RT-1模型架构(自用复习)
模型通过自注意力机制,无障碍地分析“苹果”(视觉令牌)、“捡起绿色海绵”(语言令牌)和“先前手的位置”(动作令牌)之间的关系,然后预测出。:对于机械臂的7个维度(x, y, z, 横滚,俯仰,偏航,夹爪)和底盘的3个维度(x, y, θ),分别将其可能的取值范围均匀划分为256个区间。是一个可学习的模块,它可以从EfficientNet输出的81个视觉令牌中,动态地筛选出最相关的少数几个(如8个)
🔍 第一阶段:大规模、多样化的数据收集
RT-1的性能根基在于其训练数据——一个由13台机器人耗时17个月收集的、包含13万个任务片段、覆盖700多项日常操作的真实世界数据集。
-
硬件平台:使用Kuka机械臂与移动底盘组成的机器人,配备标准二指夹爪和腕部摄像头。
-
数据内容:每个数据片段都包含:第一视角的图像序列、对应的机器人动作序列(7维机械臂+3维底盘),以及一条描述该任务的自然语言指令(如“把可乐罐放进抽屉”)。
⚙️ 第二阶段:数据预处理与令牌化
这是将原始物理世界数据转化为模型可“理解”的数字令牌的关键步骤。
-
视觉输入处理:
-
原始的RGB图像被调整至
300x300分辨率。 -
图像被输入一个在ImageNet上预训练的 EfficientNet-B3 主干网络,提取空间特征。
-
关键的一步是使用语言指令通过FiLM层调制视觉特征。FiLM层会根据当前指令生成缩放和偏置参数,动态影响视觉特征的激活,让模型学会“根据指令关注相关视觉区域”。
-
-
语言指令处理:
-
自然语言指令(如“pick up the green sponge”)通过一个预训练的 T5 SentencePiece 分词器,被转化为一串语言令牌。
-
-
动作输出处理:
-
原始的、连续的机器人动作(如关节角度、位移速度)被离散化。RT-1将机械臂的7个维度和底盘的3个维度,每个维度都均匀地划分为256个区间。这样,任何一个连续动作都被近似为一个由11个离散值(每个值在0-255之间)组成的序列,即动作令牌。
-
🧠 第三阶段:模型训练与前向推理
处理好的令牌被送入模型进行训练或决策。
-
输入序列构建:
-
在每一个时间步
t,模型的输入是一个由以下部分拼接而成的长序列:[语言令牌, 图像令牌_t, 先前动作令牌_(t-1)] -
这里的“图像令牌_t”是经过TokenLearner压缩后的关键视觉特征。TokenLearner是一个可学习的模块,它可以从EfficientNet输出的81个视觉令牌中,动态地筛选出最相关的少数几个(如8个),极大提升了处理效率。
-
-
Transformer解码器工作:
-
这个拼接序列进入一个仅有解码器的Transformer架构。
-
模型通过自注意力机制,分析指令、当前场景图像和刚刚执行过的动作三者之间的内在关联。
-
最终,Transformer输出层预测的是在当前指令和视觉观察下,机器人接下来应该执行的动作的概率分布,即下一个动作令牌。
-
-
训练目标:
-
训练的目标非常简单直接:最大化模型预测的动作序列与数据集中记录的真实动作序列之间的相似性。这是一个标准的有监督的行为克隆目标。
-
🤖 第四阶段:动作执行与闭环控制
模型输出的令牌会被转换回机器人能执行的命令。
-
动作解码:
-
模型预测出的11个离散动作令牌(每个对应一个维度),需要通过一个小型的多层感知机解码回连续的机器人控制空间。
-
在实践中,RT-1使用了 “混合高斯模型” 来建模每个离散区间对应的连续值分布,使得控制更加平滑。
-
-
发送与执行:
-
解码后的连续动作指令(位置、姿态、速度等)通过机器人操作系统发送给机械臂和底盘的控制器。
-
机器人执行该动作,环境状态改变,腕部摄像头捕获到新的图像。
-
-
循环往复:
-
新的图像与最初的指令再次构成输入,模型预测下一个动作。如此循环,直到模型预测出一个特殊的 “终止令牌” ,或者达到预设的最大步数,一个任务片段结束。
-
RT-1通过一套精巧的设计,将图像、语言和动作这三种截然不同的模态,全部转化为一个统一的、离散的令牌序列,从而让标准的Transformer架构能够直接处理机器人控制问题。
下面的流程图清晰地展示了这一“翻译”过程: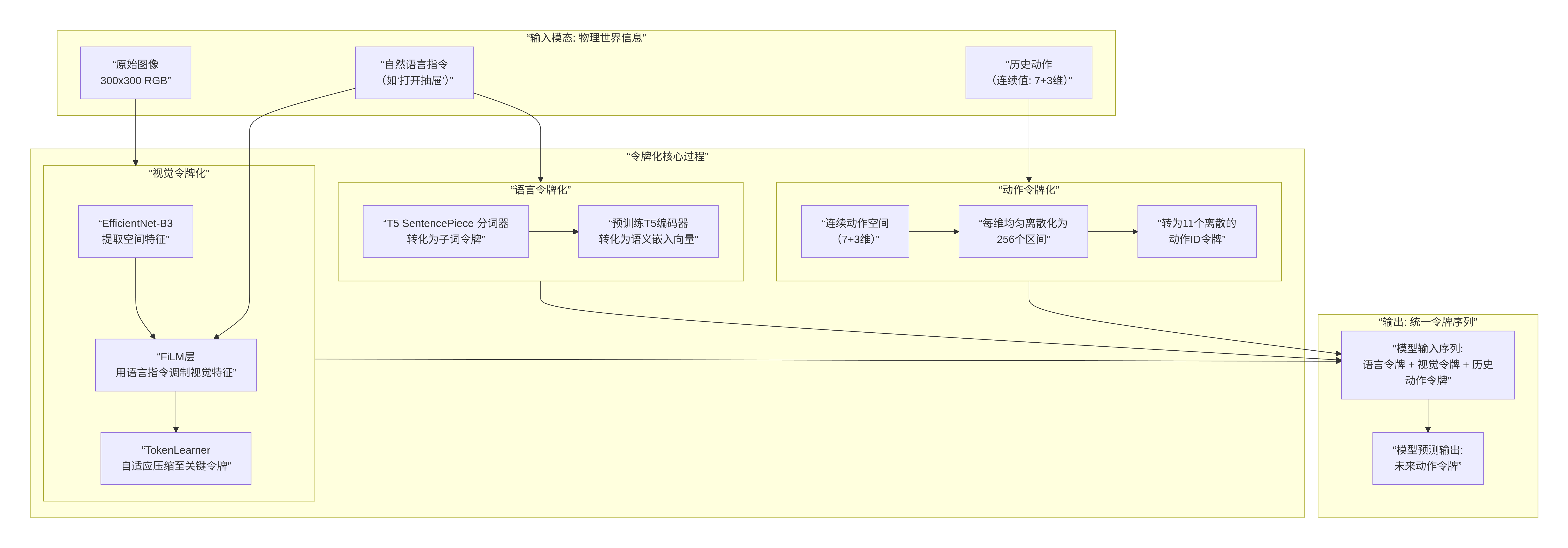
下面,我们对图中的每一个关键环节进行详细拆解。
🔍 1. 视觉令牌化:从像素到关键信息集合
目标:将一张高维、稠密的图像,压缩为一小撮包含核心信息的令牌。
-
步骤1:特征提取:输入的
300x300x3图像通过预训练的EfficientNet-B3主干网络,输出一个尺寸为9x9x512的空间特征图。你可以把它理解为一张分辨率更低(9x9)、但每个“超级像素”都包含512维高级语义信息的“特征图像”。 -
步骤2:语言条件调制:这是让视觉“聚焦”于指令相关区域的关键。该特征图会经过 FiLM层。FiLM层根据当前的语言指令,为特征图的每个通道生成一个缩放因子和偏置项,动态地对视觉特征进行加权和偏移。这相当于用语言指令告诉模型:“在当前‘把苹果放进碗里’的任务下,请更关注特征图中代表‘苹果’和‘碗’的那些通道。”
-
步骤3:自适应压缩:经过调制的
9x9=81个视觉特征向量,被送入 TokenLearner 模块。该模块通过一个可学习的注意力机制,从这81个候选特征中,动态地选择或合成出最关键的少数几个(例如8个)。这8个令牌就代表了当前任务下最相关的视觉信息,极大地减少了后续Transformer的计算量,并过滤了无关背景干扰。
📝 2. 语言令牌化:从指令到语义向量
目标:将人类指令转化为模型能理解的、富含语义的向量序列。
-
步骤1:子词分割:指令(如
“pick up the green sponge”)通过T5模型的SentencePiece分词器,被分割成一系列子词令牌,例如["▁pick", "▁up", "▁the", "▁green", "▁sp", "onge"]。这能有效处理未登录词。 -
步骤2:语义嵌入:这些子词令牌被送入一个冻结的预训练T5编码器,转化为一序列固定维度的语义嵌入向量。这些向量携带着预训练语言模型从海量文本中学到的丰富语义和上下文知识。
🎮 3. 动作令牌化:从连续控制到离散分类
目标:将连续的、高精度的机器人动作,转化为一个离散的、有限的分类问题。这是RT-1设计的精髓。
-
核心思想:放弃直接回归连续动作值,而是将每个动作维度建模为一个256类的分类问题。
-
具体操作:对于机械臂的7个维度(x, y, z, 横滚,俯仰,偏航,夹爪)和底盘的3个维度(x, y, θ),分别将其可能的取值范围均匀划分为256个区间。
-
例如,夹爪的开合度范围是
[0, 1](0为闭合,1为全开)。那么,区间0代表[0, 1/256), 区间1代表[1/256, 2/256),…,区间255代表[255/256, 1]。 -
任何一个具体的动作(如
[0.12, 0.45, ..., 0.78])都会被量化为11个离散的令牌ID(每个ID在0-255之间)。
-
-
优势与损失:
-
优势:将回归问题转化为分类问题,更匹配Transformer的强项。它使模型输出更稳定,避免了回归中常见的均值模糊问题,并且天然地限制了动作空间,有利于学习和泛化。
-
损失:损失了连续空间内的精度。一个区间内的所有连续值在模型看来是等价的。为了弥补,RT-1在解码时会使用一个小的MLP或混合高斯模型,来预测该区间内更精确的连续值。
-
🧩 4. 序列整合与模型工作
现在,所有模态都被统一成了同一种“语言”——令牌向量。
-
输入序列构建:在时间步
t,模型的输入序列为:[语言令牌_1, ..., 语言令牌_L, 视觉令牌_t1, ..., 视觉令牌_t8, 动作令牌_(t-1)1, ..., 动作令牌_(t-1)11]。 -
Transformer处理:这个序列被送入Transformer解码器。模型通过自注意力机制,无障碍地分析“苹果”(视觉令牌)、“捡起绿色海绵”(语言令牌)和“先前手的位置”(动作令牌)之间的关系,然后预测出下一个最有可能的11个动作令牌。
-
输出解码:预测出的11个离散动作ID,被解码为具体的连续动作命令,发送给机器人执行。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)