微软&港科对比多种迁移技术!VLA 到底如何有效地继承 VLM 中丰富的视觉-语义先验?
微软研究院与
在具身智能领域,基于大型视觉语言模型(VLM)初始化训练视觉语言动作模型(VLA)已成为主流范式。但核心疑问始终未解:VLA 如何有效继承 VLM 中丰富的视觉 - 语义先验?
微软研究院、香港科技大学等团队联合提出的GrinningFace 基准,以表情符号桌面操作任务为切入点,通过模拟与真实机器人双环境实验,系统对比多种迁移技术,不仅揭示了 VLM 先验对 VLA 泛化能力的关键作用,更为高效知识迁移提供了明确指导。
为什么需要专门的 VLA 知识迁移基准?
当前 VLA 训练虽普遍依托 VLM 初始化,但存在三大核心痛点,传统基准难以精准诊断:
| 核心痛点 | 具体表现 |
|---|---|
| 先验迁移效果模糊 | VLM 的视觉 - 语义知识与 VLA 的机器人动作技能交织,无法单独评估迁移成效 |
| 灾难性遗忘风险 | VLA 在机器人数据集上微调时,易丢失 VLM 的通用先验知识 |
| 技术对比缺乏统一标准 | 不同迁移技术(如参数高效微调、共训练)在不同场景下提出,难以系统比较优劣 |
关键问题在于,现有机器人数据集与 VLM 预训练数据的重叠度极低,无法剥离 “机器人动作技能” 与 “VLM 先验知识” 的贡献。
GrinningFace 基准的创新之处在于:选择表情符号作为核心代理——这类符号在 VLM 预训练的互联网规模数据中普遍存在,却几乎未出现在机器人数据集中,从而构建了 “动作技能简单可控、视觉 - 语义识别依赖 VLM 先验” 的纯净测试环境。

GrinningFace:如何精准诊断 VLA 的知识继承能力?
GrinningFace 的核心设计可概括为 “以表情符号为桥梁,分离动作执行与语义识别能力”,通过标准化任务与评估体系,实现对知识迁移效果的精准度量,具体包括两大核心模块:
核心模块 1:表情符号桌面任务设计
任务要求机器人手臂根据语言指令,将立方体放置到对应的表情符号卡片上(三选一),指令格式为 “拿起立方体并放置在 [表情描述] 上”。
- 数据划分:训练集与验证集各包含 100 个不同表情符号,确保评估泛化能力
- 数据采集:通过规则程序生成 500 条微调轨迹,随机化立方体、表情卡和机器人初始位置,避免记忆拟合
- 场景适配:同步实现 ManiSkill3 仿真环境与真实机器人平台(Realman RM75 机械臂),确保结论迁移性
核心模块 2:双维度评估体系
通过拆分成功率,单独量化动作执行与语义识别能力,公式定义为:
overall SR = execution SR × recognition SR \text{overall SR} = \text{execution SR} \times \text{recognition SR} overall SR=execution SR×recognition SR
-
执行成功率(execution SR):机器人成功抓取立方体并放置到任意表情卡的概率,反映动作技能掌握程度
-
识别成功率(recognition SR):机器人选择正确目标表情卡的概率,直接体现 VLM 先验迁移效果
-
评估协议:设计三类测试场景(ID:训练集组合、Train:训练集新组合、Val:验证集表情),全面覆盖分布内与分布外泛化
关键实验发现:哪些技术能实现高效知识迁移?
研究团队在统一 π 0 \pi_0 π0风格代码库中,系统评估了参数高效微调、VLM 冻结、共训练等主流技术,核心结论可概括为 “先验保留是关键,平衡迁移与适配是核心”:
VLM、VLA 预训练与微调的分工明确
- VLM 提供基础视觉 - 语义先验,但对桌面场景识别适配不足
- VLA 预训练负责将 VLM 先验对齐到桌面场景,支撑快速适配
- VLA 微调专注于目标任务的动作技能优化,需避免过度更新导致先验丢失
微调策略的性能对比与取舍
| 微调策略 | 核心优势 | 主要局限 |
|---|---|---|
| 全参数微调 | 适配特定任务效果好 | 易发生灾难性遗忘,丢失 VLM 先验 |
| 仅微调动作头 | 最大程度保留 VLM 先验 | 动作技能学习不足,分布内场景适配差 |
| LoRA 微调 | 平衡先验保留与动作学习 | 知识迁移提升有限,仍有优化空间 |
不同微调策略的性能差异可通过图 2 直观观察:基线模型全参数微调时,执行成功率(实线)居高不下,但验证集识别成功率(虚线)始终偏低;而 VLM 冻结 + LoRA 预训练虽能保持高识别成功率,却需要更多微调步骤才能掌握简单动作技能。
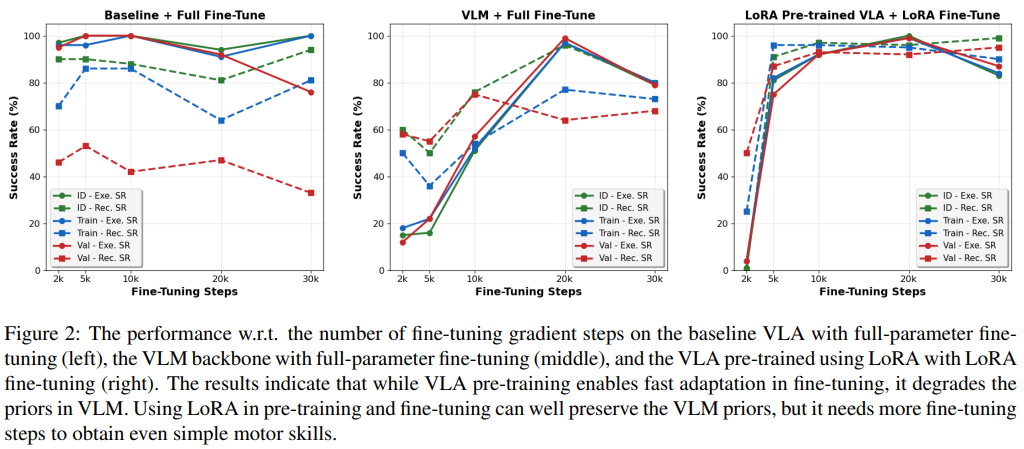
高效迁移的关键技术方向
-
共训练(Co-training):在 VLA 训练中加入视觉语言任务(如表情识别),能有效保留 VLM 先验,真实机器人实验中识别成功率达 86.7%(26/30)
-
潜态动作预测(Latent Action):将潜态动作作为高阶训练目标,避免模型被低阶信号干扰,识别成功率达 80%(24/30)
-
VLM 冻结 + LoRA 预训练:大幅提升识别成功率(超 90%),但复杂动作技能适配速度慢
-
多样化预训练数据:即使部分数据与目标场景差异较大,也能提升泛化能力,验证了数据规模对先验激活的重要性
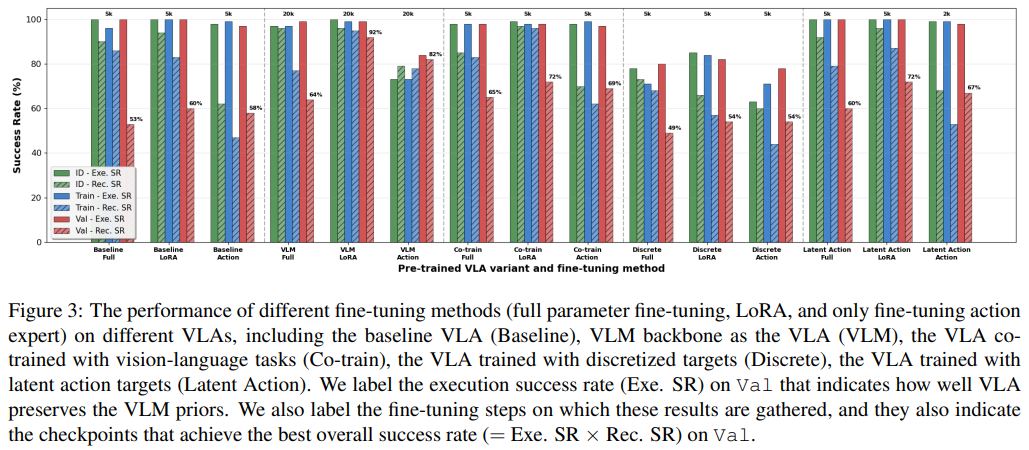
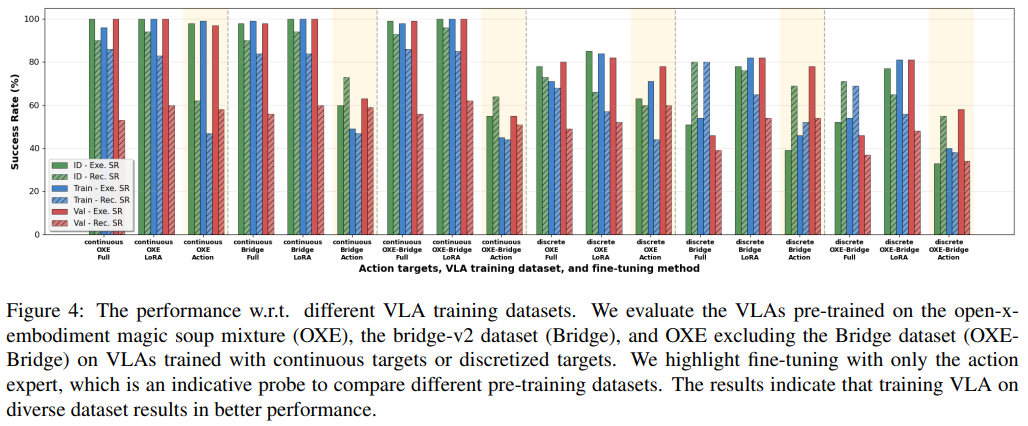
负面技术验证
- 离散动作预测:不仅未提升迁移效果,还因量化误差导致执行与识别成功率双下降
- 单一 VLM 初始化:仅依赖 VLM 权重初始化无法保证有效迁移,必须配合合理的预训练与微调策略
实验验证:仿真与真实机器人的一致性
为确保结论可靠性,研究在 Realman RM75 真实机械臂上复现了核心实验,结果与仿真环境高度一致:
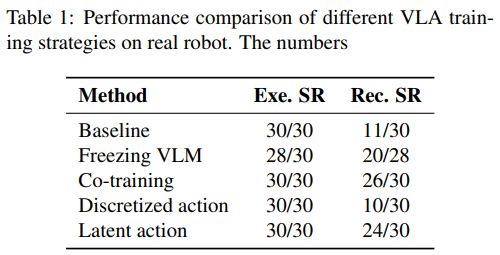
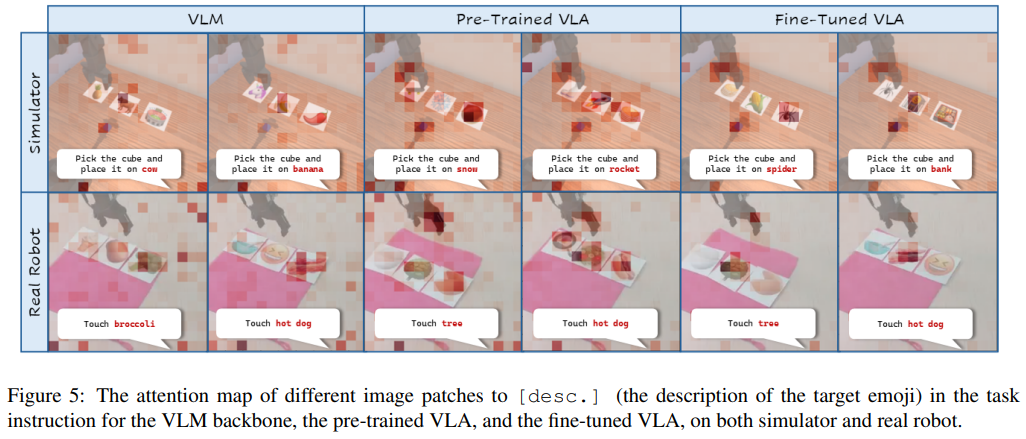
注意力图谱分析进一步揭示:VLM 能初步关注目标表情但不够聚焦,VLA 预训练使其学会关注桌面关键物体(抓手、立方体、表情卡),而优化后的微调策略能让模型精准聚焦正确表情卡,验证了 “VLM 先验→预训练对齐→微调优化” 的递进式迁移路径。
核心结论与未来方向
核心结论
- 表情符号基准能有效分离 VLA 的动作技能与 VLM 先验贡献,为知识迁移提供精准诊断工具
- VLM 先验的保留程度直接决定 VLA 的泛化能力,灾难性遗忘是当前技术的主要瓶颈
- 共训练、潜态动作预测、多样化预训练数据是实现高效迁移的三大关键方向
- 平衡 VLM 先验保留与机器人动作适配,是 VLA 设计的核心原则
未来方向
- 优化参数高效微调技术,提升 LoRA 等方法的知识迁移效率
- 设计更贴合真实场景的复杂任务,验证迁移技术的规模化应用能力
- 探索多模态先验融合,结合触觉、语音等信息增强 VLA 的环境适应能力
总结
GrinningFace 基准的提出,填补了 VLA 知识迁移评估的空白——通过表情符号这一巧妙的 “桥梁”,首次实现了对 VLM 先验迁移效果的定量分离。
其系统实验不仅验证了 VLM 先验对 VLA 泛化的决定性作用,更提供了可落地的技术指南。对于追求通用具身智能的研究而言,这一工作为打破 “局部任务适配与全局先验保留” 的矛盾提供了关键思路,也为后续 VLA 架构设计与训练策略优化奠定了基础。
具身求职内推来啦
国内最大的具身智能全栈学习社区来啦!
推荐阅读
从零部署π0,π0.5!好用,高性价比!面向具身科研领域打造的轻量级机械臂
工业级真机教程+VLA算法实战(pi0/pi0.5/GR00T/世界模型等)
具身智能算法与落地平台来啦!国内首个面向科研及工业的全栈具身智能机械臂
VLA/VLA+触觉/VLA+RL/具身世界模型等!具身大脑+小脑算法与实战全栈路线来啦~
MuJoCo具身智能实战:从零基础到强化学习与Sim2Real
Diffusion Policy在具身智能领域是怎么应用的?为什么如此重要?
1v1 科研论文辅导来啦!

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 10
10 0
0- 0



 已为社区贡献106条内容
已为社区贡献106条内容

所有评论(0)