从语音到策略——ASR + 大语言模型驱动的辩论对话系统设计实践
在“辩核 AI 具身辩论数字人系统”中,对话系统不仅要“听懂用户在说什么”,还要“理解这句话在辩论结构中的位置”,并据此作出具有策略性的回应。本文将完整拆解系统中从语音输入到大语言模型决策,再到输出协同虚拟人表达的核心工程链路,重点说明其设计思路与关键实现。
目录
前言
在多数 AI 应用中,“对话系统”往往被简化为“输入一句话,返回一段文本”。然而,当应用场景从日常闲聊转向辩论训练,这种简单模式便显得力不从心。辩论并不是信息问答,而是一种具有明确目标、立场约束和规则限制的语言对抗过程。
在“辩核 AI 具身辩论数字人系统”中,对话系统不仅要“听懂用户在说什么”,还要“理解这句话在辩论结构中的位置”,并据此作出具有策略性的回应。本文将完整拆解系统中从语音输入到大语言模型决策,再到输出协同虚拟人表达的核心工程链路,重点说明其设计思路与关键实现。
1 引言:辩论场景对 AI 对话的特殊要求
1.1 不是聊天,而是对抗与训练
与通用聊天机器人不同,辩论型对话系统的目标并非让用户“聊得开心”,而是通过对抗与反馈帮助用户提升表达与逻辑能力。这意味着 AI 的回复需要具备明确的功能性,例如反驳、追问、总结或施压。
在这种场景下,对话系统的“正确性”并不等同于“语义通顺”,而更接近于“是否符合辩论训练目标”。
1.2 上下文、立场与规则的重要性
辩论对话至少同时受到三类约束:其一是上下文连续性,其二是预设立场,其三是辩论规则。例如,AI 在正方立场下不应自我反驳,在质询阶段不应给出完整总结。这些约束如果不能在系统层面显性建模,就会完全依赖大模型的隐性推理,结果往往不稳定。
因此,辩论型对话系统必须从“工程设计”层面引入结构化控制。
2 语音识别系统设计
2.1 腾讯云 ASR 的选型原因
在语音输入环节,系统选择了腾讯云实时语音识别(ASR)服务,主要基于以下工程考量:
- 中文识别准确率在复杂口语场景下表现稳定
- 支持流式识别,适合长时间连续发言
- 提供成熟的语音活动检测能力,减少无效音频处理
相较于离线识别或简单录音上传模式,实时 ASR 能够显著降低用户输入到系统响应之间的整体延迟。
2.2 实时转写与语音活动检测
在辩论训练中,用户发言往往存在停顿、重音和修正。系统通过语音活动检测(VAD)判断用户是否仍在发言,从而避免过早提交不完整语句。
实时转写结果会被暂存,并在检测到“发言结束”事件后统一提交至后续处理流程。
2.3 useAsr 的生命周期管理
在前端工程中,ASR 功能被封装为 useAsr 组合式模块,其生命周期与训练回合紧密绑定。初始化、启动、暂停与销毁都通过显式接口控制,确保语音识别不会在错误的时机占用资源或产生干扰。
这种生命周期管理方式,也为后续引入多 ASR 服务或离线识别方案提供了扩展空间。
3 输入融合机制
3.1 语音输入与文本输入的统一处理
系统并未将语音与文本视为两条独立输入通道,而是在 ASR 结果生成后,将其统一转化为标准文本输入结构。这样一来,大语言模型服务层无需感知输入来源,显著降低了复杂度。
这一设计使得用户既可以通过语音辩论,也可以在调试或教学场景下直接输入文本。
3.2 标点、纠错与人工干预
语音识别天然存在误差,尤其在专业术语或高速表达场景下。系统在提交至大模型前,允许对转写文本进行最小程度的人工干预,例如补充标点或修正明显识别错误。
在工程实践中,这一步并非为了追求“完美文本”,而是避免低质量输入直接影响后续策略生成。
4 大语言模型服务封装(LlmService)
4.1 消息结构设计
LlmService 是整个对话系统的中枢,其核心任务是将“辩论语境”转化为大模型可理解的消息结构。每一条消息不仅包含内容文本,还包括角色、阶段、立场等元信息。
通过结构化消息设计,系统能够在不依赖复杂 prompt 拼接的情况下,对模型行为施加明确约束。
4.2 系统提示词与模式切换
系统提示词并非固定不变,而是根据当前训练模式动态切换。例如,在“模拟对手”模式下,提示词强调反驳与追问;在“点评指导”模式下,则强调总结与反馈。
这种模式切换能力,使同一套对话系统能够服务于多种训练目标,而无需更换模型。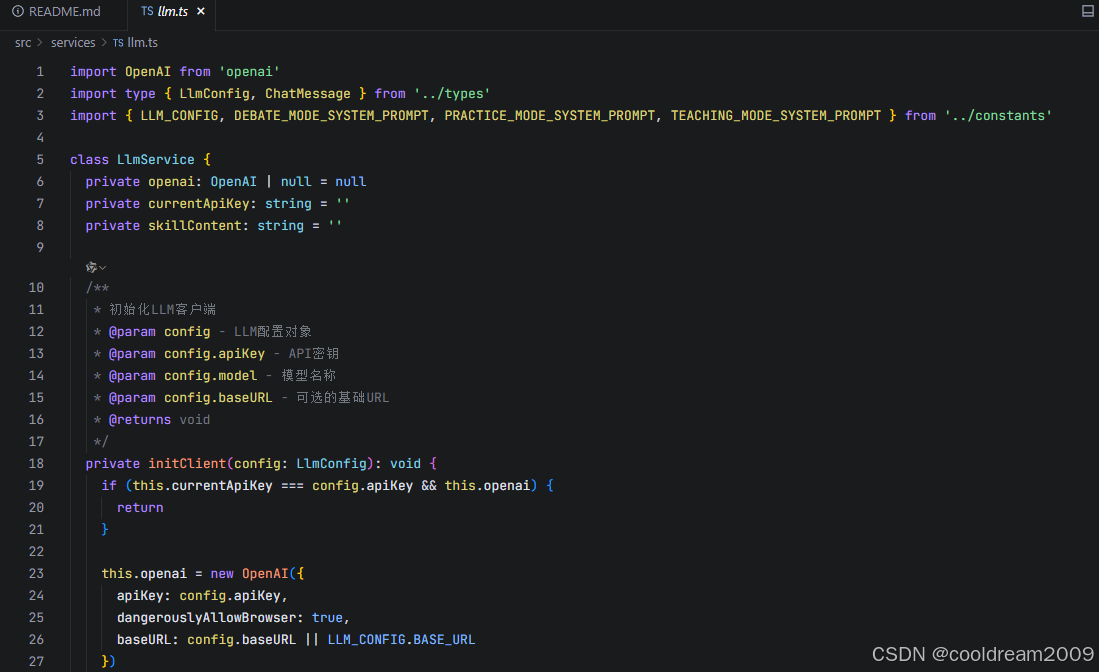
4.3 流式响应处理
为了降低等待感,LlmService 采用流式响应方式接收模型输出。生成的文本片段会被逐步推送给前端,而非等待完整回复结束。
流式处理不仅提升了交互体验,也为后续的语音合成与虚拟人驱动提供了时间优势。
5 上下文与记忆管理
5.1 辩论历史的组织方式
辩论对话的历史记录并非简单的线性对话列表,而是按照回合、角色与阶段进行组织。这样做的目的是在构建上下文时,能够有选择地保留关键内容,避免无关信息干扰模型判断。
5.2 控制上下文长度与信息密度
大模型的上下文窗口有限,系统通过摘要与裁剪策略控制输入长度,只保留对当前决策有价值的信息。这一过程本质上是“上下文工程”,而非简单的截断。
在长期训练中,这种控制对于保持回复质量至关重要。
6 流式输出与前端协作
6.1 实时展示回复内容
前端在接收到流式文本后,会即时渲染当前生成内容,使用户能够“边听边看”。这种实时反馈显著提升了系统的响应感,减少了用户对等待的焦虑。
6.2 同步驱动虚拟人播报
生成的文本片段会同步送入语音合成模块,并由虚拟人进行具身表达。通过时间轴对齐机制,系统尽量保证文字、语音与动画之间的同步一致。
这种多模态协作,是辩论对话系统区别于普通聊天应用的关键特征之一。
7 小结
从语音识别到大语言模型策略生成,再到多模态输出协同,辩论对话系统的本质是一条高度工程化的决策链路。真正的难点并不在于“能否调用模型”,而在于如何将模型能力嵌入到一个受规则、受目标约束的训练系统中。
本文所述的设计思路与实现经验,同样适用于客服模拟、面试训练、教学辅助等其他 AI 应用场景。只要对“对话目标”有清晰定义,对话系统就不再是简单的接口封装,而是可持续演进的核心能力模块。
参考资料
- 腾讯云实时语音识别(ASR)官方技术文档
- 大语言模型对话系统设计相关工程实践文章
- 流式推理与实时交互系统架构资料
- 辩论训练与人机对抗研究相关论文

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 13
13 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)