清华团队提出AirScape:动作意图可控的低空世界模型,全面开源!
清华大学团队提出AirScape,一种面向六自由度(6DoF)空中智能体的生成式世界模型,能够基于当前视觉观测和动作意图预测未来观测序列。针对低空场景缺乏数据集、视频基础模型与世界模型分布差异等挑战,团队构建了包含11k视频-动作对的数据集,并提出两阶段训练方案:先学习意图可控性,再通过self-play机制强化时空约束。实验显示,AirScape在动作对齐率(IAR)上提升超50%,生成质量指标
- Paper Name: AirScape: An Aerial Generative World Model with Motion Controllability
- Arxiv: https://arxiv.org/pdf/2507.08885
- Project: https://embodiedcity.github.io/AirScape/
- Dataset: https://huggingface.co/datasets/EmbodiedCity/AirScape-Dataset
- Code: https://github.com/EmbodiedCity/AirScape.code
人类空间感的重要组成部分之一,是对自身移动会产生的视觉观测变化的预期。这对于空间移动下的任务/动作决策至关重要。
因此,推演和想象是具身智能领域的基础问题之一,表现为预测:如果本体执行移动意图,那么具身观测将会如何变化。
现有世界模型的研究主要聚焦于人形机器人和自动驾驶应用,它们大多在二维平面上操作,动作空间有限。
具体而言,关键挑战包括:
-
缺乏低空数据集:
- 训练世界模型需要第一人称视角的低空飞行视频,以及对应空中智能体动作意图。现有的数据集要么是第三人称视角,要么是从机器人或地面车辆采集的视角。
-
视频基础模型与世界模型的分布差异:
- 条件输入方面:现有基础模型侧重于根据详尽的文本描述实现可视化视频,而世界模型则依赖简洁的指令或动作意图预测未来观测的变化。
- 生成内容方面:现有基础模型的训练数据大多由视觉变化有限的第三人称视频组成,而具身智能的第一人称视角通常视野更窄,视觉变化更大,增加了训练难度。
-
生成的多样性与复杂性:
- 无人机以六自由度运行,具有高度的灵活性。与地面智能体相比,生成的场景必须包含侧向平移、原地旋转、云台调整以及多种动作的组合,这使得生成任务更具挑战性。低空空间世界模型需要模拟更复杂的相对位置变化、视角差异和视差效应。
为此,清华大学团队提出 AirScape,专为六自由度(6DoF)空中具身智能体设计的生成式世界模型。
AirScape 能基于当前的低空视觉观测和动作意图,推演未来的序列观测。 项目的数据集和代码已全面开源。
低空世界模型数据集
为支撑低空世界模型的训练和测试,提出了包含 11k 个视频片段及其对应的文本动作意图配对的数据集。 该数据集:
- 空间多样,涵盖工业区、住宅区、海边等场景。动作类型多样,包括平移、旋转和复合动作。光照条件多样,包括晴天、多云、夜晚等。任务取材多样,涵盖视觉语言导航、跟踪等。
- 通过多模态大模型初步生成意图,并经过超过 1,000 小时的人工校正,以确保意图描述的准确性和逻辑性。
数据集示例1.mp4
数据集示例2.mp4
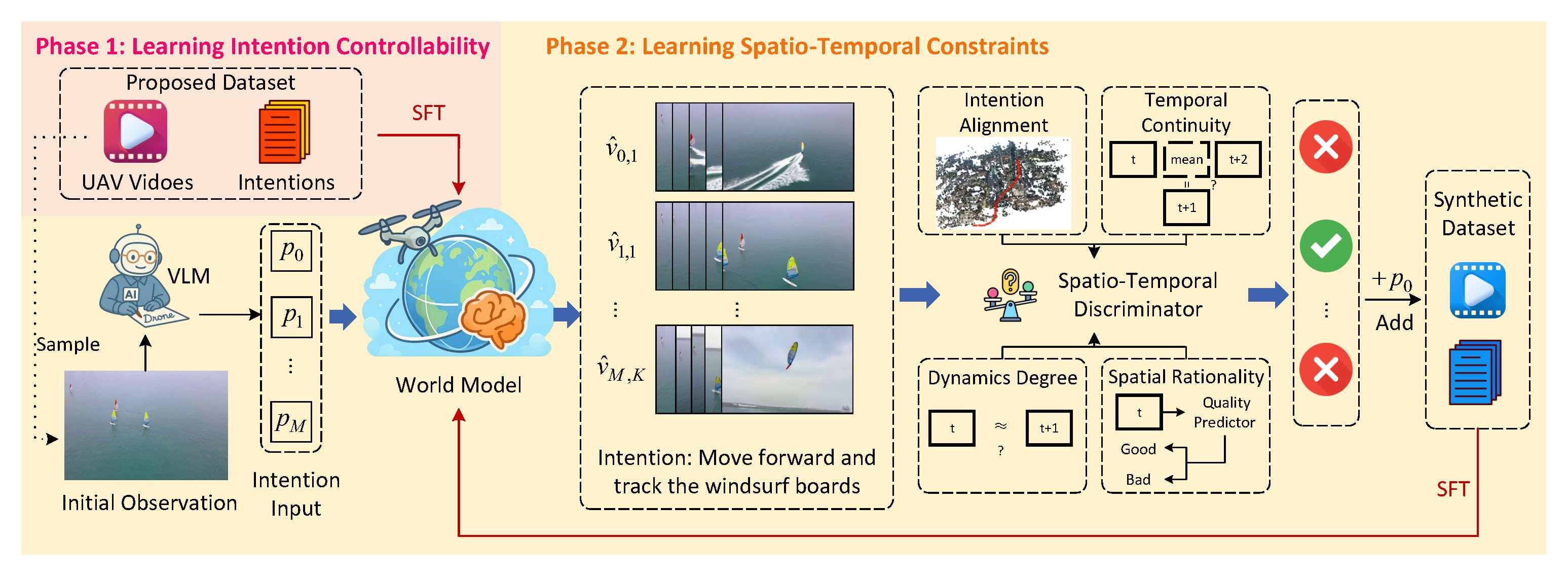
方法:两阶段训练实现可控与约束
为将缺乏具身空间知识的预训练视频生成基础模型转化为可控、并遵循物理时空约束的世界模型,AirScape 提出了一个两阶段训练方案:
-
阶段一:学习意图可控性:
- 利用提出的 11k 视频-意图对数据集,对视频生成基础模型进行监督微调。这一阶段使模型获得对低空动作意图的基本理解和生成能力。
-
阶段二:学习时空约束 (Phase 2: Learning Spatio-Temporal Constraints):
- 引入self-play training机制。
- 利用阶段一训练完的模型生成合成数据,并设计一个时空判别器对生成的视频进行拒绝采样(Rejection Sampling)。
- 该判别器评估四个关键特征:意图对齐(Intention Alignment)、时间连续性(Temporal Continuity)、动态程度(Dynamic Degree)和空间合理性(Spatial Rationality)。我们标注了一个人类偏好的数据集,基于该数据集对判别器进行训练。
- 通过迭代 SFT 训练高质量的合成数据,确保生成的视频遵循物理时空约束,抑制不合理的生成结果。
实验结果
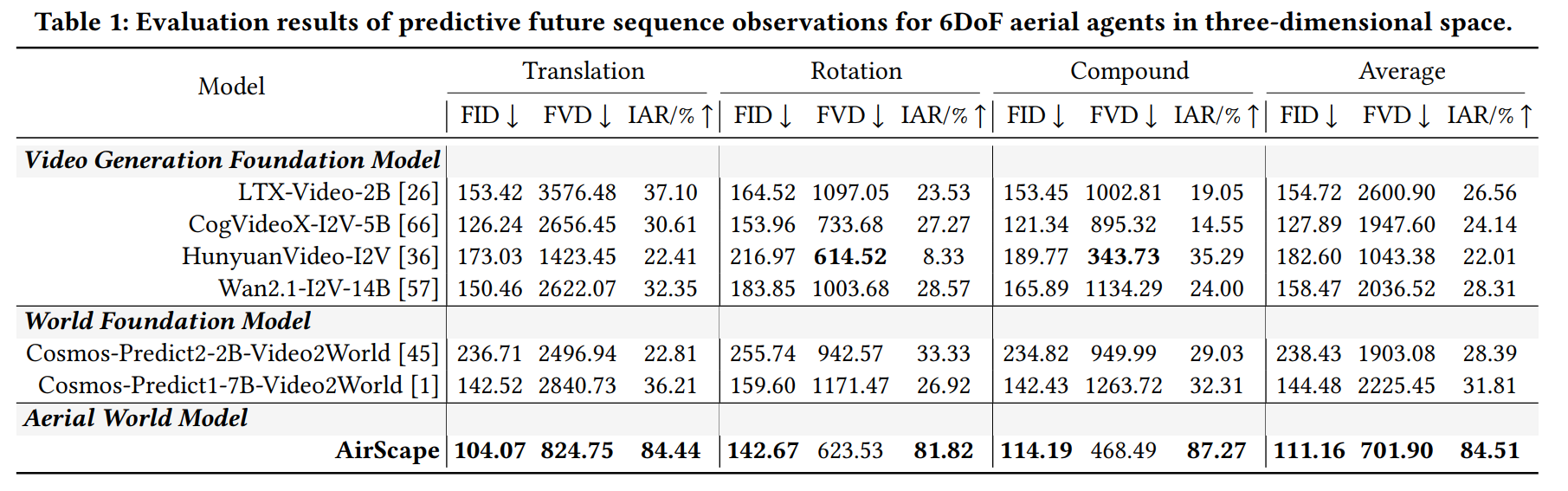
量化结果表明,AirScape 已初步具备三维空间想象能力,填补了现有的视频生成基础模型和世界基础模型在高动作自由度的低空场景上的空白。
- AirScape 在衡量动作对齐能力的关键指标 IAR (Intention Alignment Rate) 上,相对表现最佳的基线模型提升超过 50%。
- 在衡量生成视频质量的 FID、FVD 指标上,AirScape 分别取得了 15.47%、32.73% 的提升。
定性结果指出,AirScape 在给定不同的动作意图时可以预测相应的未来观测。同时,对于生成结果动作幅度有限、对象形状扭曲、时间不连续等问题,均实现了不同程度的优化和改善。
实验结果.mp4
更多结果和细节请参考原文。
结论
本文提出了一个能基于动作意图来想象未来连续视觉观察的低空世界模型。我们提出了一个包含 11k 视频-动作对的数据集,以及一个针对基础模型的两阶段训练方案。
实验结果表明,现有模型的低空空间想象能力仍未被充分研究,而我们提出的 AirScape 在所有指标上都取得了显著的改进。
未来,我们的目标是提升:1)实时性能,2)轻量化设计,以及 3)在协助现实世界空中智能体操作决策方面的适用性。
具身求职内推来啦
国内最大的具身智能全栈学习社区来啦!
推荐阅读
从零部署π0,π0.5!好用,高性价比!面向具身科研领域打造的轻量级机械臂
工业级真机教程+VLA算法实战(pi0/pi0.5/GR00T/世界模型等)
具身智能算法与落地平台来啦!国内首个面向科研及工业的全栈具身智能机械臂
VLA/VLA+触觉/VLA+RL/具身世界模型等!具身大脑+小脑算法与实战全栈路线来啦~
MuJoCo具身智能实战:从零基础到强化学习与Sim2Real
Diffusion Policy在具身智能领域是怎么应用的?为什么如此重要?
1v1 科研论文辅导来啦!

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 6
6 0
0- 0



 已为社区贡献62条内容
已为社区贡献62条内容

所有评论(0)