高级 RAG 实战指南:从基础检索到智能推理的跃迁
本文深入探讨了高级RAG(检索增强生成)技术体系,从基础RAG的三大痛点(检索失败、上下文噪声、单跳局限)出发,提出了四大进阶方案:1)查询转换技术(HyDE、查询重写);2)高级检索策略(语句窗口检索、父文档检索等);3)迭代式RAG实现多步推理;4)生成器增强检索(如FLARE方法)。文章还提供了生产级RAG的技术栈推荐和性能优化技巧,并展望了RAG与具身智能融合的未来方向,强调高级RAG能将
高级 RAG 实战指南:从基础检索到智能推理的跃迁
作者:nyzhhd
面向人群:AI 工程师、算法研究员、大模型应用开发者
在大模型时代,RAG(Retrieval-Augmented Generation) 已成为解决幻觉、提升事实准确性、注入私有知识的核心范式。但简单的 “向量检索 + Prompt” 架构在复杂场景中频频失效——检索不到关键信息、上下文噪声干扰、多跳推理失败……
本文将带你深入 高级 RAG 技术体系,从原理到实战,构建一个能思考、会规划、准检索的智能知识引擎。
一、Simple RAG:起点,但不是终点
🏖 基础 RAG 三要素
- Retriever:将用户查询嵌入向量,从数据库中检索 Top-K 相似文档;
- (可选)Reranker:用交叉编码器(如
bge-reranker)对检索结果重排序; - Generator:将查询 + 检索结果拼接成 Prompt,交由 LLM 生成答案。
# LangChain 基础 RAG 示例
from langchain_community.vectorstores import FAISS
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.llms import HuggingFaceHub
embeddings = HuggingFaceEmbeddings(model_name="BAAI/bge-small-en")
vectorstore = FAISS.load_local("my_index", embeddings)
retriever = vectorstore.as_retriever(search_kwargs={"k": 3})
# 检索 + 生成
docs = retriever.invoke("What is RAG?")
prompt = f"Context: {docs}\n\nQuestion: What is RAG?"
response = llm.invoke(prompt)
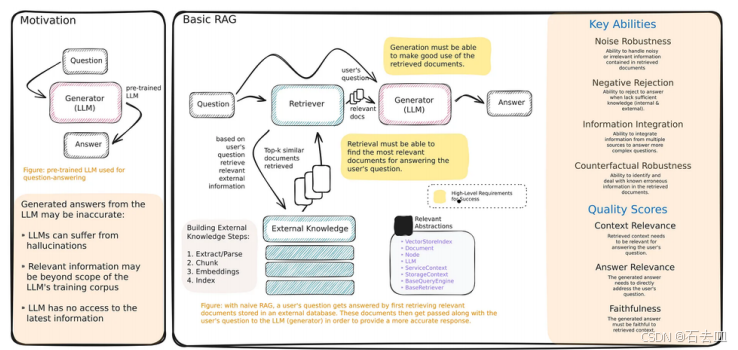
❌ 基础 RAG 的三大痛点
| 问题 | 表现 | 后果 |
|---|---|---|
| 检索失败 | 查询与文档关键词不匹配(如“LLM” vs “大语言模型”) | 返回无关上下文 |
| 上下文噪声 | 检索到长文档,关键信息被淹没 | LLM 被干扰,生成错误 |
| 单跳局限 | 无法处理“多步推理”问题(如“作者的导师是谁?”) | 直接回答“不知道” |
二、高级 RAG:让检索“会思考”
高级 RAG 的核心思想是:检索不是终点,而是推理的起点。我们通过以下技术提升系统能力。
🔧 1. 查询转换(Query Transformation)
思想:用户问得不清楚?我们帮 LLM “翻译”成更易检索的形式。
常用方法:
- HyDE(Hypothetical Document Embeddings):
先让 LLM 生成一个假设答案,再用该答案去检索真实文档。# 伪代码 hyde_doc = llm(f"假设回答:{query}") retrieved_docs = retriever.invoke(hyde_doc) - Query Rewriting:
用小型 LLM(如 Phi-3)重写查询,加入同义词、实体扩展。
💡 适用场景:用户提问模糊、术语不标准(如“AI 写代码的工具” → “GitHub Copilot, CodeWhisperer”)
🔍 2. 高级检索策略
| 技术 | 原理 | 优势 |
|---|---|---|
| 语句窗口检索(Sentence-Window Retrieval) | 不检索整个段落,而是以关键句为中心,取前后 N 句作为上下文 | 保留语义完整性,减少噪声 |
| 父文档检索(Parent Document Retriever) | 将长文档切分为小块(child)用于检索,但返回其所属的父文档(如整篇文章) | 保证上下文连贯性 |
| 融合检索(Fusion Retrieval) | 结合关键词检索(BM25) + 向量检索,加权融合结果 | 兼顾词汇匹配与语义相似 |
| 分层索引(Hierarchical Indexing) | 先检索章节/标题,再在子集中检索细节 | 适合书籍、手册类知识库 |
🚀 工程建议:
在项目中,我用“父文档检索”加载整份设备手册,确保故障代码解释不被截断。
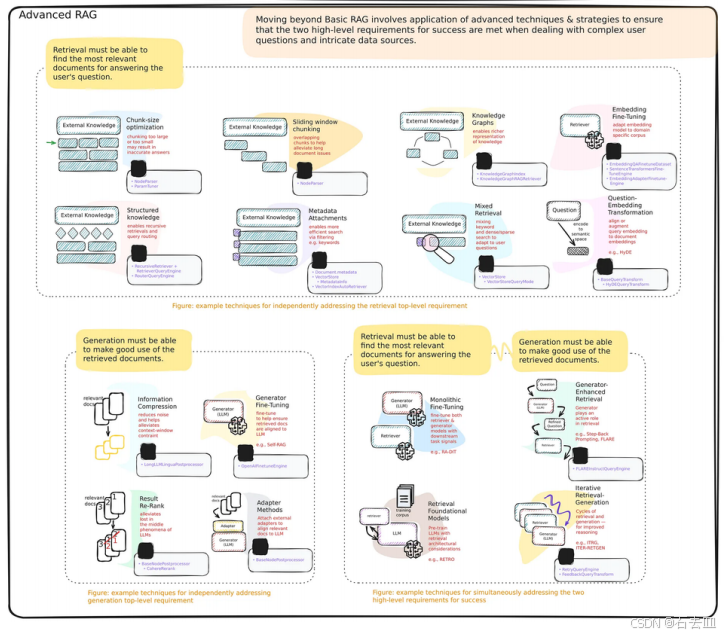
🔁 3. 迭代式 RAG(Iterative RAG)
思想:一次检索不够?那就多次检索 + 规划!
流程:
- LLM 分析查询,判断是否需要多步推理;
- 生成子查询(如“先查作者,再查其导师”);
- 递归检索,直到收集足够信息;
- 综合所有结果生成最终答案。
📌 工具推荐:LlamaIndex 的
MultiStepQueryEngine原生支持此模式。
🧠 4. 生成器增强检索(Generator-Augmented Retrieval)
思想:让 LLM 主动参与检索过程,而非被动接收结果。
典型方法:FLARE
- LLM 在生成过程中,检测到不确定性(如“据我所知……”);
- 自动触发新一轮检索,补充知识;
- 继续生成,直到 confident。
✅ 效果:在开放域问答中,准确率提升 15%+(参考论文:Active Retrieval Augmented Generation)
三、工程落地:构建生产级高级 RAG
🛠 技术栈推荐
| 组件 | 推荐方案 |
|---|---|
| Embedding | BAAI/bge-large-zh(中文),text-embedding-3-large(英文) |
| Reranker | BAAI/bge-reranker-v2-m3,Cohere Rerank |
| Vector DB | Milvus(高并发),FAISS(轻量本地) |
| 框架 | LlamaIndex(灵活性强),LangChain(生态丰富) |
📊 性能优化技巧
- 缓存查询结果:对高频查询(如“公司介绍”)缓存检索结果;
- 异步检索:并行执行 BM25 + 向量检索;
- 上下文压缩:用 LLM 提取检索文档的关键句(
ContextualCompressionRetriever); - 混合 LLM:用小模型(如 Qwen1.5-4B)做检索规划,大模型(如 DeepSeek)做最终生成。
四、未来方向:RAG 与具身智能的融合
作为具身智能(Embodied Intelligence)研究者,我认为 RAG 不仅是“知识增强”,更是“行动增强”:
- 机器人 RAG:将操作手册、故障日志作为知识库,让机械臂“边做边学”;
- 多模态 RAG:结合文本 + 点云 + 图像检索(如“找出红色螺栓的位置”);
- 实时 RAG:接入传感器流数据,动态更新知识库(如高铁轨道状态)。
🌟 结语:
高级 RAG 的本质,是将大模型从“被动回答者”转变为“主动探索者”。
掌握这些技术,你不仅能构建更准的问答系统,更能打造出会规划、能行动、可进化的 AI 智能体。
附:学习资源
- 论文:Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
- 工具库:LlamaIndex、LangChain
- 中文模型:BGE 系列(智源)
- 实战项目:RAG-Fusion(融合检索实现)
作者:nyzhhd|专注生成模型与缺陷检测的硕士生 · 具身智能探索者

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 30
30 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)