探索智能预测与分类的算法之旅:从BP到SVM再到ELM
差分进化算法优化BP神经网络,支持向量机SVM/SVR,最小二乘支持向量机LSSVM,极限学习机ELM,预测与分类。
在数据驱动的时代,预测与分类问题无处不在,从金融市场趋势预判到医疗影像疾病诊断,准确的预测与分类模型至关重要。今天,咱们就一起深入探讨几种强大的算法:差分进化算法优化BP神经网络,支持向量机(SVM/SVR),最小二乘支持向量机(LSSVM)以及极限学习机(ELM)。
差分进化算法优化BP神经网络
BP神经网络,作为经典的前馈神经网络,通过误差反向传播算法来调整网络权重,从而达到最小化预测误差的目的。然而,传统BP神经网络容易陷入局部最优解,导致模型的泛化能力不佳。这时候,差分进化算法就闪亮登场啦!
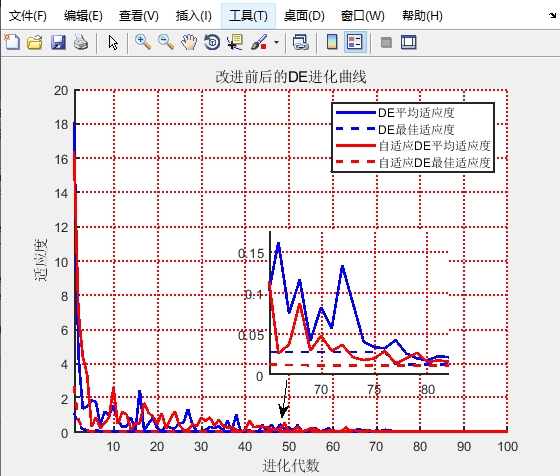
差分进化算法是一种基于群体的全局优化算法,它通过对种群个体进行差分变异、交叉和选择操作,不断地探索搜索空间,寻找最优解。当用它来优化BP神经网络时,能够帮助BP神经网络跳出局部最优,找到更好的权重组合。
下面简单写一段Python代码来感受下(这里仅为示意简化代码,实际应用中会更复杂):
import numpy as np
# 定义差分进化算法的参数
NP = 50 # 种群数量
D = 10 # 问题维度,对应BP神经网络权重数量
F = 0.5 # 缩放因子
CR = 0.9 # 交叉概率
max_iter = 100 # 最大迭代次数
# 初始化种群
pop = np.random.rand(NP, D)
for t in range(max_iter):
for i in range(NP):
# 选择三个不同的个体
r1, r2, r3 = np.random.choice([j for j in range(NP) if j!= i], 3, replace=False)
# 变异操作
v = pop[r1] + F * (pop[r2] - pop[r3])
# 交叉操作
u = np.where(np.random.rand(D) < CR, v, pop[i])
# 选择操作
if fitness(u) < fitness(pop[i]):
pop[i] = u在这段代码里,首先初始化了种群,种群里的每个个体都代表了BP神经网络权重的一种可能组合。在每次迭代中,通过变异操作生成一个新的个体v,它是基于种群中其他个体的差分得到的。然后通过交叉操作,将v与当前个体pop[i]进行组合得到u。最后,通过比较u和pop[i]的适应度(这里fitness函数未具体定义,实际中是根据BP神经网络预测误差等构建的适应度函数),如果u更优,就更新pop[i]。这样不断迭代,最终找到一组较优的BP神经网络权重。
支持向量机(SVM/SVR)
支持向量机是一种有监督学习模型,在分类和回归问题上都有出色表现。对于分类问题(SVM),它的核心思想是找到一个超平面,能够在样本空间中最大程度地分开不同类别的数据点,并且使分类间隔最大化。
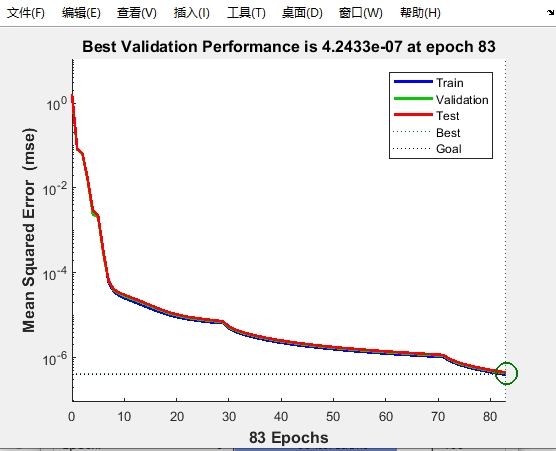
在Python中,使用sklearn库可以轻松实现SVM分类:
from sklearn import svm
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
iris = load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
clf = svm.SVC(kernel='linear')
clf.fit(X_train, y_train)
accuracy = clf.score(X_test, y_test)
print(f"测试集准确率: {accuracy}")在这段代码中,首先加载了鸢尾花数据集,然后将其划分为训练集和测试集。接着创建了一个线性核的SVM分类器clf,并使用训练数据进行训练。最后通过score方法在测试集上评估模型的准确率。
对于回归问题(SVR),SVM试图找到一个函数,使得所有样本点到该函数的距离小于某个误差值,同时使函数的复杂度最小。
from sklearn.svm import SVR
import numpy as np
# 生成一些简单的数据
X = np.sort(5 * np.random.rand(40, 1), axis=0)
y = np.sin(X).ravel()
# 添加噪声
y[::5] += 3 * (0.5 - np.random.rand(8))
svr_rbf = SVR(kernel='rbf', C=1e3, gamma=0.1)
y_rbf = svr_rbf.fit(X, y).predict(X)这里生成了一些带有噪声的正弦数据,创建了一个径向基核(RBF)的SVR模型,并对数据进行拟合和预测。
最小二乘支持向量机(LSSVM)
最小二乘支持向量机是对标准支持向量机的一种改进,它将不等式约束转化为等式约束,通过求解线性方程组来确定模型参数,从而大大降低了计算复杂度。
from sklearn.kernel_ridge import KernelRidge
import numpy as np
# 数据准备
X = np.array([[1], [2], [3], [4], [5]])
y = np.array([2, 4, 6, 8, 10])
# 创建LSSVM模型
lssvm = KernelRidge(alpha=1.0, kernel='linear')
lssvm.fit(X, y)
# 预测
new_X = np.array([[6]])
prediction = lssvm.predict(new_X)
print(f"预测结果: {prediction}")在这个简单示例中,通过KernelRidge类创建了一个线性核的LSSVM模型,对给定数据进行拟合,并对新数据进行预测。
极限学习机(ELM)
极限学习机是一种单隐层前馈神经网络,它的独特之处在于随机生成输入层到隐藏层的权重和隐藏层神经元的阈值,然后通过求解线性方程组来确定输出层的权重。这使得ELM训练速度极快,在许多场景下表现优异。
import numpy as np
from sklearn.linear_model import Ridge
# 生成数据
X = np.random.rand(100, 10)
y = np.random.rand(100, 1)
# 随机生成输入层到隐藏层的权重和隐藏层阈值
n_hidden = 50
W = np.random.rand(10, n_hidden)
b = np.random.rand(n_hidden)
# 计算隐藏层输出
H = np.tanh(np.dot(X, W) + b)
# 使用岭回归求解输出层权重
elm = Ridge(alpha=1.0)
elm.fit(H, y)在这段代码里,首先生成了一些随机数据,然后随机初始化了输入层到隐藏层的权重W和隐藏层阈值b,计算出隐藏层输出H,最后使用岭回归来确定输出层权重,从而完成了极限学习机的训练。
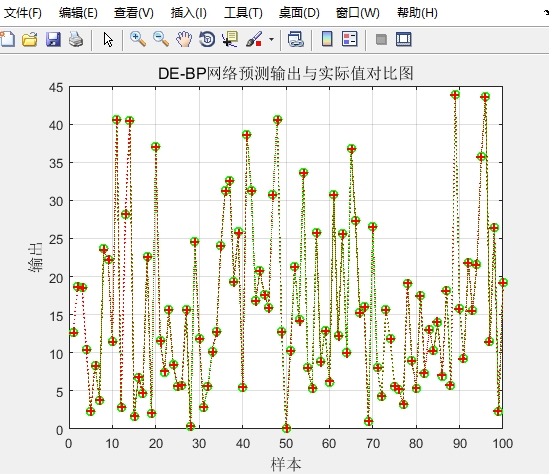
以上就是对差分进化算法优化BP神经网络,支持向量机(SVM/SVR),最小二乘支持向量机(LSSVM)以及极限学习机(ELM)在预测与分类方面的一些探讨,每个算法都有其独特的优势和适用场景,在实际应用中,我们可以根据具体问题选择最合适的算法来构建强大的预测与分类模型。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 5
5 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)