盘点|2025下半年「自动驾驶」最推荐学习的10篇强化学习应用论文
在 Bench2Drive 闭环基准测试中,搭载轻量化 Qwen2-0.5B的 LLM 的 MindDrive,取得了 78.04 的驾驶评分(DS)和 55.09% 的成功率(SR),分别超越同参数 IL 基线模型 5.15 分和 9.26%,是首个通过与环境实时交互进行在线强化学习训练的自动驾驶VLA模型。作者计划在后续更新中开源模型和部分数据集。模型不再采用“先看图、再推理”的割裂流程,而是
点击查看原文,获取更多干货内容![]() https://mp.weixin.qq.com/s/wikGc_K-tEKaE_vz3UqaVg
https://mp.weixin.qq.com/s/wikGc_K-tEKaE_vz3UqaVg

「 强化学习正在重塑端到端 」
目录
IRL-VLA: Training an Vision-Language-Action Policy via Reward World Model
FutureSightDrive: Thinking Visually with Spatio-Temporal CoT for Autonomous Driving
MindDrive: A Vision-Language-Action Model for Autonomous Driving via Online Reinforcement Learning
DIVER: Reinforced Diffusion Breaks Imitation Bottlenecks in End-to-End Autonomous Driving
今年下半年涌现的一批工作,清晰地展现了强化学习正在渗透并重塑端到端自动驾驶的几乎所有关键环节。
从基于世界模型的高效仿真训练,到利用对抗学习提升策略鲁棒性;从使用RL约束多模态轨迹生成的质量,到优化VLA模型的推理与反思能力。
这些研究有的致力于构建高效的“神经模拟器”以突破数据瓶颈,有的尝试让智能体在与环境的闭环交互中自主学习复杂策略,还有的巧妙地将RL作为“裁判”与“教练”,引导其他生成模型产出更安全、多样的规划结果。
本次盘点,我们选取了在各大顶会及社区中受到瞩目的10篇强化学习相关代表性工作。它们不仅方法本身具有创新性,更共同指向一个方向:通过强化学习将自动驾驶的“感知-决策-执行”链条真正贯通,打造能在复杂开放世界中持续学习与进化的驾驶智能体。
需要说明的是,优秀的自动驾驶RL工作远不止本文所列。本次盘点主要依据论文的RL方法创新性、对社区启发性及研究方向代表性进行筛选,难免存在取舍。不同研究在问题定义和技术路线上各有侧重,本文旨在梳理近期RL驱动的技术趋势,而非全面评判。
OmniDrive-R1: Reinforcement-driven Interleaved Multi-modal Chain-of-Thought for Trustworthy Vision-Language Autonomous Driving
-
机构:旷世科技、上海科技大学等
-
推荐理由:首个纯强化学习、无需标注的端到端视觉-语言自动驾驶框架
-
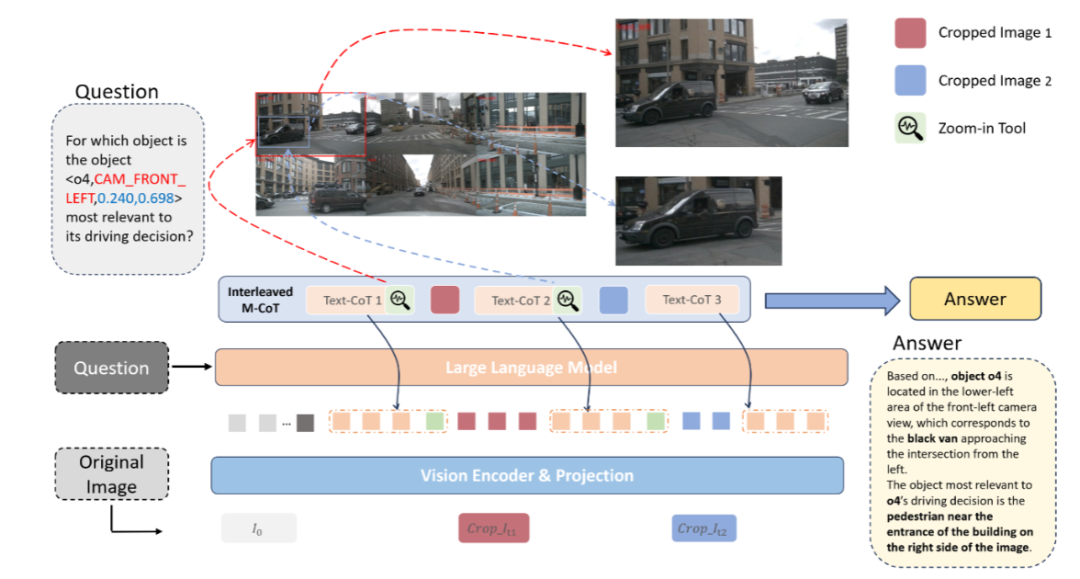
内容:OmniDrive-R1 是一项面向自动驾驶的视觉-语言模型研究,关注如何提升 VLM 在安全关键场景中的可靠性与可信推理能力。该工作指出,当前 VLM 在自动驾驶中容易出现目标幻觉等严重问题,根源在于推理过程过度依赖脱离视觉依据的纯文本 Chain-of-Thought,导致模型“会说但没看清”。
针对这一问题,OmniDrive-R1 提出了一种交错式多模态思维链(iMCoT)框架,将视觉感知与语言推理在推理过程中紧密交织。模型不再采用“先看图、再推理”的割裂流程,而是在推理过程中根据当前判断结果,动态引入新的视觉信息,逐步细化对关键区域的理解,从而形成“边看边想”的推理闭环。
在训练层面,OmniDrive-R1 引入强化学习机制,使模型能够自主决定关注哪些视觉区域,而非依赖人工标注的目标框。通过这种强化驱动的视觉聚焦方式,模型在无需密集标注的情况下实现了视觉与语言推理的一致对齐。实验结果表明,该框架在自动驾驶多模态推理任务上显著优于现有 VLM 基线,验证了交错式多模态推理在提升驾驶决策可信性方面的潜力。
-
链接:https://arxiv.org/pdf/2512.14044
IRL-VLA: Training an Vision-Language-Action Policy via Reward World Model
-
机构:博世、上海大学、上海交通大学和清华AI
-
推荐理由:首个通过端到端强化学习(包括传感器输入)实现的闭环VLA方法
-
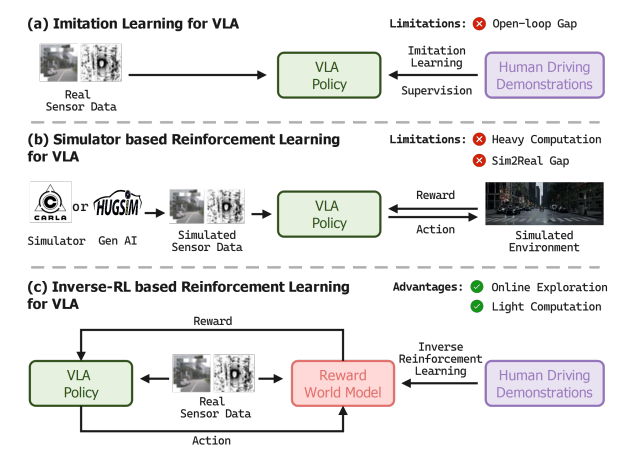
内容:作者提出了一种新颖的闭环强化学习框架,该框架通过逆向强化学习(Inverse Reinforcement Learning)与作者自建的VLA方法相结合,命名为IRL-VLA。利用框架,设计并学习了一个实时奖励世界模型(Reward World Model, RWM),该模型通过从多样化策略中进行逆向强化学习获得。
它捕捉了驾驶的多模态和多目标本质,同时能够以一种成本效益高的方式扩展到大量真实世界数据,从而规避了Sim2Real的领域适应问题。作者应用所学习的RWM来指导VLA模型的强化学习。该方法在NAVSIM v2端到端驾驶基准测试中达到了最先进的性能,在CVPR2025自动驾驶大奖赛中以45.0 EDPMS的成绩获得亚军。
-
链接:https://arxiv.org/pdf/2508.06571
FutureSightDrive: Thinking Visually with Spatio-Temporal CoT for Autonomous Driving
-
收录:NeurIPS 2025 Spotlight
-
机构:西安交通大学、高德
-
推荐理由:FSDrive提出 “时空视觉 CoT”,让模型直接 “以图思考”,用统一的未来图像帧作为中间推理步骤,联合未来场景与感知结果进行可视化推理。
-
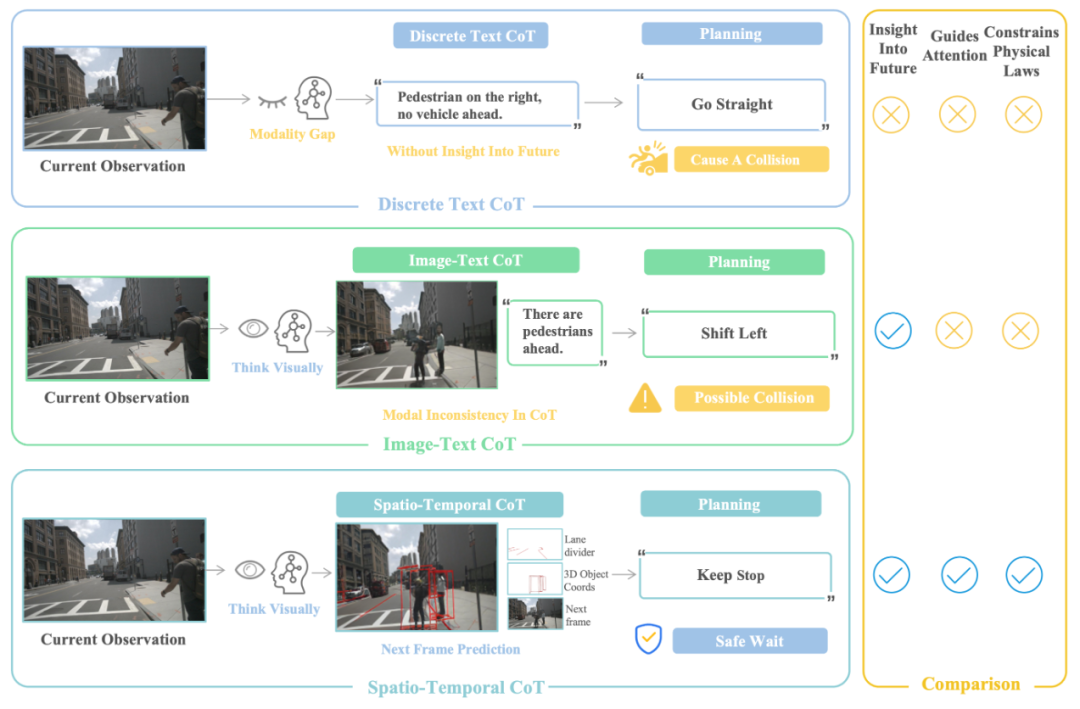
内容:FutureSightDrive(FSDrive)是一项面向端到端自动驾驶的 Vision-Language-Action 工作,关注现有 VLA 方法在推理阶段主要依赖文本形式 Chain-of-Thought 所带来的局限。该工作指出,将复杂的时空驾驶信息压缩为纯文本推理,容易丢失关键的空间结构和时间演化线索,从而在感知与规划之间形成模态不一致的问题。
为此,FSDrive 提出一种以“视觉时空 CoT”为核心的框架,使模型在规划前以视觉形式进行推理。模型首先作为世界模型运行,根据当前观测生成一个统一的未来场景表示,其中包含预测的背景信息以及具有物理约束的结构化先验,如未来车道线和三维目标框。这一生成的未来场景被用作视觉形式的时空 CoT,用于同时表达空间关系和时间变化。
在此基础上,同一 VLA 模型进一步作为逆动力学模型运行,在当前观测和视觉 CoT 的条件下生成驾驶轨迹。训练过程中,FSDrive 采用统一的预训练范式,通过扩展视觉 token 表示,并联合优化语义理解任务和未来帧预测任务。同时,引入逐步递进的课程训练方式,先生成结构化先验以约束物理合理性,再生成完整场景表示。相关实验在 nuScenes、NAVSIM 和 DriveLM 等数据集上进行,用于评估其在轨迹规划、碰撞率以及场景理解等方面的表现。
-
链接:https://arxiv.org/pdf/2505.17685
MindDrive: A Vision-Language-Action Model for Autonomous Driving via Online Reinforcement Learning
-
机构:华中科技大学、小米汽车
-
推荐理由:首个通过与环境实时交互进行在线强化学习训练的自动驾驶VLA模型。
-
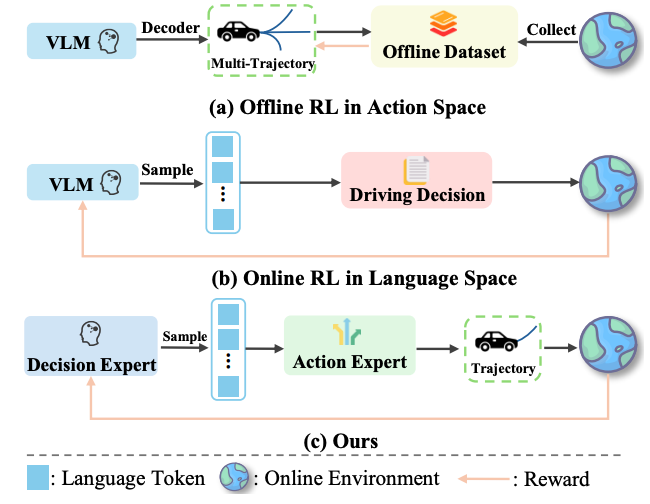
内容:MindDrive 是专为自动驾驶设计的 VLA 模型,核心创新在于通过 “语言 - 动作动态映射”,将连续的轨迹动作空间转化为离散的语言决策空间,解决了在线强化学习在自动驾驶中探索效率低下的痛点。模型采用双专家架构:共享基础大语言模型(LLM)但搭载独立 LoRA 参数的决策专家与动作专家,通过轨迹级奖励反馈优化推理能力,实现了复杂场景最优决策、类人驾驶行为与高效探索的三者平衡。在 Bench2Drive 闭环基准测试中,搭载轻量化 Qwen2-0.5B的 LLM 的 MindDrive,取得了 78.04 的驾驶评分(DS)和 55.09% 的成功率(SR),分别超越同参数 IL 基线模型 5.15 分和 9.26%,是首个通过与环境实时交互进行在线强化学习训练的自动驾驶VLA模型。
-
链接:https://arxiv.org/pdf/2512.13636
AutoDrive-R²: Incentivizing Reasoning and Self-Reflection Capacity for VLA Model in Autonomous Driving

-
机构:阿里巴巴、昆士兰大学
-
推荐理由:通过思维链处理与强化学习,同时增强自动驾驶系统的推理与自反思能力。
-
内容:这项工作聚焦于当前自动驾驶 VLA 模型中一个相对被忽视的问题:模型虽然能够输出合理的轨迹,但其决策过程本身缺乏可解释性,且动作序列在逻辑一致性和物理合理性上仍存在不稳定性。为此,作者提出了 AutoDrive-R²,一个同时强化“推理能力”和“自我反思能力”的端到端 VLA 框架。
在方法上,AutoDrive-R²首先构建了一个新的链式推理数据集 nuScenesR2-6K,用于监督微调阶段。该数据集通过一个包含自我反思的四步逻辑链,将输入的视觉与语言信息逐步映射到最终的轨迹输出,从而在感知信息与动作规划之间建立更清晰的“认知桥梁”。这一阶段主要用于引导模型学习结构化的推理过程,而不仅是直接预测结果。
在此基础上,作者进一步引入强化学习阶段,通过 Group Relative Policy Optimization(GRPO)算法联合优化推理与反思能力。不同于仅关注轨迹终点或碰撞指标的设置,该阶段采用了物理约束感知的奖励设计,综合考虑空间对齐、车辆动力学约束以及时间连续性,从而鼓励模型生成更加平滑、可执行且符合物理规律的规划轨迹。
-
链接:https://arxiv.org/pdf/2509.01944
AutoVLA: A Vision-Language-Action Model for End-to-End Autonomous Driving with Adaptive Reasoning and Reinforcement Fine-Tuning
-
收录:NeurIPS 2025
-
机构:加州大学洛杉矶分校
-
推荐理由:基于自适应推理和强化微调的端到端自动驾驶视觉语言行为模型
-
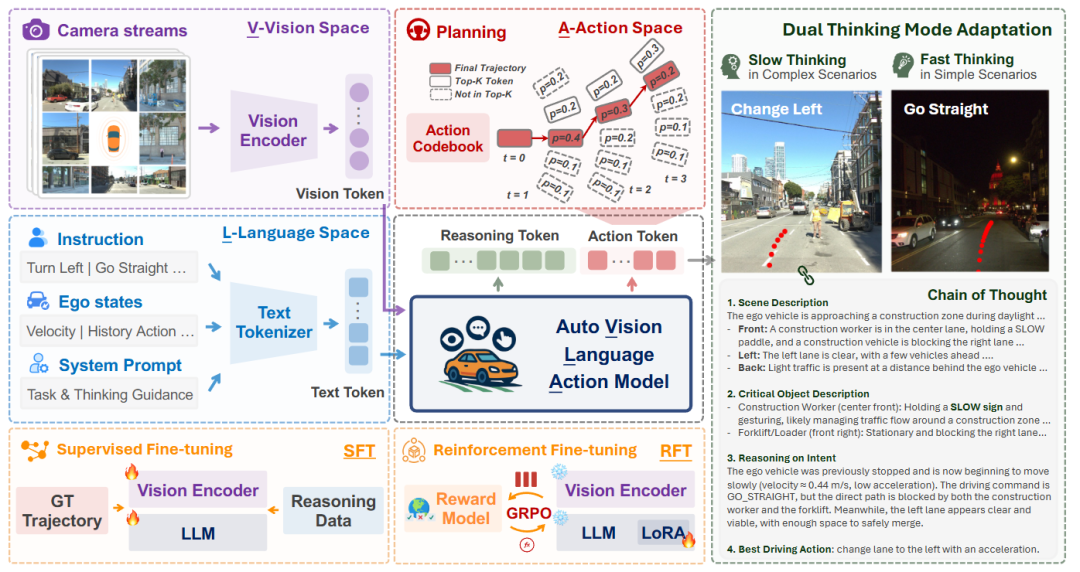
内容:AutoVLA 是一项面向端到端自动驾驶的 Vision-Language-Action 模型工作,关注如何在同一模型中同时完成语义理解、推理和轨迹规划。该工作从现有 VLA 方法在自动驾驶场景中的实际问题出发,指出部分模型存在动作不可执行、结构复杂或推理过程冗长等局限。
在模型设计上,AutoVLA 将推理过程与动作生成统一在一个自回归生成框架中,直接从原始视觉输入和语言指令生成驾驶轨迹。为适配语言模型的生成形式,工作将连续的轨迹表示离散化为可执行的动作 token,使规划结果能够直接融入语言模型的输出过程。模型在训练阶段通过监督微调学习两种不同的“思考模式”:一种仅生成轨迹的快速模式,另一种结合链式推理的增强模式,用于处理更复杂的场景。
在此基础上,AutoVLA 进一步引入基于 Group Relative Policy Optimization 的强化微调策略,用于在不同场景下自适应地调整推理深度,减少简单情形中不必要的推理开销。相关实验在多个真实和仿真自动驾驶数据集上进行,包括 nuPlan、nuScenes、Waymo 和 CARLA,用于评估模型在开放环路和闭环设置下的规划与执行表现。
-
链接:https://arxiv.org/pdf/2506.13757
Alpamayo-R1: Bridging Reasoning and Action Prediction for Generalizable Autonomous Driving in the Long Tail
机构:英伟达
推荐理由:Alpamayo-R1凭“因果链推理”重塑端到端自动驾驶
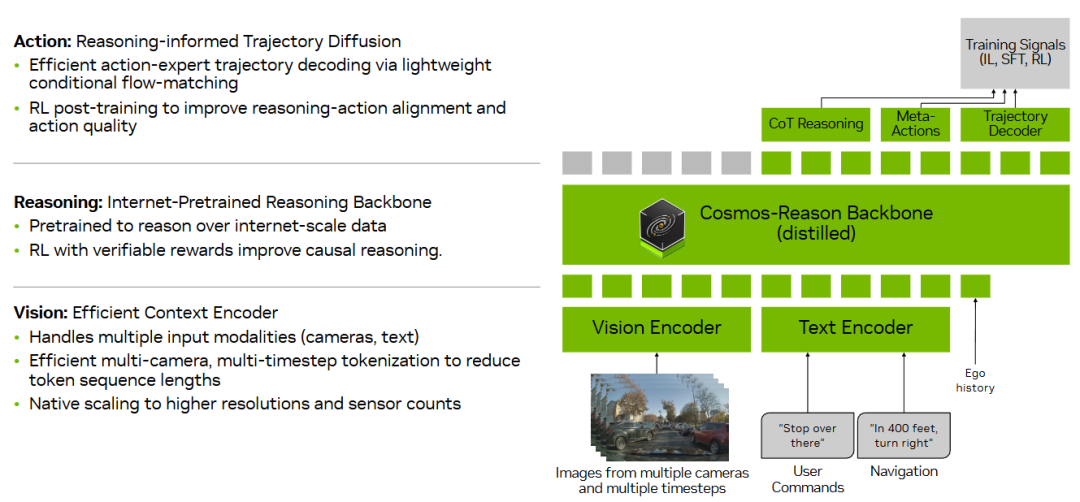
内容:Alpamayo-R1(AR1)是一项面向自动驾驶长尾场景的 Vision-Language-Action 工作,关注在安全关键、监督稀缺的复杂驾驶情形中,如何将推理过程与轨迹规划更紧密地结合。该工作指出,单纯依赖模仿学习扩展模型规模和数据规模,在长尾场景下往往难以建立稳定的因果理解,从而影响决策可靠性。
在方法设计上,AR1 将“因果链式推理”与轨迹生成纳入同一框架。首先构建了一个名为 Chain of Causation(CoC)的数据集,通过自动标注与人工参与相结合的方式,为驾驶行为生成与决策相关、具备因果关联的推理过程。模型结构采用模块化设计,高层使用针对物理场景预训练的视觉语言模型进行推理,低层则通过基于扩散的轨迹解码器生成满足运动学约束的可执行轨迹。
在训练策略上,AR1 采用多阶段流程,先通过监督微调引导模型生成与驾驶行为对应的推理过程,再引入强化学习对推理质量和推理-动作一致性进行优化。实验评估主要聚焦于复杂和长尾驾驶场景,涵盖规划精度、越界行为和近距离交互等指标,并在闭环仿真和真实道路测试中验证系统的实时性表现。论文同时报告了模型规模扩展对性能的影响,用于分析不同参数规模下的行为变化。作者计划在后续更新中开源模型和部分数据集。
链接:https://arxiv.org/pdf/2511.00088
Decision making for autonomous vehicles: A mixed curriculum reinforcement learning approach and a novel safety intervention method
-
收录:Transportation Research Part C: Emerging Technologies
-
机构:同济大学
-
推荐理由:同时解决学习效率、安全性以及灾难性遗忘问题的统一框架。
-
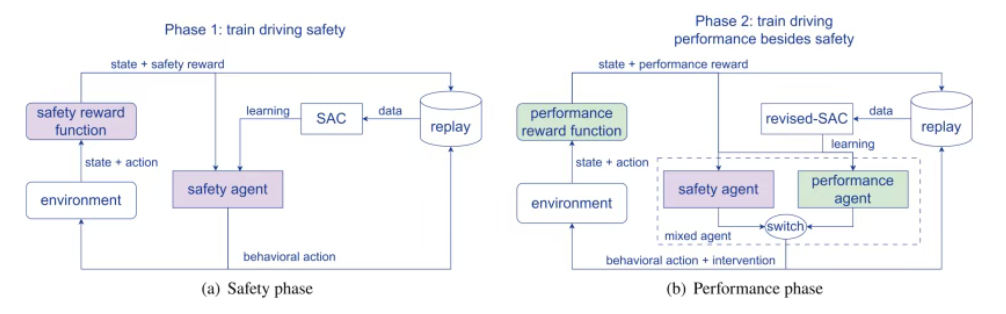
内容:本研究提出了一种混合课程学习(MCL)框架。该方法将训练过程分为两个阶段:首先,智能体集中学习并掌握基础的安全驾驶技能,形成一个可靠的“安全代理”;然后,在追求更优驾驶性能的阶段,这个预训练的安全代理会作为“教练”实时监督,通过一种新颖的概率干预机制(DDBI)在危险时刻介入,从而在不影响探索学习的前提下确保安全。这种设计有效解决了安全与效率的矛盾,并避免了对过往安全知识的遗忘。
-
链接:https://www.sciencedirect.com/science/article/abs/pii/S0968090X25003730
DiffusionDriveV2: Reinforcement Learning-Constrained Truncated Diffusion Modeling in End-to-End Autonomous Driving
-
机构:华中科技大学、地平线
-
推荐理由:利用强化学习既约束低质量模式,又探索更优轨迹。
-
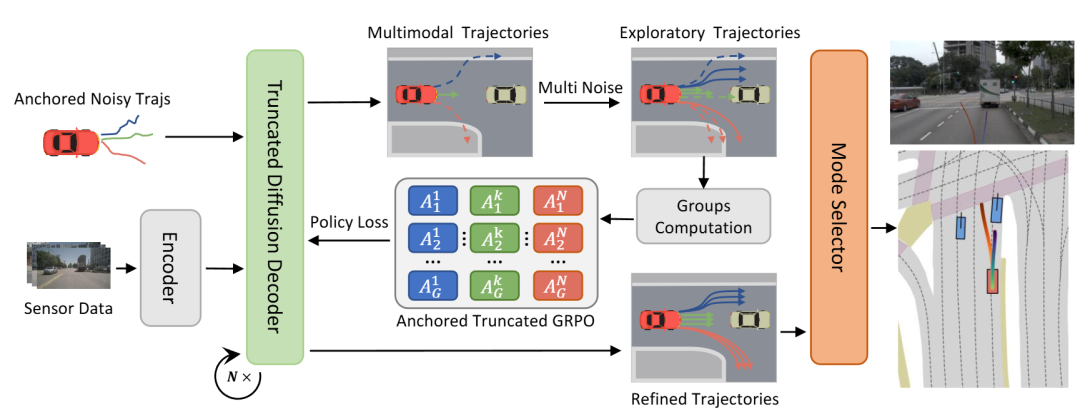
内容:DiffusionDriveV2 是一项面向端到端自动驾驶轨迹规划的生成式模型工作,关注扩散模型在多模态轨迹生成中常见的模式塌缩问题。该工作指出,已有方法虽然通过引入不同驾驶意图来增强轨迹多样性,但在仅依赖模仿学习的情况下,容易在多样性与轨迹质量之间产生权衡困难。
为此,DiffusionDriveV2 在原有基于锚点的多意图轨迹生成框架上,引入强化学习机制对生成结果进行约束与优化。方法通过高斯混合模型对不同驾驶意图进行建模,并在训练过程中结合尺度自适应的乘性噪声,以促进轨迹空间的探索。在此基础上,模型分别在单一意图内部和不同意图之间采用不同形式的策略优化方法,用于区分同一意图下的优劣轨迹,同时避免跨意图比较带来的不稳定问题。
根据论文描述,该方法在闭环自动驾驶评测中进行了系统实验,主要用于分析在保持轨迹多样性的同时提升整体规划质量的效果。相关评估在 NAVSIM 数据集的多个版本上进行,用于验证该框架在复杂驾驶场景中的行为表现。
-
链接:https://arxiv.org/pdf/2512.07745
DIVER: Reinforced Diffusion Breaks Imitation Bottlenecks in End-to-End Autonomous Driving
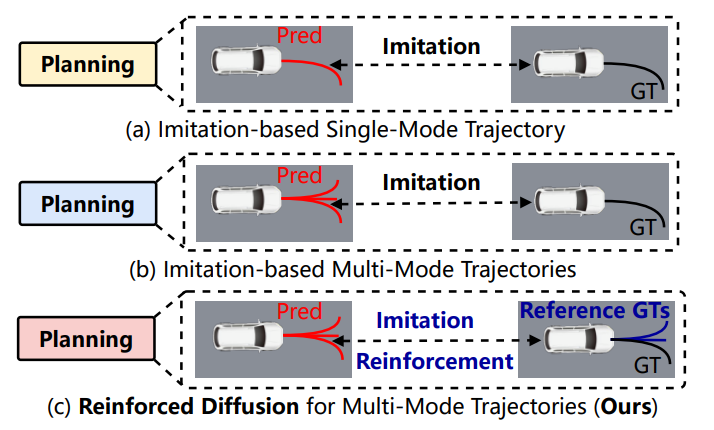
-
机构:北京交通大学、地平线
-
推荐理由:将强化学习与基于扩散的生成模型巧妙地结合起来,旨在生成既多样又安全可行的行驶轨迹。
-
内容:提出端到端自动驾驶(E2E-AD)框架DIVER,结合扩散模型和强化学习,用于生成多样化、安全且目标导向的轨迹。引入了策略感知扩散生成器(PADG),通过条件扩散生成器结合地图元素和周围智能体信息,生成多种模式的轨迹,捕捉不同的驾驶风格。利用强化学习中的Group Relative Policy Optimization(GRPO)目标来指导扩散过程,优化轨迹的多样性和安全性,解决模仿学习中的模式坍塌问题。提出轨迹多样性度量指标,为评估多模式预测的多样性提供了一种更合理的方法,相比现有指标更具原则性。在Bench2Drive、NAVSIM和nuScenes等多个基准测试中,证明了DIVER在提高轨迹多样性、安全性和可行性方面的显著优势。
-
链接:https://arxiv.org/pdf/2507.04049
关注公众号【深蓝AI】,后台私信1223,领取上述推荐论文包
总结
无论是引入链式推理、自我反思,还是通过生成式世界模型、闭环仿真、强化学习来约束规划质量,这些工作都在尝试解决同一个核心问题:如何在复杂、稀有且高风险的真实交通场景中,持续输出可解释、可执行、可泛化的驾驶行为。
值得注意的是,这些方法并未形成单一路线,而是呈现出明显的分化与互补。有的强调推理结构,有的强调数据生成与仿真闭环,有的关注多模态建模,有的聚焦于规划多样性与稳定性。它们共同指向的,不是某一个“终极模型”,而是一套正在逐步成型的系统级方法论。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 23
23 0
0- 0



 已为社区贡献47条内容
已为社区贡献47条内容

所有评论(0)