计算机革命第四春将至?一文读懂具身智能
具身智能是具备物理身体的AI,通过与真实环境交互实现智能进化,解决了传统AI缺乏物理认知的问题。其技术架构分为硬件层(驱动、传感、计算)、软件层(通讯与仿真)、算法层(感知-决策-控制)和应用层(场景解决方案)。当前挑战包括环境非结构化、控制延迟高、数据稀疏、泛化能力不足及安全风险,可通过仿真训练、分层架构、模块化设计等方案应对。尽管存在困难,具身智能有望推动人形机器人规模化应用,成为技术革命的新
什么是具身智能?
具身智能就是具备身体的AI,具备身体的智能,那些能够走出屏幕,在物理世界与环境进行交互的智能形态,就是具身智能。它本质上是一场从机算智能向物理智能跨越的深刻的产业转移。
 当前AI发展迅速,但存在”物理弱点“,比如让AI生成一个"装满水打碎后的杯子"的视频,生成后的视频存在水流违和的问题。再比如让AI生成一个”运动员翻跟头“的视频,生成后的视频也存在动作违和的问题,这些视频都是AI根据概率推演,不懂得重力和摩檫力。
当前AI发展迅速,但存在”物理弱点“,比如让AI生成一个"装满水打碎后的杯子"的视频,生成后的视频存在水流违和的问题。再比如让AI生成一个”运动员翻跟头“的视频,生成后的视频也存在动作违和的问题,这些视频都是AI根据概率推演,不懂得重力和摩檫力。
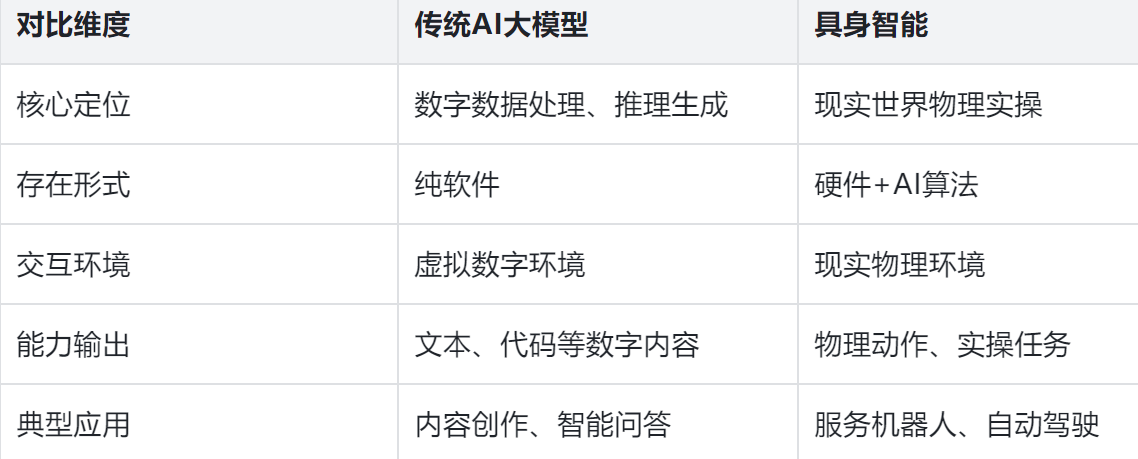
而具身智能的出现解决了AI物理认知的问题,具身智能的目标旨在真实的试错和进化,它可以感知物理规则,像人类一样学习,能够与物理世界实现终极交互。我们从下面这两张表中可以清晰看到具身智能和传统工业自动化、传统AI大模型的对比分析:
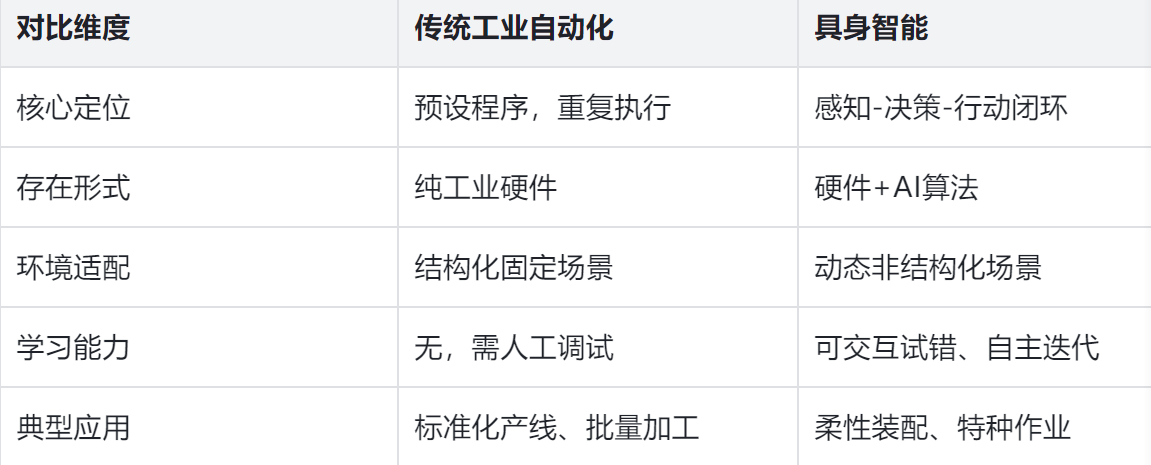
以前的传统高精度机械臂依赖昂贵硬件,且精度提升难度大,而现在的AI+视觉反馈可以做到智能和视觉闭环加持,硬件受限也能精确操作。具身智能的核心就在于交互循坏,首先我们通过视觉、触觉等传感器去感知环境,然后这些感知到的信息我们交给AI的大脑(视觉的小模型或大语言模型)进行决策,最终智能体来驱动身体,去执行新的动作,执行动作又会改变环境产生新的认知,从而进入下一个循环,所以交互是智能涌现的关键,也是具身智能的关键。
传统的大模型无法查询到最新数据,需要外挂联网搜索或知识库,而且离线训练也无法感知最新信息。具身智能与它的关键区别就在于有无交互循环,具身智能可以实现实时闭环(感知—决策—执行),执行完毕后又会产生新的感知,再进行新的决策和感知,能够持续在环境中学习和适应。
我们可以了解到具身智能就是机器人身体+AI大脑的深度融合,具身智能让拥有物理实体的智能体,在物理世界中实时交互,通过试错学习,解决现实生活中的诸多问题。
我们聊完了概念接下来我们聊一聊具身智能的技术架构吧!
我们可以将具身智能的技术架构拆分成四层,分别是应用层、算法层、软件层和硬件层。

首先是第一层硬件层,它决定了智能体物理能力的”天花板“。这一层主要干三件事,驱动、传感和计算。驱动单元我们要去控制各种电机,像直流电机、无刷电机、舵机、伺服电机等等,它是决定机前爆发力精度的前提;传感单元相当于机器人的五官,我们用摄像头去做视觉的输入,用编码器去记录关节的位置,用力传感器去感知抓取的力度;计算平台使用如STM32、边缘计算芯片、板载GPU等,这些是机器人的”小脑“和”边缘大脑“。这些硬件直接决定整个机器的上限。
其次是第二层软件层,软件层是神经系统和仿真,它主要用来连接代码、算法和硬件。我们基于Linux配合ROS进行通讯、发布和订阅数据,让所有的关节可以配合起来,而不是各转各的。然后我们在一些仿真环境(MuJoCo/Webots/Three.js)里跑程序,最终通过软件层来实现硬件间通讯协议,快速进行低成本的开发验证。
第三层是算法和认知层,也是感知决策和控制层,它是机器人的大脑。这一层重点解决感知—决策—控制:Perception,比如经典的OpenCV视觉,基于模型的Yolo CNN,Transformer,多模态的大模型等等。Planning,去让机器人思考,通过强化学习和大模型推理规划。Control,将大模型的高级指令转化成电机电流的微小变化,然后去执行动作。
最后一层是应用层,它是面向终端用户与场景,是架构的业务入口。这一层有行业场景解决方案,比如工业柔性装配、物流搬运、医疗康复、家庭服务、特种作业等等。
到此,我们发现具身智能目前已经不再是一个单一的技术突破了,它是一个非常复杂的软硬件的协同系统了。我们要在成本可控的前提下,让这四层技术架构深度耦合起来。
最后我们来看一下具身智能现在遇到的挑战。为什么现在造一个机器人会这么难?
虚拟世界和物理世界之间有一条巨大的鸿沟。
其一呢,是环境的非结构化,机器人无法提前穷举所有情况。传统工业机器人工作在标准化、封闭的产线里,工件位置、环境布局完全固定,只需执行预设程序。而家用、服务、户外机器人面对的是无序、动态的场景:地面凹凸不平、物品摆放随机、行人突然出现、光线强弱变化。这些不可控的变量,无法像训练大模型一样,用静态数据完全覆盖。
其二,机器人是要保证极低的控制延迟,软件 AI 的推理延迟几百毫秒、几秒,用户通常可以接受。但机器人的动作控制,延迟必须控制在毫秒级。行走时延迟过高会摔倒,机械臂操作时延迟过大会碰撞、损坏工件,这对软硬件的协同设计提出了极高要求。
其三,是数据的稀疏性和昂贵的试错成本。传统大模型(文本、图像大模型)可以轻松抓取互联网海量公开数据,数据体量以万亿 tokens、亿级图片计算,数据密度极高。而具身智能机器人的有效数据,必须来自物理世界的真实交互,比如抓取、行走、装配、避障等。这类数据无法批量网络爬取,只能通过真机实验、仿真采集,采集效率极低。同时,一次真机实验,要完成场地布置、设备调试、数据采集、故障排查,耗时以小时、天为单位。一旦实验失败,需要重新调试参数、修复昂贵的硬件,再开展下一轮测试。
其四,机器人泛化能力的缺失,这里的泛化能力是指在未见过的新场景、新物体、新条件下,依然能稳定完成任务的能力。通常实验室环境可控、变量少,机器人可以完美完成指定动作。一旦进入真实的工业、家庭、物流场景,环境、物体、工况稍有变化,机器人就频繁出错、停机。
其五,是物理交互带来的刚性挑战和AI 决策带来的信任、运维挑战。具身智能直接和人、环境、贵重物品进行物理交互,一旦出现安全问题,会造成人身伤害、财产损失,直接决定产品能否上市。同时,具身智能大量使用深度学习、大模型,决策过程呈现 “黑箱” 特性,可解释性严重不足。
以上五点就是目前造机器人面临的挑战啦!那我们怎么能够应对上述挑战呢?
我们采用全栈工程化的系统性方案。在训练与数据层面,优先使用高保真仿真平台结合域随机化开展海量预训练,大幅降低真机试错成本,同时联合行业共建多模态开源数据集,搭配小样本、迁移学习与大模型技术,缓解数据稀疏问题,提升模型跨域泛化能力。在系统架构上,采用 “大模型高层规划 + 传统算法中层调度 + 底层实时控制”的分层方案,配套可解释 AI 与全流程日志模块,兼顾智能性与决策可追溯性,简化故障排查。硬件与安全设计采用模块化选型,前期用低成本部件验证算法,同时搭建软件监测、力控防护、物理应急的多层安全体系,将合规认证前置,平衡安全与性能。工程落地则聚焦垂直细分场景,先打造标准化产品积累场景经验,再依托真实场景反馈持续闭环迭代,在控制成本的同时提升产品可靠性,推动具身智能从实验室走向规模化商用。
虽然目前挑战有很多,但我们依然乐观,我认为在五年后,人形机器人会走近我们的生活,相信在不久的将来又会焕发计算机革命的第四春!
以上就是本篇文章关于具身智能的所有内容啦,感兴趣的小伙伴可以一键三连哦!
文末小说明:近期琐事缠身,博客更新有所延误,在此向各位小伙伴致歉。之后我会合理规划时间,坚持为大家带来更多计算机领域的优质干货,也感谢大家的耐心等待。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 21
21 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)