上交&ai lab团队联合提出MM-ACT:一个统一的VLA模型实现感知-规划-执行的高效协同
MM-ACT 通过 “统一多模态token空间 + 差异化并行解码 + 上下文共享学习” 的创新设计,打破了现有 VLA 模型 “语义理解与动态建模割裂、生成效率与精度失衡” 的僵局。它没有局限于单一模态的优化,而是构建了 “感知 - 规划 - 执行” 的全链路协同框架,在模拟与真实场景中均展现出强大的通用性与实用性。对于工业分拣、家庭服务等规模化落地场景,这种兼顾高效性与泛化能力的方案,为通用型
在机器人操作领域,“通用性” 与 “高效性” 的平衡始终是核心挑战——现有方案要么缺乏动态建模能力,难以应对复杂环境交互;要么推理速度慢,无法满足实时控制需求。
上海 AI 实验室、上海交通大学等团队联合提出的MM-ACT,以 “统一多模态表征 + 并行解码架构” 为核心,创新引入 “上下文共享多模态学习” 范式,实现了文本、图像、动作的协同生成,既具备精准的语义理解与环境预测能力,又能高效输出执行动作,在模拟与真实场景中均展现出超越现有方案的综合性能。
- MM-ACT 官方项目页:https://github.com/HHYHRHY/MM-ACT
- 论文链接:https://arxiv.org/abs/2512.00975
为什么需要重构视觉 - 语言 - 动作(VLA)模型架构?
当前 VLA 模型陷入 “三重矛盾”:语义理解与动态建模难以兼顾、多模态生成效率低下、训练目标存在错位,核心问题可归结为 “无法在统一框架内实现‘感知 - 规划 - 执行’的高效协同”:
| 方案类型 | 代表思路 | 核心缺陷 |
|---|---|---|
| VLM 衍生模型 | 基于预训练视觉 - 语言模型添加动作头 | 1. 缺乏物理动态建模能力,时序动作生成精度低;2. 自回归解码速度慢,难以满足实时控制 |
| 视觉预测驱动模型 | 融入未来视觉预测的决策框架 | 1. 任务导向规划能力弱,指令理解不足;2. 专注预测目标,与动作执行协同性差 |
| 混合生成模型 | 文本自回归 + 图像 / 动作并行解码 | 1. 架构复杂,需适配多种注意力机制;2. 训练 pipeline 繁琐,模态间优化目标不一致 |
这些方案忽略了关键前提:机器人操作是 “语义理解 - 环境预测 - 动作执行” 的闭环过程,需要模型既能通过文本理解任务意图、通过图像预测环境变化,又能高效输出精准动作。
MM-ACT 的设计正是针对性解决这一问题:通过统一多模态表征空间消除架构割裂,通过差异化并行解码平衡效率与精度,通过上下文共享学习强化模态协同,最终实现 “三位一体” 的高效生成。
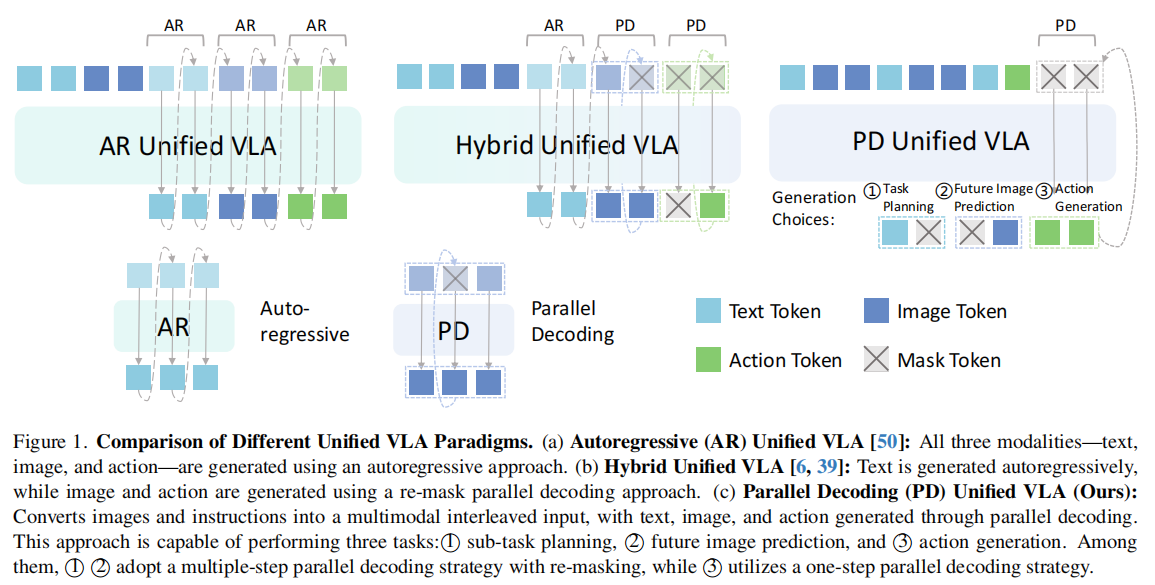
MM-ACT:如何实现多模态协同的机器人操作?
MM-ACT 的核心设计可概括为 “以统一token空间为基础,以并行解码为核心,以上下文共享学习为保障,实现文本规划、图像预测、动作生成的协同优化”。它既解决了多模态融合的架构复杂性问题,又提升了动作生成的效率与精度,具体分为三大核心模块:
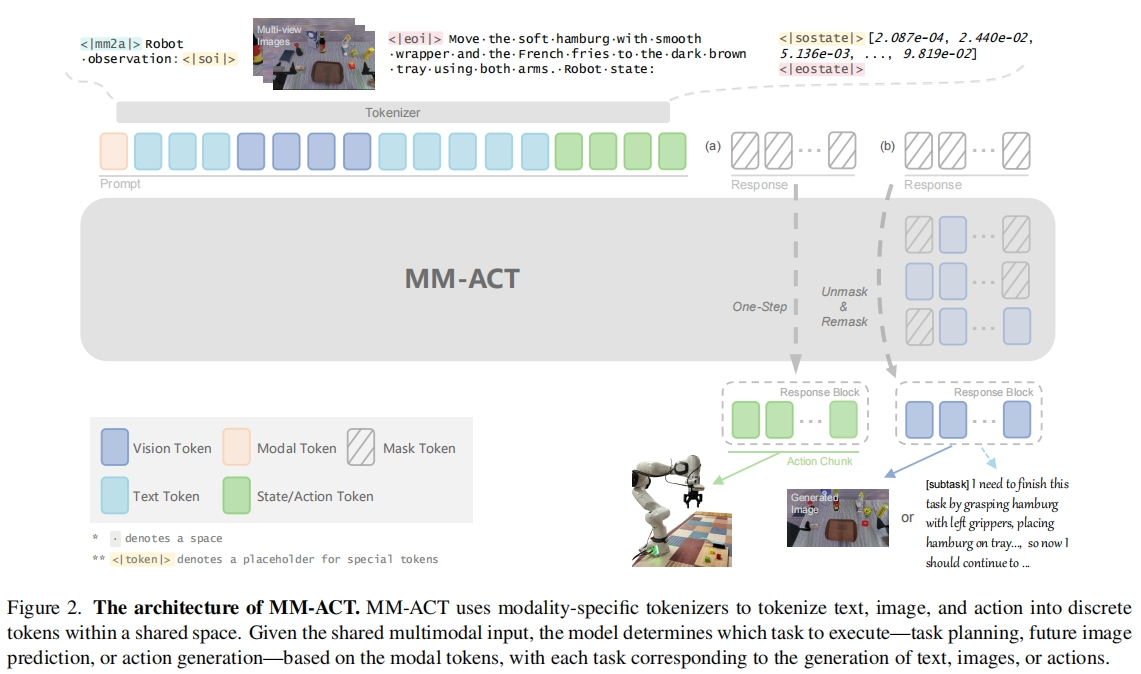
核心模块 1:统一多模态表征——打破模态壁垒
MM-ACT 通过模态专用tokenizer,将文本、图像、机器人状态与动作均编码为离散token,纳入同一表征空间,实现 “输入 - 处理 - 输出” 的端到端统一:
- 文本token化:采用 LLaDA 模型的tokenizer,直接处理任务指令、文本描述等语言输入;
- 图像token化:使用 Show-o 预训练图像量化器,将 256×256 图像编码为 256 个token(码本规模 8192),生成时通过解码还原图像;
- 动作 / 状态token化:采用 bin tokenizer,将连续动作与状态值归一化至 [-1,1] 后量化为 2048 个专用token,输出时反量化为连续控制值。
这种设计消除了不同模态的表征差异,为跨模态学习提供了基础,模型输入格式统一为 “模态标识 + 多模态交织上下文 + 掩码块”,其中模态标识<<|mm2a|>(动作生成)、<<|mmu|>(文本规划)、<<|t2i|>(图像预测)指定生成目标。
核心模块 2:差异化并行解码——平衡效率与精度
针对不同模态的生成特性,MM-ACT 设计了两种并行解码策略,既保证文本 / 图像生成质量,又满足动作实时性需求:
- 重掩码并行解码(文本 / 图像):采用离散扩散的迭代去噪思路,通过多步重掩码优化生成质量。文本生成限制在 256 token内,适配任务规划场景;图像生成保持 256 token输出,精准预测动作执行后的环境状态;
- 单步并行解码(动作):为满足机器人实时控制需求,动作生成采用 “全掩码单次预测” 策略,在一个前向传播中生成整个动作块(块大小 = 动作维度 × chunk 尺寸),推理延迟低至 0.22 秒,支持 40Hz 高频率动作输出。
两种策略均基于双向注意力机制,避免了自回归架构的串行依赖,大幅简化了模型结构与训练流程。
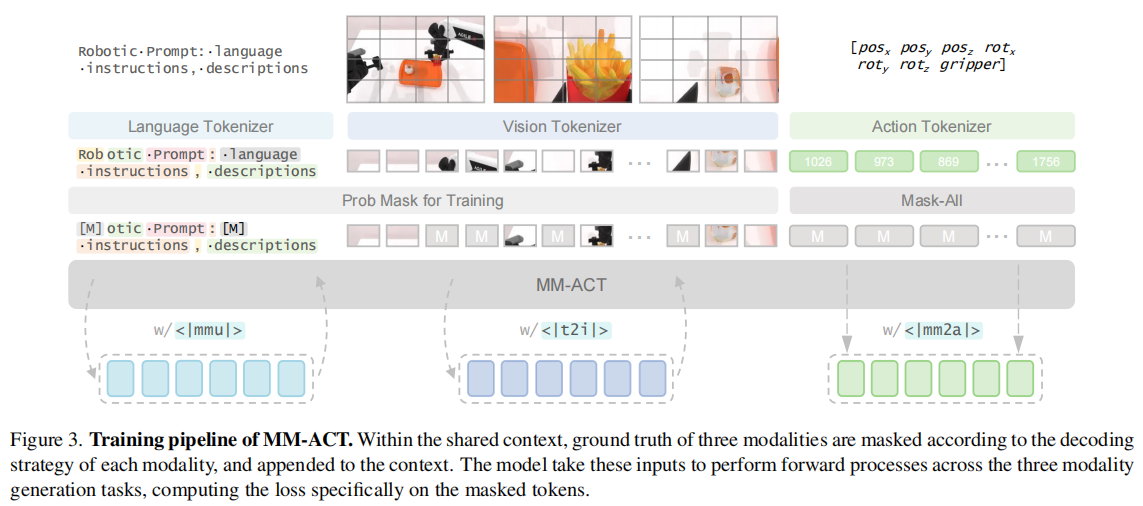
核心模块 3:上下文共享多模态学习——强化跨模态协同
创新提出 “上下文共享学习” 范式,在相同的机器人观测、任务指令等上下文下,同时监督文本规划、图像预测、动作生成三大任务,通过梯度共享实现模态间的正向迁移:
-
双阶段训练流程:
第一阶段:仅训练文本与图像生成,优化模态基础生成能力,直至损失收敛;
第二阶段:加入动作生成任务,通过损失权重调节(文本 / 图像权重 0.05-0.1,动作权重 1),在保持文本 / 图像生成质量的同时,利用跨模态信息提升动作生成精度;
-
统一优化目标:所有模态均采用掩码token预测的交叉熵损失,避免多目标优化的冲突,数学表达为:
L = λ m m 2 a L a c t + λ m m u L t e x t + λ t 2 i L i m g L = \lambda_{mm2a}L_{act} + \lambda_{mmu}L_{text} + \lambda_{t2i}L_{img} L=λmm2aLact+λmmuLtext+λt2iLimg
其中仅对掩码位置计算损失,确保训练聚焦生成目标。
实验结果:多场景验证通用能力与性能优势
MM-ACT 在模拟(LIBERO、RoboTwin2.0)与真实机器人(Franka)场景中进行了全面评估,核心结论可概括为 “精度高、泛化强、效率优”:
核心性能:刷新多数据集基准

如表 1 所示,MM-ACT 平均成功率 96.3%,超越 UniVLA(95.5%)、DreamVLA(92.6%)等所有基线,Libero-Long 长序列任务成功率提升 5.0%。在 LIBERO 的四个子基准中均表现优异,尤其是在长序列任务中,文本 - 动作联合训练带来显著提升。
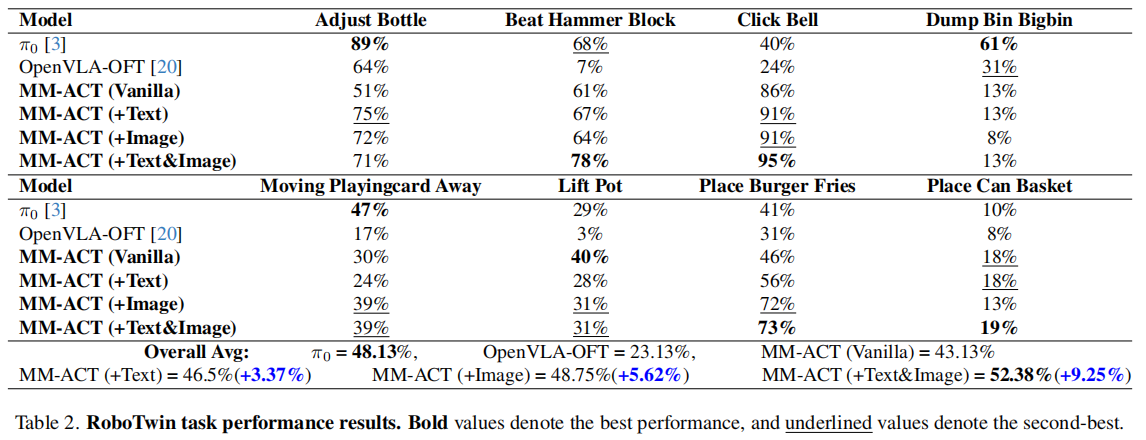
如表 2 所示,在 RoboTwin2.0 的 8 个跨域任务中,平均成功率 52.38%,较单动作训练提升 9.25%,超越 π 0 \pi_0 π0(48.13%)和 OpenVLA-OFT(23.13%),三模态联合训练的优势更为突出。

如表 3 所示,3 个实物操作任务(按按钮、堆叠积木、分拣果蔬)平均成功率 72.0%,优于 π 0 \pi_0 π0(70.0%)和 OpenVLA-OFT(58.6%)。真实机器人实验进一步验证了模型的落地能力,在物理交互场景中保持领先性能。
关键分析:跨模态学习的价值
通过消融实验验证多模态协同的核心作用:
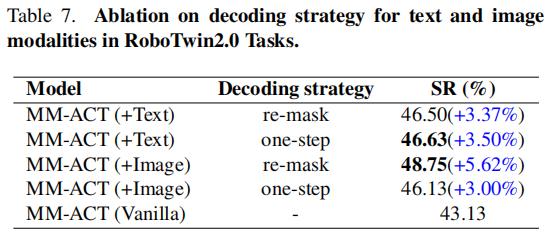

- 文本 - 动作联合训练:动作生成成功率提升 3.37%,证明任务规划文本能引导动作序列优化;
- 图像 - 动作联合训练:成功率提升 5.62%,说明未来图像预测为动作执行提供了环境约束;
- 文本 - 图像 - 动作三模态联合:验证跨模态信息的互补性,实现 1+1+1>3 的效果。

解码策略与效率权衡

综合机器人实时性需求,最终选择 “单步并行解码 + 动作块大小 8” 的配置,平衡效率与精度。
RoboTwin2.0 场景表现与关键支撑
RoboTwin2.0 聚焦双臂机器人复杂操作,包含 8 项核心任务,覆盖双臂协同、精细操作、动态交互等多元场景,且所有任务均加入场景随机化(外观、光照、物体位置随机变化),严格测试模型跨域适应能力。
关键任务示例:
- Place Burger Fries(双臂协同放置):需双手分别抓取汉堡与薯条,精准放置到托盘,考验双臂空间协调能力;
- Click Bell(精细操作):需精准点击铃铛顶部中心,对动作精度要求极高;
- Dump Bin Bigbin(动态交互):抓取小桶并将内部小球倒入大桶,涉及物体姿态变化与动态轨迹规划。

MM-ACT 通过自动化文本标注生成结构化任务规划,为双臂操作提供清晰引导,生成文本与真值逻辑高度一致。
核心优势:
- 标注自动化:基于技能函数调用序列,自动生成 “指令 + 规划 + 历史进度 + 当前子任务” 的文本,无需人工干预,构建约 70k 训练样本;
- 逻辑连贯性强:从图 11 示例可见,无论是 “Adjust Bottle”(直立瓶子)还是 “Beat Block Hammer”(锤击方块)任务,模型生成的规划文本均能准确衔接历史操作与当前目标,明确双臂分工与下一步动作;
- 协同引导有效:在 “Place Burger Fries” 任务中,文本规划明确 “左臂抓汉堡、右臂抓薯条” 的协同逻辑,直接提升动作执行的协调性,该任务成功率达 73%,远超基线模型。

关键结论与未来方向
核心结论
- 统一表征是基础:文本、图像、动作的离散token统一,消除了模态融合的架构壁垒,简化了训练流程;
- 并行解码显优势:差异化解码策略既保证了文本 / 图像的生成质量,又实现了动作的低延迟输出,适配机器人实时控制;
- 跨模态学习提精度:上下文共享的多模态训练,使任务规划、环境预测与动作执行形成协同,大幅提升泛化能力。
未来方向
- 模态扩展:融入触觉、力反馈等模态,提升复杂操作的环境适应性;
- 长序列优化:针对更长动作序列,探索重掩码与单步解码的混合策略;
- 真实场景扩展:扩充更多真实世界数据集,进一步缩小模拟到真实的迁移差距。
总结
MM-ACT 通过 “统一多模态token空间 + 差异化并行解码 + 上下文共享学习” 的创新设计,打破了现有 VLA 模型 “语义理解与动态建模割裂、生成效率与精度失衡” 的僵局。它没有局限于单一模态的优化,而是构建了 “感知 - 规划 - 执行” 的全链路协同框架,在模拟与真实场景中均展现出强大的通用性与实用性。对于工业分拣、家庭服务等规模化落地场景,这种兼顾高效性与泛化能力的方案,为通用型机器人操作技术的产业化提供了重要参考。
具身求职内推来啦
国内最大的具身智能全栈学习社区来啦!
推荐阅读
从零部署π0,π0.5!好用,高性价比!面向具身科研领域打造的轻量级机械臂
工业级真机教程+VLA算法实战(pi0/pi0.5/GR00T/世界模型等)
具身智能算法与落地平台来啦!国内首个面向科研及工业的全栈具身智能机械臂
VLA/VLA+触觉/VLA+RL/具身世界模型等!具身大脑+小脑算法与实战全栈路线来啦~
MuJoCo具身智能实战:从零基础到强化学习与Sim2Real
Diffusion Policy在具身智能领域是怎么应用的?为什么如此重要?
1v1 科研论文辅导来啦!

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 21
21 0
0- 0



 已为社区贡献39条内容
已为社区贡献39条内容

所有评论(0)