自动驾驶VLA和世界模型的统一架构论文笔记:DriveVLA-W0[中科院&引望],MindDrive[北航],UniUGP[字节Seed]
DriveVLA-W0[中科院&引望],MindDrive[北航],UniUGP[字节Seed] 论文解读
【如果笔记对你有帮助,欢迎关注&点赞&收藏,收到正反馈会加快更新!谢谢支持!】
论文1: DriveVLA-W0: World Models Amplify Data Scaling Law in Autonomous Driving
- 动机:VLA的训练仅依赖于稀疏的、低维度的动作信号(如转向、油门等),模型无法充分利用其表征能力来学习丰富的世界动态表示
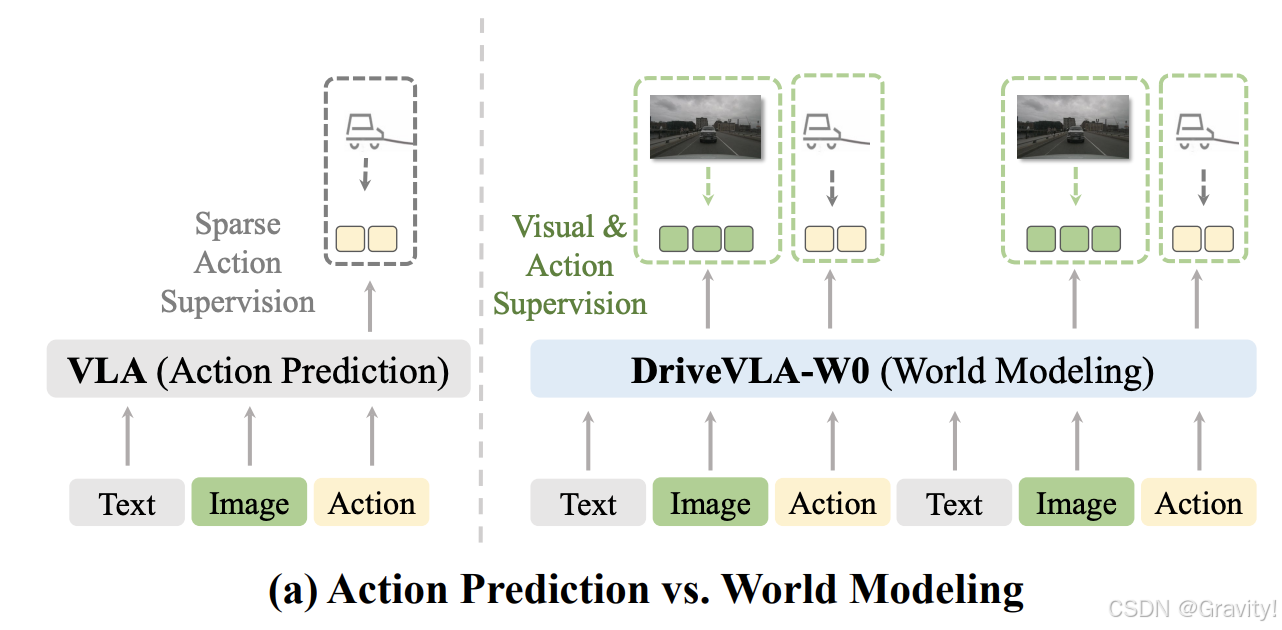
- 解决:用世界模型作为自监督任务,生成密集且丰富的监督信号,迫使模型学习环境的底层动态,不仅预测未来的动作,还预测未来的视觉场景
- 覆盖两种主流VLA:1. 离散token【AR世界模型】 2. 连续特征【扩散世界模型】
- 世界建模能显著放大VLA的数据缩放效应 → 随着训练数据量(从7万帧到7000万帧)的增加,性能提升更近显著
- Pipeline
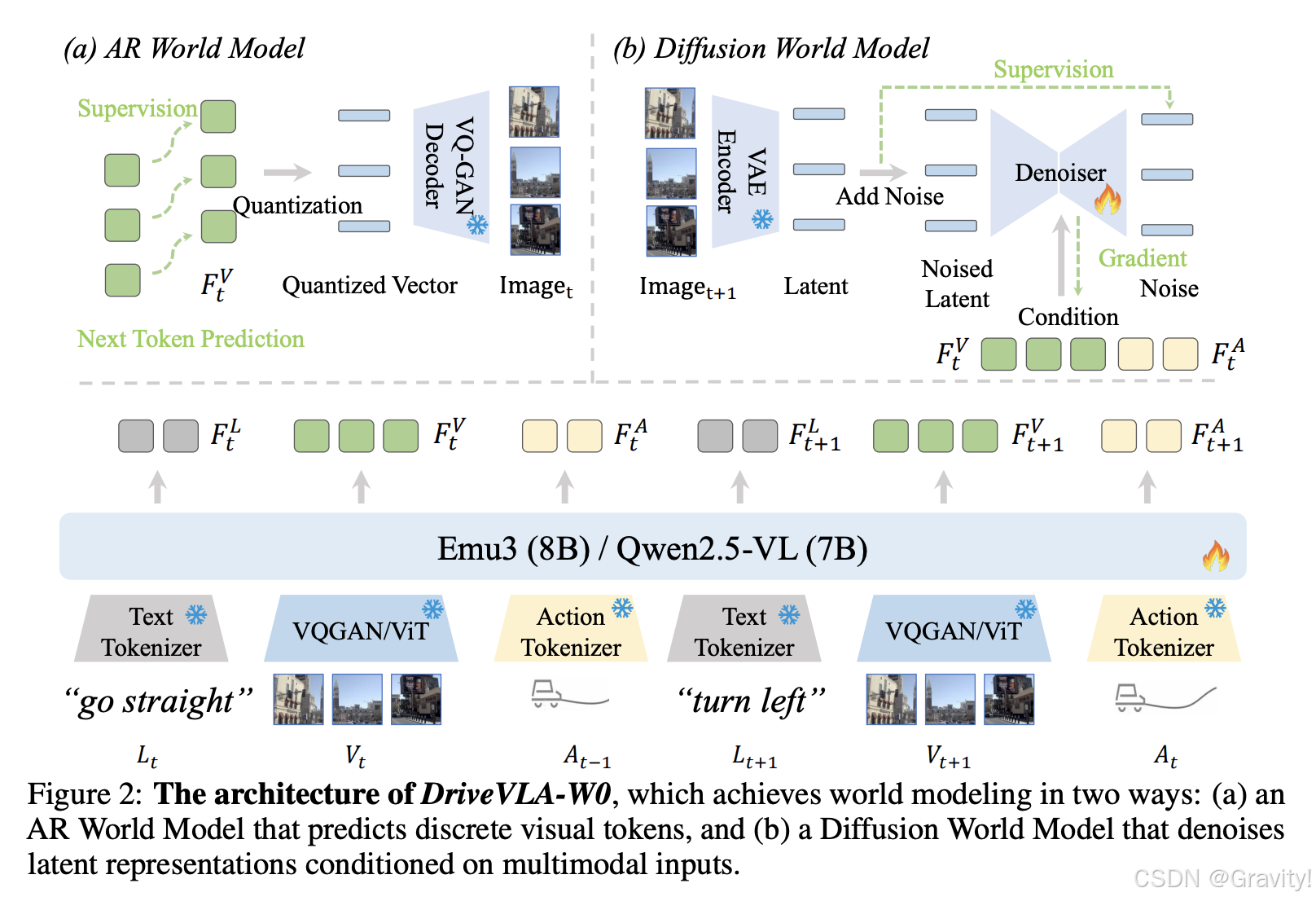
- 世界模型部分:
- AR World Model:图像离散token的embedding送到VQ-GAN
- Diffusion World Model:连续的图像token作为diffusion的condition输入
- 动作专家MoE:Action Expert和VLA架构层数相同,压缩hidden states纬度。两者Attention共享
- Query-based (输入action query):单次前向传播即可输出整个轨迹,速度最快
- Autoregressive (Action Token自回归):建模能力强大,但推理速度取决于需要生成的token数量
- Flow Matching(Noised Action去噪):能产生高质量的连续轨迹,但需要多步迭代去噪,推理速度较慢
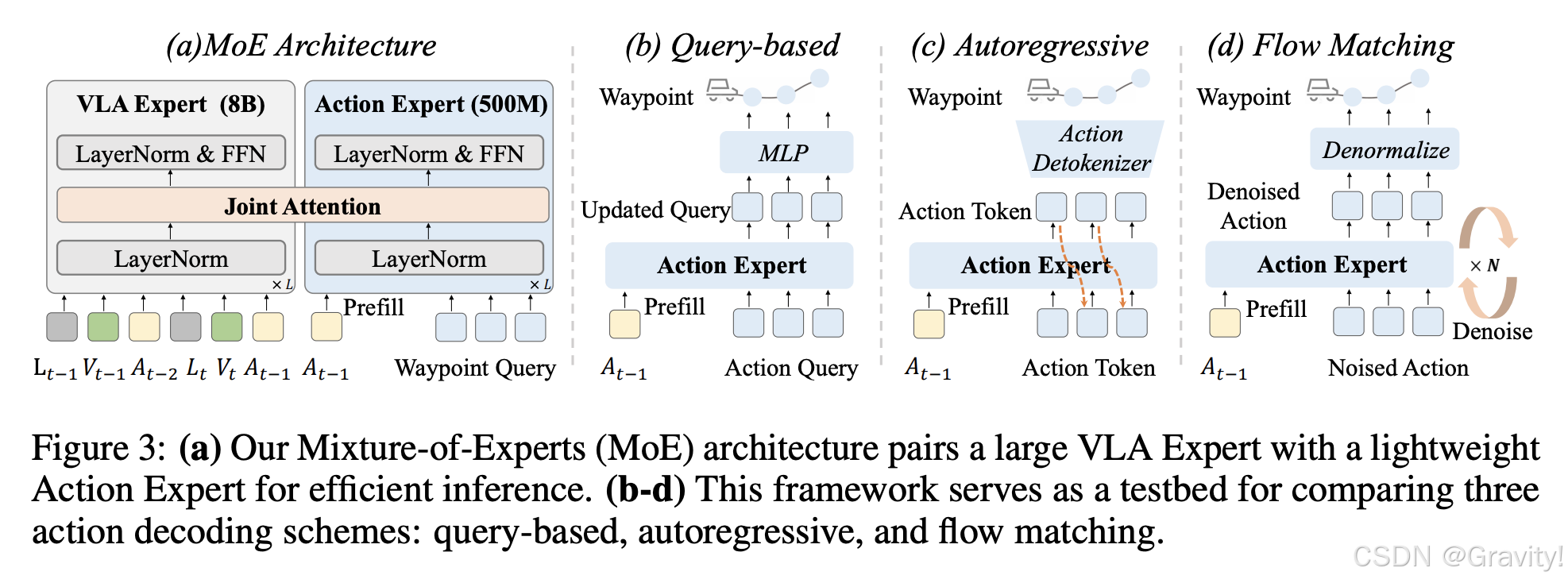
- 实验
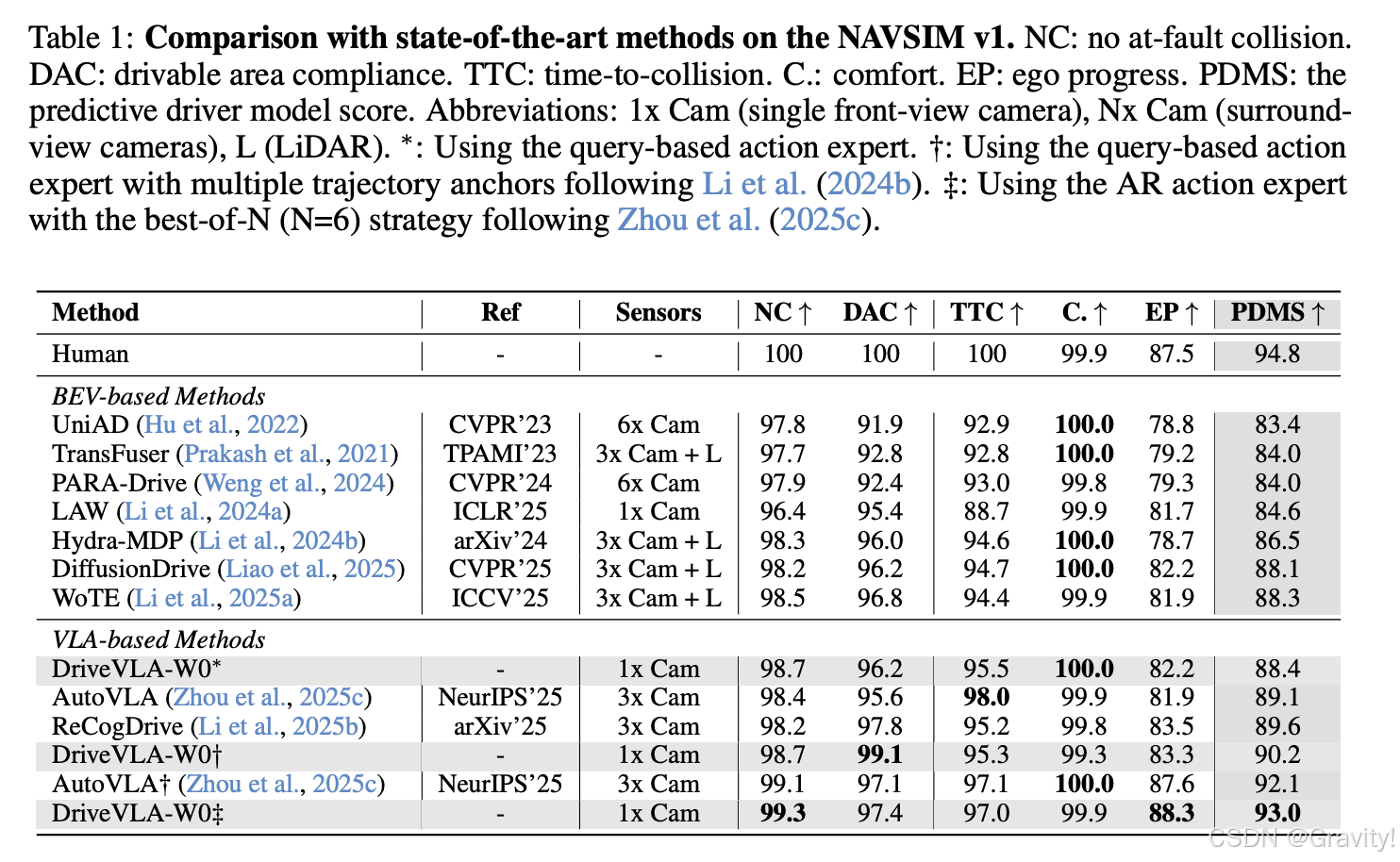
- 结论:
- 世界模型显著提升了数据缩放定律
- 世界模型增强了模型的泛化能力
- 动作解码器的性能在大规模数据下发生逆转:在小型 NAVSIM 数据集上,基于查询的解码器表现最好,因为轨迹分布简单,其高精度占优;在大型内部数据集上:自回归解码器成为最佳选择
论文1: MindDrive: An All-in-One Framework Bridging World Models and Vision-Language Model for End-to-End Autonomous Driving
- 当前端到端自动驾驶的轨迹规划的两个方向
- Trajectory generation-oriented methods 轨迹生成导向:专注生成高质量、多样化的轨迹,但最终的轨迹选择机制(如简单的MLP头)较为薄弱,缺乏多目标评估;如 VADv2, GaussianAD, DiffusionDrive
- Trajectory selection-oriented methods 轨迹选择导向: 侧重于对预生成的轨迹候选进行多维度评估(如安全性、舒适性、效率),但其轨迹生成能力有限 如 WoTE, Hydra-MDP
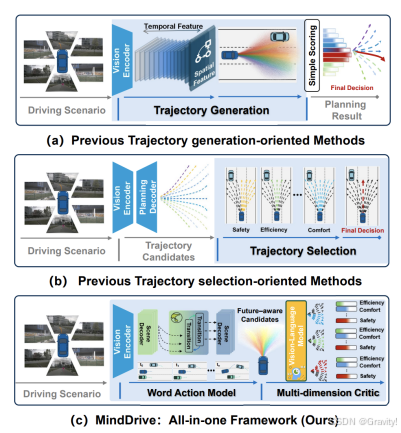
- MindDrive为轨迹生成(WM) + 轨迹选择(VLM)
- “what-if simulation – candidate generation – multi-objective trade-off.” “假设模拟 - 候选生成 - 多目标权衡” 结构化推理过程
- Future-aware Trajectory Generator 世界动作模型 + VLM-oriented Evaluator 视觉语言模型
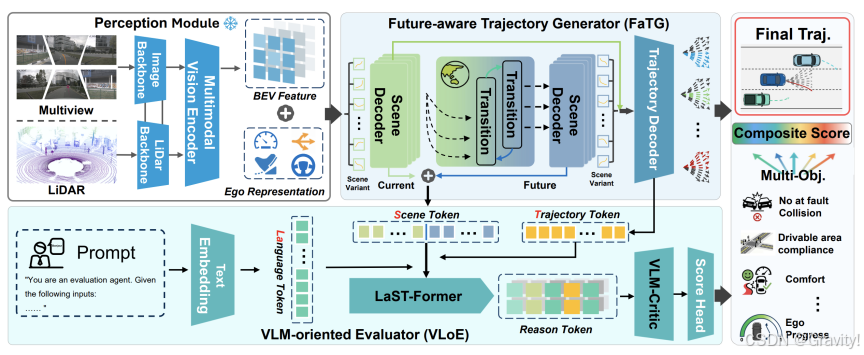
- Pipeline
- 感知模块: 融合多视角相机和LiDAR数据,生成BEV特征表示,并提取自车状态和初始行为意图。
- 轨迹生成 (FaTG): 将不同行为意图注入BEV特征,构建场景变体。WAM对这些变体进行时空推演,预测未来状态。轨迹解码器结合当前和预测特征,生成多样化的轨迹候选。
- 轨迹选择 (VLoE): LaST-Former模块将prompt、场景token和轨迹token对齐融合成推理令牌。VLM-Critic则基于这些令牌进行语言引导的推理,输出多目标评分,从而选择最终轨迹。
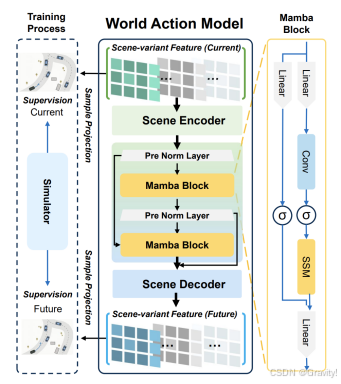
- World Action Model (WAM)
- 场景变体特征构建 (Scene-Variant Feature Construction)
- 目的:从同一个当前状态,生成多个代表不同未来可能性的“场景变体”。 方法: 首先,通过对训练数据集中所有专家轨迹进行 K-Means 聚类,得到 N 个轨迹锚点 (Trajectory Anchors),这些锚点代表了自车可能采取的几种基本行为意图(如左转、直行、右转的倾向)。
- 每个轨迹锚点经过编码后,与自车状态特征融合,生成一个动作令牌 (Action Token),该令牌编码了自车的初始意图。
- 将这个动作令牌通过双线性插值的方式,“注入”到从感知模块得到的鸟瞰图特征图中。这样,对于每个动作意图,都创建了一个独特的场景变体特征,它假设自车将按照该意图行动。
- 世界模型推演 (World-Model Rollout)
- 目的:对上述每个场景变体进行未来多步的预测,模拟其时空演化。
- 架构:WAM 采用了一种“空间-时序-空间三明治”架构,以确保高效和准确的预测
- 空间编码 (Transformer Encoder):首先使用 Transformer 编码器处理场景变体特征,捕捉当前时刻场景中各元素(自车、周围车辆、道路结构)之间的空间依赖关系。
- 时序推理 (Mamba Blocks):然后使用 Mamba(一种选择性状态空间模型)块进行时序推理。Mamba 能以线性计算复杂度高效地模拟时间动态,预测未来几个时间步的潜在场景状态。论文中采用了两个 Mamba 块进行堆叠,以增强时序建模能力。
- 空间重建 (Transformer Decoder):最后,再使用一个 Transformer 解码器将时序推理后的特征重新映射回场景特征空间,生成未来场景变体特征。 通过多步递归推演,WAM 能够为每个初始动作意图生成一系列未来的场景状态预测。
- 场景变体特征构建 (Scene-Variant Feature Construction)
- 轨迹解码器 (Trajectory Decoder)
- 场景特征增强 (Scene-Feature Augmentation)
-
对于每个轨迹候选
n,解码器会获取其对应的当前时刻的场景变体特征和 WAM 预测的未来某时刻的场景特征。 -
将这两个特征在通道维度上进行拼接,形成一个增强的时空嵌入。这个嵌入同时包含了当前环境的静态信息和在未来演变的动态信息。
-
-
轨迹候选生成 (Trajectory Candidate Generation)
-
每个动作令牌(代表初始意图)会与它对应的增强时空嵌入进行多头交叉注意力 (Multi-Head Cross-Attention, MHCA) 计算。这个过程可以理解为让自车的意图去“查询”当前和未来的环境上下文
-
注意力计算的结果被送入一个轻量级的轨迹解码头,输出一组相对于初始轨迹锚点的偏移量
-
最终,轨迹候选 = 轨迹锚点 + 预测偏移量。这样生成的轨迹不仅符合初始意图,而且已经考虑到了该行为可能引发的未来环境变化,从而更加合理和安全
-
- 场景特征增强 (Scene-Feature Augmentation)
-
VLM-oriented Evaluator, VLoE
-
LaST-Former:语言-场景-轨迹对齐融合器
-
令牌编码 (Token Encoding)
-
场景令牌 (Scene Token):将 WAM 预测的多时刻未来场景特征在时间维度上拼接,形成一个包含时空信息的综合场景表示。然后通过一个卷积网络和投影层将其压缩为一维的序列化场景上下文特征。
-
Sentinel Insertion哨兵插入:用 <scene> 和 <traj> 作为占位符,模型处理时被替换为实际特征,对齐到同个序列
-
-
VLM-Critic (Language-guided Evaluation)
-
Score Token (<score_feature>): 额外添加的特殊token,聚合整个推理序列中的上下文信息,充当“评估节点”
-
推理:模型会提取 <score_feature>令牌对应的hidden state作为评估特征。这个特征向量包含了 VLM 对当前轨迹候选在安全性、舒适性、效率等多个维度的“理解”
-
Scoring head:轻量级的评分头,输出最终的、量化的轨迹综合得分
-
-
-
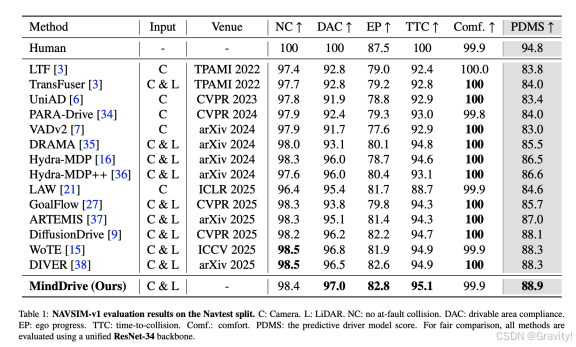
实验
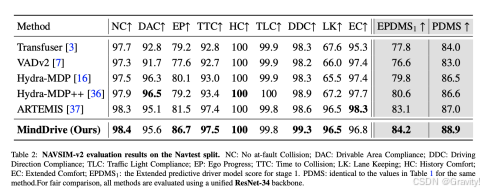
-
消融实验结论
-
在处理高风险、长尾场景时的强大安全性(安全关键场景集 Navsafe)
-
规划轨迹在面对未来环境不确定性时具有更好的稳定性和鲁棒性(交互密集型挑战集 Navhard)
-
同时使用未来感知轨迹生成器(FaTG)和VLM导向评估器(VLoE)时性能最佳,两者是互补且不可或缺的
-
采用 Transformer-Mamba 混合架构(“三明治”设计)并进行多步递归预测(0s→2s→4s)能获得最优性能
-
加入VLM进行推理评估后,在指标上均有显著提升
-
论文2:UniUGP: Unifying Understanding, Generation, and Planing For End-to-end Autonomous Driving
- Motivation
- World Model: Generation and Action Planning ✅ Understanding and Reasoning ❌
- VLM & VLA Knowledge and Reasoning of LLM ✅ Generation and Interactivity ❌
- Unified Models: Understanding and Generation ✅ Reasoning or Interaction ❌ Continuous Generation or Action ❌
- 数据构建
- Data Source: Waymo-E2E, DADA2000, Lost and Found (LaF), StreetHazards (StHa), SOM, AADV
- 标注任务包括:小物体检测、事故主体关系分析、事故预测、CoT推理等
- 数据处理与任务构建:
- 感知与理解:数据集标签和VLM 【小物体识别,事故主体关系,异常事故预测(判断题和选择题)】
- 因果思维链推理:用真实的未来规划轨迹和prompt,引导VLM生成准确的CoT,并进行人工校准 【场景分析 → 关键物体识别 → 意图推断(物体的可能未来运动及其对自车的影响) → 行动原因】
- 规划:数据集中的真实车辆的未来轨迹
- 指令遵循任务:语言指令与具体驾驶动作之间的映射关系,构建QA对
- Pipeline
- 采用混合专家架构(理解专家、规划专家和生成专家)
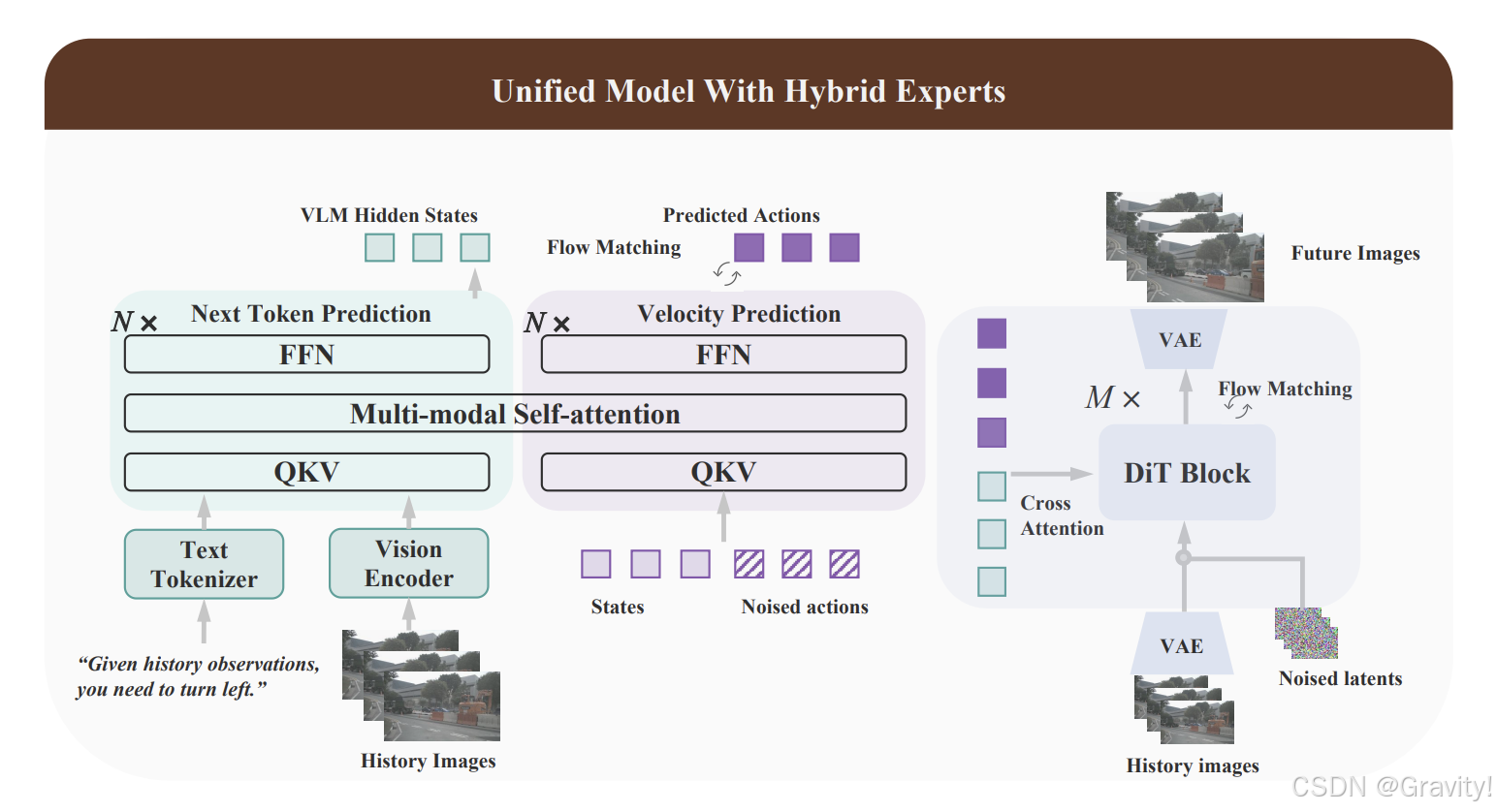
- 理解专家与规划专家【混合Transformer 架构】
- 理解专家:Next-token Prediction for Causal Reasoning,以 Qwen2.5-VL 作为backbone
- 语义理解和推理,包括分析交通场景、识别关键物体、推断交互意图,并生成可解释的CoT推理过程
- 规划专家:Mixture-of-Transformers (MoT) 结构,用Flow Matching来建模未来的轨迹
- 两个专家的 token 通过多个 MoT 层进行交互,每层先进行跨模态Self-Attn,然后通过各自的FFN。
- 最终,理解专家的输出被映射为文本 logits,规划专家的输出被映射为预测的去噪向量场
- 理解专家:Next-token Prediction for Causal Reasoning,以 Qwen2.5-VL 作为backbone
- 生成专家【DiT 架构】
- 串联方式与理解和规划专家交互
- Flow Matching 来生成未来视频,以 Wan2.1 作为基础模型
- 输入包括由 VAE 编码的历史图像 token 和加噪的未来图像 token,生成条件则来自理解专家的隐藏状态和规划专家预测动作的嵌入
- 输出是预测的去噪向量场(指示了如何将加噪的帧 “推”向真实的未来帧)
- Action embeddings设计:50%用真实轨迹(准确的指导信号),50%用规划专家预测的轨迹(增强鲁棒性,促进专家对齐)
- 采用混合专家架构(理解专家、规划专家和生成专家)
- 训练流程
- Stage 1 基础场景理解:理解专家建立对多样化驾驶场景(包括常见交通和长尾案例)的全面理解
Stage 2 视觉动态建模与规划:训练生成和规划专家,理解专家冻结
Stage 3 文本推理学习:将思维链推理能力整合进理解专家
Stage 4 多能力融合混合训练:联合训练三个专家,增强跨场景的泛化能力,实现一致的端到端性能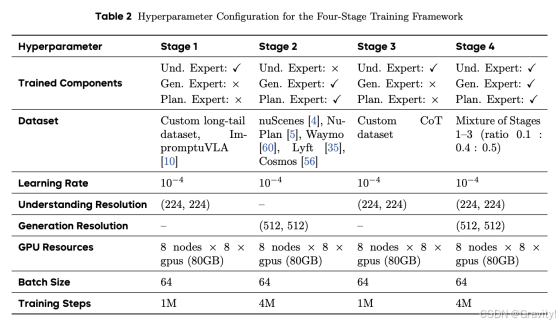
- Stage 1 基础场景理解:理解专家建立对多样化驾驶场景(包括常见交通和长尾案例)的全面理解
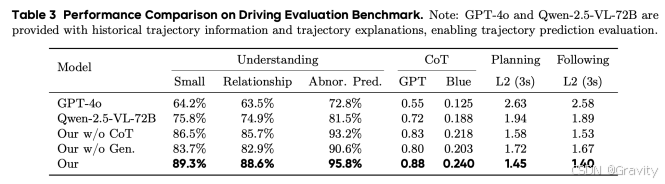
- 实验

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 11
11 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)