论文精读:FUnIE-GAN
水下视觉感知是机器人领域公认的核心挑战之一。光在水中的散射和吸收效应,会导致图像产生严重的色彩偏差、低对比度和细节损失,从而严重影响各类视觉算法的性能。然而,现有的图像增强方法大多计算成本过高,难以在资源受限的水下机器人平台上进行实时部署。为了解决这一难题,本文提出了 FUnIE-GAN:一个基于条件生成对抗网络的轻量级、高效率水下图像增强模型。它摒弃了复杂的物理建模,通过端到端学习的方式,直接构
论文精读:FUnIE-GAN
一、水下视觉感知的背景与挑战
水下视觉感知是机器人领域公认的核心挑战之一。光在水中的散射和吸收效应,会导致图像产生严重的色彩偏差、低对比度和细节损失,从而严重影响各类视觉算法的性能。然而,现有的图像增强方法大多计算成本过高,难以在资源受限的水下机器人平台上进行实时部署。
为了解决这一难题,本文提出了 FUnIE-GAN:一个基于条件生成对抗网络的轻量级、高效率水下图像增强模型。它摒弃了复杂的物理建模,通过端到端学习的方式,直接构建从降质图像到清晰图像的映射。
二、FUnIE-GAN核心方法与架构
FUnIE-GAN(Fast Underwater Image Enhancement Generative Adversarial Network)是本文提出的一种条件生成对抗网络(cGAN)模型,其核心目标是实现快速且实时的水下图像增强。该模型通过学习从退化(输入)图像到增强(输出)图像的非线性映射,将图像增强问题转化为一个图像到图像的转换任务。
生成器架构
FUnIE-GAN的生成器(Generator)G采用了受U-Net启发的编码器-解码器结构,但在设计上进行了简化,以确保模型在推理速度上的优势。
其输入尺寸为256×256×3(RGB图像),输出同样为256×256×3的增强图像。如图2(a)所示,生成器包含五个编码器(e1-e5)和五个解码器(d1-d5)层。编码器负责逐步提取图像的深层特征,而解码器则将这些特征重建为增强图像。为了保留图像的细节信息并缓解信息瓶颈,模型引入了残差连接,将编码器各层的输出直接连接到对应的解码器层(例如,e1连接到d5,e2连接到d4,以此类推),这种设计对于图像到图像转换任务的性能提升至关重要。网络中的所有层均采用2D卷积(卷积核大小为4×4),紧随其后的是Leaky-ReLU激活函数和批标准化(Batch Normalization, BN),这有助于提高模型的训练稳定性和收敛速度。整个网络是全卷积的,不包含全连接层,进一步降低了参数数量,从而实现更快的推理速度。
判别器架构
判别器(Discriminator)D采用的是Markovian PatchGAN结构,其设计宗旨是有效捕捉图像的局部纹理和风格信息,而非全局图像内容。这种局部判别机制不仅对高频特征(如纹理和边缘)的感知更加敏感,而且由于其操作范围仅限于图像块(patch-level),相比于全局判别器,其参数量更少,计算效率更高。如图2(b)所示,判别器将输入的真实图像或生成图像(256×256×6,其中6代表输入图像的RGB通道与生成图像的RGB通道拼接)通过四层卷积转换成一个16×16×1的输出,该输出代表判别器对不同图像块有效性响应的平均值。每层卷积同样使用3×3的卷积核,步长为2,并结合非线性激活和批标准化处理。
多模态目标函数
为了全面评估和优化增强图像的感知质量,FUnIE-GAN构建了一个多模态目标函数,它结合了多种损失项,涵盖了图像的全局内容、颜色、局部纹理和风格信息。
-
条件对抗损失(Conditional Adversarial Loss, LCGANL_{CGAN}LCGAN)
这是标准GAN模型的核心,生成器G试图最小化LCGANL_{CGAN}LCGAN以生成逼真的图像,而判别器D则试图最大化LCGANL_{CGAN}LCGAN以区分真实图像和生成图像。
LCGAN(G,D)=Ex,y[logD(Y)]+Ex,y[log(1–D(X,G(X,Z)))]L_{CGAN}(G, D) = E_{x,y} [log D(Y)] + E_{x,y} [log(1 – D(X, G(X, Z)))]LCGAN(G,D)=Ex,y[logD(Y)]+Ex,y[log(1–D(X,G(X,Z)))]
其中,XXX是输入退化图像,YYY是目标增强图像,G(X,Z)G(X, Z)G(X,Z)是生成器生成的增强图像。 -
全局相似性损失(L1L_1L1 Loss)
为了促使生成器学习生成与目标图像在全局上相似的图像,并避免常见的模糊问题,模型引入了L1损失。实验表明,L1损失在防止图像模糊方面优于L2损失。
L1(G)=Ex,y,z[∣∣Y–G(X,Z)∣∣1]L_1(G) = E_{x,y,z} [||Y – G(X, Z)||_1]L1(G)=Ex,y,z[∣∣Y–G(X,Z)∣∣1]
通过图4( C )的消融实验,我们可以看到L1损失对生成图像的清晰度有显著贡献。 -
图像内容损失(LconL_{con}Lcon)
为了确保增强图像在高级语义内容上与目标图像保持一致,模型引入了内容损失。受先前工作的启发,这里的内容函数Φ(⋅)\Phi(\cdot)Φ(⋅)定义为预训练的VGG-19网络中block5_conv2层提取的高级特征。
Lcon(G)=Ex,y,z[∣∣Φ(Y)–Φ(G(X,Z))∣∣2]L_{con}(G) = E_{x,y,z} [||\Phi(Y) – \Phi(G(X, Z))||_2]Lcon(G)=Ex,y,z[∣∣Φ(Y)–Φ(G(X,Z))∣∣2]
内容损失通过强制生成图像与真实图像在特征空间上接近,进一步提升了增强效果的真实感和细节保留。图4( c )的消融研究也表明,LconL_{con}Lcon有助于提升图像的精细纹理细节。
在配对训练中,上述三个损失函数被组合起来,通过加权求和的方式构成生成器的最终目标函数,其中L1L_1L1和LconL_{con}Lcon的权重分别为λ1=0.7\lambda_1 = 0.7λ1=0.7和λc=0.3\lambda_c = 0.3λc=0.3。 -
循环一致性损失(Cycle-Consistency Loss, LcycL_{cyc}Lcyc)
针对非配对训练场景,当无法获取精确的配对数据时,FUnIE-GAN借鉴了CycleGAN的思想,引入了循环一致性损失。该损失项确保了从源域X到目标域Y的映射GFG_FGF和从目标域Y到源域X的重建映射GRG_RGR能够相互逆转。具体来说,即X→GF(X)→GR(GF(X))≈XX \rightarrow G_F(X) \rightarrow G_R(G_F(X)) \approx XX→GF(X)→GR(GF(X))≈X 和 Y→GR(Y)→GF(GR(Y))≈YY \rightarrow G_R(Y) \rightarrow G_F(G_R(Y)) \approx YY→GR(Y)→GF(GR(Y))≈Y。
Lcyc(GF,GR)=EX,Y,Z[∣∣X–GR(GF(X,Z))∣∣1]+EX,Y,Z[∣∣Y–GF(GR(Y,Z))∣∣1]L_{cyc}(G_F,G_R) = E_{X,Y,Z} [||X – G_R(G_F(X, Z))||_1] + E_{X,Y,Z} [||Y – G_F(G_R(Y,Z))||_1]Lcyc(GF,GR)=EX,Y,Z[∣∣X–GR(GF(X,Z))∣∣1]+EX,Y,Z[∣∣Y–GF(GR(Y,Z))∣∣1]
在非配对训练中,生成器GFG_FGF和GRG_RGR的目标函数包含了各自的条件对抗损失,并加上循环一致性损失(权重λcyc=0.1\lambda_{cyc} = 0.1λcyc=0.1),以实现跨域的有效图像转换。
三、EUVP大规模水下图像数据集
为了克服现有水下图像增强数据集规模小、泛化能力弱的局限性,本文提出了一个大规模的水下图像数据集,命名为EUVP (Enhancement of Underwater Visual Perception)。该数据集是研究领域的一项重要贡献,旨在为训练鲁棒且高性能的水下图像增强模型提供坚实的基础。
数据集特点
EUVP数据集的显著特点体现在以下几个方面:
- 大规模与多样性: 数据集包含了超过12,000个配对图像和8,000个非配对图像实例。这些图像来源于七种不同的相机设备,包括GoPros、Aqua AUV的uEye相机、低光USB相机和Trident ROV的HD相机等。这种多样化的采集设备确保了数据能够覆盖广泛的视觉条件。
- 真实世界场景: 图像采集于海洋探索、人机协作实验等多种实际海洋环境,涵盖了不同的能见度条件、水体类型和光照情况,大大增强了模型的泛化能力。此外,数据集中还纳入了部分来自公开YouTube视频的图像,进一步丰富了场景多样性。
- 配对与非配对数据: EUVP同时提供配对和非配对图像,支持更灵活的模型训练范式,例如单向对抗训练和双向对抗训练。
数据制备方法
数据集的制备过程综合了人工筛选和学习型生成方法:
- 非配对数据: 通过六名人类参与者的视觉检查来分离“差质量”和“好质量”的图像。评估标准包括图像的色彩、对比度、清晰度以及场景的可解释性(例如,前景/物体是否可识别)。这种方法确保了非配对数据能够反映人类对水下图像质量的感知偏好。非配对图像示例,如图3(b)所示:

- 配对数据: 为了获得配对数据,首先在非配对数据集上训练一个基于CycleGAN的模型,使其能够学习从高质量图像到低质量图像的域转换(即“劣化”过程)。随后,利用这个学习到的模型对优质图像进行“劣化”,从而生成对应的配对图像。同时,数据集还从ImageNet和Flickr中选取了部分水下图像进行扩充。配对图像示例,如图3(a)所示。
EUVP数据集的构建,有效地解决了以往水下图像增强研究中数据稀缺和缺乏真实多样性的问题。通过提供大规模、高质量的配对和非配对数据,该数据集对于训练出更鲁棒、泛化能力更强的水下图像增强模型至关重要,并为推动水下视觉感知领域的发展奠定了基础。
四、实验评估与分析
定性评估
首先,对FUnIE-GAN的增强效果进行了视觉上的定性分析。
-
如图所示,FUnIE-GAN能够有效地恢复图像的真实色彩和锐度。

具体而言,它成功纠正了水下图像中普遍存在的偏绿/偏蓝色调,并显著提升了图像的全局对比度,这些都是有效水下图像增强器的关键特性。
-
通过消融实验(如图中Ablation experiment所示),我们进一步探讨了目标函数中各个损失项的贡献。结果表明,L1损失有助于生成更锐利的图像,而内容损失(Lcon)则有助于保留更精细的纹理细节。在没有L1和Lcon损失项的情况下,平均UIQM值显著下降了17.6%,这进一步印证了这些损失项的重要性。
我们将FUnIE-GAN的性能与多款先进模型进行了对比,包括基于学习的UGAN-P、Pix2Pix、LS-GAN、Res-GAN、Res-WGAN、CycleGAN以及基于物理模型的Mband-EN和Uw-HL。
- 观察发现:Res-GAN、Res-WGAN和Mband-EN往往会导致图像过度饱和。LS-GAN在色彩校正方面表现不佳。UGAN-P、Pix2Pix和Uw-HL虽然表现良好,但UGAN-P在处理亮区域时有时会出现过度饱和,而Pix2Pix在某些情况下无法有效增强全局亮度。
- 值得注意的是,尽管FUnIE-GAN采用了更简化的网络架构,并且无需深度或水体光学特性等先验信息,其增强效果与基于物理模型或现有学习模型相当甚至更优。此外,FUnIE-GAN-UP(非配对训练版本)在泛化性能上普遍优于CycleGAN。
定量评估
为提供更客观的性能衡量,我们采用了PSNR(峰值信噪比)、SSIM(结构相似性)和UIQM(水下图像质量测量)等标准指标进行定量评估。
-
PSNR与SSIM:
- PSNR用于衡量增强图像与真实图像之间的重建质量,其计算公式为:
PSNR(x,y)=10log10[2552/MSE(x,y)]PSNR(x, y) = 10 \log_{10} [255^2/MSE(x,y)]PSNR(x,y)=10log10[2552/MSE(x,y)] - SSIM则从亮度、对比度和结构三个维度评估图像相似性:
SSIM(x,y)=(2μxμy+c1)(σxy+c2)(μx2+μy2+c1)(σx2+σy2+c2)SSIM(x, y) = \frac{(2\mu_x\mu_y + c_1)(\sigma_{xy} + c_2)}{(\mu_x^2 + \mu_y^2 + c_1)(\sigma_x^2 + \sigma_y^2 + c_2)}SSIM(x,y)=(μx2+μy2+c1)(σx2+σy2+c2)(2μxμy+c1)(σxy+c2) - 表一展示了在EUVP数据集1K张配对测试图像上的PSNR和SSIM结果。
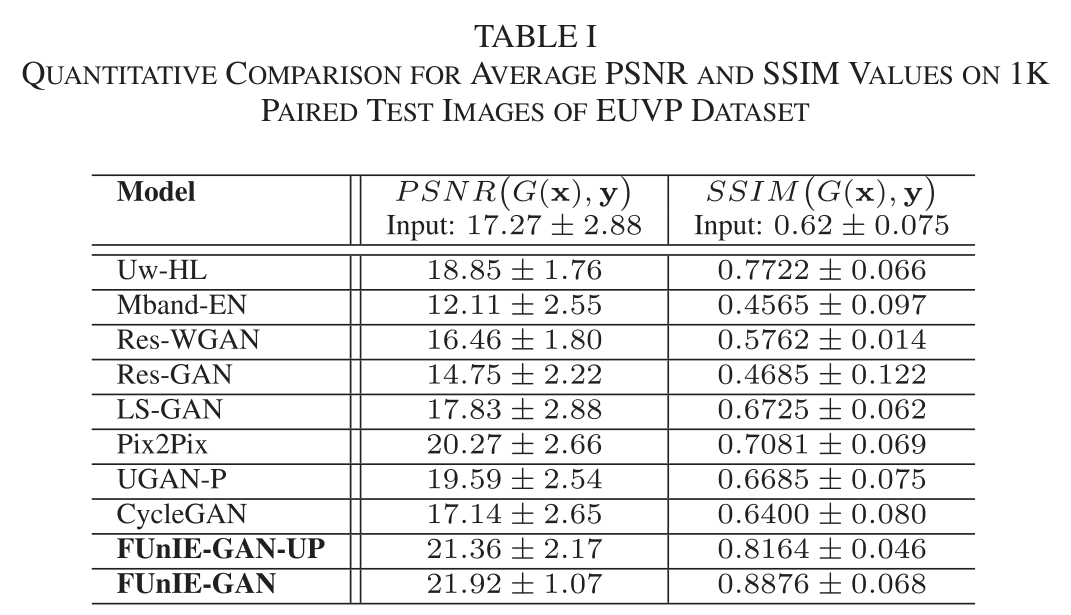
FUnIE-GAN在这两项指标上均表现最佳。我们推测,FUnIE-GAN和Pix2Pix中的全局相似性L1损失项,以及UGAN-P中的梯度惩罚项,都对性能提升起到了关键作用。
- PSNR用于衡量增强图像与真实图像之间的重建质量,其计算公式为:
-
UIQM:
- UIQM是一种专门针对水下图像的质量评估指标,综合衡量图像的色彩、锐度和对比度。
- 表二比较了不同模型在配对和非配对测试集上的平均UIQM值。
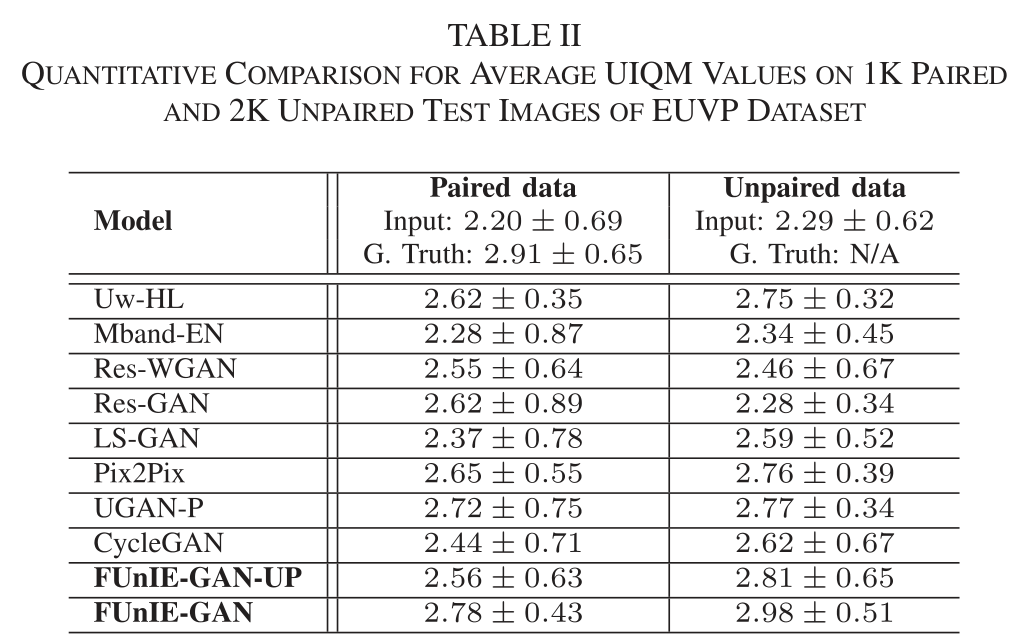
结果表明,FUnIE-GAN同样取得了领先的UIQM得分。对于配对数据集,特别是由FUnIE-GAN、UGAN-P和Pix2Pix训练的模型表现更优。
用户研究
为了将人类主观感知纳入评估体系,研究者进行了一项用户研究。
- 研究方法:共有78名参与者对9幅图像的不同增强结果进行了排名,总计收集了312份反馈。
- 研究结果:如表三所示,原始图像的平均前三名准确率仅为6.67%,这强烈表明用户普遍偏好增强后的图像。
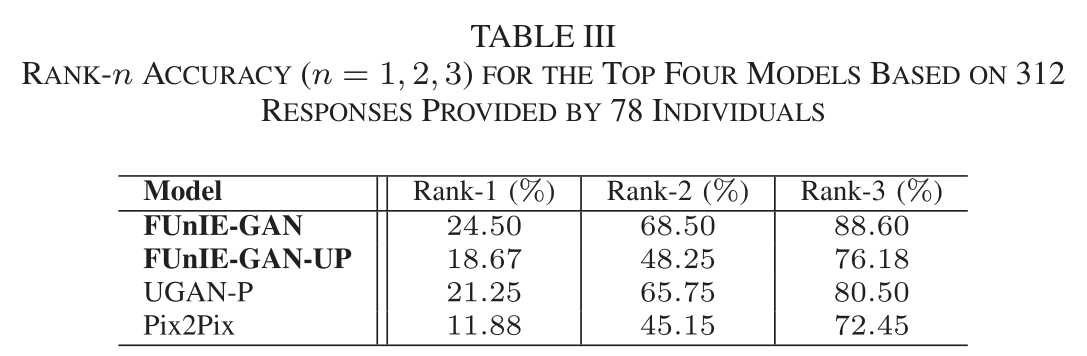
在所有增强模型中,用户最青睐FUnIE-GAN、UGAN-P和Pix2Pix,其中FUnIE-GAN在排名第一的准确率上表现最佳(24.50%)。
下游任务影响
FUnIE-GAN增强后的图像显著提升了多个水下视觉感知任务的性能。
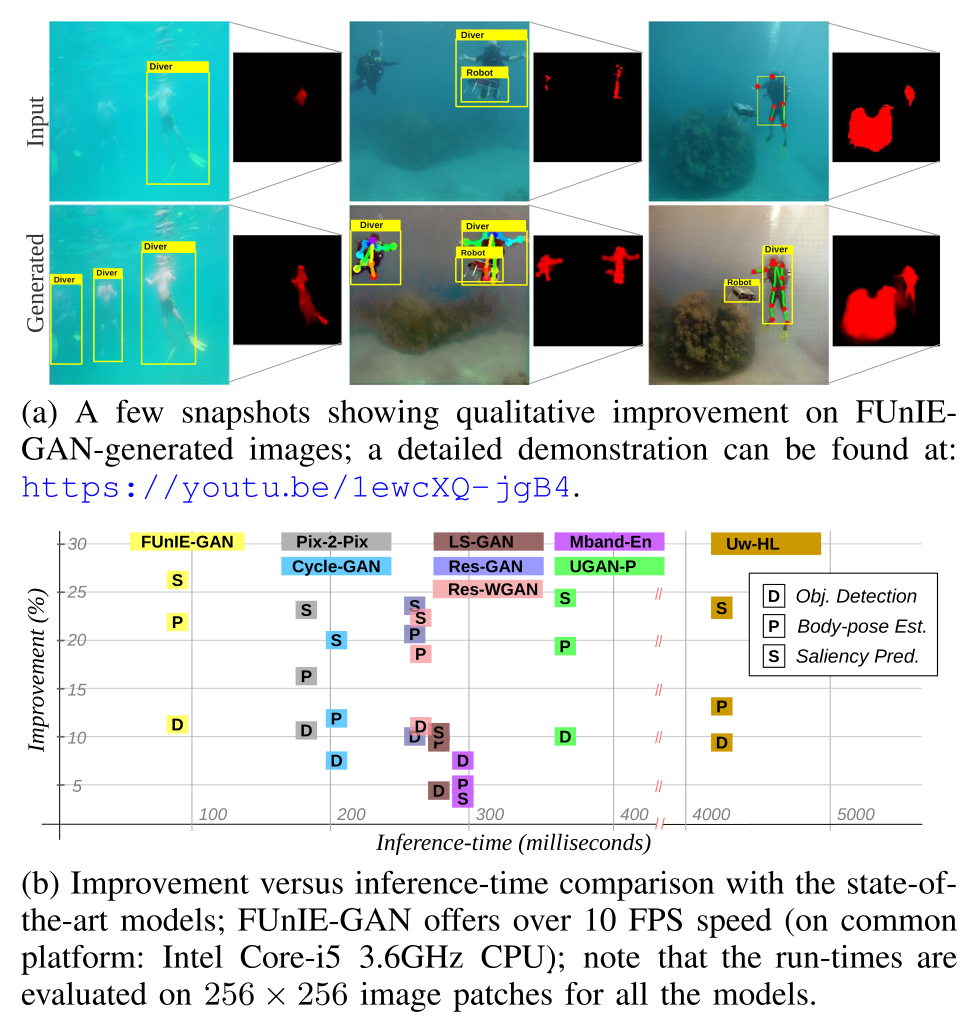
- 具体提升:如图所示,FUnIE-GAN能够有效改善水下目标检测、人体姿态估计和显著性预测任务的准确性。

在不同测试集上,对象检测平均提升11-14%,人体姿态估计提升22-28%,显著性预测提升26-28%。 - 与其他模型的对比:如图所示,在实现性能提升的同时,FUnIE-GAN的推理速度远快于其他先进模型,这对于实时机器人应用至关重要。
效率分析
FUnIE-GAN在效率方面表现出色,完全满足实时应用的需求。
- 内存占用:模型仅占用17MB内存。
- 推理速度:在NVIDIA Jetson TX2单板计算机上,FUnIE-GAN的推理速度达到25.4 FPS;在NVIDIA GTX 1080显卡上达到148.5 FPS;在Intel Core-i3 6100U机器人CPU上也能达到7.9 FPS。
- 实时性验证:这些优异的计算性能使得FUnIE-GAN非常适合作为水下视觉引导机器人实时感知流程中的图像预处理模块。
模型局限性
尽管FUnIE-GAN表现优异,但在某些极端情况下仍存在局限性。
- 极度退化和缺乏纹理的图像:如图所示,对于严重退化或缺乏纹理的图像,FUnIE-GAN的增强效果不尽理想。

在这种情况下,生成的图像往往因噪声放大而过度饱和,色彩和纹理恢复效果不佳。 - 非配对训练的稳定性问题:FUnIE-GAN-UP版本在非配对训练时容易出现稳定性问题,即判别器可能过早变得过于强大,导致生成器面临梯度消失,从而影响模型学习。这会导致生成的图像缺乏色彩一致性和准确的纹理细节,需要精细的超参数调整。
- 性能与效率的权衡:FUnIE-GAN在鲁棒性和效率之间进行了权衡,这在一定程度上限制了其性能上限。对于非实时应用,可以采用更复杂的深度模型以获得更高的增强质量。
- 非像素级真实度保证:FUnIE-GAN主要针对感知图像质量进行增强,因此无法保证恢复图像的真实像素强度。如果场景深度和水体光学特性等信息可用,结合物理模型可以实现更精确的图像恢复。
五、结论与未来工作
本文提出了一种简单而高效的条件生成对抗网络(cGAN)模型——FUnIE-GAN,专注于实时水下图像增强。该模型的核心创新在于其独特的多模态感知损失函数,该函数综合评估图像的全局色彩、内容、局部纹理和风格信息,从而有效地提升了水下图像的视觉质量。通过引入大规模的EUVP数据集,FUnIE-GAN在配对和非配对训练数据上均展现出卓越的性能。
实验结果一致表明,FUnIE-GAN在定性与定量评估中均优于现有先进模型,尤其在推理速度上具有显著优势,满足了水下机器人实时视觉感知对效率的要求。更重要的是,经FUnIE-GAN增强的图像显著提升了水下目标检测、人体姿态估计和显著性预测等关键视觉感知任务的性能,验证了其在自主水下机器人视觉处理管线中的实用价值。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 36
36 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)