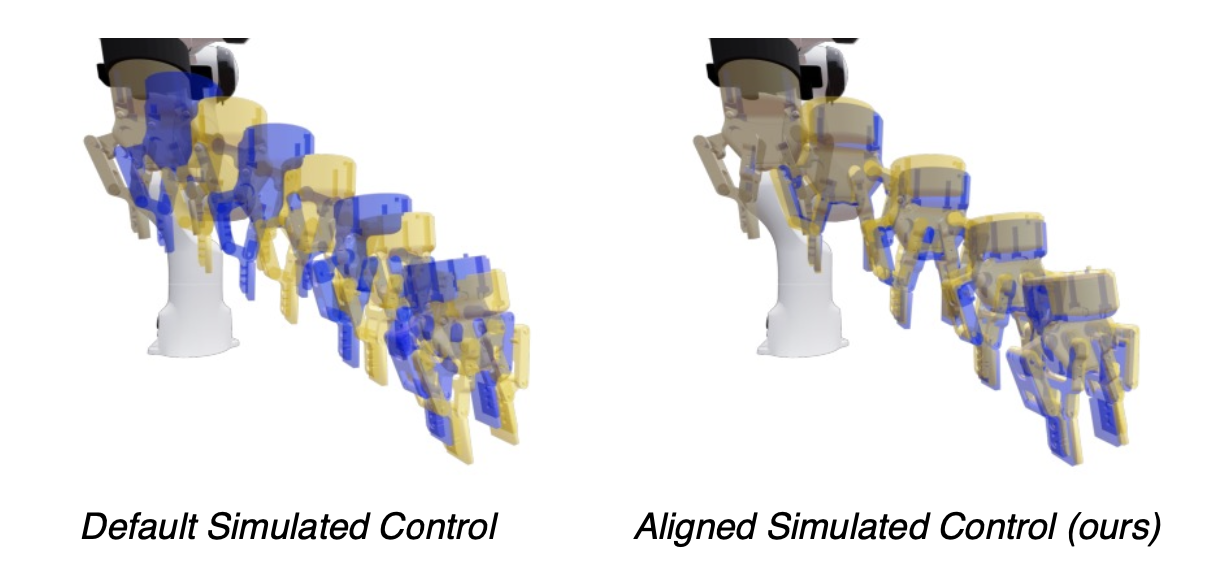
REALM 的主要目标是提供关于 VLA 在各种扰动下泛化能力的可靠见解,并充分反映其在实际应用中的性能。
验证设置。将任务在真实 DROID 平台及其模拟的“数字版”[36](如图所示)上的执行过程进行比较,以验证基准测试能够准确反映真实策略的性能。用三个指标:(i) 真实任务进程与模拟任务进程之间的皮尔逊相关系数 ®,数值越高表示一致性越好;(ii) 对观测数据进行标准双侧 t 检验得到的 p 值,数值越低越好;(iii) SIMPLER [20] 中提出的平均最大排名违背 (MMRV) 指标,用于评估真实环境与模拟环境之间策略排名的一致性,数值越低越好。在 MMRV 指标中,当一个策略在模拟环境中优于另一个策略,但在真实环境中却并非如此时,就会发生排名违背;该指标取最大成对排名违背的平均值。
如下图所示,无论总体而言还是在个体视觉和行为扰动下,相关性始终很高,呈接近恒等线的线性趋势,且相对策略排名基本一致(如较低的 MMRV 值所示)。最后,下图显示的所有结果都来自以前未见过的场景的数字版,这表明 REALM 为评估大规模 VLA 模型中的泛化能力提供一个可靠的框架。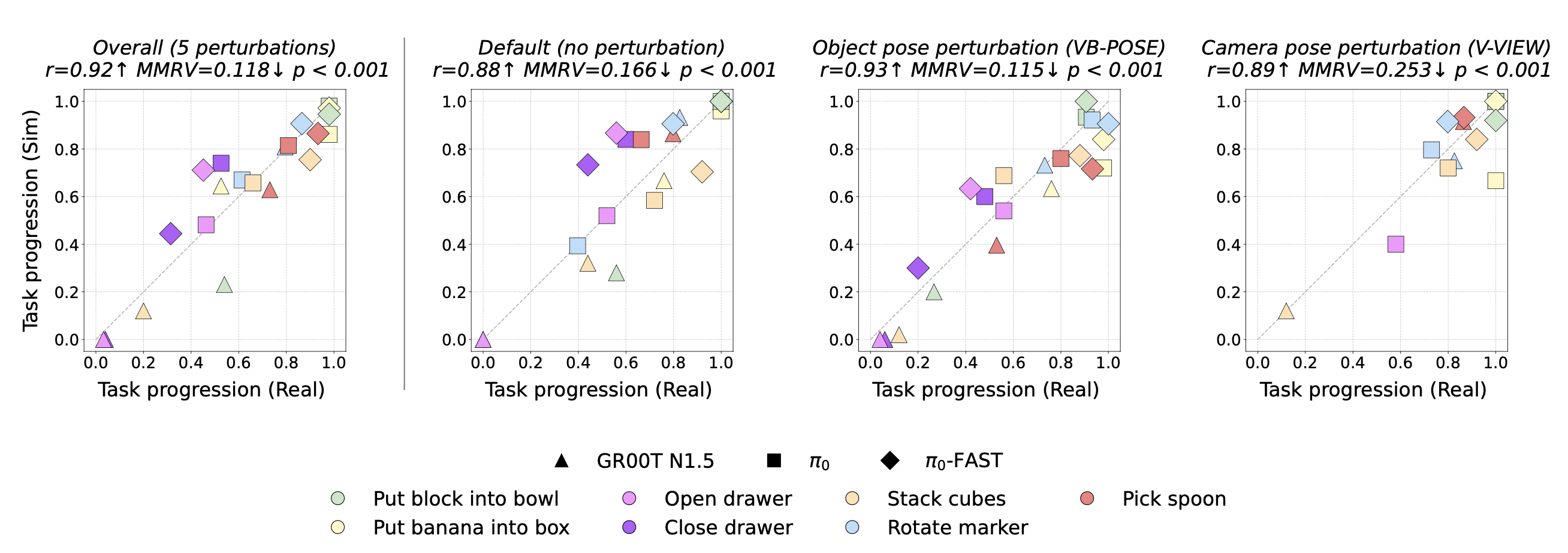
进一步验证视觉差距。与默认机器人控制不同,模拟的视觉保真度足够高,无需进行额外的调整,例如纹理匹配[20]。首先通过上图中模拟任务进展与真实任务进展之间的高度相关性证明这一点。接下来,计算 π0 模型动作专家在模拟视频帧和真实视频帧上的注意力图之间的余弦相似度,来单独分离并量化视觉差距(如下图所示)。π0 注意图的余弦相似度此前已被证明是衡量episodes间分布偏差状态的良好离线指标[50],因此,较高的分数(在本例中为 0.85/1)表明,仅使用模拟渲染不足以导致模型预测与真实世界出现显著差异。


DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 14
14 0
0- 0



 已为社区贡献211条内容
已为社区贡献211条内容

所有评论(0)