Act2Goal——基于世界模型的通用目标条件策略:生成未来视觉轨迹指导低层运动控制,且MSTH将轨迹分解为近端和远端帧,以兼顾长时规划与局部控制
摘要:本文介绍了智元团队2025年底发布的Act2Goal框架,该研究将目标条件世界模型与多尺度时间哈希机制结合,解决了长时程任务中的泛化难题。通过分解视觉轨迹为近端控制帧和远端规划帧,实现了全局一致性与局部响应性的平衡。框架支持基于Hindsight Experience Replay的无监督在线改进,采用LoRA微调实现快速适应。相比传统方法,Act2Goal通过显式建模视觉动态过程,为机器人
前言
今天的新的一年2026年第一天,从2010年10月写博至今,竟然已写博15年3个月,这15年多的时间,我回顾了下每一年写博客的数量,发现最近三年真是疯狂更新,一方面解读大量论文,二方面分享我司的各种大模型实践、具身实践
之所以在过去三年如此疯狂更新,个人觉得归根结底有两个原因
- chatgpt重新唤醒了我对技术的绝对热情,比如大模型、特别是具身智能
- 过去三年,我司从教育公司先后历经大模型应用开发、具身开发
而在具身落地的过程中,技术亟待突破
一方面,需要保持对最新技术的追踪
二方面,具身智能把「个人热情和工作需要」完美的结合在了一起,既照顾了个人兴趣,又推动了公司
三方面,我十分的清楚,无论是我对论文解读,还是分享我司在具身落地方面的实践经验,都会帮助千千万万的人
如此,使得我持续更新本博客的动力 达到最高点,史无前例
过去一年,不少研究团队发布过世界模型相关的工作,新的一年第一篇解读就来介绍智元于25年年底发布的Act2Goal吧
第一部分 Act2Goal: From World Model To GeneralGoal-conditioned Policy
1.1 引言与相关工作
1.1.1 引言
如原论文所述,目标条件策略(Goal-conditioned policies,GCPs)将当前观测与目标视觉目标直接映射为动作 [1, 2, 3, 4]
- 尽管这些方法在短时程设定中表现良好,并展现出一定的泛化能力[5, 6],但在长时程任务中的性能会下降
这一局限性的产生是因为标准的 GCPs 通过直接动作预测进行决策 [7],因而缺乏对任务进展、中间可行性或长时跨度一致性的显式表征 - 这个问题在使用范围狭窄的示范数据训练 GCPs 时会进一步加剧。缺少朝向目标的视觉状态转移的显式模型时,此类策略往往会对示范中的状态–动作映射发生过拟合,并且必须依赖稠密监督来弥补缺乏结构化中间引导的不足
这一局限在长时跨度或分布外场景中尤为明显,此时要保持朝向目标的连贯推进,需要进行超出局部观测到的状态转移之外的推理
因此,为了在示范数据之外实现泛化,GCPs 必须显式建模达到期望目标所需的视觉动态过程。缺少这种机制时,策略就无法分辨哪些动作能够实质性地推动朝目标前进,哪些动作仅仅是在局部上匹配示范中观察到的状态–动作相关性
- 世界模型的最新进展为解决这些局限性提供了一条很有前景的途径
8-Sora
9-LTX-Video: Realtime Video Latent Diffusion
10-Cosmos world foundation model platform for physical ai
视觉–语言世界模型表明,在任务指令条件下对未来视觉状态进行生成式预测,可以有效支持规划与决策
11-Video prediction policy:A generalist robot policy with predictive visual representations
12-Vidman: Exploiting implicit dynamics from video diffusion model for effective robot manipulation
13-Genie envisioner: A unified world foundation platform for robotic manipulation - 基于这一洞见,作者考虑其在目标条件下的对应形式:目标条件世界模型(goal-conditioned world model)
目标条件世界模型并非从高层语言出发预测未来,而是生成一段合理的中间状态序列,用以弥合当前观测与期望视觉目标之间的鸿沟
————
借助这一能力,弥补了传统 GCPs 的一个根本局限:通过显式表示场景随时间演化的过程,使得朝向特定目标的轨迹在视觉上有据可依,并与任务保持一致
然而,预测一个合理的视觉路径只是问题的一部分。要可靠地执行长时域操作任务,还必须解决更深层次的控制挑战
一个通用的 GCP 必须在全局一致性——即保持对长期目标的忠实性,与局部反应性(即对扰动做出鲁棒响应并在闭环执行中纠正误差)之间取得平衡 全轨迹规划能够提供全局连贯性,但在发生偏离时却非常脆弱;
短时域控制则可以提高鲁棒性,却在长时间任务中很容易丧失方向一致性
这种内在张力构成了将 GCP 部署为通用机器人控制器的一个根本性障碍
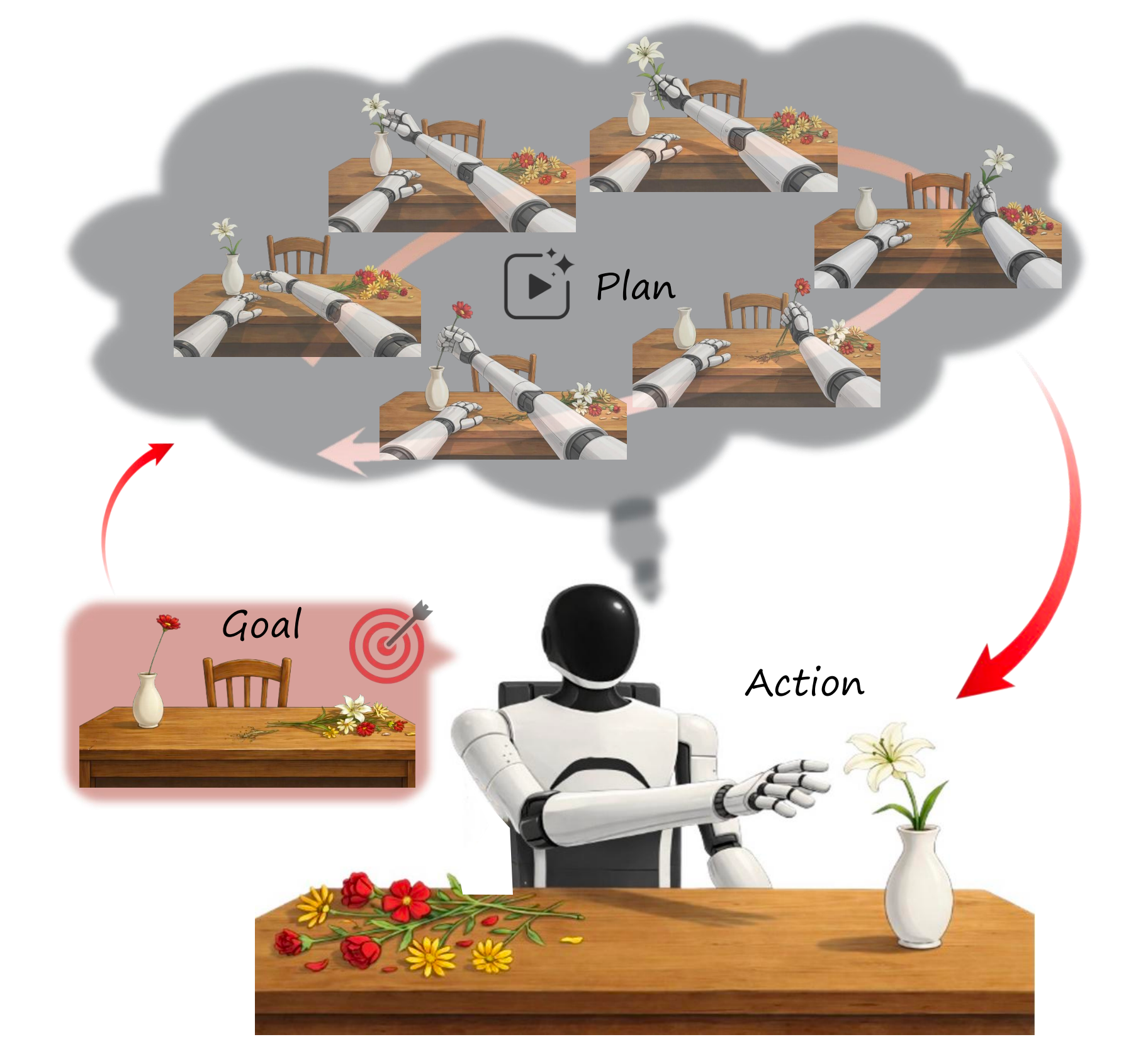
为弥合这一差距,来自的研究者提出 Act2Goal
- 其论文地址为:Act2Goal: From World Model To General Goal-conditioned Policy
其作者包括
Pengfei Zhou1*, Liliang Chen1*, Shengcong Chen1, Di Chen1,
Wenzhi Zhao1, Rongjun Jin1, Guanghui Ren1, Jianlan Luo1† - 其项目地址为:act2goal.github.io
具体而言,这是一种通用的目标条件策略,将目标条件世界模型与一种称为多尺度时间哈希(Multi-Scale Temporal Hashing,MSTH)的新型时间分解机制相结合
- MSTH 将生成的视觉轨迹分解为用于细粒度控制的稠密近端帧,以及稀疏且可随时间视野自适应(无需奖励的在线自适应机制)的远端帧,用来锚定全局规划
MSTH decomposes the generated visual trajectory into dense proximal frames for fine-grained control and sparse, horizon-adaptive distal frames that anchor the global plan.
说白了,即将轨迹分解为近端和远端帧,在长时规划与闭环局部控制之间取得平衡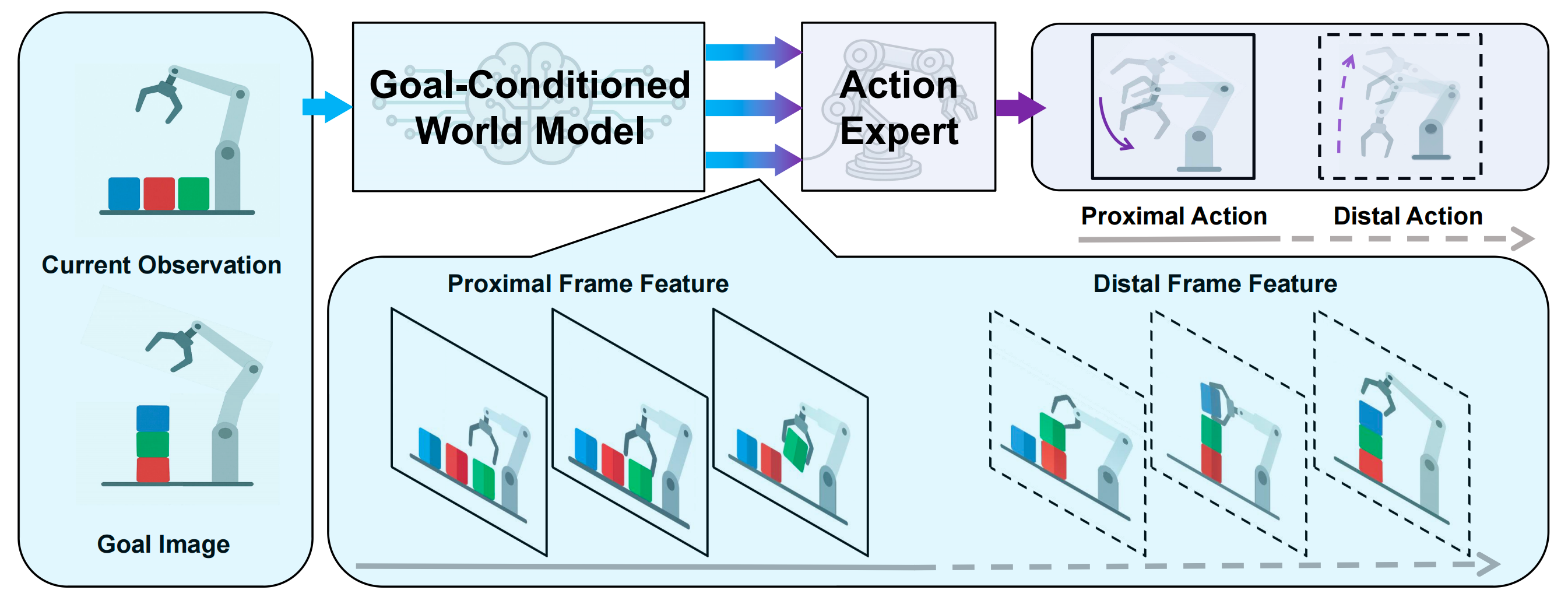
- 这样的多尺度结构使策略在闭环执行过程中,既能够对长时间跨度的目标进行推理,又能快速响应局部扰动
————
且作者进一步通过逐层交叉注意力将目标条件世界模型与动作专家耦合起来,使中间视觉表征能够在端到端可微分的架构中指导低层次运动控制
We further couple the goal-conditioned world model with an action expert via layer-wise cross-attention,allowing intermediate visual representations to guide low-level motor control in an end-to-end differentiable architecture
总之
- 一方面,Act2Goal 还通过Hindsight Experience Replay (HER) [14] 支持无需奖励的在线自主改进。通过将自身的 rollout 重新标注为额外的达成目标的轨迹,并通过基于 LoRA 的微调 [15] 高效更新策略,系统可以在没有外部监督的情况下快速适应新的真实场景
- 二方面,目标条件化的世界模型与多尺度时间推理相结合,能够为长时间跨度操纵任务中的稳健泛化和闭环执行提供所需的结构化中间指导『that goal-conditionedworld models, combined with multi-scale temporal reasoning,provide the structured intermediate guidance necessary for ro-bust generalization and closed-loop execution in long-horizonmanipulation』
解释一下《Hindsight Experience Replay》
- 核心动机:解决“奖励稀疏”难题
在传统的强化学习中,为了让机器人学会复杂的任务(如把物体放入盒子里),研究人员通常需要精心设计“奖励函数”(Reward Shaping)来引导智能体
如果只给智能体一个简单的二元奖励(完成任务给 1,未完成给 0),智能体在早期由于随机探索几乎不可能触碰目标,从而无法获得任何正向反馈,导致学习失败- 灵感来源:从失败中学习
论文作者受人类行为的启发:当我们尝试完成一个目标却失败时,我们并不会一无所获例子:如果你练习打冰球,想把球射入球门却偏向了右侧。标准的强化学习算法会认为这次尝试失败了,学不到东西
HER 的逻辑:虽然你没射中球门,但你完成了一个“把球射入右侧某点”的任务。如果你把那个“错误点”当成目标,这次动作就是完美的- HER 的工作机制
HER 是一种可以与任何离策强化学习(Off-policy RL)**算法(如 DQN, DDPG)结合的技术
通用价值函数(UVFA):HER 要求智能体的策略不仅以“状态”为输入,还要以“目标”为输入
重新标记(Re-labeling):在训练过程中,智能体尝试完成目标但最终达到了状态
。HER 会将这段经历存入经验回放池(Replay Buffer)两次:
以原始目标
————
意义:这保证了即使智能体总是失败,回放池中也会有大量的“成功案例”供其学习如何到达不同的状态HER 实际上形成了一种隐式的“教学大纲”,它证明了通过巧妙地重新利用“失败”经验,让智能体先学会到达附近的状态,再逐渐学会到达更远的目标,让机器人在极度稀疏的反馈中学会极其复杂的技能
1.1.2 相关工作
作者认为,Act2Goal 策略将带有目标条件的世界模型,与能够在线自主改进的动作专家相结合
首先,对于目标条件策略
- 目标条件策略学习旨在训练智能体去达到多种形式的目标,例如视觉目标[2, 3, 4, 16, 17, 18, 19]、跟踪点[20, 21]以及运动场[22]
早期工作通过对目标进行重新标注[3, 14]来增强模仿学习,另一些工作则利用结构化的目标表示[4, 23]来扩展强化学习 - 最新进展进一步探索长时序推理[24]、基于关键帧的规划[24]以及通过程序综合生成目标[23,25]
其中,GoalGAIL[3]结合HER,从次优或仅有状态的示范中进行学习,从而在模仿学习场景中提升样本效率
CoA[24]提出从目标关键帧反向生成动作序列,以在操作任务中保持长时序的一致性 - 然而,这些方法通常依赖于显式的目标监督,或者在将当前观测与远期目标对齐方面存在困难
Act2Goal 通过引入一个以目标为条件的世界模型,用于模拟结构化的视觉轨迹,并提出多尺度时间哈希(Multi-ScaleTemporal Hashing,MSTH),以支持一致且高效的长时域规划,从而在未见任务上实现更好的泛化能力
其次,对于面向机器人控制的世界模型
世界模型已经成为机器人控制中的一种强大工具,使智能体能够模拟环境动力学 [26, 27, 28]、生成用于训练的合成数据 [29, 30],或作为学习得到的模拟器来指导策略学习[31, 32]
- 近期的工作进一步将世界模型与动作专家(Action Experts, AEs)结合,以构建策略规划系统 [33,34, 12, 11]
其中,世界模型提供未来状态特征,而 AE 则据此预测相应的动作 - 在这些方法中
GE-Act [13-Genie envisioner] 采用双模块架构:世界模型根据语言指令预测未来视觉特征,而基于Transformer 的规划器生成动作
WorldVLA [35]在统一的潜在空间中联合预测视觉与动作,旨在实现更紧密的视觉-动作对齐 - 不同于以往工作,Act2Goal 利用纯视觉的、以目标为条件的世界模型,通过结构化的视觉轨迹来引导策略学习
作者宣称,这是首个将世界模型整合到以目标为条件的策略学习中的工作
最后,对于在线自主改进
- 为在部署过程中提升策略的适应性,近期研究探索了通过交互式模仿学习(如 DAgger [36, 37,38])或上下文学习(in-context learning, ICL)[39, 40]进行在线改进
然而,DAgger 风格的方法需要频繁的专家干预,而 ICL 方法则不会更新模型权重,并且在复杂任务上通常表现受限 - 另一类研究工作利用 Hindsight ExperienceReplay(HER)[14] 及其扩展方法 [41, 42, 43],通过用已达到的状态替换原始目标来重标记状态转移,然后使用强化学习或模仿学习来优化策略
尽管这些方法减少了对显式奖励的需求,但它们仍然依赖于复杂的奖励重标记过程或外部奖励信号 - Act2Goal 在实现完全自主的在线改进方面更进了一步。通过将 HER 风格的重标注与高效的基于LoRA 的微调相结合,它能够直接基于自主收集的执行轨迹进行策略适应,而无需任何任务奖励或人工标注
由此得到一种轻量级、完全自监督的更新机制,适用于现实世界的部署
1.2 从世界模型到通用目标条件策略
Act2Goal框架旨在解决长时域目标条件操作中的两个关键挑战:
- 使动作策略与高层目标语义对齐
如图 2 所示
作者通过引入目标条件世界模型(GCWM)来应对第一个挑战,该模型以想象的视觉未来来引导策略,从而提供丰富且时间上连贯的表征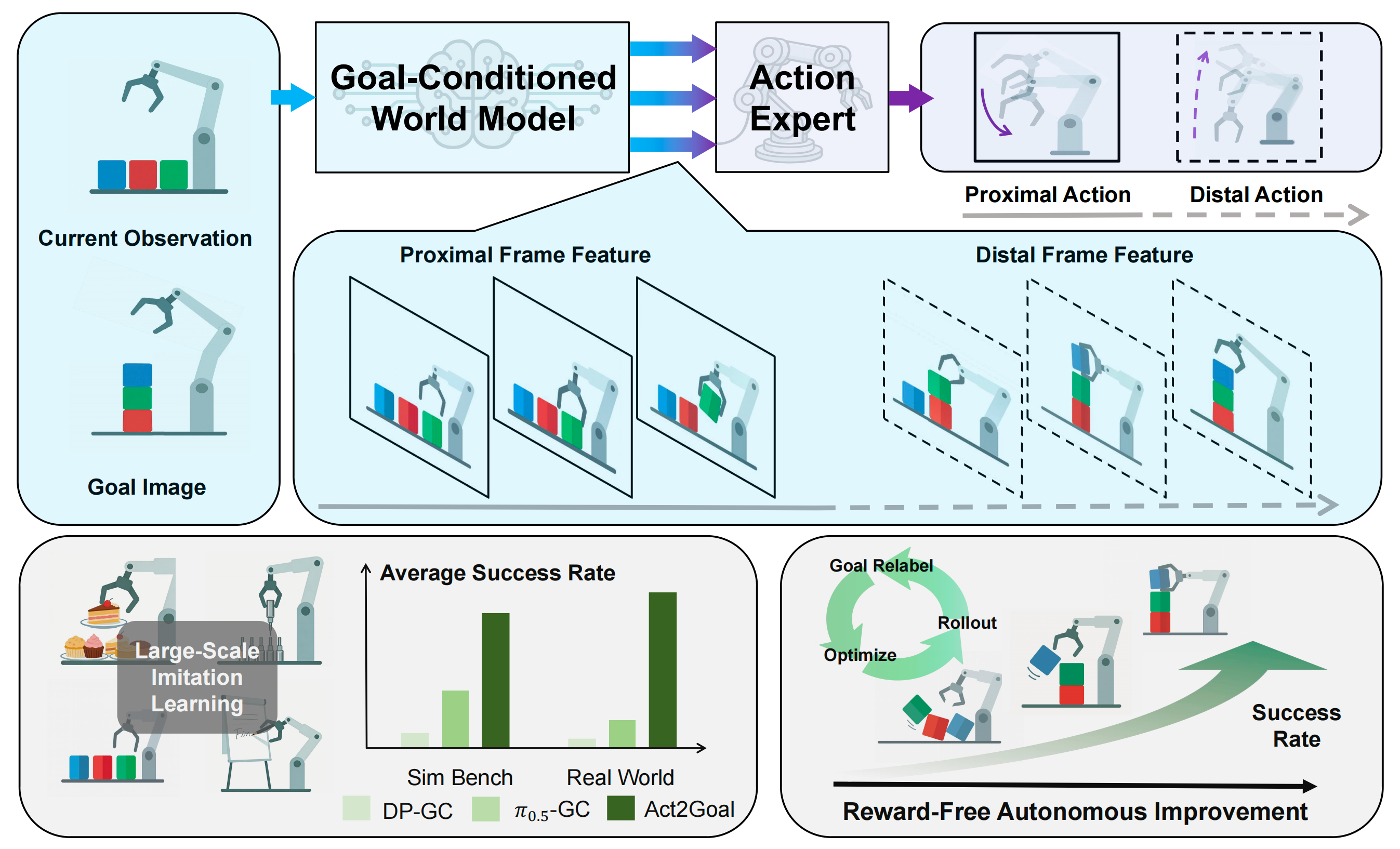
- 在较长时间尺度上保持规划效率
为应对第二个挑战,作者提出了多尺度时间哈希(MSTH),通过结构化的时间抽象,使策略既能关注短期执行,又能兼顾长期目标感知
Act2Goal的学习过程由三个阶段组成
- 对GCWM 和动作专家进行联合训练,以对齐它们的表示
- 侧重于动作适配,进一步提升策略的性能
- 引入可选的自主改进机制,使模型在部署过程中能够在新颖场景下自我适应
1.2.1 目标条件化世界模型引导的策略
如图3 所示,作者的目标条件世界模型建立在Genie En-visioner 架构之上,并进行了关键修改以适应目标条件策略学习[13]
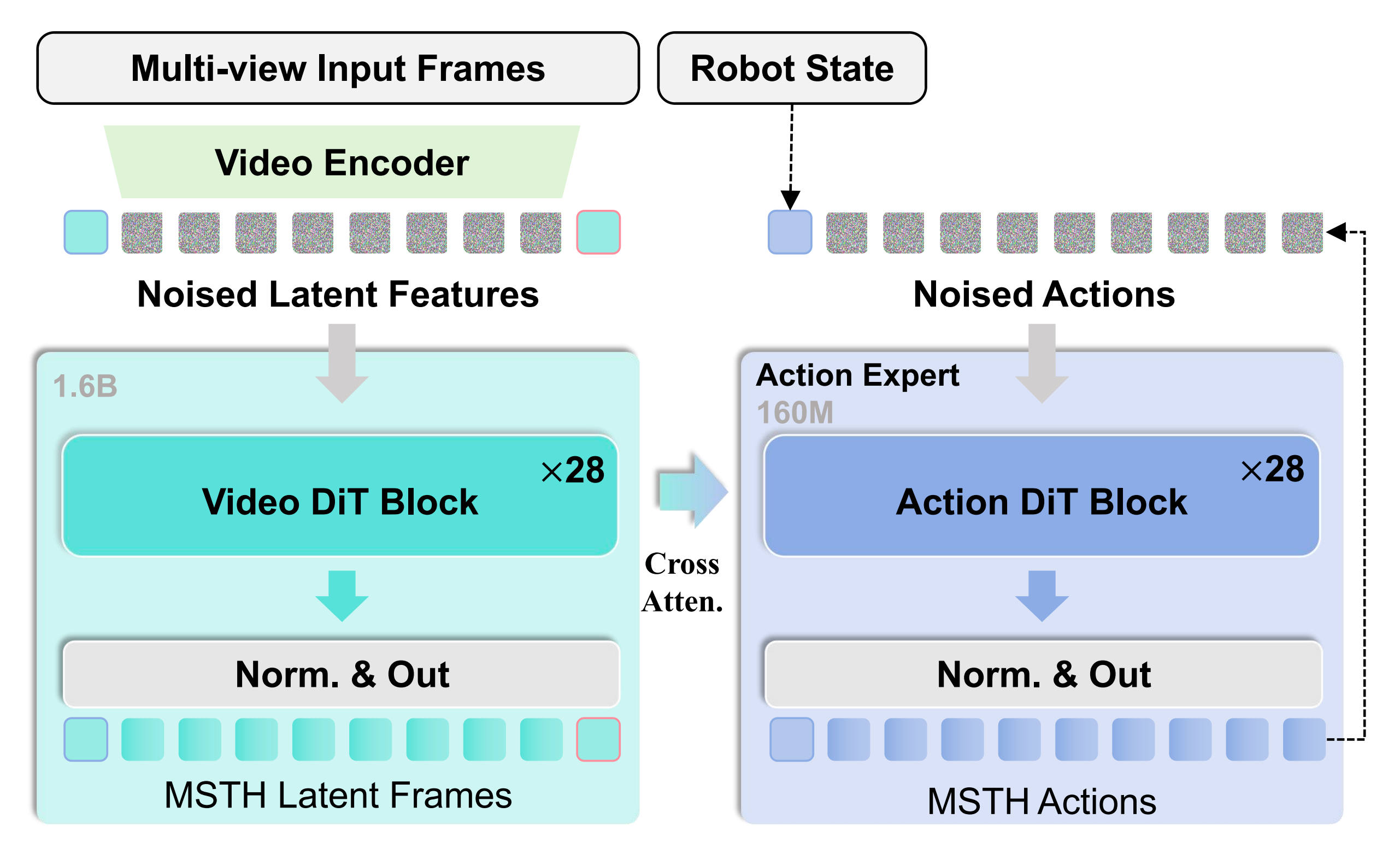
下图展示了 Act2Goal 模型的网络架构
- 左侧,多视角输入帧(包含当前观测和目标)通过视频编码器被编码为潜在表示,并与带噪潜在表示拼接,随后经过 Video DiT 模块精炼为MSTH 潜在帧
On the left, multi-view inputframes, including current observation and goal, are encoded into latents via a video encoder and concatenated with noisylatents, then refined into MSTH latent frames through VideoDiT blocks- 右侧,机器人状态和来自世界模型的多尺度特征通过交叉注意力输入到同构的 ActionDiT 模块中,从而生成具有 MSTH 结构的动作
On the right, the robot state and multi-scalefeatures from the world model are fed via cross-attention intoisomorphic Action DiT blocks, generating MSTH-structuredactions
- 作者引入了一个目标视觉条件,将其与当前观测在隐藏状态序列的维度上进行拼接,同时移除所有语言条件组件,从而构建一个纯视觉的模型
- 该目标条件化世界模型在生成建模中采用连续流匹配方法。该过程可以抽象为:在当前观测和目标状态共同作为条件的情况下——相当于current observetion和goal image
从随机噪声学习到结构化视觉序列的变换
其中,和
分别是当前观测和目标的VAE 压缩潜变量,
表示随机噪声输入,其形状与
相同,而
是流匹配模型,用于在当前观测与目标之间生成潜在帧
- 在推理阶段,模型通过一个确定性的流动过程逐步对含噪潜变量进行细化:
其中是学习到的向量场,引导在多个步骤
上的去噪过程,完成的潜在帧可以使用VAE 解码器:解码为视觉状态
遵循 GE-Act(Genie envisioner)的实现,动作专家采用与世界模型同构的网络架构,具有相同数量的 DiT 模块,但网络宽度有所缩减 [13]
动作轨迹则是使用同时以本体感觉状态
和来自世界模型的多尺度特征
为条件的流匹配过程进行预测
由此可以将动作预测过程形式化为
其中,是动作流匹配模型,ζ 是用于动作生成的噪声输入,
表示分层的转移特征,
- 推理过程中针对动作的流匹配过程遵循迭代细化:
其中是用于动作生成的已学习向量场
1.2.2 用于视觉状态和动作的多尺度时间哈希
// 待更

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 9
9 0
0- 0



 已为社区贡献60条内容
已为社区贡献60条内容

所有评论(0)