记忆成本狂砍19倍!阿里联合清华北大提出:统一的终身导航框架
▲图6|压缩率与记忆长度的折中:压太狠会掉精度,压得适中更划算。在 GOAT-Bench 的未见场景子集上,对比不同 token 压缩率与不同存储图像数量下的导航准确性,展示“更长记忆”通常有益,但“过度压缩”会让关键线索丢失,从而影响表现。,针对这一现实痛点:让机器人在“终身导航”设置下,不用改下游模型,即插即用,在陌生环境探索成功率提升 15%,熟悉环境路径效率翻倍。更重要的是,这种“上下文压
目录

将“记忆”粗暴等同于“存视频”
——方法论陷阱
具身导航想落地 “长期驻场”,核心矛盾是:机器人必须存下过往路径和地标,但现有图像中心方法一沾历史视觉数据就瘫痪。
让机器人在真实楼宇里找打印室,第一次,它靠试探、摸索、试错;可当第二次、第三次再去同一个地方,照样把整层楼重新排查一遍,像“第一次来”。
问题不在于它看不见,而在于它记不住,或者说“记忆”太贵了。
很多端到端导航方法如果想把一路看到的画面都塞进模型上下文,就会被视觉 token 的数量拖垮,算力、显存、推理速度一起吃紧。
这导致所谓终身学习机器人,本质上只是个带硬盘的摄像头——路径重复探索,算力空耗在冗余像素里。

近日,来自阿里、清华、北大团队提出的 AstraNav-Memory,针对这一现实痛点:让机器人在“终身导航”设置下,不用改下游模型,即插即用,在陌生环境探索成功率提升 15%,熟悉环境路径效率翻倍。
01 问题背景
具身导航面临一个很现实的问题——
机器人如果想“长期在同一栋楼里工作”,就得把以前走过的路、见过的地标带在身上。
可现在很多图像中心的导航方法,一旦想把历史画面放进模型,就会被“信息量”压垮。
这里的关键问题在于:视觉Tokens
你可以把它理解成:模型不会直接“吃”一张完整图片,而是先把图片切成很多小块,每一块变成一个小的“信息碎片”,这些碎片合起来才是模型眼里的图像。
碎片越多,模型看得越细,但计算也越慢、越吃显存。
例如:一帧 720×640 的图像进入视觉语言模型(Qwen2.5-VL)后,会变成将近 600 个这样的碎片。要是再把几百帧历史都塞进去,就像把一本厚厚的相册一次性摊在桌上,模型再聪明也容易“看不过来”。
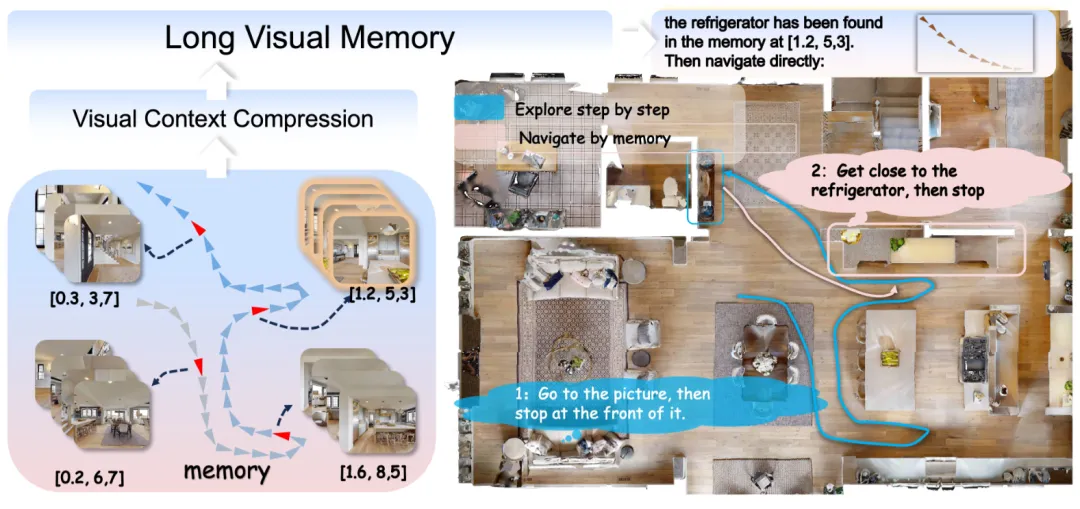
▲图1|终身导航(lifelong)设定:先探索一次,后面靠记忆省大力气。第一次进入陌生环境时,智能体需要用“前沿探索”(去未知区域试探)找到目标。关键在于:环境状态和智能体状态不会在任务之间重置,会被保留下来。后续再收到新指令时,智能体会先查自己的记忆,如果之前见过目标,就能直接规划到目标位置的路径,不用再把环境重新探索一遍
AstraNav-Memory 的解决思路是:给这些视觉碎片做一次“上下文压缩”。
它先用一个已经训练好的视觉特征提取器,再用轻量模块把每帧图像的碎片数量大幅压缩到一个固定、很小的规模。
这样,机器人就能在不把算力拖垮的前提下,把更长的历史带进决策过程。
最后,这些压缩后的信息会和语言指令一起送入大模型,由它输出下一步动作(前进、左转、右转、停止),实现连续导航。
02 技术亮点
用“视觉上下文压缩”把长历史塞进模型
终身导航要用记忆,就得处理大量历史观测,但原始视觉 tokens 数量太夸张。
AstraNav-Memory 将每帧压到约 30 tokens,相当于把“过去”的体积瘦身到“可携带”的程度,让智能体能在一个任务接一个任务的过程中持续利用历史。
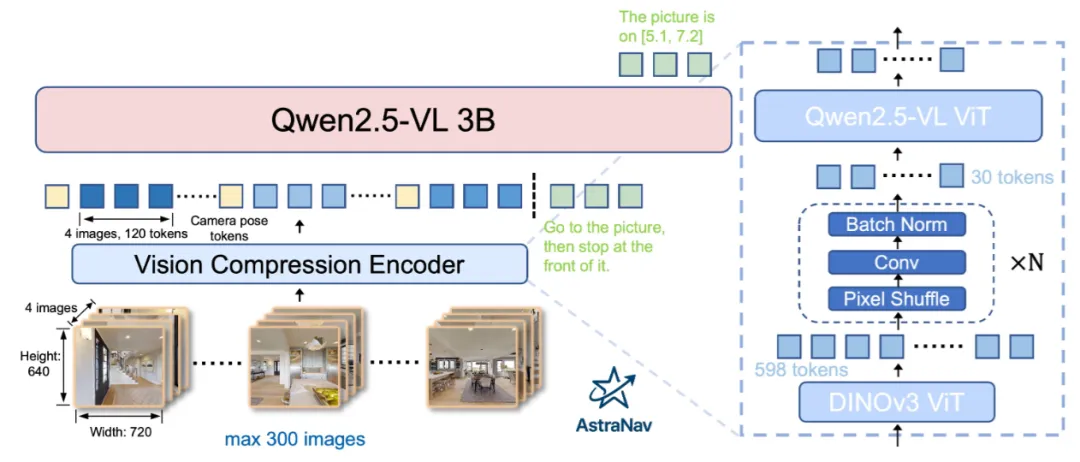
▲图2|AstraNav-Memory 框架:把“视觉信息”压缩后再送进大模型,实现长记忆推理。导航过程中最多会累计到数百张历史图像:先用 DINOv3 的 ViT 把每张图像编码成大量视觉 token(可理解成图像被拆成很多“信息碎片”),再用轻量压缩头把这些碎片压到更小数量,使其能兼容 Qwen2.5-VL 原有的视觉输入格式。压缩后的视觉 token 与语言指令一起送入 Qwen2.5-VL-3B,从而在较低计算开销下对“长历史视觉记忆”进行推理与决策
这一步的意义是工程性的:记忆不再是“想要但用不起”的奢侈品,机器人在执行重复任务的时候不需要每次都把任务当做“第一次”来执行。
压缩不是简单下采样,而是尽量保住“空间线索”和“地标差异”
研究在压缩模块里用了记忆载体重排式的处理思路,不只是做平均池化那种“粗暴”缩小。
压缩的过程一定是伴随着信息损失的,但是对于导航任务,如果机器人能够记住每一个关键的路标点,那么导航过程中的“街景”似乎没那么重要。
因此研究的核心思路,是在压缩的过程中保留重要的信息,也就是中层的特征。
中层特征能把一些类别差异和区域显著性保留下来,因为走路更依赖布局、通行区域、转角地标,而不是只靠物体分类。
换句话说,它压的是 token 数量,尽量不压掉“方向感”。

▲图3|DINOv3 特征可视化:模型在图里会把哪些区域当成“相似地标”。对每张图先选一个小区域作为查询点,再计算它与整张图其他区域的特征相似度,并画成热力图。颜色越暖表示越相似,用于直观展示 DINOv3 的中层特征能抓住哪些结构或纹理线索
端到端系统提升效率与可扩展性
压缩器输出的 tokens 被设计成能直接喂进 Qwen2.5-VL 的视觉入口(从第一个 block 开始继续处理),语言模型部分不需要大改。
这样做的好处是:系统既能继承大模型的指令理解能力,又能让它在更长历史下仍然跑得动。
03 实验与表现
该实验的核心直面回答两件事:
- 第一,压缩后还能不能“记得对”,即长记忆到底有没有变成真正的导航收益;
- 第二,压缩到底能省多少资源,能不能让终身导航在工程上跑得起来。
问题一:终身导航评测
在 GOAT-Bench 这种“一个任务接着一个任务、不重置环境”的终身导航评测里,研究展示了一个非常符合直觉的趋势:
第一次进入环境时,机器人仍需要探索;但随着任务推进,它越来越会利用记忆,路线从“到处试探”变成“更直接的走法”。
这点在他们的轨迹可视化里很直观,一条是探索式的弯弯绕绕,另一条更像记住路之后的近最短路径。
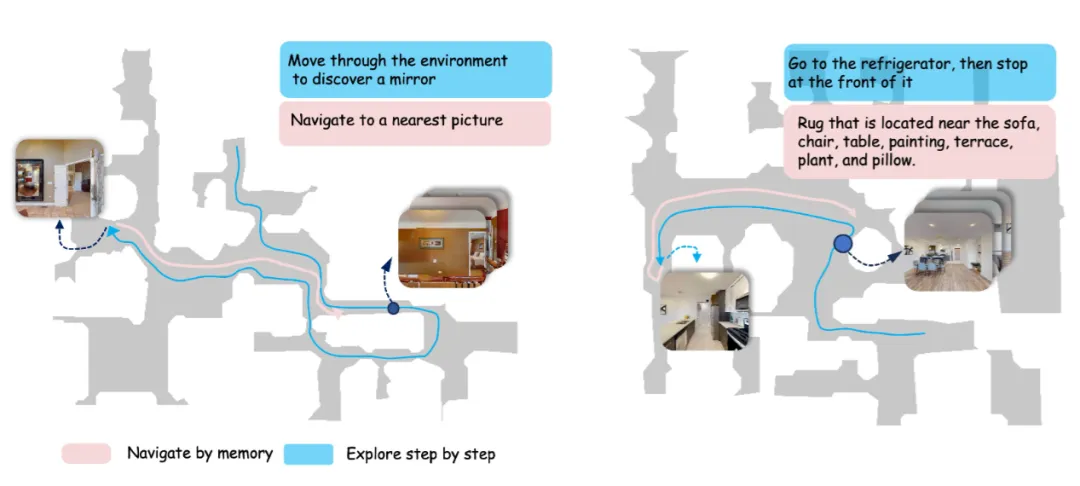
▲图5|两种导航模式对比:一步步探索 vs 查记忆走“近似最优路”。在 Habitat-Sim 中可视化 GOAT-Bench 的导航过程:一种是逐步探索未知区域、边走边找;另一种是在记忆中已有线索时,直接按记忆规划更接近最短的路径,体现“终身记忆”带来的效率优势
定量结果显示:在未见场景上,AstraNav-Memory 的成功率与路径效率达到 62.7% SR / 56.9% SPL,并显著高于文中对比的若干方法。
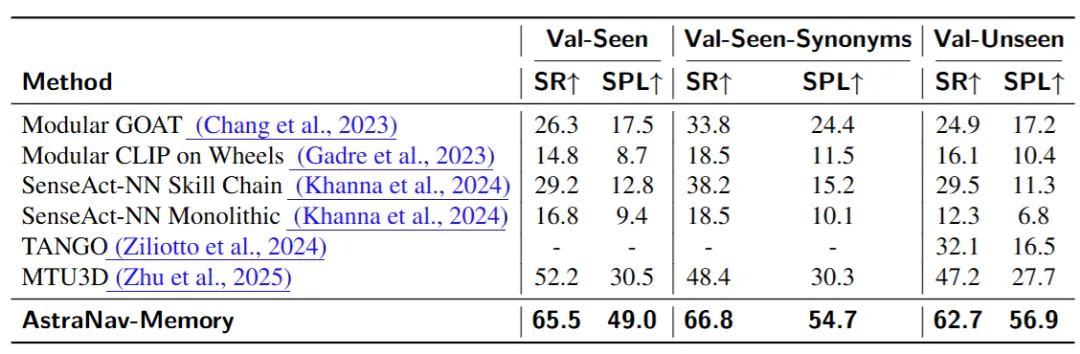
▲图4|GOAT-Bench 终身导航主结果:成功率与路径效率对比。给出多模态终身导航设置下的两项核心指标:成功率(SR)与路径效率(SPL),用于衡量模型是否“能到达”和“走得是否划算”
更重要的是,该方法在“未见环境”上优势更明显,这说明压缩后的记忆不只是背答案,而是在更泛化的场景里也能派上用场。
问题二:压缩的价值平衡
接着是消融实验讲清“怎么压才不翻车”。
研究结论很明确:压缩比不是越大越好。
压得过狠(例如 64×)会让性能明显下滑,说明信息被压没了;而适中的压缩通常能在保持效果的同时,把算力开销压下来。
换句话说,它不是单纯“省”,而是在省的同时尽量保住导航最关键的线索。
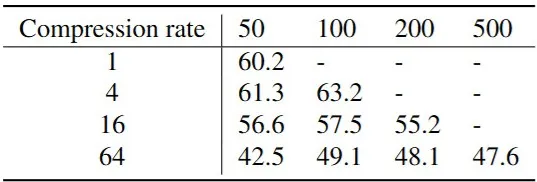
▲图6|压缩率与记忆长度的折中:压太狠会掉精度,压得适中更划算。在 GOAT-Bench 的未见场景子集上,对比不同 token 压缩率与不同存储图像数量下的导航准确性,展示“更长记忆”通常有益,但“过度压缩”会让关键线索丢失,从而影响表现
同样训练设置下,压缩能明显减少迭代时间、显存占用和推理耗时。这一点对“终身导航”尤其关键,因为终身任务的历史会越来越长,只有当模型在长历史下仍然跑得动,“记忆”才不是演示,而是真能上系统。
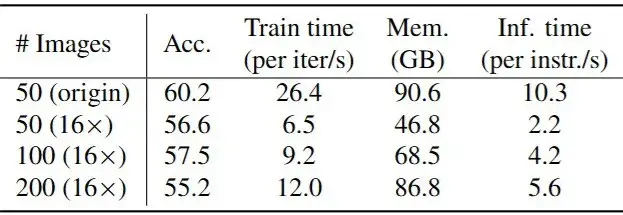
▲图7|效率对比:在不同“记忆长度”(存储图像数量)下,使用与不使用 16× token 压缩时的训练/推理效率开销,说明压缩能显著缓解长记忆带来的计算压力
04 总结
AstraNav-Memory 给终身具身导航提供了一个很务实的方向:与其不断想办法让模型“更能记”,不如先让记忆“更便宜”。
当每帧视觉信息从几百个 tokens 缩到几十个,几百帧历史才有机会真正进入决策过程,机器人也才可能在熟悉环境里越跑越顺。
同时我们也注意到其局限性:对地毯这类依赖细粒度纹理的目标,特征易模糊导致性能下滑;压缩率需精准把控;且当前仅验证静态场景,动态环境适应性仍待测试。
从行业来看,具身导航落地还需补全短板:融合 SAM 等模型的边界特征覆盖细粒度目标、设计动态压缩率适配场景变化。
但这篇论文的核心价值在于撕开了 “存储即记忆” 的误区 —— 更重要的是,这种“上下文压缩”的思路不只服务导航,它也在提醒我们:具身智能的长时能力,往往先卡在算力与表示的现实边界。
Ref:
论文题目:AstraNav-Memory: Contexts Compression forLong Memory
论文作者:Botao Ren, Junjun Hu, Xinda Xue, Minghua Luo, Jintao Chen, Haochen Bai, Liangliang You, Mu Xu
论文地址:https://arxiv.org/pdf/2512.21627
项目地址:https://astra-amap.github.io/AstraNav-Memory.github.io/

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 17
17 0
0- 0



 已为社区贡献55条内容
已为社区贡献55条内容

所有评论(0)