梳理 VLA 执行接触任务时安全落地的可行技术方案
训练阶段你需要的是“允许探索但不越界”的机制,用安全边界、干预式兜底把危险动作拦住,让模型学到更稳定的策略风格;部署阶段你需要的是“能长期守规矩、抗不确定”的执行栈,用柔顺控制、MPC/CBF 等护栏把动作落稳,把语言层约束变成可执行的物理约束;VLA 再强,也不适合单独承担这两件事——这也是为什么 “语义接口 + 物理兜底” 的双重架构,不是可选,而是某种程度上的“必选项”。一是安全是 “复用性
目录
更现实的做法:prompt 负责“说清规则”,系统负责“强制执行”
用“概率红线”控制风险:机会约束(Chance Constraints)
做具身操作,最棘手的不是“能不能动”,而是“动的时候会不会出事”,尤其对于接触丰富(contact-rich)的任务。
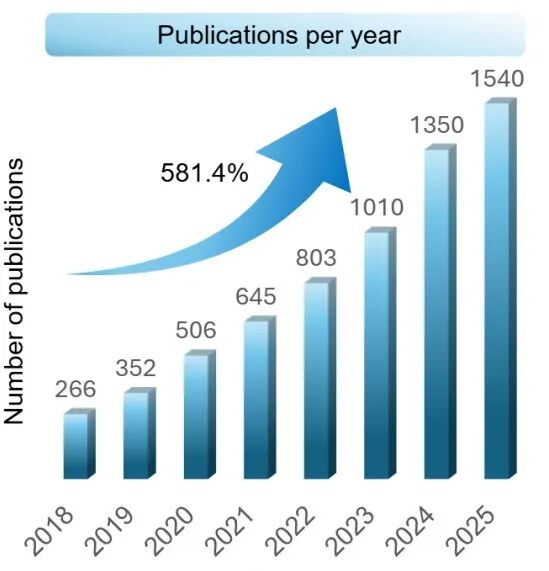
相关数据表明:近年来,围绕“安全”和“接触密集型任务”的机器人研究,呈爆发式增长,7年间涨幅比高达581.4%。
其中原因,也非常好理解:越是把机器人推向真实世界、让它动手干活,越会发现“能完成任务”远远不够——卡在的正是 “安全交互” 这道鸿沟。
VLA 的出现,被赋予了“打破这道鸿沟”更多的希望。
很多人第一反应会是:既然 VLA 能读懂指令,那我们能不能像 CoT(Chain-of-thought,) 一样,直接在 prompt 里把“安全”写清楚?
比如说:“你要把水果夹起来,但不要碰撞、不要用太大力,保证安全。”
这类提示当然有用,它至少让模型在决策时把“安全”当成目标的一部分。
但是,语言提示更像“安全意图声明”,很难直接变成“可验证的安全行为保证”。
那么如何在不确定的接触中学习,并确保学习过程与执行结果的双重安全?
今天这篇文章,我们具体梳理一下 VLA 做接触任务时具体的难点是什么,以及让 VLA 接触任务安全落地,又有哪些可行方案。
01 基于VLA的接触任务难在哪里
关键仍在于数据。
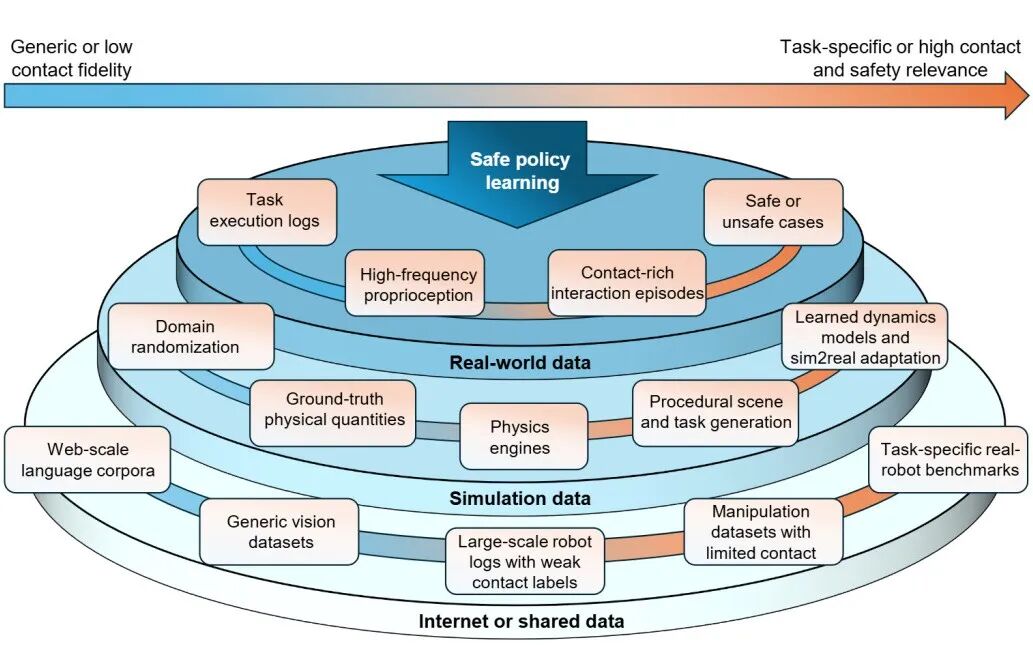
▲机器人要安全学会 “接触密集型任务”,不能只靠某一种数据
图中展示了机器人接触密集型任务安全学习,所需数据的 “层级结构” :
-
最顶层是真实世界数据:
包括高频的关节/速度/触觉与力-力矩传感,以及安全/不安全(失败)案例。
它最贴近真实接触与事故模式,所以对“上线不越界”最关键,但也最难采、最昂贵。
-
中间是仿真:
能做大规模探索,适合“训练阶段的安全探索”,但再强也难完全复刻真实接触的复杂性,只能说是可控但不完美。
-
底层是互联网与共享数据集:
数量大,但对“接触细节”和“安全关键现象”刻画往往是间接的。
而且很多真实任务是“多种困难叠在一起”的,比如既要插入对齐、又要控制接触力、还要处理物体滑动或变形。
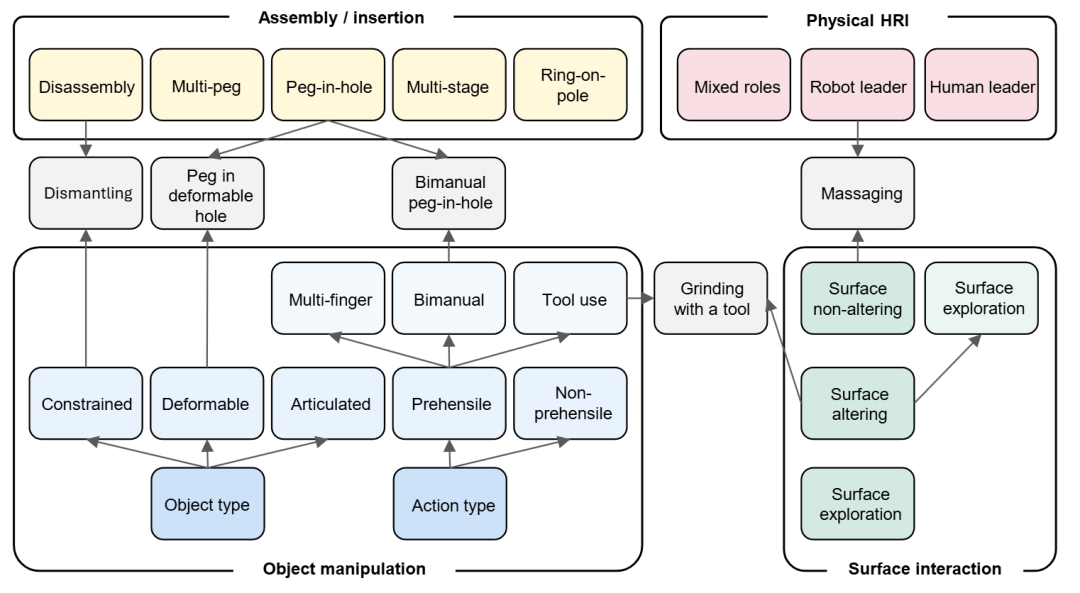
▲接触丰富任务四个类型
这也解释了:为什么光靠语言指令,难以实现“接触操作任务中的安全落地”,因为如果缺少真实接触与失败证据,模型很难真正学会“物理后果”。
下面我们具体分析其中原因。
语言安全约束,往往是“懂了也没法直接执行”
例如一些接触任务的语言指令(prompt):
不要碰撞、轻轻夹、慢慢插入
这些语言,人类听得懂,但对于机器人来说,没有一套真正能衡量的、可落地的、可计算的“量”:
-
碰撞的定义是什么?
是“末端和物体零接触”还是“允许轻微接触但不能冲击”?
-
“轻轻”到底是多大力?
不同物体允许的阈值不同,甚至同一个物体不同位置也不同。
-
“慢慢”是速度上限还是加速度上限?
接触过程中要不要随时降速?什么时候该停、什么时候该让?
也就是说,prompt 解决的是“你想要什么”,但安全执行更依赖“你如何把这句话翻译成‘可计算’的约束”。
VLA 输出的是动作,但风险常发生在“动作落地的物理细节”
接触丰富任务里,危险经常不是来自“方向错了”,而是来自接触瞬间的力、顺应、抖动、卡滞。
VLA 就算在高层规划上非常合理,也可能在这些细节上踩坑:同样是“夹起水果”,
真正决定安全的往往是末端的柔顺程度、接触模式切换时机、力的上升斜率……
而这些东西靠一句 prompt 很难稳定控制。

也就是说,prompt 能让模型更“谨慎地想”,但不能替代它在物理层面“持续地守规矩”。
更现实的做法:prompt 负责“说清规则”,系统负责“强制执行”
因此,更可落地的安全接入方式通常是“分层的”:
-
语言层(VLM/提示词):
把安全要求说清楚、结构化,最好能明确“哪些是硬红线,哪些是软偏好”。
-
策略层(VLA):
负责根据观测与指令输出动作或动作参数,让系统具备通用性和任务适应能力。
-
执行层(护栏层):
把语言里的“安全”变成能实时检查、能强制满足的约束。

▲几类代表性方向:面向接触任务的控制、安全控制,以及学习驱动的方法路线,基本对应后文提到的“安全探索/安全执行”两条主线。
VLA 的安全需要完成两次关键 “落地”
语言更像“安全规则的接口”,而真正兜底的,仍然是那些能计算、能验证、能实时拦截的机制。
对 VLA 来说,安全要分两次“落地”:
第一次落在训练数据与探索策略里,避免把危险习惯学进模型;
第二次落在部署时的控制与约束层里,保证每一步动作都不越界。
下面我们就按这两个阶段,看看当前接触任务在安全探索、安全执行两个方向上,都有哪些主流做法。
02 训练阶段:安全探索
训练阶段的核心矛盾是:学习需要探索,但探索很容易把“危险动作”也探索出来。
那么,如何在训练阶段,让机器人“少犯”危险动作至关重要。
而这一点在 VLA 中尤其明显:
VLA 往往直接从图像+指令输出动作(或输出一段动作参数),训练时如果让它“自由试”,它可能会为了完成目标去推、去挤、去硬插。
短期看起来更快,长期却可能学到一套“强行完成任务”的坏风格。
我们把这一阶段常见的做法,按“怎么把约束加进去”,分成了三类,更好理解。
用“安全边界”把探索圈起来:控制障碍函数(CBF)
CBF 你可以把它理解成一个“安全边界计算器”:
研究人员先定义什么叫安全,比如:
末端与人保持至少 d 的距离、接触力不能超过 F、机械臂不能进入禁区。
然后每次模型给出一个动作,CBF 会做一次快速的优化:
尽量不改动模型动作,但如果这个动作会越界,就把它修正回安全边界以内。
对 VLA 来说,这种方式很像给端到端模型加了一个“最终审查”。
模型可以大胆提议动作,但最后落地的是“通过安全审查的动作”,如下入所示:
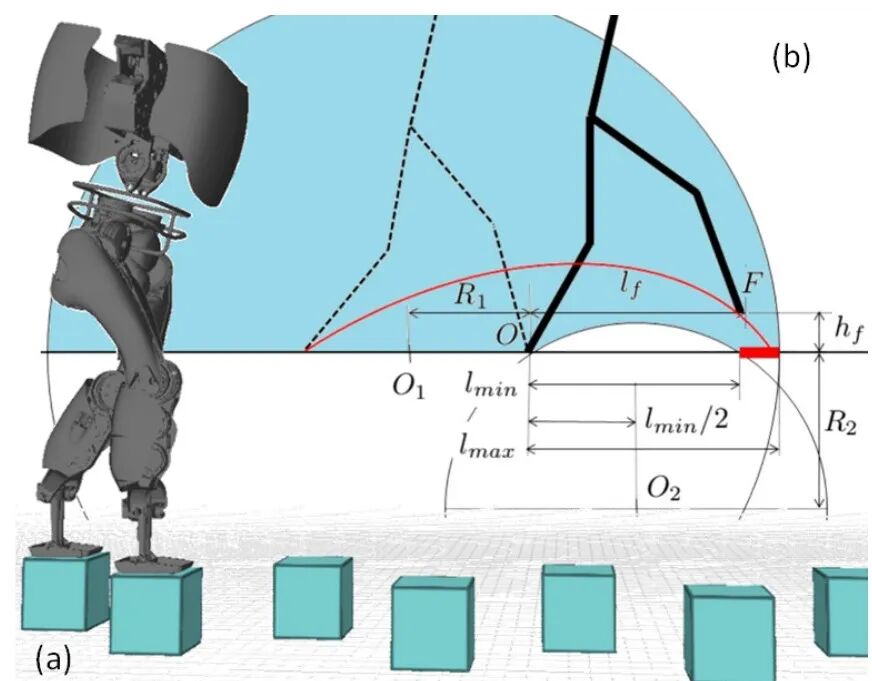
▲CBF 的直觉版示意,给 VLA 的动作加一道“落脚护栏”。
这是一个很典型的安全关键任务:机器人要在“踏石”地形上动态行走。
这里的“危险”不是走得快不快,而是每一步脚落下去能不能踩在石头上,一旦踩空就可能摔倒或损坏设备。
CBF的作用就是替代右侧(b)中的那一堆安全公式:
当 VLA 给出的动作会导致落脚点越界(比如步子迈太大、迈太小、或者落点偏出踏石),CBF就会把动作拉回到安全可行的落脚区域里,确保机器人每一步都“走在规则里”,而不是只“听起来很安全”。
CBF 的优势很直观:能把红线写得清清楚楚,越界就拦。
但接触任务里还有个极常见的问题:
环境参数不确定(摩擦、刚度、孔位误差),安全边界也会“算得不准”。
于是又会出现带不确定性的 CBF 变体,思路是把未知因素也考虑进去,只是往往会更保守。
用“概率红线”控制风险:机会约束(Chance Constraints)
有些约束你很难说“绝对不能”,只能说“发生概率必须极低”。
比如抓取时偶尔轻微碰触可以接受,但不能频繁撞击。
机会约束就是这种思路:允许极少数违规,但把违规概率压到阈值以下。
对 VLA 来说,它更像“风险预算”:
模型可以更灵活,但系统会严格控制风险暴露的概率。
但其难点也非常明显,就是“计算”,很多真实场景的可行域并不规整,算起来重,工程上不如 CBF 那么干脆利落。
配一个“安全兜底动作”:可达性过滤 / 干预式安全层
还有一类更实用的做法:
模型照样输出动作,但系统随时准备一个“安全备份”。
一旦当前动作可能导致“不可恢复”的危险,系统就切换到备份策略,或者把动作投影到一个可达、安全的轨迹集合里。
类似于自动驾驶里的“安全接管”:
平时你让学习策略开车;但只要检测到要撞,就强制刹车或改道。
这种策略也被迁移到了VLA的训练过程中:
因为VLA 再聪明,它本质上仍可能在长尾场景里犯错,干预式安全层可以保证训练阶段不会因为“一次极端动作”就把环境和机器人搞坏,也能让数据采集更可控。
03 部署阶段:安全执行
如果说探索阶段是“别学坏”,那执行阶段就是“别失控”。
因此,部署阶段的目标就是让机器人具备“稳、守规矩、抗不确定性”的能力。
我们都清楚:接触丰富任务上线后的风险通常更隐蔽,因为你可能看不出它马上会撞,但它在持续接触中慢慢积累偏差,最后突然卡死、弹开、或者力爆掉。
在这一阶段,研究人员通常不会只靠“一个大模型直接出动作”,而是会在底层放一个更可靠的执行栈,最典型的是柔顺控制。
柔顺控制:让机器人“会让步”,而不是硬刚
柔顺控制常用两种形式:
-
阻抗控制(Impedance)
让机器人表现得像一个“弹簧+阻尼”,外界推它,它不会硬顶,而是吸收冲击、稳定接触。
-
导纳控制(Admittance)
更像“你给我多大力,我就按一定规律让出多少位移”,特别适合外力变化大的互动。
延展阅读:署名是英伟达×斯坦福,但C位是宇树的。

▲例如这项工作就是可控柔顺性与 VLA 任务理解的精准匹配
为什么这对 VLA 很重要?
因为 VLA 输出的动作往往是高层的“我要怎么动”;
但接触任务真正安全的关键常常是“我该用多少力、我什么时候该大力操作、什么时候该缓一下”。
柔顺控制就是把这部分“物理直觉”固化在执行层里,让系统不会因为一点误差就变成硬碰硬。

▲机器人柔顺控制的例子,在受到外力之后,机器人并没有依靠关节的刚性硬顶冲击,而是借着外力倒下,随后再站起来。这种柔顺控制使得机器人能够有效“卸力”,四两拨千斤,而不是依靠自己的钢铁之躯“硬抗”,导致不必要的安全隐患
难点
柔顺控制不是开关,它有一堆参数(刚度、阻尼等),因此柔顺参数不好调,调错了反而更危险。
参数太硬,接触力会上去,容易损坏;
参数太软,动作漂,插不进去、拧不紧;
环境一变(材质、摩擦、孔位误差),原来调好的参数又不灵了。
因此执行阶段一个重要趋势是——让学习方法去自动调柔顺参数
在不同接触条件下动态选择更合适的“软硬程度”。
这里学习的角色不是替代控制器,而是帮控制器“选参数”,把安全和性能一起兼顾。
放一个“安全护栏”:MPC 安全屏蔽的思路
除了柔顺控制,还有一类很常见的部署“护栏”:
用模型预测控制(MPC)的思想做安全屏蔽。
它的逻辑是:每次动作输出前,系统会“短视地”预测未来几步,如果发现这条动作链会导致约束违背,就改成一条可行的、安全的动作序列。
对 VLA 来说,这种做法非常适合作为“最后一道门”:
VLA 负责提出意图和动作候选,MPC 把它修正成短期可执行、可验证的动作。
这样既保留 VLA 的灵活性,又不会让它把低层动力学约束踩穿。
不可能三角
安全不是“越保守越好”,它永远要跟任务和效率做交换。
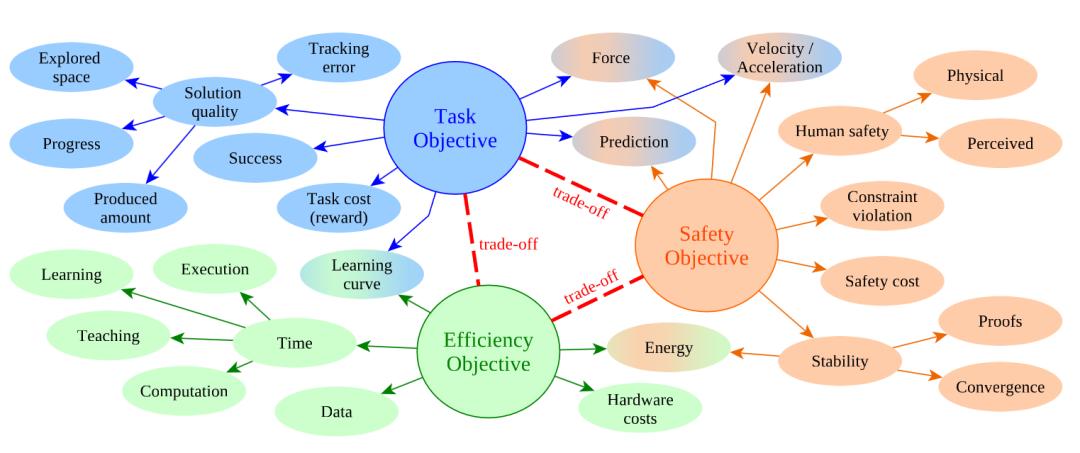
▲3 个核心评价维度
如图所示,指标被分成三类:安全、任务成功、效率,并强调它们之间存在 trade-off。
这对接触任务尤其明显:把力限制得太严可能任务做不成;动作太保守则时间与能耗飙升。
像接触力、速度、能量这些指标之所以常被反复使用,就是因为它们往往同时反映“安全边界”和“任务质量”。
简单说就是 “机器人干活又安全、又能干好、又高效,很难三者兼顾”。
04 总结
当我们把安全拆成“训练阶段”和“执行阶段”之后,很多争论反而会更清晰:
-
训练阶段你需要的是“允许探索但不越界”的机制,用安全边界、干预式兜底把危险动作拦住,让模型学到更稳定的策略风格;
-
部署阶段你需要的是“能长期守规矩、抗不确定”的执行栈,用柔顺控制、MPC/CBF 等护栏把动作落稳,把语言层约束变成可执行的物理约束;
VLA 再强,也不适合单独承担这两件事——
这也是为什么 “语义接口 + 物理兜底” 的双重架构,不是可选,而是某种程度上的“必选项”。
但当跳出文章框架再来看“VLA 接触任务的安全落地”,其实还有几个容易被忽视的关键视角:
一是安全是 “复用性” 的前提
如果每次换个零件、换个场景,都要重新标注 “安全力阈值”“禁止接触区域”,VLA 的 “通用性” 就成了空谈。
二是人机协同的 “隐性安全” 比 “显性约束” 更重要。
拿机器人按摩来说,“力度刚好不疼”,比单纯的力阈值更影响用户接受度。
三是安全的 “可追溯性”
具身智能越普及,安全的 “责任界定” 越重要。当 VLA 应用到医疗、工业等高危场景(比如手术机器人、工业装配机器人),安全不只是 “不出事”,还要 “出事能溯源”,这是跨场景落地必须解决的问题之一。
所以,安全不是阻碍 VLA 拓展能力,而是让它的能力拓展有 “可预期的边界”
—— 恰恰是这个边界,让 VLA 开出的「安全支票」,能在物理银行真正「兑现」。
Ref:
论文题目:Safe Learning for Contact-Rich Robot Tasks: A Survey from Classical Learning-Based Methods to Safe Foundation Models
论文地址:https://arxiv.org/pdf/2512.11908

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 7
7 0
0- 0



 已为社区贡献47条内容
已为社区贡献47条内容

所有评论(0)