最强开源机器人大脑!蚂蚁两万小时真机数据开启物理AI缩放定律
蚂蚁集团开源具身智能基座模型LingBot-VLA,用两万小时真机数据证明了机器人学习存在类似大语言模型的缩放定律且远未达到瓶颈。LingBot-VLA相较于现有方案具有显著优势,表现出卓越的性能与广泛的泛化能力。在三款不同机器人平台上实现了超越同行的通用操作能力。看到下面这个机器用软布袋收纳物品的视频,真的挺震撼的。机器打开柔软的收纳布袋,将物品放入袋中,然后拉上拉链,一气呵成。物理AI真的开始
蚂蚁集团开源具身智能基座模型LingBot-VLA,用两万小时真机数据证明了机器人学习存在类似大语言模型的缩放定律且远未达到瓶颈。

LingBot-VLA相较于现有方案具有显著优势,表现出卓越的性能与广泛的泛化能力。
在三款不同机器人平台上实现了超越同行的通用操作能力。
看到下面这个机器用软布袋收纳物品的视频,真的挺震撼的。
机器打开柔软的收纳布袋,将物品放入袋中,然后拉上拉链,一气呵成。物理AI真的开始加速了。
数据规模引发质变
通用机器人领域长期面临一个棘手的难题。
大多数机器人只能在特定环境下重复单一动作,一旦环境改变或者更换了机身,之前的技能包就会失效。
要打破这个魔咒,必须让机器人见多识广。
LingBot-VLA是一个务实的视觉-语言-动作(VLA)基础模型。
团队收集了大约20,000小时的真实世界机器人操作数据。
这些数据并非来自单一机型。它们涵盖了9种主流的双臂机器人配置。

数据采集的方式多种多样。
其中包括Agibot G1,它拥有两个7自由度的机械臂和三个RGB-D相机,数据通过VR遥操作采集。
还有AgileX,配备了两个6自由度机械臂,通过同构臂进行控制采集。
Galaxea R1Lite和R1Pro系列则提供了带有立体相机和手腕相机的视角。
甚至包括人形机器人Qinglong和Leju KUAVO 4 Pro。
这些机器人形态各异,不仅涵盖了桌面固定式机械臂,还包括了拥有全身控制维度的人形机器人。
如此多样化的机身结构汇聚在一起,构成了一个极具挑战性的多模态数据集。
过去的研究往往受限于数据规模,难以窥见机器人学习的本质规律。
在真实世界中,数据量的增加是否真的能带来智能的提升?答案是肯定的。
研究团队对预训练数据的规模进行了系统性的缩放分析。
他们将数据量从3,000小时逐步增加到20,000小时。
随着数据量的增长,模型在下游任务中的成功率持续且显著地提升。
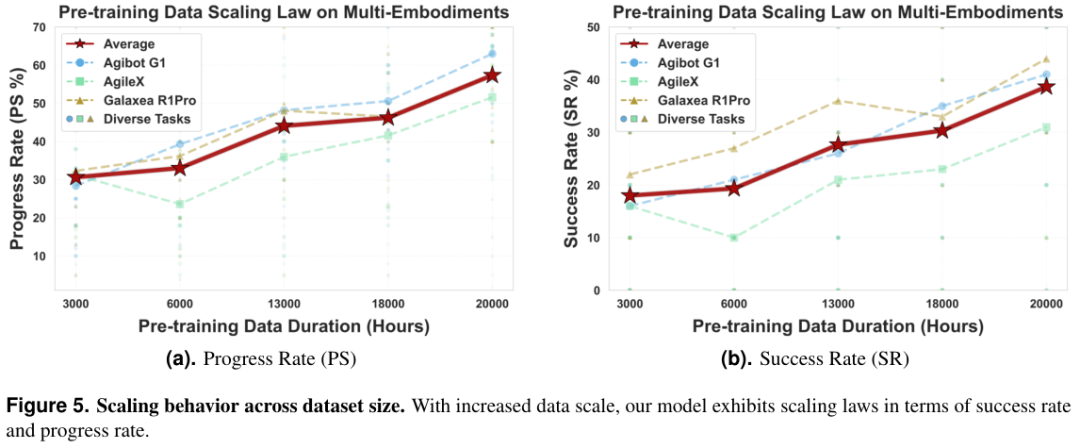
最值得注意的是这种增长并没有出现饱和的迹象。
即便到了20,000小时这个量级,曲线依然保持上扬。
这表明目前的机器人性能仍然可以通过增加数据量来进一步压榨。
这与大语言模型(LLM)的发展路径如出一辙。只要有足够多且高质量的数据,机器人的通用能力就能不断进化。
我们不再需要为每一个新任务从头编写代码。只需要收集更多的数据,让模型自己去领悟物理世界的规律。
为了让这些数据发挥最大价值,数据的标注工作也做得非常精细。
视频数据被分解为原子的动作片段。
人类标注员会去除视频首尾的静止帧,只保留核心动作。
利用强大的Qwen3-VL大模型,团队对这些片段进行了精准的语言描述。
比如“从左到右按大小分类方块”或者“用削皮器削柠檬皮”。
这种图文对应的精细化处理,让模型能够准确理解人类指令与机械臂动作之间的关联。

通过词云图可以看出,预训练数据涵盖了极其丰富的动作类型。
从简单的抓取(Grasp)、放置(Place),到复杂的拧开(Unscrew)、折叠(Fold)。
行为上的多样性,是模型能够应对未知任务的基础。
分层架构实现脑手协同
拥有了海量数据,还需要一个聪明的大脑来消化它们。
LingBot-VLA在架构设计上采用了一种脑手协同策略。
它将视觉语言模型(VLM)与动作生成模块巧妙地结合在一起,这种架构被称为动作专家(Action Expert)模式。
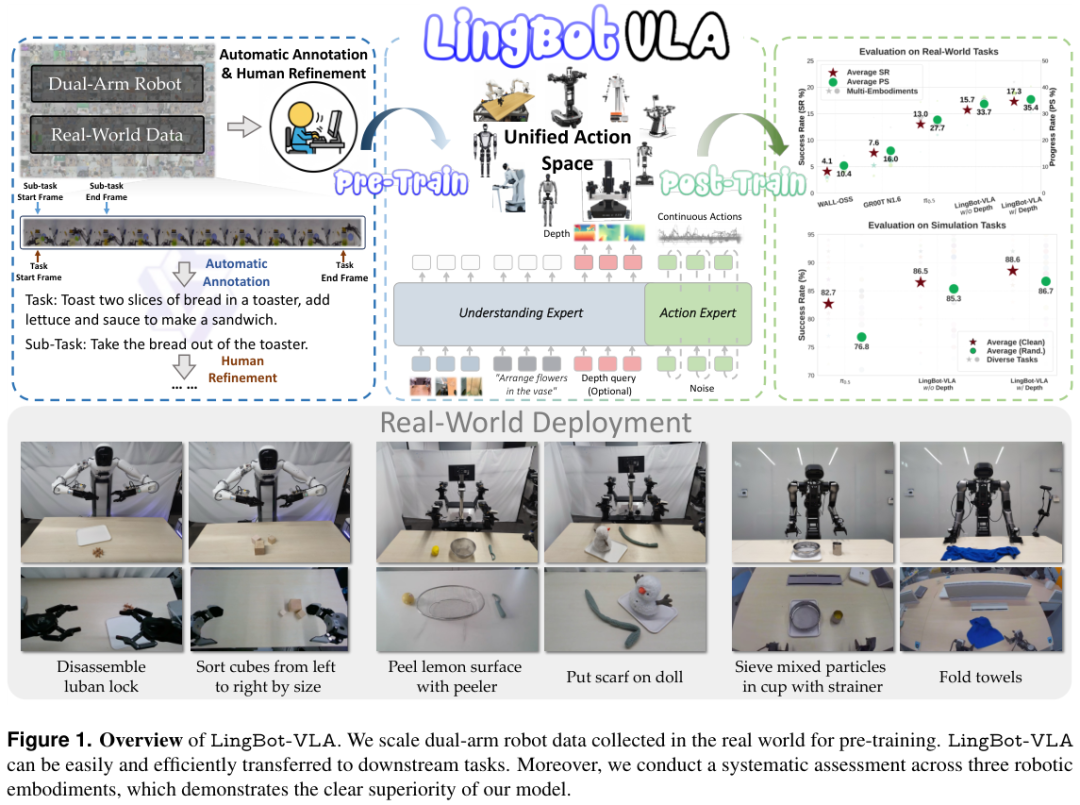
整个模型的大脑部分采用了预训练好的Qwen2.5-VL模型,负责理解“眼前是什么”以及“用户想要做什么”。它处理多视角的图像输入和自然语言指令。
这些高维度的语义信息被编码后,作为引导信号传递给动作专家。动作专家则专注于手的工作。它负责生成具体的机器人关节控制信号。
这里采用了一种叫做Flow Matching(流匹配)的技术。Flow Matching能够生成连续、平滑且高精度的动作轨迹。相比于传统的离散动作预测,这种方法更适合复杂的机械臂控制。它可以让机器人的动作看起来更加行云流水,而不是像老式机器那样卡顿生硬。
为了让大脑和手配合默契,LingBot-VLA使用了混合Transformer(MoT)架构。视觉语言信息和动作信息在各自的通道中处理。但它们通过共享的自注意力机制进行信息交互。
这种设计既保证了高层语义对动作的指导,又避免了跨模态信号的相互干扰。
就像人类在做动作时,大脑提供目标指引,小脑负责协调肌肉,两者紧密配合又各司其职。
为了增强模型对三维空间的感知能力,团队还引入了深度信息。
传统的VLM模型往往擅长语义理解,但在精确的空间几何推理上容易“眼高手低”。
比如它知道那是一个杯子,但可能判断不准杯子离手到底有多远。
LingBot-VLA通过引入深度图,并利用可学习的查询向量(Queries)来提取空间特征。
这些特征与视觉特征进行对齐,从而赋予了模型更强的空间感知能力。
这在处理堆叠物体、精确插拔等需要精细操作的任务时显得尤为重要。
实验表明,引入深度信息后,模型的成功率得到了显著提升。
无论是在仿真环境还是真实世界,带有深度感知的版本都表现得更加稳健。
极致工程压榨硬件性能
训练一个包含视觉、语言和动作的多模态大模型是一项浩大的工程。尤其是面对20,000小时的高频动作数据。
数据I/O的瓶颈和多卡训练的通信开销往往会拖慢迭代速度。
LingBot-VLA团队并没有直接沿用现有的开源代码库,而是重新打造了一套高性能的训练基础设施。
这套代码库在8个GPU的集群上实现了每GPU每秒261个样本的吞吐量。
相比于OpenPI、Dexbotic等现有框架,速度提升了1.5到2.8倍。
这种效率的提升对于大规模实验至关重要。原本需要一个月的训练周期,现在可能只需要十天。极大地缩短了科研探索的反馈回路。
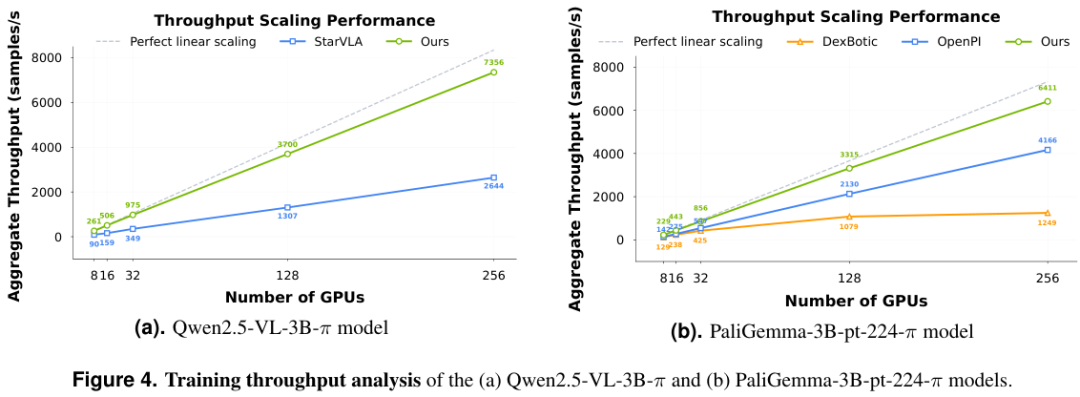
为了实现这种极致性能,团队采用了多种工程优化手段。
首先是分布式策略的优化。
他们采用了完全分片数据并行(FSDP)技术。
通过将优化器状态、模型参数和梯度进行分片存储,极大地降低了显存占用。
针对动作专家模块,他们还设计了特定的分片组(shard groups)。这种策略有效地减少了参数分片带来的通信开销。
在计算层面,他们引入了混合精度训练。
关键的数值计算使用32位浮点数以保证稳定性,而存储和通信则使用16位浮点数以节省带宽。
此外,他们还利用了FlexAttention来优化稀疏注意力计算。
多模态数据的融合本质上是一个稀疏的注意力过程。
通过算子融合技术,减少了内核启动的开销,最大化了内存带宽的利用率。
随着GPU数量的增加,LingBot-VLA的吞吐量几乎呈线性增长。框架具有极佳的可扩展性,非常适合在大规模集群上运行。
严苛测试验证通用能力
为了验证LingBot-VLA的真实能力,团队设计了一个大规模的评估基准。
这个基准包含100个精心设计的操作任务(GM-100)。
测试涉及3种完全不同的机器人平台:AgileX、Agibot G1和Galaxea R1Pro。
为了保证测试的公正性,所有任务都在真实的物理机器人上进行。
测试过程中,物体的摆放位置和朝向都是随机的。
这能够有效防止模型死记硬背特定的空间位置。
评估指标也非常严格。
不仅看任务是否最终成功(成功率SR),还引入了进度分(Progress Score PS)。
进度分用来衡量任务完成了多少步骤。
比如一个任务分为6步,如果完成了4步失败了,那么进度分就是0.67。
这种指标比单纯的成功率更能反映模型的鲁棒性和部分完成能力。
在总共22,500次实机测试中,LingBot-VLA展现出了压倒性的优势。
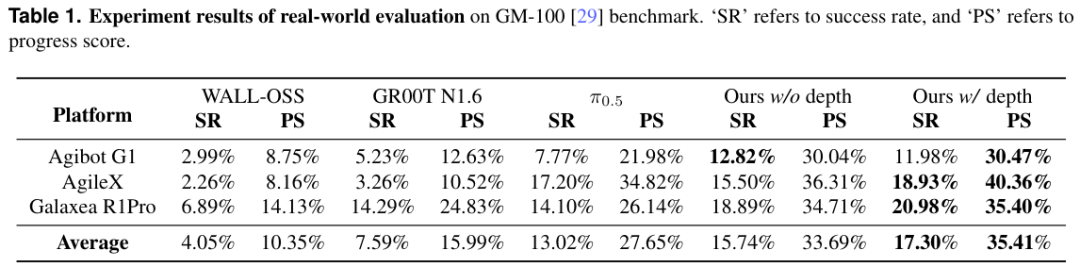
LingBot-VLA在所有平台上都击败了强劲的竞争对手。
相比于π0.5模型,LingBot-VLA(带深度版)的平均成功率提升了4.28%,进度分提升了7.76%。
特别是在Galaxea R1Pro平台上,表现尤为出色。
这得益于预训练数据中包含了大量该机型的数据,证明了数据与性能之间的正相关性。
更有趣的是数据效率的分析。
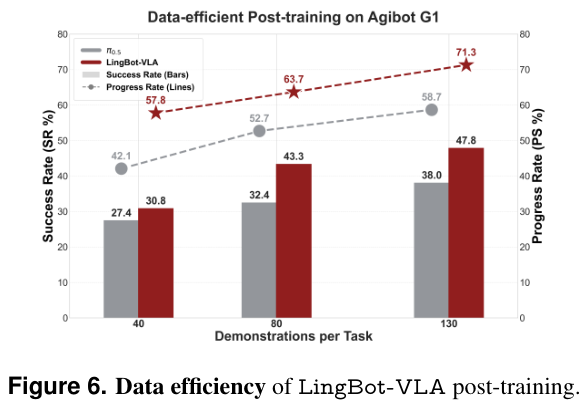
实验显示,LingBot-VLA具有极强的数据利用效率。
在微调阶段,即便只给它看80次演示,它的表现依然超过了看完全部130次演示的π0.5模型。
这种高效的学习能力对于机器人的实际部署意义重大。在现实应用中,要为每一个新任务收集成百上千次演示是非常昂贵的。
LingBot-VLA通过大规模预训练获得的通用特征,可以极大地降低下游任务的适配成本。

RoboTwin 2.0基准上的仿真评估结果显示,无论是在干净场景还是随机化场景中,LingBot-VLA都表现出了优于基线的性能,验证了其在抗干扰和泛化方面的优势。
LingBot-VLA为通用机器人的发展提供了一个务实的范本。
团队已经将代码、模型和数据开源。这将加速整个社区在机器人学习领域的探索步伐。
未来,随着数据量的进一步指数级增长,我们或许很快就能看到真正能干活的机器人走进我们的生活。
参考资料:
https://technology.robbyant.com/lingbot-vla
https://arxiv.org/pdf/2601.18692
https://github.com/Robbyant/lingbot-vla
https://huggingface.co/collections/robbyant/lingbot-vla
https://www.modelscope.cn/collections/Robbyant/LingBot-VLA

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 9
9 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)