GR-Dexter技术报告
25年12月来自字节Seed的论文“GR-Dexter Technical Report”。视觉-语言-动作(VLA)模型实现语言控制的长范围机器人操作,但现有系统大多仅限于机械臂。由于动作空间扩展、手部与物体频繁遮挡以及采集真实机器人数据的成本高昂,将VLA策略扩展到具有高自由度(DoF)灵巧手的双臂机器人仍然面临挑战。本文提出GR-Dexter,一个用于在双臂灵巧手机器人上进行基于VLA通用操
25年12月来自字节Seed的论文“GR-Dexter Technical Report”。
视觉-语言-动作(VLA)模型实现语言控制的长范围机器人操作,但现有系统大多仅限于机械臂。由于动作空间扩展、手部与物体频繁遮挡以及采集真实机器人数据的成本高昂,将VLA策略扩展到具有高自由度(DoF)灵巧手的双臂机器人仍然面临挑战。本文提出GR-Dexter,一个用于在双臂灵巧手机器人上进行基于VLA通用操作的整体硬件-模型-数据框架。该方法结合紧凑型21自由度机械手的设计、用于采集真实机器人数据的直观双臂远程操作系统,以及利用远程操作机器人轨迹、大规模视觉-语言数据集和精心整理的跨具身数据集等训练方案。在涵盖长期日常操作和通用抓取放置任务的真实场景评估中,GR-Dexter 均展现出强大的域内性能,并提高对未知物体和未知指令的鲁棒性。
ByteDexter系列机械手采用连杆驱动传动机构,具有力反馈透明、耐用、易于维护等优势。作为V1型机械手[61]的升级版,ByteDexter V2型机械手增加一个拇指自由度,使总自由度达到21个,同时缩小整体尺寸(高度:219毫米,宽度:108毫米)。每个手指有四个自由度,拇指有五个自由度,从而提供了更广泛的对握运动,如图所示。还通过执行全部33种Feix定义的抓握类型[18]展示其类人抓握能力。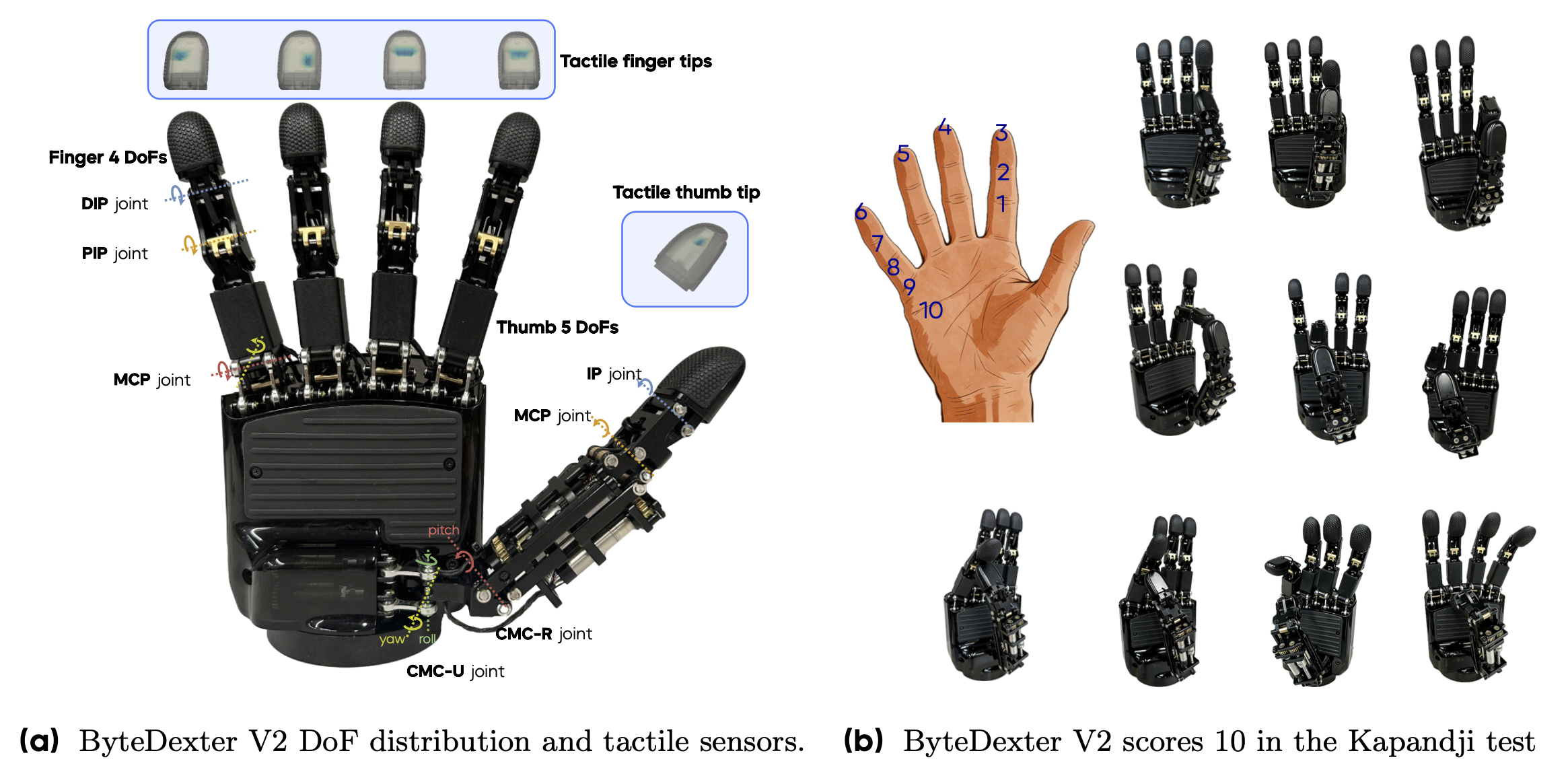
手部设计
手指(食指、中指、无名指、小指):四根手指采用模块化结构。每根手指在掌指关节 (MCP) 处有一个万向关节,在近端指间关节 (PIP) 和远端指间关节 (DIP) 处各有一个旋转关节。MCP 的两个自由度由位于掌心的两个电机驱动,实现外展-内收和屈曲-伸展运动。与 ILDA 手 [29] 不同,ByteDexter V2 将 PIP 的屈曲与 MCP 的屈曲解耦,因此 PIP 由一个独立的第三个电机驱动。
拇指:在人手中,鞍状的腕掌关节 (CMC) 实现屈曲-伸展和外展-内收运动,这对于灵巧的手部操作至关重要。 ByteDexter V2 在腕掌关节 (CMC) 处采用万向节,并配合一个旋转关节,以模拟这些运动学特征并保留关键功能特性(上图 a)。紧凑的集成式拇指机构最大限度地减少内部体积,同时显著增加拇指的运动范围。由此扩大的可触及工作空间使得所有四个手指都能实现稳健的对掌接触(上图 b)。
欠驱动:四个手指的远端指间关节 (DIP) 和拇指的指间关节 (IP) 均存在欠驱动现象。ByteDexter V2 采用仿生四杆机构,将每个 DIP 与其对应的近端指间关节 (PIP) 连接起来,从而重现人类 DIP-PIP 关节复合体中观察的固有运动学耦合。
触觉传感:ByteDexter V2 的五个指尖覆盖有高密度压阻式触觉阵列,用于测量法向接触力(上图 a)。该可视化技术对接触位置和力的大小进行编码,阵列可在指尖、指腹和侧面提供精细的空间分辨率。
双臂系统与控制
构建一个双臂平台,配备两个 ByteDexter V2 机械手,用于双臂操作(如图所示)。由此产生的 56 自由度机器人旨在支持协调的手臂-手部控制,以实现可靠的灵巧抓取和操作。为了减少遮挡并从多个视角捕捉手部与物体的交互,部署四个全局 RGB-D 摄像头:一个主视角(以自我为中心)和三个辅助的第三人称视角。该平台支持远程操作数据采集和自主策略部署。
双臂远程操作。使用双臂远程操作界面采集真实世界的机器人数据。该界面由 MetaQuest VR 设备(用于追踪腕部姿态)、两个 Manus Metaglove 手套(用于捕捉手部运动)以及用于启用/禁用远程操作的脚踏板组成。两个 MetaQuest 控制器安装在手套的背面,以提高协调的腕部-手部追踪的可靠性。该设置允许远程操作者在执行远距离操作任务时,同时协调两个 Franka 机械臂和两个 ByteDexter V2 机械手。人体运动通过全身控制器实时重定向至关节位置指令,从而实现运动学一致的映射。该系统集成安全机制,用于处理间歇性的视觉跟踪丢失,并降低危险操作的风险。手部运动重定向,被建模为一个约束优化问题,该问题结合腕部到指尖和拇指到指尖的对齐项、碰撞规避约束和正则化,并使用序列二次规划求解。
策略展开:在策略展开阶段,模型生成未来动作块,以促进协调一致、时间上一致的手臂-手部运动,从而实现灵巧操作。参数化的轨迹优化器对生成的动作进行平滑处理,这对于精细抓取至关重要,并确保动作块内部和动作块之间的平滑过渡。
该双手动系统展现出高效性、类人灵巧性和可靠的长时间运行能力。经过最少的训练,远程操作员成功完成从粗略操作(例如,搭建积木)到精细动作任务(例如,编织)的各种任务,如图所示。任务的广泛性突显该系统对现实世界中双手操作的适用性,从而能够可靠地收集数据和进行政策评估。
GR-Dexter 沿用 GR-3 [12] 的设计,并采用混合 Transformer 架构来构建具有 4B 个参数的视觉-语言-动作 (VLA) 模型 π_θ。π_θ(a_t | l,o_t,s_t) 通过生成一个长度为 k 的动作块 a_t = a_t:t+k 来控制一个固定底座的双臂机器人,该动作块的生成条件为输入语言指令 l、观测值 o_t 和机器人状态 s_t。具体来说,与学习二元离散夹爪动作的 GR-3 不同,GR-Dexter 中的每个动作 a_t 都是一个长度为 88 的向量,包含以下四个部分:1) 手臂关节动作(每条手臂 7 个自由度),2) 手臂末端执行器位姿(每条手臂 6 个自由度),3) 手部关节动作(每只手 16 个活动自由度),以及 4) 指尖位置(每个手指 3 个自由度)。
训练方案
用三种不同的数据源混合训练 GR-Dexter:网络规模的视觉-语言数据、跨具身真实机器人数据和人类轨迹数据。
视觉-语言数据:复用 GR-3 中的视觉-语言数据集,该数据集涵盖广泛的任务,包括图像描述、视觉问答、图像接地和交错接地图像描述。机器人轨迹数据用于训练 VLM 主干网络和动作 DiT,训练目标为流匹配。视觉-语言数据仅用于训练 VLM 主干网络,训练目标为下一个token预测。为简化起见,在小批量训练中动态混合视觉-语言数据和机器人轨迹数据。因此,协同训练目标是下一个token预测损失和流匹配损失之和。
跨实体数据采集:在高自由度 Byte-Dexter 平台上大规模远程操作数据的采集,受到硬件可用性和熟练远程操作员稀缺性的制约。为了缓解这一问题,利用现有的开源双臂人形机器人数据集。具体而言,选择三个涵盖不同实体和任务设置的双臂灵巧操作数据集:Fourier ActionNet 数据集 [20],其中包含约 140 小时使用 Fourier 6 自由度手进行的各种人形机器人双臂操作数据;OpenLoong Baihu 数据集 [57],其中包含超过 10 万条跨越多种机器人实体的机器人轨迹数据;RoboMIND [62],其中包含 10.7 万条演示轨迹,涵盖 479 个不同任务,涉及 96 个物体类别。
人类轨迹:虽然跨实体机器人数据能够提供精确的机器人状态信息,但任务的规模和多样性不可避免地受到硬件成本的限制。利用易于获取的虚拟现实设备进行众包人体演示,为扩展数据量和多样性提供一种很有前景的解决方案。采用人体轨迹数据(超过 800 小时的以自我为中心的视频,并附带 3D 手部和手指追踪数据),并补充使用 Pico 虚拟现实设备收集的额外数据。
为了处理数据集之间的结构差异,屏蔽不可用或不可靠的动作维度(例如,目标模型中不存在的特定关节)。
跨具身运动重定向与迁移
将灵巧操作技能从不同的具身模型以及人类演示中迁移到其他模型,需要对视觉感知和动作空间进行精细的校准。通过统一的预处理和重定向流程来应对这一挑战,该流程能够协调所有数据源的视觉几何、运动学和轨迹质量。
跨具身轨迹迁移。首先对数据集中的相机观测数据进行标准化。所有图像都被调整大小并裁剪成标准格式,使机器人手臂、灵巧的手和物体的大小比例保持一致。这个过程只需对每个数据集手动完成一次,然后即可应用于所有数据集。接下来,轨迹经过严格的质量控制,只保留高质量的轨迹。然后,通过对齐指尖,将轨迹精确重定向到 ByteDexter V2 手。这种以指尖为中心的对齐方式,既保留与任务相关的接触几何,又避免关节层面的差异。然后,将生成的轨迹按任务类别进行重采样,以生成平衡的跨具身训练语料库。
迁移人类轨迹。人类演示除了跨机器人迁移之外,还带来了其他挑战。人手和机器人手的运动学差异很大:VR 数据采集由于头戴式摄像头而引入自我运动,而单帧手部姿态估计通常会导致时间抖动和不一致性——尤其是在快速运动或部分遮挡的情况下。首先基于手部可见性和速度进行仔细的过滤。接下来,将人类轨迹映射到与机器人数据相同的视觉和运动学表示中,类似于跨具身数据清洗过程,从而能够无缝集成到 GR-Dexter 训练流程中。
长范围灵巧操作
首先测试 GR-Dexter 在化妆品整理任务中的长范围操作能力。该任务涉及对形状和尺寸各异的物品以及抽屉等铰接体进行长时间的操作。该任务需要协调的双手操作和精细的技能。收集约 20 小时的远程操控机器人轨迹数据。用视觉-语言数据和远程操控机器人轨迹数据进行协同训练,从而训练 GR-Dexter。还将 GR-Dexter 与仅使用机器人数据训练的普通 VLA 基线模型进行比较。在策略展开过程中,机器人会依次收到自然语言子任务描述(六个项目;每个项目一条指令),直到任务完成。每个子任务的执行都从机器人的初始姿态开始。用多次评估试验的平均成功率来报告任务性能。
基本设置:在基本设置中,物体的相对空间配置(布局)已包含在训练数据中。在此设置下,普通的 VLA 与 GR-Dexter 的性能相当,成功率分别为 0.96 和 0.97。这表明,协同训练保留仅使用远程操作的基线模型在领域内的强大能力。
分布外设置:在此设置下,物体的相对空间配置在测试时是全新的。在五个未见过的布局上进行评估,同时保持指令顺序与基本设置相同。在分布外设置下,普通 VLA 的性能下降到 0.64,而 GR-Dexter 的性能显著提升至 0.89。这些结果表明,使用视觉-语言数据进行协同训练可以显著增强对未见过空间布局的泛化能力,同时保持领域内的性能。
可泛化的拾取-放置任务
评估 GR-Dexter 在拾取放置任务上的泛化能力。收集约 20 小时的机器人轨迹,其中包含 20 个用于训练的物体。比较三种模型:普通 VLA、不包含跨具身数据的 GR-Dexter,和 GR-Dexter。用任务成功率来评估性能。在策略展开过程中,模型会收到一条自然语言指令,该指令指定一个目标物体。如果机器人拾取目标物体并将其放入容器中,则认为该次试验成功。对于每个评估批次,保持所有策略在展开过程中的物体布局不变。
基本设置:用已观察的物体构建 10 个评估批次,每个批次包含五个物体。在域内的基本设置下,普通 VLA 的完成率达到 0.87,不包含跨具身数据的 GR-Dexter 的完成率达到 0.85,而 GR-Dexter 的性能最佳,完成率达到 0.93。结果很有意思:(1) 不使用跨具身数据的 GR-Dexter 的性能略逊于纯 VLA,这是因为在分布内设置中,VLA 数据并未提供额外信息,反而增加优化难度;(2) 使用跨具身数据后,GR-Dexter 的性能显著优于两个基线模型,这表明经过仔细的数据处理和对齐后,对动作专家进行更大规模的跨具身训练可以提高 GR-Dexter 的整体鲁棒性和性能。
未见物体和指令:对于未见物体,选择 23 个未见物体,并构建 10 个评估批次,每个批次包含 5 个物体。此外,还构建 5 个包含已见物体和未见物体的评估批次,并用未见语言指令提示模型。在这两种设置下,都观察到:(1) 纯 VLA 的性能显著下降; (2) VLM协同训练显著提升GR-Dexter的鲁棒性和泛化能力,但经验表明,未采用跨具身数据的GR-Dexter抓取精度仍然不高;(3) 通过精心筛选和对齐的跨具身协同训练,GR-Dexter展现出对未见物体和指令的强大泛化能力,最终成功率分别达到0.85和0.83。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 26
26 0
0- 0



 已为社区贡献209条内容
已为社区贡献209条内容

所有评论(0)