北大团队发布 IndoorUAV:首个大规模室内无人机视觉语言导航基准
「GPT-4o做大脑,VLA做小脑」
目录
当我们还在讨论人形机器人如何走进家庭时,北大团队已经将目光投向了更具挑战性的室内低空。相比于空旷的室外飞行,室内环境狭窄、障碍物密集,对无人机的空间感知能力提出了极高要求。
这项工作填补了具身智能领域的一块重要拼图。它不仅构建了包含 1000+ 丰富场景的仿真环境,更通过 5 万余条高质量 3D 飞行轨迹与任务,一举打破了室内 3D 导航训练数据长期匮乏的困境。
这一目前规模最大、场景最丰富的基准,让我们看到了未来室内搜救、仓库巡检甚至家庭服务无人机的雏形。
论文中展示的大脑(GPT-4o分解任务)+小脑(VLA执行动作)的分层架构,或许正是通往通用具身智能的必经之路。从二维地面到三维空间,AI 对物理世界的理解正在发生质的飞跃。
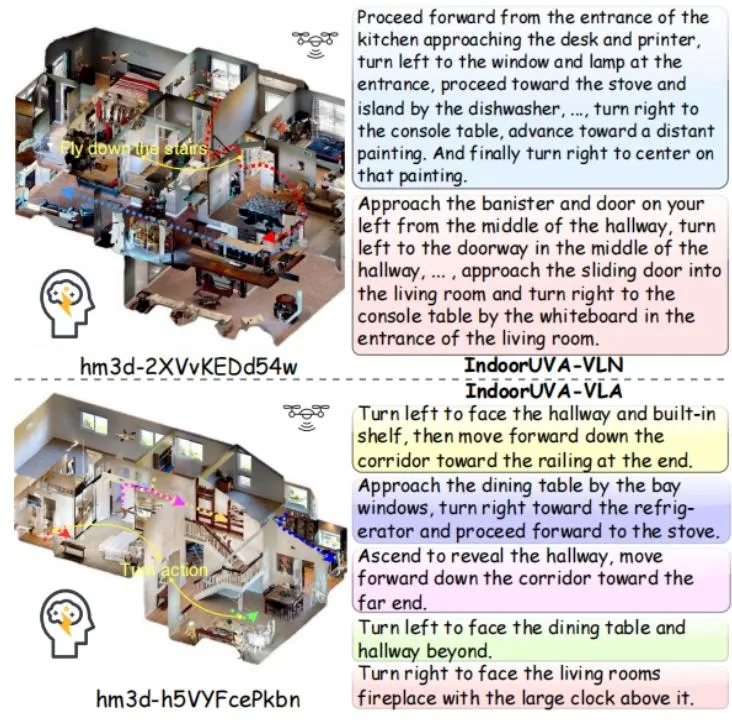
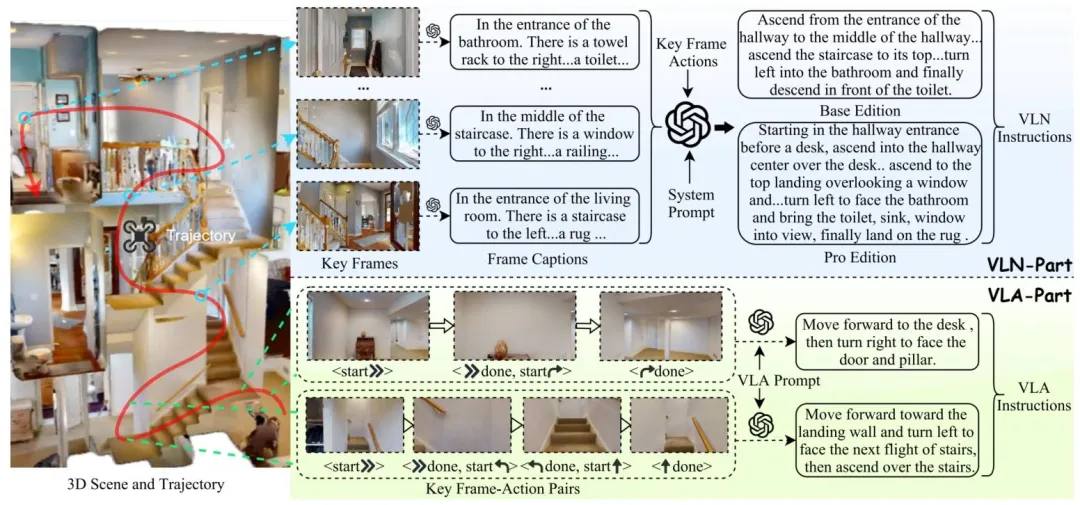
图1| IndoorUAV-VLN(上)与 IndoorUAV-VLA(下)数据集示意图。上图展示了包含复杂任务与长轨迹的长视距 VLN 任务;下图展示了仅包含 1-3 个动作、专注于精细操控的短视距 VLA 任务。
01 主要方法
为了解决室内无人机在长视距导航中任务复杂、路径过长的问题,论文提出了一种名为 IndoorUAV-Agent 的分层导航架构。该架构巧妙地结合了大语言模型(LLM)的语义推理能力和视觉-语言-动作(VLA)模型的动作控制能力,采用了高层规划 + 底层执行 + 时序衔接的策略。
1.1 高层规划:基于 LLM 的任务分解
在导航的初始阶段,Agent 首先启用 GPT-4o 作为高层大脑。它的核心任务是处理语义复杂的长视距任务,例如“飞出厨房,沿着走廊走到底,进入右边的第二个房间”。
系统将长文本输入 GPT-4o,利用其强大的语义推理能力,将宏观目标拆解为一系列短视距的 VLA 子任务。每一个子任务通常只包含 1 到 3 个具体的子动作(如“向前飞向桌子”、“向右转对准门口”),从而将复杂的逻辑推理问题简化为一系列可执行的短程目标。
1.2 底层执行: 基于 的VLA控制
的VLA控制
一旦任务被拆解清晰,具体的飞行控制则交给底层小脑,该小脑由一个经过微调的模型构成。这是一个基于流匹配的策略网络,能够实现高达 50Hz 的连续控制生成。
模型接收当前的视觉观测、分解后的子任务以及当前状态,直接输出连续的无人机控制信号。其动作预测公式如下:
其中,为初始观测,
为当前时刻观测,
为当前的自然语言任务,
为当前的三维坐标及偏航角状态。模型会一次性预测未来
个时间步的轨迹状态,确保了飞行动作的平滑性。
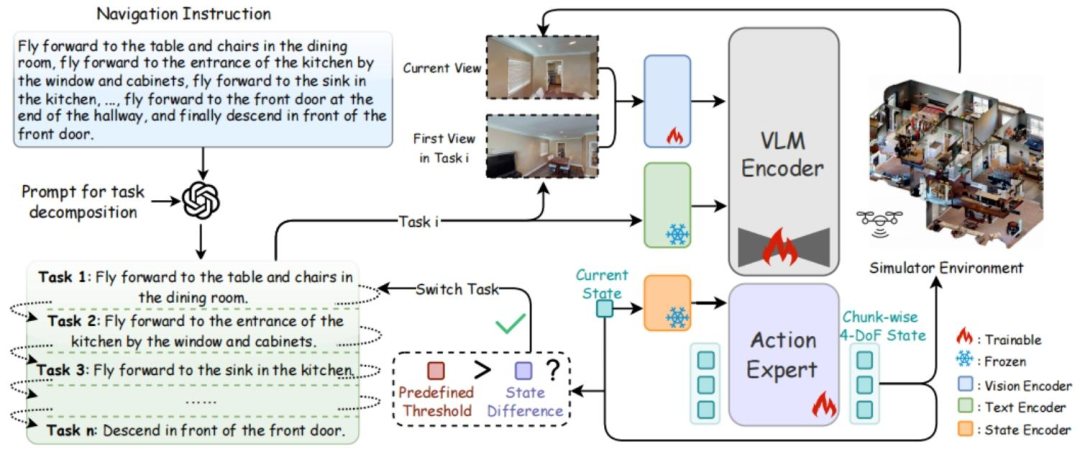
图2| 基于 LLM 的任务分解(左)与VLA 动作执行网络(右)。 GPT-4o 将复杂的长任务智能拆解为若干个简短、明确的子任务(Task 1, Task 2...),每个子任务仅对应简单的飞行动作。底层模型接收当前视觉画面与分解后的短任务,通过 VLM 编码器与Action Expert网络,实时输出精准的飞行轨迹。
1.3 时序衔接:子任务的动态切换
为了保证无人机在执行这一系列子任务时不会失忆,IndoorUAV-Agent设计了一套时序衔接机制。系统按顺序处理 GPT-4o 生成的子任务链,重要的是,模型会将上一个子任务预测的最终视觉状态,作为下一个子任务的初始参考帧。
这种设计确保了模型在执行每一个新动作时,都拥有准确的历史上下文参照。它有效缓解了长距离导航中常见的累积误差问题,确保无人机能够像人类一样,完成一个目标后,基于当前位置自然地开启下一个目标。

图3| 长视距导航实例。复杂的跨房间导航被拆解为从卧室起飞、穿过客厅、进入厨房等连续的短程动作,模型通过子任务的串联成功完成了长距离飞行。
02 实验结果
为了验证 IndoorUAV-Agent的有效性,研究团队在两个维度的任务上进行了广泛的基准测试:短视距的动作执行(VLA)和长视距的复杂导航(VLN)。
2.1 定性分析:复杂空间中的精准穿梭
可视化结果直观地展示了IndoorUAV-Agent在狭窄室内环境中的表现。在成功的案例中,可以看到无人机能够精准地理解语义指令。例如,面对指令“Ascend from the entrance... hover above the table... finally descend in front of the fireplace”(从入口上升……悬停在桌子上方……最后降落在壁炉前),IndoorUAV 成功生成了包含垂直爬升、水平移动和避障悬停的复杂飞行轨迹。

图4| IndoorUAV-Agent 导航可视化。 展示了一个成功的长视距导航案例:无人机准确理解了包含多个路标的复杂指令,在客厅、走廊和餐厅之间完成了流畅的穿梭飞行。
2.2 定量分析:任务分解带来的性能跃升
实验数据表明,在面对复杂的长指令时,传统的端到端模型往往力不从心,而引入了大模型进行任务分解的 IndoorUAV-Agent 取得了显著优势。
VLA 任务(短程):经过微调的模型展现了强大的底层控制能力,在简单任务上的成功率达到了46.58%,远超传统的 Seq2Seq 和 CMA 模型(不足 3%)。这证明了高质量的 3D 飞行数据对于训练动作模型至关重要。
VLN 任务(长程):IndoorUAV-Agent在可见环境(Seen)和不可见环境(Unseen)中分别取得了 7.29% 和 5.06% 的成功率,均为最高 。
消融实验:相比于没有使用任务分解、直接使用进行端到端规划的基准模型,IndoorUAV-Agent将成功率分别提升了4.37%(Seen) 和 2.23% (Unseen) 。这一数据直接证明了GPT-4o分解任务 + VLA执行动作 的分层策略,能有效缓解长距离导航中的累积误差。
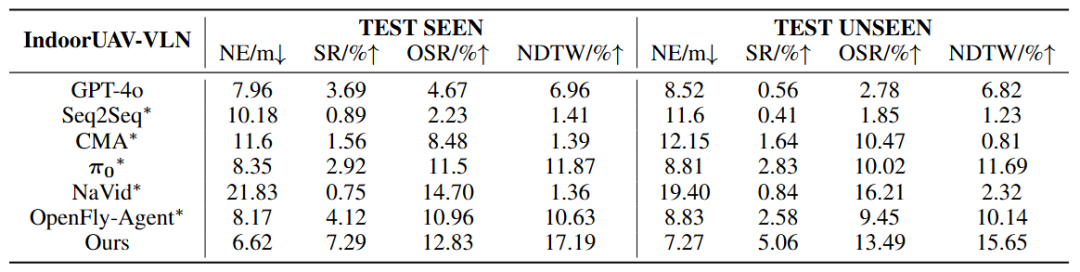
图5| IndoorUAV-Agent 长视距导航基准测试结果。 采用了任务分解策略的IndoorUAV-Agent在成功率 (SR) 和路径加权成功率 (SPL) 上均超越了 NaVid 和 OpenFly 等 SOTA 模型,同时也显著优于未进行分解的基线
03 总结
IndoorUAV-Agent作为由北大团队发布的首个大规模室内无人机视觉语言导航Benchmark,填补了具身智能在室内复杂三维空间的数据空白。该工作不仅开源了包含 1000+ 仿真场景和 5 万余条高质量 3D 飞行轨迹的巨型数据集,还提出了一种大脑(GPT-4o分解任务)+小脑(VLA执行动作)的创新分层架构,成功实现了无人机在狭窄室内环境下的语义理解与精准机动,为未来室内搜救与家庭服务机器人的落地提供了关键的算法与数据底座。
当然,我们也必须正视眼前的技术鸿沟。即便是目前表现最优的模型,其成功率也仅为 7.29%。大量失败案例集中在终点目标识别偏差与长序列决策的误差累积上,这揭示了当前 AI 在处理三维空间复杂导航时仍显吃力。这也间接证明:室内 3D 导航绝非简单的二维延伸,而是一个亟待攻克的硬核难题,这为具身智能社区提供了一个含金量极高的攻坚方向。
论文题目:IndoorUAV: Benchmarking Vision-Language UAV Navigation in Continuous Indoor Environments
论文作者:Xu Liu, Yu Liu, Hanshuo Qiu, Yang Qirong, Zhouhui Lian
论文地址:https://arxiv.org/abs/2512.19024

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 23
23 0
0- 0



 已为社区贡献167条内容
已为社区贡献167条内容

所有评论(0)