RoboCerebra:用于长范围机器人操作评估的大规模基准测试
25年10月来自北航、新加坡国立和上海交大的论文“RoboCerebra: A Large-scale Benchmark for Long-horizon Robotic Manipulation Evaluation”。视觉-语言模型(VLM)的最新进展使得指令控制型机器人系统具备更强的泛化能力。然而,现有的大部分工作都集中于反应式的系统1策略,未能充分利用VLM在语义推理和长时程规划方面的优
25年10月来自北航、新加坡国立和上海交大的论文“RoboCerebra: A Large-scale Benchmark for Long-horizon Robotic Manipulation Evaluation”。
视觉-语言模型(VLM)的最新进展使得指令控制型机器人系统具备更强的泛化能力。然而,现有的大部分工作都集中于反应式的系统1策略,未能充分利用VLM在语义推理和长时程规划方面的优势。这些以深思熟虑、目标导向思维为特征的系统2能力,由于现有基准测试的时间尺度和结构复杂性的限制,仍未得到充分探索。为了弥补这一不足,RoboCerebra,用于评估长范围机器人操作中高级推理能力的基准测试。RoboCerebra包含:(1)一个大规模仿真数据集,该数据集在家庭环境中具有扩展的任务时域和多样化的子任务序列;(2)一个分层框架,该框架结合高级VLM规划器和低级视觉-语言-动作(VLA)控制器;以及(3)一个评估协议,该协议通过结构化的系统1-系统2交互来评估规划、反思和记忆能力。该数据集采用自顶向下的流程构建,其中 GPT 生成任务指令并将其分解为子任务序列。人类操作员在模拟环境中执行这些子任务,从而生成具有动态物体变化的高质量轨迹。与之前的基准数据集相比,RoboCerebra 具有更长的动作序列和更密集的标注。进一步,其将最先进的 VLM 作为系统 2 模块进行基准测试,并分析它们在关键认知维度上的性能,从而推进功能更强大、更通用的机器人规划器的开发。
RoboCerebra 是一种新型基准测试工具,用于评估系统 2 在长时程机器人操作中的能力,它统一采用视觉-语言模型 (VLM) 范式。
RoboCerebra 由三个核心组件构成:(1) 一个旨在捕捉自然地在较长时间范围内展开的现象任务套件;(2) 一个在多个维度上标注的多样化数据集;(3) 一个多方面的评估协议。这些组件共同构成一个全面的框架,用于评估 VLM 在复杂、时间跨度较长的机器人环境中的规划、推理和记忆能力。
如图所示:(a) 自顶向下的数据生成流程使用 LLM 生成高级任务指令并将其分解为子任务。人工操作员在仿真环境中执行这些子任务以收集轨迹,并通过多阶段验证确保轨迹的质量和语义一致性。(b) 数据集示例展示在动态变化的视觉条件下执行长而细粒度的子任务序列。© RoboCerebra 的轨迹长度显著更长,约为现有机器人操作基准测试的 6 倍。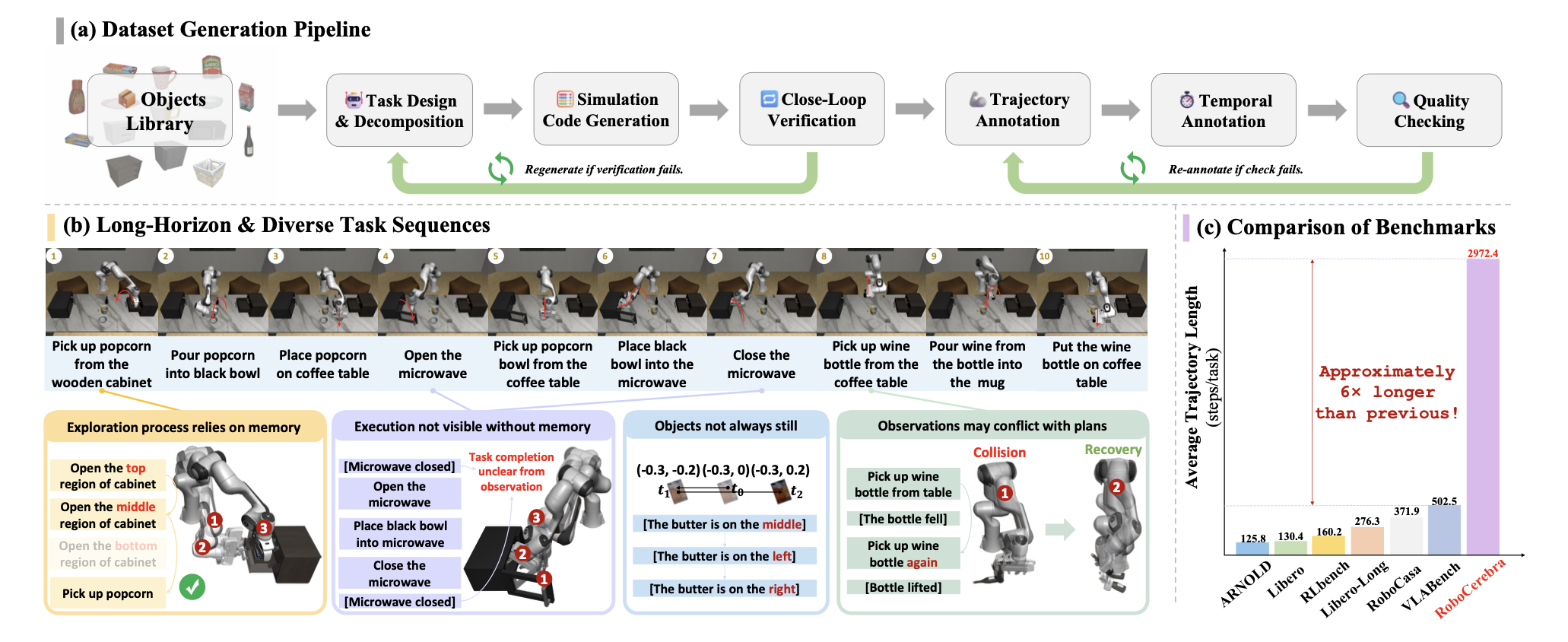
如图所示:RoboCerebra 中的任务生成流程。(a) 从 Libero 的物品库中随机抽取对象,并根据其类别和属性将其转换为结构化表示。(b) 将结构化数据输入到 LLM 中,生成高级任务描述,这些描述被分层分解为低级子步骤。© 通过基于规则的转换,将生成的任务计划解析为可执行的模拟器代码。然后,通过包含符号检查和视觉语言一致性验证的闭环过程(使用 VLM)来验证生成的场景。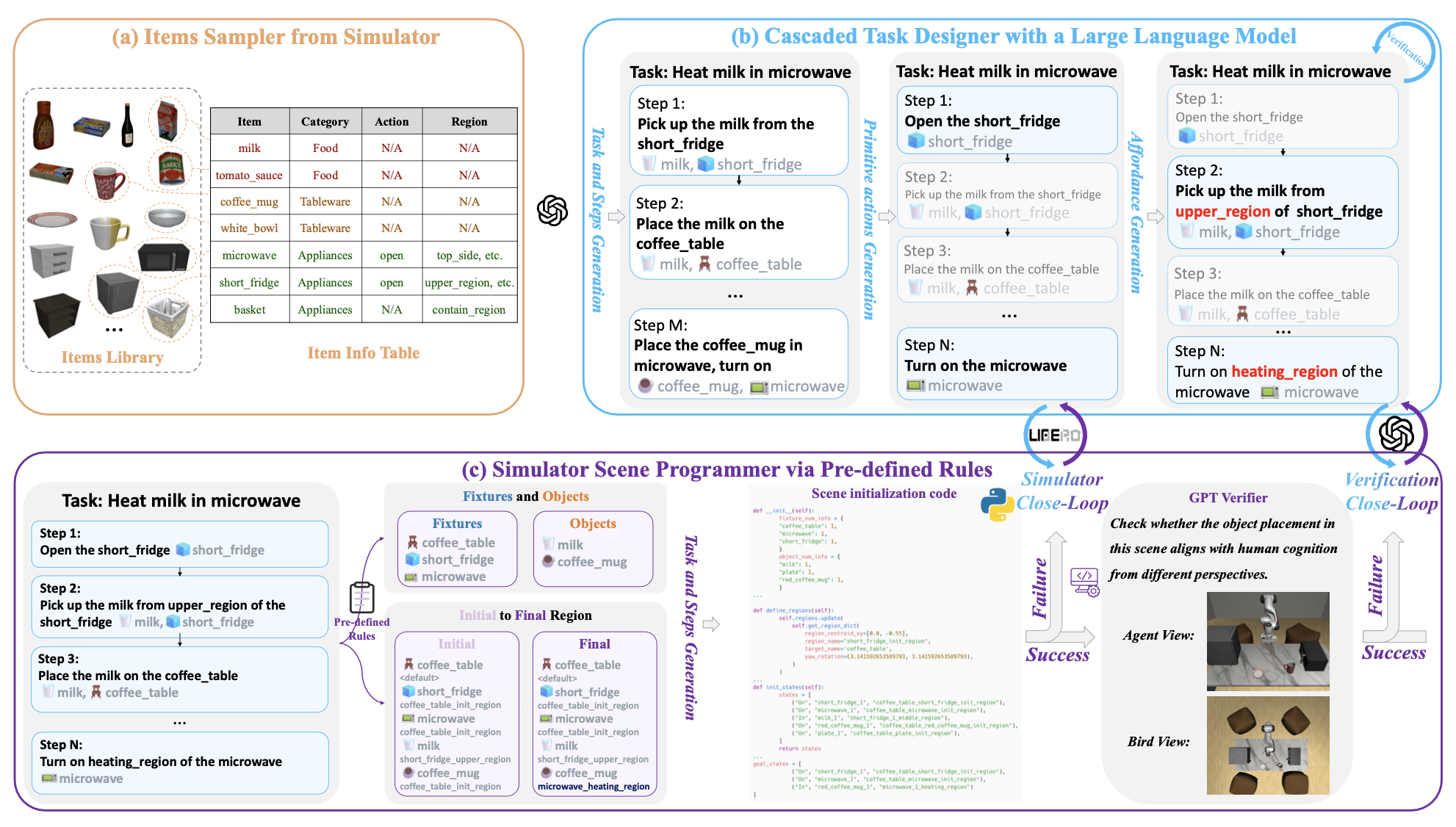
任务设定
设计长范围机器人操作基准需要解决短时程设置中不存在的挑战。除了将任务分解为离散步骤之外,智体还必须对扩展的时间依赖性进行推理,在部分可观测性下运行,并适应动态变化的环境。这包括维护记忆(例如,回忆已探索过的柜子隔间)、推断隐藏状态(例如,记住放置在封闭容器中的物品)、随着环境变化更新信念(例如,物体移动)以及从干扰中恢复(例如,物体掉落)。为了捕捉这些复杂性,定义六种具有代表性的子任务类型:
理想任务——静态、完全可观测设置中的基线任务;
记忆探索任务——需要主动探索以形成内部表征;
记忆执行任务——需要检索记忆以完成目标;
随机干扰任务——引入意外的环境变化;
观测不匹配任务——需要对计划与感知不匹配具有鲁棒性;
混合——结合记忆和动态因素,在不确定性下不断重新规划。
数据集构建流程
开发一个模块化流程,用于构建结构化的、可执行的任务,以支持长时域机器人操作。该流程基于 Libero 仿真平台 [7],包含三个关键阶段:(1)级联任务生成,利用 GPT 合成高级任务并将其分解为子任务序列;(2)场景初始化和验证,将任务实例化到物理和语义上有效的仿真场景中;(3)人工演示和标注,操作人员执行子任务并提供细粒度的时间标签。该流程能够构建可扩展的高质量数据集,用于评估动态环境中的系统 2 推理能力。
级联任务生成。该阶段旨在基于从仿真器中采样的对象配置自动构建结构化的、可执行的任务。给定一组物品,首先将每个对象转换为结构化表示,该表示捕捉其类别、功能特性和空间上下文。这些表征随后被用于引导 GPT-o3-mini[20] 生成各种高级任务描述(例如,“用微波炉加热牛奶”),这些描述随后被分解为连贯的逐步子任务指令。为了确保时间一致性和物理合理性,在引导过程中融入感知affordance和空间基础的推理。模型被引导去验证各步骤中的前提条件、后置条件和对象交互,从而避免逻辑无效或物理上不可行的方案。这种级联生成流程能够创建可扩展的任务,这些任务既具有语义意义又可执行,支持各种对象组合和操作目标。生成的任务-子任务对将作为下游数据收集和学习的基础。
场景初始化和验证执行。此阶段旨在将结构化的任务指令转换为模拟器中可执行的场景。鉴于级联任务规划,每个动作步骤都被解析为一组空间和关系约束(例如,将牛奶从冰箱上层区域放置到咖啡桌上方)。维护一个固定装置和可移动物体的注册表,并应用基于规则的映射将每个步骤转换为相应的初始物体位置和目标物体位置。然后,这些位置被编译成模拟器可执行代码,以构建完整的场景。为了确保生成的环境在功能上正确且语义上合理,执行两级验证。首先,一个符号模拟器循环验证各个步骤中物体状态和关系约束的一致性。其次,一个视觉语言验证循环利用 GPT-4o 从多视图 RGB-D 渲染中评估空间合理性,确保其与人类常识理解相符。这种双循环验证过程确保实例化的场景在物理上可实现,并忠实地反映预期的任务语义。
人工演示与标注。尽管自动化程度很高,但高质量的演示对于学习扎实、长时程的操作仍然至关重要。采用人工操作人员在模拟环境中执行任务指令,生成多样化且逼真的动作轨迹。每条轨迹都标注细粒度的子任务边界,以将动作与特定的任务步骤对齐。这种子任务级别的标注能够实现精确的时间分割,支持多种执行方式,并确保对各种任务变体和长度的全面覆盖。它还有助于将语言指令与运动片段关联起来,从而训练出具有时间感知和指令条件化的策略。为了大规模地保持标注质量,投入大量的人力:400 小时用于轨迹和时间标注,另有 200 小时专门用于单独的验证阶段。这一严谨的流程确保标注计划和状态转换的一致性、完整性和准确性。
数据分析
RoboCerebra 包含 1000 条人工标注的轨迹,涵盖 100 种任务变型,每种变型都旨在反映长时程和组合式操作场景(如图所示)。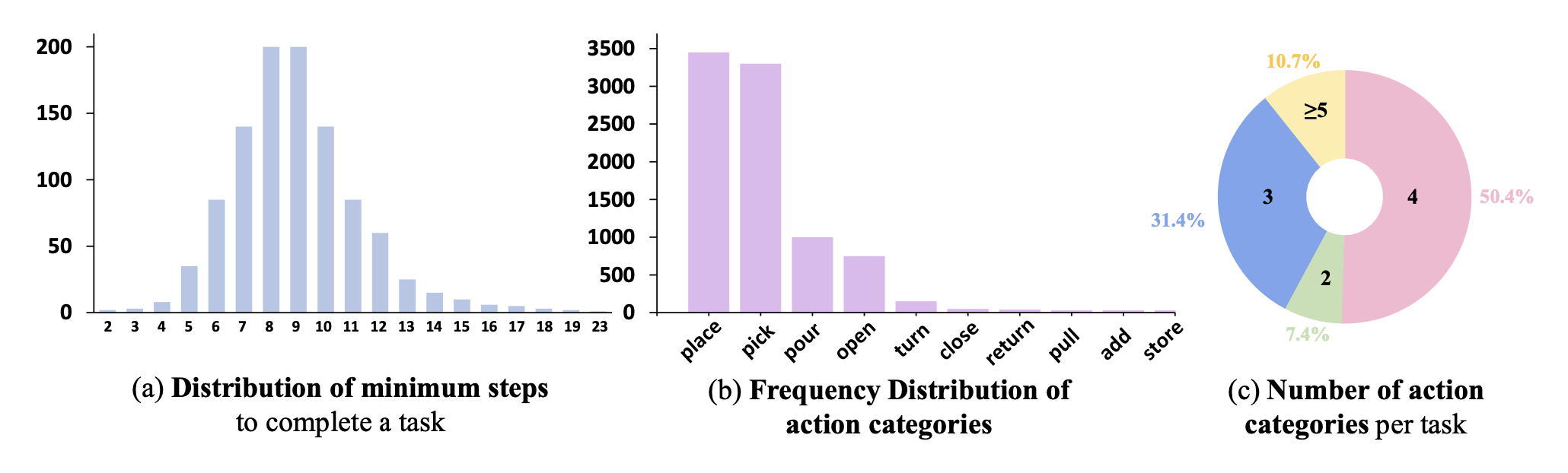
这些任务涵盖广泛的家务活动,包括准备饮料、整理杂货、打扫卫生和摆放餐具。每个任务实例包含 2 到 20 多个原子步骤(平均 9.1 个),从而产生超过 10000 个具有精细时间标注的步骤级片段。该数据集捕捉了不同空间和时间环境下的各种执行模式(图 (a))。为了描述动作的多样性,定义 12 种不同的动作类型。常见的基本动作(例如放置、拾取和倾倒)占据主导地位,而低频动作(例如转向、返回和存储)则突显实际任务中所需的精细控制(图 (b))。平均而言,每个任务包含 3.5 个动作类别,超过 10% 的任务需要五个或更多动作类别,这表明其组合复杂性很高(图 ©)。
RoboCerebra 的一个显著特征是其扩展的时间尺度。平均轨迹长度达到 2972.4 个模拟步长,约为现有长时程操作数据集的 6 倍。这种丰富的时间尺度支持对基于记忆的控制、子目标抽象以及长期依赖下的规划进行研究。此外,该数据集在轨迹长度和任务类型方面保持了广泛的分布,便于评估各种规划挑战。
多维评估
用 N 个长范围操作任务的基准测试来评估系统性能。每个任务 i 由 K_i 个关键对象状态转换序列定义,记为 s(1)_i, s(2)_i, …, s^(K_i)_i,这些转换构成成功完成任务的最小充分条件。这些转换通过模拟器内部谓词函数 ψ(s) 自动验证,如果目标条件在状态 s 下成立,则 ψ(s) 返回 True。
虽然二元任务成功是一种标准指标,但它本身无法捕捉长时域操作更广泛的认知需求。因此,提出一种基于四个互补指标的多维评估协议:(1) 任务成功率,(2) 规划准确率,(3) 规划效率,以及 (4) 动作完成准确率。每个指标都针对长时域推理的不同方面,从而能够更全面地理解系统行为。
为了评估规划效率,用精确序列匹配,将大语言模型 (LLM) 生成的预测高级规划 πpred_i 与人工标注的真实规划 πGT_i 进行比较。实际的符号执行轨迹表示为 A_i = [a_1, a_2, …, a_T],其中 a_t 表示步骤 t 的离散符号动作。
为了评估感知一致性和语义可解释性,引入一个 VideoQA 基准测试,其中包含 M 个人工编写的二元问题 q_j。每个问题都使用验证函数 δ(q_j) 进行评估,如果从执行过程中推断出正确答案,则返回 1,否则返回 0。我们定义以下评估指标:
任务成功率 (SR):衡量智能体是否实现了预期的对象状态转换;
平均计划匹配准确率 (Acc_P):衡量预测的高级规划与真实计划之间的平均一致性;
计划效率 (η):通过将成功率除以平均计划长度来衡量符号规划的效率;
动作完成准确率 (Acc_C):通过 QA 基准测试评估语义可解释性,该指标与模型的反思能力密切相关。
分层规划与执行框架
为了充分发挥高层推理和底层控制的互补优势,提出一种分层规划与执行(HPE)框架。如图所示,该系统由两个组件构成:一个基于低频自我中心观测数据生成和更新步骤级子目标的 VLM,以及一个基于高频输入数据执行细粒度动作的 VLA。共享内存库用于协调两个模块之间的通信,从而实现任务的动态协调和闭环执行。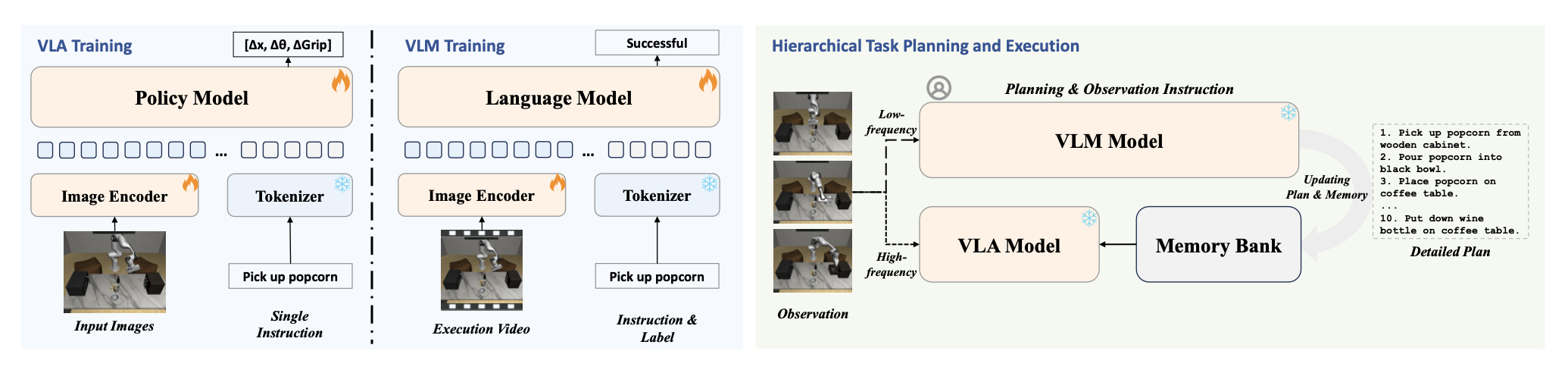
训练流程
为了支持分层系统内的有效协调,采用一种两阶段监督式微调范式,为两个模块提供针对性的监督。该策略赋予 VLA 底层控制能力,并赋予 VLM 高层推理和进度监控能力。在第一阶段,训练 VLA 基于自我中心观测数据和步骤级指令执行细粒度动作。训练数据来源于长范围演示,其中每个(图像,指令)对都与相应的机器人动作配对。参照 OpenVLA [13],将连续动作离散化为token序列,并通过下一个token预测来训练模型。这使得 VLA 能够获取可重用的视觉运动基元,从而为可泛化的底层控制奠定可靠的基础。在第二阶段,训练 VLM 来解读视频-指令对并评估任务进度。为此,构建一个包含步骤级指令标注的视频数据集,其中既包含成功执行的,也包含未完成的。通过对比监督,模型学习将视觉序列与指令完成状态关联起来。这使得 VLM 能够基于实时视觉反馈进行进度感知规划和重规划。通过显式地对执行状态进行建模,VLM 增强了鲁棒性,并有助于在长范围任务中与底层控制器进行更紧密的协调。
分层任务规划与执行
在推理阶段,视觉逻辑模型(VLM)将高层任务指令解析为一系列步骤级子目标,并存储在内存库中。视觉逻辑控制器(VLA)持续查询当前激活的子目标,并基于高频视觉观察执行相应的底层操作。同时,VLM 会定期查看最近的观察结果以监控执行进度。一旦检测到子目标完成或出现偏差,它会将内存更新为下一个子目标,或者发出更精确的指令。这种闭环协调机制在确保响应式控制的同时,也保持了时间抽象性,从而在长范围任务中实现稳健且可解释的性能。
实验设置
系统 1 模型。为了使 VLA 模型适应长范围域,从 RoboCerebra 训练集中抽取 100 个任务实例,并基于时间标注将每个实例分解为单步序列。在此数据集上对 OpenVLA [13] 进行微调。该模型训练 20 万步,全局批大小为 64,初始学习率为 5e-5(10 万步后衰减),输入分辨率为 256×256。训练和评估在 8 个 NVIDIA A100 GPU 上进行。
系统 2 模型。评估不同系统 2 模型在多种设置下的推理能力。具体而言,考虑三类模型:(1)预训练的视觉语言模型(VLM)(GPT-4o [11]、Qwen2.5-VL [21] 和 LLaVA-Next-Video [22]),(2)盲VLM模型(LLaVA-Next-Video)(禁用视觉输入以隔离基于语言的推理),以及(3)在视频指令数据集上训练的监督式微调 VLM,该数据集在子任务级别上标记成功和失败。每个系统 2 模型都作为一个高级控制器运行,生成由固定的系统 1 策略执行的逐步指令。因此,任务成功主要反映系统 2 模块的推理能力。
基线。进一步研究系统 2 在不同认知功能(计划、观察和记忆)中的作用。基于这些维度,实现多个基线。例如,规划器基线从初始指令生成整个子目标序列,而无需进一步的感知或反馈。为了更好地利用VLM的能力,实现一个分层框架。在该框架中,系统 2 动态监控环境、更新子目标,并与内存模块交互以进行长期规划。
评估协议。对每种方法进行 600 次部署(60 个任务 × 10 次试验)的评估。为了公平地比较不同规划模型,定义一组锚点,用于确定系统 1 在子目标之间转换的时间点。这些与锚点对齐的转换将步骤切换与模型解耦,从而保证不同模型之间时间粒度的一致性。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 38
38 0
0- 0



 已为社区贡献211条内容
已为社区贡献211条内容

所有评论(0)