多模态模型Qwen3-VL在Llama-Factory中断LoRA微调训练+测试+导出+部署全流程--以具身智能数据集open-eqa为例
1.准备模型
克隆https://github.com/QwenLM/Qwen3-VL项目,方便之后研究阿里官方的代码,当然你也可以不克隆项目,毕竟Llama-Factory这个一站式大模型训练与微调平台对大多数个人开发者使用主流模型是简单且够用的。
到https://huggingface.co/Qwen/Qwen3-VL-2B-Instruct下载Qwen3-VL模型,创建并放到自己的文件夹,这里放到相对路径Qwen3-VL/model/Qwen3-VL-2B-Instruct
2.open-eqa数据集下载及预处理
在任意目录如dataset创建open-eqa目录,在dataset编写脚本执行下载,这里为了减少时间和空间的开销,每个数据只抽取8帧并进行压缩,编写脚本get_dataset.py,其中的关键代码是
from datasets import load_dataset
ds = load_dataset("Embodied1/open-eqa")打开终端进入dataset目录运行get_dataset.py下载

打开文件查看
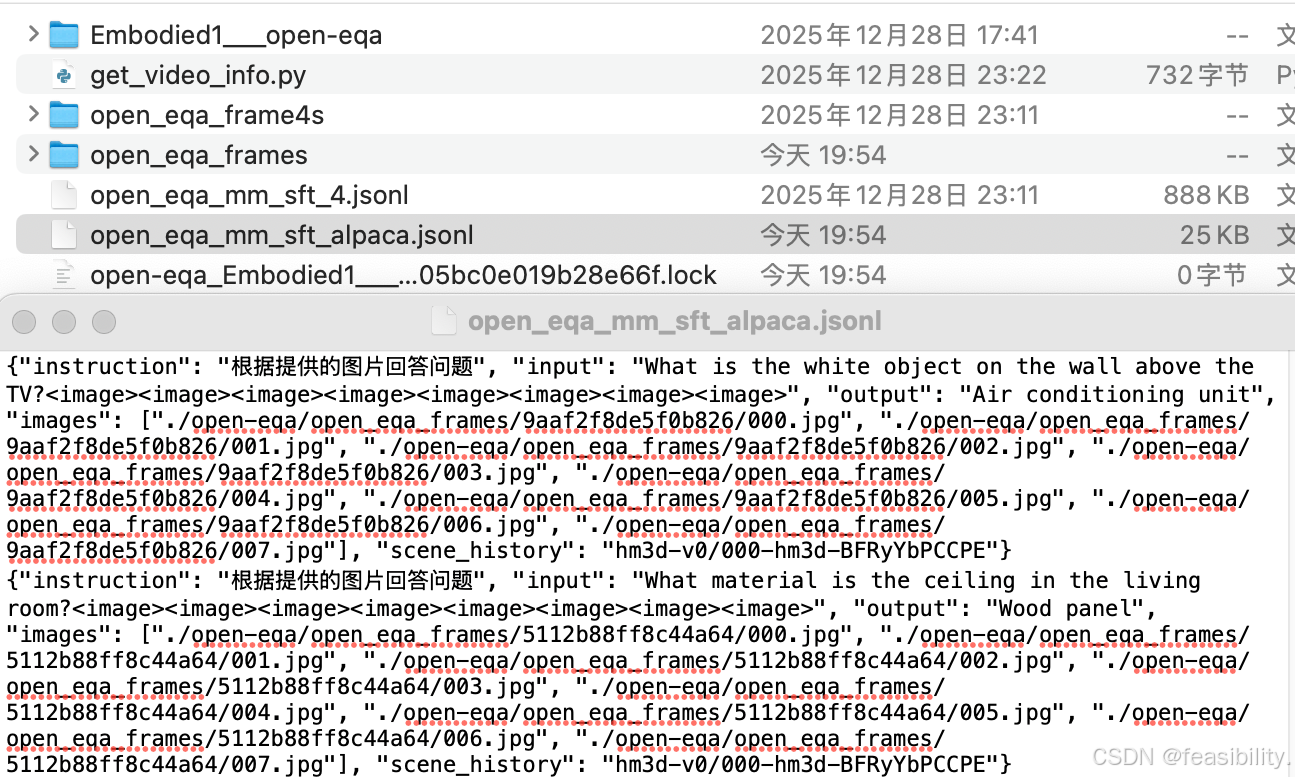
编写split_data.py脚本,放在open-eqa中,拆分数据集,并去掉多余路径前缀

若对下载和处理的代码有兴趣,可以通过网盘分享的文件:OpenEQACode.zip 链接: https://pan.baidu.com/s/1DqmIp1Xw6HJPX77O-iOXdQ?pwd=dgn8 提取码: dgn8
如果不方便下载和处理数据集,可以通过网盘分享的文件:OpenEQA8s.zip
链接: https://pan.baidu.com/s/1_6G4YwI5tmYXUSDLssJ13A?pwd=hfvw 提取码: hfvw
3.Llama-Factory使用
3.1环境配置
git clone https://github.com/hiyouga/LlamaFactory.git 到自己的路径
通过cd LlamaFactory进入目录
配置python环境,之后执行下面命令安装依赖项
pip install -e .
pip install -r requirements/metrics.txt
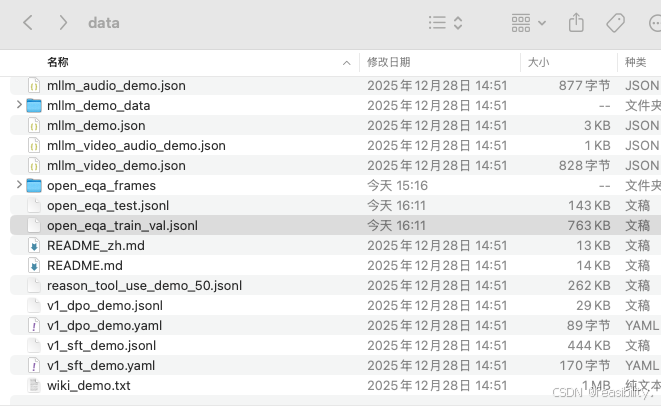
移动文件和图片目录到llama-factory的data路径中
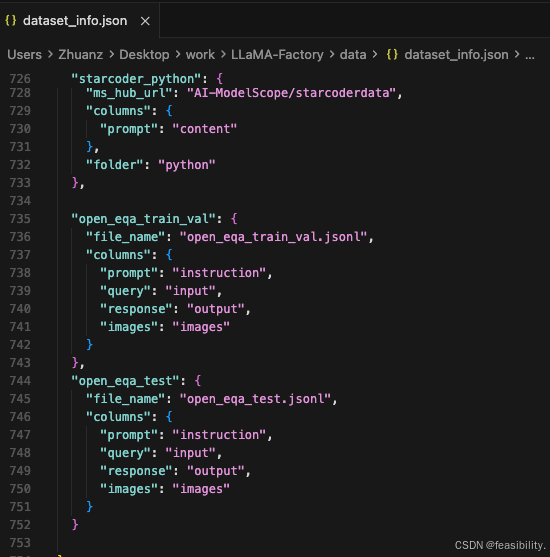
修改dataset_info.json,注册数据集
"open_eqa_train_val": {
"file_name": "open_eqa_train_val.jsonl",
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output",
"images": "images"
}
},
"open_eqa_test": {
"file_name": "open_eqa_test.jsonl",
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output",
"images": "images"
}
}
3.2微调训练
在LLaMA-Factory创建saves/Qwen3-VL-2B-Instruct/lora/train_openeqa,并创建文件training_args.yaml,其中eval_step是验证步数,num_train_epochs是训练轮次(微调训练一般是3-5轮数,太多会过拟合),注意要改基座模型路径model_name_or_path和微调模型路径output_dir,dataset指定时数据集的名称,max_samples可设超过数据集的任意数比如 99999
bf16: false
cutoff_len: 2048
dataset: open_eqa_train_val
dataset_dir: data
ddp_timeout: 180000000
do_train: true
eval_steps: 100
eval_strategy: steps
finetuning_type: lora
flash_attn: auto
freeze_multi_modal_projector: true
freeze_vision_tower: true
gradient_accumulation_steps: 8
image_max_pixels: 589824
image_min_pixels: 1024
include_num_input_tokens_seen: true
learning_rate: 5.0e-05
logging_steps: 5
lora_alpha: 16
lora_dropout: 0
lora_rank: 8
lora_target: all
lr_scheduler_type: cosine
max_grad_norm: 1.0
max_samples: 99999
model_name_or_path: /Users/Zhuanz/Desktop/work/Qwen3-VL/model/Qwen3-VL-2B-Instruct
num_train_epochs: 3.0
optim: adamw_torch
output_dir: saves/Qwen3-VL-2B-Instruct/lora/train_openeqa
packing: false
per_device_eval_batch_size: 1
per_device_train_batch_size: 2
plot_loss: true
preprocessing_num_workers: 2
dataloader_num_workers: 0
report_to: none
save_steps: 10
stage: sft
template: qwen3_vl_nothink
enable_thinking: false
trust_remote_code: true
val_size: 0.125
video_max_pixels: 65536
video_min_pixels: 256
warmup_steps: 0
参数详细说明如下
1)基础模型配置
| 参数 | 设置值 | 说明 |
|---|---|---|
model_name_or_path |
/Users/.../Qwen3-VL-2B-Instruct |
基座模型路径(本地2B参数多模态模型) |
trust_remote_code |
true |
允许加载远程/本地自定义模型架构代码 |
template |
qwen3_vl_nothink |
对话模板(无思考模式,直接输出答案) |
enable_thinking |
false |
不启用思考能力 |
bf16 |
false |
使用FP16混合精度(非BF16),兼容旧架构显卡 |
flash_attn |
auto |
自动检测并启用Flash Attention 2加速 |
2) LoRA微调配置
| 参数 | 设置值 | 说明 |
|---|---|---|
finetuning_type |
lora |
低秩适配微调(仅训练适配器,冻结主干) |
lora_rank |
8 |
低秩矩阵秩(参数量↓,r=8为轻量级配置) |
lora_alpha |
16 |
缩放系数(α/r=2,控制_adapter_权重强度) |
lora_dropout |
0 |
LoRA层丢弃率(0表示不丢弃,满秩训练) |
lora_target |
all |
目标模块(所有线性层:q_proj/k_proj/v_proj/o_proj等) |
freeze_vision_tower |
true |
冻结视觉编码器(不更新图像理解参数) |
freeze_multi_modal_projector |
true |
冻结投影层(保持图像-文本特征映射固定) |
3)数据集与预处理
| 参数 | 设置值 | 说明 |
|---|---|---|
dataset |
open_eqa_train_val |
数据集名称(具身问答OpenEQA训练集) |
dataset_dir |
data |
数据集存放目录 |
cutoff_len |
2048 |
最大序列长度(含图像Token+文本) |
max_samples |
99999 |
最大样本数(实际上使用全部数据) |
val_size |
0.125 |
验证集比例(12.5%,即1/8数据用于验证) |
preprocessing_num_workers |
2 |
数据预处理进程数 |
packing |
false |
不启用序列打包(保持独立样本) |
4)多模态参数配置
| 参数 | 设置值 | 计算/说明 |
|---|---|---|
image_max_pixels |
589824 |
最大图像分辨率 768×768 |
image_min_pixels |
1024 |
最小图像分辨率 32×32 |
video_max_pixels |
65536 |
视频单帧最大 256×256 |
video_min_pixels |
256 |
视频单帧最小 16×16 |
include_num_input_tokens_seen |
true |
统计实际输入Token数(含视觉Token) |
5)训练超参数
| 参数 | 设置值 | 说明/影响 |
|---|---|---|
stage |
sft |
监督微调阶段(Supervised Fine-Tuning) |
do_train |
true |
执行训练(非仅评估) |
num_train_epochs |
3.0 |
训练轮次(数据集完整遍历3次) |
per_device_train_batch_size |
2 |
单卡训练批次大小(每步2个样本) |
per_device_eval_batch_size |
1 |
验证批次大小 |
gradient_accumulation_steps |
8 |
梯度累积步数(实际全局批次=16) |
learning_rate |
5.0e-05 |
初始学习率(5e-5,LoRA建议范围) |
lr_scheduler_type |
cosine |
余弦退火调度(平滑衰减至0) |
warmup_steps |
0 |
预热步数(无预热,直接应用 peak LR) |
max_grad_norm |
1.0 |
梯度裁剪阈值(防梯度爆炸) |
optim |
adamw_torch |
AdamW优化器(PyTorch原生实现) |
6) 评估与保存策略
| 参数 | 设置值 | 周期计算 |
|---|---|---|
eval_strategy |
steps |
按步数评估(非按epoch) |
eval_steps |
100 |
每100步验证一次 |
save_steps |
10 |
每10步保存检查点(高频保存) |
logging_steps |
5 |
每5步记录日志(TensorBoard/Wandb) |
plot_loss |
true |
训练结束后生成Loss曲线图 |
report_to |
none |
不上传至外部平台(Wandb/TensorBoard本地记录) |
7)系统与性能配置
| 参数 | 设置值 | 说明 |
|---|---|---|
output_dir |
saves/.../train_openeqa |
模型输出路径 |
ddp_timeout |
180000000 |
分布式训练超时时间(约50小时,防长时间预处理断连) |
dataloader_num_workers |
0 |
数据加载进程(0=主进程加载,避免多进程问题) |
Llama-Factory可以通过llamafactory-cli webui生成可视化界面,然后点击按钮和输入值设置训练,但这里为了方便中断训练所以执行llamafactory-cli train saves/Qwen3-VL-2B-Instruct/lora/train_openeqa/training_args.yaml开始训练
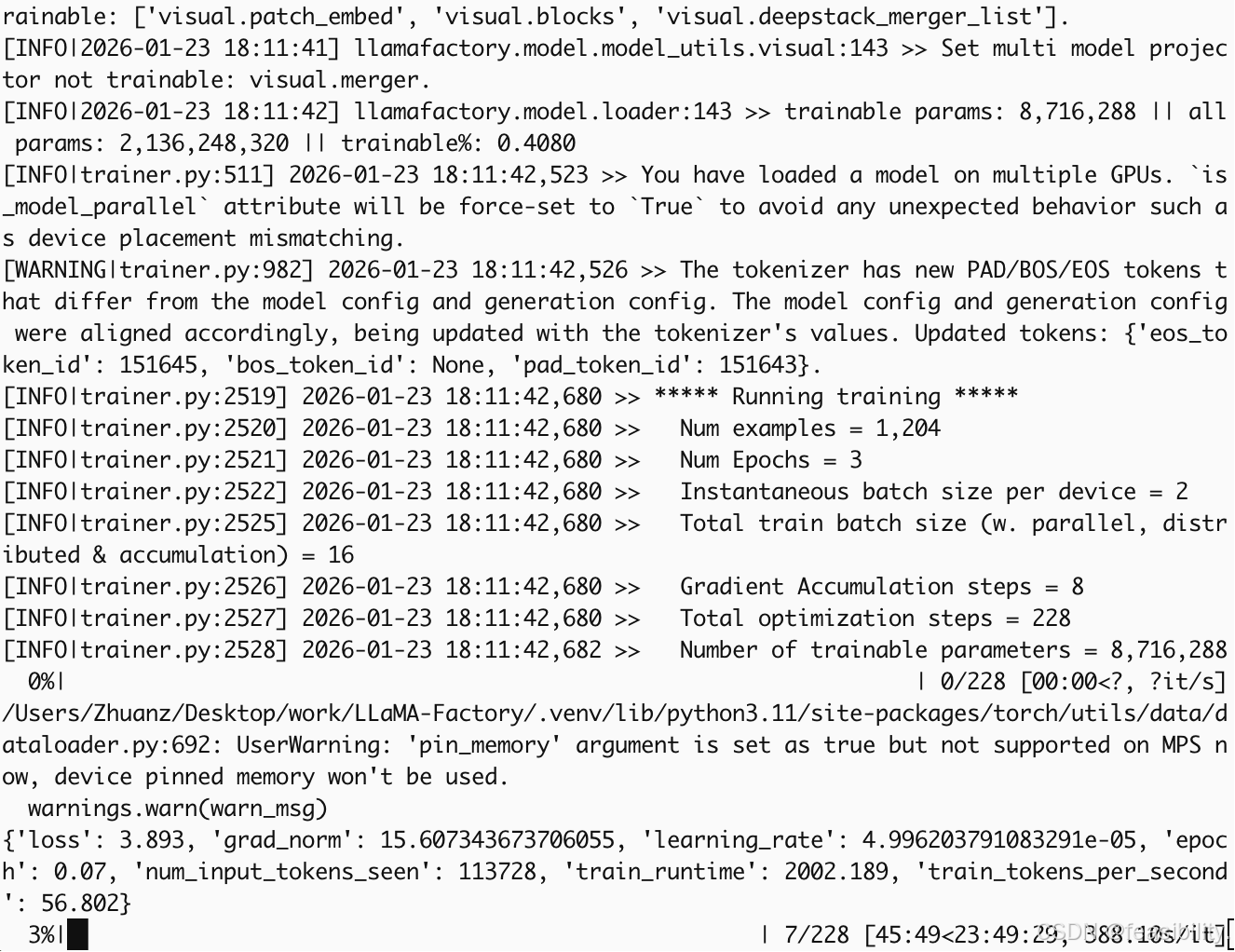
对于你的yaml文件采用参数resume_from_checkpoint可中断训练,resume_from_checkpoint设置为true或具体路径saves/Qwen3-VL-2B-Instruct/lora/train_openeqa/checkpoint-20,路径根据自己的情况改
执行llamafactory-cli train saves/Qwen3-VL-2B-Instruct/lora/train_openeqa/training_args.yaml继续训练
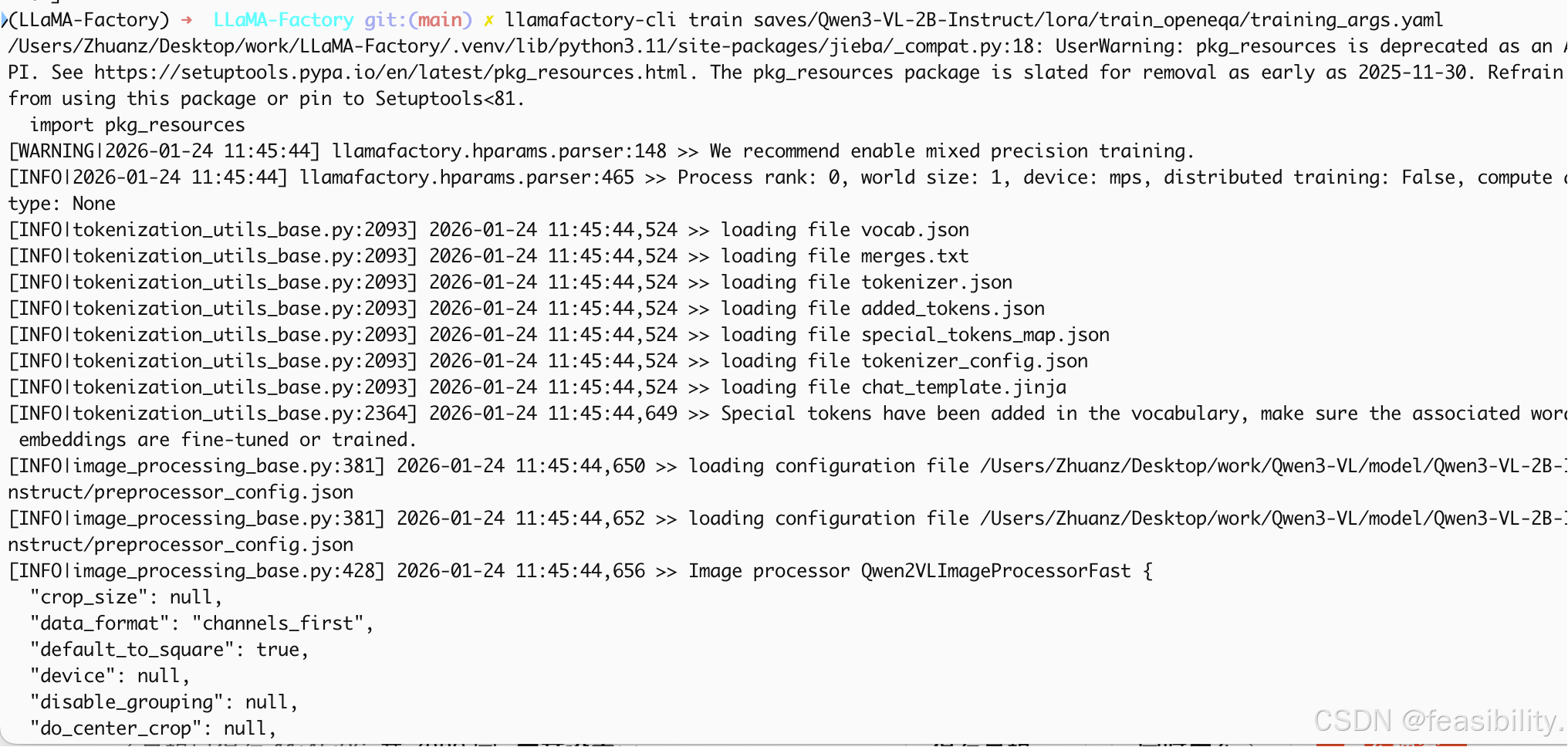
可以看出确实是恢复中断训练了
第一次进入验证阶段
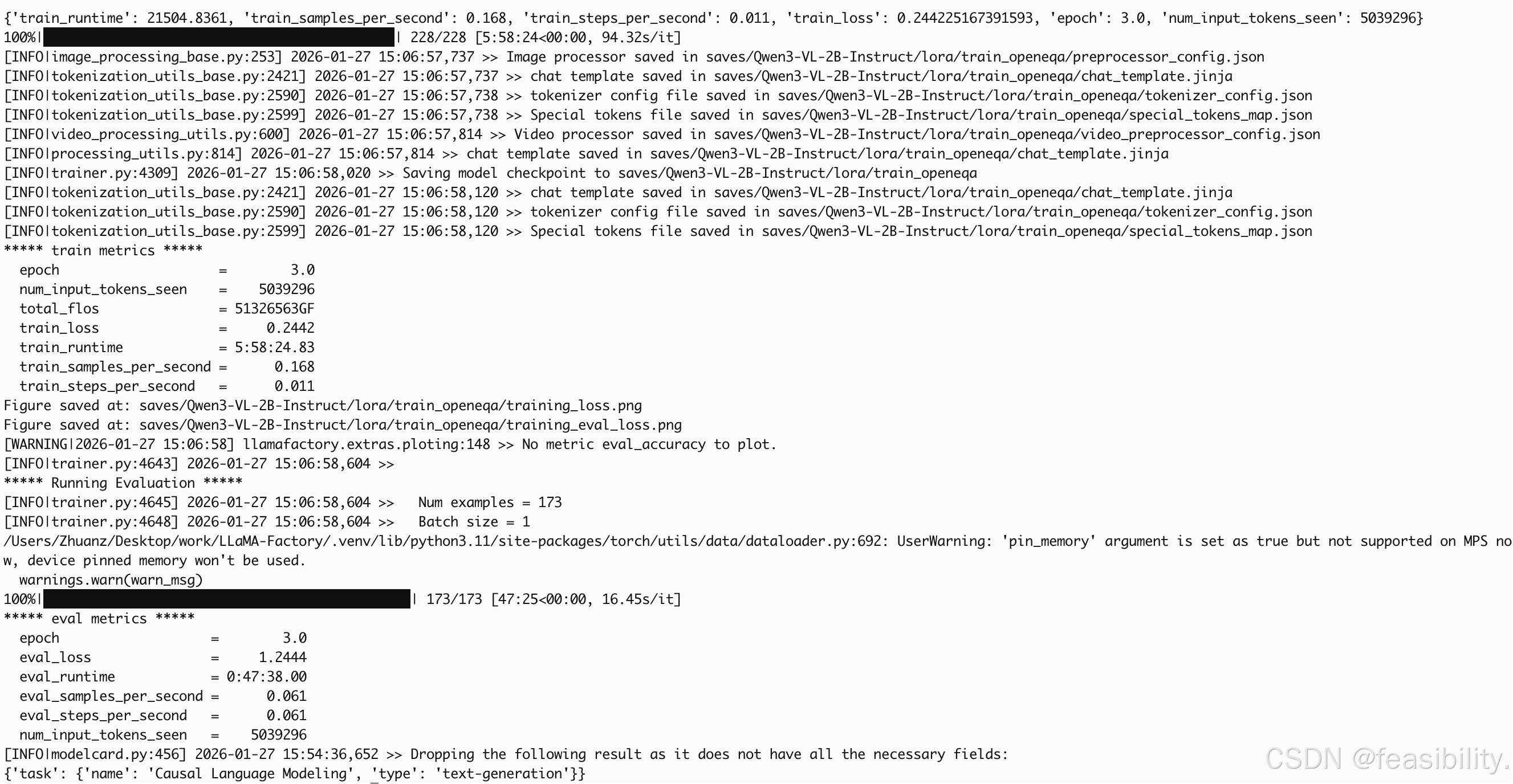
 训练结束
训练结束
观察图像
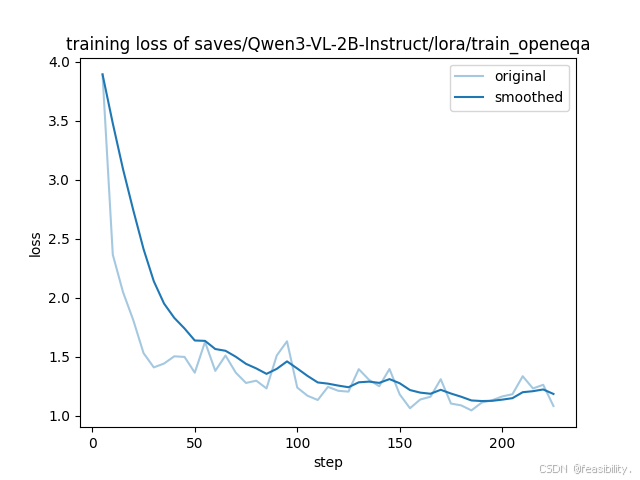
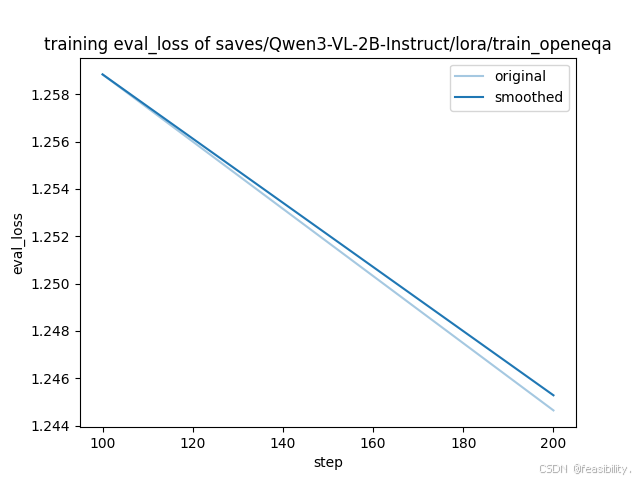
根据训练-验证结果,可以发现Qwen3-VL-2B-Instruct 在 Open-EQA 多模态小样本训练-验证集的训练阶段的表现:收敛充分,拟合效果优异
-
损失下降趋势显著:训练损失从初始近 4.0 的高值快速下降,最终稳定在 1.0 左右区间,平均训练损失低至 0.2442。
-
拟合状态稳定:平滑后的损失曲线无明显震荡或回升,说明模型对多模态特征的提取与文本生成的协同能力得到持续优化,参数更新已进入收敛尾声(学习率最终衰减至 3.796e-08)。
-
训练过程安全:梯度范数(2.3898)处于合理区间,未出现梯度爆炸或消失问题,训练过程稳定可靠。
而Qwen3-VL-2B-Instruct 在 Open-EQA 多模态小样本训练-验证集的验证阶段的表现:泛化能力暂稳,但验证密度与样本量需优化
-
验证损失平稳下降:验证损失从 1.258 平稳下降至最终 1.2444,全程无上升趋势,结合训练损失的收敛性,可初步判断模型未出现过拟合。
-
结论的局限性:受限于仅 3 次验证的低频率,以及 Open-EQA 验证集(测试集仅为训练数据的 1.25%)的极小样本量,小规模可能掩盖潜在的过拟合风险,当前 “泛化能力暂稳” 的结论存在一定不确定性,需在测试集的评估来进一步佐证泛化能力。若增加验证频率(如每 50 步验证一次),可能捕捉到更细微的损失波动。
3.3测试评估
创建saves/Qwen3-VL-2B-Instruct/lora/eval_openeqa目录,并建立eval_args.yaml,内容如下,其中do_predict设置为true代表评估测试,注意要改适配器路径adapter_name_or_path、基座模型路径model_name_or_path和是融合模型路径output_dir
adapter_name_or_path: saves/Qwen3-VL-2B-Instruct/lora/train_openeqa/checkpoint-228
cutoff_len: 2048
dataset_dir: data
ddp_timeout: 180000000
do_predict: true
eval_dataset: open_eqa_test
finetuning_type: lora
flash_attn: auto
max_new_tokens: 128
max_samples: 99999
model_name_or_path: /Users/Zhuanz/Desktop/work/Qwen3-VL/model/Qwen3-VL-2B-Instruct
output_dir: saves/Qwen3-VL-2B-Instruct/lora/eval_openeqa
per_device_eval_batch_size: 2
predict_with_generate: true
preprocessing_num_workers: 4
quantization_method: bnb
report_to: none
stage: sft
temperature: 0.2
template: qwen3_vl_nothink
top_p: 1.0
trust_remote_code: true
参数详细说明如下:
1)模型加载配置
| 参数 | 设置值 | 说明 |
|---|---|---|
model_name_or_path |
/Users/.../Qwen3-VL-2B-Instruct |
基座模型路径(与训练一致) |
adapter_name_or_path |
.../checkpoint-228 |
加载训练的LoRA权重(第228步检查点) |
finetuning_type |
lora |
指定为LoRA模式(用于正确加载适配器) |
trust_remote_code |
true |
允许执行模型仓库自定义代码 |
quantization_method |
bnb |
4Bit量化(BitsAndBytes),降低显存占用约60-70% |
flash_attn |
auto |
自动启用Flash Attention加速推理 |
2)数据与评估配置
| 参数 | 设置值 | 说明 |
|---|---|---|
eval_dataset |
open_eqa_test |
测试集(训练时用train_val,推理换test) |
dataset_dir |
data |
数据集目录路径 |
max_samples |
99999 |
最大评估样本数(全量测试) |
cutoff_len |
2048 |
最大输入长度(与训练保持一致) |
preprocessing_num_workers |
4 |
预处理进程数(比训练时高,加速数据加载) |
per_device_eval_batch_size |
2 |
推理批次大小(受显存限制) |
3)生成参数配置
| 参数 | 设置值 | 影响与特点 |
|---|---|---|
max_new_tokens |
128 |
最大生成长度(限制简短回答,防冗长) |
temperature |
0.2 |
低温度(确定性生成,减少随机性,适合QA任务) |
top_p |
1.0 |
Top-p采样(1.0=不限制,配合temp=0.2使用近似贪婪解码) |
predict_with_generate |
true |
启用自回归生成(非仅分类头输出) |
template |
qwen3_vl_nothink |
必须与训练模板一致(直接回答模式) |
do_predict |
true |
执行预测生成(非训练) |
4)系统配置
| 参数 | 设置值 | 说明 |
|---|---|---|
output_dir |
.../eval_openeqa |
推理结果输出目录(存生成文本、metrics) |
stage |
sft |
阶段标识(SFT模型推理) |
report_to |
none |
不上传至外部监控平台 |
ddp_timeout |
180000000 |
分布式超时(保留但单卡推理时不影响) |
执行llamafactory-cli train saves/Qwen3-VL-2B-Instruct/lora/eval_openeqa/eval_args.yaml
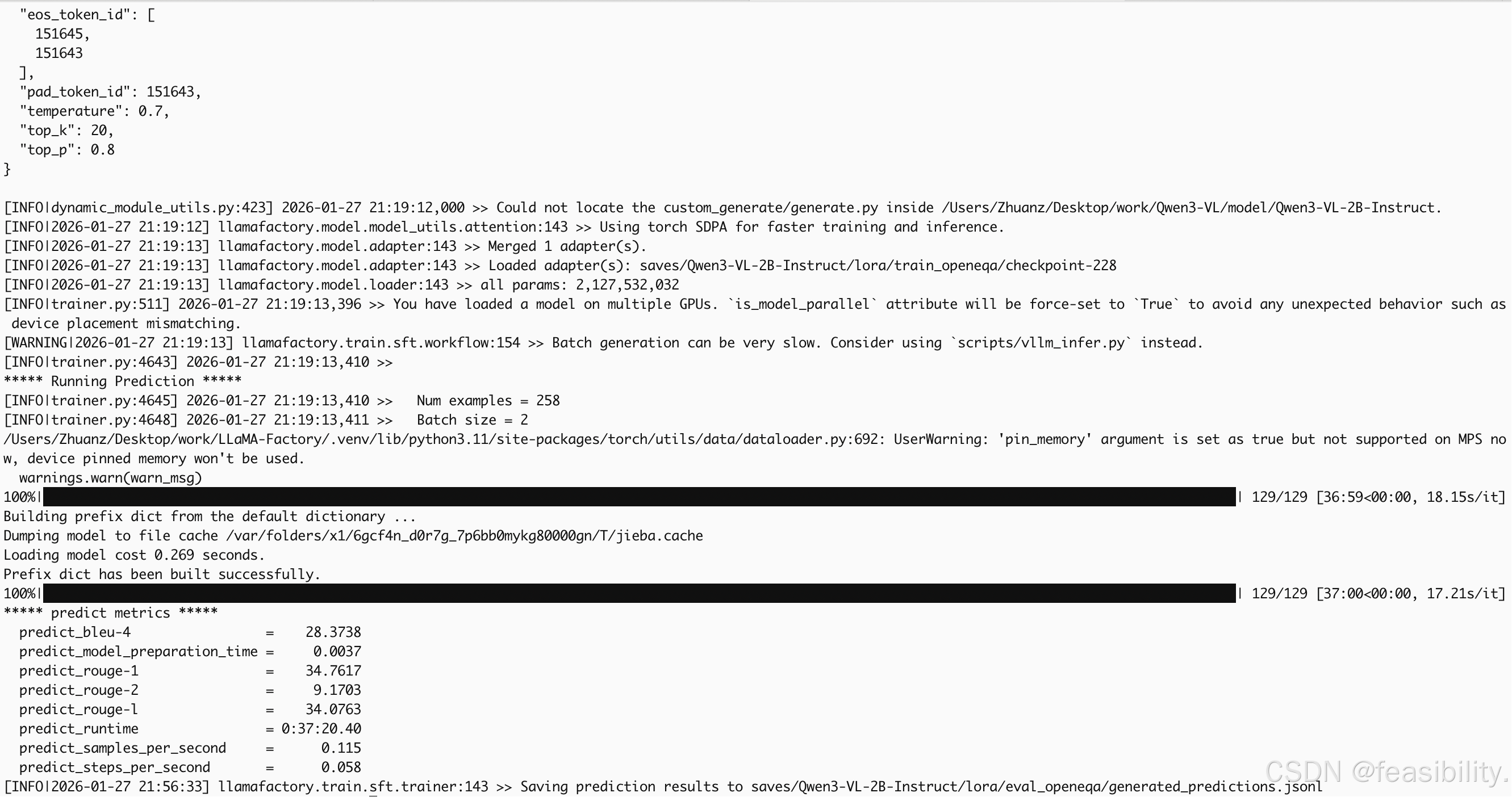
采用生成任务经典指标完成量化评估,Llama-Factory框架自动加载结巴分词适配中英混合场景,指标数值符合具身智能多模态问答的任务特征,验证了 LoRA 微调的有效性。各指标简单释义及测试结果如下:
| 评估指标 | 数值 | 简单含义 |
|---|---|---|
| BLEU-4 | 28.37 | 四字粒度,生成答案与标准答案的语义贴合度 |
| ROUGE-1 | 34.76 | 单字粒度,答案核心词汇的匹配能力 |
| ROUGE-2 | 9.17 | 双字粒度,答案短语的匹配能力(具身问答句式灵活,该指标偏低为正常现象) |
| ROUGE-L | 34.08 | 最长序列,答案整体结构与标准答案的相似性 |
整体来看,微调后模型可有效理解具身智能场景下的多图视觉信息与中英混合指令,实现跨模态的答案生成,满足具身智能问答的基础需求。
本次具身智能多模态推理的性能偏慢,核心耗时数据如下:
-
总推理耗时:37 分 20 秒;
-
样本处理速率:0.115 样本 / 秒;
-
单步推理耗时:17~18 秒 / 步。
性能瓶颈核心原因:① 具身智能场景固有耗时:单样本 8 张图片的视觉特征提取、多图融合跨模态计算量远高于纯文本任务;② 脚本与环境限制:LLaMA-Factory 原生脚本无批量优化,Mac MPS 对大模型多模态任务的加速能力有限,且不支持 pin_memory 内存优化。
3.4融合模型导出
创建saves/Qwen3-VL-2B-Instruct/lora/merge目录,并建立merge_openeqa.yaml,路径同样需要修改,内容如下,
### model
model_name_or_path: /Users/Zhuanz/Desktop/work/Qwen3-VL/model/Qwen3-VL-2B-Instruct
adapter_name_or_path: /Users/Zhuanz/Desktop/work/LLaMA-Factory/saves/Qwen3-VL-2B-Instruct/lora/train_2025-12-29-19-22-59
template: qwen3_vl_nothink
finetuning_type: lora
trust_remote_code: true
### export
export_dir: /Users/Zhuanz/Desktop/work/LLaMA-Factory/saves/Qwen3-VL-2B-Instruct/lora/merge
export_size: 2 #导出模型分片(shard)的单文件大小上限,单位是 GB
export_device: auto #导出设备
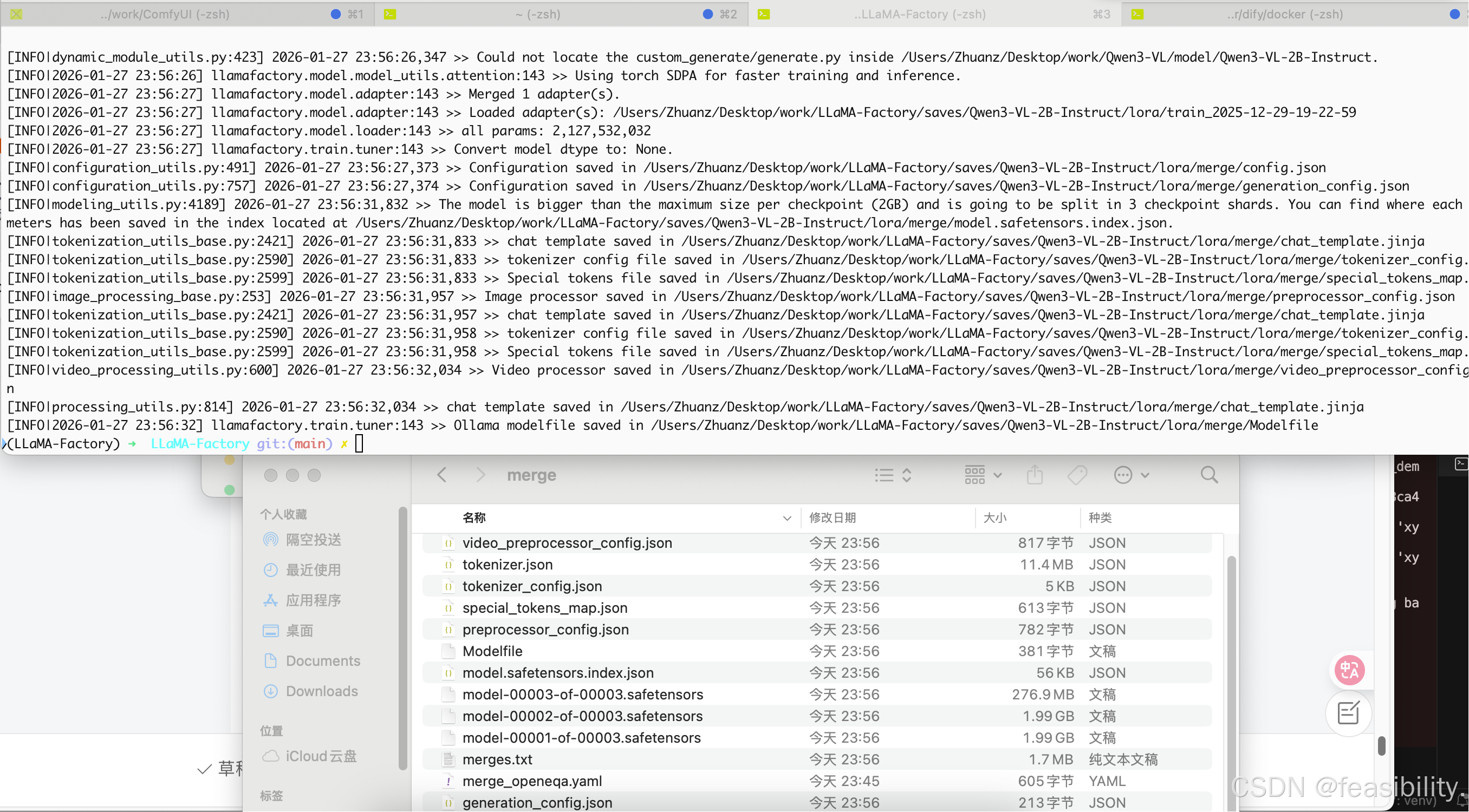
export_legacy_format: false #true:导出 .bin(旧/legacy) false:导出 .safetensors(默认/推荐)将微调产生的适配器和原始模型融合,在终端执行llamafactory-cli export saves/Qwen3-VL-2B-Instruct/lora/merge/merge_openeqa.yaml
3.5对话界面展示
执行llamafactory-cli webui,自动打开页面http://localhost:7860/,设置模型路径model path(因为已经融合了模型所以不设置适配器路径chechpoint path),选择对话模式chat,这里量化和推理框架选择等暂时不做演示
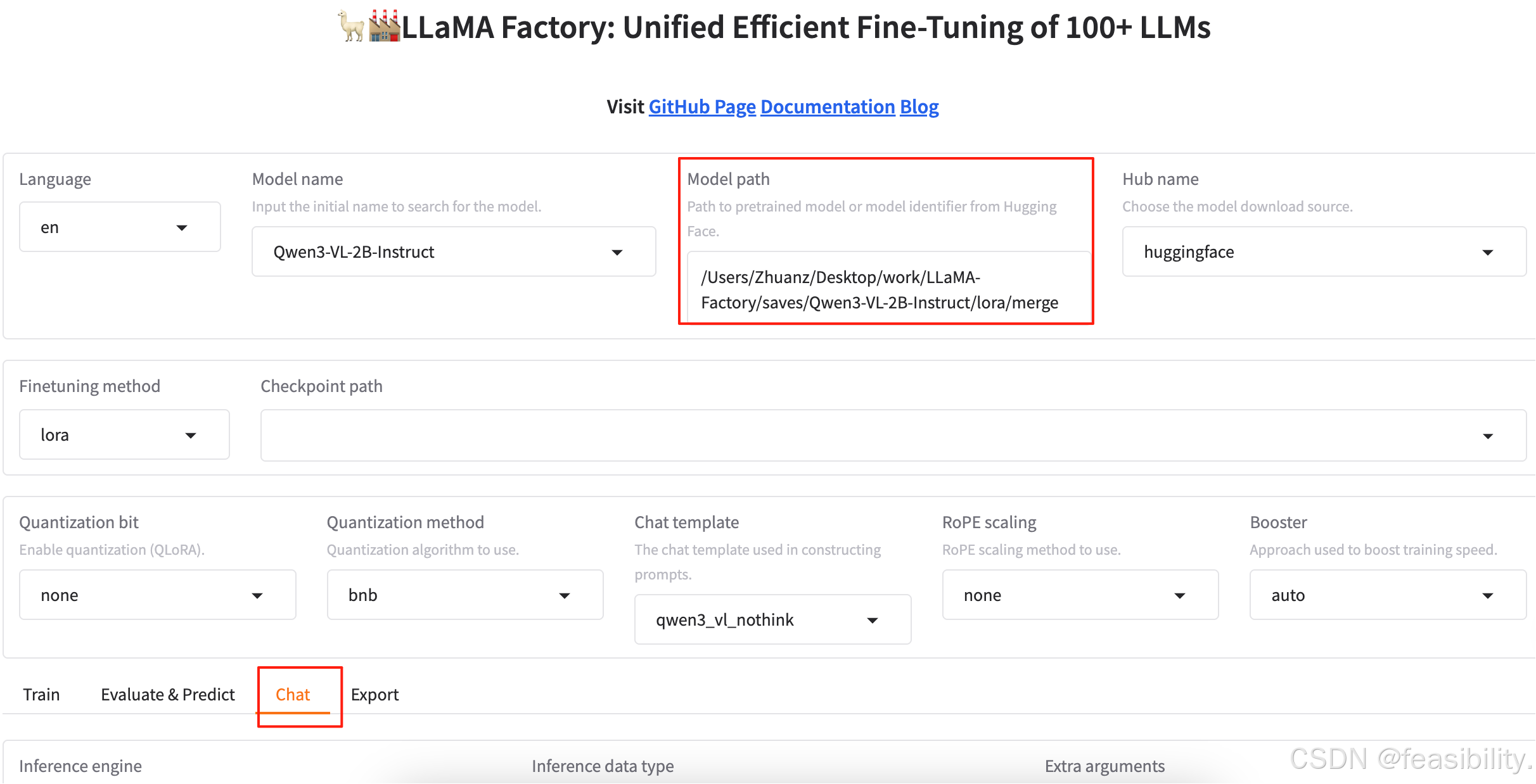
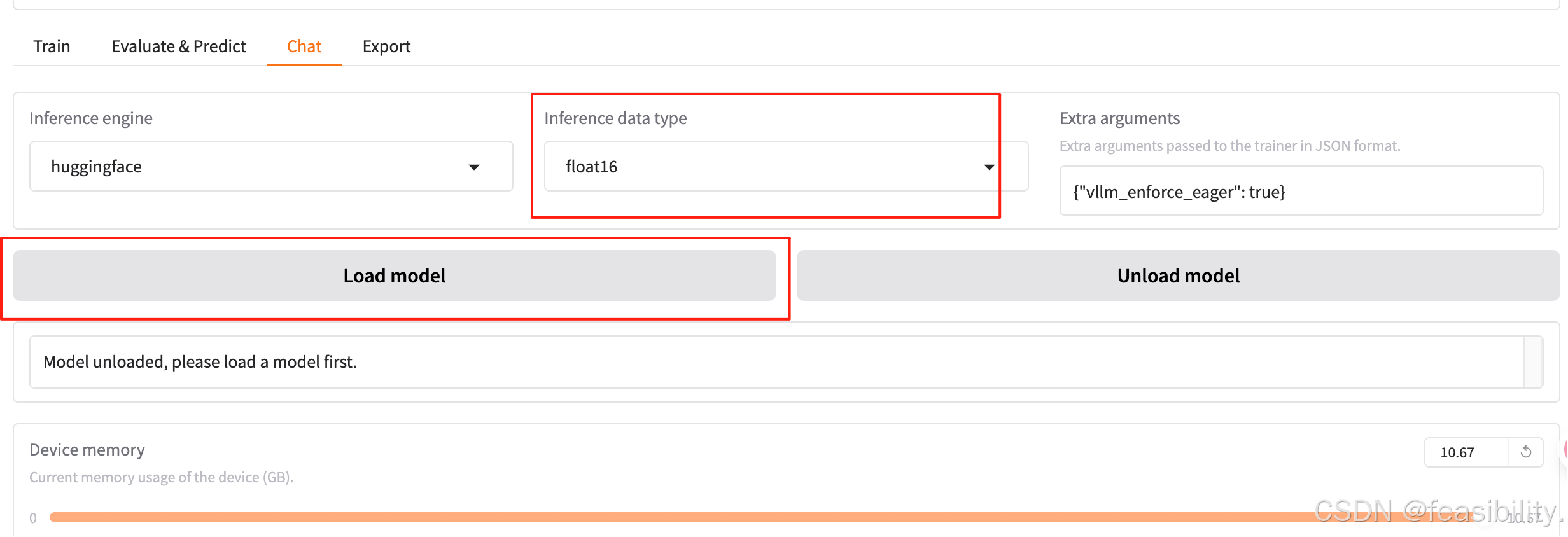
选择半精度,点击加载模型
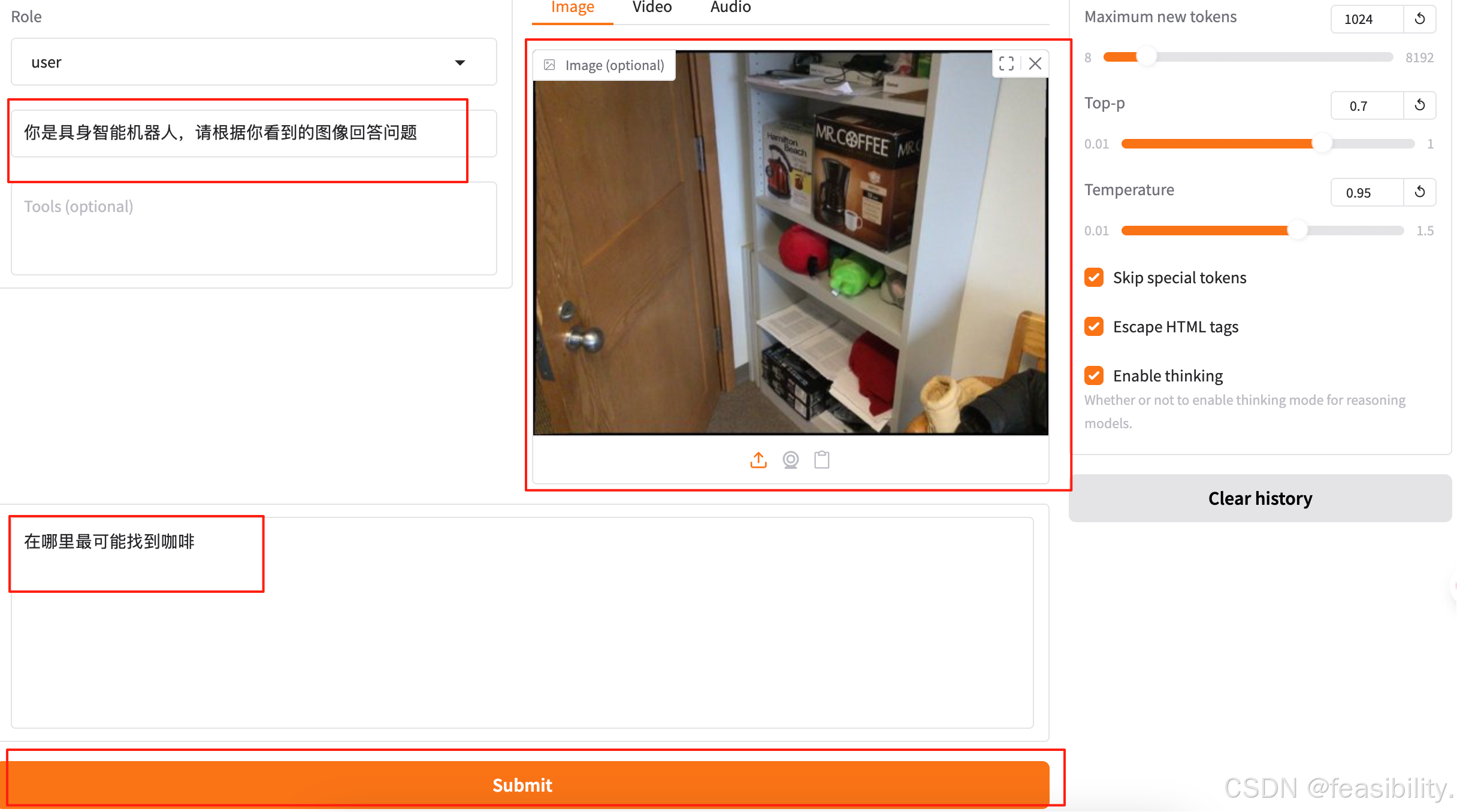
设置系统提示词、用户提示词和图像,点击submit提交,当然你也可以设置回答长度、温度和是否启用思考模式等配置。
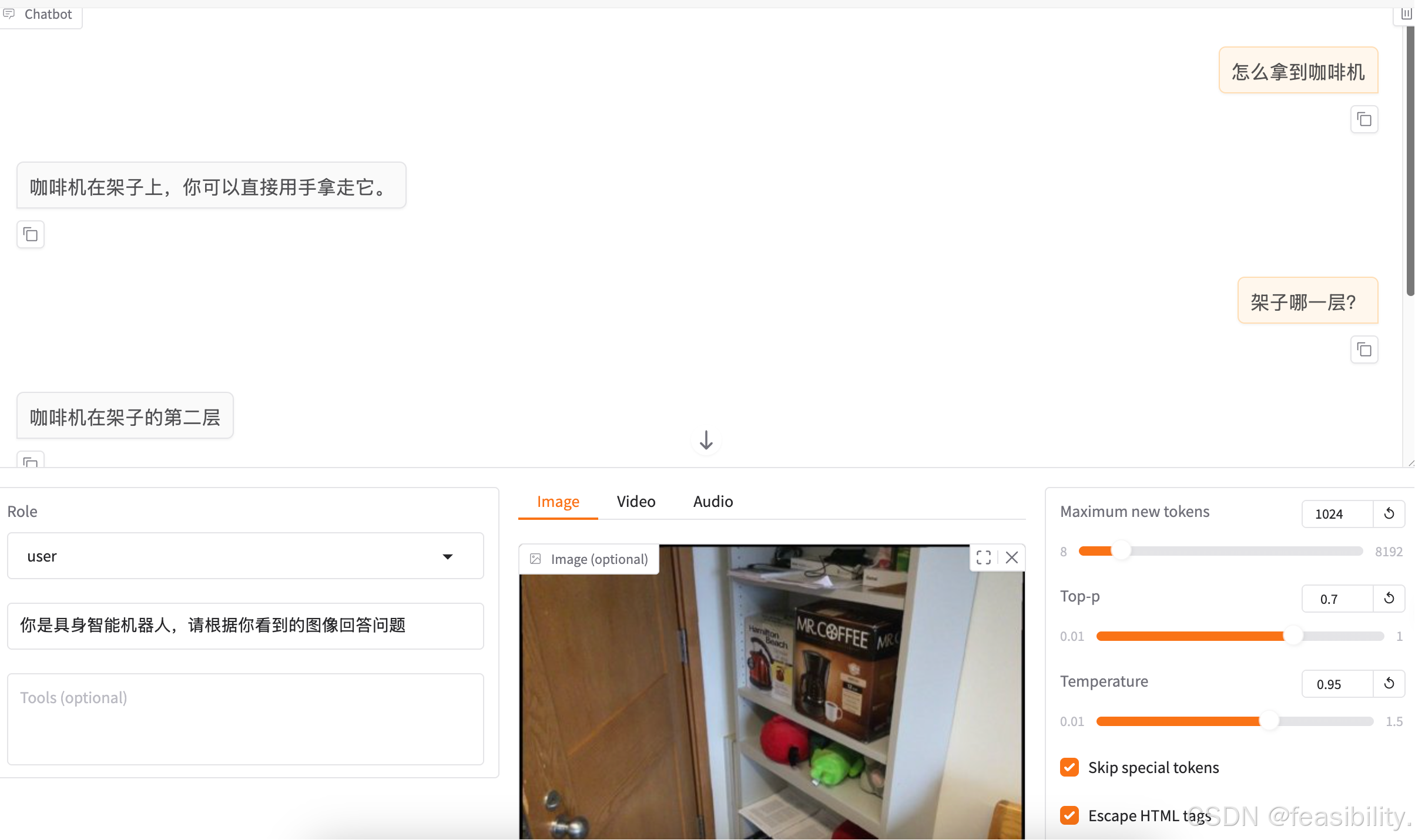
3.6推理部署API服务
创建saves/Qwen3-VL-2B-Instruct/lora/infer目录,并建立saves/Qwen3-VL-2B-Instruct/lora/infer/infer_openeqa.yaml,路径同样需要修改,如果没有融合也可以填适配器路径,内容如下,
### model
model_name_or_path: /Users/Zhuanz/Desktop/work/LLaMA-Factory/saves/Qwen3-VL-2B-Instruct/lora/merge
template: qwen3_vl_nothink
finetuning_type: lora
trust_remote_code: true指定端口号,部署api服务,执行API_PORT=8000 llamafactory-cli api saves/Qwen3-VL-2B-Instruct/lora/infer/infer_openeqa.yaml
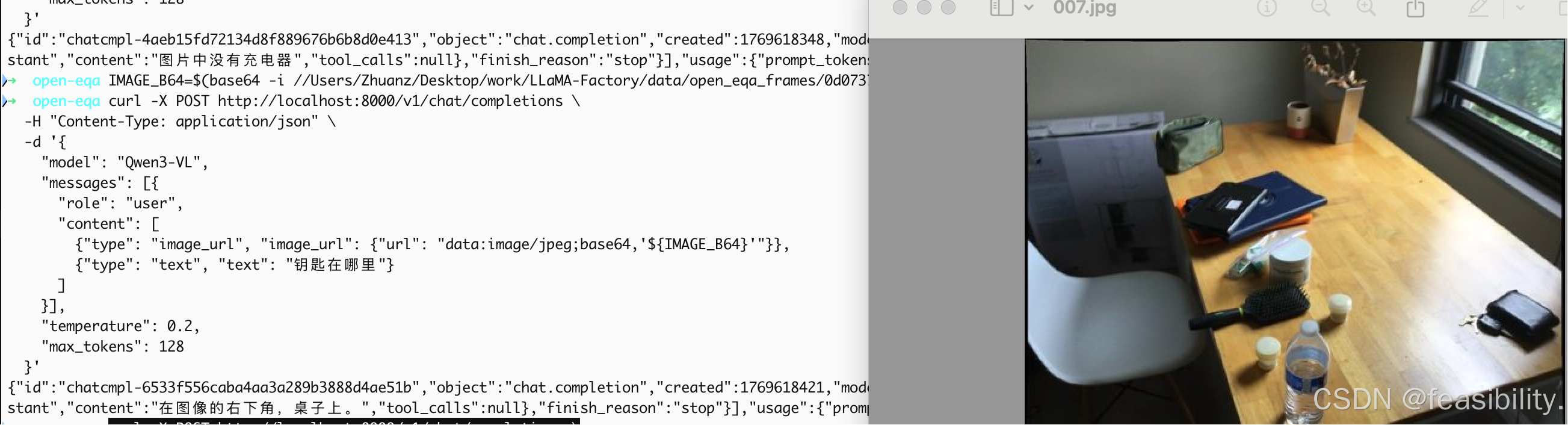
调用服务有两种方法
1)curl命令行
# 先安装 base64 工具(macOS/Linux 自带)
IMAGE_B64=$(base64 -i /path/to/your/image.jpg)
curl -X POST http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen3-VL",
"messages": [{
"role": "user",
"content": [
{"type": "image_url", "image_url": {"url": "data:image/jpeg;base64,'${IMAGE_B64}'"}},
{"type": "text", "text": "这张图片里有什么?"}
]
}],
"temperature": 0.2,
"max_tokens": 128
}'执行效果
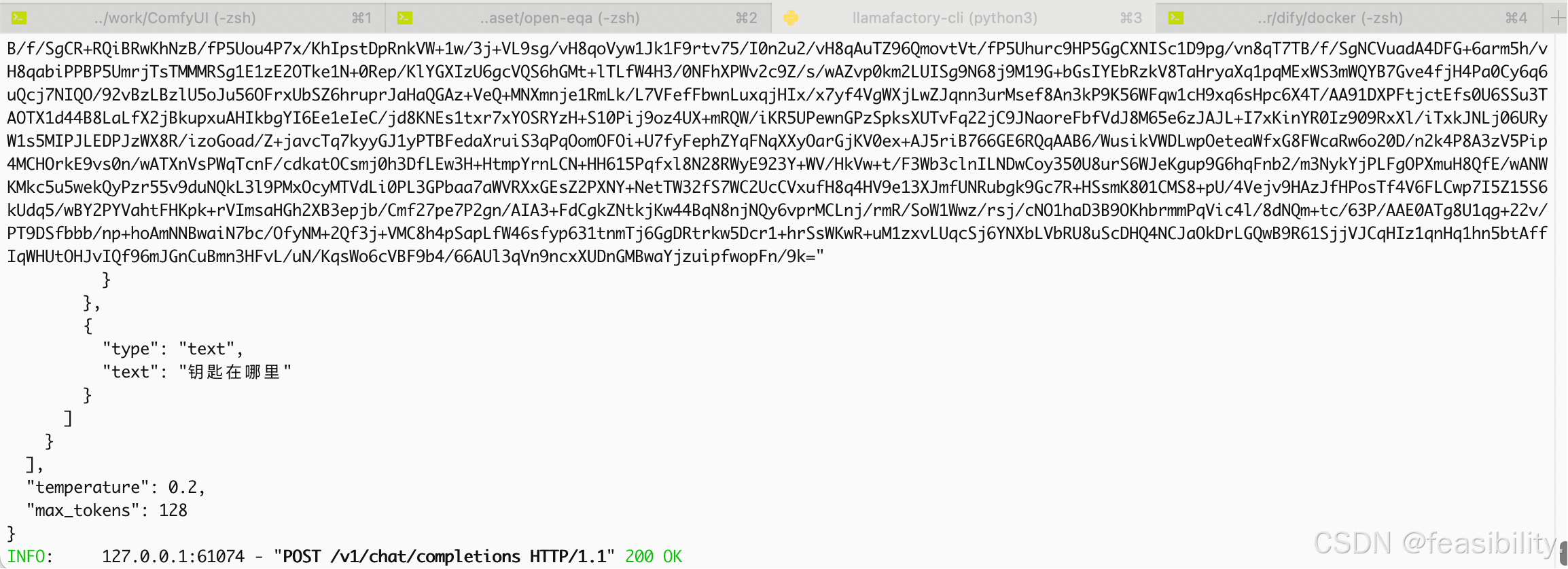
2)客户端
import base64
import requests
from pathlib import Path
# 配置
API_URL = "http://localhost:8000/v1/chat/completions"
IMAGE_PATH = r"/Users/Zhuanz/Desktop/work/LLaMA-Factory/data/open_eqa_frames/0dbc7b51e8042ff1/000.jpg" # 你的本地图像路径
# 1. 将本地图像转为 Base64
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
image_base64 = encode_image(IMAGE_PATH)
# 2. 构造多模态消息(OpenAI 兼容格式)
payload = {
"model": "Qwen3-VL-2B-Instruct", # 可任意填写,LLaMA-Factory会忽略
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{image_base64}"
}
},
{
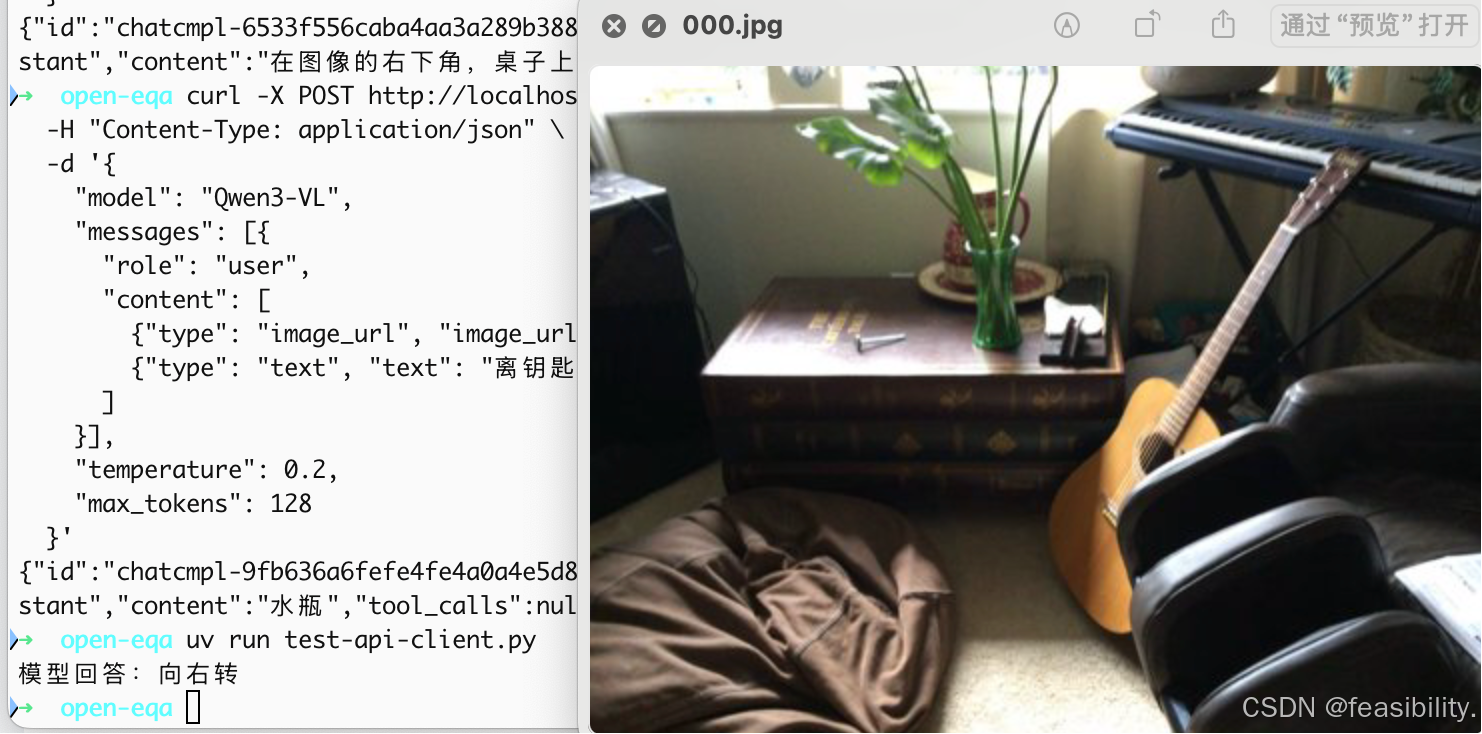
"type": "text",
"text": "你是具身智能机器人,应该向左转还是向右转才能拿到吉他?"
}
]
}
],
"temperature": 0.2,
"max_tokens": 128,
"top_p": 1.0
}
# 3. 发送请求
response = requests.post(API_URL, json=payload)
result = response.json()
# 4. 提取回答
if "choices" in result:
answer = result["choices"][0]["message"]["content"]
print(f"模型回答:{answer}")
else:
print(f"错误:{result}")执行代码,查看效果
创作不易,禁止抄袭,转载请附上原文链接及标题
参考教程:https://llamafactory.readthedocs.io/zh-cn/latest/getting_started/data_preparation.html#id13

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 56
56 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)