【无标题】
论文时间:2025论文链接:https://arxiv.org/abs/2505.08243机器人思维链推理(CoT)—— 即模型在选择动作前预测有用的中间表征 —— 为提升机器人策略(尤其是视觉 - 语言 - 动作模型,VLAs)的泛化能力与性能提供了有效方法。尽管此类方法已被证明能提升性能与泛化能力,但它们存在核心局限性:需专用机器人推理数据,且推理速度较慢。为设计可解决这些问题的新型机器人推
Training strategies for efficient embodied reasoning
论文时间:2025
论文链接:https://arxiv.org/abs/2505.08243
机器人思维链推理(CoT)—— 即模型在选择动作前预测有用的中间表征 —— 为提升机器人策略(尤其是视觉 - 语言 - 动作模型,VLAs)的泛化能力与性能提供了有效方法。尽管此类方法已被证明能提升性能与泛化能力,但它们存在核心局限性:需专用机器人推理数据,且推理速度较慢。为设计可解决这些问题的新型机器人推理方法,全面阐明推理为何能提升策略性能至关重要。本文提出机器人推理提升策略性能的三种潜在机制:(1)更优的表征学习;(2)更完善的学习课程化;(3)更强的表达能力。随后,我们设计了机器人 CoT 推理的简化变体,以分离并验证每种机制的作用。研究发现,学习生成推理内容确实能优化 VLA 的表征,而关注推理过程则有助于实际利用这些特征来改进动作预测。基于对 CoT 推理为何助力 VLA 的深入理解,我们提出两种简单、轻量级的机器人推理替代方案。所提方法相较于非推理策略实现了显著性能提升,在 LIBERO-90 基准测试中取得最先进结果,且推理速度较标准机器人推理提升 3 倍。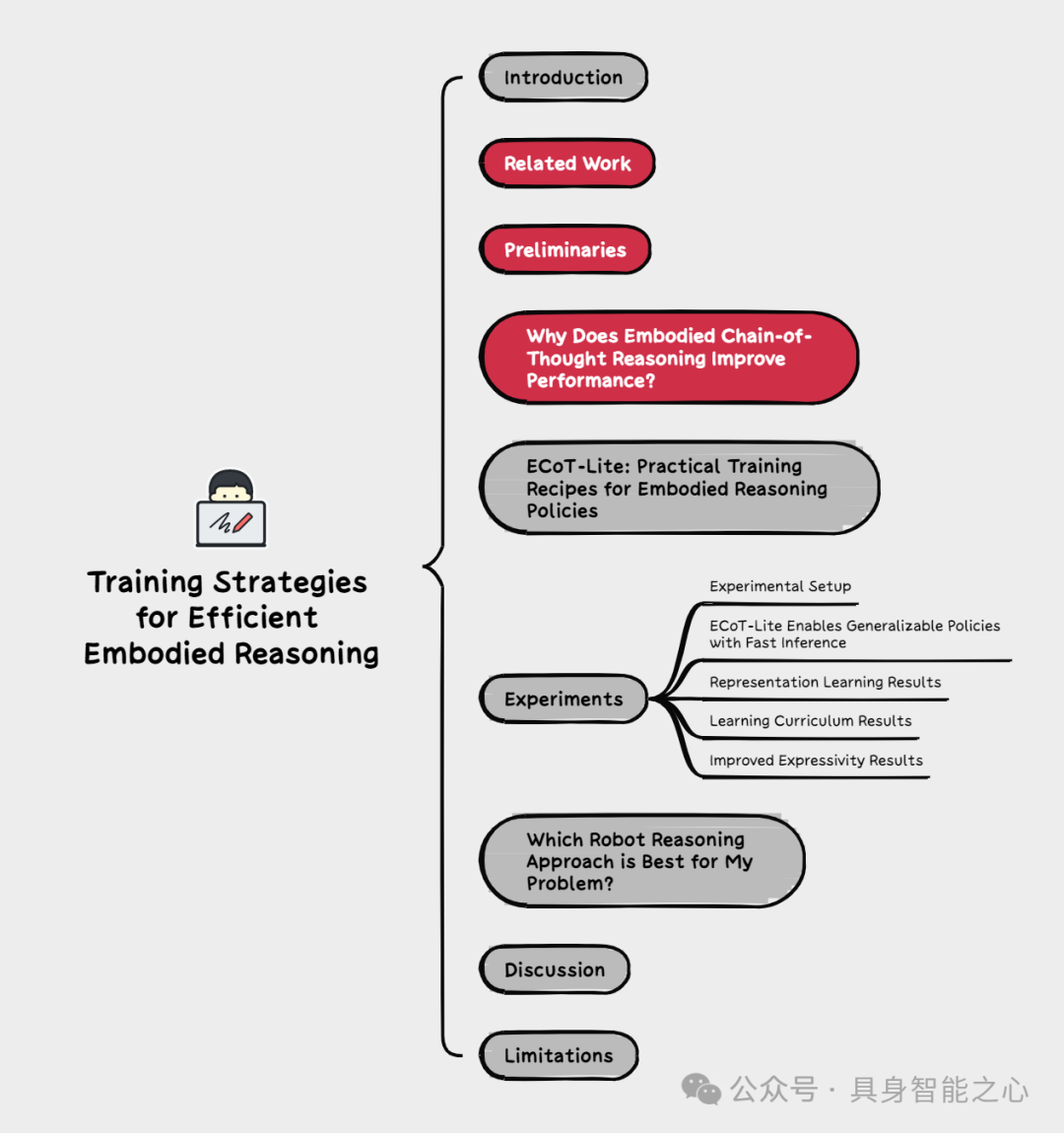
CAST: Counterfactual labels improve instruction following in vision-language-action models
论文时间:2025
论文链接:https://arxiv.org/abs/2508.13446
通用机器人应具备理解并跟随用户指令的能力,但当前的视觉 - 语言 - 动作(vision-language-action, VLA)模型尽管提供了将开放词汇自然语言指令映射到机器人动作的强大架构,却难以跟随细粒度指令。造成这一问题的原因之一是现有机器人数据集缺乏语义多样性和语言接地性,具体而言,对于相似观测结果,其细粒度任务多样性不足。为解决此问题,我们提出一种新方法:利用视觉语言模型(vision language models, VLMs)生成反事实标签,以此扩充现有机器人数据集。该方法通过生成反事实语言与动作,增加机器人数据集语言接地的多样性和粒度,进而提升 VLA 模型的指令跟随能力。我们在 3 个不同的室内外环境中开展视觉语言导航实验,评估所提模型对各类语言指令(从简单的物体中心指令到复杂的指称任务)的跟随能力。实验结果表明,在无需额外采集数据的情况下,反事实重标记显著提升了 VLA 策略的指令跟随性能,使其可与最先进方法媲美,且导航任务的成功率提升了 27%。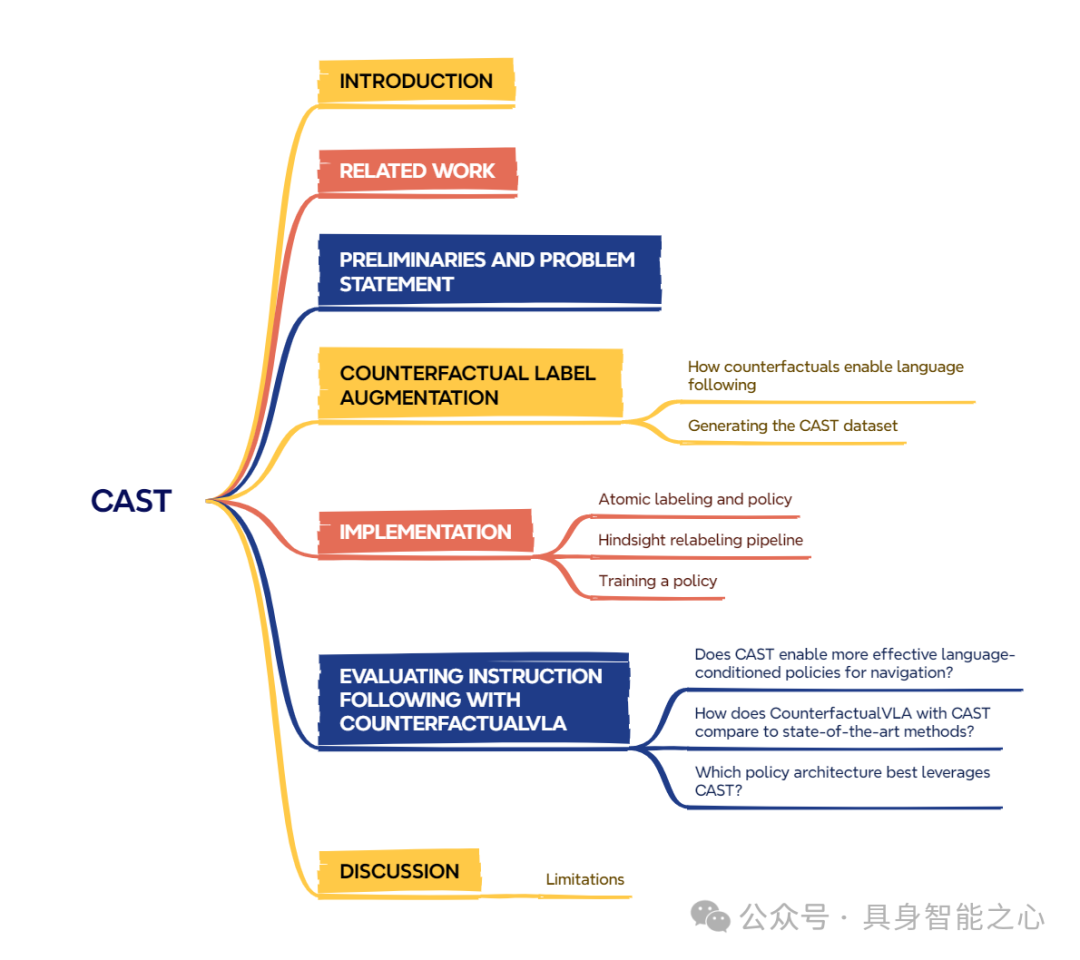
RoboBrain: A unified brain model for robotic manipulation from abstract to concrete
论文时间:2025
论文链接:https://arxiv.org/abs/2502.21257
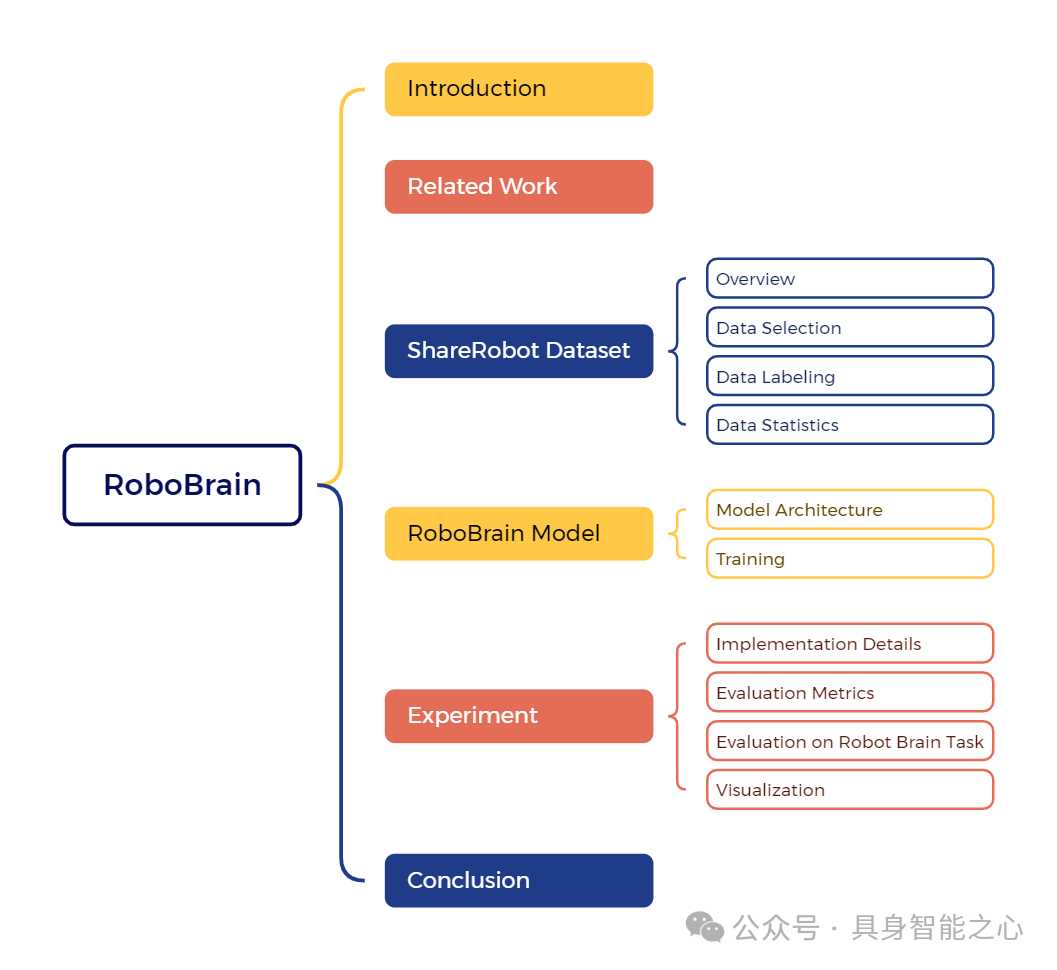
近年来,多模态大语言模型在多模态上下文处理中展现出卓越的能力。然而,它们在机器人场景中的应用,特别是对于长周期操作任务,显示出显著的局限性。这些局限性源于当前MLLMs缺乏三个关键的机器人脑能力:规划能力,即将复杂的操作指令分解为可管理的子任务;可供性感知,即识别和解释交互对象可供性的能力;以及轨迹预测,即预见到成功执行所需的完整操作轨迹的前瞻能力。为了从抽象到具体地增强机器人脑的核心能力,我们引入了ShareRobot,一个高质量异构数据集,它标注了任务规划、对象可供性和末端执行器轨迹等多维度信息。ShareRobot的多样性和准确性已由三位人工标注者精心完善。基于此数据集,我们开发了RoboBrain,一个基于MLLM的模型,它结合了机器人和通用多模态数据,采用了多阶段训练策略,并融入了长视频和高分辨率图像以提升其机器人操作能力。广泛的实验表明,RoboBrain在各种机器人任务中实现了最先进的性能,突显了其提升机器人脑能力的潜力。
DROID: A large-scale in-the-wild robot manipulation dataset
论文时间:2025
论文链接:https://arxiv.org/abs/2403.12945
构建大规模、多样化、高质量的机器人操作数据集,是研发更具能力与鲁棒性的机器人操作策略过程中的重要垫脚石。然而,此类数据集的构建面临诸多挑战:在多样化环境中采集机器人操作数据不仅存在后勤与安全难题,还需要在硬件和人力方面进行大量投入。因此,即便如今最具通用性的机器人操作策略,其训练数据也大多来源于少数几个环境,场景与任务的多样性十分有限。
在本研究中,我们提出了 DROID(分布式机器人交互数据集,Distributed Robot Interaction Dataset)—— 一个多样化的机器人操作数据集。该数据集包含 7.6 万条演示轨迹(对应 350 小时的交互数据),由 50 名数据采集者在 12 个月内,于北美、亚洲和欧洲的 564 个场景中完成 86 项任务后采集得到。实验表明,利用 DROID 训练的策略在性能和泛化能力上均有提升。我们将完整数据集、策略学习代码以及复现机器人硬件设置的详细指南开源发布。
ViSA-Flow: Accelerating robot skill learning via large-scale video semantic action flow
论文时间:2025
论文链接:https://arxiv.org/abs/2505.01288
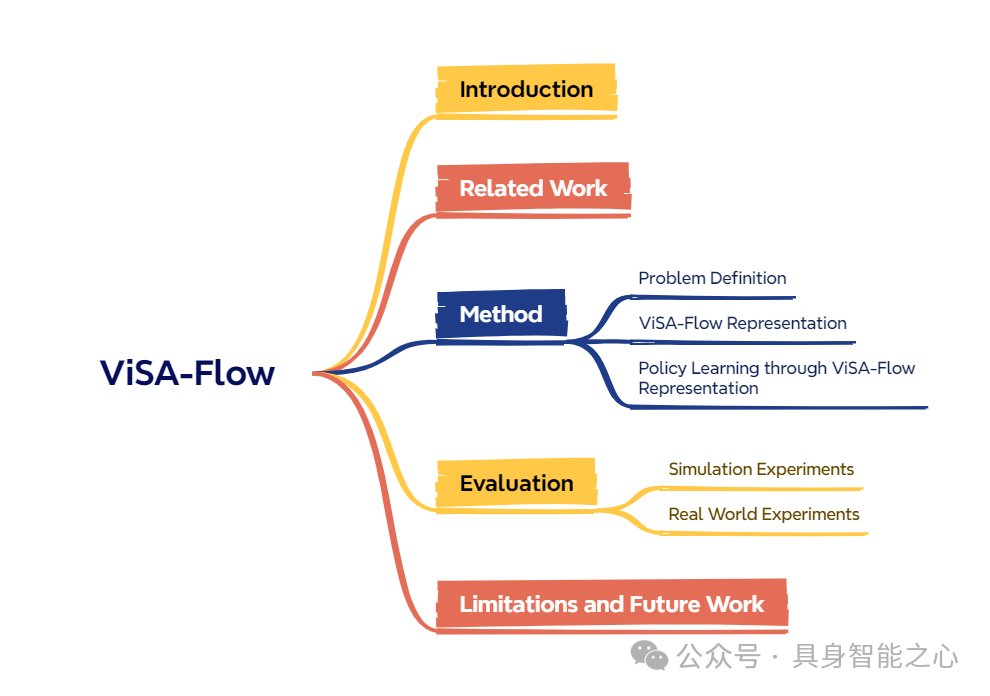
阻碍机器人获取复杂操作技能的核心挑战之一在于收集大规模机器人示范数据的高昂成本。相比之下,人类能够通过观察他人与环境互动来高效学习。为弥补这一差距,我们引入了语义动作流 作为一个核心的中间表示,它捕捉了关键的时空操作者-物体交互,且对表面的视觉差异具有不变性。我们提出了 ViSA-Flow,这是一个从无标签的大规模视频数据中自监督学习该表示的框架。首先,一个生成模型在大规模人-物交互视频数据中自动提取的语义动作流上进行预训练,从而学习到关于操作结构的鲁棒先验。其次,通过在一个小规模机器人示范数据集上,使用相同的语义抽象流程进行处理并微调,该先验被高效地适配到目标机器人上。我们在 CALVIN 基准测试和真实世界任务上进行的广泛实验表明,ViSA-Flow 实现了最先进的性能,尤其在低数据情况下,通过有效地将知识从人类视频观察迁移到机器人执行,超越了现有方法。
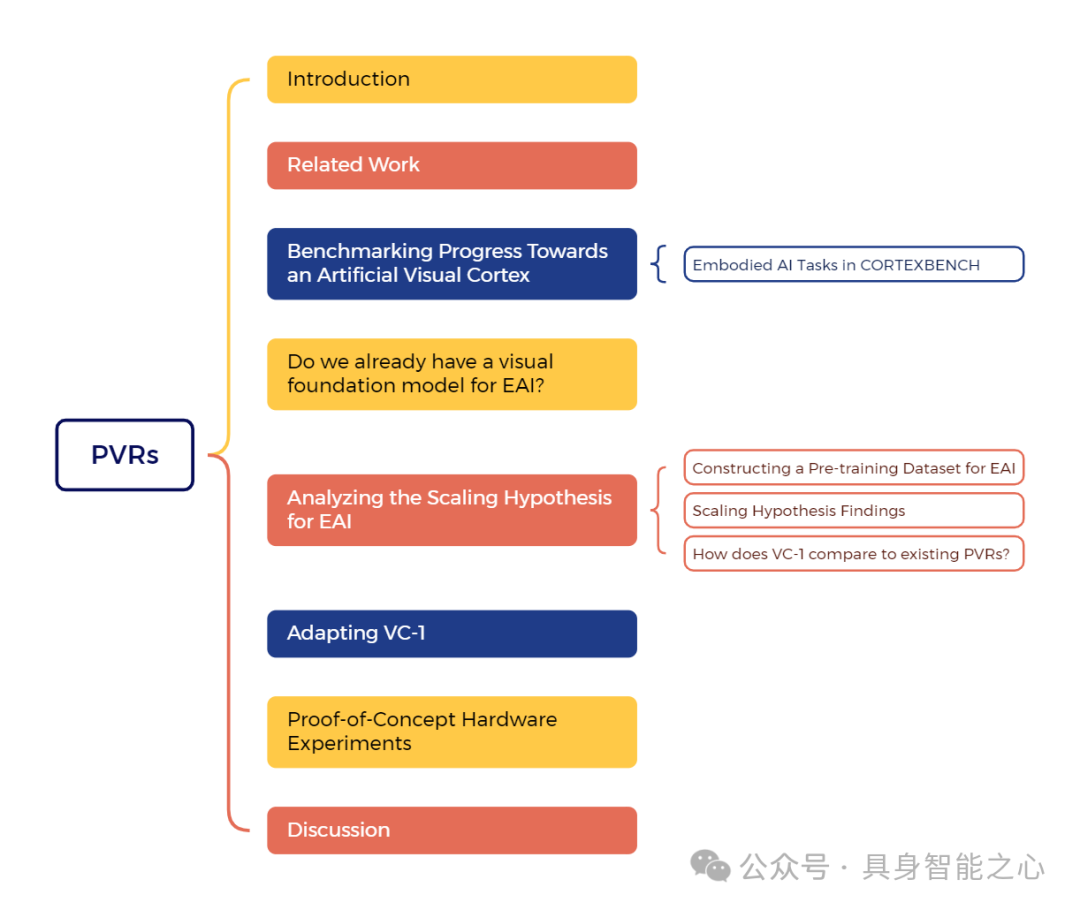
Where are we in the search for an artificial visual cortex for embodied intelligence?
论文时间:2024
论文链接:https://arxiv.org/abs/2303.18240
我们针对具身智能(Embodied AI)的预训练视觉表征(PVRs,即视觉 “基础模型”)开展了规模最大、最全面的实证研究。首先,我们构建了 CORTEXBENCH 基准测试集,该测试集包含 17 项不同任务,涵盖运动控制、导航、灵巧操作和移动操作。其次,我们对现有预训练视觉表征进行了系统性评估,发现没有任何一种预训练视觉表征能在所有任务中普遍占据优势。
为探究预训练数据规模和多样性的影响,我们整合了来自 7 个不同来源、时长超过 4000 小时的第一视角视频(含超 430 万张图像)与 ImageNet 数据集,基于该整合数据的不同子集,采用掩码自编码(MAE)方法训练了不同规模的视觉 Transformer 模型。与先前研究的推断相反,我们发现扩大数据集规模和多样性并不会在所有任务中普遍提升性能(但平均而言会有提升)。我们规模最大的模型 VC-1,平均性能优于所有现有预训练视觉表征,但同样无法在所有任务中普遍占据优势。
随后,我们发现对 VC-1 进行任务或领域特异性适配可带来显著性能提升,适配后的 VC-1(VC-1 adapted)在 CORTEXBENCH 所有基准测试任务上的性能均达到或优于已知的最佳结果。最后,我们开展了真实硬件实验,结果表明 VC-1 及其适配版本的性能优于现有性能最强的预训练视觉表征。总体而言,本文未提出新的技术方法,而是提供了严谨的系统性评估、一系列关于预训练视觉表征的广泛发现(部分发现反驳了先前在特定窄领域的结论),并开源了相关代码与模型(训练耗时超过 10000 GPU 小时),以供研究使用。
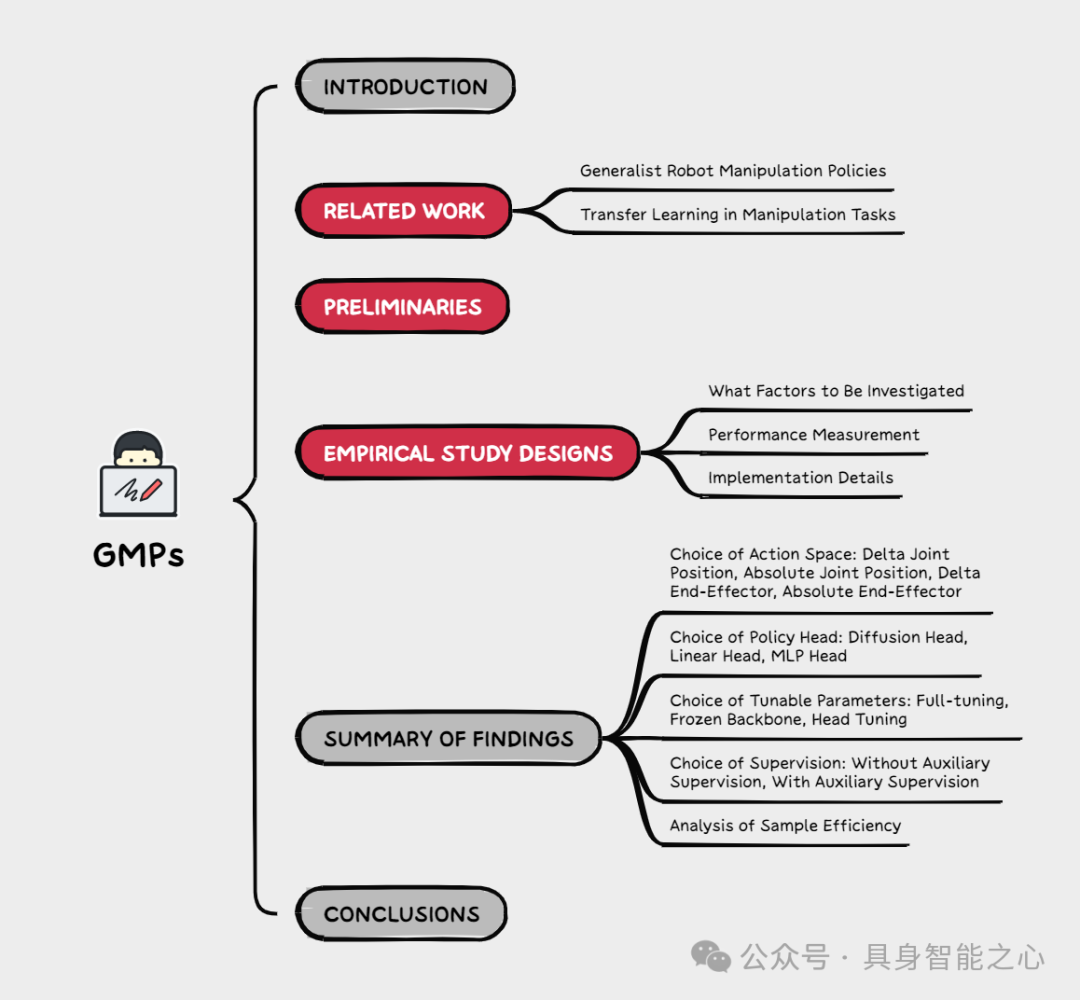
Effective tuning strategies for generalist robot manipulation policies
论文时间:2024
论文链接:https://arxiv.org/abs/2410.01220
通用机器人操作策略(GMPs)具有在广泛任务、设备和环境中泛化的潜力。然而,由于收集足够覆盖广泛多样领域的动作数据存在固有困难,现有策略在处理分布外场景时仍然面临挑战。虽然微调提供了一种实用的方法,可以利用有限样本快速将 GMPs 适配到新领域和任务,但我们观察到,由此产生的 GMPs 的性能因微调策略的设计选择而有显著差异。在这项工作中,我们首先进行了一项深入的实证研究,以调查 GMPs 微调策略中关键因素的影响,涵盖动作空间、策略头、监督信号以及可调参数的选择,其中每个单一配置评估了 2,500 次 rollout。我们系统地讨论和总结了我们的发现,并确定了关键的设计选择,我们相信这为 GMPs 的微调提供了实用指南。我们观察到,在低数据情况下,通过精心选择的微调策略,GMPs 显著优于最先进的模仿学习算法。本工作中呈现的结果为未来关于微调 GMPs 的研究建立了一个新的基准,并为社区的 GMPs 工具箱增添了重要内容。
CACTI: A framework for scalable multi-task multi-scene visual imitation learning
论文时间:2023
论文链接:https://arxiv.org/abs/2212.05711
大规模训练已推动人工智能多个子领域(如计算机视觉和自然语言处理)取得显著进展。然而,构建具有相当规模的机器人学习系统仍面临挑战。要开发出能够掌握多种技能并适应新场景的机器人,不仅需要高效的方法来收集物理机器人系统上大量且多样的数据,还需要具备利用此类数据集训练高容量策略的能力。在本研究中,我们提出了一个用于扩展机器人学习的框架,重点关注仿真环境和真实世界中厨房场景下的多任务多场景操作任务。
我们提出的框架 CACTI 包含四个阶段,分别处理:数据收集、数据增强、视觉表征学习和模仿策略训练,以实现机器人学习的可扩展性。在数据增强阶段,我们采用最先进的生成模型;同时,利用预训练的域外观视觉表征来提高训练效率。实验结果证明了该方法的有效性:在真实机器人设置中,CACTI 能够高效训练出单一策略,该策略可完成 10 项涉及厨房物体的操作任务,且对干扰物的不同布局具有鲁棒性;在仿真厨房环境中,CACTI 训练出的单一策略可在每项任务的 100 种布局变化下完成 18 项语义任务。我们将发布仿真任务基准以及真实和仿真环境下的增强数据集,以促进未来的相关研究。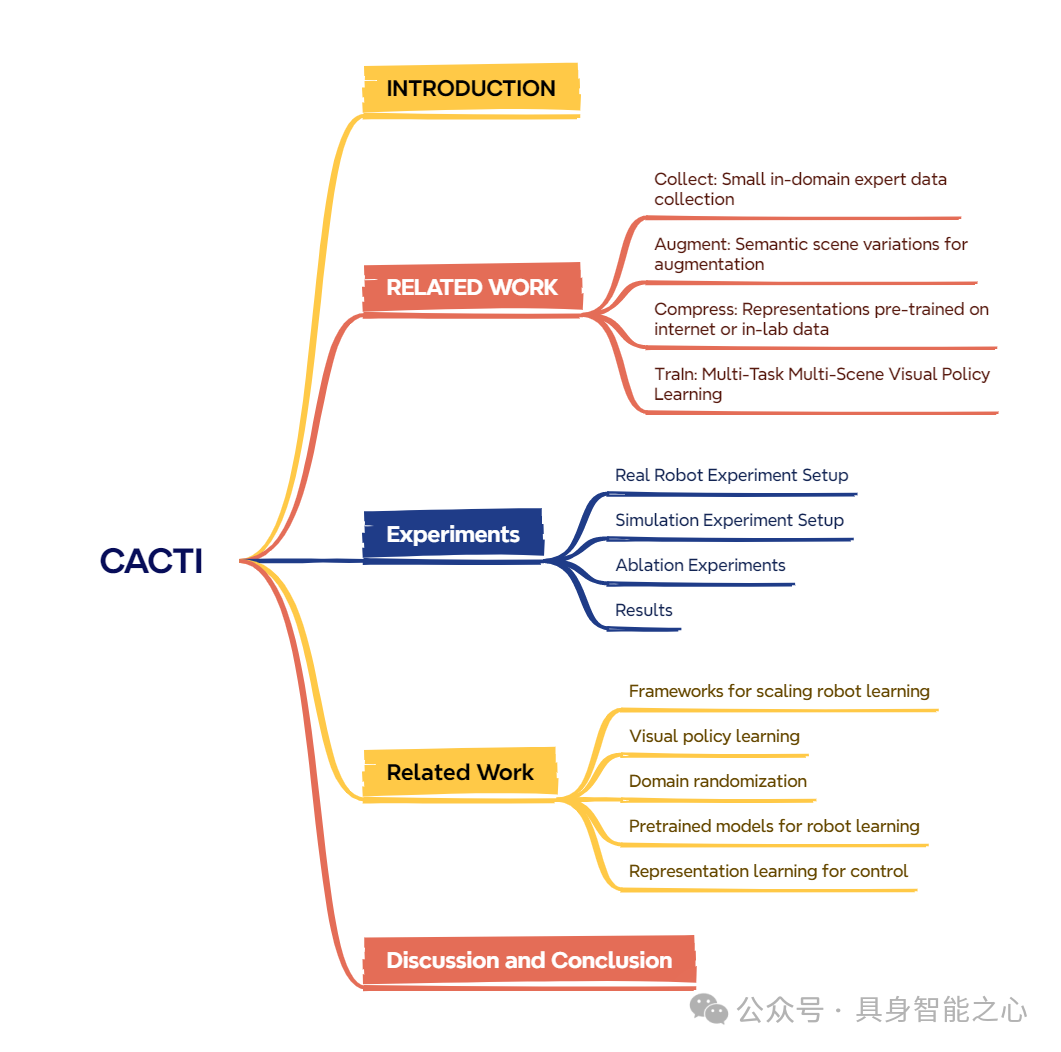
R3m: A universal visual representation for robot manipulation
论文时间:2022
论文链接:https://arxiv.org/abs/2203.12601
我们研究了在多样化人类视频数据上预训练的视觉表示如何能够实现下游机器人操作任务的数据高效学习。具体而言,我们使用 Ego4D 人类视频数据集,结合时间对比学习、视频-语言对齐以及鼓励稀疏紧凑表示的 L1 惩罚项,预训练了一个视觉表示。由此产生的表示 R3M,可以作为下游策略学习的冻结感知模块。在一套包含 12 个模拟机器人操作任务的测试中,我们发现与从头开始训练相比,R3M 将任务成功率提高了超过 20%;与 CLIP 和 MoCo 等最先进的视觉表示相比,提高了超过 10%。此外,R3M 使 Franka Emika Panda 机械臂能够在仅给出 20 次演示的情况下,在真实、杂乱的公寓环境中学习一系列操作任务。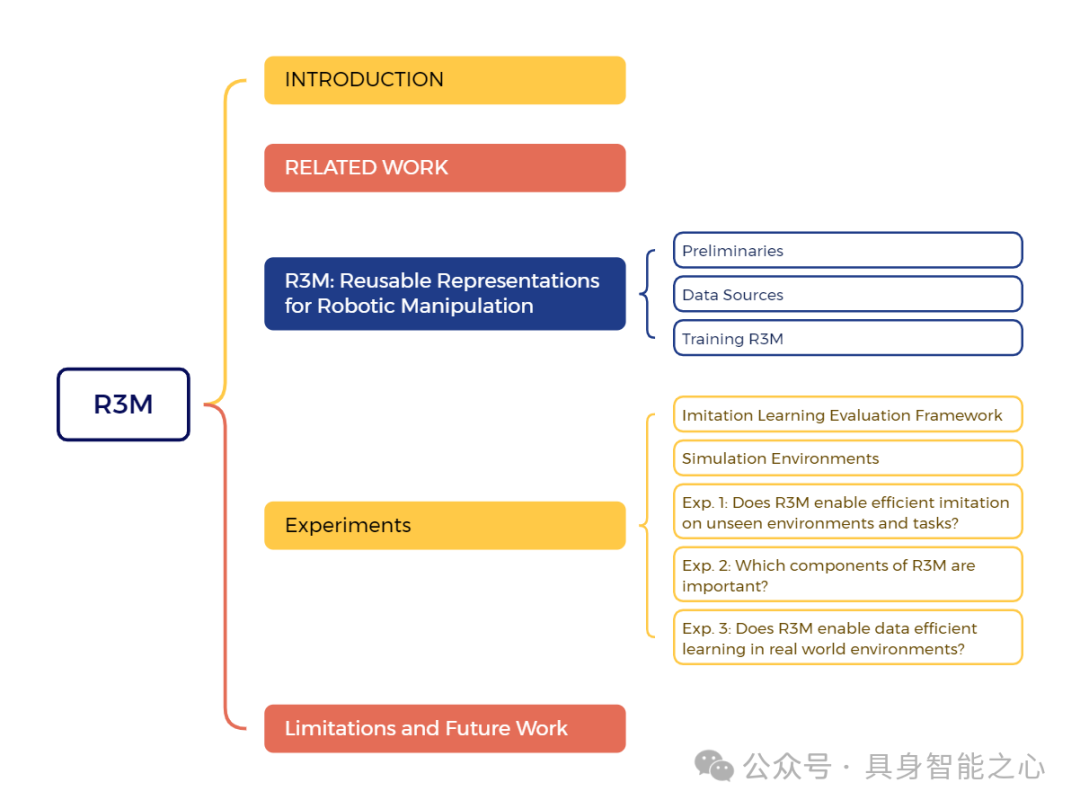
具身求职内推来啦
国内最大的具身智能全栈学习社区来啦!
推荐阅读
从零部署π0,π0.5!好用,高性价比!面向具身科研领域打造的轻量级机械臂
工业级真机教程+VLA算法实战(pi0/pi0.5/GR00T/世界模型等)
具身智能算法与落地平台来啦!国内首个面向科研及工业的全栈具身智能机械臂
VLA/VLA+触觉/VLA+RL/具身世界模型等!具身大脑+小脑算法与实战全栈路线来啦~
MuJoCo具身智能实战:从零基础到强化学习与Sim2Real
Diffusion Policy在具身智能领域是怎么应用的?为什么如此重要?
1v1 科研论文辅导来啦!

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 4
4 0
0- 0



 已为社区贡献64条内容
已为社区贡献64条内容

所有评论(0)