Training-Time RTC——在训练时模拟推理延迟(前缀部分无需去噪专心预测后续动作即可):消除推理阶段的计算开销,让π0.6完成箱子装配与咖啡制作
前言
自从23年大模型火爆以来,我博客的影响力每天都在极速增长
- 特别是24年我博客内开始解读一系列具身前沿论文,以及分享我司在具身方面的实践落地之后,使得不只是国内清北复交浙等等的博士生 在看本博客,连斯坦福的博士生们 也在看了
- 而这博客影响力的极速增长,也成为了我一直更新博客的重要动力之一
对于具身,自从PI公司推出π0之后,他们每个对外发布的工作都有着很高的影响力
- 比如对于机器人的高频控制技术,我在之前解读过实时分块(RTC)技术
『详见此文《实时动作分块RTC——为解决高延迟,让π0.5也可以点燃火柴、插入网线:执行当前动作分块时生成下一个分块,且已执行的冻结 未执行的则通过“图像修复”做补全》』 - 其通过异步预测动作块,并借助推理时图像修复对已执行动作进行调节,使VLA能够生成流畅、响应迅速的机器人运动轨迹
然而这种修复方法会引入增加推理延迟的计算开销
- PI因此再次提出一种简洁替代方案:在训练时模拟推理延迟,直接对动作前缀进行调节,从而消除所有推理时开销
该方法无需修改模型架构或机器人运行时系统,仅需增加数行代码即可实现 - 至于实际效果上
一方面,模拟实验表明,在较高推理延迟场景下,本文要介绍的训练时实时分块(training-time RTC)性能优于推理时实时计算(inference-time RTC)
第一部分
1.1 引言、相关工作、预备知识
1.1.1 引言
如原论文所述,与聊天机器人或搜索引擎不同,具身智能体必须在实时环境中运行
- 智能体行为与其环境之间的反馈回路要求系统具备高度反应性——就像人类运动员一样,当外部世界在不断变化时,智能体不能简单地“停下来思考”
- 然而,前沿模型规模日益庞大,使这一点愈发困难。这一点在机器人学习领域体现得尤为明显:在该领域中,包含数十亿参数的视觉-语言-动作模型(Vision-Language-Action models,VLAs)越来越多地被用来以高频率控制机器人,以完成复杂灵巧的任务
当模型推理延迟达到几十到数百毫秒时,要产生既平滑又具备良好反应性的轨迹,是一个相当严峻的挑战
实时分块处理技术(RTC;[5])通过融合动作分块[9, 27]、流匹配[13]和推理时动作修复[18, 21],为解决该问题提供了有效途径
实时分块(Real-Time Chunking, RTC;[5])提出了一种解决这一问题的方法,它结合了:动作分块(action chunking)[9,27]、流匹配(flow matching)[13]、以及推理阶段的补画(inference-time inpainting)[18,21]
- 在 RTC中,动作分块是异步预测的——在当前分块仍在执行时就生成下一个分块
为了保证分块之间的连续性,每次生成都会基于一个由先前预测动作构成、被冻结的前缀进行条件建模,并对其余部分进行补画 - 然而,RTC所采用的推理阶段补画方法会引入额外的计算开销——从而带来额外的延迟——在一定程度上削弱了其实时执行框架的优势
通过实证研究,作者还发现,推理阶段补画inpainting 在应对高推理延迟方面存在根本性局限
对此,来自PI公司的研究者 Kevin Black、Allen Z. Ren、Michael Equi、Sergey Levine通过一种训练时模拟推理延迟的图像修复方法增强RTC系统,彻底消除推理阶段的计算开销『we augment RTC with an inpainting method that simulates inference delay at training time and eliminates any inference-time computational overhead』
- 该方法不要在推理时修补动作,而在训练时就教会模型应对延迟
咋做到呢?
很简单,说白了,既然在真实物理世界中不可避免地存在推理延迟,不如直接在训练阶段就让模型习惯这种延迟——在训练阶段,模拟推理延迟
即,直接把“前缀动作”(即推理期间机器人已经执行掉的动作)作为已知条件喂给模型,让模型只负责预测剩下的“后缀动作”
是不和跟『基于多帧历史观测输入(而非只输入当前帧观测)去预测未来动作』很像
其可作为推理时RTC的直接替代方案:无需修改模型架构或机器人运行时环境,仅需添加数行代码即可实现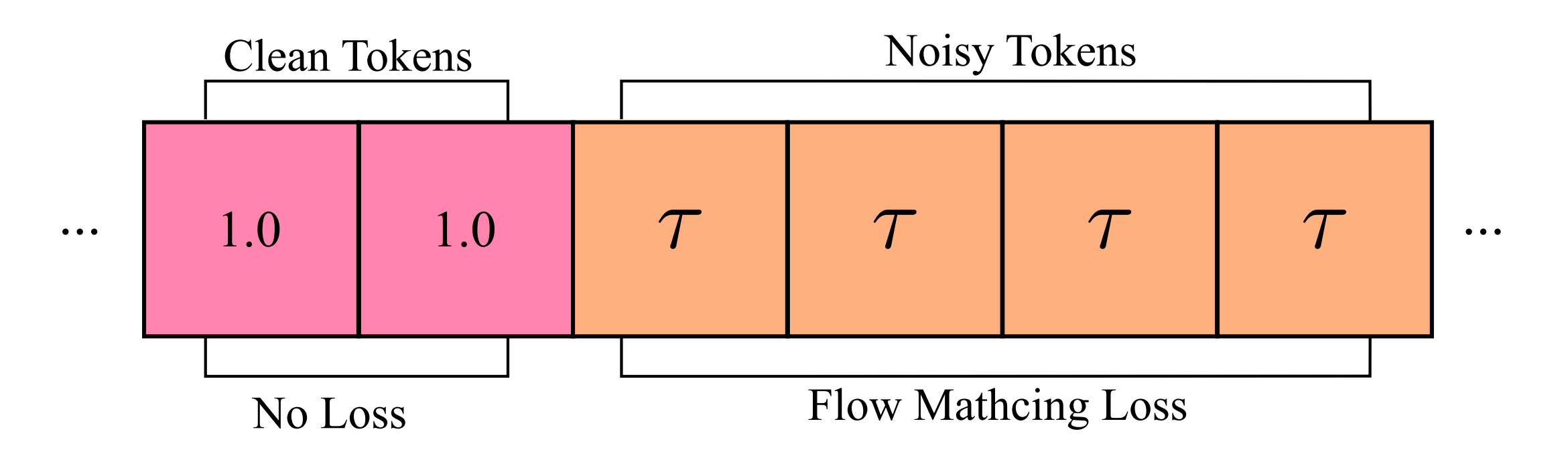
- 在模拟基准测试中,训练时实时分块(training-time RTC)在高延迟场景下表现优于推理时实时分块(inference-time RTC)
真实场景验证表明,通过对未经动作前缀调节预训练的基础模型进行微调,可成功实现训练时RTC的部署
比如通过将训练时实时分块应用于π0.6 VLA模型[24],作者在两项高复杂度任务(箱体构建与浓缩咖啡制作)中展现出优于推理时实时计算的性能提升
为方便大家一目了然、一看即懂,我还是再给大家举个通俗易懂的例子
1. 场景设定
机器人就像接力赛的跑步者,必须不停地跑(实时动作),不能停下来发呆
AI 模型就像大脑,负责规划接下来的路线
难题(延迟): 大脑思考“下一步怎么跑”是需要时间的(比如需要 0.1 秒)。而在大脑思考的这 0.1 秒里,跑步者(机器人)其实依然靠惯性往前跑了几步
2. 笨办法(旧的“推理时 RTC”方案)
做法: 大脑在思考(生成动作)的全过程中,每产生一点念头(每一步去噪),都要停下来检查:“现在的开头跟机器人实际位置对得上吗?”
补救:为了强行对齐,大脑必须在思考的每一步都进行反向计算(算导数),强迫(最新)生成的动作前缀必须吻合既定事实(已经跑出去的那 2 米)
后果: 这种“边想边改”极其消耗算力,因为通过大量的数学计算“硬拽”着模型去思考,导致推理速度变慢
3. 聪明办法(本文的“训练时 RTC”方案)
做法: 既然知道大脑思考需要 0.1 秒,那在平时训练的时候,就专门做一种特训
特训内容: 教练(训练算法)直接告诉大脑:“你开始思考吧,但在你思考完的那一瞬间,机器人肯定已经跑到前方 2 米的位置了。所以,请你直接从 2 米外那个点开始规划后面的路线! ”
结果:
大脑在思考时,已经把“由于延迟而跑掉的那几步(前缀动作)”考虑进去了
生成的路线天生就是完美的连接,不需要事后修补
这就是“训练时动作条件化”:在训练时就把“既定事实(前缀)”作为条件喂给模型,让它只管预测后面的事
总之,不要等跑完步发现路线对不上再去修图(推理时修补),而是在起跑前就预判好你会跑到哪,直接规划后面的路(训练时条件化)
1.1.2 相关工作
首先,对于动作分块与VLA模型
- 动作分块[9,26]已成为端到端模仿学习中视觉运动控制的实际标准方法。近期研究表明,通过增强视觉语言模型(VLM)生成动作分块的能力,在机器人操作领域取得显著成功,由此催生了VLA[4,6-8,10-12,14,17,28,29]
- 随后涌现出大量方法,旨在解决大型VLA模型与高频控制之间的协调难题
例如Gemini Robotics[23]与GR00T[3]采用分层式VLA架构,将模型拆分为重量级系统2(高层规划)与轻量级系统1(底层动作生成)组件
MiniVLA [2] 和 SmolVLA [20] 提出的视觉语言动作模型架构,相比大多数设计具有更快的运行速度和更高的效率,使得边缘设备上的推理部署更具可行性
这些贡献与本文介绍的Training-Time RTC正交,各自存在权衡取舍
其次,对于VLA的实时执行
- 最密切相关的先前研究是实时分块技术(RTC; [5]),其提出的异步执行框架为本研究奠定了基础
- 同样相关的是 SmolVLA [20],其提出的异步执行算法与 RTC 技术相似;然而 SmolVLA 未能解决分块间不连续性问题,导致分块衔接处出现分布外的'抖动'现象
- 与本研究同期,A2C2 [19] 和 VLASH [22] 分别通过添加轻量级校正头模块和基于单个未来动作的条件处理,解决了不连续性问题
与VLASH不同,作者在完整未来动作前缀上进行条件约束
1.1.3 背景知识
作者采用与RTC[5]相同的问题建模
- 从一个动作分块策略开始,记为
其中表示未来动作块
表示观测值,
代表控制器时间步
且称为预测时域,在推理阶段,每个动作块展开执行
个时间步,其中
称为执行范围
- 为考虑模型推理耗时,作者定义
若推理始于第步方可使用,因此前
但若满足,这些前
作者称当前块与先前块重叠的这
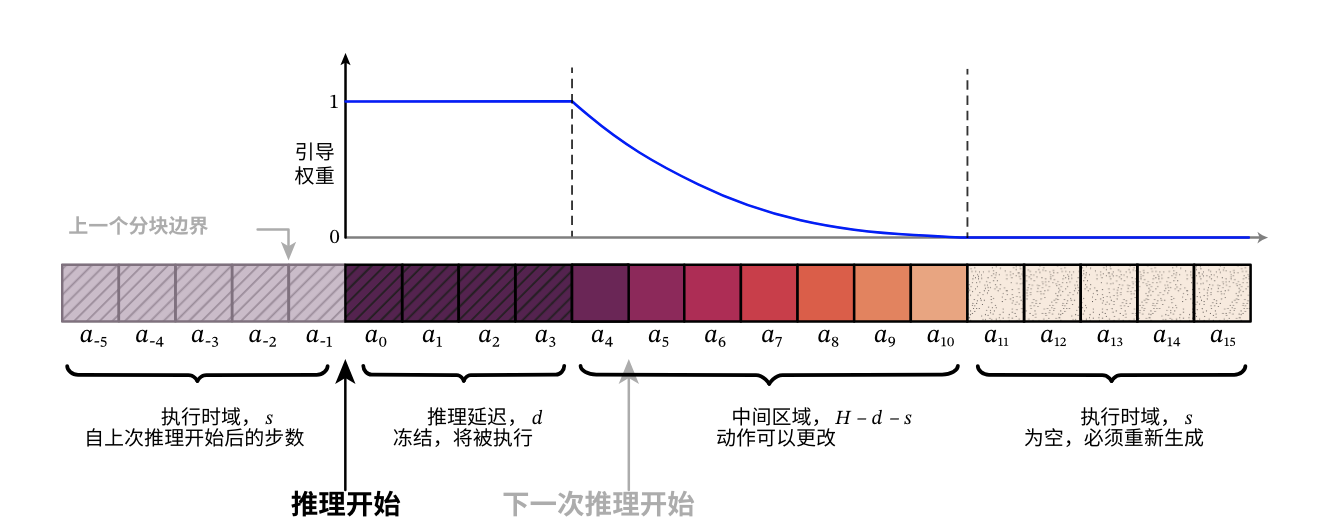
上图展示两个重叠动作分块的示意图位于时间点 t 与 t+d 之间的动作(取自前一分块)即为动作前缀(红色标注)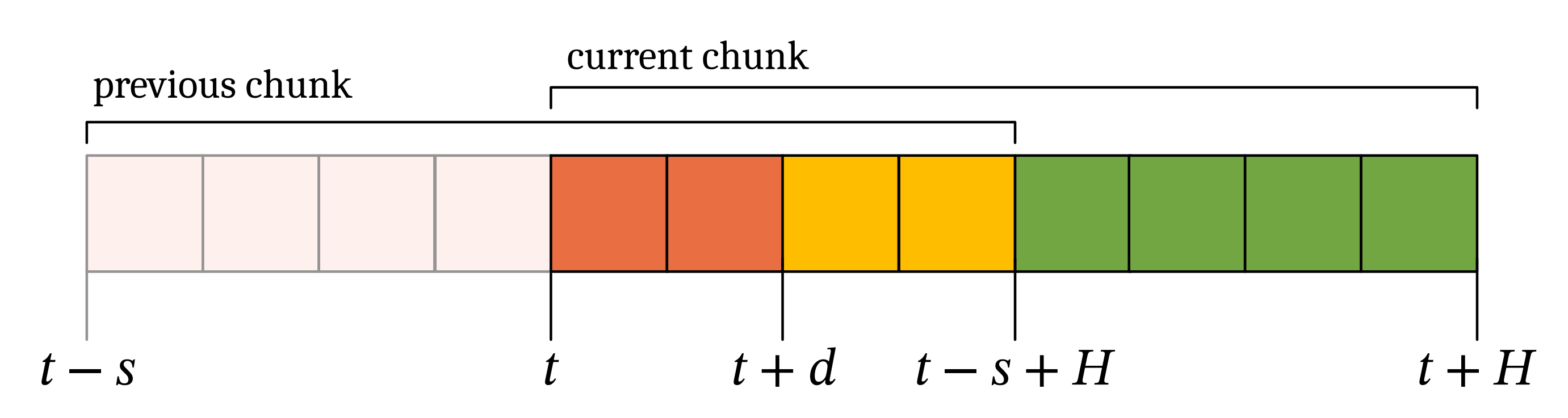
由图可知,必须满足约束条件才能构成有效动作前缀需注意:
- 作者考虑采用条件流匹配[13]训练的策略,该方法最小化以下损失函数:
其中是神经网络,
表示流匹配时间步长。在推理时,可将
积分至 1,以生成数据集分布
的样本
1.2 训练时动作条件化
1.2.1 模拟推理延迟,在训练时以前缀动作为条件实现策略条件化
推理时实时计算[5]通过基于伪逆引导[18,21]的推理时图像修复方法,将策略条件化于动作前缀(图1红色部分)
- 为提升分块间连续性,推理时实时计算(RTC)额外以所有重叠动作为条件,对超出前缀的动作采用指数递减权重(图1黄色部分)
在RTC中,该技术被称为'软掩码'。虽然伪逆引导提供了极大灵活性——可实现软掩码——但它也要求在每次去噪步骤中计算向量-雅可比乘积(通过反向传播实现) - 而本研究Training-Time RTC的核心洞见在于:可以通过模拟推理延迟,在训练时以前缀动作为条件实现策略条件化
尽管这无法达到推理时图像修复的同等级灵活性,但彻底消除了计算开销
————
形式化表述为:可学习,其中
为动作前缀(图1红色部分),
为动作后缀(图1黄绿色部分),两者均取自同一真实动作块
在大多数标准策略架构中实现此功能仅需进行3处最小改动
- 修改模型架构,允许每个动作时间步长使用不同的流匹配时间步长
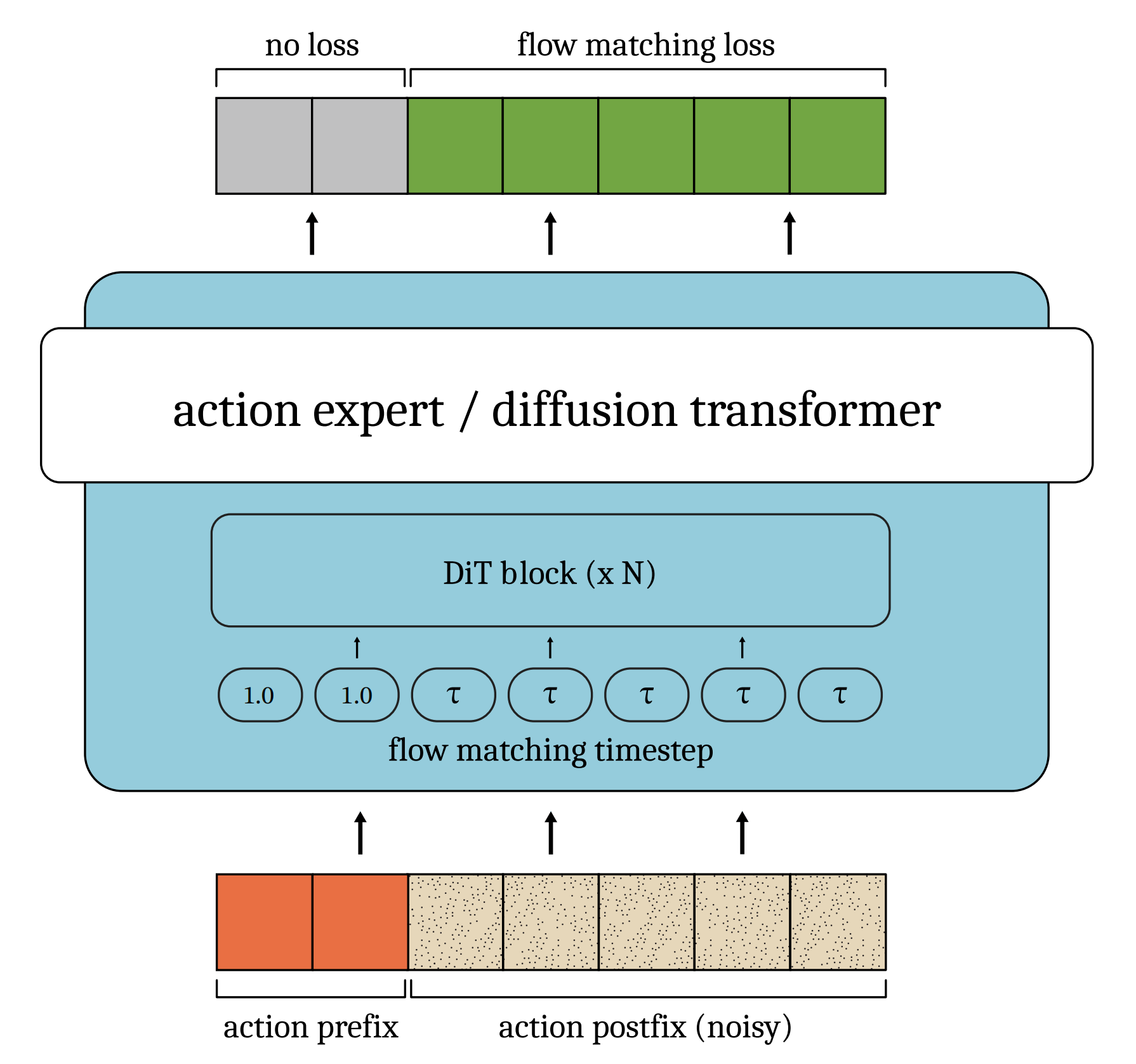
对于采用adalN-zero条件化处理流匹配时间步长的类扩散变换器架构[16],这很简单——只需允许不同token间的缩放、平移和门控参数不同。此修改不改变可学习参数数量 - 对前缀使用真实无噪动作,并将对应流匹配时间步长设为1。后缀部分保持不变
这使模型基于真实动作前缀进行条件化,同时仅用其去除后缀噪声 - 对损失函数进行屏蔽处理,使损失计算仅针对对应于后缀的输出部分
关于此条件方案在标准类扩散变换器架构(例如π0.6动作专家)中的应用示例,请参见图2『始终输入真实无噪的前缀动作,同时学习对后缀动作进行去噪。不同token的流匹配时间步长存在差异,这向模型指示了推理延迟』
1.2.2 完整实现代码(含我个人对代码的详细解释:让公式与代码逐一对应)
完整实现损失计算与动作生成的Python代码请参见算法1。 实际应用中,由于无法预先获知确切的推理延迟(且现实场景中的推理延迟可能存在波动),在训练期间对延迟量 进行随机采样
经此修改后,动作生成器以动作前缀及延迟量d作为输入,并输出动作后缀
说白了,该方法模拟推理时的延迟。它将动作序列分为两部分:
Prefix (前缀):模拟已经执行或确定的动作(作为条件,视为已知)
Postfix (后缀):需要预测的未来动作(需要去噪生成)
因此,该组件遵循与推理时实时计算(RTC)的动作生成模块相同的接口规范(参见文献[5]算法1),可作为无缝替代组件直接部署

为方便大家更好的理解上述代码中的一系列操作,特别是把对应的代码与公式逐一对应起来,故我还是给大家做个详尽细致的解释说明
整个代码分为两个部分
首先是第一部分:训练损失计算(compute_loss)
这个函数用于在训练过程中计算损失。它随机采样一个延迟 ,将前
个动作视为已知(Prefix),训练模型去预测剩余的动作(Postfix)
- 初始化与随机采样
标准流匹配的时间采样和噪声采样
# [cite: 252-257] b, ah, ad = action_chunk.shape noise_rng, time_rng, delay_rng = jax.random.split(rng, 3) time = jax.random.uniform(time_rng, (b,)) # 采样流匹配的时间步 t (0到1之间) noise = jax.random.normal(noise_rng, (b, ah, ad)) # 采样高斯噪声 epsilon - 模拟推理延迟
上面代码模拟了现实世界中不同的推理延迟,# [cite: 258-259] # 随机采样延迟 d,范围从 0 到 max_delay delay = jax.random.randint(delay_rng, (b,), 0, max_delay) - 构建时间掩码
这是算法最关键的一步。它打破了标准流匹配中所有 token 共享同一个时间
接下来,注意了# [cite: 260-261] # 创建前缀掩码:如果索引小于 delay,则为 True prefix_mask = jnp.arange(ah)[None, :] < delay[:, None] # 核心逻辑:如果是前缀,时间设为 1.0;如果是后缀,保持原随机时间 t time = jnp.where(prefix_mask, 1.0, time[:, None])
————
通常流匹配插值公式为
代入公式:
这意味着前缀部分直接输入干净的 Ground Truth (真实动作),不加噪声
这意味着后缀部分是加噪的,模型需要学习去噪 - 生成加噪输入(Noised Action)
上述代码对应于论文中的公式1# [cite: 262] x_t = time[:, :, None] * action_chunk + (1 - time[:, :, None]) * noise
但注意,由于 time 已经根据前缀/后缀进行了修改,这里的实际上是一个混合体:前半部分是真实动作,后半部分是加噪动作
- 模型预测与损失计算
上述代码对应论文中的公式2# [cite: 262-266] # 模型预测速度向量 v pred_v_t = model(observation, x_t, time) # 计算预测值与目标值 (data - noise) 的差异 loss = (pred_v_t - (action_chunk - noise)) ** 2
注意,原论文公式写为,但代码通常实现为目标方向
或
,取平方后等价,代表向量场的方向
- 损失掩码
对于上述代码而言,我们不希望模型预测前缀(因为前缀是已知的条件,且输入时没有加噪),所以只计算 Postfix (后缀) 部分的损失# [cite: 267-270] postfix_mask = jnp.logical_not(prefix_mask)[:, :, None] # 只计算后缀部分的损失 loss = jnp.sum(loss * postfix_mask) / (jnp.sum(postfix_mask) + 1e-8)
相当于教会模型:“给定观测和前
其次是第二部分:动作生成与采样
-
初始化
# [cite: 271-275] # action_prefix 包含已知的过去动作,但在延迟 d 之后的部分是无效的 x_t = jax.random.normal(rng, (b, ah, ad)) # 从纯噪声开始 time = 0.0 # 初始时间为 0 dt = 1 / num_steps # 时间步长上述代码,流匹配生成过程通常是从纯噪声
-
积分循环
# [cite: 277-279] for _ in range(num_steps): # 强制将前缀部分,替换为真实的 action_prefix x_t = jnp.where(prefix_mask[:, :, None], action_prefix, x_t)上述代码是Training-Time RTC 在推理时的核心特性。在每一步去噪过程中,作者强制将前
这类似于图像生成中的 "Inpainting"(修补),但这里是硬性约束
————
jnp.where 的逻辑是:“如果 是前缀(Mask为True),就强制使用 真实的 action_prefix;否则(Mask为False),继续使用 当前正在去噪生成的 x_t”
言外之意是,不管模型怎么算,均强制把前 -
准备模型输入
# [cite: 280-281] # 同样,前缀的时间设为 1.0,后缀的时间为当前积分时间 time time_masked = jnp.where(prefix_mask, 1.0, time) v_t = model(observation, x_t, time_masked)上述代码意味着,模型接收的 time 参数告诉它:前缀部分已经是最终结果
,不需要去噪;后缀部分还处于中间状态
,需要根据流场进行更新
-
更新Euler Step
# [cite: 282-283] x_t = x_t + dt * v_t # 更新状态 time = time + dt # 更新时间上述代码是标准的欧拉积分步。通过沿着预测的速度向量场
移动,逐渐将噪声转化为合理的动作序列
总之,这个算法巧妙地修改了输入数据构造和损失函数,而没有改变模型架构(Transformer 依然处理序列,只是不同 token 看到的 不同)
- 训练时:它教会模型看着“部分答案”(Prefix)做题
- 推理时:它允许我们直接把已经发生的动作塞进去,模型就能无缝地补全剩下的动作,从而消除了额外的计算开销
// 待更

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 25
25 0
0- 0



 已为社区贡献77条内容
已为社区贡献77条内容

所有评论(0)