视觉VLA看不到的“那堵墙”,被发现了......
LingBot-Depth 是蚂蚁集团旗下具身智能公司灵波科技开源的高精度空间感知模型,可在不更换硬件的前提下显著提升透明、反光等复杂材质场景的深度输出质量,给机器人一双看清三维空间的“眼睛”。LingBot-Depth 的核心创新,是提出了 “Masked Depth Modeling(掩码深度建模)” 范式和可扩展的真实深度数据数采范式。不把深度相机的缺失数据当 “噪声”,而是视为反映场景几何
想象一下:在一个阳光充足的下午,机器人在打扫房间。在窗户边上的桌子,透明的玻璃水杯需要放回指定的位置,机器人走过去,面对强光直射和透明的物体,机器人只能无意义的重复抓取动作,仿佛面对一个“幽灵”。
这不是什么科幻场景,而是当下具身领域的现实困境 —— 在透明、反光、极端光照等日常场景中,3D 空间感知失效,让具身机器人不再智能…
原文链接:视觉VLA看不到的“那堵墙”,被发现了…
一、纯视觉方案的“有心无力”
具身领域正在逐渐脱离“讲故事”的阶段,转变为生产力是每家企业都在思考的问题。
但在真实物理世界中,纯视觉依赖RGB图像的纹理、色彩信息推断空间关系,现实中大量场景让这种“空间感知”寸步难行。
1. 透明物体:纯视觉VLA的“幽灵”

透明材质(玻璃、亚克力、透明容器)是纯视觉感知的噩梦。在机器人抓取任务中,纯视觉甚至无法定位透明存储盒的存在,更别提精准抓取。虽然有一些方法尝试在解决这个问题,但效果还比较受限,主要是因为:
- 透明物体无自身固定纹理,表面信息完全依赖环境反射与折射;
- 仅通过RGB图像,模型无法判断其轮廓、厚度与空间位置;
- 就像面对“视觉幽灵”,看得见却摸不着。
2. 反光与极端光照:无纹理场景的“感知失明”
同样,反光表面(金属器皿、镜子、光滑车漆)和极端光照(强光直射、暗光环境),会彻底摧毁纯视觉依赖的“纹理特征”。
- 反光材质会反射周围环境的光影,形成与物体本身无关的虚假纹理 —— 传统立体匹配算法会被这些虚假信息误导,将反射光斑误判为物体表面;
- 极端光照则进一步放大了感知缺陷:强光直射下,RGB 图像出现过曝,物体边缘与背景融为一体,暗光环境中,图像噪点剧增,低纹理表面(如白墙、瓷砖地面)更会让“感知失明”。
二、Depth提供了空间的尺子,但依然“模糊不清”
RGB-D相机的出现,提供了空间感知的一把尺子。在正常环境中,它可以提供稳定的深度,让机器人操作“从从容容,游刃有余”,是目前最理想的3D感知模态,但现实很骨感。

硬件的物理局限,让这把“空间标尺”始终“模糊不清”:
- 深度缺失:在透明、反光、低纹理表面,立体匹配算法频频失效,导致深度图出现大量“黑洞”,这些失效会导致严重的数据损坏和真值缺失,直接违背了对密集、像素对齐几何结构的要求;
- 测量噪声:受传感器精度、光照变化影响,有效深度像素也存在量化误差、光子噪声,导致深度图边缘模糊、细节丢失;
- 硬件依赖:高端深度相机(如LiDAR)成本高昂,但消费级RGB-D相机也难以直接用于高精度场景。
现有基于双目深度相机工作方式类似人眼:两个镜头从略有差异的视角同时拍摄场景,系统通过匹配两幅图像中的对应点来计算深度。
然而这种方法存在先天缺陷——在纹理缺失区域、透明材质或强反光表面上,匹配算法往往失效,因为两路图像要么过于相似、要么发生严重畸变。结果就是:恰恰在最需要深度信息的地方,传感器反而输出空洞或错误数据。
所以,硬件层面无法解决的感知缺陷,只能靠算法来弥补。
三、深度图+视觉模型的“重大突破”
就在今天,蚂蚁灵波提出了LingBot-Depth,给Depth这把“尺子”,上了更精细的“刻度”。
- 论文标题:Masked Depth Modeling for Spatial Perception
- 开源链接:https://github.com/robbyant/lingbot-depth
- 项目主页:https://technology.robbyant.com/lingbot-depth
目前,LingBot-Depth的源码和模型均已开源。
demo1
1. 一句话定义:具身智能的“视觉增强”引擎
LingBot-Depth 是蚂蚁集团旗下具身智能公司灵波科技开源的高精度空间感知模型,可在不更换硬件的前提下显著提升透明、反光等复杂材质场景的深度输出质量,给机器人一双看清三维空间的“眼睛”。
LingBot-Depth 的核心创新,是提出了 “Masked Depth Modeling(掩码深度建模)” 范式和可扩展的真实深度数据数采范式。
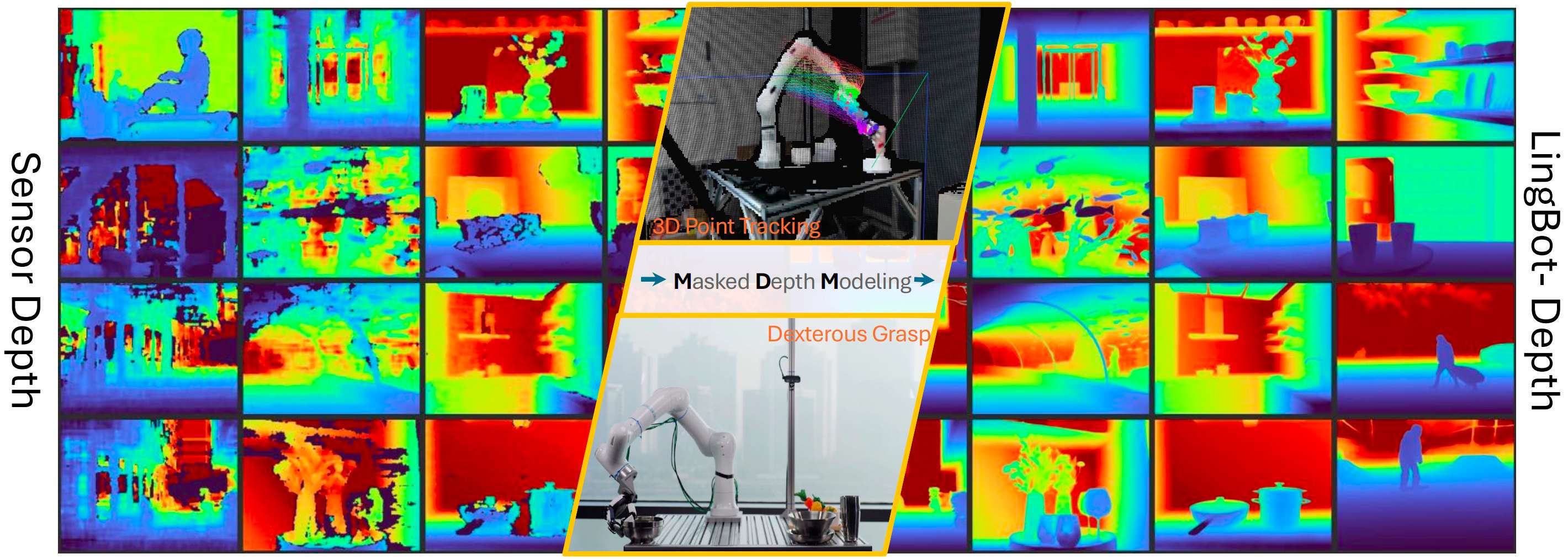
不把深度相机的缺失数据当 “噪声”,而是视为反映场景几何模糊性的 “自然掩码”,通过 RGB 与深度的跨模态联合学习,让模型学会 “用视觉上下文补全空间信息”。
值得一提的是,我们在本文中发现奥比中光深度实验室也验证了LingBot-Depth的性能。
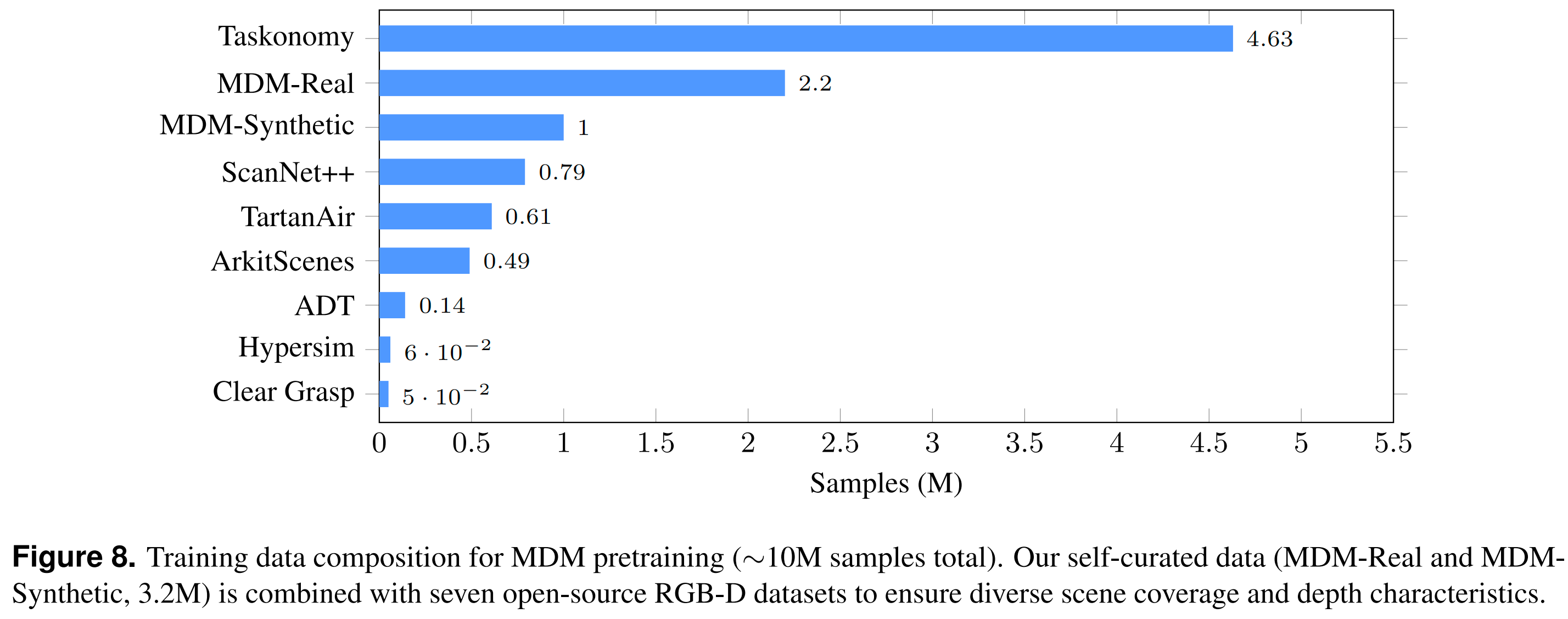
2. 千万量级数据:Depth Scaling再升级
蚂蚁灵波的LingBot-Depth提供了千万量级的大规模RGB-D预训练数据,并设计了一套可供参考的合成数据和真实数据收集流程。

现有RGB-D数据集要么为减少缺失深度测量而避开复杂成像条件,要么使用高质量3D资产和渲染引擎生成近乎完美的深度图。因此,这些数据集缺乏掩码深度建模所需的自然产生的深度不完整性。
为克服这一限制,LingBot-Depth保留真实传感器缺失模式下的RGB-D数据,并设计了两条数据收集流程。
- 合成数据LingBot Depth-S:LingBot Depth的目标不是制作完美的深度图,相反,它明确模拟真实世界主动式RGB-D相机的成像过程,生成带有自然缺陷的逼真深度观测值。最终从442个室内场景中渲染了100万个合成样本。
- 真实数据LingBot Depth-R:可扩展的RGB-D相机采集系统,通过3D打印设计并制造了定制安装支架,允许不同商用RGB-D相机灵活安装。最终收集了200万个场景多样性丰富的真实采集数据,用于掩码深度建模。
这套流程为学术界和工业界提供了一套完整的数据制作 → 模型训练 → 下游应用的闭环范式。
除制作的的320万数据外,LingBot-Depth还使用开源数据集作为补充,形成总计1000万个训练样本用于模型训练。
3. 不止是“补全”:从单一任务到全能感知
模型层面,LingBot-Depth以“掩码深度建模”为核心,遵循encoder–decoder框架下掩码图像建模的通用范式,但通过对RGB-D输入进行处理,将学习目标从外观重建转向深度图预测。
训练过程中,LingBot-Depth使用海量 RGB–深度图像对,但刻意遮挡其中一部分深度区域,让模型仅根据 RGB 图像去预测缺失的深度值。
随着训练进行,模型逐渐学会建立“外观—几何”之间的对应关系,也就是从“物体看起来像什么”推断“它大概有多远”。
核心点在于:传感器失效并非随机噪声,而是在特定材质与光照条件下可预测地发生。
因此LingBot-Depth不再将这些区域简单视为需要滤除的坏数据,而是把它们当作有价值的学习信号。模型会逐渐掌握这样的规律:“当我看到这种类似玻璃的外观和反射模式时,对应的深度大致应落在这个范围。”
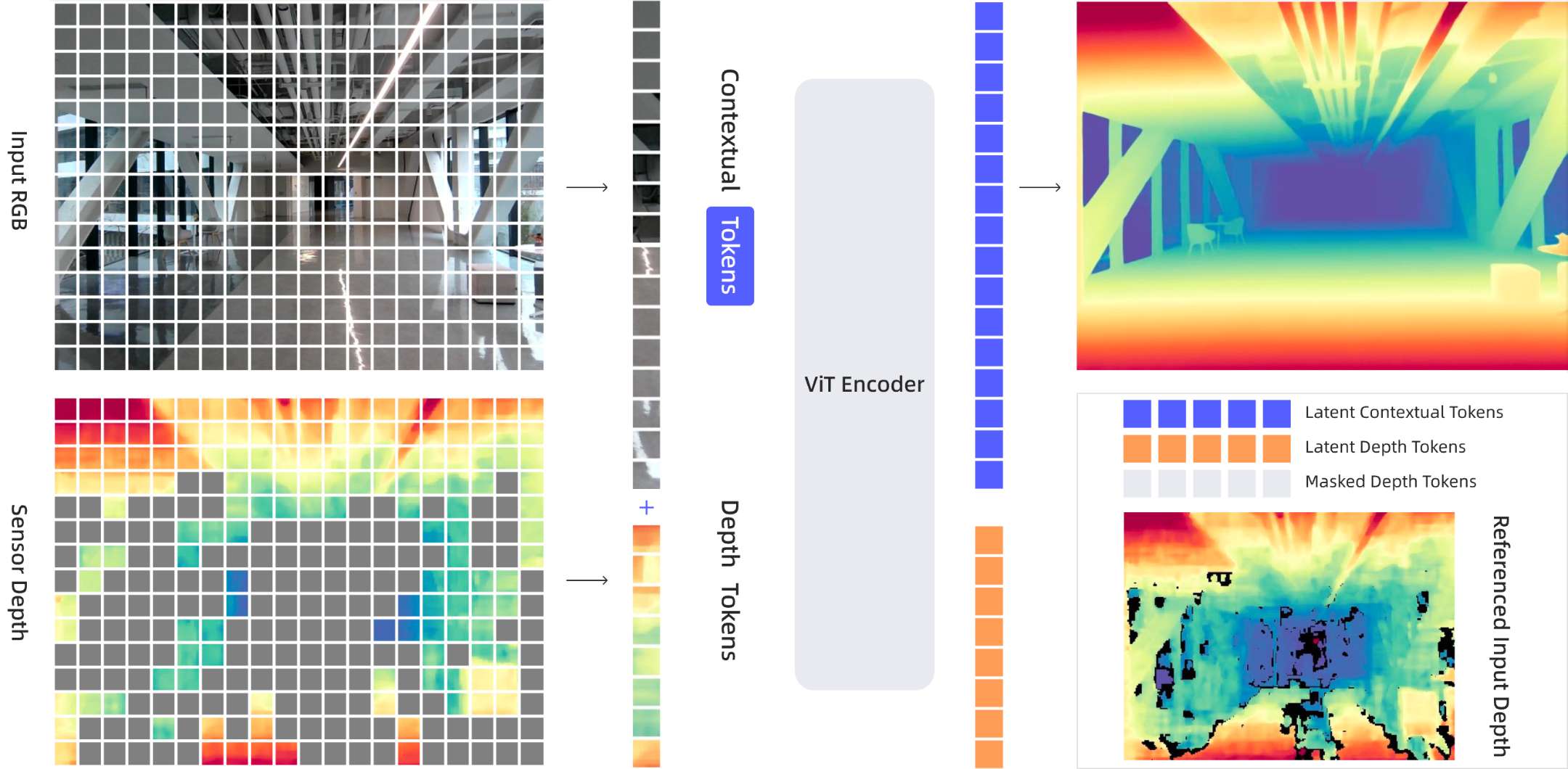
通过ViT学习RGB外观与深度几何的联合表征,既能补全缺失的深度信息,又能提升单目深度估计、立体匹配的精度,本质是为RGB-D相机加装了“视觉增强模块”。
传统深度补全模型仅能填充缺失像素,而LingBot-Depth实现了“一专多能”:
- 深度补全:在iBims、NYUv2等数据集,均超越OMNI-DC、PromptDA等主流方案,极端条件下RMSE(降低40%以上,能精准还原透明物体、反光表面的深度轮廓;
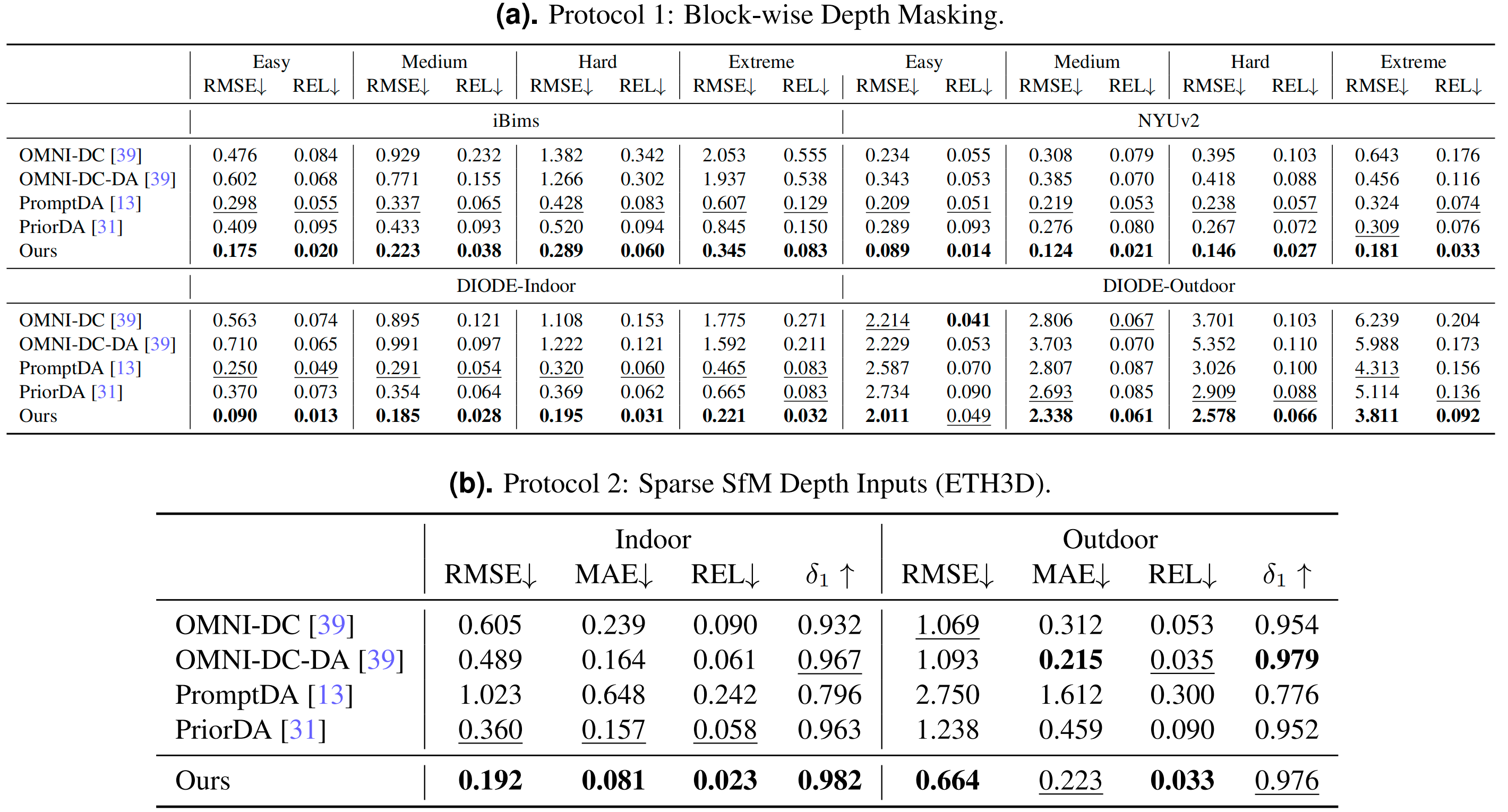
- 单目深度估计:仅用RGB图像,就能输出高精度深度图,在10个不同场景的数据集(室内、户外、合成、真实)中,性能全面超越基于DINOv2预训练的基座模型;
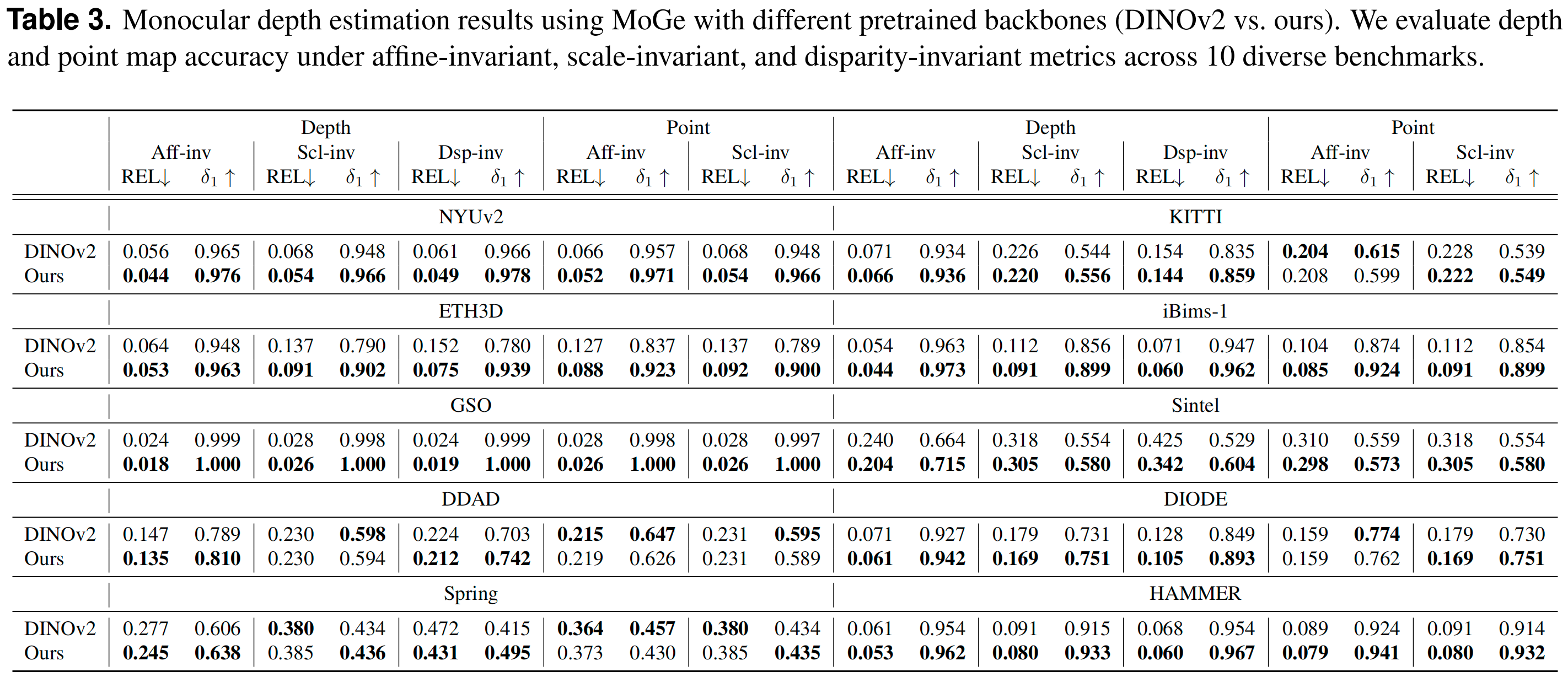
- 立体匹配增强:作为FoundationStereo的深度先验,让立体匹配模型收敛速度提升3倍,最终EPE降低20%,在HAMMER、Booster等难点数据集表现最优。
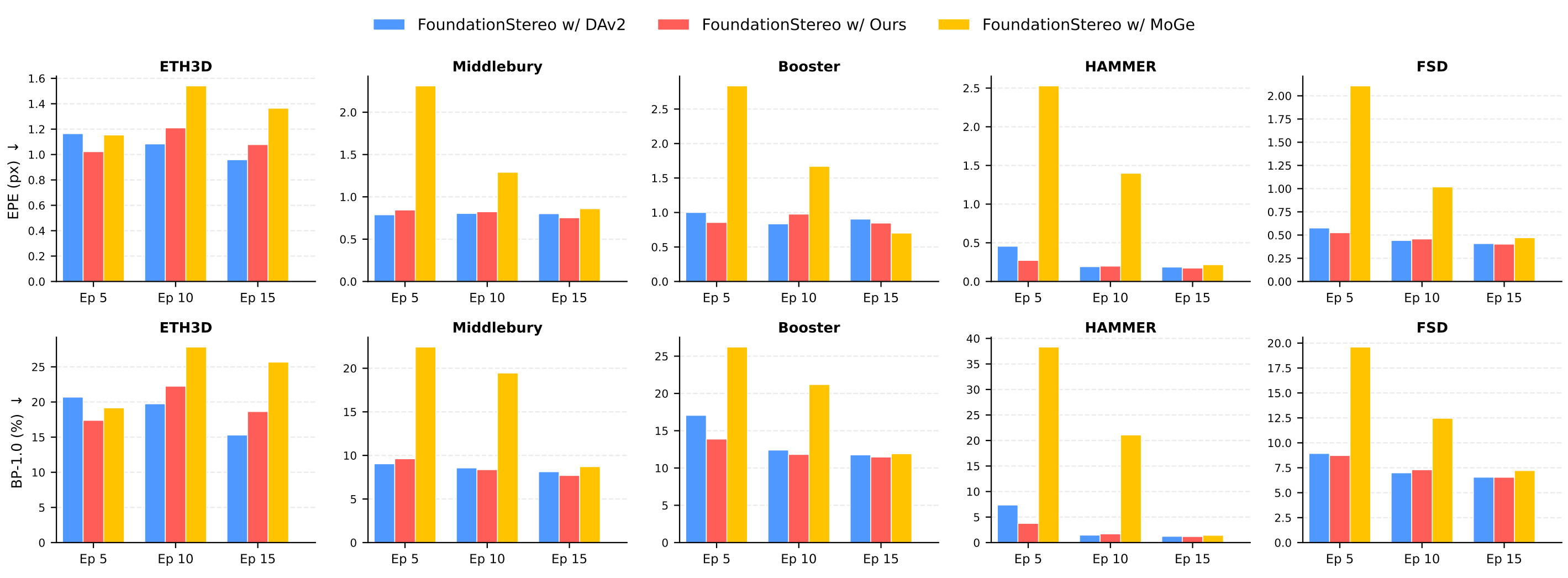
这种全能性背后,是MDM范式的核心优势:通过“自然掩码”学习到的跨模态表示,既包含RGB的纹理信息,又融合深度的几何先验,让模型具备了更通用的空间理解能力。
4. 极端环境下的“一目了然”:透明/强光/暗光都不怕

极端环境下的真实场景,LingBot-Depth表现出极强的鲁棒性:
- 视频时空一致性:即使仅在静态图像上训练,模型处理视频时仍能保持深度的时空平滑性,在玻璃大厅、健身房等动态场景中,输出的深度序列无抖动,远超ZED等高端立体相机;
- 强光场景:在DIODE户外数据集(深度范围大、光照强烈)中,模型仍能保持RMSE 3.811,远低于同类方案的6.239;
- 暗光/低纹理场景:在无纹理白墙、夜间室内等场景,模型通过RGB图像的全局上下文(如墙面与物体的边界、光影变化),补全深度细节,避免传统方案的“大面积模糊”。
面对真实世界的灵巧抓取过程,准确的深度信息对于生成精确的抓取姿态至关重要。如下图所示,原始深度传感器通常会失效的透明和反射物体,LingBot-Depth生成的深度都非常完美。
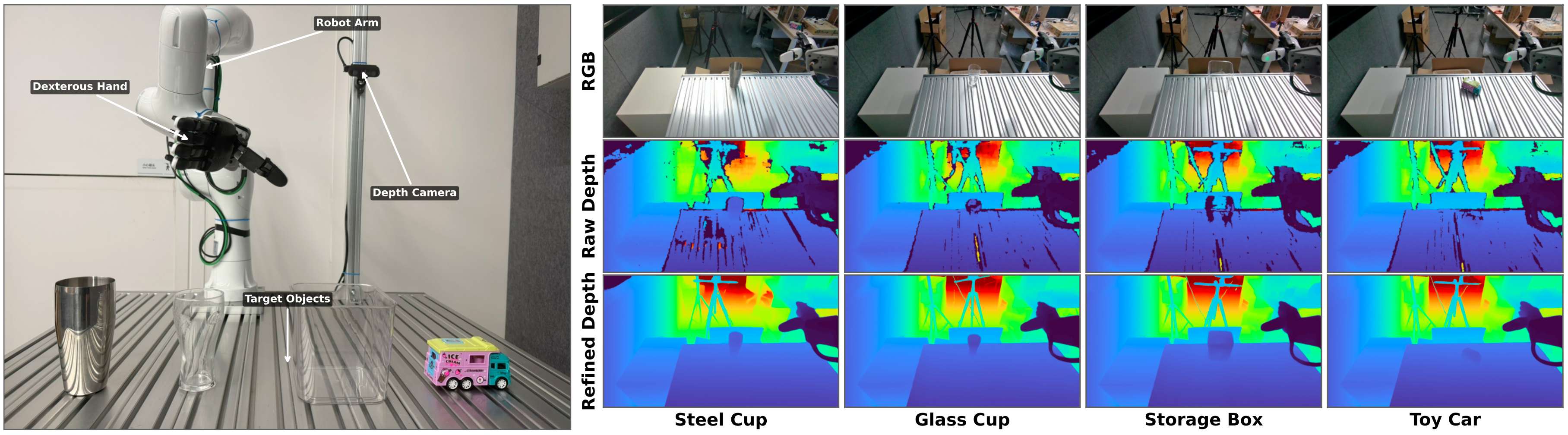
LingBot-Depth提供的深度持续提升了具身抓取的成功率。由于严重的深度损坏,使用原始深度完全无法抓取透明储物盒,基于优化的depth训练后的模型,仍实现了50%的成功率。
这些结果表明,深度补全性能的提升可以直接转化为真实世界场景中更可靠的机器人操作。
demo2
不止是应用在具身抓取领域,LingBot-Depth在相机位姿和4D点跟踪等空间感知任务上的效果也可圈可点。
通过将含噪且不完整的传感器深度优化为干净、稠密且具备真实尺度的三维测量结果,模型显著提升了多种高层视觉任务的稳定性与精度。这使得系统能够在复杂真实环境中建立一致、连续且可用于决策与交互的空间理解表征。
demo3
5. 不挑硬件,无痛迁入“3D相机”方案中
LingBot-Depth的另一大优势是“低门槛落地”:
- 硬件兼容:支持Intel RealSense、Orbbec Gemini、ZED等主流消费级RGB-D相机,无需改装硬件,直接接入即可提升性能;
- 数据支撑:灵波团队构建了规模化数据采集 pipeline,包含210万真实场景样本+100万合成样本,覆盖住宅、商场、医院、户外等12类场景,再结合7个开源数据集,总训练数据达1000万,确保模型的泛化能力;
- 轻量化部署:模型采用BF16混合精度训练,推理时无需复杂后处理,能满足实时性需求(30 FPS),可直接嵌入现有具身VLA模块。

四、结语:LingBot-Depth仅仅是个开始
技术的终极意义在于落地,LingBot-Depth没有追求更昂贵的传感器,而是通过更普世的方法让整个领域享受技术发展的红利。
LingBot-Depth,仅仅是个开始。
这只是蚂蚁灵波迈出的第一步,本质是“算法弥补硬件局限”,并且验证了深度优化对具身操作有效的能力提升。
未来,也期待看到灵波在具身领域更多的工作。
具身求职内推来啦
国内最大的具身智能全栈学习社区来啦!
推荐阅读
从零部署π0,π0.5!好用,高性价比!面向具身科研领域打造的轻量级机械臂
工业级真机教程+VLA算法实战(pi0/pi0.5/GR00T/世界模型等)
具身智能算法与落地平台来啦!国内首个面向科研及工业的全栈具身智能机械臂
VLA/VLA+触觉/VLA+RL/具身世界模型等!具身大脑+小脑算法与实战全栈路线来啦~
MuJoCo具身智能实战:从零基础到强化学习与Sim2Real
Diffusion Policy在具身智能领域是怎么应用的?为什么如此重要?
1v1 科研论文辅导来啦!

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 28
28 0
0- 0



 已为社区贡献106条内容
已为社区贡献106条内容

所有评论(0)