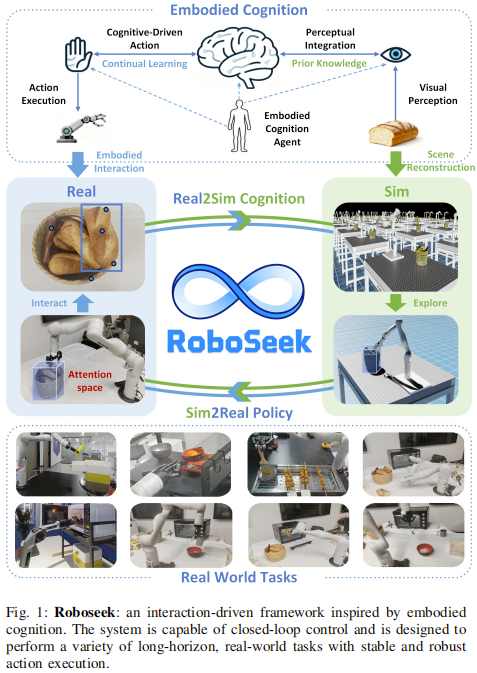
RoboSeek破解了长时程任务的核心难题,当操作任务遇上 “具身认知”
对人类而言,“打开抽屉 — 放入香蕉 — 关闭抽屉” 只是举手之劳,但对追求通用能力的机器人来说,这一连串动作却是重重难关的缩影:既要精准识别抽屉把手的 “可开合” 属性(即任务关键的 “可用性”),又要规划关节协同运动以保证动作连贯,还得实时应对物理摩擦、物体位置偏差等不确定因素。在具身智能领域,这类需多步交互、工具使用与动态决策的长时程机器人操作任务,正是制约机器人从 “特定场景专用” 走向
对人类而言,“打开抽屉 — 放入香蕉 — 关闭抽屉” 只是举手之劳,但对追求通用能力的机器人来说,这一连串动作却是重重难关的缩影:既要精准识别抽屉把手的 “可开合” 属性(即任务关键的 “可用性”),又要规划关节协同运动以保证动作连贯,还得实时应对物理摩擦、物体位置偏差等不确定因素。在具身智能领域,这类需多步交互、工具使用与动态决策的长时程机器人操作任务,正是制约机器人从 “特定场景专用” 走向 “开放环境通用” 的核心瓶颈——能否突破这一瓶颈,直接决定了机器人能否真正融入家庭、工业等真实生活场景。
然而,传统技术路线始终难以跨越这道鸿沟。一方面,大语言模型(LLMs)与视觉语言模型(VLMs)虽能高效理解静态场景信息,却缺乏与物理世界的实时交互反馈,无法动态更新对物体 “可用性” 的认知,比如无法通过触碰确认 “哪个部位是抽屉的发力点”;另一方面,端到端视觉语言动作模型(VLAs)虽尝试连接感知与动作,却因缺少闭环修正机制,在长时程任务中极易出现动作偏差,难以稳定完成全流程操作。更关键的是训练与部署的矛盾:在真实世界中训练机器人,不仅存在硬件损坏风险,还面临环境不可控导致的训练不稳定问题;而仅在仿真环境中训练,又会因 “仿真 - 现实差异”,使模型在真实机器人上 “水土不服”,无法落地应用。
正是在这一技术困境下,RoboSeek 框架的提出带来了突破性思路,其创新核心源于对 “具身认知理论” 的深度落地 —— 该理论颠覆了 “认知孤立于交互” 的传统认知,强调智能体的认知能力源于与物体、环境的动态交互。基于这一理念,RoboSeek 构建了 “交互驱动感知与动作联合优化” 的全新架构:通过动态进化的 “注意力空间” 捕捉任务关键信息,用强化学习驱动的具身执行器实现精准动作控制,再借助交叉熵方法迭代优化关键目标,最后通过 “从现实到仿真再到现实”(real2sim2real)的迁移流程,破解仿真与现实脱节的难题。
这一创新设计的价值不言而喻:在 8 项长时程任务、2 类不同机器人平台的测试中,RoboSeek 实现了 79% 的平均成功率,远超传统基线方法(成功率均低于 50%),不仅为长时程机器人操作提供了稳定可靠的解决方案,更填补了 “具身认知理论” 到 “机器人实际操作” 的落地空白,为通用机器人在真实环境中的应用开辟了可复制、可推广的新范式
核心方法:RoboSeek 的三大核心模块与real2sim2real 闭环设计
RoboSeek 的核心逻辑是 “以交互为纽带,串联感知表征、动作执行与跨域迁移”,整体架构分为注意力空间、RL 具身执行器、CEM 优化器三大模块,并通过 real2sim2real 流程实现从仿真到现实的稳定部署。
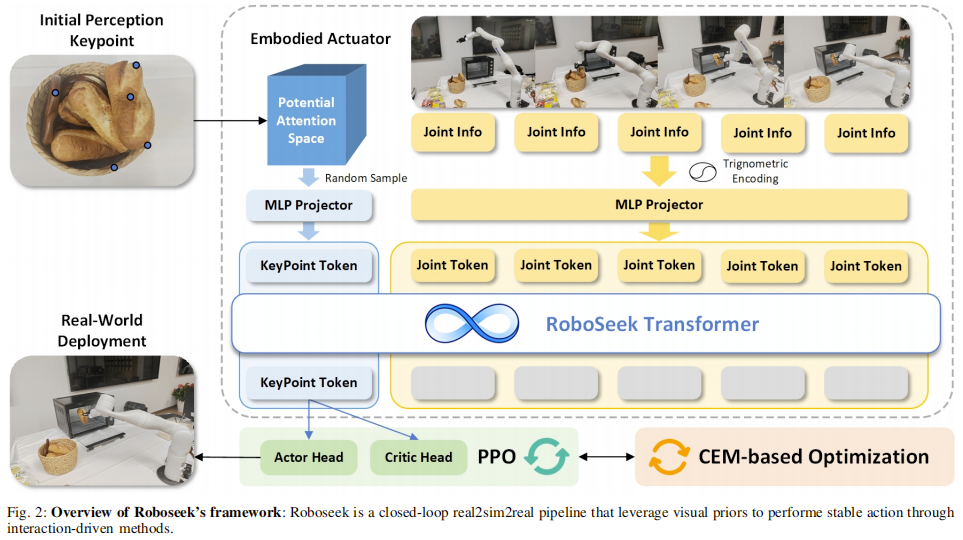
注意力空间:动态编码 “任务相关可用性”(感知表征)
注意力空间是 RoboSeek 的感知核心,它并非静态的物体模型,而是随交互进化的 3D 语义关键点集合(记为 A ⊂ R 3 A \subset \mathbb{R}^3 A⊂R3),每个关键点 k ∈ A k \in A k∈A对应任务所需的 “可用性”(如抽屉把手、勺子头部)。其构建与优化遵循两大原则:
初始化:基于高层感知的关键点预测 利用 Embodied-R1 作为高层感知模型,结合 Intel RealSense 相机的 RGB-D 数据与 SLAT 3D 重建技术,将 2D 语义关键点反投影为 3D 空间坐标,为后续动作提供初始目标。
进化:随交互动态更新 区别于传统静态表征,注意力空间会根据机器人与环境的交互反馈(如 “触碰抽屉把手后是否能打开抽屉”)实时筛选关键点,确保始终聚焦对当前任务最关键的区域。
RL 驱动的具身执行器:实现精准、稳定的低阶动作控制(动作执行)
该模块负责在注意力空间内执行关节运动,核心是通过强化学习训练 “感知 - 动作” 映射策略,具体设计如下:
训练平台与算法选择
- 仿真平台:采用 IsaacLab 机器人仿真工具,确保物理环境(如重力、摩擦)与现实的一致性;
- 核心算法:近端策略优化(PPO),平衡 “探索新动作” 与 “收敛到最优动作”;
- 网络架构:6 层 Transformer(含 3 个注意力头),其自注意力机制能有效学习关节间的协同运动(如 “打开抽屉时,肩部与肘部关节的配合”)及关节与关键点的姿态差异。
输入编码:解决 “仿真 - 现实表征差异” 为减少 sim2real gap,对机器人关节角度采用正余弦编码——既避免角度的周期性歧义(如 0° 与 360° 的混淆),又能保留关节间的相对位置信息;同时,输入还包含历史动作序列,确保运动的连贯性。
奖励函数:多维度平衡精度与安全性 设计加权复合奖励函数 r t = r t d i s t + r t o r i + r t a c t r_t = r_t^{dist} + r_t^{ori} + r_t^{act} rt=rtdist+rtori+rtact,各分项功能如下:
- 距离奖励:结合欧氏距离与两个不同尺度的 tanh 核( σ 1 = 0.3 \sigma_1=0.3 σ1=0.3用于粗引导, σ 2 = 0.05 \sigma_2=0.05 σ2=0.05用于细精度),确保机器人末端精准靠近目标关键点;
- 姿态奖励:基于四元数的球面距离( θ t = 2 arccos ( ∣ < q t e e , q t ∗ > ∣ ) \theta_t=2\arccos(|< q_{t}^{ee}, q_{t}^{*}> |) θt=2arccos(∣<qtee,qt∗>∣)),负向惩罚姿态偏差(如 “倾倒牛奶时勺子倾斜角度不足”);
- 动作正则奖励:惩罚过大的关节动作幅度、动作速率及关节速度(公式为 r t a c t = − w ℓ 2 ∥ a t ∥ 2 2 − w r a t e ∥ a t − a t − 1 ∥ 2 2 − w v e l ∥ q ˙ t ∥ 2 2 r_t^{act}= -w_{\ell2}\|a_t\|_2^2 - w_{rate}\|a_t-a_{t-1}\|_2^2 - w_{vel}\|\dot{q}_t\|_2^2 rtact=−wℓ2∥at∥22−wrate∥at−at−1∥22−wvel∥q˙t∥22),避免剧烈运动损伤硬件。
训练策略:课程学习避免局部最优 动态调整各奖励项的权重(如训练初期侧重距离奖励,后期侧重姿态与动作正则奖励),引导模型逐步掌握复杂动作,避免早期收敛到 “仅靠近关键点却无法完成任务” 的局部最优。
CEM 注意力空间优化器:筛选 “最优关键点”(迭代优化)
通过交叉熵方法(CEM)迭代优化注意力空间的关键点分布,确保筛选出能最大化任务奖励的 “最优关键点”,具体流程如下(对应图 3 的 CEM 可视化逻辑):
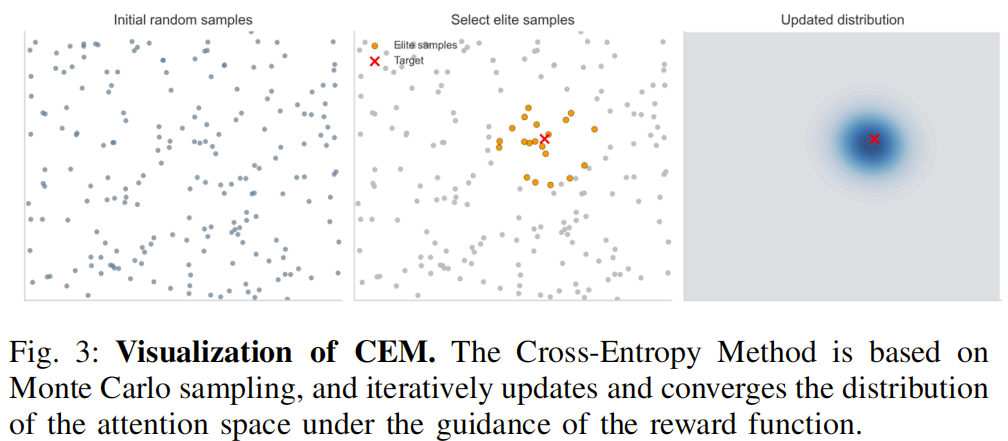
初始化分布:将关键点分布建模为高斯分布 N ( μ 0 , Σ 0 ) \mathcal{N}(\mu_0, \Sigma_0) N(μ0,Σ0),其中 μ 0 \mu_0 μ0为初始感知预测的关键点坐标, Σ 0 \Sigma_0 Σ0为初始方差;
采样与评估:每次迭代采样m个候选关键点,每个关键点执行n次动作 “rollout”(重复执行动作),计算平均奖励 R ( x i ) = 1 n ∑ j = 1 n r ( x i , j ) R(x_i) = \frac{1}{n}\sum_{j=1}^n r(x_i,j) R(xi)=n1∑j=1nr(xi,j);
更新分布:选择奖励最高的k个候选点(精英集),更新高斯分布的均值 μ t + 1 = 1 k ∑ i ∈ S t x i \mu_{t+1} = \frac{1}{k}\sum_{i \in S_t} x_i μt+1=k1∑i∈Stxi与协方差 Σ t + 1 = 1 k ∑ i ∈ S t ( x i − μ t + 1 ) ( x i − μ t + 1 ) T \Sigma_{t+1} = \frac{1}{k}\sum_{i \in S_t}(x_i-\mu_{t+1})(x_i-\mu_{t+1})^T Σt+1=k1∑i∈St(xi−μt+1)(xi−μt+1)T;
收敛条件:当协方差范数 ∥ Σ t ∥ < ϵ \|\Sigma_t\|<\epsilon ∥Σt∥<ϵ(预设阈值)或达到最大迭代次数时,停止优化,此时的均值 μ t \mu_t μt即为 “最优关键点”。
此外,为适配不同任务,研究团队利用 LLM 基于任务示例自动生成奖励计算代码(如 “开柜门任务” 中,奖励与门的开合角度正相关),大幅减少人工设计成本。
real2sim2real 迁移流程:破解 “仿真 - 现实差异”(跨域迁移)
为平衡训练安全性与部署稳定性,RoboSeek 设计三步迁移机制,大幅缩小 sim2real gap:
real2sim:复刻真实场景到仿真 通过 SLAT 3D 重建技术,将真实环境(如厨房抽屉、烤箱)的视觉与物理属性(尺寸、材质摩擦系数)复刻到仿真中,确保仿真环境的 “真实性”;
仿真训练增强:提升模型鲁棒性
- 域随机化(Domain Randomization):在训练中随机扰动初始姿态、关节速度及物理参数(如摩擦系数),让模型适应现实中的不确定性;
- 正余弦编码:如前所述,减少关节角度在仿真与现实中的表征差异;
sim2real:实体机器人部署
- 执行频率:20 Hz,匹配实体机器人的硬件响应速度;
- 动作逻辑:抓取任务中,机械爪在到达目标关键点前保持张开,到达后闭合;非抓取任务(如刷油)中保持闭合以稳定操作;
- 硬件无关性:无需针对特定机器人修改模型,可直接部署到 Kinova Gen3、Agilex Piper 等不同平台。
关键实验分析:多平台、多任务验证 RoboSeek 的性能
研究团队通过 “任务成功率对比”“sim2real 迁移能力评估”“长时程任务稳定性验证” 三大维度,在 2 类机器人平台、8 项长时程任务上验证 RoboSeek 的有效性,核心实验结果如下。
实验设置:平台、任务与基线
硬件平台
- Kinova Gen3:6 自由度机械臂,用于执行烧烤(刷油)、抽屉放置、烤箱放置、倒牛奶、舀谷物、倒食物 6 项任务;
- Agilex Piper:4 自由度机械臂,用于执行抽屉放置(取物)、微波炉放置(取饭团)2 项任务;
- 感知设备:Intel RealSense 相机,用于获取 RGB-D 数据以实现 3D 重建与关键点定位。
任务定义 所有任务均为长时程多步交互任务,需满足 “工具使用” 或 “物体运输” 需求,例如:

- 抽屉放置(Kinova Gen3):打开抽屉→放入香蕉→关闭抽屉;
- 舀谷物:用勺子舀取谷物→倒入碗中;
- 微波炉放置(Piper):打开微波炉门→取出饭团→放置到指定位置。
基线方法
- Rekep 、IKER:仅在仿真中评估,依赖预计算的任务解读;
- Embodied-R1:结合传统运动规划器,在实体机器人上评估,缺乏闭环修正机制。
核心结果 1:RoboSeek 在实体任务上的高成功率
表 1 展示了 RoboSeek 在 2 类平台、8 项任务上的成功率(每项任务运行 20 次,成功定义为 “完整完成所有步骤”):
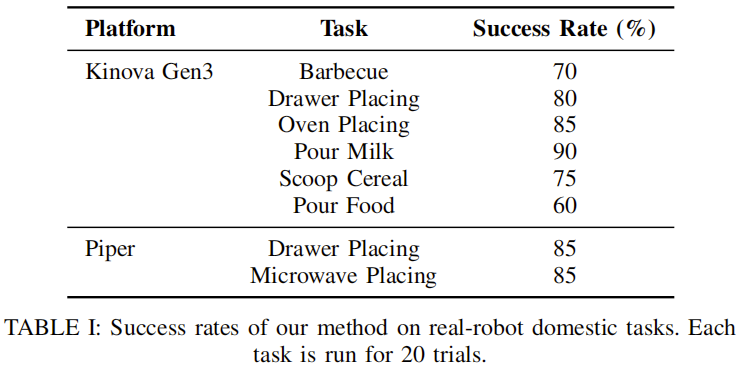
从表中可见,RoboSeek 在 “倒牛奶”“烤箱放置”“Piper 平台抽屉 / 微波炉放置” 等任务上表现突出(成功率≥85%),仅在 “倒食物” 任务上成功率较低(60%),原因是 “开盖 + 倒出” 的两步动作对关节协同要求更高,且仿真中难以完全复现食物的粘性物理属性。
核心结果 2:RoboSeek 显著优于基线方法
图 5 对比了 RoboSeek 与基线方法在 “抽屉放置”“倒牛奶”(长时程任务)及 “拾取 - 放置”(简单任务)上的成功率,核心结论如下:
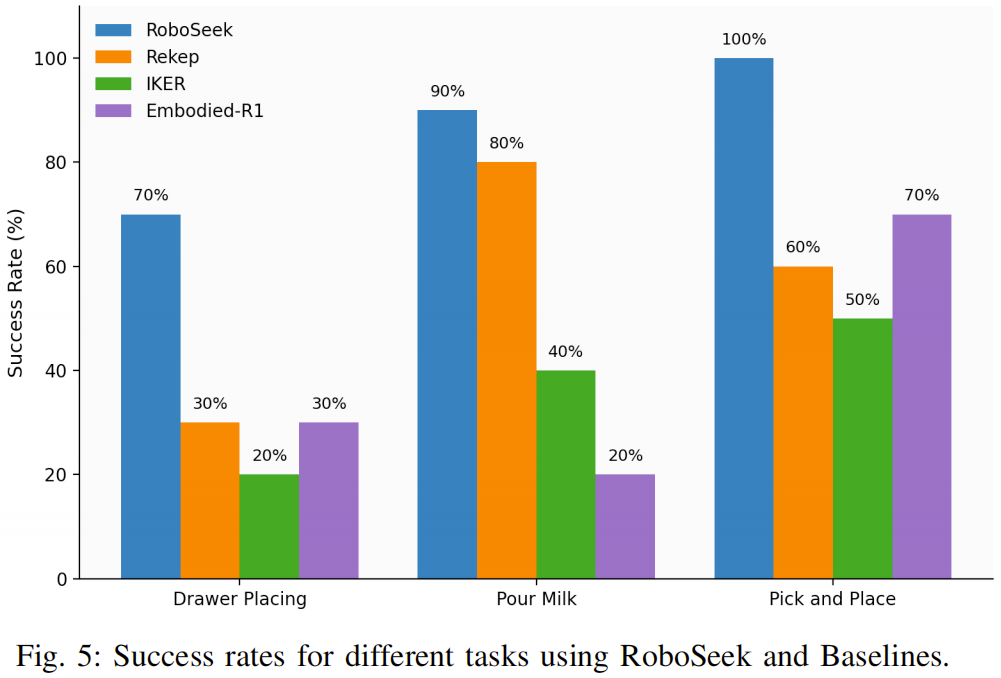
长时程任务优势明显
- Rekep 与 IKER 虽能在仿真中生成平滑运动,但因无法提取 “任务关键关键点”(如抽屉把手),在实体任务中频繁抓取失败,成功率低于 30%;
- Embodied-R1 虽能识别关键点,但传统运动规划器无法应对物理不确定性(如抽屉摩擦),成功率约 40%-50%;
- RoboSeek 因 “闭环修正 + 最优关键点筛选”,在抽屉放置、倒牛奶任务上成功率分别达 80%、90%,远超基线。
简单任务表现稳定 在 “拾取 - 放置” 任务上,RoboSeek 成功率仍高于基线,证明其不仅擅长复杂任务,在基础任务上也具备可靠性。
核心结果 3:real2sim2real 迁移能力强
表 2 评估了 RoboSeek 在 “纯仿真”“实体部署”“无域随机化(w/o DR)”“无正余弦编码(w/o TE)” 四种设置下的成功率,验证 sim2real 迁移机制的有效性:
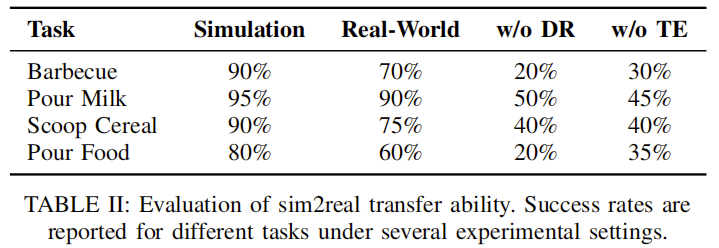
从表中可得出两大关键结论:
sim2real gap 小:实体成功率与仿真成功率差距最大仅 20%(烧烤任务),最小仅 5%(倒牛奶任务),远低于基线方法(差距通常≥40%);
迁移机制不可或缺:无域随机化或无正余弦编码时,成功率大幅下降(如烧烤任务从 70% 降至 20%),证明这两项技术是缩小 sim2real gap 的核心。
失败案例分析
RoboSeek 的失败主要源于 “仿真 - 现实物理参数不匹配”:例如在 “舀谷物” 任务中,仿真低估了谷物颗粒间的摩擦系数,导致机器人动作过快,谷物洒出;在 “倒食物” 任务中,仿真无法复现食物的粘性,导致部分食物残留容器内,无法完成 “倒出” 步骤。这些问题提示,未来需进一步提升仿真物理引擎的精度。
结论与局限
RoboSeek 通过**“注意力空间 + RL 执行器 + CEM 优化器”**的组合,成功将具身认知理论落地为可执行的机器人操作框架,其 real2sim2real 流程大幅降低了仿真-现实迁移的难度,在多平台、多任务上展现出优异的泛化性与稳定性。
但研究仍存在三方面局限:一是模型规模较小,在多物体遮挡等复杂环境中泛化性不足;二是单任务训练需约 2 小时,难以支持实时任务适配;三是仿真无法完全复现复杂物理交互(如液体晃动、颗粒摩擦),仍存在少量 sim2real gap。未来可通过融合大型基础模型、优化训练流程、提升仿真精度进一步突破这些瓶颈。
参考
[1]RoboSeek: You Need to Interact with Your Objects
具身求职内推来啦
国内最大的具身智能全栈学习社区来啦!
推荐阅读
从零部署π0,π0.5!好用,高性价比!面向具身科研领域打造的轻量级机械臂
工业级真机教程+VLA算法实战(pi0/pi0.5/GR00T/世界模型等)
具身智能算法与落地平台来啦!国内首个面向科研及工业的全栈具身智能机械臂
VLA/VLA+触觉/VLA+RL/具身世界模型等!具身大脑+小脑算法与实战全栈路线来啦~
MuJoCo具身智能实战:从零基础到强化学习与Sim2Real
Diffusion Policy在具身智能领域是怎么应用的?为什么如此重要?
1v1 科研论文辅导来啦!

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 16
16 0
0- 0



 已为社区贡献106条内容
已为社区贡献106条内容

所有评论(0)