港理&清华等首个具身程序性综述:让机器人从第一人称视角学习步骤、纠错与问答
该文提出了一个第一人称视角程序性AI助手(EgoProceAssist)的概念,并划分三个核心技术任务:第一人称视角程序性错误检测、第一人称视角程序学习和第一人称视角程序问答。同时,提出一种新的分类体系,对现有方法进行了系统分类和整合,并对用于评估这三个主要任务的常用数据集和评估指标进行深入考察。此外,该文章设计了一种新的实验范式,评估了生成式人工智能助手在第一人称视角程序性错误检测和第一人称视角
本文分享一篇由香港理工,清华,华科,南洋理工联合公开在arXiv 2025的综述文章『Building Egocentric Procedural AI Assistant: Methods, Benchmarks, and Challenges』。
作者从构建一个在第一人称视角下辅助人们日常程序性活动的AI助手(EgoProceAssist)的设想出发,根据该助手需要具备的三大核心技术任务展开详细梳理分析。该文章首次系统性地总结了第一人称视角视觉中程序性相关任务的研究,填补了现有综述在第一人称视角视觉,程序性任务,AI Agent之间的空白。
提出了全新的分类法,归纳了第一人称视角程序性错误检测(Egocentric Procedural Error Detection), 第一人称视角程序学习(Egocentric Procedural Learning), 第一人称视角程序问答(Egocentric Procedural Question Answering)三大任务的现有关键技术,相关数据集与评估指标。并且设计补充实验验证了现有的主流VLM和Agent在辅助程序性任务上的不足,最后提出了相关领域面临的挑战和未来可行的研究方向,并建立了一个资源库实时更新相关工作。
· 论文链接:https://arxiv.org/pdf/2511.13261
· 仓库链接:https://github.com/z1oong/Building-Egocentric-Procedural-AI-Assistant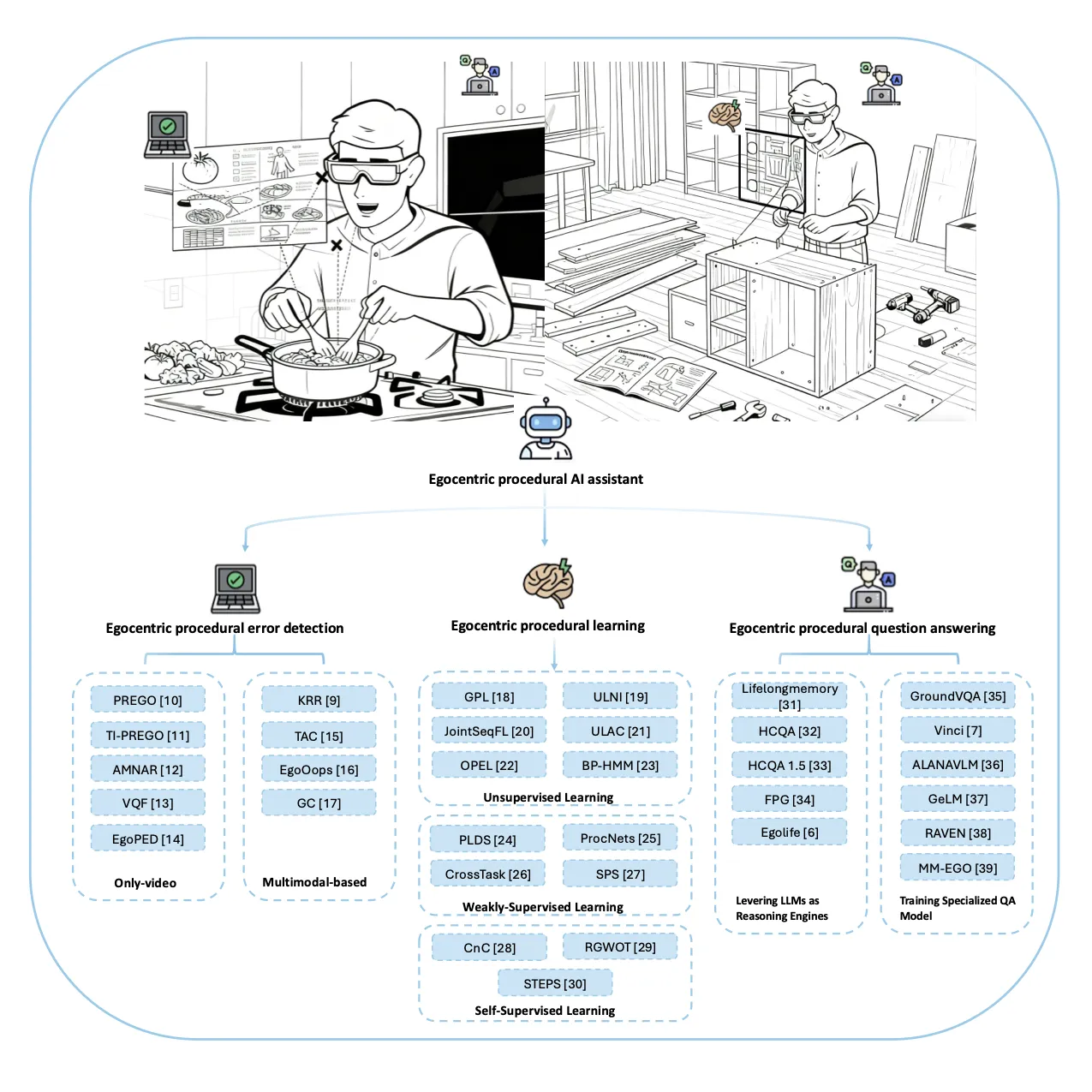
图1:归纳总结第一人称视角程序性错误检测,第一人称视角程序学习,第一人称视角程序问答三大核心技术任务。
动机
在我们的日常生活中,存在大量的程序性任务。程序性任务有着一定的步骤顺序约束,只有完成一系列关键步骤才能达到目的,例如在煮咖啡时,必须成功地“研磨咖啡豆”才能进行“冲煮”,在拼装家具时,大部分步骤都建立在正确完成上一步的前提下。从厨房烹饪,到工厂制造,甚至外科手术都属于程序性任务,一些任务具有危险性,出现程序性错误会带来严重的后果。
因此,随着具身智能,AI代理等技术不断发展,这篇文章提出构建一个通过可穿戴设备辅助人们进行日常程序性活动的AI助手(EgoProceAssist),它能为我们的日常生活带来极大的便利,并在危险性任务上为执行者保驾护航。此外,通过智能眼镜作为载体的AI助手,也能够改善视力受损人群的生活。
从这个角度出发,EgoProceAssist应该是一个能够实时检测程序性错误,自主学习关键步骤序列,并且回答任何相关问题的助手。通过它能够实现的基本功能,文章提出全新的分类法,划分上述三大核心技术任务,并根据这三个关键词,分别归纳了现有方法,相关数据集与评估指标。
据我们所知,这篇文章是首次对这三个方向进行系统性总结。此外,为了更加客观有力的展示现有VLM和Agent在辅助第一人称视角下程序性任务方面的局限,该文设计了补充实验,选用四个数据集,包含厨房烹饪,化学实验,积木拼装,电路实验,电脑装配等程序性任务场景,对他们在第一人称视角程序性错误检测和第一人称视角程序学习两个任务下的表现进行全面评估。通过实验结果发现,现有方法还无法直接用于辅助第一视角下的程序性任务,还存在很大的发展空间。最后,该文章总结了现有技术在构建EgoProceAssist时面临的挑战,并提出了可行的研究方向。
分类法
第一人称视角程序性错误检测(Egocentric Procedural Error Detection)
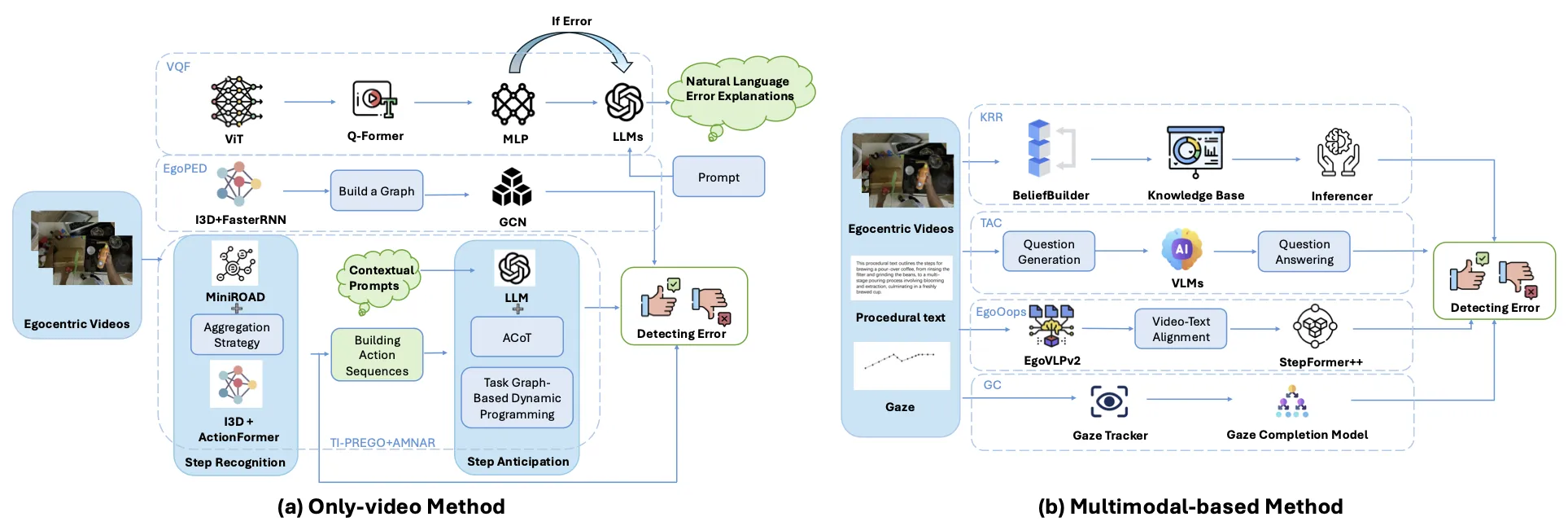
图2:对现有的Egocentric Procedural Error Detection方法进行归纳。通过输入数据的模态划分成只需要视频数据(Only-Video)方法和需要多模态数据(Multimodal-based)方法。
程序性错误不同于视频异常检测(Anomaly Detection),程序性错误检测服务于达成一个目的的特定步骤序列,步骤序列虽然不唯一但在一些关键步骤中存在特定的顺序约束,而视频异常检测专注在视频中的”异常情况“,类似有人摔倒了,有花瓶破碎了。例如在做一道菜的时候,交换了两个步骤的顺序可能并不会被视为异常情况,并且两个步骤也分别正确执行了,但错误的顺序导致它成为了一个程序性错误。
如图2所示,文章根据输入数据的模态对现有方法进行了合理划分。一些方法仅仅只需要输入视频,就可以进行错误检测任务,这些方法对数据的要求低,更加高效。一些方法整合了例如程序文本,视频,视线轨迹等数据,更好的利用了第一人称视角视觉的特性。
为了更直观地比较不同方法之间的性能表现,文章整理了这些方法在各个指标下的表现。同时选取第一人称视角程序性错误检测任务相关的12个数据集和重要的评估指标进行了比较,并且对他们的数据量,涵盖的场景进行了深入调查,具体内容可以在论文中查看。
第一人称视角程序学习(Egocentric Procedural Learning)
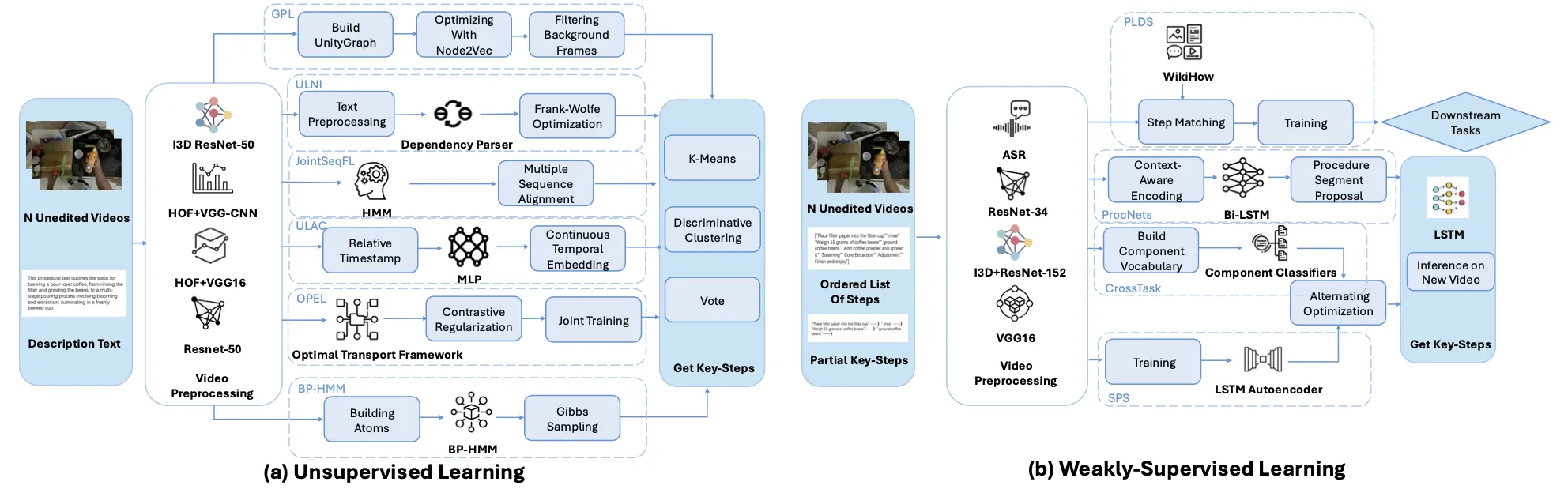
图3:该图对现有的重要程序学习方法进行了总结归纳。通过监督水平划分为无监督,弱监督和自监督三大类别。图中展示的是无监督和弱监督方法。
在进行一项程序性任务时,并非所有动作都会影响达到最终目标,程序学习的目的是,识别出对实现目标真正重要的关键步骤序列,过滤掉无关和冗余的动作。自主识别关键步骤序列十分重要,能够帮助模型更有效进行程序性错误识别,程序性问答,甚至帮助人们规划未来计划。以往的程序学习工作受限于数据集等原因,大多集中在处理第三人称视角视频,这篇文章主要介绍了重要的程序学习工作,其中不少都涉及到对第一人称视角视频数据的处理。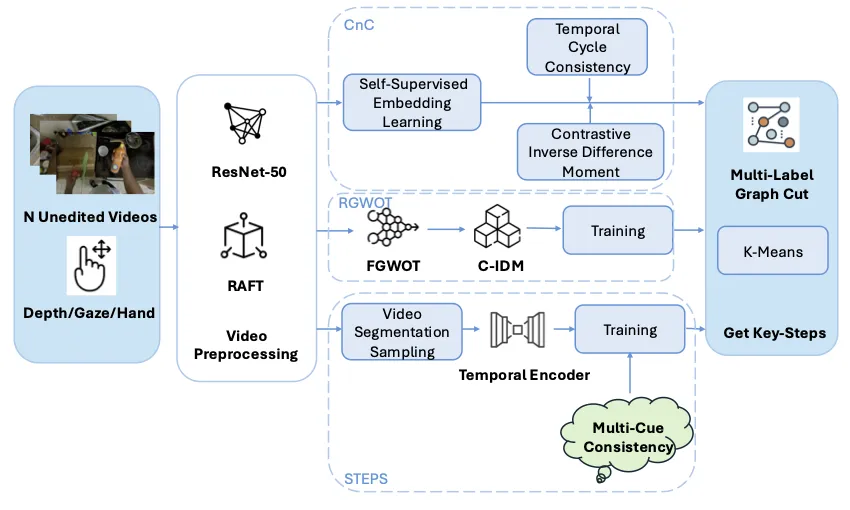
图4:该图总结了自监督水平下的程序学习方法。
主流的方法都依赖于不同级别的标注,在这篇文章中,按照监督水平进行了划分,如图3,图4所示。无监督方法无需人工标注,直接利用原始数据,适合标注数据稀缺的场景,与监督方法不同,它避免了标签引入的偏差并挖掘了数据中的潜在信息。弱监督方法使用有限的标注信息(例如,视频级标签),通过较低的标注成本获得了更好的准确性,并且能够避免自监督方法中常见的代理任务限制和伪标签错误。自监督方法通过创建辅助任务,从未标记数据中生成监督信号。作为无监督学习的一个子集,它减少了人工标注的工作量,并增强了大规模训练的泛化能力。
为了更好的比较不同方法之间的性能,文章也整理了各种方法在不同数据集下的各个指标数据。同时总结了程序学习会涉及到的8个相关数据集和重要评估指标,并且进行了数据量的归纳整理,具体内容可以在论文中查看。
第一人称视角程序问答(Egocentric Procedural Question Answering)
一个聪明的助手必须要能够回答使用者提出的问题,先前的视频问答方法,大多集中在处理第三人称视角的视频上。第一人称视角视频,相较于第三人称,含有更多的场景变换,会出现更多对物体或肢体的遮挡,并且无法捕捉完整的人体结构,直接将在第三人称视角数据上训练的方法运用在第一人称视角,会显著的降低模型性能。同时,在第一人称视角下,回答与程序性相关的问题例如,在拼装家具时问“我上一步做了什么?”“我下一步该做什么?”,需要模型在第一人称视角下具有强大的理解能力,长期记忆能力甚至推理能力。在这一部分中,该文章总结了现有的相关第一人称视角视频问答技术,其中涉及能够长时间记忆的方法Lifelongmemory等。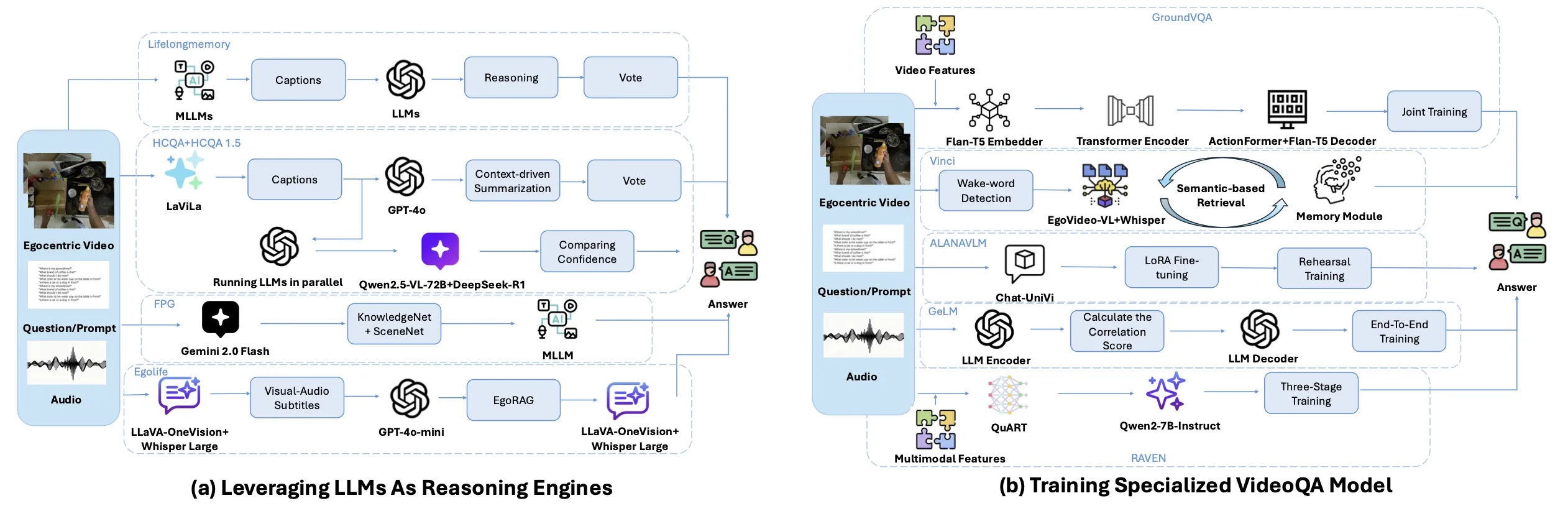
图5:该图对现有的第一人称视角视频问答技术进行了归纳总结。根据算法结构,分为以LLM为推理引擎和专门训练理解第一人称视角视频的模型两类。
现有的第一人称视角视频问答方法大致可以分为两类,一类使用LLM作为固定的推理引擎,一类训练专门处理第一人称视角视频的问答模型。如图5所示,该文章按照这两个类别,归纳总结了现有方法。以LLM作为推理引擎,不需要额外大规模训练单独的模型,更加高效,但在视频到文本的转换阶段,可能会存在一定的信息丢失,其准确性受到一定限制。专门训练理解第一人称视角视频数据的问答模型,虽然需要投入一定的训练成本,但在这种范式下,模型能够直接基于视频数据进行端到端训练,整合视觉语言特征,这种方法擅长捕捉细微的视觉差异和时空关系。
此外,还总结了一些专为第一人称视角视觉设计的AI agent,例如Vinci,它结合了EgoVideo和InternLM-7B,并在Ego4D,EgoExoLearn和Ego4D-Goalstep三个数据集上进行微调,能够有效理解第一人称视角视频,检索历史信息进行问答,并且还具有任务规划能力。结构上,它包含一个用于存储时间上下文的记忆模块,一个基于SEINE的视频生成模块用于教学演示,以及一个使用FAISS的检索系统,能够帮助Vinci在HowTo100M数据集中检索教学内容。
为了更好的展示方法性能之间的差异,文章对比了每个方法在不同的benchmark下的表现。同时,选取9个相关的数据集或是benchmark进行对比分析,并总结重要评估指标,更多具体信息可以在论文中查看。
补充实验
现有的VLMs在视频理解方面已经展示了不错的性能,也有许多专为理解第一人称视角的AI agent例如EgoGPT, Vinci等被提出,那么能否直接将强大的Vinci用于辅助人们的日常程序性活动呢?
这篇文章的观点认为,不能。为了给这一观点提供有力的支撑,该文章设计了补充实验,选取几个主流的VLMs和专为第一人称视角视觉设计的AI agent进行在第一人称视角下的程序性错误检测任务和程序学习任务,展示他们对于程序性任务理解的不足。
图6:在补充实验中,选取的四个第一人称视角视频数据集,分别是CaptainCook4D,EgoPER,EgoOops和EgoProceL。
第一人称视角程序性错误检测实验
在该实验中,选取三个第一人称视角视频数据集(如图6),包含厨房烹饪,搭积木等多个场景,选取VLM和agent一一进行程序性错误检测活动,并且计算Precison,EDA,Accuracy等多个通用指标。其中,比较重要的是EDA和Precision。EDA展示了模型在程序性错误检测中总体的判断准确率,Precision展示了模型对于错误的识别精确度。Precision越高,说明模型对于错误的理解越强。从图7中可以看到,现有的VLM与agent还无法很好的识别程序性错误。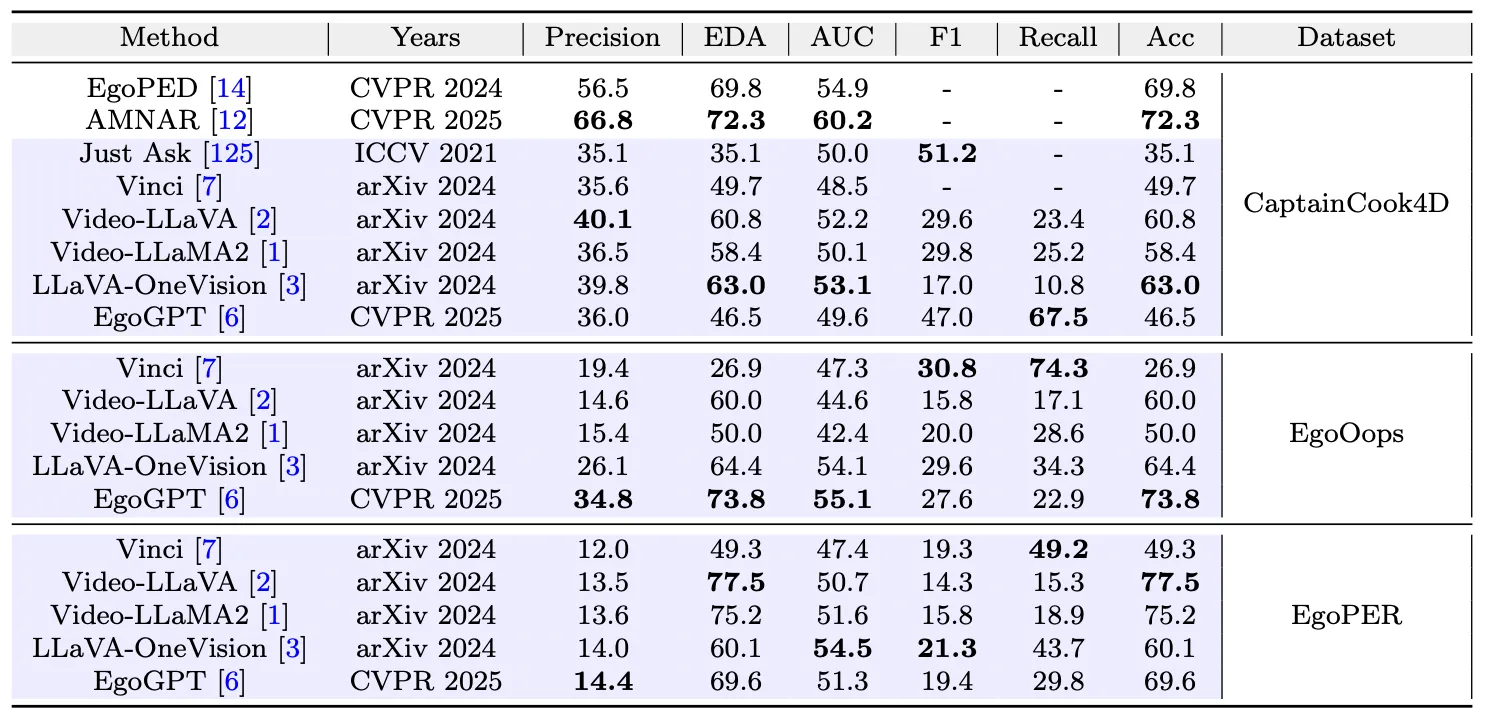
图7:在程序性错误检测任务上的性能,其中,紫色高亮部分是该文的补充实验,白色部分是传统方法。加粗部分是在各个指标上的最优结果。
第一人称视角程序学习实验
在该实验中,选取EgoProceL数据集,对电脑装配和电脑拆卸任务进行程序学习,使用匈牙利算法对程序学习得到的结果进行映射,提高准确性,最后计算F1分数,IoU指标。F1分数,衡量模型在关键步骤识别上的准确性和完整性,IoU,衡量模型对关键步骤时间定位的准确性。通过图8的结果可以看到,现有方法在程序学习任务上,仍然存在很大的发展空间。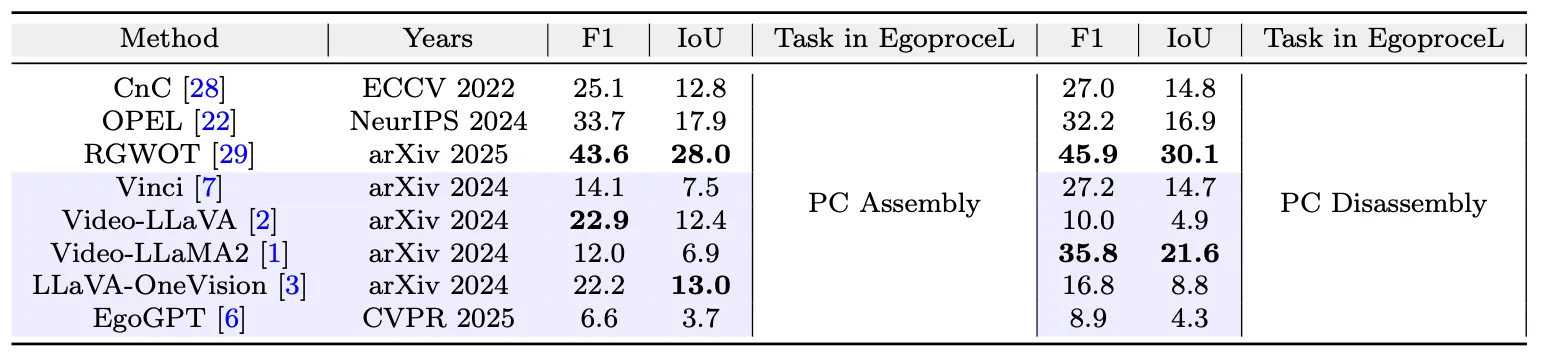
图8:在程序学习任务上的性能,其中,紫色高亮部分是该文的补充实验,白色部分是传统方法。加粗部分是在各个指标上的最优结果。
更多的实验细节与分析,可以在论文中查看。
挑战
- 数据稀缺
现有的第一人称视角视频数据集稀缺,并且场景单一缺乏多样性。与程序性任务相关的标注较少,同时许多数据缺乏细粒度的动作标注。许多程序学习的数据来自第三人称视角,无法很好的满足第一人称视角的训练与测试需求,大多数可用于错误检测的数据集也仅涵盖狭窄的活动场景。
- 对长期程序性活动的理解有限
现有模型难以捕捉程序性活动中的逻辑和时间依赖关系,无法区分真正的程序性错误或提供解释。它们在计算效率、语义理解和多模态信号的有效整合方面面临诸多困难,这阻碍了对视频的全面解读。现有方法在进行例如错误检测任务时,仅依赖于模型对程序步骤的基础理解。未来的研究应优先考虑将先进的长视频理解框架应用于第一人称视角场景。
- 严重依赖人工标注,缺乏实时性
一个AI助手要能够有效的辅助人们的生活,必须能够提供实时帮助。对人工标注的依赖限制了真实世界环境下的实用性,限制了实时检测能力,也限制了应用范围。目前,很少有方法能够在实时在线环境中有效运行。让AI助手能够提供实时的帮助仍然是一个关键挑战,合理的结合动作预测,未来规划等技术也许是一个可行的办法。
总结
该文提出了一个第一人称视角程序性AI助手(EgoProceAssist)的概念,并划分三个核心技术任务:第一人称视角程序性错误检测、第一人称视角程序学习和第一人称视角程序问答。同时,提出一种新的分类体系,对现有方法进行了系统分类和整合,并对用于评估这三个主要任务的常用数据集和评估指标进行深入考察。
此外,该文章设计了一种新的实验范式,评估了生成式人工智能助手在第一人称视角程序性错误检测和第一人称视角程序学习任务上的性能。实验结果表明,现有的人工智能助手尚不足以直接支持程序性任务辅助。最后,该研究阐述了第一人称视角的视觉研究中持续存在的挑战和固有的局限性,尤其侧重于智能体的构建,并阐明了可能对该领域后续发展产生重大影响的未来方向。我们希望这项工作能够为该领域的进一步研究提供参考和启发。
具身求职内推来啦
国内最大的具身智能全栈学习社区来啦!
推荐阅读
从零部署π0,π0.5!好用,高性价比!面向具身科研领域打造的轻量级机械臂
工业级真机教程+VLA算法实战(pi0/pi0.5/GR00T/世界模型等)
具身智能算法与落地平台来啦!国内首个面向科研及工业的全栈具身智能机械臂
VLA/VLA+触觉/VLA+RL/具身世界模型等!具身大脑+小脑算法与实战全栈路线来啦~
MuJoCo具身智能实战:从零基础到强化学习与Sim2Real
Diffusion Policy在具身智能领域是怎么应用的?为什么如此重要?
1v1 科研论文辅导来啦!

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 28
28 0
0- 0



 已为社区贡献106条内容
已为社区贡献106条内容

所有评论(0)