在看完近50篇 VLA+RL 工作之后......
本文对该领域的关键论文进行了分类整理,涵盖离线RL、在线RL、世界模型、推理时RL及对齐技术。
·
主页:http://qingkeai.online/
原文:https://mp.weixin.qq.com/s/lfkwxQ-7N2jdVaOFAN5GmQ
随着基于大规模模仿学习的视觉-语言-动作 (VLA) 模型取得显著进展,将 VLA与强化学习 (RL)相结合已成为一种极具前景的新范式。该范式利用与环境的试错交互或预先采集的次优数据,进一步提升机器人的决策与执行能力。
本文对该领域的关键论文进行了分类整理,涵盖离线RL、在线RL、世界模型、推理时RL及对齐技术。
一、 离线强化学习 (Offline RL)
离线 RL 预训练的 VLA 模型利用人类演示和自主收集的数据进行学习,无需实时环境交互。
Q-Transformer: Scalable Offline Reinforcement Learning via Autoregressive Q-Functions
链接:https://arxiv.org/abs/2309.10150
代码:https://github.com/google-deepmind/q_transformer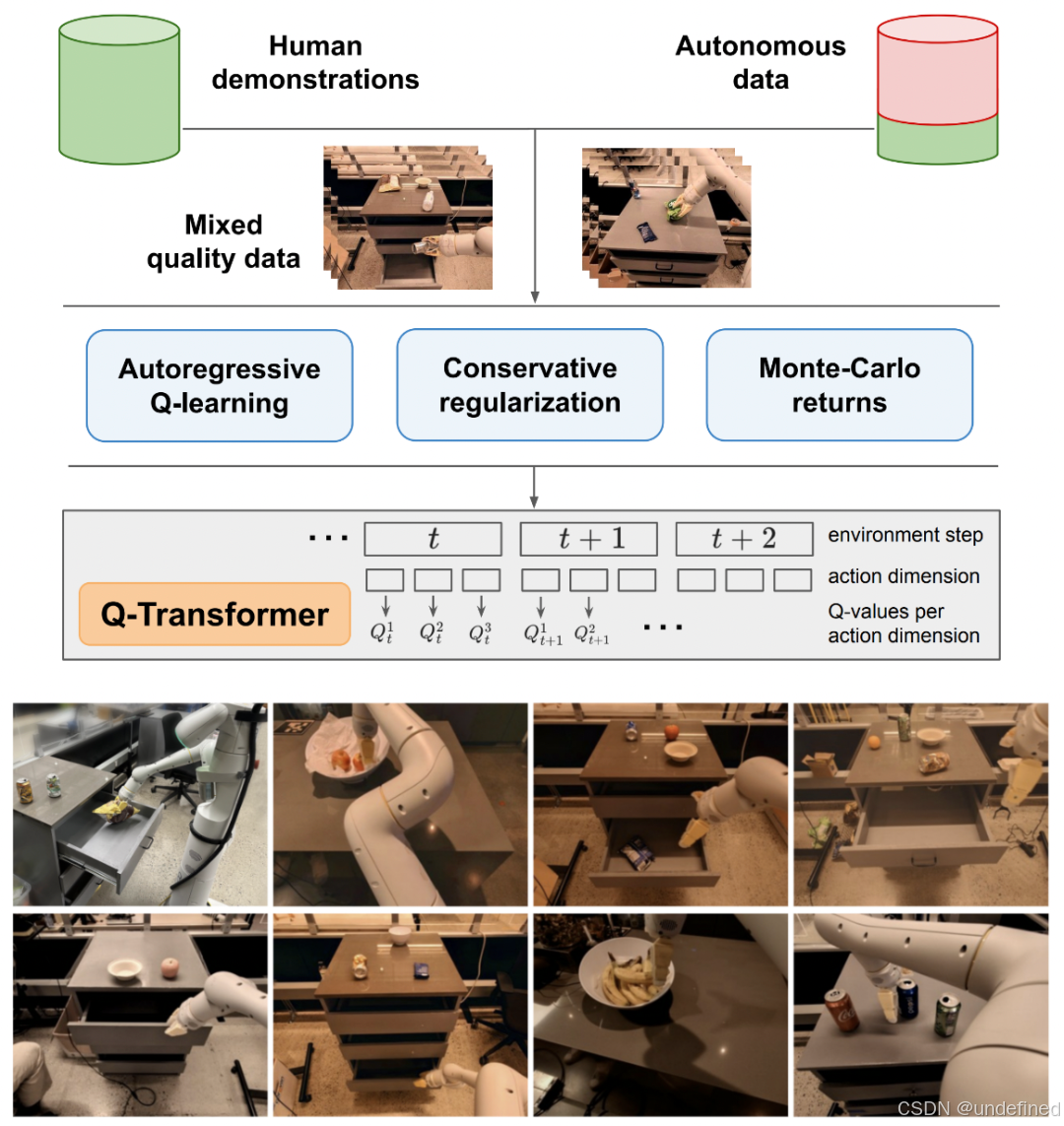
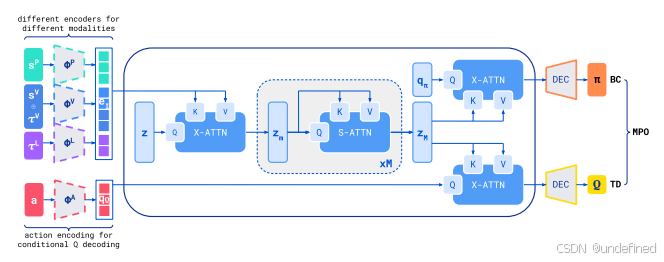
Offline Actor-Critic Reinforcement Learning Scales to Large Models (Perceiver-Actor-Critic)
链接:https://arxiv.org/abs/2402.05546
代码:https://offline-actor-critic.github.io/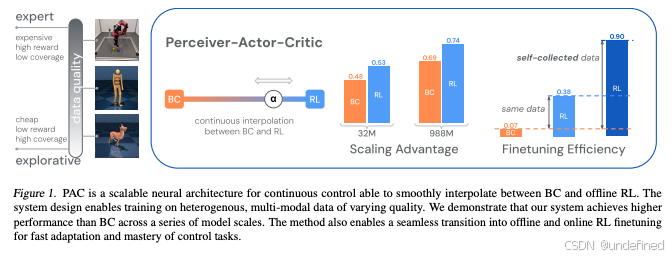
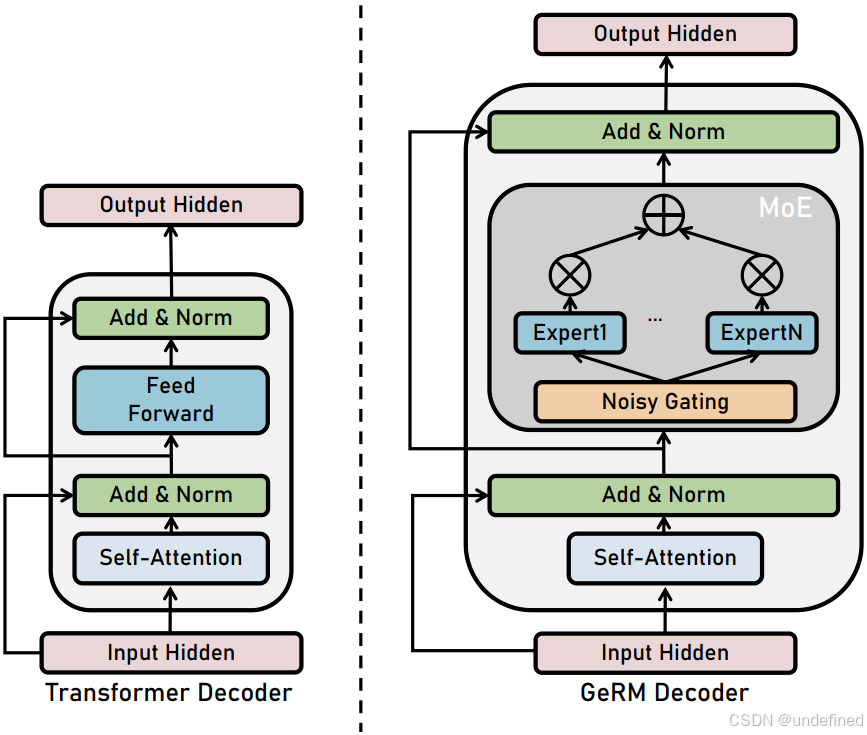
GeRM: A Generalist Robotic Model with Mixture-of-experts for Quadruped Robot
链接:https://arxiv.org/abs/2403.13358
代码:https://github.com/Improbable-AI/germ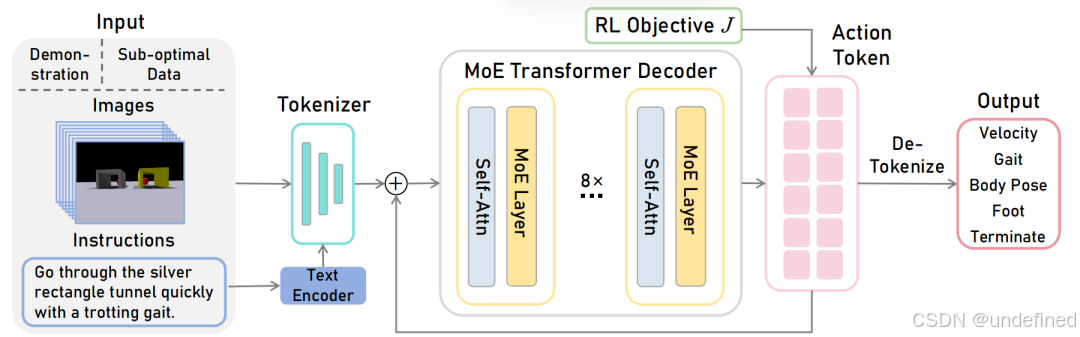
ReinboT: Amplifying Robot Visual-Language Manipulation with Reinforcement Learning
链接:https://arxiv.org/abs/2505.07395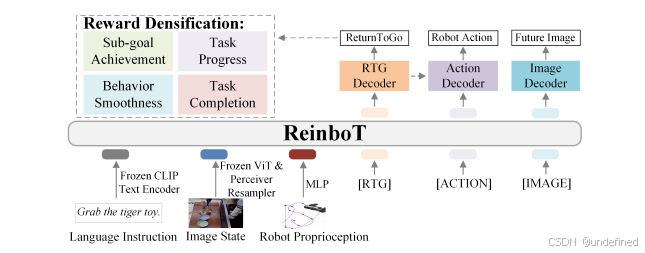
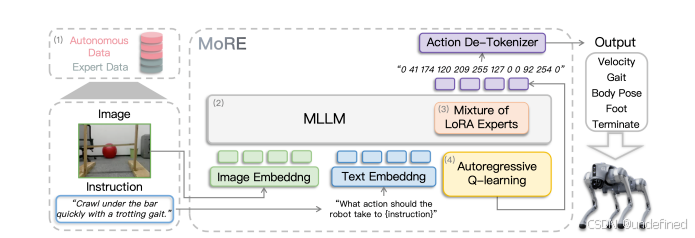
MoRE: Unlocking Scalability in Reinforcement Learning for Quadruped Vision-Language-Action Models
链接:https://arxiv.org/abs/2503.08007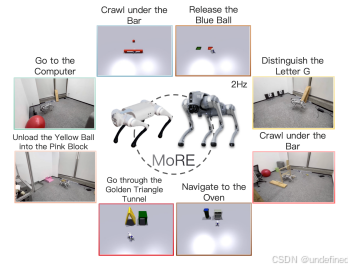
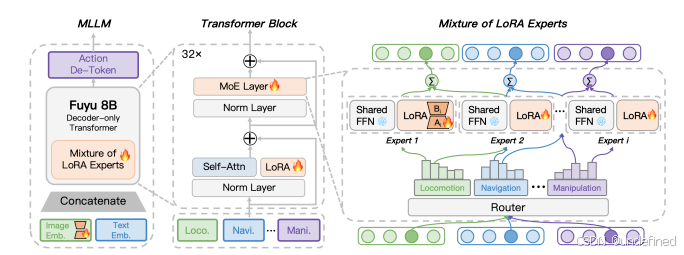
CO-RFT: Efficient Fine-Tuning of Vision-Language-Action Models through Chunked Offline Reinforcement Learning
链接:https://arxiv.org/pdf/2508.02219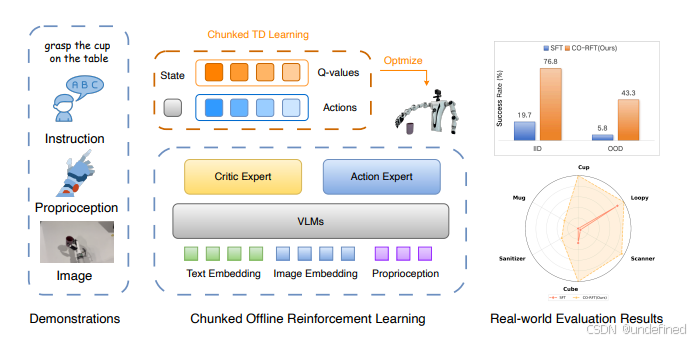
Balancing Signal and Variance: Adaptive Offline RL Post-Training for VLA Flow Models (ARFM)
链接:https://arxiv.org/pdf/2509.04063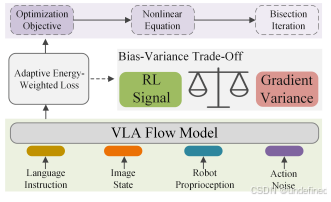
二、 在线强化学习 (Online RL)
通过在环境中的试错交互,进一步优化 VLA 模型的性能。
1. 仿真环境内 (In Simulator)
FLaRe: Achieving Masterful and Adaptive Robot Policies with Large-Scale Reinforcement Learning Fine-Tuning
链接:https://arxiv.org/abs/2409.16578
代码:https://github.com/flare-vla/flare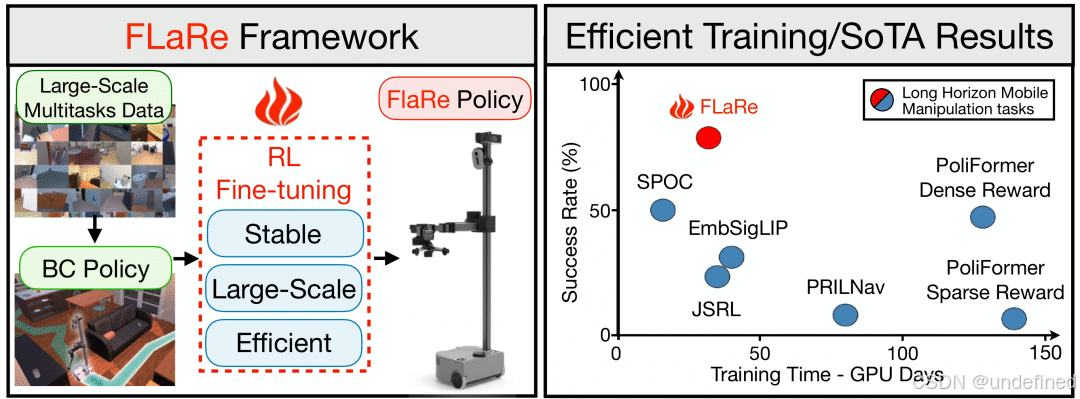
Policy Agnostic RL: Offline RL and Online RL Fine-Tuning of Any Class and Backbone (PA-RL)
链接:https://arxiv.org/abs/2412.06685
代码:https://pa-rl.github.io/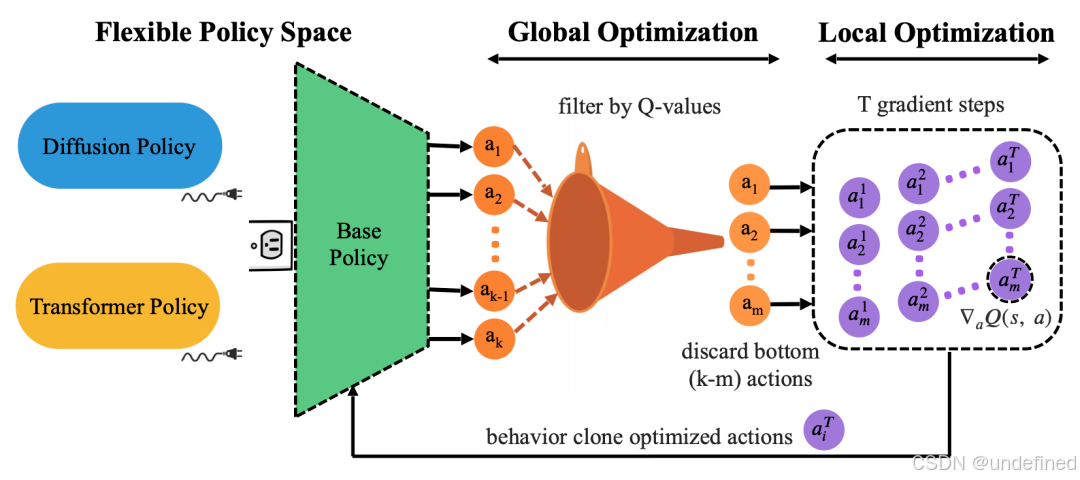
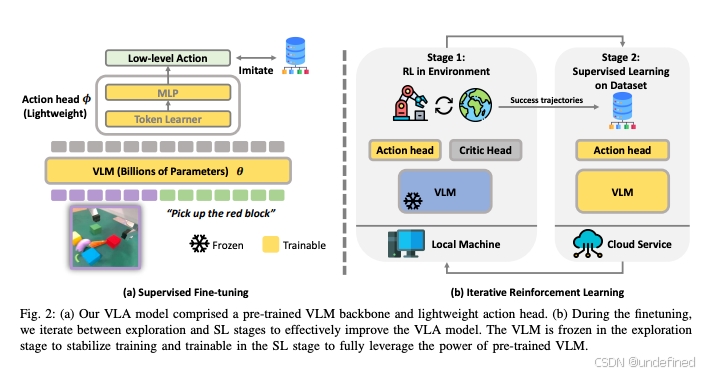
Improving Vision-Language-Action Model with Online Reinforcement Learning (iRe-VLA)
链接:https://arxiv.org/abs/2501.16664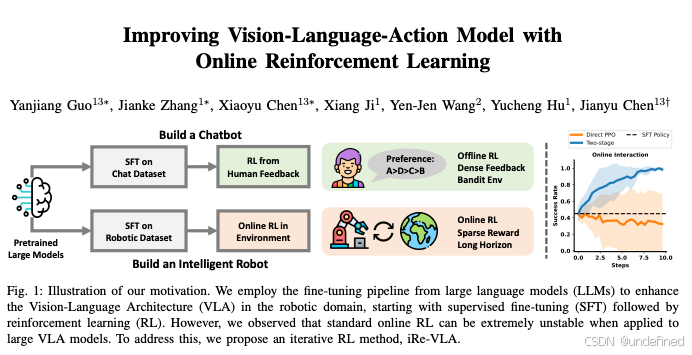
Interactive Post-Training for Vision-Language-Action Models (RIPT-VLA)
链接:https://arxiv.org/abs/2505.17016
代码:https://github.com/OpenHelix-Team/RIPT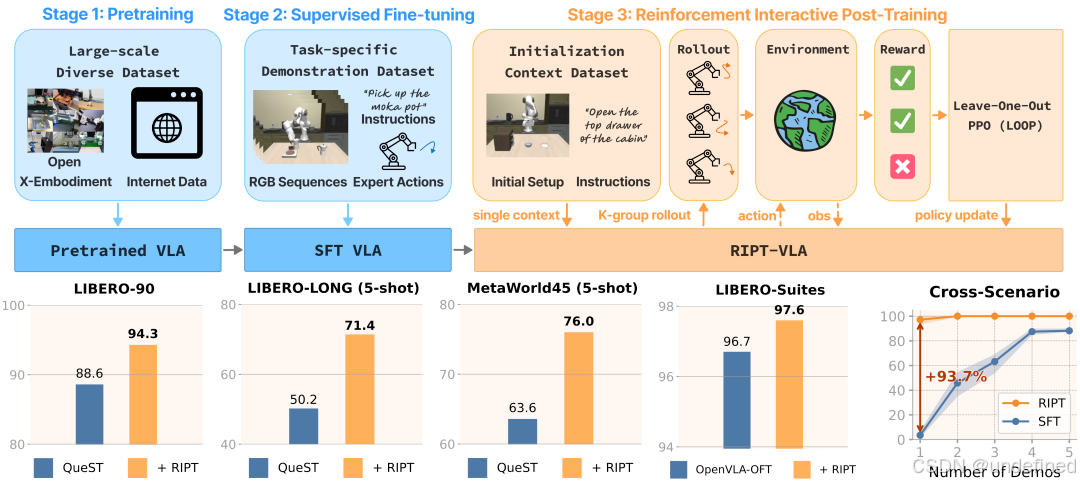
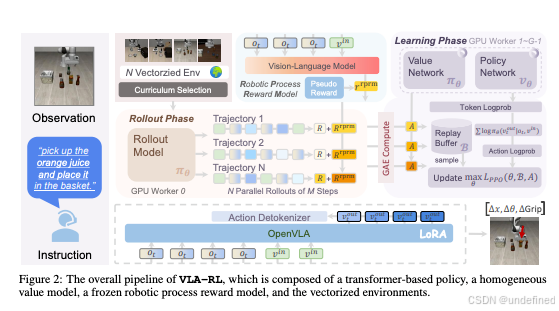
VLA-RL: Towards Masterful and General Robotic Manipulation with Scalable Reinforcement Learning
链接:https://arxiv.org/abs/2505.18719
代码:https://github.com/vla-rl/vla-rl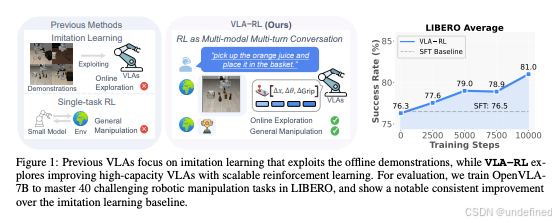
What Can RL Bring to VLA Generalization? An Empirical Study (RLVLA)
链接:https://arxiv.org/abs/2505.19789
代码:https://github.com/S-S-X/RLVLA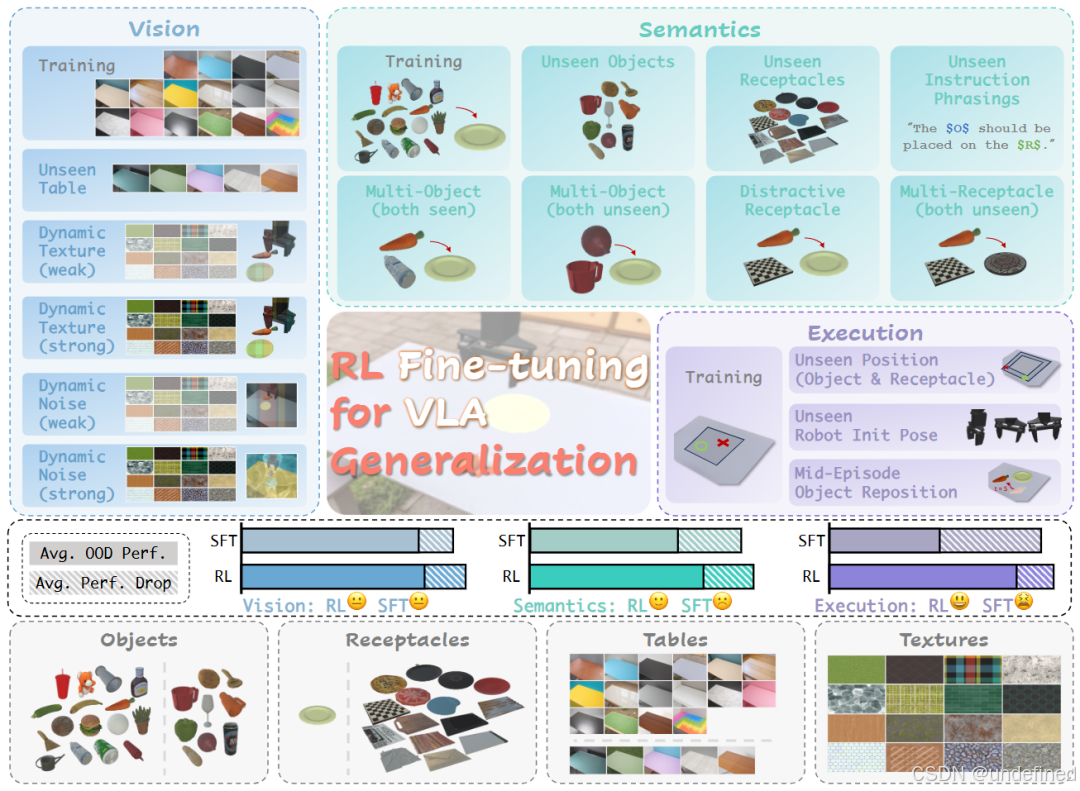
RFTF: Reinforcement Fine-tuning for Embodied Agents with Temporal Feedback
链接:https://arxiv.org/abs/2505.19767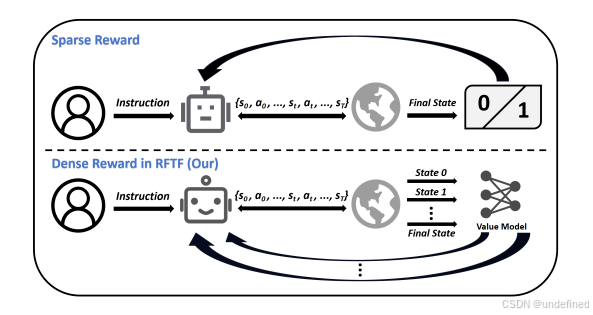
SimpleVLA-RL: Scaling VLA Training via Reinforcement Learning
周六上午10点!一起聊聊VLA强化学习训练框架:SimpleVLA-RL
链接:https://arxiv.org/pdf/2509.09674
代码:https://github.com/SimpleVLA/SimpleVLA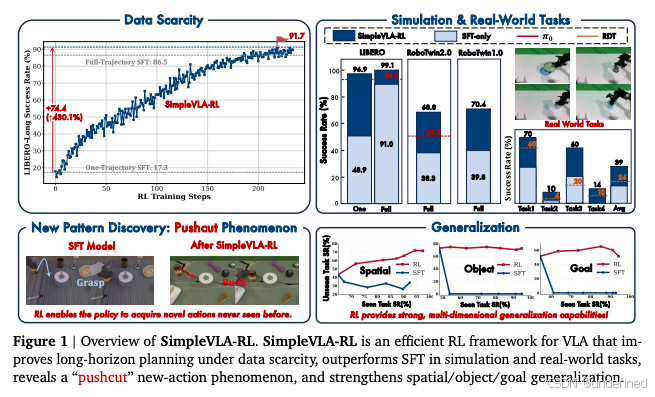
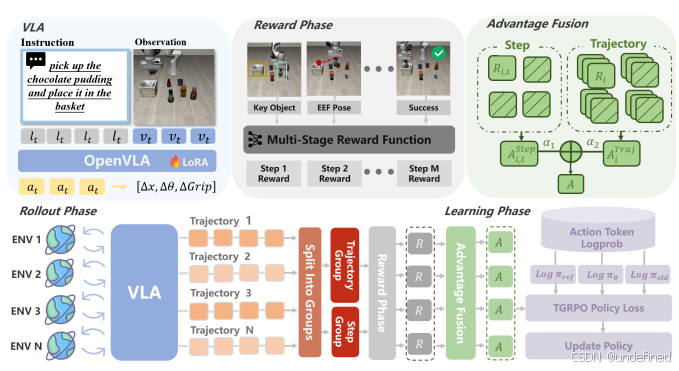
TGRPO: Fine-tuning Vision-Language-Action Model via Trajectory-wise Group Relative Policy Optimization
链接:https://arxiv.org/abs/2506.08440
代码:https://github.com/TGRPO/TGRPO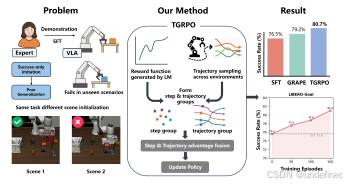
OctoNav: Towards Generalist Embodied Navigation
链接:https://arxiv.org/abs/2506.09839
代码:https://octonav.github.io/
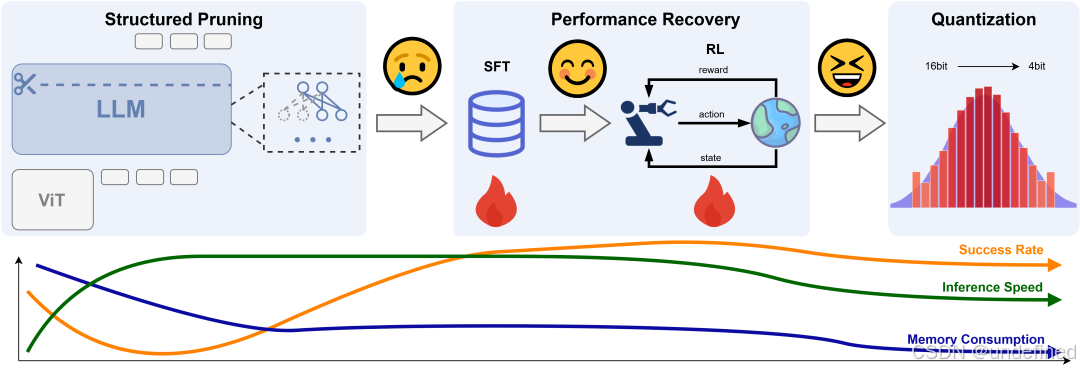
RLRC: Reinforcement Learning-based Recovery for Compressed Vision-Language-Action Models
链接:https://arxiv.org/pdf/2506.17639
代码:https://rlrc-vla.github.io/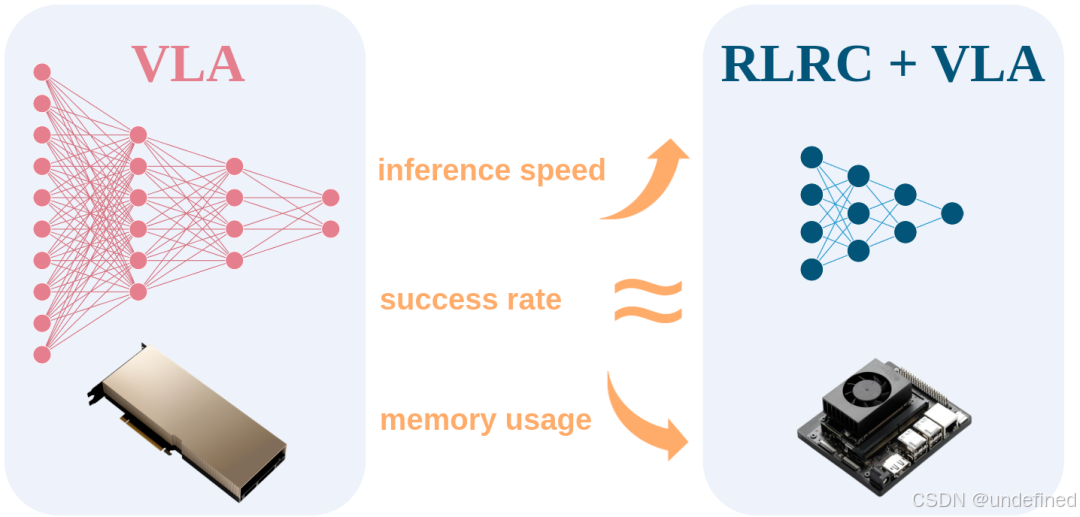
RLinf: Reinforcement Learning Infrastructure for Agentic AI
下周二晚8点!和无问芯穹首席研究员林灏,一起聊聊具身智能 RL 训练框架 RLinf 的系统设计
链接:https://arxiv.org/pdf/2509.15965
代码:https://rlinf.github.io/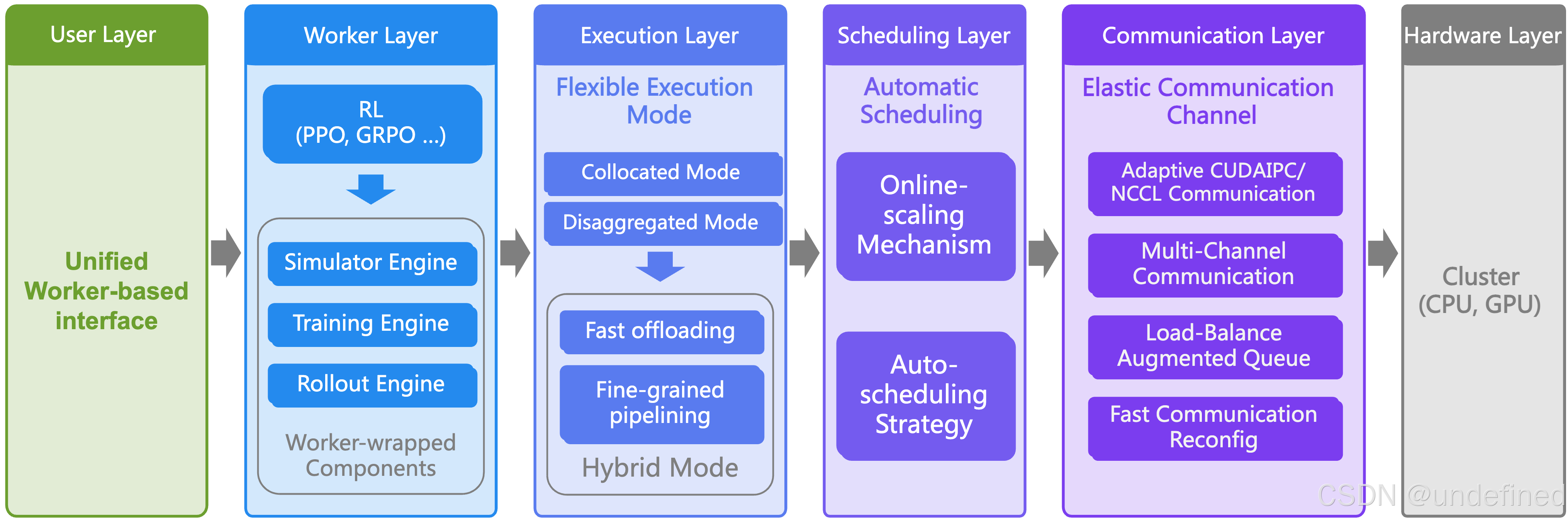
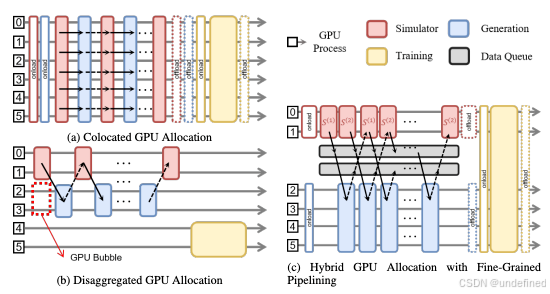
RLinf-VLA: A Unified and Efficient Framework for VLA+RL Training
VLA+RL 算法如何设计?从零上手 OpenVLA 的强化学习微调实践
链接:https://arxiv.org/pdf/2510.06710v1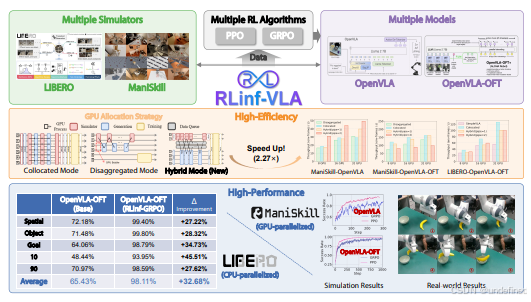
2. 真实世界 (In Real-World)
RLDG: Robotic Generalist Policy Distillation via Reinforcement Learning
链接:https://arxiv.org/abs/2412.09858
代码:https://rldg.github.io/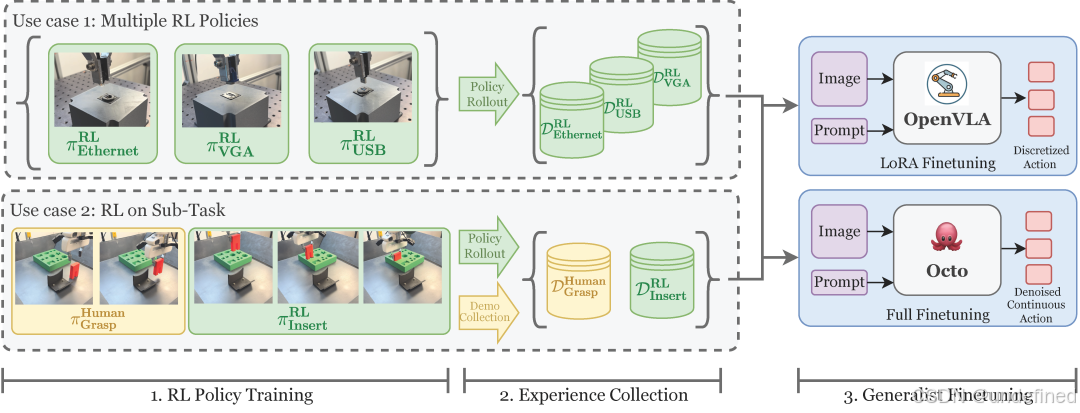
Policy Agnostic RL: Offline RL and Online RL Fine-Tuning of Any Class and Backbone
链接:https://arxiv.org/abs/2412.06685
代码:https://github.com/MaxSobolMark/PolicyAgnosticRL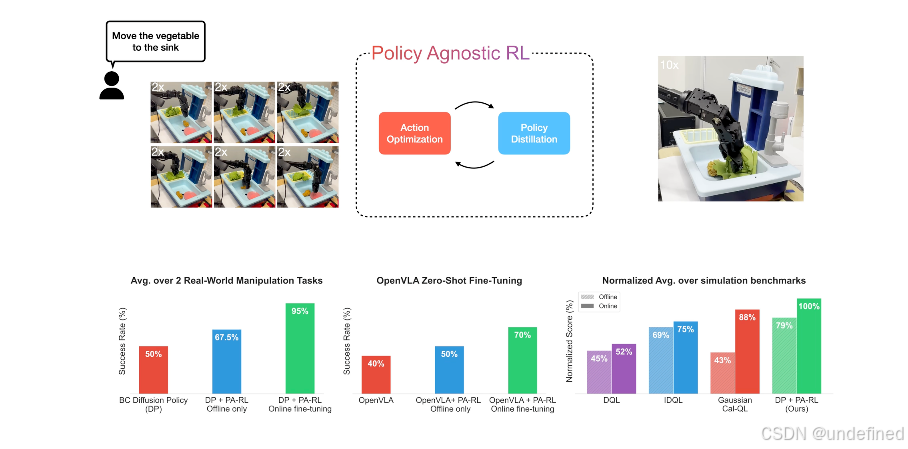
Improving Vision-Language-Action Model with Online Reinforcement Learning
链接:https://arxiv.org/abs/2501.16664
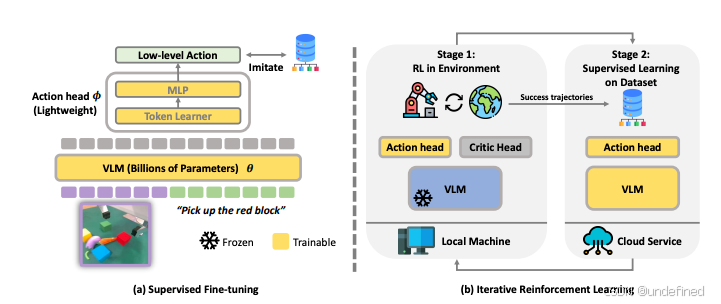
ConRFT: A Reinforced Fine-tuning Method for VLA Models via Consistency Policy
链接:https://arxiv.org/abs/2502.05450
代码:https://github.com/ConRFT/ConRFT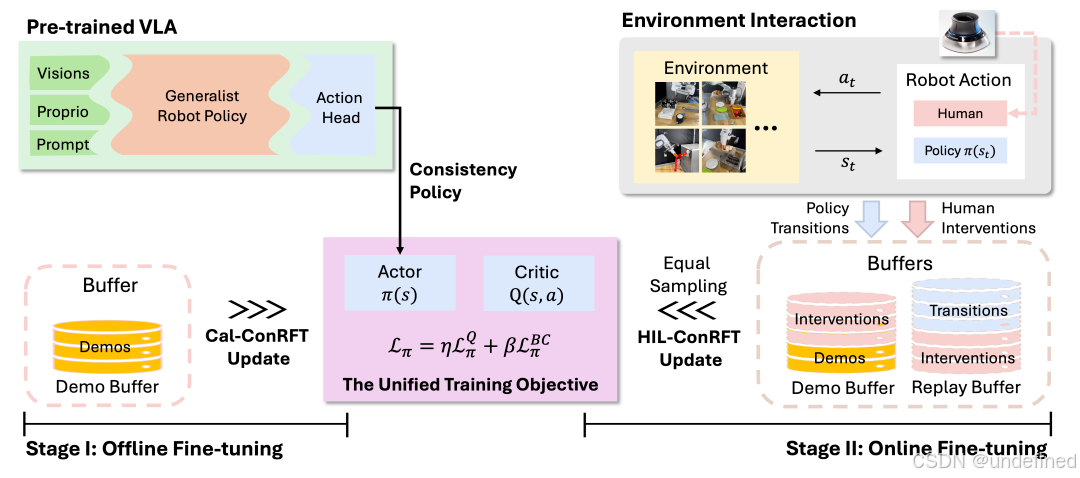
VLAC: A Vision-Language-Action-Critic Model for Robotic Real-World Reinforcement Learning
链接:https://arxiv.org/abs/2509.15937
代码:https://github.com/VLAC-VLA/VLAC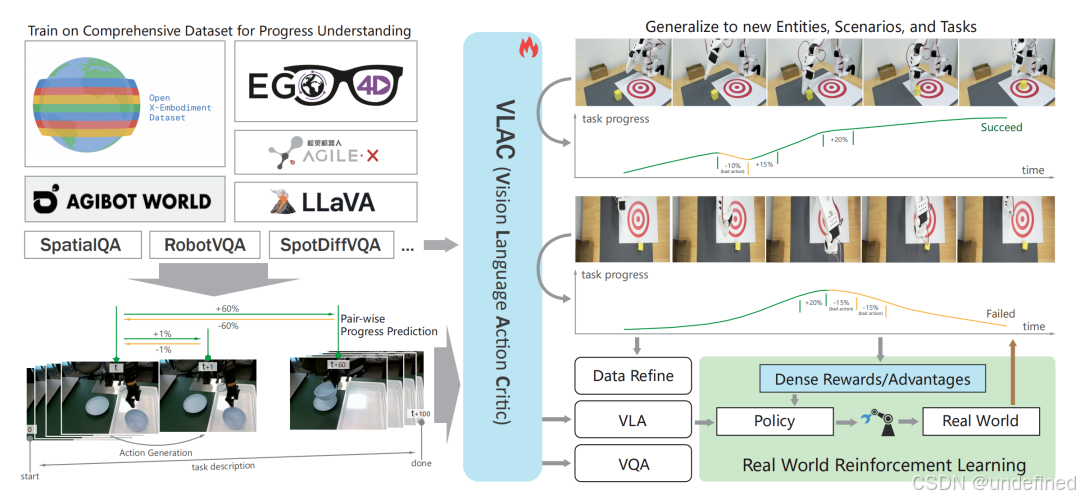
Self-Improving Embodied Foundation Models (Generalist)
链接:https://arxiv.org/pdf/2509.15155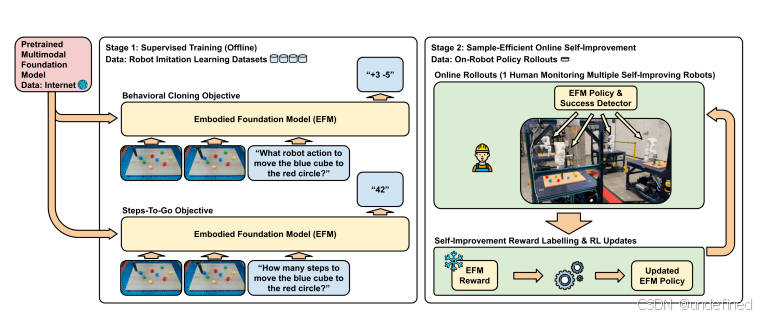
三、 世界模型 (World Model / Model-Based RL)
利用世界模型作为虚拟环境,实现低成本、安全的 VLA 策略后训练。
World-Env: Leveraging World Model as a Virtual Environment for VLA Post-Training
链接:https://arxiv.org/abs/2509.24948
代码:https://github.com/amap-cvlab/world-env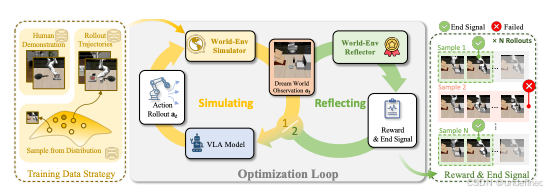
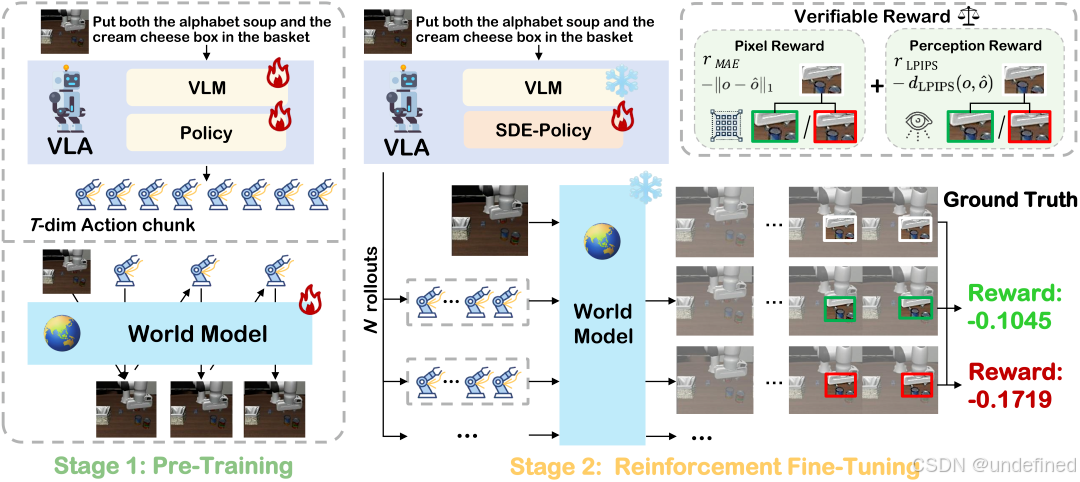
VLA-RFT: Vision-Language-Action Reinforcement Fine-tuning with Verified Rewards in World Simulators
链接:https://arxiv.org/pdf/2510.00406
代码:https://github.com/VLA-RFT/VLA-RFT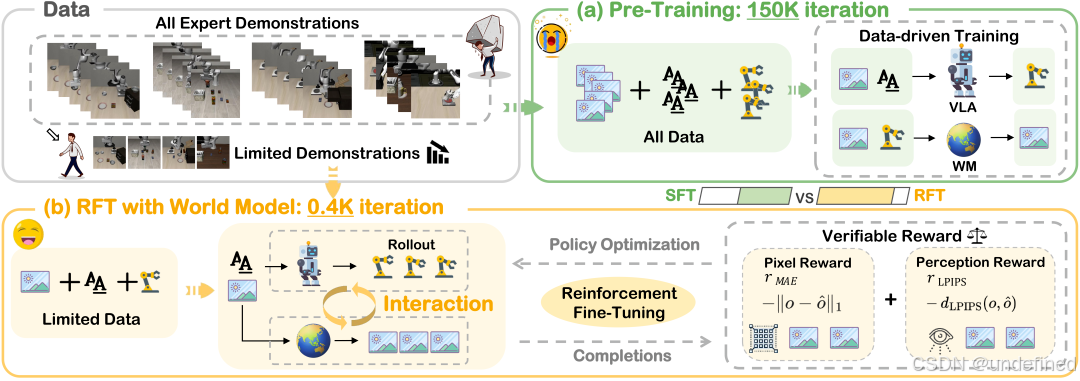

四、 推理时强化学习 (Test-Time RL)
在部署阶段利用预训练的价值函数进行实时优化或纠错。
To Err is Robotic: Rapid Value-Based Trial-and-Error during Deployment (Bellman-Guided Retrials)
链接:https://arxiv.org/abs/2406.15917
代码:https://github.com/notmahi/bellman-guided-retrials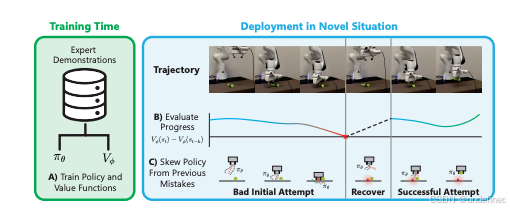
Steering Your Generalists: Improving Robotic Foundation Models via Value Guidance (V-GPS)
链接:https://arxiv.org/abs/2410.13816
代码:https://v-gps.github.io/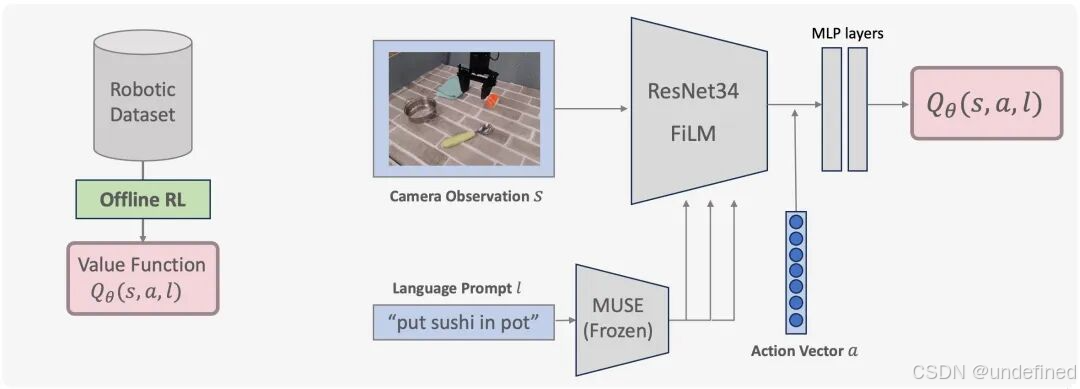
Hume: Introducing System-2 Thinking in Visual-Language-Action Model
链接:https://arxiv.org/abs/2505.21432
代码:https://github.com/Hume-VLA/Hume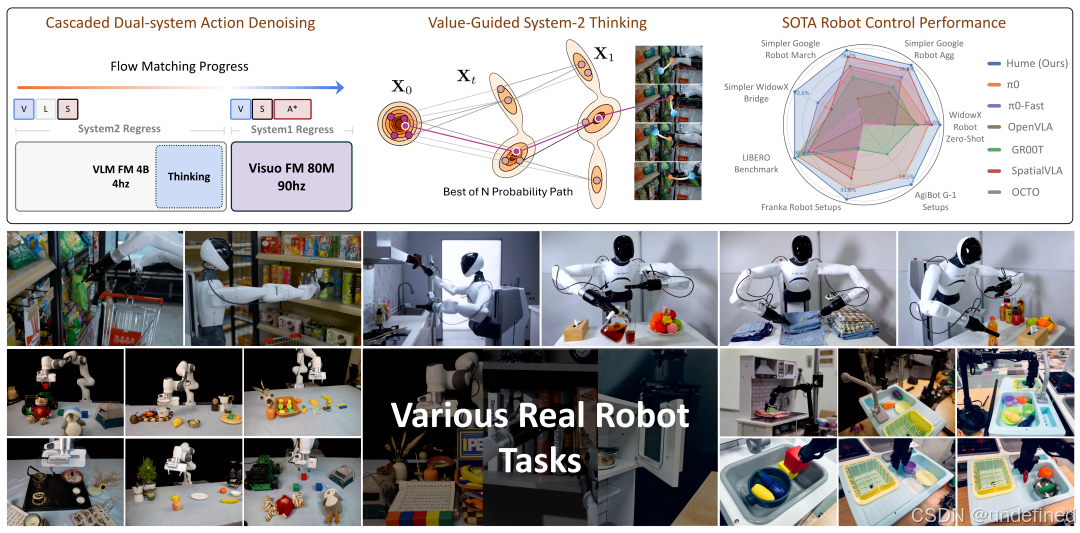
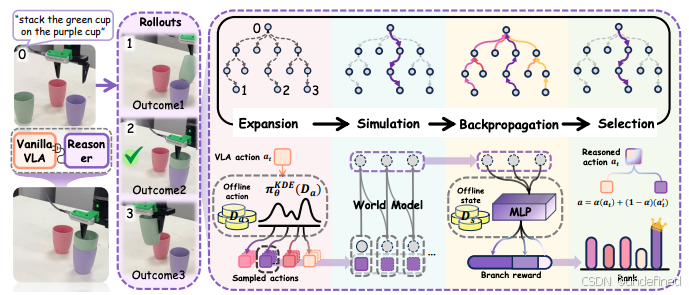
VLA-Reasoner: Empowering Vision-Language-Action Models with Reasoning via Online Monte Carlo Tree Search
链接:https://arxiv.org/abs/2509.22643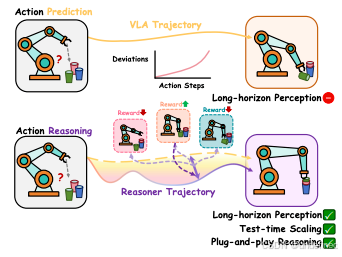
五、 强化学习对齐 (RL Alignment)
旨在使 VLA 策略符合人类偏好或安全约束。
GRAPE: Generalizing Robot Policy via Preference Alignment
链接:https://arxiv.org/abs/2411.19309
代码:https://github.com/GRAPE-VLA/GRAPE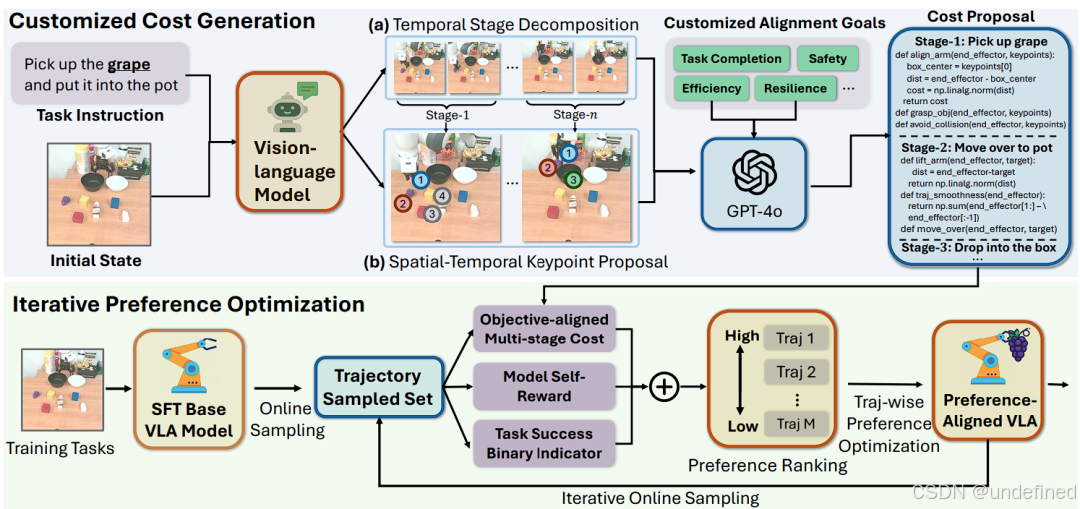
SafeVLA: Towards Safety Alignment of Vision-Language-Action Model via Constrained Learning
链接:https://arxiv.org/abs/2503.03480
代码:https://safevla.github.io/
六、 其他分类 (Unclassified)
RPD: Refined Policy Distillation: From VLA Generalists to RL Experts
链接:https://arxiv.org/abs/2503.05833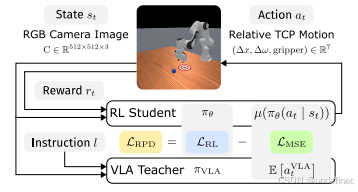
总结
VLA 与 RL 的结合正处于快速爆发期。将模仿学习的大规模先验与强化学习的自进化能力相结合,是通向具身通用人工智能的关键路径。
都看到这了,点个关注再走吧🧐~

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 18
18 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)