全身操控!星尘推出异步快慢的VLA策略,端到端训练+3 倍于同类模型的推理速度
Astribot团队提出的DuoCore-FS框架创新性地解决了大语言模型(VLM)与机器人实时控制间的矛盾。该框架采用"快慢双路径异步架构",通过模态对齐缓冲、全身体动作token化和跨时标联合训练三层技术体系,首次实现3B参数大模型与30Hz高频全身体控的兼顾。实验表明,该方案推理速度达32.3Hz,是同类模型的2.6倍,整体任务成功率90%,在分布外场景中表现优异。该研究为复杂场景下的机器人
在VLA机器人研究领域,大语言模型(VLM)的语义推理能力与机器人实时控制需求长期存在矛盾——大模型的低推理速度严重限制了全身体控的稳定性与响应性。Astribot 团队提出的 DuoCore-FS 框架,以 “快慢双路径异步架构” 为核心,通过 “模态对齐缓冲 - 全身体动作token化 - 跨时标联合训练” 的三层技术体系,首次实现 3B 参数大模型与 30Hz 高频全身体控的兼顾,为复杂场景下的机器人操纵提供了全新解决方案。
论文题目:Astribot: Asynchronous Fast-Slow Vision-Language-Action Policies for Whole-Body Robotic Manipulation
论文链接:https://arxiv.org/pdf/2512.20188
核心亮点:真正异步快慢双路径、模态对齐桥接缓冲、全身体动作token化、端到端联合训练、3 倍于同类模型的推理速度
问题根源:大模型驱动机器人操纵的三大核心挑战
DuoCore-FS 的设计逻辑源于对现有 VLA 系统痛点的精准洞察,三大核心挑战构成技术突破的起点:
频率耦合瓶颈
传统 VLA 系统将 VLM 推理与动作生成绑定在同一频率,大模型(尤其是 3B 级以上)的低推理速度(通常<15Hz)直接限制了全身体控的响应频率,无法满足多关节、动态场景的实时需求。
全身体控表征难题
全身体操纵涉及 25+ 自由度(DoF)的关节协调,高维动作空间导致传统离散token化方案出现组合爆炸,难以实现紧凑且统一的动作表征。
异步训练推理错位
现有异步双系统架构多采用固定频率配比或级联设计,缺乏真正的并行执行机制,且端到端训练缺失导致高层语义推理与底层实时控制难以高效协同。
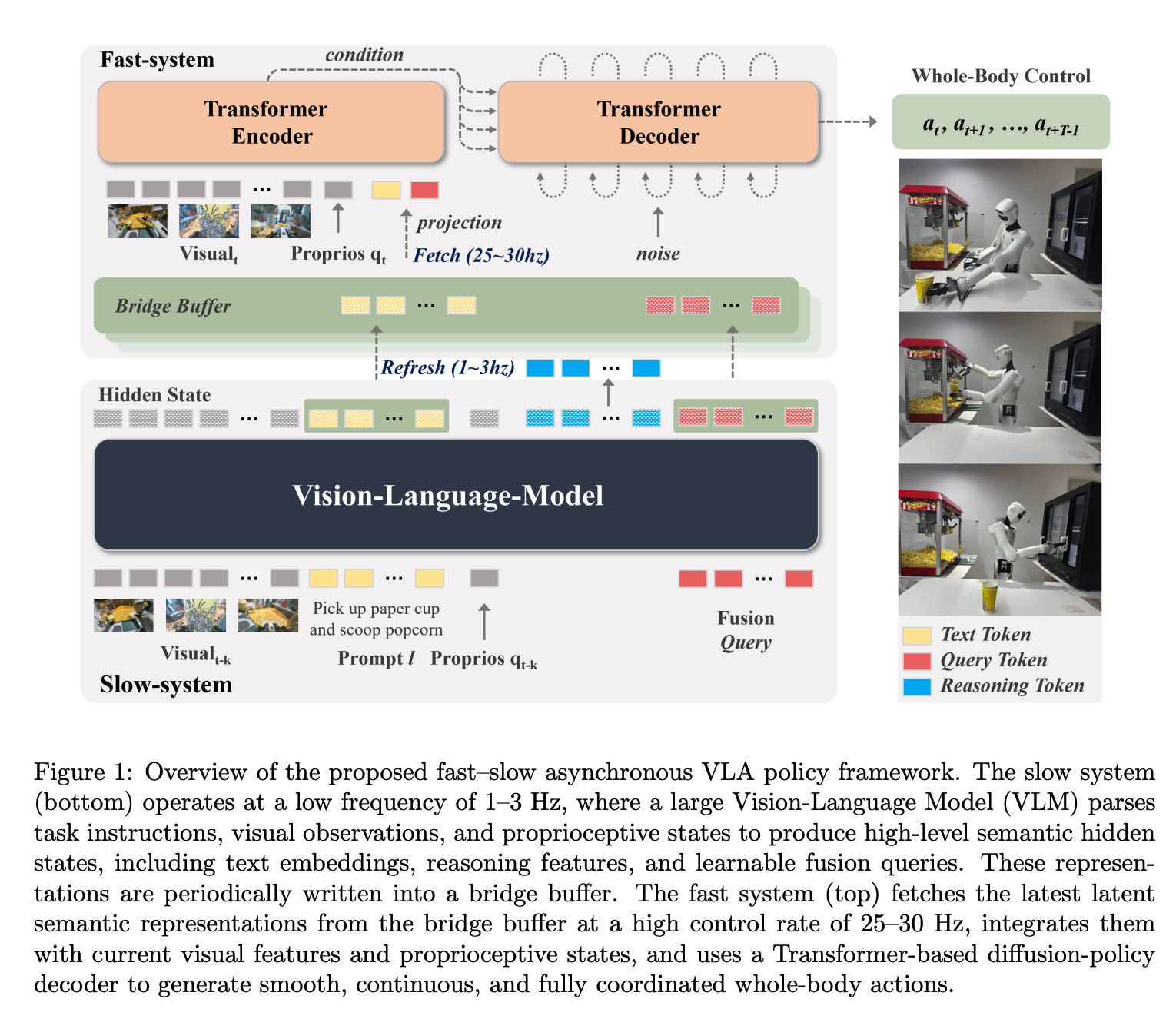
方案设计:DuoCore-FS 的三层技术闭环
针对上述挑战,DuoCore-FS 构建了 “快慢双路径 - 桥接缓冲 - token化 - 联合训练” 的完整技术闭环,层层递进实现大模型语义指导与高频全身体控的统一:
第一层:异步双路径架构——解耦推理与控制频率
创新设计真正并行的快慢双系统,实现语义推理与动作生成的频率解耦:
- 慢路径(1-3Hz):基于 3B 参数 VLM(如 PaliGemma-3B、Qwen2.5-VL-3B),处理视觉观测、本体感受与自然语言指令,生成语义隐藏态、推理特征与融合查询,提供高层任务意图指导;
- 快路径(25-30Hz):采用轻量级扩散策略网络,整合桥接缓冲的最新语义表征与实时感知数据,生成连续、协调的全身体动作块(action chunk),保障实时控制响应;
- 核心差异:区别于 FiS-VLA 的固定频率配比、Hume 的级联设计,DuoCore-FS 实现完全并行异步执行,快路径频率不受慢路径推理速度约束。
第二层:关键技术组件——支撑双路径高效协同
模态对齐桥接缓冲
作为快慢系统的交互接口,存储指令嵌入、融合查询等模态对齐表征,慢路径以 1-3Hz 刷新,快路径以 25-30Hz 读取,既传递高层语义指导,又避免频率耦合。缓冲同时保留原始指令表征与动态推理特征,防止关键任务信息丢失。
全身体动作token化
针对 25DoF 全身体动作空间,设计几何感知的 RVQ-VAE token化方案:
- 动作分解:将 29 维动作向量拆分为位置增量(pos)、姿态增量(rot)、夹爪开度(grip)三个语义组件;
- 多流token化:通过独立 1D 卷积编码器处理各组件,再经残差向量量化(RVQ)生成离散token,每个流维护 1024 规模码本;
- 损失设计:位置与夹爪分支采用 L2 重建损失,姿态分支采用 SO (3) 测地线距离损失,确保token化表征的几何一致性。
跨时标联合训练
分两阶段实现端到端优化,解决快慢系统频率差异导致的训练推理错位:

- 第一阶段:独立训练慢路径 VLM,优化语义推理与动作token预测,对齐视觉 - 语言 - 动作模态;
- 第二阶段:引入跨时标采样策略,模拟真实部署中的异步延迟(Δ~U [0, Δ m a x \Delta_{max} Δmax]),联合训练快慢路径,采用加权损失( λ s l o w \lambda_{slow} λslow=1, λ f a s t \lambda_{fast} λfast=10)强化快路径的精准控制能力。
第三层:异步推理流水线——保障实时部署性能
部署阶段采用全异步执行流程,进一步优化推理效率:
- 慢路径优化:采用 Jacobi 式并行解码策略,加速 VLM 推理,降低语义更新延迟;
- 快路径加速:通过 TensorRT 编译 BF16 精度模型,确保 25-30Hz 稳定输出;
- 缓冲容错机制:快路径优先使用缓冲中最新语义表征,即使慢路径未更新,仍可基于历史有效信息维持稳定控制。
验证逻辑:从定量指标到真实场景的全面性能验证
DuoCore-FS 在 Astribot S1 全身体机器人平台上,通过 “基准任务 - 泛化能力 - 异常场景 - ablation 分析” 的四级验证体系,充分证明其技术有效性:
核心性能突破
在爆米花舀取(长时程全身体任务)与饮料柜关门(短时程任务)中,DuoCore-FS 表现远超同类模型:


- 速度提升:推理频率达 32.3Hz,是 π₀ 模型(12.5Hz)的 2.6 倍,满足全身体控实时需求;
- 精度保持:整体成功率 90%,超越基线模型,且在细粒度动作(如勺子对齐、爆米花倾倒)中表现稳定;

- 泛化能力:分布外场景(杯子置于桌沿等未见过位置)中,整体成功率 50%,远超基线模型的 10%;

- 异常鲁棒性:杯子倾倒、倒置、被移走等场景中,检测与恢复成功率 95.8%,略高于基线的 91.7%。
关键能力验证

- 语言跟随:在相同视觉观测下,执行 “关门” 指令的成功率达 42.9%,是基线模型(14.3%)的 3 倍,证明慢路径语义推理的有效性;

- token化效率:RVQ-VAE token化方案的平均token长度仅 36,远短于 FAST token化的 81.12,推理频率提升 3.4 倍,且任务成功率达 83.3%(FAST 方案为 0%)。
局限与未来方向
DuoCore-FS 作为大模型驱动全身体控的突破性工作,仍存在可优化空间:
- 慢路径推理加速:未来可探索一致性解码等技术,进一步降低 VLM 推理延迟,提升语义更新频率;
- 快路径效率优化:减少扩散模型的流匹配步骤,探索单步生成方案,突破 30Hz 频率上限;
- 桥接机制升级:设计更精细的模态交互机制,强化快慢路径的语义对齐,提升复杂任务成功率;
- 多模态融合拓展:融入力触觉、听觉等信号,适配接触密集型任务,进一步提升真实场景鲁棒性;
- 任务覆盖扩展:需在更多动态场景、长时程任务中验证框架的通用性与稳定性。
总结:DuoCore-FS 的范式价值与行业影响
DuoCore-FS 的核心贡献不仅在于实现了 3B 级 VLM 与 30Hz 全身体控的兼顾,更在于建立了 “异步架构 - 模态对齐 - token化 - 联合训练” 的完整技术链路:通过真正并行的快慢双路径破解频率耦合瓶颈,通过 RVQ-VAE token化解决全身体控表征难题,通过跨时标训练消除异步执行的训练推理错位。其开源的训练、推理与部署方案已集成于 Astribot 机器人平台,为机器人学、计算机视觉、自然语言处理等领域提供了统一研究平台,推动大模型驱动的机器人操纵从实验室走向真实场景,加速通用自主机器人的产业化落地。
具身求职内推来啦
国内最大的具身智能全栈学习社区来啦!
推荐阅读
从零部署π0,π0.5!好用,高性价比!面向具身科研领域打造的轻量级机械臂
工业级真机教程+VLA算法实战(pi0/pi0.5/GR00T/世界模型等)
具身智能算法与落地平台来啦!国内首个面向科研及工业的全栈具身智能机械臂
VLA/VLA+触觉/VLA+RL/具身世界模型等!具身大脑+小脑算法与实战全栈路线来啦~
MuJoCo具身智能实战:从零基础到强化学习与Sim2Real
Diffusion Policy在具身智能领域是怎么应用的?为什么如此重要?
1v1 科研论文辅导来啦!

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 12
12 0
0- 0



 已为社区贡献43条内容
已为社区贡献43条内容

所有评论(0)