OpenVLA
OpenVLA以Llama 2语言模型为基础,结合了融合DINOv2和SigLIP预训练特征的视觉编码器。通过现代低秩自适应方法,OpenVLA可在消费级GPU上进行微调,并通过量化实现高效部署,且不会降低下游任务成功率。Prismatic VLM 是一个「通用视觉-语言模型骨架」,用于把图像 + 语言 → 映射到统一 token 序列空间,具体流程如下:图像 patch (补丁) → visua
OpenVLA以Llama 2语言模型为基础,结合了融合DINOv2和SigLIP预训练特征的视觉编码器。
通过现代低秩自适应方法,OpenVLA可在消费级GPU上进行微调,并通过量化实现高效部署,且不会降低下游任务成功率。
Prismatic VLM
Prismatic VLM 是一个「通用视觉-语言模型骨架」,用于把图像 + 语言 → 映射到统一 token 序列空间,具体流程如下:
-
图像 patch (补丁) → visual tokens
-
文本 → text tokens
-
视觉 + 语言 在 LLM token 级别融合
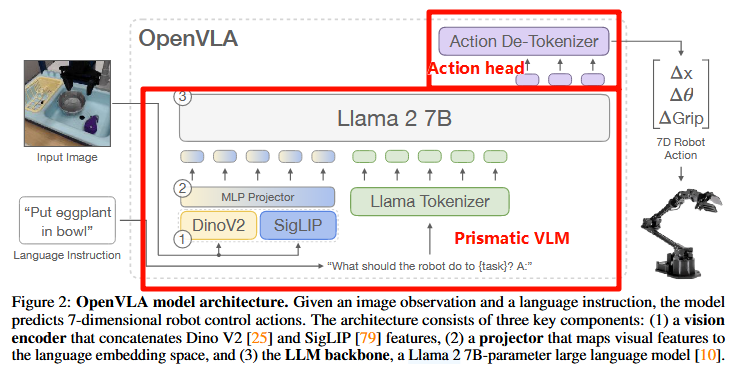
OpenVLA模型结构
Prismatic VLM + Action Head
基本原理就是:将图像输入经过视觉编码器映射为“图像补丁嵌入(image patches)”,再经过MLP Projector将image patches映射到 Llama 2模型的空间(即将patches 转换为 token嵌入到语言模型中);最后,语言模型输出的token 经过 action head 反解token (de-tokenizer)。
模型基于Prismatic-7B VLM构建,该模型包含6亿参数的视觉编码器、2层MLP投影器和70亿参数的Llama 2语言模型骨干网络。其视觉编码器由预训练的SigLIP和DinoV2模型组成,输入图像补丁分别通过两个编码器处理后,特征向量在通道维度上拼接。(与仅使用CLIP或SigLIP的视觉编码器相比,DinoV2特征的加入有助于提升空间推理能力,这对机器人控制尤为重要。)
训练过程
对预训练的Prismatic-7B VLM骨干网络进行微调,以实现机器人动作预测。我们将动作预测问题转化为“视觉-语言”任务,即输入观测图像和自然语言任务指令,输出预测机器人动作的字符串。
为使VLM的语言模型骨干网络能够预测机器人动作,我们将连续的机器人动作映射为语言模型令牌生成器使用的离散令牌。将动作处理为令牌序列后,OpenVLA采用标准的下一个令牌预测目标(即给定前面的token 去预测下一个token)进行训练,仅对预测动作令牌(不关心中间的视觉文本token)的交叉熵损失(动作token是离散的,动作预测转换为离散动作变量的最大似然估计)进行评估。
动作映射
使用有7个自由度的机器人,将机器人动作的每个维度分别离散化为256个区间。对于每个动作维度,区间宽度根据训练数据中动作的第1百分位数和第99百分位数均匀划分,这种基于百分位数的方式可忽略数据中的异常动作,避免离散化区间过大导致动作离散化的有效粒度降低。
即N维机器人动作被转化为N个介于0-255之间的离散整数(每一维度动作选取都是从256个整数间进行采样)。由于OpenVLA的语言骨干网络使用的Llama令牌生成器仅预留100个“特殊令牌”用于微调期间新增的令牌,无法满足256个动作令牌的需求,文章直接用动作令牌覆盖Llama令牌生成器词汇表中使用频率最低的256个令牌(即最后256个令牌)。
训练细节
数据集:数据集采用仅包含至少带有一个第三人称相机且采用单臂末端执行器控制的操作数据集;
图像分辨率:224×224像素和384×384像素的输入图像,发现两者在评估中性能无差异,最终采用224×224像素分辨率。
训练轮次::与LLM或VLM训练通常最多迭代1-2轮数据集不同,VLA训练需要多次迭代数据集,直到训练动作令牌准确率超过95%,机器人实际性能才会持续提升,最终训练完成了27轮数据集迭代。
学习率:在多个数量级的学习率中进行筛选,发现采用固定学习率2e-5(与VLM预训练使用的学习率相同)时效果最佳,学习率预热未带来性能提升。
参数高效微调
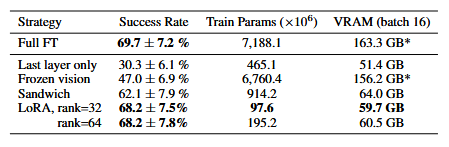
对比的微调方法包括:全微调(更新所有权重)、仅微调最后一层(仅更新OpenVLA Transformer骨干网络的最后一层和令牌嵌入矩阵)、冻结视觉编码器(冻结视觉编码器,微调其他所有权重)、夹层微调(解冻视觉编码器、令牌嵌入矩阵和最后一层)、LoRA(应用于模型所有线性层,测试多个秩值r)。
结果显示,仅微调网络最后一层或冻结视觉编码器会导致性能不佳,表明视觉特征需进一步适配目标场景。夹层微调由于微调了视觉编码器,性能更优,且因未微调完整LLM骨干网络,GPU内存占用更低。LoRA在性能和训练内存占用之间取得了最佳平衡,仅微调1.4%的模型参数,却能达到与全微调相当的性能。LoRA的秩值对策略性能影响微乎其微,建议默认使用秩值r=32。借助LoRA,可在单块A100 GPU上10-15小时内完成OpenVLA的新任务微调,计算量较全微调减少8倍。
代码解读
基本推理流程
准备指令输入:直接将指令拼接到固定的prompt末尾;确保输入的prompt 模板在 OUT: / ASSISTANT: 之后通常会出现一个特定的“空白/占位 token(token id为29871)”

图像预处理后和tokenizer后的prompt即inputids,一起送入模型进行推理,得到输出的generated_ids
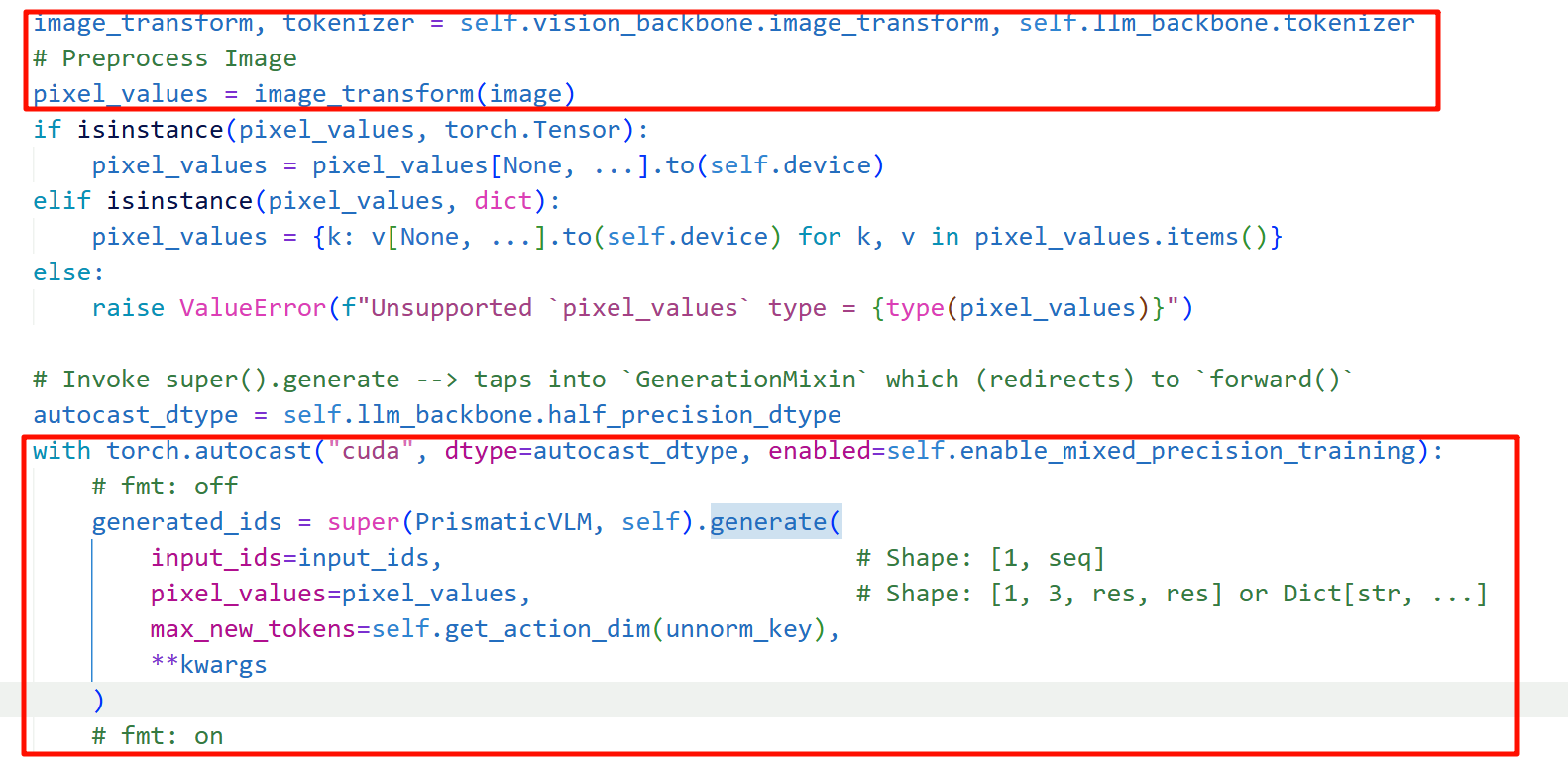
截取出动作的token id(限制了动作token id在固定的位置和固定的长度);然后对动作token ids进行de-tokenizer

动作de-tokenizer
首先,通过self.tokenizer.vocab_size - action_token_ids得到原始bin索引(范围是1~256,动作 token 被放在 vocab 的尾部并且是“倒着编码”的);
然后,通过clip得到[0,255)的bin 区间索引;最后,通过索引去bin_center获取离散化后的动作取值(范围是[-1, 1])。

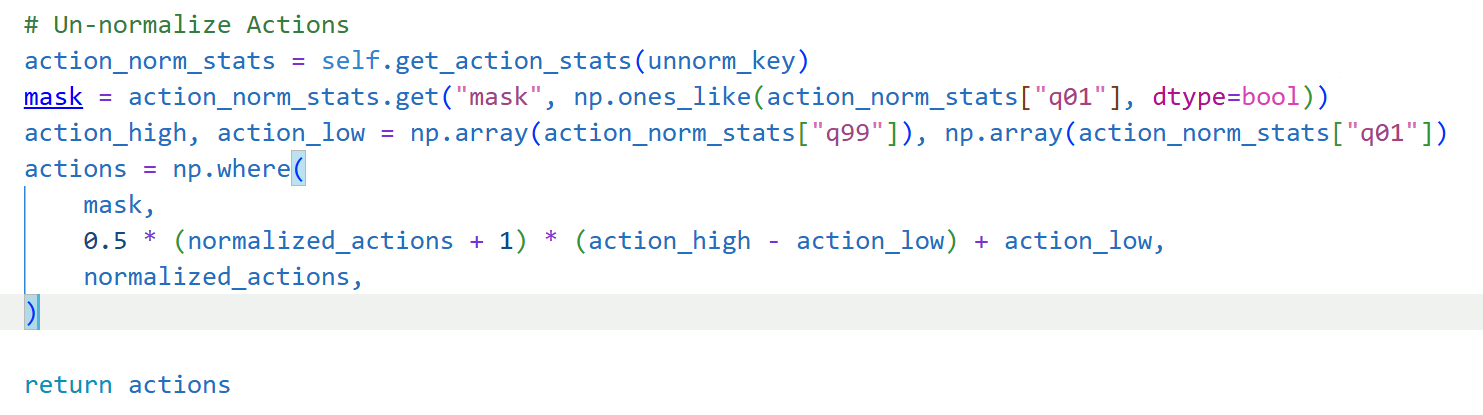
动作反归一化
将得到的归一化后的动作,通过unnorm_key进行反归一化得到真实物理世界动作

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 25
25 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)